目录
背景:
想获得最高的效率,需要反复的优化,以及对硬件和编程细节的详细了解,怎么评估效率,时间是个很直观的测量方式。
c语言
在c语言当中我们测试一个效率,往往用到clock函数或者time函数
clock():CPU 运行时间(代码真正运算的时间)
cpp// 记录开始时间 clock_t start = clock(); // 被测代码 for (int i = 0; i < 100000000; i++); // 记录结束时间 clock_t end = clock(); // 计算耗时 double time = (double)(end - start) / CLOCKS_PER_SEC; std::cout<<"消耗时间:"<<time;cudaDeviceSynchronize();
你可能会想调用这个函数,等待gpu同步,然后调用核函数之前start,同步完之后end,然后相减就能得到时间
但是这样是错误的,因为clock是记录cpu运行的时间,不包括休眠的时间
CUDA程序如何测效率
gettimeofday()测量的是真实世界流逝的时间,也叫"墙钟时间"。
cppint gettimeofday(struct timeval *tv, struct timezone *tz); struct timeval { time_t tv_sec; // 总秒数(从1970-01-01 00:00:00 至今) suseconds_t tv_usec; // 微秒数 1s = 1000000 μs };
必须同步 :你必须在核函数启动后,调用
cudaDeviceSynchronize()或同步的cudaMemcpy,确保 GPU 的工作已经全部完成。否则,计时器只会测量到 CPU 下达命令的时间,而不是 GPU 真正执行的时间。这是主机端测时:这个方法测量的是从 CPU 角度看,一个任务花了多久。它包含了 GPU 计算时间和可能的 PCIe 传输时间,是衡量整体性能的常用指标。
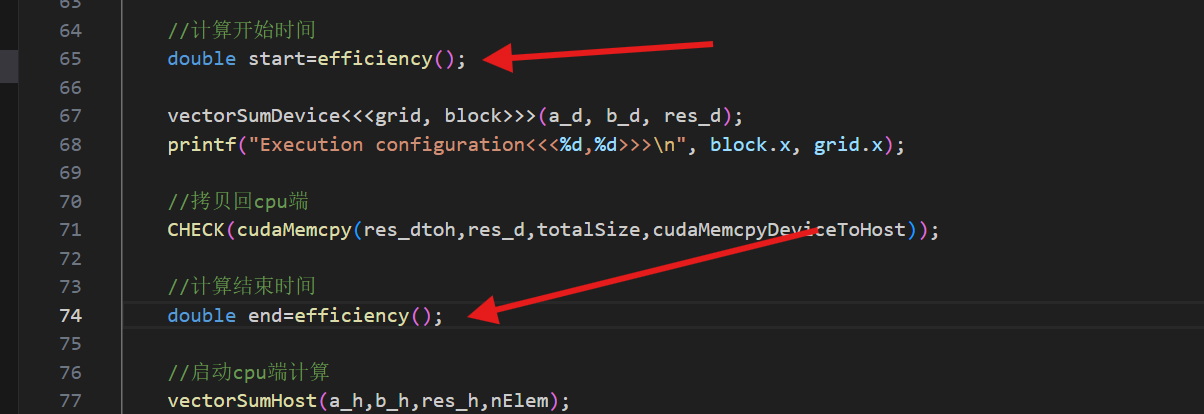
接下来我们在freshman.hpp当中进行封装一个函数,这样以后记录就会很方便,直接调用
cpp//计算效率,gettimeofday double efficiency(){ struct timeval tv; gettimeofday(&tv,nullptr); return ((double)tv.tv_sec + (double)tv.tv_usec * 1.e-6); }接下来我们使用之前写过的向量加法进行测试,算一下跑这个核函数用了多少时间
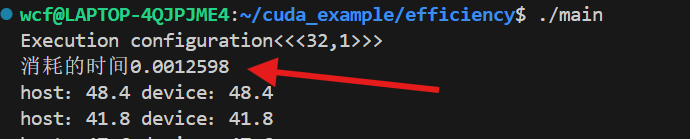
之前学过这个cudaMemcpy是会阻塞等待gpu把数据拷贝过来的,所以这里我们不需要调用cudaDeviceSynchronization函数了
消耗时间是0.0012598s
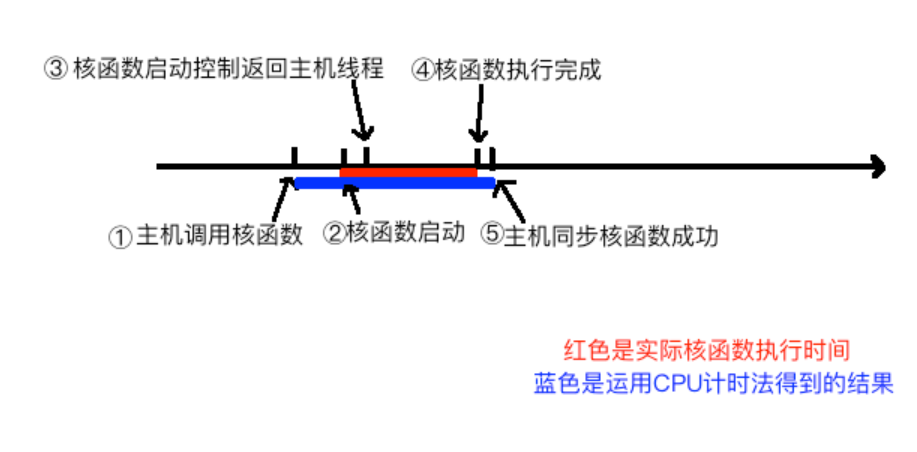
我们可以大概分析下核函数启动到结束的过程:
- 主机线程启动核函数
- 核函数启动成功
- 控制返回主机线程
- 核函数执行完成
- 主机同步函数侦测到核函数执行完
接下来我们测试一下针对不同的方案的时间,比如有1<<24个向量加法,我们如何配置grid和block呢???
第一组<65536,256>
第二组<32768,512>
第三组<16384,1024>
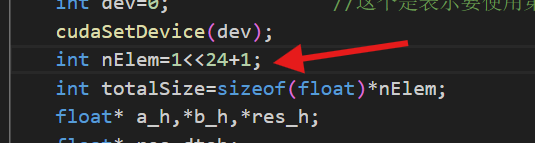
接下来我们给要进行计算的向量大小加1
因为要向上取整才能覆盖所有任务
消耗时间直接翻倍
当数据不能被完整切块的时候性能滑铁卢了,这个我们可以使用一点小技巧,比如只传输可完整切割数据块,然后剩下的1,2个使用cpu计算,这种技巧后面有介绍,以及包括如何选择系数。
并行计算的性能瓶颈,很多时候不在于计算本身,而在于数据布局和任务分配是否完美匹配硬件的执行习惯。






工具链的学习
工具 主要用途 何时使用 Nsight Systems 系统级性能分析,看清整个程序的宏观瓶颈。 刚开始优化时,先用它找出是 GPU 计算慢、PCIe 数据传输慢,还是 CPU 端逻辑慢。 Nsight Compute 核函数级详细分析,深入单个核函数内部,定位微观瓶颈。 确定某个核函数慢后,用它看线程束占用率、内存带宽利用率、计算与访存比例等底层指标。 nsys --help ncu --help 可以看使用手册
nsys:
bashnsys profile -o report ./main
-o report:把分析结果保存到文件report.qdrep(可以用 Nsight Systems 图形界面打开)。
选项 作用 示例 -o <文件名>输出 .qdrep文件,供 GUI 打开nsys profile -o my_report ./app--stats=true在命令行直接打印统计摘要 nsys profile --stats=true ./app--trace=cuda,osrt追踪 CUDA API 和系统运行时事件 nsys profile --trace=cuda,osrt ./app--backtrace=dwarf收集 CPU 调用栈(定位调用来源) nsys profile --backtrace=dwarf ./app
cppTime (%) Total Time (ns) Num Calls Avg (ns) Name -------- --------------- --------- ----------- ---------------------- 70.5 101226565 3 33742188.3 cudaMemcpy 26.1 37483909 1 37483909.0 cudaLaunchKernel 1.8 2652081 3 884027.0 cudaFree 1.5 2221440 3 740480.0 cudaMalloc由于博主是使用的wsl2,本身就受限了,看不到核函数的时间
ncu:
bashncu ./main后面可以跟你的程序需要的命令行参数
默认情况下,
ncu可能只显示简单的摘要。要获得完整的性能分析数据,一般会加上--set full参数(线程束占用率、共享内存使用、全局内存读写带宽、计算与访存的平衡等。)
bashncu --set full ./vectorSum当有多个核函数的时候,只想分析某个核函数可以使用--kernel -name
bashncu --kernel-name vectorSumDevice ./main由于没有权限,看不了gpu参数,所以我们需要提权sudo,但是可能sudo之后没有可执行ncu的路径,所以最好是指定
由于博主是使用的wsl2,本身就受限了,即使sudo也没用
综上所述,我们应该知道自己的硬件的性能上限是多少,如果一直优化,已经接近上限就没必要优化了,应该花钱买机器
