注:本文为 "错误、异常与故障 |" 相关合辑。
英文引文,机翻未校。
如有内容异常,请看原文。
Errors, exceptions and faults, oh my!
错误、异常与故障,令人头疼的编程难题!
Oren Einiaka Ayende Rahien,Jun 22 2018
If we could code for the happy path only, I think that our lives would have been much nicer. Errors are hard, because you keep having to deal with them, and even basic issues in error handling can take down systems that are composed of thousands of nodes.
如果我们只需要为理想执行流程编写代码,那编程工作会轻松得多。错误处理十分棘手,因为我们必须持续应对各类错误,即便是错误处理中的基础问题,也可能导致由数千个节点组成的系统崩溃。
I went out to look at research around error handling rates, and I found this paper. It says that about 3% of code (C#, mind) is error handling. However, it counts only the code inside catch / finally as error handling. My recent foray into C allow me another data point. The short version, with no memory handling is 30 lines of code, the long version, with error handling, is over a 100.
我查阅了关于错误处理代码占比的研究,找到了这篇论文。论文指出,C# 语言中约 3% 的代码用于错误处理,但该统计仅将 catch / finally 代码块内的逻辑算作错误处理。我近期对 C 语言的研究提供了另一个参考数据:不包含内存管理的精简版代码仅有 30 行,而添加错误处理后的完整版代码超过 100 行。
If I had to guess, I would say that error handling is at least 10 -- 15 %, and I would be surprised by 25 -- 30%. In C# and similar languages, a centralized error handling strategy can help a lot in this regard, I think.
我个人推测,错误处理代码至少占总代码的 10% -- 15%,若占比达到 25% -- 30% 也不足为奇。我认为,在 C# 等编程语言中,集中式错误处理策略能极大优化这一问题。
Anyway, let's explore a few options for error handling:
接下来,我们探讨几种主流的错误处理方案:
The C way -- return codes. This sucks. I think that this is universally known to suck. In particular, there is no rhyme or reason for return codes. Something you need to check for INVALID_HANDLE_VALUE, sometimes for a value that is different from zero. Sometimes the return code is the error code. In other times you need to call a separate function to get it. It also forces you to have a very localized error handling mode. All error handling should be done all the time, which can easily lead to either a single forgotten return code causing issues down the line (forgetting to check fsync() return code got data corruption in Postgres, for example) or really bad code where you lose sight of what is actually going on because there are so much error handling that the real functionally went into hiding.
C 语言的方案------返回值。这种方式十分糟糕,这是业内公认的事实。最关键的问题是,返回值的规则毫无章法:有时需要检查是否为无效句柄值,有时需要判断是否为非零值;有时返回值本身就是错误码,有时又需要调用独立函数获取错误码。同时,这种方式强制使用局部化错误处理模式,必须时刻处理所有错误。这很容易引发两种问题:要么遗漏一次返回值检查就导致后续故障(例如,PostgreSQL 中因未检查 fsync() 返回值引发数据损坏);要么错误处理代码过于繁杂,掩盖了核心业务逻辑,导致代码可读性极差。
The return code model also doesn't compose very well, in the case of complex operations failing midway. It doesn't provide contextual information or allow you to get stack traces easily. Each of this is important if you want to have a good error handling strategy (and good debugging / troubleshooting experience).
对于中途失败的复杂操作,返回值模型的组合性也很差。它无法提供上下文信息,也难以轻松获取堆栈跟踪。对于完善的错误处理策略和高效的调试、故障排查体验而言,这两点都至关重要。
So the C way of doing things is out .What are we left? We have a few options:
既然 C 语言的方案不可取,我们还有哪些选择?主要有以下几种:
-
Go with multiple return codes
使用多返回值的 Go 语言方案
-
Rust with Option, Result
基于 Option、Result 的 Rust 语言方案
-
Node.js with callbacks
基于回调函数的 Node.js 方案
-
C# / Java with Exceptions
基于异常机制的 C# / Java 语言方案
Let's talk about the Go approach for a bit. I think that this is universally loathed as being very similar to the C method and cause a lot of code repetition. On the other hand, at least we don't have GetLastError() / errno to deal with. And one advantage off Go in this regard that the defer command allow you to much more cleanly handle state (you can just return and any resource will be cleaned up). This means that the code may be repetitive to write, but it is much easier to review.
我们简单聊聊 Go 语言的方案。业内普遍不认可这种方式,因为它和 C 语言的方案高度相似,会产生大量重复代码。但优势在于,我们无需处理 GetLastError() / errno 这类全局错误码。此外,Go 语言的 defer 语句能让状态管理更简洁:函数直接返回即可,所有资源会自动释放。这意味着编写代码时会有重复逻辑,但代码审查会更轻松。
The problem with this approach is that it is hard to compose errors. Imagine a method that needs to read a string from the network, parse a number from the string and then update a value in a file. Without error handling, this looks like so:
这种方案的核心问题是错误组合难度大。假设一个函数需要完成三个步骤:从网络读取字符串、从字符串解析数字、更新文件中的数值。不添加错误处理时,代码十分简洁:
I haven't even written the file handling path, mostly because it got too tiring. In this case, there are so many things that can go wrong. The code above handles failure to make the request, failure to read the value from the server, failure to parse the string, etc. With a file, you need to handle failure to open the file, read its content, parse them, do something with the value from the server and file value and then serialize the value back to bytes to be written to the file. About every other word in this previous statement require some form of error handling. And the problem is that when we have complex system, we don't just need to handle errors, we need to compose them so they would make sense .
我甚至没有编写文件处理逻辑,因为代码会变得过于繁琐。这个场景中存在大量可能出错的环节:上述代码需要处理请求失败、服务器数值读取失败、字符串解析失败等问题。加入文件操作后,还需要处理文件打开失败、内容读取失败、数据解析失败、服务器数值与文件数值运算失败、数值序列化失败等问题。几乎每一步操作都需要配套错误处理。而复杂系统的核心难点在于:我们不仅要处理错误,还要合理组合错误,让错误信息具备实际意义。
EPERM error from somewhere is pretty useless, so having the file name is huge help in figuring out what the problem was. But knowing that the error is actually because we tried to write to save the data to the on-disk cache give me the proper context for the error. The problem with errors is that they can happen very deeply in the code path, and the policy for handling such errors belong much higher in the stack.
一个无任何上下文的权限错误(EPERM)毫无参考价值,而附带文件名的错误能极大帮助定位问题。如果能明确错误是因写入磁盘缓存导致,就能获得完整的错误上下文。错误处理的痛点在于:错误往往发生在代码调用链路的深层,而处理策略却需要在调用链路的上层执行。
Rust's approach for errors is cleaner than Go, you don't have multiple result types but the result is actually wrapped in a Result / Option value that you need to explicitly handle. Rust also contain some syntax sugar to make this pretty easy to write.
Rust 语言的错误处理方案比 Go 更简洁:无需定义多种结果类型,而是将执行结果封装在 Result / Option 枚举中,必须显式处理。同时 Rust 提供了语法糖,降低了代码编写难度。
However, Rust error handling just plain sucks when you try to actually compose errors. Imagine the case where I want to do several operations, some of which may fail. I need to report success if all has passed, but error if any had errored. For a bit more complexity, we need to provide good context for the error, so the error isn't something as simple as "int parse failure" but with enough details to know that it was an int parse failure on the sixth line of a particular file that belong to a certain operation.
但在错误组合场景下,Rust 的错误处理方案表现极差。假设需要执行多个可能失败的操作,要求全部成功则返回成功,任意失败则返回错误。更复杂的需求是,为错误提供完整上下文:不只是简单提示"整数解析失败",而是明确告知"某操作关联的特定文件第六行整数解析失败"。
The reason I say that Rust sucks for this is that for consuming error, things are pretty simple. But for producing them? The suggestion to library authors is to implement your own Error type. That means that you need to implement the Display trait manually, you need to write a separate From trait for each error that you want to compose up. If your code suddenly need to handle a new error type, you deal with that by writing a [lot of boiler plate code. Any change in the error enum require touching multiple places in the code, violating SRP. You can use Box, it seems, but in this case, you have just "an error occurred" and it is complex to get back the real error and act on it.
我说 Rust 表现差的原因是:使用 错误很简单,但生成自定义错误却极其繁琐。官方建议库开发者自定义错误类型,这意味着需要手动实现 Display 特征,为每一种需要组合的错误单独实现 From 特征。如果代码需要新增错误类型,就必须编写大量样板代码。错误枚举的任何修改都需要改动多处代码,违反单一职责原则。虽然可以使用 Box,但这种方式只能提示"发生错误",很难获取真实错误信息并针对性处理。
A major complication of all the return something option is the fact that they usually don't provide you with a stack trace. I think that having a stack trace in the error is extremely helpful to actually analyzing a problem and being able to tell what actually happened.
所有基于返回值的方案,都存在一个核心缺陷:通常不提供堆栈跟踪。我认为,错误中的堆栈跟踪信息对问题分析、还原故障现场至关重要。
Callbacks, such as was done with node.js, are pretty horrible. On the one hand, it is much easier to provide the context, because you are called from the error site and can check your current state. However, there is only so much that you can do in such a case, and state management is a pain. Callbacks have proven to be pretty hard to program with, and the industry as a whole is moving to async/await model instead. this give you sequential like mechanism and much better way to reason about the action of the system.
Node.js 采用的回调函数方案也十分糟糕。优势是更容易提供错误上下文,因为回调会在错误发生点触发,可直接获取当前状态。但这种方案能实现的功能有限,状态管理也极为痛苦。实践证明,回调函数的开发难度极高,整个行业都在转向 async/await 模型。该模型提供了类似同步的执行机制,让系统行为的逻辑推理更简单。
Finally, we have exceptions. There are actually several different models for exceptions. You have Java with checked exceptions, with the associated baggage there (cannot change the interface, require explicit handling, etc). There is the Pony language which has "exceptions". That is really strange choice of implementation. Pony has exceptions for flow control, but it doesn't give you any context about the actual error. Just that one happened. The proper way of handling errors in Pony is to return a union of the result and possible errors (similar to how Rust does it, although the syntax looks nicer and there is less work).
最后是异常方案。异常分为多种实现模式:Java 采用受检异常,存在诸多限制(无法随意修改接口、必须显式处理异常等);Pony 语言也实现了"异常",但其设计十分怪异:异常仅用于流程控制,不提供任何错误上下文,仅提示发生错误。Pony 语言推荐的错误处理方式,是返回结果与可能错误的联合类型(和 Rust 方案类似,但语法更简洁、开发成本更低)。
I'm going to talk about C#'s exceptions. Java's exceptions, except for some of them being checked, are pretty much the same.
我重点讲解 C# 的异常机制,Java 的异常机制除了部分受检异常外,与 C# 基本一致。
Exceptions have the nice property that they are easily composable, it is easy to decide to handle some errors and to pass some up the chain. Generic error handling is also easy. Exceptions are problematic because they break the flow of the code. An exception in one location can be handled somewhere completely different, and there is no way for you to see that when looking on the code. In fact, I'm not even aware of any IDE / tooling that can provide you this insight.
异常机制的优势十分明显:组合性极佳,可以轻松选择处理部分错误、将其余错误向上抛出;通用错误处理也很便捷。但异常的缺陷是会打断代码执行流程:一处抛出的异常可能在完全不同的位置被捕获,仅通过阅读代码无法感知这一点。截至目前,我还没有发现任何 IDE 或工具能直观展示这种异常传递关系。
In languages with exceptions, you also can have exceptions pretty much at any location, which mean that you need to write exception-safe code to make sure that an exception don't leave your code in an inconsistent state. There is also a decidedly non trivial cost of exceptions. To start with, many optimizations are mitigated by try blocks and throwing exceptions is often very expensive. Part of that is the fact that we need to capture the oh so valuable stack trace, of course.
支持异常的语言中,几乎任何代码位置都可能抛出异常,这意味着必须编写异常安全代码,确保异常不会导致代码处于不一致状态。同时,异常的性能开销极大:try 代码块会影响编译器优化,抛出异常的操作通常非常耗时,这很大程度上是因为需要捕获极具价值的堆栈跟踪信息。
There is also another aspect to error handling to consider. There are many cases where you don't care about errors. Any time that you have generic framework code that calls to user code. An HTTP Handler is a good example of that. You call the user's code to handle the request, and you don't care about errors. You simple catch that error and return 500 / message to the client. Any error handling strategy must handle both scenarios. The "I really care about every single detail and separate error handling code path for everything" and "I just want to know if there is an error and print it, nothing else".
错误处理还有一个重要维度需要考虑:大量场景下我们无需关心错误细节。例如通用框架调用用户代码时,HTTP 请求处理器就是典型案例:框架调用开发者代码处理请求,无需关心具体错误,只需捕获异常并向客户端返回 500 状态码和错误信息即可。任何优秀的错误处理策略,都必须同时适配两种场景:一是需要关注所有细节、为每种错误单独处理的场景;二是仅需感知错误并打印信息的极简场景。
In theory, I really love the Rust error handling mechanism, but the complexity of composability and generic handling means that it is a lot less convenient to actually consume and produce errors. Exceptions are great in terms of composability and the amount of detail they provide, but they are also breaking the flow of the code and introduce a separate and invisible code paths that are hard to reason about in many cases. On the other hand, exceptions allow you to bubble errors upward natively and easily,直到执行到具备对应处理策略的代码位置。
理论上,我非常喜欢 Rust 的错误处理机制,但错误组合和通用处理的复杂性,让实际开发中生成和使用错误变得十分不便。异常机制在组合性和信息完整性上表现优秀,但会打断代码流程,引入独立且不可见的执行路径,多数场景下难以推理逻辑。不过,异常的核心优势是支持原生、便捷的向上抛出,直到传递到能够执行对应处理策略的代码位置。
A good example from a recent issue we had to deal with. When running on a shared drive, a file delete isn't going to be processed immediately, there is a gap of time in which the delete command seems to have succeeded, but attempting to re-create the file will fail with EEXISTS (and trying to open the file will give you ENOENT, so that's fun). In this case, we throw the error up the stack. In our use case, we have this situation only when dealing with temporary files, and given that they are temporary, we can detect this scenario and use another file name to avoid this issue. So we catch a FileNotFoundException and retry with a different file name. This goes through four of five layers of code and was pretty simple to figure out and implement.
分享一个我们近期处理的实际案例:在共享磁盘中,文件删除操作不会立即执行,存在一段窗口期------删除命令看似执行成功,但重新创建文件会报文件已存在错误(EEXISTS),而打开文件又会报文件不存在错误(ENOENT),十分棘手。这种场景下,我们将错误向上抛出。由于该问题仅出现在临时文件操作中,且临时文件可灵活更名,因此我们能检测到该场景,通过更换文件名重试来解决问题。我们只需捕获文件未找到异常,并用新文件名重试即可,整个逻辑跨越了四到五层代码,排查和实现都非常简单。
Doing that with error codes is hard, and adding another member for the Error type will likely have cascading implications for the rest of the code. On the other hand, throwing a new exception type from a method can also break the contract. Explicitly in languages like Java and implicitly in languages like C#. In fact, with C#, for example, the implied assumption is always: "Can throw the following exceptions for known error cases, and other exceptions for unexpected". This is similar to checked exceptions vs. runtime exceptions in Java. But in this case, this is the implicit default and it gives you more freedom overall when writing your code. Checked exceptions sounds great, but they have been proven to be a problem for developers in practices.
如果用返回值实现这个逻辑会非常困难,为错误类型新增成员还可能对其他代码产生级联影响。另一方面,函数抛出新的异常类型也可能破坏接口约定:在 Java 中是显式破坏,在 C# 中是隐式破坏。实际上,C# 的默认约定是:为已知错误抛出指定异常,为未知错误抛出其他通用异常,这和 Java 的受检异常与运行时异常的划分类似。但 C# 的隐式默认规则,让代码编写拥有更高的自由度。受检异常听起来很完美,但实践证明它给开发者带来了诸多麻烦。
Oh well, I guess I won't be able to solve the error handling problem perfectly in a single blog post.
唉,我想单凭一篇博客文章,是无法完美解决错误处理这个行业难题的。
Simple Testing Can Prevent Most Critical Failures: An Analysis of Production Failures in Distributed Data-Intensive Systems
简单测试即可规避绝大多数严重故障------面向分布式数据密集型系统线上故障的分析研究
usenix
A
ASSOCIATION
美国计算机系统设计实现研讨会(USENIX)协会
Ding Yuan, Yu Luo, Xin Zhuang, Guilherme Renna Rodrigues, Xu Zhao, Yongle Zhang, Pranay U. Jain, and Michael Stumm, University of Toronto
多伦多大学:丁元、罗宇、庄鑫、吉列尔梅·雷纳·罗德里格斯、赵旭、张永乐、普拉纳伊·U·贾因、迈克尔·斯塔姆
This paper is included in the Proceedings of the 11th USENIX Symposium on Operating Systems Design and Implementation. October 6--8, 2014 • Broomfield, CO 978-1-931971-16-4
本文收录于第 11 届 USENIX 操作系统设计与实现研讨会论文集,会议于 2014 年 10 月 6 日至 8 日在美国科罗拉多州布鲁姆菲尔德举办,ISBN:978-1-931971-16-4。
Open access to the Proceedings of the 11th USENIX Symposium on Operating Systems Design and Implementation is sponsored by USENIX.
第 11 届 USENIX 操作系统设计与实现研讨会论文集的开放获取由 USENIX 协会赞助。
Abstract
摘要
Large, production quality distributed systems still fail periodically, and do so sometimes catastrophically, where most or all users experience an outage or data loss. We present the result of a comprehensive study investigating 198 randomly selected, user-reported failures that occurred on Cassandra, HBase, Hadoop Distributed File System (HDFS), Hadoop MapReduce, and Redis, with the goal of understanding how one or multiple faults eventually evolve into a user-visible failure. We found that from a testing point of view, almost all failures require only 3 or fewer nodes to reproduce, which is good news considering that these services typically run on a very large number of nodes. However, multiple inputs are needed to trigger the failures with the order between them being important. Finally, we found the error logs of these systems typically contain sufficient data on both the errors and the input events that triggered the failure, enabling the diagnose and the reproduction of the production failures.
大规模商用分布式系统仍会间歇性出现故障,部分故障会演变为灾难性事故,造成大部分甚至全部用户服务中断或数据丢失。本文针对 Cassandra、HBase、Hadoop 分布式文件系统(HDFS)、Hadoop MapReduce 以及 Redis 五款系统,随机选取 198 条用户上报的线上故障开展全面研究,旨在分析单个或多个缺陷如何逐步演变为用户可感知的故障。研究发现:从测试角度来看,几乎所有故障仅需 3 个及以内节点即可复现,而这类服务通常部署在大规模集群中,该结论具备实际参考价值;但故障触发往往需要多个输入事件,且事件的执行顺序至关重要。此外,这类系统的错误日志通常完整记录了故障信息与触发故障的输入事件,能够支撑线上故障的排查与复现。
We found the majority of catastrophic failures could easily have been prevented by performing simple testing on error handling code -- the last line of defense -- even without an understanding of the software design. We extracted three simple rules from the bugs that have lead to some of the catastrophic failures, and developed a static checker, Aspirator, capable of locating these bugs. Over 30% of the catastrophic failures would have been prevented had Aspirator been used and the identified bugs fixed. Running Aspirator on the code of 9 distributed systems located 143 bugs and bad practices that have been fixed or confirmed by the developers.
研究表明,即便不深入理解软件架构,仅针对作为最后一道防护屏障的异常处理代码开展基础测试,就能规避大部分灾难性故障。本文从引发灾难性故障的缺陷中总结出三条简易规则,并基于规则实现静态检测工具 Aspirator,用于识别此类缺陷。若提前使用该工具并修复检出问题,可规避超 30% 的灾难性故障。将 Aspirator 应用于 9 款分布式系统后,共检出 143 处缺陷与不规范编码行为,相关问题均已得到开发人员确认或修复。
1 Introduction
1 引言
Real-world distributed systems inevitably experience outages. For example, an outage to Amazon Web Services in 2011 brought down Reddit, Quora, FourSqure, part of the New York Times website, and about 70 other sites 1, and an outage of Google in 2013 brought down Internet traffic by 40% 21. In another incident, a DNS error dropped Sweden off the Internet, where every URL in the .se domain became unmappable 46.
实际运行中的分布式系统难免出现服务中断。例如,2011 年亚马逊云服务故障导致红迪网、问答平台 Quora、四方定位、《纽约时报》部分页面及其他约 70 个网站瘫痪;2013 年谷歌服务中断致使全球网络流量下降 40%;还有一起域名系统故障导致瑞典国家域名(.se)下所有网址解析失败,整个国家网络断连。
Given that many of these systems were designed to be highly available, generally developed using good software engineering practices, and intensely tested, this raises the questions of why these systems still experience failures and what can be done to increase their resiliency. To help answer these questions, we studied 198 randomly sampled, user-reported failures of five data-intensive distributed systems that were designed to tolerate component failures and are widely used in production environments. The specific systems we considered were Cassandra, HBase, Hadoop Distributed File System (HDFS), Hadoop MapReduce, and Redis.
这类系统均以高可用为设计目标,开发过程遵循标准软件工程规范,且经过充分测试。这也引出两个问题:为何系统仍会频发故障?如何提升系统容错能力?为解答上述问题,本文选取五款具备组件容错能力、在生产环境广泛使用的数据密集型分布式系统,随机抽取 198 条用户上报故障展开研究,研究对象包括 Cassandra、HBase、Hadoop 分布式文件系统(HDFS)、Hadoop MapReduce 与 Redis。
Our goal is to better understand the specific failure manifestation sequences that occurred in these systems in order to identify opportunities for improving their availability and resiliency. Specifically, we want to better understand how one or multiple errors evolve into component failures and how some of them eventually evolve into service-wide catastrophic failures. Individual elements of the failure sequence have previously been studied in isolation, including root causes categorizations 33, 52, 50, 56, different types of causes including misconfiguraitons 43, 66, 49, bugs 12, 41, 42, 51 hardware faults 62, and the failure symptoms 33, 56, and many of these studies have made significant impact in that they led to tools capable of identifying many bugs (e.g., 16, 39). However, the entire manifestation sequence connecting them is far less well-understood.
本文旨在梳理系统故障的完整演变流程,以此寻找提升系统可用性与容错能力的优化方向。具体而言,研究重点为:单个或多个异常如何演变为组件故障,部分组件故障又如何进一步扩散为全域灾难性故障。过往研究大多孤立分析故障流程中的单一环节,例如根因分类、配置错误、代码缺陷、硬件故障、故障现象等,也据此研发出多款缺陷检测工具并取得良好效果。但针对故障从产生到扩散的完整链路,目前相关研究仍较为匮乏。
For each failure considered, we carefully studied the failure report, the discussion between users and developers, the logs and the code, and we manually reproduced 73 of the failures to better understand the specific manifestations that occurred.
针对每一条样本故障,本文逐一研读故障工单、用户与开发人员的沟通记录、系统日志及源码,并手动复现其中 73 起故障,深入分析故障的具体表现形式。
Overall, we found that the error manifestation sequences tend to be relatively complex: more often than not, they require an unusual sequence of multiple events with specific input parameters from a large space to lead the system to a failure. This is perhaps not surprising considering that these systems have undergone thorough testing using unit tests, random error injections 18, and static bug finding tools such as FindBugs 32, and they are deployed widely and in constant use at many organization. But it does suggest that top-down testing, say using input and error injection techniques, will be challenged by the large input and state space. This is perhaps why these studied failures escaped the rigorous testing used in these software projects.
整体来看,故障的演变流程较为复杂:多数故障需要一系列非常规事件按特定顺序触发,同时搭配海量参数空间中的特定入参,才能使系统出现异常。这类系统均经过单元测试、随机故障注入、FindBugs 等静态缺陷检测工具的全面测试,且已在大量机构落地并长期运行,出现此类故障并不意外。这也说明,基于输入与故障注入的自上而下测试方式,会受限于庞大的输入空间与系统状态空间,难以覆盖全部场景,这也是现有测试流程未能发现这类故障的核心原因。
We further studied the characteristics of a specific subset of failures - the catastrophic failures that affect all or a majority of users instead of only a subset of users. Catastrophic failures are of particular interest because they are the most costly ones for the vendors, and they are not supposed to occur as these distributed systems are designed to withstand and automatically recover from component failures. Specifically, we found that:
本文进一步聚焦一类特殊故障------灾难性故障,这类故障会影响全部或大部分用户,而非局部用户。灾难性故障会给服务商带来巨大损失,而分布式系统本就设计为可抵御组件故障并自动恢复,因此这类故障的成因极具研究价值。本文得出如下结论:
almost all (92%) of the catastrophic system failures are the result of incorrect handling of non-fatal errors explicitly signaled in software.
92% 的系统灾难性故障,均源于软件对可预见的非致命异常处理不当。
While it is well-known that error handling code is often buggy 24, 44, 55, its sheer prevalence in the causes of the catastrophic failures is still surprising. Even more surprising given that the error handling code is the last line of defense against failures, we further found that:
业内早已知晓异常处理代码是缺陷高发区域,但该问题成为绝大多数灾难性故障的根因,仍超出预期。异常处理代码是抵御故障的最后一道防线,本文还发现:
in 58% of the catastrophic failures, the underlying faults could easily have been detected through simple testing of error handling code.
58% 的灾难性故障,其底层缺陷仅需对异常处理代码开展基础测试即可检出。
In fact, in 35% of the catastrophic failures, the faults in the error handling code fall into three trivial patterns: (i) the error handler is simply empty or only contains a log printing statement, (ii) the error handler aborts the cluster on an overly-general exception, and (iii) the error handler contains expressions like "FIXME" or "TODO" in the comments. These faults are easily detectable by tools or code reviews without a deep understanding of the runtime context. In another 23% of the catastrophic failures, the error handling logic of a non-fatal error was so wrong that any statement coverage testing or more careful code reviews by the developers would have caught the bugs.
具体而言,35% 的灾难性故障对应的异常处理缺陷可归纳为三类低级问题:(1)异常处理块为空,或仅打印日志无任何处理逻辑;(2)捕获范围过广的异常,并直接关停整个集群;(3)代码注释中包含 FIXME、TODO 等待完善标记。这类缺陷无需结合运行时场景,通过工具扫描或代码审查就能轻松发现。另有 23% 的灾难性故障,其非致命异常的处理逻辑存在明显错误,开发人员通过语句覆盖测试或细致的代码审查即可检出。
To measure the applicability of the simple rules we extracted from the bugs that have lead to catastrophic failures, we implemented Aspirator, a simple static checker. Aspirator identified 121 new bugs and 379 bad practices in 9 widely used, production quality distributed systems, despite the fact that these systems already use state-of-the-art bug finding tools such as FindBugs 32 and error injection tools 18. Of these, 143 have been fixed or confirmed by the systems' developers.
为验证从故障缺陷中总结的简易规则的实用性,本文实现了静态检测工具 Aspirator。多款商用分布式系统已部署 FindBugs、故障注入等主流检测工具,在此前提下,Aspirator 仍在 9 款常用分布式系统中检出 121 处新增缺陷与 379 项不规范编码行为,其中 143 项问题已被开发人员确认或修复。
Our study also includes a number of additional observations that may be helpful in improving testing and debugging strategies. We found that 74% of the failures are deterministic in that they are guaranteed to manifest with an appropriate input sequence, that almost all failures are guaranteed to manifest on no more than three nodes, and that 77% of the failures can be reproduced by a unit test.
本文还总结了多项可用于优化测试与排障策略的结论:74% 的故障属于确定性故障,只要按指定顺序输入事件,故障必然复现;几乎所有故障均可在不超过 3 个节点的环境中复现;77% 的故障能够通过单元测试完成复现。
Moreover, in 76% of the failures, the system emits explicit failure messages; and in 84% of the failures, all of the triggering events that caused the failure are printed into the log before failing. All these indicate that the failures can be diagnosed and reproduced in a reasonably straightforward manner, with the primary challenge being to have to sift through relatively noisy logs.
此外,76% 的故障会触发系统输出明确的报错信息;84% 的故障在发生前,所有触发事件均已被日志记录。以上特征说明,这类故障的排查与复现难度较低,主要难点在于从海量冗余日志中筛选有效信息。
2 Methodology and Limitations
2 研究方法与局限性
We studied 198 randomly sampled, real world failures reported on five popular distributed data-analytic and storage systems, including HDFS, a distributed file system 27; Hadoop MapReduce, a distributed data-analytic framework 28; HBase and Cassandra, two NoSQL distributed databases 2, 3; and Redis, an inmemory key-value store supporting master/slave replication 54. We focused on distributed data-intensive systems because they are the building blocks of many internet software services, and we selected the five systems because they are widely used and are considered production quality.
本文从五款主流分布式数据分析与存储系统中随机抽取 198 条线上真实故障开展研究,研究对象包括:分布式文件系统 HDFS、分布式数据分析框架 Hadoop MapReduce、两款 NoSQL 分布式数据库 HBase 与 Cassandra,以及支持主从复制的内存键值数据库 Redis。数据密集型分布式系统是各类互联网服务的基础组件,且这五款系统均经过商用验证、应用范围极广,因此被选为研究样本。
The failures we studied were extracted from the issue tracking databases of these systems. We selected tickets from these databases because of their high quality: each selected failure ticket documents a distinct failure that is confirmed by the developers, the discussions between users and developers, and the failure resolutions in the form of a patch or configuration change. Duplicate failures were marked by the developers, and are excluded from our study.
研究样本均取自对应系统的问题跟踪库。该类工单数据质量较高:每一条入选工单均对应一起经开发人员确认的独立故障,完整留存了用户与开发人员的沟通记录,以及通过代码补丁或配置修改完成的故障修复方案。开发人员标记的重复故障工单已被剔除。
The specific set of failures we considered were selected from the issue tracking databases as follows. First, we only selected severe failures with the failure ticket priority field marked as "Blocker", "Critical", or "Major". Secondly, we only considered tickets dated 2010 or later so as not to include failures of obsolete systems or systems early in their lifetime. Thirdly, we filtered out failures in testing systems by heuristically rejecting failures where the reporter and assignee (i.e., the developer who is assigned to resolve the failure) were the same. Finally, we randomly selected failures from the remaining set to make our observations representative of the entire failure population. Table 1 shows the distribution of the failure sets considered amongst the five systems and their sampling rates.
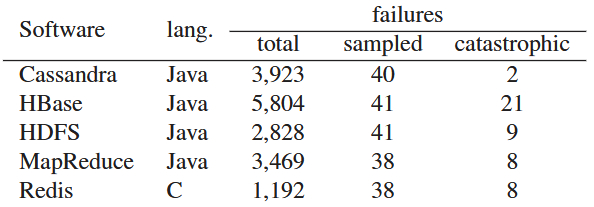
故障筛选规则如下:第一,仅选取优先级为"阻断级""严重级""主要级"的高危故障工单;第二,工单创建时间不早于 2010 年,排除老旧系统或系统早期版本的故障;第三,通过规则过滤测试环境故障,剔除上报人与处理人(负责修复故障的开发人员)为同一人的工单;最后,在剩余工单中随机抽样,保证样本能够反映整体故障特征。表 1 展示了五款系统的故障总量、抽样数量及灾难性故障数量。
Table 1 : Number of reported and sampled failures for the systems we studied, and the catastrophic ones from the sample set.
表 1 研究系统的故障上报总量、抽样数量及样本中的灾难性故障数量
For each sampled failure ticket, we carefully studied the failure report, the discussion between users and developers, related error logs, the source code, and patches to understand the root cause and its propagation leading to the failure. We also manually reproduced 73 of the failures to better understand them.
针对每一条抽样工单,本文逐一分析故障描述、沟通记录、错误日志、源码与修复补丁,梳理故障根因与传播链路,并手动复现其中 73 起故障以深化分析。
Limitations: as with all characterization studies, there is an inherent risk that our findings may not be representative. In the following we list potential sources of biases and describe how we used our best-efforts to address them.
研究局限性:同所有特征分析类研究一样,本文结论存在无法完全代表全体场景的风险。下文列出潜在偏差来源,以及对应的规避措施。
(1) Representativeness of the selected systems . We only studied distributed, data-intensive software systems. As a result, our findings might not generalize to other types of distributed systems such as telecommunication networks or scientific computing systems. However, we took care to select diverse types of data-intensive programs that include both data-storage and analytical systems, both persistent store and volatile caching, both written in Java and C, both master-slave and peer-to-peer designs. (HBase, HDFS, Hadoop MapReduce, and Redis use master-slave design, while Cassandra uses a peer-to-peer gossiping protocol.) At the very least, these projects are widely used: HDFS and Hadoop MapReduce are the main elements of the Hadoop platform, which is the predominant big-data analytic solution 29; HBase and Cassandra are the top two most popular wide column store system 30, and Redis is the most popular keyvalue store system 53.
研究系统的代表性。本文仅针对数据密集型分布式系统开展研究,结论不一定适用于通信网络、科学计算等其他类型分布式系统。但本次选取的数据密集型系统覆盖多种类型:包含存储系统与分析框架、持久化存储与内存缓存、Java 与 C 两种开发语言、主从架构与点对点架构(HBase、HDFS、MapReduce、Redis 采用主从架构,Cassandra 采用点对点 Gossip 协议)。所选系统均为行业主流:HDFS 与 MapReduce 是大数据平台 Hadoop 的核心组件;HBase 与 Cassandra 是应用最广泛的两大宽列存储数据库;Redis 是主流键值数据库。
Our findings also may not generalize to systems earlier in their development cycle since we only studied systems considered production quality. However, while we only considered tickets dated 2010 or later to avoid bugs in premature systems, the buggy code may have been newly added. Studying the evolutions of these systems to establish the correlations between the bug and the code's age remains as the future work.
本文研究对象均为商用成熟系统,因此结论不一定适用于开发初期的系统。虽然本次筛选 2010 年及之后的工单以规避早期系统缺陷,但故障对应的问题代码也可能是后期新增的。分析系统迭代过程、探究缺陷与代码迭代周期的关联,将作为后续研究方向。
(2) Representativeness of the selected failures . Another potential source of bias is the specific set of failures we selected. We only studied tickets found in the issue tracking databases that are intended to document software bugs. Other errors, such as misconfigurations, are more likely to be reported in user discussion forums, which we chose not to study because they are much less rigorously documented, lack authoritative judgements, and are often the results of trivial mistakes. Consequently, we do not draw any conclusions on the distribution of faults, which has been well-studied in complementary studies 50, 52. Note, however, that it can be hard for a user to correctly identify the nature of the cause of a failure; therefore, our study still includes failures that stem from misconfigurations and hardware faults.
抽样故障的代表性。本次研究仅分析问题跟踪库中记录的代码缺陷类工单。配置错误等问题大多上报至用户论坛,这类数据记录不规范、缺少权威判定,且多为简单人为失误,因此未纳入研究范围。本文不针对故障根因分布得出结论,该方向已有大量专项研究。需要说明的是,普通用户难以精准判定故障类型,因此本次样本中仍包含配置错误、硬件故障引发的问题。
In addition, we excluded duplicated bugs from our study so that our study reflects the characteristics of distinct bugs. One could argue that duplicated bugs should not be removed because they happened more often. There were only a total of 10 duplicated bugs that were excluded from our original sample set. Therefore they would not significantly change our conclusions even if they were included.
此外,本文剔除了重复缺陷工单,确保样本反映独立缺陷的特征。有观点认为重复故障发生频次更高,不应剔除,但本次仅剔除 10 条重复工单,即便保留也不会对整体结论造成明显影响。
(3) Size of our sample set . Modern statistics suggests that a random sample set of size 30 or more is large enough to represent the entire population 57. More rigorously, under standard assumptions, the Central Limit Theorem predicts a 6.9% margin of error at the 95% confidence level for our 198 random samples. Obviously, one can study more samples to further reduce the margin of error.
样本量。现代统计学表明,随机样本量达到 30 及以上即可代表整体特征。基于中心极限定理计算,本次 198 条随机样本在 95% 置信水平下,误差幅度为 6.9%。扩大样本量可进一步降低误差。
(4) Possible observer errors . To minimize the possibility of observer errors in the qualitative aspects of our study, all inspectors used the same detailed written classification methodology, and all failures were separately investigated by two inspectors before consensus was reached.
人为分析误差。为降低定性分析中的人为误差,所有分析人员统一使用标准化分类规则;每一条故障均由两名分析人员独立研判,达成一致后才确定结论。
3 General Findings
3 整体研究结论
This section discusses general findings from the entire failure data set in order to provide a better understanding as to how failures manifest themselves. Table 2 categorizes the symptoms of the failures we studied.
本节基于全部故障样本总结通用结论,梳理故障的表现形式。表 2 对故障现象进行分类统计。
Table 2 : Symptoms of failures observed by end-users or operators. The right-most column shows the number of catastrophic failures with "%" identifying the percentage of catastrophic failures over all failures with a given symptom. *: examples of potential data loss include under-replicated data blocks.
表 2 终端用户与运维人员观测到的故障现象。最右侧列为对应现象下的灾难性故障数量,百分比为该类现象中灾难性故障的占比。注:潜在数据丢失包含数据块副本数不足等场景。
| Symptom 故障现象 | all 全部故障 | catastrophic 灾难性故障 |
|---|---|---|
| Unexpected termination 进程异常退出 | 74 | 17 (23%) |
| Incorrect result 结果错误 | 44 | 1 (2%) |
| Data loss or potential data loss* 数据丢失 / 潜在数据丢失 | 40 | 19 (48%) |
| Hung System 系统卡死 | 23 | 9 (39%) |
| Severe performance degradation 性能严重下降 | 12 | 2 (17%) |
| Resource leak/exhaustion 资源泄露 / 资源耗尽 | 5 | 0 (0%) |
| Total 总计 | 198 | 48 (24%) |
Overall, our findings indicate that the failures are relatively complex, but they identify a number of opportunities for improved testing. We also show that the logs produced by these systems are rich with information, making the diagnosis of the failures mostly straightforward. Finally, we show that the failures can be reproduced offline relatively easily, even though they typically occurred on long-running, large production clusters. Specifically, we show that most failures require no more 3 nodes and no more than 3 input events to reproduce, and most failures are deterministic. In fact, most of them can be reproduced with unit tests.
整体而言,故障的触发逻辑较为复杂,但也为测试优化提供了明确方向。系统日志包含充足的有效信息,大幅降低故障排查难度。即便故障发生在长期运行的大规模生产集群中,离线复现的难度也相对较低:大部分故障仅需不超过 3 个节点、不超过 3 个输入事件即可复现,且多数为确定性故障,可通过单元测试完成复现。
Table 3 : Minimum number of input events required to trigger the failures.
表 3 触发故障所需的最少输入事件数量
| Num. of events 事件数量 | % 占比 | Classification 分类 |
|---|---|---|
| 1 | 23% | single event 单一事件 |
| 2 | 50% | multiple events 多事件组合 |
| 3 | 17% | multiple events 多事件组合 |
| 4 | 5% | multiple events 多事件组合 |
| >4 大于 4 | 5% | multiple events 多事件组合 |
3.1 Complexity of Failures
3.1 故障的复杂度
Overall, our findings indicate that the manifestations of the failures are relatively complex.
整体来看,故障的表现与触发逻辑具备一定复杂度。
Finding 1 : A majority (77%) of the failures require more than one input event to manifest, but most of the failures (90%) require no more than 3. (See Table 3.)
结论 1:77% 的故障需要多个输入事件共同触发,90% 的故障触发所需输入事件不超过 3 个(详见表 3)。
Table 4 : Input event type. The % column reports the percentage of failure where the input event is required to trigger the failure. Most failures require multiple preceding events, so the sum of the "%" column is greater than 100%.
表 4 输入事件类型。百分比表示该类事件参与触发的故障占比。由于多数故障由多个事件共同触发,各占比之和大于 100%。
| Input event type 输入事件类型 | % 占比 |
|---|---|
| Starting a service 服务启动 | 58% |
| File/database write from client 客户端文件/数据库写入 | 32% |
| Unreachable node (network error, crash, etc.) 节点不可达(网络异常、节点宕机等) | 24% |
| Configuration change 配置变更 | 23% |
| Adding a node to the running system 运行中集群新增节点 | 15% |
| File/database read from client 客户端文件/数据库读取 | 13% |
| Node restart (intentional) 手动重启节点 | 9% |
| Data corruption 数据损坏 | 3% |
| Other 其他 | 4% |
Figure 1 provides an example where three input events are required for the failure to manifest.
图 1 展示了一起需要 3 个输入事件才能触发的故障案例。
Table 4 categorizes the input events that lead to failures into 9 categories. We consider these events to be "input events" from a testing and diagnostic point of view - some of the events (e.g., "unreachable node", "data corruption") are not strictly user inputs but can easily be emulated by a tester or testing tools. Note that many of the events have specific requirements for a failure to manifest (e.g., a "file write" event needs to occur on a particular data block), making the input event space to explore for testing immensely large.
本文将触发故障的输入事件划分为 9 类。从测试与排障视角,这类事件均定义为"输入事件";其中部分事件(如节点不可达、数据损坏)并非严格意义上的用户输入,但测试人员与测试工具可轻松模拟。多数故障对事件执行对象有特定要求(例如文件写入需作用于指定数据块),导致测试需要覆盖的输入空间极其庞大。
Of the 23% of failures that require only a single event to manifest, the event often involves rarely used or newly introduced features, or are caused by concurrency bugs.
23% 仅需单一事件触发的故障,大多对应冷门功能、新上线功能,或是并发缺陷引发的问题。
Finding 2 : The specific order of events is important in 88% of the failures that require multiple input events.
结论 2:在需要多事件触发的故障中,88% 的故障对事件执行顺序有严格要求。
Obviously, most of the individual events in Table 4 are heavily exercised and tested (e.g., read and write), which is why only in minority of cases will a single input event induce a failure. In most cases, a specific combination and sequence of multiple events is needed to transition the system into a failed state. Consider the failure example shown in Figure 1. While the events "upload file", "append to file", and "add another datanode" are not problematic individually, the combination of the first two will lead the system into an error state, and the last event actually triggers the failure.
表 4 中的多数单一事件(如读写操作)均经过高频测试,因此仅有少数故障可由单一事件触发。绝大多数故障需要多个事件按特定组合与顺序执行,才能使系统进入异常状态。以图 1 案例为例:文件上传、文件追加、新增数据节点这三个事件单独执行均无问题,但前两个事件会让系统进入异常状态,最后一个事件则最终触发故障。
Figure 1 : An HDFS failure where a data block remains under-replicated, potentially leading to a data loss. Three input events are needed (shown in boxes): (1) the user uploads a data block, causing HDFS to assign a generation stamp. NameNode (NN) asks DataNode1 (DN1) to store this block, and because this block is currently under-replicated, adds it to needReplication queue. (2) the user appends to this block, causing DN1 to increment the generation stamp from 100 to 101. However, the generation stamp in the needReplication queue is not updated -- an error. (3) DN2 is started, so NN asks DN1 to replicate the block to DN2. But since the generation stamps from needReplication queue and DN1 do not match, DN1 keeps refusing to replicate.
图 1 HDFS 数据块副本不足故障(存在数据丢失风险)。该故障需 3 个输入事件触发:(1)用户上传数据块,HDFS 为数据块分配版本戳;名称节点(NN)将数据块下发至数据节点 1(DN1)存储,因副本数不足,该数据块被加入待复制队列。(2)用户对该数据块执行追加操作,DN1 将版本戳由 100 更新为 101,但待复制队列中的版本戳未同步更新,产生异常。(3)数据节点 2(DN2)启动,名称节点要求 DN1 向 DN2 复制数据块;由于队列版本戳与 DN1 本地版本戳不一致,DN1 拒绝执行复制操作。
Finding 1 and 2 show the complexity of failures in large distributed system. To expose the failures in testing, we need to not only explore the combination of multiple input events from an exceedingly large event space, we also need to explore different permutations.
结论 1 与结论 2 体现了大型分布式系统故障的复杂性。测试过程中,不仅需要在海量事件空间中遍历多事件组合,还需要覆盖不同的事件执行顺序。
3.2 Opportunities for Improved Testing
3.2 测试优化方向
Additional opportunities to improve existing testing strategies may be found when considering the types of input events required for a failure to manifest. We briefly discuss some of the input event types of Table 4.
结合触发故障的事件类型,可进一步优化现有测试方案。下文针对表 4 中的典型事件类型展开分析。
Starting up services: More than half of the failures require the start of some services. This suggests that the starting of services - especially more obscure ones - should be more heavily tested. About a quarter of the failures triggered by starting a service occurred on systems that have been running for a long time; e.g., the HBase "Region Split" service is started only when a table grows larger than a threshold. While such a failure may seem hard to test since it requires a long running system, it can be exposed intentionally by forcing a start of the service during testing.
服务启动:超半数故障与服务启动相关。这说明需要加强服务启动场景的测试,尤其是冷门服务。由服务启动触发的故障中,约四分之一发生在长期运行的系统上,例如 HBase 的分区拆分服务仅在数据表大小超过阈值时才会启动。这类故障看似依赖系统长期运行,实则可在测试中主动强制启动对应服务,从而覆盖该场景。
Unreachable nodes: 24% of the failures occur because a node is unreachable. This is somewhat surprising given that network errors and individual node crashes are expected to occur regularly in large data centers 14. This suggests that tools capable of injecting network errors systematically 18, 23, 65 should be used more extensively when inputing other events during testing.
节点不可达:24% 的故障由节点不可达引发。大型数据中心中网络异常、节点宕机属于常态,该占比超出预期。这表明在执行其他测试操作时,应更多使用自动化网络故障注入工具,模拟节点不可达场景。
Configuration changes: 23% of the failures are caused by configuration changes. Of those, 30% involve misconfigurations. The remaining majority involve valid changes to enable certain features that may be rarely used. While the importance of misconfigurations have been observed in previous studies 22, 50, 66, only a few techniques exist to automatically explore configurations changes and test the resulting reaction of the system 19, 40, 63. This suggests that testing tools should be extended to combine (both valid and invalid) configuration changes with other operations.
配置变更:23% 的故障由配置变更引发,其中 30% 属于配置错误,其余大部分为启用冷门功能的合规配置修改。过往研究已证实配置错误的危害性,但目前能够自动遍历配置项并验证系统表现的工具较少。因此需要扩展测试工具能力,将合规配置变更、错误配置变更与其他操作结合开展测试。
Adding a node: 15% of the failures are triggered by adding a node to a running system. Figure 1 provides an example. This is somewhat alarming, given that elastically adding and removing nodes is one of the principle promises of "cloud computing". It suggests that adding nodes needs to be tested under more scenarios.
新增节点:15% 的故障由运行中集群新增节点触发,图 1 即为典型案例。弹性扩缩容是云计算的核心能力之一,该类故障的存在需重视,应在更多场景下开展节点扩容测试。
The production failures we studied typically manifested themselves on configurations with a large number of nodes. This raises the question of how many nodes are required for an effective testing and debugging system.
本次研究的线上故障大多发生在大规模集群中,由此引出一个问题:开展有效测试与故障复现,最少需要多少个节点?
Finding 3 : Almost all (98%) of the failures are guaranteed to manifest on no more than 3 nodes. 84% will manifest on no more than 2 nodes. (See Table 5.)
结论 3:98% 的故障可在不超过 3 个节点的环境中稳定复现,84% 的故障可在不超过 2 个节点的环境中复现(详见表 5)。
Table 5 : Min. number of nodes needed to trigger the failures.
表 5 触发故障所需的最少节点数(累计占比)
| Number of nodes 节点数量 | all failures 全部故障 | catastrophic 灾难性故障 |
|---|---|---|
| 1 1 个 | 37% | 43% |
| ≤2 不超过 2 个 | 84% | 86% |
| ≤3 不超过 3 个 | 98% | 98% |
| >3 大于 3 个 | 100% | 100% |
The number is similar for catastrophic failures. Finding 3 implies that it is not necessary to have a large cluster to test for and reproduce failures.
灾难性故障的节点分布规律与整体故障基本一致。结论 3 说明,测试与故障复现无需搭建大规模集群。
Note that Finding 3 does not contradict the conventional wisdom that distributed system failures are more likely to manifest on large clusters. In the end, testing is a probabilistic exercise. A large cluster usually involves more diverse workloads and fault modes, thus increasing the chances for failures to manifest. However, what our finding suggests is that it is not necessary to have a large cluster of machines to expose bugs, as long as the specific sequence of input events occurs.
该结论与"分布式系统故障更易在大规模集群中出现"的普遍认知并不冲突。测试本质是概率性验证:大规模集群承载的负载与故障场景更丰富,故障触发概率更高。但本文结论证明,只要还原指定的事件序列,小规模集群同样能够复现缺陷。
We only encountered one failure that required a larger number of nodes (over 1024): when the number of simultaneous Redis client connections exceeded the OS limit, epoll() returned error, which was not handled properly, causing the entire cluster to hang. All of the other failures require fewer than 10 nodes to manifest.
本次样本中仅 1 起故障需要超过 1024 个节点才能触发:Redis 客户端并发连接数超出操作系统上限,epoll 调用返回异常,而系统未正确处理该异常,最终导致整个集群卡死。其余所有故障均可在少于 10 个节点的环境中复现。
Table 6 : Number of failures that are deterministic.
表 6 确定性故障统计
| Software 软件系统 | deterministic failures 确定性故障占比 |
|---|---|
| Cassandra | 76% (31/40) |
| HBase | 71% (29/41) |
| HDFS | 76% (31/41) |
| MapReduce | 63% (24/38) |
| Redis | 79% (30/38) |
| Total 总计 | 74% (147/198) |
3.3 The Role of Timing
3.3 时序因素的影响
A key question for testing and diagnosis is whether the failures are guaranteed to manifest if the required sequence of input events occur (i.e., deterministic failures), or not (i.e., non-deterministic failures)?
测试与排障的核心问题之一:在还原指定输入事件序列后,故障是否必然复现(即区分确定性故障与非确定性故障)。
Finding 4 : 74% of the failures are deterministic - they are guaranteed to manifest given the right input event sequences. (See Table 6.)
结论 4:74% 的故障属于确定性故障,只要执行指定的输入事件序列,故障必然复现(详见表 6)。
This means that for a majority of the failures, we only need to explore the combination and permutation of input events, but no additional timing relationship. This is particularly meaningful for testing those failures that require long-running systems to manifest. As long as we can simulate those events which typically only occur on long running systems (e.g., region split in HBase typically only occurs when the region size grows too large), we can expose these deterministic failures. Moreover, the failures can still be reproduced after inserting additional log output, enabling tracing, or using debuggers.
这意味着针对大部分故障,仅需遍历输入事件的组合与顺序,无需额外控制时序。该结论对依赖系统长期运行才会触发的故障测试极具参考价值:只要模拟长期运行场景下的特有事件(例如 HBase 分区因容量过大触发拆分),即可发现这类确定性故障。此外,增加日志、开启追踪、使用调试器,均不会影响此类故障的复现。
Finding 5 : Among the 51 non-deterministic failures, 53% have timing constraints only on the input events. (See Table 7.)
结论 5:在 51 起非确定性故障中,53% 的故障仅对输入事件的时序有要求(详见表 7)。
Table 7 : Break-down of the non-deterministic failures. The "other" category is caused by nondeterministic behaviors from the OS and third party libraries.
表 7 非确定性故障根因分类。"其他"类由操作系统或第三方库的非确定性行为引发。
| Source of non-determinism 非确定性来源 | number 数量 | proportion 占比 |
|---|---|---|
| Timing btw. input event & internal exe. event 输入事件与系统内部执行事件的时序竞争 | 27 | 53% |
| Multi-thread atomicity violation 多线程原子性破坏 | 3 | 6% |
| Multi-thread deadlock 多线程死锁 | 13 | 25% |
| Multi-thread lock contention (performance) 多线程锁竞争(引发性能问题) | 4 | 8% |
| Other 其他 | 4 | 8% |
| Total 总计 | 51 | 100% |
These constraints require an input event to occur either before or after some software internal execution event such as a procedure call. Figure 2 shows an example. In addition to the order of the four input events (that can be controlled by a tester), the additional requirement is that the client write operations must occur before HMaster assigns the region to a new Region Server, which cannot be completely controlled by the user.
这类故障要求输入事件与函数调用等系统内部执行事件保持固定先后顺序,图 2 为对应案例。该案例包含 4 个可由测试人员控制的输入事件,同时还有一项额外约束:客户端写入操作必须发生在 HMaster 将分区分配至新分区服务器之前,而该内部行为无法由用户完全控制。
Figure 2 : A non-deterministic failure in HBase with timing requirements (shown with solid arrows) only on input events (boxed). Some newly written data will be lost because when HMaster assigns a new region server, it only recovered the old HLog that does not contain the newly written data.
图 2 HBase 非确定性故障:实线代表时序约束,方框代表输入事件。HMaster 分配新分区服务器时,仅恢复旧预写日志(未包含新写入数据),最终导致新数据丢失。
write_lock();
largedirectory /
/*removea
write_unlock();
Critical region is too large, causing concurrent write requests to hang
Figure 3 : Performance degradation in HDFS caused by a single request to remove a large directory.
代码片段:加写锁、删除大目录、释放写锁。
图 3 HDFS 性能问题案例:单次大目录删除操作导致临界区过大,阻塞并发写入请求。
These non-deterministic dependencies are still easier to test and debug than non-determinisms stemming from multi-threaded interleavings, since at least one part of the timing dependency can be controlled by testers. Testers can carefully control the timing of the input events to induce the failure. Unit tests and model checking tools can further completely manipulate such timing dependencies by controlling the timing of both the input events and the call of internal procedures. For example, as part of the patch to fix the bug in Figure 2, developers used a unit test that simulated the user inputs and the dependencies with HMaster's operations to deterministically reproduce the failure.
相较于多线程交替执行引发的非确定性问题,这类时序依赖故障的测试与排障难度更低,因为测试人员可控制部分时序条件。测试人员可精准调控输入事件的时序以触发故障;单元测试、模型检测工具还可同时控制输入事件与内部函数调用的时序,完全复现该类问题。例如,开发人员在修复图 2 缺陷时,就编写了单元测试,模拟用户操作与 HMaster 内部行为的时序关系,实现故障确定性复现。
The majority of the remaining 24 non-deterministic failures stem from shared-memory multi-threaded interleavings. We observed three categories of concurrency bugs in our dataset: atomicity violation 42, deadlock, and lock contention that results in performance degradation. It is much harder to expose and reproduce such failures because it is hard for users or tools to control timing, and adding a single logging statement can cause the failure to no longer expose itself. We reproduced 10 of these non-deterministic failures and found the atomicity violations and deadlocks the most difficult to reproduce (we had to manually introduce additional timing delays, like Thread.sleep() in the code to trigger the bugs). The lock contention cases, however, are not as difficult to reproduce. Figure 3 shows an example where a bug caused unnecessary lock contention.
剩余 24 起非确定性故障,大多由共享内存多线程交替执行引发。样本中的并发缺陷分为三类:原子性破坏、死锁、锁竞争引发性能下降。这类故障的触发与复现难度极高,人工与工具均难以精准控制线程时序,甚至新增一行日志代码都会改变线程执行顺序,导致故障无法复现。本文手动复现了其中 10 起故障,发现原子性破坏与死锁最难触发,需要在代码中手动增加延时(如线程休眠)才能复现;锁竞争类故障的复现难度相对较低,图 3 即为锁竞争案例。
3.4 Logs Enable Diagnosis Opportunities
3.4 日志对故障排查的支撑
Overall, we found the logs output by the systems we studied to be rich with useful information. We assume the default logging verbosity level is used.
在默认日志级别下,本次研究的所有系统输出日志均包含大量有效信息。
Finding 6 : 76% of the failures print explicit failure-related error messages. (See Figure 4.)
结论 6:76% 的故障会输出明确的报错信息(详见图 4)。
This finding somewhat contradicts the findings of our previous study 67 on failures in non-distributed systems, including Apache httpd, PostgreSQL, SVN, squid, and GNU Coreutils, where only 43% of failures had explicit failure-related error messages logged. We surmise there are three possible reasons why developers output log messages more extensively for the distributed systems we studied. First, since distributed systems are more complex, and harder to debug, developers likely pay more attention to logging. Second, the horizontal scalability of these systems makes the performance overhead of outputing log message less critical. Third, communicating through message-passing provides natural points to log messages; for example, if two nodes cannot communicate with each other because of a network problem, both have the opportunity to log the error.
该结论与团队过往针对单机系统(Apache httpd、PostgreSQL、SVN、Squid、GNU 工具集)的研究结果形成反差:单机系统中仅 43% 的故障会输出明确报错日志。本文分析分布式系统日志更完善的三点原因:第一,分布式系统架构复杂、排障难度大,开发人员更加重视日志输出;第二,分布式系统具备水平扩展能力,日志打印带来的性能开销影响较小;第三,分布式系统基于消息传递通信,天然存在大量日志埋点,例如节点间网络不通时,通信双方均可记录异常日志。
Finding 7 : For a majority (84%) of the failures, all of their triggering events are logged. (See Figure 4.)
结论 7:84% 的故障,其全部触发事件均被日志完整记录(详见图 4)。
This suggests that it is possible to deterministically replay the majority of failures based on the existing log messages alone. Deterministic replay has been widely explored by the research community 4, 13, 15, 26, 35, 47, 61. However, these approaches are based on intrusive tracing with significant runtime overhead and the need to modify software/hardware.
该结论说明,仅依靠现有日志,就能对大部分故障进行确定性回放。故障回放技术已有大量相关研究,但现有方案大多属于侵入式追踪,不仅会产生较大运行开销,还需要修改软硬件。
Finding 8 : Logs are noisy: the median of the number of log messages printed by each failure is 824.
结论 8:日志存在冗余问题:单起故障对应的日志条数中位数为 824 条。
This number was obtained when reproducing 73 of the 198 failures with a minimal configuration and using a minimal workload that is just sufficient to reproduce the failure. Moreover, we did not count the messages printed during the start-up and shut-down phases.
该统计数据基于 73 起故障的复现环境得出,复现采用最小化配置与最小负载(仅保证故障触发),且未统计系统启停阶段的日志。
This suggests that manual examination of the log files could be tedious. If a user only cares about the error symptoms, a selective grep on the error verbosity levels will reduce noise since a vast majority of the printed log messages are at INFO level. However, the input events that triggered the failure are often logged at INFO level. Therefore to further infer the input events one has to examine almost every log message. It would be helpful if existing log analysis techniques 5, 6, 48, 64 and tools were extended so they can infer the relevant error and input event messages by filtering out the irrelevant ones.
人工分析海量日志效率极低。绝大部分日志为普通信息级别,若仅关注故障现象,可按日志级别过滤报错信息,减少冗余内容。但触发故障的输入事件大多也记录在普通信息日志中,若要还原完整触发链路,仍需逐条分析日志。因此,现有日志分析技术与工具需要进一步优化,实现自动过滤无关日志、提取异常信息与触发事件。
3.5 Failure Reproducibility
3.5 故障复现能力
Conventional wisdom has it that failures which occur on large, distributed system in production are extremely hard to reproduce off-line. The users' input may be unavailable due to privacy concerns, the difficulty in setting up an environment that mirrors the one in production, and the cost of third-party libraries, are often reasons cited as to why it is difficult for vendors to reproduce production failures. Our finding below indicates that failure reproduction might not be as hard as it is thought to be.
传统观点认为,大型分布式系统的线上故障极难离线复现,主要原因包括:用户输入数据因隐私问题无法获取、生产环境难以复刻、第三方组件部署成本高等。但本文研究表明,故障复现的难度远低于普遍认知。
Finding 9 : A majority of the production failures (77%) can be reproduced by a unit test. (See Table 8.)
结论 9:77% 的线上故障可通过单元测试完成复现(详见表 8)。
Table 8 : Percentage of failures that can be reproduced by unit test. The reason that only a relatively small number of Redis failures can be reproduced by unit tests is that its unit-test framework is not as powerful, being limited to command-line commands. Consequently, it cannot simulate many errors such as node failure, nor can it call some internal functions directly.
表 8 可通过单元测试复现的故障占比。Redis 可复现比例偏低,原因是其单元测试框架能力有限,仅支持命令行操作,无法模拟节点故障等场景,也不能直接调用部分内部函数。
| Software | % of failures reproducible by unit test 单元测试可复现故障占比 |
|---|---|
| Cassandra | 73% (29/40) |
| HBase | 85% (35/41) |
| HDFS | 82% (34/41) |
| MapReduce | 87% (33/38) |
| Redis | 58% (22/38) |
| Total | 77% (153/198) |
While this finding might sound counter-intuitive, it is not surprising given our previous findings because: (1) in Finding 4 we show that 74% of the failures are deterministic, which means the failures can be reproduced with the same operation sequence; and (2) among the remaining non-deterministic failures, in 53% of the cases the timing can be controlled through unit tests.
该结论看似违背常识,但结合前文结论不难理解:第一,74% 的故障为确定性故障,固定操作序列即可复现;第二,剩余非确定性故障中,53% 的时序约束可通过单元测试进行控制。
Specific data values are not typically required to reproduce the failures; in fact, none of the studied failures required specific values of user's data contents. Instead, only the required input sequences (e.g., file write, disconnect a node, etc.) are needed.
故障复现一般不需要使用真实业务数据,本次所有样本故障均无需依赖特定数据内容,仅需还原输入操作序列(如文件写入、节点断连等)即可。
Figure 6 : Unit test for the failure shown in Figure 2.
图 6 图 2 故障对应的单元测试伪代码。
java
public void testLogRollAfterSplitStart{
startMiniCluster(3);
//create an HBase cluster with 1 master and 2 RS
HMaster.splitHLog();
//simulate a hlog splitting(HMaster's recovery of RS'region data)when RS cannot be reached
RS.rollHLog();
//simulate the region server's log rolling event
for(i=0;i<NUM_WRITES;i++) writer.append(..);//write to RS'region
HMaster.assignNewRS(); //HMaster assigns the region to a new RS
assertEquals(NUM_WRITES,countWritesHLog());
} //Check if any writes are lostWhile this finding might sound counter-intuitive, it is not surprising given our previous findings because: (1) in Finding 4 we show that 74% of the failures are deterministic, which means the failures can be reproduced with the same operation sequence; and (2) among the remaining non-deterministic failures, in 53% of the cases the timing can be controlled through unit tests.
部分故障难以简易复现,原因通常为依赖特定运行环境(如操作系统版本、第三方库),或是由多线程随机交替执行引发。
4 Catastrophic Failures
4 灾难性故障分析
Table 2 in Section 3 shows that 48 failures in our entire failure set have catastrophic consequences. We classify a failure to be catastrophic when it prevents all or a majority of the users from their normal access to the system. In practice, these failures result in cluster-wide outage, a hung cluster, or a loss to all or a majority of the user data. Note that a bug resulting in under-replicated data blocks is not considered as catastrophic, even when it affect all data blocks, because it does not prevent users from their normal read and write to their data yet. We specifically study the catastrophic failures because they are the ones with the largest business impact to the vendors.
由表 2 可知,本次样本中有 48 起灾难性故障。本文对灾难性故障的定义为:导致全部或大部分用户无法正常访问系统的故障,具体表现为集群全域中断、集群卡死、全部/大部分用户数据丢失。需要说明:数据块副本数不足这类问题,即便影响全部数据块,也不判定为灾难性故障,因为不会阻碍用户正常读写。灾难性故障对服务商的业务影响最大,因此作为重点研究对象。
The fact that there are so many catastrophic failures is perhaps surprising given that the systems considered all have High Availability (HA) mechanisms designed to prevent component failures from taking down the entire service. For example, all of the four systems with a master-slave design - namely HBase, HDFS, MapReduce, and Redis - are designed to, on a master node failure, automatically elect a new master node and fail over to it. Cassandra is a peer-to-peer system, thus by design it avoids single points of failure. Then why do catastrophic failures still occur?
本次样本中存在大量灾难性故障,这一现象值得深思。研究对象均配备高可用机制,旨在避免单个组件故障引发全域服务瘫痪:HBase、HDFS、MapReduce、Redis 四款主从架构系统,支持主节点宕机后自动选主并完成故障转移;点对点架构的 Cassandra 从设计上就规避了单点故障。那么灾难性故障为何仍会发生?
Finding 10 : Almost all catastrophic failures (92%) are the result of incorrect handling of non-fatal errors explicitly signaled in software. (See Figure 5.)
结论 10:92% 的灾难性故障,均源于软件对可预见的非致命异常处理不当(详见图 5)。
These catastrophic failures are the result of more than one fault triggering, where the initial fault, whether due to a hardware fault, a misconfiguration, or a bug, first manifests itself explicitly as a non-fatal error - for example by throwing an exception or having a system call return an error. This error need not be catastrophic; however in the vast majority of cases, the handling of the explicit error was faulty, resulting in an error manifesting itself as a catastrophic failure.
灾难性故障是多级缺陷叠加的结果:硬件故障、配置错误、代码缺陷等初始问题,首先会触发非致命异常(例如抛出异常、系统调用返回错误)。这类非致命异常本身不会造成严重影响,但绝大多数场景下,异常处理逻辑存在缺陷,最终将普通异常放大为灾难性故障。
This prevalence of incorrect error handling is unique to catastrophic failures. In comparison, only 25% of the non-catastrophic failures in our study involve incorrect error handling, indicating that in non-catastrophic failures, error handling was mostly effective in preventing the errors from taking down the entire service.
异常处理不当是灾难性故障的核心特征。与之对比,非灾难性故障中仅有 25% 由异常处理不当引发,说明正常场景下,异常处理逻辑大多能够阻断故障扩散。
Overall, we found that the developers are good at anticipating possible errors. In all but one case, the errors were checked by the developers. The only case where developers did not check the error was an unchecked error system call return in Redis. This is different from the characteristics observed in previous studies on file system bugs 24, 41, 55, where many errors weren't even checked. This difference is likely because (i) the Java compiler forces developers to catch all the checked exceptions; and (ii) a variety of errors are expected to occur in large distributed systems, and the developers program more defensively. However, we found they were often simply sloppy in handling these errors. This is further corroborated in Findings 11 and 12 below. To be fair, we should point out that our findings are skewed in the sense that our study did not expose the many errors that are correctly caught and handled.
整体来看,开发人员能够预判大部分潜在异常。本次样本中仅 Redis 存在一处未校验系统调用返回值的情况,其余所有异常均做了捕获判断。这与过往文件系统缺陷研究结论不同,文件系统中存在大量未做校验的异常。差异原因主要有两点:第一,Java 编译器强制要求捕获受检异常;第二,大型分布式系统运行环境复杂,开发人员普遍采用防御式编程。但开发人员在异常处理逻辑上普遍不够严谨,下文结论 11、12 将进一步佐证。同时需要说明:本文仅分析引发故障的异常,未统计大量被正确捕获并处理的异常,结论存在一定偏向性。
Nevertheless, the correctness of error handling code is particularly important given their impact. Previous studies 50, 52 show that the initial faults in distributed system failures are highly diversified (e.g., bugs, misconfigurations, node crashes, hardware faults), and in practice it is simply impossible to eliminate them all in large data centers 14. It is therefore unavoidable that some of these faults will manifest themselves into errors, and error handling then becomes the last line of defense 45.
即便如此,异常处理代码的正确性依旧至关重要。过往研究表明,分布式系统的初始故障来源繁杂(代码缺陷、配置错误、节点宕机、硬件故障等),大型数据中心无法彻底杜绝此类问题。初始问题演变为异常不可避免,因此异常处理是保障系统稳定的最后一道防线。
Of the catastrophic failures we studied, only four were not triggered by incorrect error handling. Three of them were because the servers mistakenly threw fatal exceptions that terminated all the clients, i.e., the clients' error handling was correct. The other one was a massive performance degradation when a bug disabled DNS look-up result caching.
本次研究的灾难性故障中,仅 4 起与异常处理无关:其中 3 起是服务端主动抛出致命异常导致所有客户端中断,客户端异常处理逻辑无问题;剩余 1 起由 DNS 缓存功能失效引发,表现为系统性能严重下降。
4.1 Trivial Mistakes in Error Handlers
4.1 异常处理中的低级错误
Finding 11 : 35% of the catastrophic failures are caused by trivial mistakes in error handling logic - ones that simply violate best programming practices; and that can be detected without system specific knowledge.
结论 11:35% 的灾难性故障由异常处理逻辑中的低级错误引发,这类问题明显违背编码规范,无需了解系统业务逻辑即可检出。
Figure 5 further breaks down the mistakes into three categories: (i) the error handler ignores explicit errors; (ii) the error handler over-catches an exception and aborts the system; and (iii) the error handler contains "TODO" or "FIXME" in the comment.
图 5 将此类低级错误划分为三类:(1)异常处理逻辑直接忽略已捕获的异常;(2)异常捕获范围过广,并直接关停系统;(3)异常处理代码注释中包含 TODO、FIXME 等待完善标记。
25% of the catastrophic failures were caused by ignoring explicit errors (an error handler that only logs the error is also considered as ignoring the error). For systems written in Java, the exceptions were all explicitly thrown, whereas in Redis they were system call error returns. Figure 7 shows a data loss in HBase caused by ignoring an exception. Ignoring errors and allowing them to propagate is known to be bad programming practice 7, 60, yet we observed this lead to many catastrophic failures. At least the developers were careful at logging the errors: all the errors were logged except for one case where the Redis developers did not log the error system call return.
25% 的灾难性故障源于忽略已捕获异常(仅打印日志、无任何处理逻辑,也判定为忽略异常)。Java 系统中异常均为主动抛出,Redis 等 C 语言系统则体现为系统调用返回错误。图 7 展示了 HBase 因忽略异常导致数据丢失的案例。忽略异常、放任异常向上传递是典型的不规范编码行为,却引发了多起灾难性故障。值得一提的是,除 Redis 一处未记录系统调用错误外,其余所有异常均被日志记录。
Figure 7 : A data loss in HBase where the error handling was simply empty except for a logging statement. The fix was to retry in the exception handler.
图 7 HBase 数据丢失案例:异常处理块仅打印日志,无其他逻辑。修复方案为在异常处理中增加重试逻辑。
Figure 8 : Entire HDFS cluster brought down by an over-catch.
图 8 HDFS 集群全域瘫痪案例:异常捕获范围过大。
Another 8% of the catastrophic failures were caused by developers prematurely aborting the entire cluster on a non-fatal exception. While in principle one would need system specific knowledge to determine when to bring down the entire cluster, the aborts we observed were all within exception over-catch, where a higher level exception is used to catch multiple different lower-level exceptions. Figure 8 shows such an example. The exit() was intended only for IncorrectVersionException. However, the developers catch a high-level exception: Throwable. Consequently, when a glitch in the namenode caused registerDatanode() to throw RemoteException, it was over-caught by Throwable and thus brought down every datanode. The fix was to handle RemoteException explicitly, so that only IncorrectVersionException would fall through. However, this is still bad practice since later when the code evolves, some other exceptions may be over-caught again. The safe practice is to catch the precise exception 7.
另有 8% 的灾难性故障,是开发人员针对非致命异常直接关停整个集群导致。理论上,判断是否关停集群需要结合业务逻辑,但本次案例均为泛化捕获异常 :使用顶层异常类捕获多种底层异常。图 8 即为典型案例:exit() 逻辑本仅用于版本错误异常,但代码使用顶层 Throwable 捕获所有异常。当名称节点出现小故障,触发远程调用异常时,该异常被顶层捕获,进而关停所有数据节点。修复方案为单独处理远程调用异常,仅让版本错误异常触发退出逻辑。但该修复方式仍存在隐患,代码迭代后可能再次出现泛化捕获问题。行业最佳实践是精准捕获指定异常。
Figure 9 : A catastrophic failure in MapReduce where developers left a "TODO" in the error handler.
图 9 MapReduce 灾难性故障案例:异常处理代码中遗留 TODO 待办注释。
User: MapReduce jobs hang when a rare Resource Manager restart occurs.
I have to ssh to every one of our 4000 nodes in a cluster and try to kill all the running Application Manager.
java
catch (IOException e) {
// TODO LOG("Error event from RM: shutting down..");
}Patch:
java
catch (IOException e) {
// This can happen if RM has been restarted. Must clean up.
eventHandler.handle(..);
}用户描述:资源管理器偶发重启后,MapReduce 任务卡死,运维需要登录集群 4000 个节点,手动终止应用管理进程。
原始代码异常处理块仅保留 TODO 注释,无处理逻辑;修复后补充对应的异常处理逻辑。
Figure 9 shows an even more obvious mistake, where the developers only left a comment "TODO" in the handler logic in addition to a logging statement. While this error would only occur rarely, it took down a production cluster of 4,000 nodes.
图 9 是更为直观的案例:异常处理代码仅打印日志并遗留 TODO 注释。该异常触发概率较低,但一旦发生,会导致 4000 节点的生产集群出现故障。
Figure 10 : A catastrophic failure where the error handling code was wrong and simply not tested at all. A rare sequence of events caused newlyOpened() to throw a rare KeeperException, which simply took down the entire HBase cluster.
图 10 HBase 灾难性故障案例:异常处理逻辑错误且从未经过测试。一系列低概率事件触发 newlyOpened() 方法抛出罕见异常,直接导致整个 HBase 集群宕机。
4.2 System-specific Bugs
4.2 业务相关类缺陷
The other 57% of the catastrophic failures are caused by incorrect error handling where system-specific knowledge is required to detect the bugs. (See Figure 5.)
剩余 57% 的灾难性故障由业务相关的异常处理错误引发,这类缺陷需要结合系统业务逻辑才能识别(见图 5)。
Finding 12 : In 23% of the catastrophic failures, while the mistakes in error handling were system specific, they are still easily detectable. More formally, the incorrect error handling in these cases would be exposed by 100% statement coverage testing on the error handling logic.
结论 12 :23% 的灾难性故障属于业务相关异常处理错误,但依旧易于检测。具体而言,只要对异常处理代码做到语句全覆盖测试,这类问题就必然会被发现。
In other words, once the problematic basic block in the error handling code is triggered, the failure is guaranteed to be exposed. This suggests that these basic blocks were completely faulty and simply never properly tested. Figure 10 shows such an example. Once a test case can deterministically trigger KeeperException, the catastrophic failure will be triggered with 100% certainty.
也就是说,只要执行到异常处理代码的问题逻辑块,故障就一定会出现。这说明这类代码块本身存在严重问题,且从未经过正规测试。图 10 就是典型案例:一旦测试用例稳定触发分布式协调异常,对应的灾难性故障必然复现。
Hence, a good strategy to prevent these failures is to start from existing error handling logic and try to reverse engineer test cases that trigger them. For example, symbolic execution techniques 8, 10 could be extended to purposefully reconstruct an execution path that can reach the error handling code block, instead of blindly exploring every execution path from the system entry points.
因此,规避此类故障的有效思路是:以现有异常处理代码为出发点,反向设计可触发对应逻辑的测试用例。例如,可以扩展符号执行技术,定向构造能够进入异常处理代码块的执行路径,而非从系统入口盲目遍历所有执行分支。
While high statement coverage on error handling code might seem difficult to achieve, aiming for higher statement coverage in testing might still be a better strategy than a strategy of applying random fault injections. For example, the failure in Figure 10 requires a very rare combination of events to trigger the buggy error handler. Our finding suggests that a "bottom-up" approach could be more effective: start from the error handling logic and reverse engineer a test case to expose errors there.
尽管实现异常处理代码的高语句覆盖率存在难度,但相比随机故障注入,提升语句覆盖率仍是更优的测试方案。以图 10 的故障为例,触发问题异常处理逻辑需要一组极难出现的事件组合。本研究表明,自底向上的测试思路效果更佳:从异常处理逻辑出发,反向构造测试用例以暴露其中缺陷。
Existing testing techniques for error handling logic primarily use a "top-down" approach: start the system using testing inputs or model-checking 23, 65, and actively inject errors at different stages 9, 18, 44. Tools like LFI 44 and Fate&Destini 23 are intelligent to inject errors only at appropriate points and avoid duplicated injections. Such techniques inevitably have greatly improved the reliability of software systems. In fact, Hadoop developers have their own error injection framework to test their systems 18, and the production failures we studied are likely the ones missed by such tools.
现有针对异常处理逻辑的测试技术大多采用自顶向下思路:通过测试输入或模型检测启动系统,并在不同运行阶段主动注入故障。LFI、Fate&Destini 等工具能够智能选择注入点位、避免重复注入,这类技术已大幅提升软件可靠性。Hadoop 团队也自研了故障注入框架用于测试,但本次研究发现的线上故障,大多是这类工具未能覆盖的场景。
However, our findings suggest that it could be challenging for such "top-down" approaches to further expose these remaining production failures. They require rare sequence of input events to first take the system to a rare state, before the injected error can take down the service. In addition, 38% of the failures only occur in long-running systems. Therefore, the possible space of input events would simply be untractable.
但研究表明,自顶向下的方式很难再发现这类遗留线上故障。想要触发故障,需要先依靠低概率事件组合将系统推入特殊状态,再叠加注入故障才会引发服务瘫痪。此外,38% 的故障仅在系统长期运行后才会出现,这使得输入事件的遍历空间大到无法处理。
Complex bugs: the remaining 34% of the catastrophic failures involve complex bugs in the error handling logic. These are the cases where developers did not anticipate certain error scenarios. As an example, consider the failure shown in Figure 11. While the handling logic makes sense for a majority of the checksum errors, it did not consider the scenario where a single client reports a massive number of corruptions (due to corrupt RAM) in a very short amount of time. These type of errors - which are almost byzantine - are indeed the hardest to test for. Detecting them require both understanding how the system works and anticipating all possible real-world failure modes. While our study cannot provide constructive suggestions on how to identify such bugs, we found they only account for one third of the catastrophic failures.
复杂缺陷:剩余 34% 的灾难性故障源于异常处理逻辑中的复杂缺陷。这类问题是由于开发人员未能预判部分特殊异常场景导致。图 11 即为典型案例:系统针对绝大多数校验和错误设计了合理的处理逻辑,但未考虑一种极端场景------单个客户端因内存损坏,在短时间内上报大量数据损坏告警。这类非常规异常场景是测试工作中最难覆盖的类型,检测此类缺陷既需要吃透系统原理,还要预判线上所有潜在故障形态。本研究暂未针对这类缺陷提出解决方案,好在其仅占灾难性故障总数的三分之一。
Figure 11 : A massive data loss for all clients in HDFS. A client with corrupted RAM reported data corruption on almost every block it reads to the namenode. Instead of verifying the checksum on datanodes, namenode blindly trusts the faulty client and marks the blocks as permanently corrupted, causing a massive data loss to all clients.
图 11 HDFS 全域数据丢失故障。一台内存损坏的客户端,将读取到的几乎所有数据块都上报为损坏。名称节点未在数据节点侧二次校验数据,而是盲目采信异常客户端的上报信息,将对应数据块标记为永久损坏,最终造成所有用户的数据丢失。
4.3 Discussion
4.3 讨论
While we show that almost all of the catastrophic failures are the result of incorrect error handling, it could be argued that most of the code is reachable from error handling blocks in real-world distributed system, therefore most of the bugs are "incorrect error handling". However, our findings suggest many of the bugs can be detected by only examining the exception handler blocks (e.g., the catch block in Java). As we show will in Table 9, the number of catch blocks in these systems is relatively small. For example, in HDFS, there are only 2652 catch blocks. In particular, the bugs belonging to the "trivial mistakes" category in Finding 11 can be easily detected by only examining these catch blocks.
本文指出几乎所有灾难性故障都由异常处理错误引发。有人会提出质疑:在真实分布式系统中,大部分代码执行路径最终都会进入异常处理块,因此绝大多数缺陷都可以归为"异常处理错误"。但本研究证明,仅单独检查异常捕获代码块(例如 Java 的 catch 代码块),就能发现大量缺陷。如表 9 所示,这类系统中的异常捕获块数量并不庞大,例如 HDFS 仅包含 2652 个捕获块。尤其是结论 11 中归纳的低级错误,仅通过审计捕获块即可轻松识别。
An interesting question is whether the outages from large internet software vendors are also the result of incorrect error handling. While we cannot answer this rigorously without access to their internal failure databases, the postmortem analysis of some of the most visible outages are released to the public. Interestingly, some of the anecdotal outages are the result of incorrect error handling. For example, in an outage that brought down facebook.com for approximately 2.5 hours, which at that time was "the worst outage Facebook have had in over four years", "the key flaw that caused the outage to be so severe was an unfortunate handling of an error condition" 17. In the outage of Amazon Web Services in 2011 59 that brought down Reddit, Quora, FourSquare, parts of the New York Times website, and about 70 other sites, the initial cause was a configuration change that mistakenly routed production traffic to a secondary network that was not intended for heavy workload. Consequently, nodes start to fail. What lead this to further propagate into a service-level failure was the incorrect handling of node-failures - "the nodes failing to find new nodes did not back off aggressively enough when they could not find space, but instead, continued to search repeatedly". This caused even more network traffic, and eventually lead to the service-level failure.
一个值得探讨的问题:大型互联网厂商的服务中断是否也源于异常处理不当?由于无法获取其内部故障库,我们无法给出严谨定论,但多家知名故障的事后复盘报告对外公开,其中多起重大中断确实由异常处理错误导致。例如,Facebook 官网曾中断约 2.5 小时,这也是其四年内最严重的故障,复盘指出异常场景处理不当是故障恶化的核心原因。2011 年亚马逊云服务故障导致红迪网、Quora、四方定位、《纽约时报》部分页面及另外约 70 个网站瘫痪:故障初始原因为配置错误,将线上流量导向无法承载高负载的备用网络,进而引发大量节点异常。而节点故障处理逻辑的缺陷让问题持续扩散------节点在无法找到可用资源时,没有合理退避,而是反复重试查询,不断挤占网络带宽,最终演变为全域服务故障。
5 Aspirator: A Simple Checker
5 Aspirator:一款简易检测工具
In Section 4.1, we observed that some of the most catastrophic failures are caused by trivial mistakes that fall into three simple categories: (i) error handler is empty; (ii) error handler over-catches exceptions and aborts; and (iii) error handler contains phrases like "TODO" and "FIXME". To measure the applicability of these simple rules, we built a rule-based static checker, Aspirator, capable of locating these bug patterns. Next we discuss how Aspirator is implemented and the results of applying it to a number of systems.
在 4.1 节中,我们归纳出引发灾难性故障的三类典型低级错误:异常处理块为空、异常捕获范围过广并直接终止服务、异常处理代码中包含 TODO 或 FIXME 标记。为验证这套规则的实用性,本文基于规则实现了静态代码检测工具 Aspirator,专门识别上述缺陷模式。下文将介绍该工具的实现原理,以及在多款系统中的实测结果。
5.1 Implementation of Aspirator
5.1 Aspirator 实现原理
We implemented Aspirator using the Chord static analysis framework 11 on Java bytecode. Aspirator works as follows: it scans Java bytecode instruction by instruction. If an instruction can throw exception e, Aspirator identifies and records the corresponding catch block for e. Aspirator emits a warning if the catch block is empty or just contains a log printing statement, or if the catch block contains "TODO" or "FIXME" comments in the corresponding source code. It also emits a warning if a catch block for a higher-level exception (e.g., Exception or Throwable) might catch multiple lower-level exceptions and at the same time calls abort or System.exit(). Aspirator is capable of identifying these over-catches because when it reaches a catch block, it knows exactly which exceptions from which instructions the catch block handles.
Aspirator 基于 Chord 静态分析框架,针对 Java 字节码开发。工具工作流程如下:逐行扫描 Java 字节码,若某条指令会抛出异常 e,则定位并记录对应捕获该异常的 catch 代码块。当出现以下场景时,工具会输出告警:捕获块为空、仅包含日志打印逻辑、源码注释中存在 TODO 或 FIXME;若代码使用顶层异常类(如 Exception、Throwable)大范围捕获各类底层异常,同时调用终止服务的方法(abort、System.exit()),工具同样会触发告警。由于工具在解析 catch 块时,可精准识别该块能捕获哪些指令抛出的异常,因此能够有效识别泛化捕获问题。
Not every empty catch block is necessarily a bad practice or bug. Consider the following example where the exception is handled outside of the catch block:
并非所有空的异常捕获块都属于不规范代码或缺陷,如下示例中,异常逻辑在捕获块外部处理:
uri = null;
{
try
uri = Util.fileAsURI(new File(uri));
catch (IOException ex) { /* empty */ }
}
if (uri == null) { // handle it here!Therefore Aspirator will not emit a warning on an empty catch block if both of the following conditions are true: (i) the corresponding try block modifies a variable V; and (ii) the value of V is checked in the basic block following the catch block. In addition, if the last instruction in the corresponding try block is a return, break, or continue, and the block after the catch block is not empty, Aspirator will not report a warning if the catch block is empty because all the logic after the catch block is in effect exception handling.
为此,Aspirator 增加判定逻辑,满足以下两个条件时,不会对空捕获块告警:(1)try 代码块修改了变量 V;(2)捕获块之后的代码会校验变量 V 的值。此外,若 try 块最后一条指令为 return、break 或 continue,且捕获块后续存在有效代码,空捕获块也不会触发告警------这种场景下,后续代码实际承担了异常处理的职责。
Aspirator further provides runtime configuration options to allow programmers to adjust the trade-offs between false positives and false negatives. It allows programmers to specify exceptions that should not result in a warning. In our testing, we ignored all instances of the FileNotFound exception, because we found the vast majority of them do not indicate a true error. Aspirator also allows programmers to exclude certain methods from the analysis. In our testing, we use this to suppress warnings if the ignored exceptions are from a shutdown, close or cleanup method - exceptions during a cleanup phase are likely less important because the system is being brought down anyway. Using these two heuristics did not affect Aspirator's capability to detect the trivial mistakes leading to catastrophic failures in our study, yet significantly reduce the number of false positives.
Aspirator 支持运行时配置,开发者可自主权衡误报与漏报。用户可指定无需告警的异常类型,本测试中我们屏蔽了文件未找到异常,因为该类场景绝大多数属于正常业务逻辑。工具还支持排除指定方法不参与检测,本次测试将服务关闭、资源释放、数据清理类方法纳入排除列表------系统关停阶段的异常影响较小。上述两项优化不会削弱工具对高危低级错误的检测能力,同时大幅降低了误报数量。
Limitations: As a proof-of-concept, Aspirator currently only works on Java and other languages that are compatible with Java bytecode (e.g., Scala), where exceptions are supported by the language and are required to be explicitly caught. The main challenge to extend Aspirator to non-Java programs is to identify the error conditions. However, some likely error conditions can still be easily identified, including system call error returns, switch fall-through, and calls to abort().
局限性:本工具为原型实现,目前仅支持 Java 及兼容 Java 字节码的语言(如 Scala),这类语言原生支持异常机制且要求显式捕获异常。将工具拓展至非 Java 语言的核心难点是识别各类错误状态。不过部分通用错误场景仍可轻松识别,例如系统调用返回错误、分支语句穿透、主动调用终止函数等。
In addition, Aspirator cannot estimate the criticality of the warnings it emits. Hence, not every warning emitted will identify a bug that could lead to a failure; in fact, some false positives are emitted. However, because Aspirator provides, with each warning, a list of caught exceptions together with the instructions that throw them, developers in most cases will be able to quickly assess the criticality of each warning and possibly annotate the program to suppress specific future warnings.
此外,Aspirator 无法判断告警问题的严重等级,因此部分告警并非真实缺陷,存在一定误报。但每条告警都会附带异常类型以及抛出异常的指令信息,开发者可快速评估风险等级,也可通过代码注解屏蔽后续同类告警。
Finally, the functionality of Aspirator could (and probably should) be added to existing static analysis tools, such as FindBugs 32.
最后,Aspirator 的检测逻辑完全可以集成到 FindBugs 等现有静态分析工具中。
5.2 Checking Real-world Systems
5.2 线上系统实测效果
We first evaluated Aspirator on the set of catastrophic failures used in our study. If Aspirator had been used and the captured bugs fixed, 33% of the Cassandra, HBase, HDFS, and MapReduce's catastrophic failures could have been prevented.
我们首先使用本次研究的灾难性故障样本验证工具效果:若提前部署 Aspirator 并修复检出问题,可规避 Cassandra、HBase、HDFS、MapReduce 中 33% 的灾难性故障。
We then used Aspirator to check the latest stable versions of 9 distributed systems or components used to build distributed systems (e.g., Tomcat web-server). Aspirator's analysis finishes within 15 seconds for each system on a MacBook Pro laptop with 2.7GHz Intel Core i7 processor, and has memory footprints of less than 1.2GB.
随后,我们使用 Aspirator 检测 9 款分布式系统及中间件(如 Tomcat 网页服务器)的最新稳定版本。在 2.7GHz 酷睿 i7 处理器的苹果笔记本上,单款系统的分析耗时不超过 15 秒,内存占用低于 1.2GB。
We categorize each warning generated by Aspirator into one of three categories: bug, bad practice, and false positive. For each warning, we use our best-effort to understand the consequences of the exception handling logic. Warnings are categorized as bugs only if we could definitively conclude that, once the exception occurs, the handling logic could lead to a failure. They were categorized as false positives if we clearly understood they would not lead to a failure. All other cases are those that we could not definitively infer the consequences of the exception handling logic without domain knowledge. Therefore we conservatively categorize them as bad practices.
我们将工具输出的告警分为三类:真实缺陷、不规范编码、误报。针对每一条告警,我们分析异常处理逻辑的影响:若可确定异常触发后必然引发故障,则判定为真实缺陷;若明确不会产生任何问题,则判定为误报;其余在缺少业务知识时无法判定影响的场景,统一归类为不规范编码。
Table 9 : Results of applying Aspirator to 9 distributed systems. If a case belongs to multiple categories (e.g., an empty handler may also contain a "TODO" comment), we count it only once as an ignored exception. The "Handler blocks" column shows the number of exception handling blocks that Aspirator discovered and analyzed. "-" indicates Aspirator reported 0 warning.
表 9 Aspirator 在 9 款分布式系统中的检测结果。若某一问题同时符合多种类型(例如空处理块同时包含 TODO 注释),仅统计为异常忽略类问题。"处理块总数"列为工具扫描并分析的异常处理代码块数量。"-"代表无对应告警。
| System 系统 | Handler blocks 异常处理块总数 | Bug (total / confirmed) 缺陷(总数/已确认) | Ignore / Abort / Todo 异常忽略/终止服务/待办标记 | Bad practice 不规范编码 | False pos. 误报 |
|---|---|---|---|---|---|
| Cassandra | 4,365 | 2 / 2 | 2 | 2 | 9 |
| Cloudstack | 6,786 | 27 / 24 | 25 | 185 | 20 |
| HBase | 2,652 | 24 / 16 | 23 | 32 | 5 |
| HDFS | 4,995 | 16 / 9 | 11 | 43 | 6 |
| Hive | 9,948 | 25 / 15 | 23 | 54 | 8 |
| Tomcat | 5,257 | 7 / 4 | 6 | 23 | 4 |
| Spark | 396 | 2 / 2 | 2 | 1 | 2 |
| YARN/MR2 | 1,069 | 13 / 8 | 6 | 15 | 4 |
| Zookeeper | 1,277 | 5 / 5 | 5 | 24 | 9 |
| Total 总计 | 36,745 | 121 / 85 | 101 | 379 | 115 |
Bugs: many bugs detected by Aspirator could indeed lead to catastrophic failures. For example, all 4 bugs caught by the abort-in-over-catch checker could bring down the cluster on an unexpected exception in a similar fashion as in Figure 8. All 4 of them have been fixed.
真实缺陷:Aspirator 检出的大量缺陷确实会引发灾难性故障。例如,工具检出 4 个泛化捕获异常并终止集群的问题,一旦触发非预期异常,就会像图 8 案例一样造成集群瘫痪,目前这 4 个问题均已修复。
Some bugs can also cause the cluster to hang. Aspirator detected 5 bugs in HBase and Hive that have a pattern similar to the one depicted in Figure 12 (a). In this example, when tableLock cannot be released, HBase only outputs an error message and continues executing, which can deadlock all servers accessing the table. The developers fixed this bug by immediately cleaning up the states and aborting the problematic server 31.
部分缺陷会造成集群卡死。Aspirator 在 HBase 和 Hive 中共检出 5 个与图 12(a) 模式一致的问题:数据表锁释放失败时,系统仅打印日志并继续运行,最终导致所有访问该表的服务死锁。开发人员的修复方案为:立即清理现场状态并关停异常服务。
Figure 12 : Two new bugs found by Aspirator.
图 12 Aspirator 检出的两类新增缺陷
(a)
try {
journal.recoverSegments();
} catch (IOException ex) {
try {
tableLock.release();
} catch (IOException e) {
LOG("Can't release lock", e);
}
}hang: lock is never released!
(问题:锁无法释放,引发服务卡死)
(b)
Cannot apply the updates from Edit log, ignoring it can cause dataloss!
(问题:忽略编辑日志的回放异常,会导致数据丢失)
Figure 12 (b) shows a bug that could lead to data loss. An IOException could be thrown when HDFS is recovering user data by replaying the updates from the Edit log. Ignoring it could cause a silent data loss.
图 12(b) 为数据丢失类缺陷:HDFS 回放编辑日志恢复数据时会抛出 IO 异常,代码直接忽略该异常,进而引发隐性数据丢失。
Bad practices: the bad practice cases include potential bugs for which we could not definitively determine their consequences without domain expertise. For example, if deleting a temporary file throws an exception and is subsequently ignored, it may be inconsequential. However, it is nevertheless considered a bad practice because it may indicate a more serious problem in the file system.
不规范编码:此类告警对应潜在风险,在不了解业务逻辑的前提下,无法判定其最终影响。例如,删除临时文件时抛出异常并被忽略,大概率不会造成故障,但这仍属于不规范写法,可能预示文件系统存在深层问题。
Some of these cases could as well be false positives. While we cannot determine how many of them are false positives, we did report 87 of the cases that we initially classified as "bad practices" to developers. Among them, 58 were confirmed or fixed, but 17 were rejected. The 17 rejected ones were subsequently classified as "false positives" in Table 9.
部分不规范编码类告警实际为误报。我们将 87 条初始判定为"不规范编码"的问题提交给开发团队,其中 58 条被确认并修复,17 条被判定为无问题,这 17 条在表 9 中统一修正为误报。
False positives: 19% of the warnings reported by Aspirator are false positives. Most of them are due to that Aspirator does not perform inter-procedural analysis. Consider the following example, where an exception is handled by testing the return value of a method call:
误报:Aspirator 的告警中有 19% 为误报,主要原因是工具未做跨过程分析。如下示例中,异常通过函数返回值判断处理,而非在当前捕获块中处理:
try {
set_A();
} catch (SomeException e) { /* empty */ }
if (A_is_not_set()) {/* handle it here! */}In addition to FileNotFound and exceptions from from shutdown, close, and cleanup, Aspirator should have been further configured to exclude the warnings on other exceptions. For example, many of the false positives are caused by empty handlers of Java's reflection related exceptions, such as NoSuchFieldException. Once programmers realize an exception should have been excluded from Aspirator's analysis, they can simply add this exception to Aspirator's configuration file.
除文件未找到异常、服务关停与资源清理阶段的异常外,还可通过配置屏蔽其他类型异常的告警。例如,大量误报来自 Java 反射相关异常(如字段不存在异常)的空捕获块。开发者只需将这类异常添加至配置文件,即可屏蔽对应告警。
5.3 Experience
5.3 落地实践反馈
Interaction with developers: We reported 171 bugs and bad practices to the developers through the official bug tracking website. To this date, 143 have already been confirmed or fixed by the developers (73 of them have been fixed, and the other 70 have been confirmed but not fixed yet), 17 were rejected, and the others have not received any responses.
与开发人员的沟通反馈:我们通过官方问题平台,向各项目团队提交了 171 条缺陷与不规范编码问题。截至目前,143 条得到确认或修复(73 条已完成修复,70 条已确认待修复),17 条被判定为无问题,剩余问题暂未收到回复。
We received mixed feedback from developers. On the one hand, we received some positive comments like: "I really want to fix issues in this line, because I really want us to use exceptions properly and never ignore them", "No one would have looked at this hidden feature; ignoring exceptions is bad precisely for this reason", and "catching Throwable i.e., exception over-catch is bad, we should fix these". On the other hand, we received negative comments like: "I fail to see the reason to handle every exception".
开发人员的反馈褒贬不一。正面观点包括:"我希望修复这类问题,规范异常处理,不再忽略异常"、"这类隐蔽功能点很容易被忽视,而忽略异常恰恰会埋下隐患"、"使用顶层类捕获所有异常是错误写法,应当整改"。也存在不同意见:"没必要对每一个异常都做特殊处理"。
There are a few reasons for developers' obliviousness to the handling of errors. First, these ignored errors may not be regarded as critical enough to be handled properly. Often, it is only until the system suffers serious failures will the importance of the error handling be realized by developers. We hope to raise developers' awareness by showing that many of the most catastrophic failures today are caused precisely by such obliviousness to the correctness of error handling logic.
开发人员忽视异常处理主要有几方面原因。第一,多数被忽略的异常在日常运行中影响轻微,未被视作高危问题,往往只有在系统发生重大故障后,团队才会意识到异常处理的重要性。本文也希望通过研究结论,提升开发人员对异常处理代码质量的重视程度------大量灾难性故障均源于对异常处理细节的漠视。
Secondly, the developers may believe the errors would never (or only very rarely) occur. Consider the following code snippet detected by Aspirator from HBase:
第二,开发人员主观认为部分异常永远不会触发,或触发概率极低。以下是 Aspirator 在 HBase 中检出的代码片段:
java
catch (IOException e) {
new TimeRange(timestamp, timestamp+1);
// Will never happen
}In this case, the developers thought the constructor could never throw an exception, so they ignored it (as per the comment in the code). We observed many empty error handlers contained similar comments in multiple systems we checked. We argue that errors that "can never happen" should be handled defensively to prevent them from propagating. This is because developers' judgement could be wrong, later code evolutions may enable the error, and allowing such unexpected errors to propagate can be deadly. In the HBase example above, developers' judgement was indeed wrong. The constructor is implemented as follows:
开发人员在注释中标注该异常"永远不会发生",因此直接忽略。在多款被测系统中,我们都发现了带有同类注释的空异常处理块。我们认为,即便是判定为"不会发生"的异常,也应采用防御式编程做好处理,避免异常向上传递。原因在于:人工判断可能出现失误、代码迭代可能让原本不会触发的异常变为常态,而未处理的意外异常极易引发严重事故。上述 HBase 案例中,开发人员的判断就出现了偏差,其构造函数实现如下:
java
public TimeRange (long min, long max) throws IOException {
if (max < min)
throw new IOException("max < min");
}It could have thrown an IOException when there is an integer overflow, and swallowing this exception could have lead to a data loss. The developers later fixed this by handling the IOException properly.
当出现整数溢出时,该构造函数就会抛出 IO 异常,而原代码直接吞噬异常,最终引发数据丢失。后续开发人员已对该异常做了规范化处理并完成修复。
Thirdly, proper handling of errors can be difficult. It is often much harder to reason about the correctness of a system's abnormal execution path than its normal execution path. This problem is further exacerbated by the reality that many of the exceptions are thrown by third party components lacking of proper documentations. We surmise that in many cases, even the developers may not fully understand the possible causes or the potential consequences of an exception. This is evidenced by the following code snippet from CloudStack:
第三,异常本身的处理存在技术难度。相较于正常业务流程,梳理异常分支的正确性难度更高。若异常由缺乏完善文档的第三方组件抛出,问题会进一步加剧。我们发现,很多时候开发人员也无法完全理清异常的触发原因与潜在影响,CloudStack 中的代码片段就是典型佐证:
java
catch (NoTransitionException ne) {
/* Why this can happen? Ask God not me. */
}Fourthly, in reality feature development is often prioritized over exception handling when release deadlines loom. We embarrassingly experienced this ourselves when we ran Aspirator on Aspirator's code: we found 5 empty exception handlers, all of them for the purpose of catching exceptions thrown by the underlying libraries and put there only so that the code would compile.
第四,在版本交付压力下,功能开发的优先级往往高于异常处理。我们在使用 Aspirator 扫描自身源码时也发现了同类问题:工具代码中存在 5 个空异常处理块,仅为兼容底层库抛出的异常、保证代码编译通过而编写。
Good practice in Cassandra: among the 9 systems we checked, Cassandra has the lowest bug-to-handler-block ratio, indicating that Cassandra developers are careful in following good programming practices in exception handling. In particular, the vast majority of the exceptions are handled by recursively propagating them to the callers, and are handled by top level methods in the call graphs. Interestingly, among the 5 systems we studied, Cassandra also has the lowest rate of catastrophic failures in its randomly sampled failure set (see Table 1).
优秀实践------Cassandra:在 9 款被测系统中,Cassandra 的异常处理块缺陷率最低,说明其开发团队严格遵守异常处理的编码规范。该系统绝大多数异常会逐层向上抛至调用方,最终由调用链顶层方法统一处理。与之对应,在最初研究的五款系统中,Cassandra 抽样样本里的灾难性故障占比也为最低(详见表 1)。
6 Related Work
6 相关研究
A number of studies have characterized failures in distributed systems, which led to a much deeper understanding of these failures and hence improved reliability. Our study is the first (to the best of our knowledge) analysis to understand the end-to-end manifestation sequence of these failures. The manual analysis allowed us to find the weakest link on the manifestation sequence for the most catastrophic failures, namely the incorrect error handling. While it is well-known that error handling is a source of many errors, we found that these bugs in error handling code, many of them extremely simple, are the dominant cause of today's catastrophic failures.
已有多项研究针对分布式系统故障做特征分析,加深了业界对故障的认知,并推动系统可靠性优化。据我们所知,本文是首篇完整剖析故障端到端演变链路的研究。通过人工深度分析,我们定位出灾难性故障传导链路中的薄弱环节------异常处理错误。业内早已知晓异常处理是缺陷高发区,但本文进一步证实:如今绝大多数灾难性故障,都源于异常处理代码中的各类问题,其中大量还是低级错误。
Next, we discuss three categories of related work: characterization studies, studies on error handling code, and distributed system testing.
下文将从三大方向梳理相关研究:故障特征分析、异常处理代码研究、分布式系统测试技术。
Failure characterization studies
故障特征分析研究
Oppenheimer et al. eleven years ago studied over 100 failure reports from deployed internet services 50. They discussed the root causes, time-to-repair, and mitigation strategies of these failures, and summarized a series of interesting findings (e.g., operator mistakes being the most dominant cause). Our study is largely complementary since the open-source projects allow us to examine a richer source of data, including source code, logs, developers' discussions, etc., which were not available for their study. Indeed, as acknowledged by the authors, they "could have been able to learn more about the detailed causes if they had been able to examine the system logs and bug tracking database".
十一年前,Oppenheimer 等人分析了上百条线上互联网服务故障工单,研究了故障根因、修复时长与缓解方案,并得出多项结论(例如人为操作失误是首要故障原因)。两项研究形成互补:本文选取开源系统作为研究对象,可获取源码、日志、开发沟通记录等更丰富的数据,而这些数据在其研究中无法获取。该团队也曾表示,若能查阅系统日志与问题库,就能进一步深挖故障细节。
Rabkin and Katz 52 analyzed reports from Cloudera's production hadoop clusters. Their study focused on categorizing the root causes of the failures.
Rabkin 与 Katz 分析了 Cloudera 公司线上 Hadoop 集群的故障工单,研究重点为故障根因分类。
Li et al. 38 studied bugs in Microsoft Bing's data analytic jobs written in SCOPE. They found that most of the bugs were in the data processing logic and were often caused by frequent change of table schema.
Li 等人针对微软必应搜索引擎基于 SCOPE 语言开发的数据分析任务开展缺陷研究,发现大部分缺陷集中在数据处理逻辑,且数据表结构频繁变更为主要诱因。
Others studied bugs in non-distributed systems. In 1985, Gray examined over 100 failures from the Tandem operating system 22, and found operator mistakes and software bugs to be the two major causes. Chou et al. 12 studied OS bugs and observed that device drivers are the most buggy. This finding led to many systems and tools to improve device driver quality, and a study ten years later suggested that the quality of device drivers have indeed greatly improved. Lu et al. 42 studied concurrency bugs in server programs, and found many inter-thread interleavings can be triggered using 2 threads.
也有部分研究聚焦非分布式系统缺陷。1985 年,Gray 分析了 Tandem 操作系统的上百起故障,指出人为操作失误与软件缺陷是两大主因。Chou 等人研究操作系统缺陷后发现,设备驱动程序是缺陷重灾区,该结论推动了驱动程序质量优化;十年后的跟踪研究证实,驱动程序的可靠性已大幅提升。Lu 等人针对服务端并发缺陷展开研究,发现绝大多数线程交替执行类问题仅需 2 个线程即可触发。
Study on error handling code
异常处理代码相关研究
Many studies have shown that error handling code is often buggy 24, 44, 55, 58. Using a static checker, Gunawi et al. found that file systems and storage device drivers often do not correctly propagate error code 24. Fu and Ryder also observed that a significant number of catch blocks were empty in many Java programs 20. But they did not study whether they have caused failures. In a study on field failures with IBM's MVS operating system between 1986 and 1989, Sullivan et al. found that incorrect error recovery was the cause of 21% of the failures and 36% of the failures with high impact 58. In comparison, we find that in the distributed systems we studied, incorrect error handling resulted in 25% of the non-catastrophic failures, and 92% of the catastrophic ones.
多项研究证实异常处理代码缺陷率偏高。Gunawi 等人借助静态检测工具发现,文件系统与存储驱动普遍存在错误码传递不规范的问题。Fu 和 Ryder 发现大量 Java 代码中存在空异常捕获块,但并未研究这类代码是否会引发故障。Sullivan 等人分析 1986--1989 年 IBM MVS 操作系统线上故障后得出:异常恢复逻辑错误引发了 21% 的普通故障与 36% 的高影响故障。与之对比,本文研究的分布式系统中,异常处理不当引发了 25% 的普通故障、92% 的灾难性故障。
Many testing tools can effectively expose incorrect error handling through error injections 18, 23, 44. Fate&Destini 23 can intelligently inject unique combinations of multiple errors; LFI 44 selectively injects errors at the program/library boundary and avoids duplicated error injections. While these tools can be effective in exposing many incorrect error handling bugs, they all use a "top-down" approach and rely on users/testers to provide workloads to drive the system. In our study, we found that a combination of input events is needed to drive the system into the error state which is hard to trigger using a top-down approach. Our findings suggests that a "bottom-up" approach, which reconstruct test cases from the error handling logic, can effectively expose most faults that lead to catastrophic failures.
多款测试工具依靠故障注入技术检测异常处理错误。Fate&Destini 可智能组合注入多种故障;LFI 在应用与库函数的边界处选择性注入故障,避免重复操作。这类工具能够发现大量异常处理缺陷,但均采用自顶向下的思路,依赖测试人员提供负载用例驱动系统运行。本研究发现,触发故障往往需要多事件组合将系统推入特殊状态,这正是自顶向下方案的短板。而基于异常处理逻辑反向构造用例的自底向上思路,能够高效发现引发灾难性故障的各类缺陷。
Other tools are capable of identify bugs in error handling code via static analysis 24, 55, 67. EIO 24 uses static analysis to detect error code that is either unchecked or not further propagated. Errlog 67 reports error handling code that is not logged. In comparison, our simple checker is complementary. It detects exceptions that are checked but incorrectly handled, regardless whether they are logged or not.
还有部分工具依托静态分析检测异常处理缺陷。EIO 用于识别未校验、未传递的错误码;Errlog 专门检测未打印日志的异常处理代码。本文实现的简易检测工具与上述工具形成互补:聚焦已捕获但处理逻辑错误的异常,不依赖日志输出与否做判断。
Distributed system testing
分布式系统测试技术
Model checking 25, 34, 37, 65 tools can be used to systematically explore a large combination of different events. For example, SAMC 37 can intelligently inject multiple errors to drive the target system into a corner case. Our study further helps users make informed decisions when using these tools (e.g., users need to check no more than three nodes).
模型检测工具可系统性遍历海量事件组合,SAMC 等工具能够智能注入多类故障,主动将系统推入边界场景。本文结论也可为这类工具的使用提供参考:测试环境无需搭建大规模集群,最多 3 个节点即可完成大部分验证。
7 Conclusions
7 结论
This paper presented an in-depth analysis of 198 user-reported failures in five widely used, data-intensive distributed systems in the form of 12 findings. We found that the error manifestation sequences leading to the failures to be relatively complex. However, we also found that for the most catastrophic failures, almost all of them are caused by incorrect error handling, and 58% of them are trivial mistakes or can be exposed by statement coverage testing.
本文对五款主流数据密集型分布式系统的 198 条用户上报故障开展深度分析,总结出 12 项核心结论。研究发现,故障的完整演变流程具备一定复杂度;但几乎所有灾难性故障都源于异常处理不当,其中 58% 的问题属于低级错误,或是可通过语句覆盖测试轻松发现。
It is doubtful that existing testing techniques will be successful uncovering many of these error handling bugs. They all use a "top-down" approach: start the system using generic inputs or model-checking 65, 23, and actively inject errors at different stages 9, 18, 44. However the size of the input and state space, and the fact that a significant number of failures only occur on longrunning systems, makes the problem of exposing these bugs intractable. For example, Hadoop has its own error injection framework to test their system 18, but the production failures we studied are likely the ones missed by such tools.
现有主流测试技术难以彻底发现这类异常处理缺陷。这类技术均采用自顶向下模式:通过通用输入、模型检测启动系统,并在运行阶段注入故障。但庞大的输入与状态空间、大量故障仅在系统长期运行后触发等特点,让这类方法难以覆盖全部场景。Hadoop 虽自研了故障注入框架,但本次研究发现的线上故障,大多被这类工具遗漏。
Instead, we suggest a three pronged approach to expose these bugs: (1) use a tool similar to the Aspirator that is capable of identifying a number of trivial bugs; (2) enforce code reviews on error-handling code, since the error handling logic is often simply wrong; and (3) use, for example, extended symbolic execution techniques 8, 10 to purposefully reconstruct execution paths that can reach each error handling code block. Our detailed analysis of the failures and the source code of Aspirator are publicly available at: http://www.eecg.toronto.edu/failureAnalysis/.
对此,本文提出三套互补的解决方案来发现此类缺陷:(1)使用 Aspirator 这类静态检测工具,批量识别异常处理中的低级错误;(2)针对异常处理代码强制开展代码审查,排查逻辑错误;(3)扩展符号执行等技术,定向构造可进入异常处理代码块的执行路径。本次故障详细分析数据与 Aspirator 源码已开源,地址:http://www.eecg.toronto.edu/failureAnalysis/。
Acknowledgements
致谢
We greatly appreciate the anonymous reviewers, our shepherd Jason Flinn, and Leonid Ryzhyk for their insightful feedback. This research is supported by NSERC Discovery grant, NetApp Faculty Fellowship, and Connaught New Researcher Award.
由衷感谢匿名审稿人、责任编辑 Jason Flinn 与 Leonid Ryzhyk 给出的宝贵意见。本研究得到加拿大自然科学与工程研究理事会探索基金、NetApp 学者基金、康诺特青年研究者奖的资助。
References
参考文献
(原文参考文献为文献索引列表,格式统一保留,无逐句翻译必要,内容为行业标准文献引用条目)
1 Why Amazon's cloud titanic went down. http://money.cnn.com/2011/04/22/technology/amazonec2cloudoutage/index.htm.
2 Apache Cassandra. http://cassandra.apache.org.
3 Apache HBase. http://hbase.apache.org.
4 T. Bergan, N. Hunt, L. Ceze, and S. D. Gribble. Deterministic process groups in dOS. In Proceedings of the 9th USENIX Conference on Operating Systems Design and Implementation, OSDI'10, 2010.
5 I. Beschastnikh, Y. Brun, , J. Abrahamson, M. D. Ernst, and A. Krishnamurthy. Unifying FSM-inference algorithms through declarative specification. In Proceedings of The International Conference on Software Engineering, ICSE'13, 2013.
6 I. Beschastnikh, Y. Brun, M. D. Ernst, A. Krishnamurthy, and T. E. Anderson. Mining temporal invariants from partially ordered logs. In Managing Large-scale Systems via the Analysis of System Logs and the Application of Machine Learning Techniques, SLAML'11, pages 3:1--3:10, 2011.
7 J. Bloch. Effective Java (2nd Edition). Prentice Hall, 2008.
8 C. Cadar, D. Dunbar, and D. Engler. Klee: Unassisted and automatic generation of high-coverage tests for complex systems programs. In Proceedings of the 8th USENIX Conference on Operating Systems Design and Implementation, OSDI'08, pages 209--224, 2008.
9 Chaos monkey. https://github.com/Netflix/SimianArmy/wiki/Chaos-Monkey.
10 V. Chipounov, V. Kuznetsov, and G. Candea. The S2E platform: Design, implementation, and applications. ACM Trans. Comput. Syst., 30(1):2:1--49, Feb. 2012.
11 Chord: A program analysis platform for Java. http://pag.gatech.edu/chord.
12 A. Chou, J. Yang, B. Chelf, S. Hallem, and D. Engler. An empirical study of operating systems errors. In Proceedings of the 18th ACM Symposium on Operating Systems Principles, SOSP '01, pages 73--88, 2001.
13 H. Cui, J. Simsa, Y.-H. Lin, H. Li, B. Blum, X. Xu, J. Yang, G. A. Gibson, and R. E. Bryant. Parrot: A practical runtime for deterministic, stable, and reliable threads. In Proceedings of the Twenty-Fourth ACM Symposium on Operating Systems Principles, SOSP '13, pages 388--405, 2013.
14 J. Dean. Underneath the covers at Google: current systems and future directions. In Google I/O, 2008.
15 G. W. Dunlap, S. T. King, S. Cinar, M. A. Basrai, and P. M. Chen. ReVirt: enabling intrusion analysis through virtual-machine logging and replay. In Proceedings of the Fifth Symposium on Operating System Design and Implementation, OSDI'02, 2002.
16 D. Engler, B. Chelf, A. Chou, and S. Hallem. Checking system rules using system-specific, programmer-written compiler extensions. In Proceedings of the 4th conference on Symposium on Operating System Design and Implementation, OSDI'00, pages 1--16, 2000.
17 Facebook: More details on today's outage. https://www.facebook.com/note.php?note id= 4314413389199&id=9445547199&ref=mf.
18 Hadoop team. Fault injection framework: How to use it, test using artificial faults, and develop new faults. http://wiki.apache.org/hadoop/HowToUseInjectionFramework.
19 N. Feamster and H. Balakrishnan. Detecting BGP configuration faults with static analysis. In Proceedings of the 2nd USENIX Symposium on Networked System Design and Implementation, NSDI'05, 2005.
20 C. Fu and G. B. Ryder. Exception-chain analysis: Revealing exception handling architecture in java server applications. In 29th International Conference on Software Engineering, ICSE'07, pages 230--239, 2007.
21 Google outage reportedly caused big drop in global traffic. http://www.cnet.com/news/googleoutage-reportedly-caused-big-drop-inglobal-traffic/.
22 J. Gray. Why do computers stop and what can be done about it? In Proceedings of the Symposium on Reliability in Distributed Software and Database Systems, 1986.
23 H. S. Gunawi, T. Do, P. Joshi, P. Alvaro, J. M. Hellerstein, A. C. Arpaci-Dusseau, R. H. Arpaci-Dusseau, K. Sen, and D. Borthakur. FATE and DESTINI: a framework for cloud recovery testing. In Proceedings of the 8th USENIX conference on Networked Systems Design and Implementation, NSDI'11, 2011.
24 H. S. Gunawi, C. Rubio-Gonz´alez, A. C. Arpaci-Dusseau, R. H. Arpaci-Dussea, and B. Liblit. EIO: Error handling is occasionally correct. In Proceedings of the 6th USENIX Conference on File and Storage Technologies, FAST'08, 2008.
25 H. Guo, M. Wu, L. Zhou, G. Hu, J. Yang, and L. Zhang. Practical software model checking via dynamic interface reduction. In Proceedings of the 23rd ACM Symposium on Operating Systems Principles, pages 265--278, October 2011.
26 Z. Guo, X. Wang, J. Tang, X. Liu, Z. Xu, M. Wu, M. F. Kaashoek, and Z. Zhang. R2: An application-level kernel for record and replay. In Proceedings of the 8th USENIX Conference on Operating Systems Design and Implementation, OSDI'08, pages 193--208, Berkeley, CA, USA, 2008.
27 Hadoop Distributed File System (HDFS) architecture guide. http://hadoop.apache.org/docs/stable/hdfs design.html.
28 Hadoop MapReduce. http://hadoop.apache.org /docs/stable/mapred tutorial.html.
29 Hadoop market is expected to reach usd 20.9 billion globally in 2018. http://www.prnewswire.com/news-releases/hadoop-market-is-expectedto-reach-usd-209-billion-globallyin-2018-transparency-market-research217735621.html.
30 DB-Engines ranking of wide column stores. http://db-engines.com/en/ranking/wi de+column+store.
31 HBase bug report 10452 -- Fix bugs in exception handler. https://issues.apache.org/jira/brow se/HBASE-10452.
32 D. Hovemeyer and W. Pugh. Finding bugs is easy. SIGPLAN Notice, 39(12):92--106, Dec. 2004.
33 S. Kandula, R. Mahajan, P. Verkaik, S. Agarwal, J. Padhye, and P. Bahl. Detailed diagnosis in enterprise networks. In Proceedings of the ACM SIGCOMM 2009 conference, SIGCOMM '09, pages 243--254, 2009.
34 C. Killian, J. W. Anderson, R. Jhala, and A. Vahdat. Life, death, and the critical transition: finding liveness bugs in systems code. In Proceedings of the Fourth Symposium on Networked Systems Design and Implementation, pages 243--256, April 2007.
35 O. Laadan, N. Viennot, and J. Nieh. Transparent, lightweight application execution replay on commodity multiprocessor operating systems. In Proceedings of the ACM SIGMETRICS International Conference on Measurement and Modeling of Computer Systems, SIGMETRICS '10, pages 155--166, 2010.
36 J.-C. Laprie. Dependable computing: concepts, limits, challenges. In Proceedings of the 25th International Conference on Fault-tolerant Computing, FTCS'95, pages 42--54, 1995.
37 T. Leesatapornwongsa, M. Hao, P. Joshi, J. F. Lukman, and H. S. Gunawi. Samc: Semantic-aware model checking for fast discovery of deep bugs in cloud systems. In Proceedings of the 11th USENIX Symposium on Operating System Design and Implementation, OSDI'14, 2014.
38 S. Li, T. Xiao, H. Zhou, H. Lin, H. Lin, W. Lin, and T. Xie. A characteristic study on failures of production distributed data-parallel programs. In Proc. International Conference on Software Engineering (ICSE 2013), Software Engineering in Practice (SEIP) track, May 2013.
39 Z. Li, S. Lu, S. Myagmar, and Y. Zhou. Cp-miner: A tool for finding copy-paste and related bugs in operating system code. In Proceedings of the 6th Conference on Symposium on Opearting Systems Design and Implementation, OSDI'04, 2004.
40 G. C. Lorenzo Keller, Prasang Upadhyaya. ConfErr: A tool for assessing resilience to human configuration errors. In Proceedings International Conference on Dependable Systems and Networks, DSN'08, 2008.
41 L. Lu, A. C. Arpaci-Dusseau, R. H. Arpaci-Dusseau, and S. Lu. A study of Linux file system evolution. In Proceedings of the 11th USENIX Conference on File and Storage Technologies, FAST'13, pages 31--44, 2013.
42 S. Lu, S. Park, E. Seo, and Y. Zhou. Learning from mistakes: a comprehensive study on real world concurrency bugs characteristics. In Proceedings of the 13th international conference on Architectural support for programming languages and operating systems, ASPLOS'08, pages 329--339, 2008.
43 R. Mahajan, D. Wetherall, and T. Anderson. Understanding BGP misconfiguration. In Proceedings of the ACM SIGCOMM 2002 conference, SIGCOMM '02, pages 3-- 16, 2002.
44 P. D. Marinescu, R. Banabic, and G. Candea. An extensible technique for high-precision testing of recovery code. In Proceedings of the 2010 USENIX annual technical conference, USENIX ATC'10, 2010.
45 P. D. Marinescu and G. Candea. Efficient testing of recovery code using fault injection. ACM Trans. Comput. Syst., 29(4):11:1--11:38, Dec. 2011.
46 Missing dot drops Sweden off the internet. http://www.networkworld.com/communi ty/node/46115.
47 P. Montesinos, L. Ceze, and J. Torrellas. Delorean: Recording and deterministically replaying sharedmemory multiprocessor execution. In Proceedings of the 35th Annual International Symposium on Computer Architecture, ISCA '08, pages 289--300, Washington, DC, USA, 2008. IEEE Computer Society.
48 K. Nagaraj, C. Killian, and J. Neville. Structured comparative analysis of systems logs to diagnose performance problems. In Proceedings of the 9th USENIX conference on Networked Systems Design and Implementation, NSDI'12, 2012.
49 K. Nagaraja, F. Oliveira, R. Bianchini, R. P. Martin, and T. D. Nguyen. Understanding and dealing with operator mistakes in internet services. In Proceedings of the 6th conference on Symposium on Opearting Systems Design and Implementation, OSDI'04, 2004.
50 D. Oppenheimer, A. Ganapathi, and D. A. Patterson. Why do Internet services fail, and what can be done about it? In Proceedings of the 4th conference on USENIX Symposium on Internet Technologies and Systems, USITS'03, pages 1--15, 2003.
51 N. Palix, G. Thomas, S. Saha, C. Calv`es, J. Lawall, and G. Muller. Faults in Linux: ten years later. In Proceedings of the 16th International Conference on Architectural Support for Programming Languages and Operating Systems, ASPLOS'11, pages 305--318, 2011.
52 A. Rabkin and R. Katz. How Hadoop clusters break. Software, IEEE, 30(4):88--94, 2013.
53 DB-Engines ranking of key-value stores. http://dbengines.com/en/ranking/key-value+store.
54 Redis: an open source, advanced key-value store. http://redis.io/.
55 C. Rubio-Gonz´alez, H. S. Gunawi, B. Liblit, R. H. Arpaci-Dusseau, and A. C. Arpaci-Dusseau. Error propagation analysis for file systems. In Proceedings of the 2009 ACM SIGPLAN Conference on Programming Language Design and Implementation, PLDI '09, pages 270--280, 2009.
56 B. Schroeder and G. Gibson. A large-scale study of failures in high-performance computing systems. IEEE Transactions on Dependable and Secure Computing, 7(4):337--350, 2010.
57 C. Spatz. Basic statistics, 1981.
58 M. Sullivan and R. Chillarege. Software defects and their impact on system availability - A study of field failures in operating systems. In Twenty-First International Symposium on Fault-Tolerant Computing, FTCS'91, pages 2-- 9, 1991.
59 Summary of the Amazon EC2 and RDS service disruption. http://aws.amazon.com/message /65648/.
60 The curse of the swallowed exception. http://mi chaelscharf.blogspot.ca/2006/09/dontswallow-interruptedexception-call.html.
61 K. Veeraraghavan, D. Lee, B. Wester, J. Ouyang, P. M. Chen, J. Flinn, and S. Narayanasamy. DoublePlay: Parallelizing sequential logging and replay. In Proceedings of the 16th International Conference on Architectural Support for Programming Languages and Operating Systems, ASPLOS'11, pages 388-- 405, 2011.
62 K. V. Vishwanath and N. Nagappan. Characterizing cloud computing hardware reliability. In Proceedings of the 1st ACM symposium on Cloud computing, SoCC '10, pages 193--193--194, New York, NY, USA, 2010. ACM.
63 T. Xu, J. Zhang, P. Huang, J. Zheng, T. Sheng, D. Yuan, Y. Zhou, and S. Pasupathy. Do not blame users for misconfigurations. In Proceedings of the 24th ACM Sympo sium on Operating Systems Principles, SOSP '13, 2013.
64 W. Xu, L. Huang, A. Fox, D. Patterson, and M. I. Jordan. Detecting large-scale system problems by mining console logs. In Proceedings of the ACM SIGOPS 22nd Symposium on Operating Systems Principles, SOSP '09, pages 117--132, 2009.
65 J. Yang, T. Chen, M. Wu, Z. Xu, X. Liu, H. Lin, M. Yang, F. Long, L. Zhang, and Z. Zhou. MODIST: Transparent model checking of unmodified distributed systems. In Proceedings of the Sixth Symposium on Networked Systems Design and Implementation (NSDI '09), pages 213-- 228, 2009.
66 Z. Yin, X. Ma, J. Zheng, Y. Zhou, L. N. Bairavasundaram, and S. Pasupathy. An empirical study on configuration errors in commercial and open source systems. In Proceedings of the Twenty-Third ACM Symposium on Operating Systems Principles, SOSP '11, pages 159--172, 2011.
67 D. Yuan, S. Park, P. Huang, Y. Liu, M. Lee, M. Zhou, and S. Savage. Be conservative: Enhancing failure diagnosis with proactive logging. In Proceedings of the 10th USENIX Symposium on Operating Systems Design and Implementation, OSDI'12, pages 293--306, 2012.
- Errors, exceptions and faults, oh my! - Ayende @ Rahien
https://ayende.com/blog/183489-a/errors-exceptions-and-faults-oh-my - Simple Testing Can Prevent Most Critical Failures:An Analysis of Production Failures in Distributed
Data-Intensive Systems 2014 osdi14-paper-yuan.pdf
https://www.usenix.org/system/files/conference/osdi14/osdi14-paper-yuan.pdf