在视频编码中,率失真优化(Rate-Distortion Optimization, RDO) 是决定编码器画质与压缩效率的"大脑"。HEVC(H.265)之所以能比 H.264 提升 50% 的压缩效率,除了引入更灵活的划分结构外,最核心的原因就在于它在极其复杂的选择空间中,利用 RDO 找到了数学上的最优解。
简而言之,RDO 的核心任务是:在码率(Rate)受限的死命令下,通过挑选最佳的编码参数,让画面失真(Distortion)降到最低。
一图总结
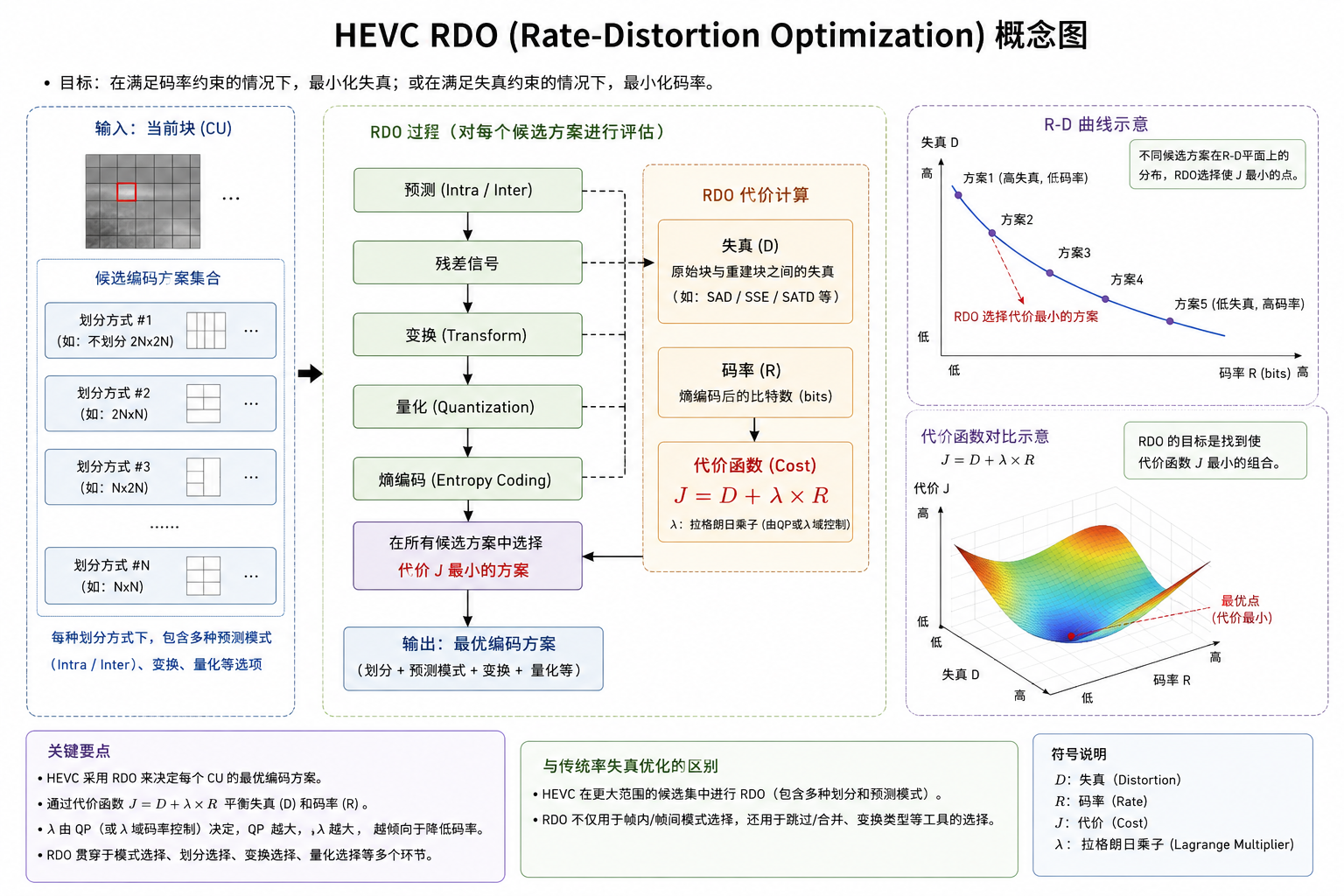
一句话总结
RDO(率失真优化) 就是视频编码器里的"性价比终极考量":它把画面切成无数个小块,让每一种画质配置和划分方式都去PK同一个公式------"谁能用最少的流量(码率)换来最清晰的画面(最小失真),谁就胜出"。
RDO 的数学本源:拉格朗日乘子法
视频编码本质上是一个受约束的优化问题:
minDs.t.R≤Rmax\min D \quad \text{s.t.} \quad R \le R_{\text{max}}minDs.t.R≤Rmax
即:在总比特数 RRR 不超过最大限制 RmaxR_{\text{max}}Rmax 的前提下,寻找一种编码模式组合,使重构图像与原始图像之间的失真 DDD 最小。
直接求解这个有约束的非线性规划问题在工程上极难实现。为了打破僵局,信号处理领域引入了拉格朗日乘子法 ,将约束问题转化为无约束的率失真代价(R-D Cost, 记为 JJJ) 最小化问题:
J=D+λ⋅RJ = D + \lambda \cdot RJ=D+λ⋅R
- DDD(Distortion,失真) :代表编码后的画面偏离原始画面的程度。常用指标有 SSD (平方误差和,数学性质好,最常用)和 SAD(绝对误差和,计算快)。
- RRR(Rate,率):编码当前模块实际消耗的比特数(包括残差系数、运动矢量 MV、语法元素等熵编码后的总和)。
- λ\lambdaλ(Lambda,拉格朗日乘子) :核心调节杠杆。它决定了编码器对"比特"和"画质"的敏感程度。λ\lambdaλ 的值通常由量化参数 QPQPQP 决定(在 HEVC 中,经验公式通常为 λ=c⋅2QP−123\lambda = c \cdot 2^{\frac{QP-12}{3}}λ=c⋅23QP−12)。
- QPQPQP 大 →λ\rightarrow \lambda→λ 大 :意味着比特非常昂贵。公式中 RRR 的权重极大,编码器会为了省比特(求更低的 JJJ)而忍受大失真,画面变糊。
- QPQPQP 小 →λ\rightarrow \lambda→λ 小 :意味着比特很便宜。编码器会为了压低失真 DDD 而疯狂砸比特,换取高画质。
HEVC 为什么要进行全方位的 RDO?
在 H.264 时代,模式选择相对简单。但在 HEVC 中,编码器的决策空间呈爆炸式增长:
- 块划分的爆炸组合 :CTU(最大 64×6464\times6464×64)可以递归划分为 CU(最小 8×88\times88×8),CU 内部又派生出 PU(预测单元)和 TU(变换单元)。一个 64×6464\times6464×64 的区域有上万种可能的划分方式。
- 帧内预测模式剧增:从 H.264 的 9 种方向飙升到 HEVC 的 35 种(33 种角度 + DC + Planar)。
- 帧间预测的灵活性 :支持 Merge、Skip、AMVP 模式,以及 8 种不对称运动划分(AMP,如 nLxMnLxMnLxM 等)。
面对如此庞大的选择组合,编码器无法只靠经验盲猜,必须让每一种可能的组合都走一遍 J=D+λ⋅RJ = D + \lambda \cdot RJ=D+λ⋅R 的考场,谁的 JJJ 最小,谁就是最后的赢家。
HEVC RDO 的分层决策架构
为了防止计算量彻底失控,HEVC 官方参考软件(HM)及主流商用编码器(如 x265)采用了自底向上(Bottom-Up)递归决策与分级筛选的经典 RDO 架构。
帧内预测(Intra)的 RDO 流程
对于一个给定的 CU,要从 35 种模式中挑出最优,直接做全套 RDO 计算量会让人崩溃。因此,HM 引入了粗选(Rough Mode Decision, RMD) 与 全 RDO 结合的两级筛选机制:
-
第一级:RMD 粗选(低复杂度代价)
不进行真正的变换、量化和熵编码。直接计算 35 种模式下,原始像素与预测像素之间的 SADSADSAD 加上模式本身的比特估计代价 :JRMD=SAD+λmotion⋅RmodeJ_{\text{RMD}} = SAD + \lambda_{\text{motion}} \cdot R_{\text{mode}}JRMD=SAD+λmotion⋅Rmode。
按 JRMDJ_{\text{RMD}}JRMD 从小到大排序,筛选出前几名(根据块大小保留 3 种或 8 种候选模式),并加入最可能预测模式(MPM)。
-
第二级:全 RDO 决胜负
对通过粗选的极少数精英候选模式,执行完整的预测 →\rightarrow→ 变换 →\rightarrow→ 量化 →\rightarrow→ 反量化 →\rightarrow→ 反变换 →\rightarrow→ 重构。
此时,计算最精确的 D=SSDD = SSDD=SSD(重构与原始的平方差),并通过实际的 CABAC 估计出精准的比特数 RRR。计算 J=SSD+λ⋅RJ = SSD + \lambda \cdot RJ=SSD+λ⋅R,代价最小的模式胜出。
帧间预测(Inter)的 RDO 流程
帧间预测主要解决运动估计(ME)和模式选择(Merge/Skip vs AMVP)的问题:
- Skip/Merge 模式代价计算 :由于 Skip 和 Merge 模式不需要传输运动矢量残差(MVD),只传一个索引,所以比特数 RRR 极低。编码器会先计算它们的 JJJ,作为后续对比的"基准线"。
- AMVP 模式下的运动搜索(ME) :
- 整数像素搜索 :为了快,通常使用 J=SAD+λmotion⋅RMVDJ = SAD + \lambda_{\text{motion}} \cdot R_{\text{MVD}}J=SAD+λmotion⋅RMVD 作为代价函数寻找最佳匹配块。
- 分像素搜索(半像素、1/4像素) :由于需要插值,计算量大,通常改用 SATDSATDSATD(经哈达玛变换后的绝对误差和)替代 SADSADSAD,使之更接近真实频域失真。
- 终极全 RDO 裁决 :将求出的最佳运动矢量(MV)进行残差编码,与 Skip/Merge 模式一起进入全 RDO(SSD+λ⋅RSSD + \lambda \cdot RSSD+λ⋅R)进行终极PK。
树状划分(CU/PU/TU)的递归 RDO
这是 HEVC RDO 最消耗算力的部分。以一个 64×6464\times6464×64 的 CTU 为例,它的最优划分是通过深度优先递归算出来的:
- 假设当前在深度 0(64×6464\times6464×64)。编码器首先尝试不划分,把它当成一个单一的 CU。计算该情况下最优预测模式的全 RDO 代价,记为 JParentJ_{\text{Parent}}JParent。
- 然后,编码器将该块强行切分为 4 个 32×3232\times3232×32 的子块(深度 1)。
- 对这 4 个子块分别进行递归,每一个子块内部又会继续尝试往下切分(直到 8×88\times88×8)。每一层都会计算出子块的最优代价。
- 当 4 个 32×3232\times3232×32 的子块全部计算完毕后,将它们的最小代价相加:JChildren=∑i=14Jchildi+Rsplit_flag⋅λJ_{\text{Children}} = \sum_{i=1}^4 J_{\text{child}i} + R{\text{split\_flag}} \cdot \lambdaJChildren=∑i=14Jchildi+Rsplit_flag⋅λ。
- 做出决断 :比较 JParentJ_{\text{Parent}}JParent 和 JChildrenJ_{\text{Children}}JChildren。
- 如果 JParent≤JChildrenJ_{\text{Parent}} \le J_{\text{Children}}JParent≤JChildren,说明"不切分"更划算,该块维持 64×6464\times6464×64。
- 如果 JParent>JChildrenJ_{\text{Parent}} > J_{\text{Children}}JParent>JChildren,说明"切分"能用更少的比特换来更好的画质,编码器决定执行切分。
RDO 的核心痛点:计算复杂度与工程优化
虽然 RDO 在数学上完美,但它的计算复杂度极其恐怖。如果开启全 RDO,编码器需要对每一个最小单元进行无数次的变换、量化、反量化、反变换和通电重构。在商用实时编码(如直播、4K/8K 传输)中,"全盲搜索"的 RDO 是绝对无法接受的。
因此,现代视频编码器(如开源的 x265)的核心科技,就在于如何优雅地"偷懒"(降低 RDO 复杂度):
-
Early Skip / Early Termination(提前终止机制):
在递归进行 CU 划分时,如果发现当前 64×6464\times6464×64 的块在 Skip 模式下的 R-D Cost 已经小于一个特定阈值,且残差基本为 0,编码器就会断定这是一个"静态背景静态区",直接终止向下划分,直接跳过后面几万次的递归计算。
-
基于机器学习/统计学的划分预测:
利用邻近块的时空相关性,或者通过轻量级的纹理分析(如计算当前块的梯度、方差),提前预测该块大概率不需要切分,或者大概率只能走某些帧内方向,从而将 35 种模式裁剪到 3-5 种。
-
Hadamard 代价(SATD)替代 SSDSSDSSD:
在非最终决策层级,用计算极为简单的哈达玛变换能量(SATD)来模拟频域量化后的失真 DDD,避免了真正走一遍量化、反量化和重构的硬件流水线。
-
RDOQ(率失真优化量化):
在量化阶段,普通的量化只是机械地做四舍五入。而 RDOQ 会对变换系数中的每一个非零系数进行微调(比如把一个接近 0.5 的系数强制变成 1 还是变成 0),看哪种选择带来的 J=D+λ⋅RJ = D + \lambda \cdot RJ=D+λ⋅R 综合代价更低。这能为 HEVC 额外带来 5% 左右的省带宽增益。
总结
HEVC 的 RDO(率失真优化) 是通过拉格朗日乘子 λ\lambdaλ 架起的一座桥梁,它把本无法直接相加的两个物理量------主观画质的物理损耗(失真 DDD) 与 客观世界的网络资源(码率 RRR) 成功统一在同一个价值评价体系内。
通过自底向上的树状递归模式比对,RDO 确保了编码器输出的每一帧画面、每一段运动矢量、每一个划分语法,都符合"性价比最高"的原则。理解了 RDO 的拉格朗日代价函数,就理解了现代视频编码器在性能、画质与带宽之间进行极限拉扯与平衡的底层逻辑。