需求规格说明书中的非功能性需求:被忽视的"看不见的一半"
功能性需求决定了产品能不能交付,非功能性需求决定了交付后能不能活下来。大多数项目失败不是因为功能做不出来,而是上线后------慢到没人用、挂了恢复不了、安全漏洞被 exploit、加个功能就全崩了。
一、什么是非功能性需求?
功能性需求说的是系统做什么------登录、下单、搜索,好理解、好写、好测。
非功能性需求说的是系统做到什么程度 ------快不快、稳不稳、安全不安全、能不能扩展。它们不描述功能本身,而是描述功能的品质属性。
一个经典的比喻:
功能性需求决定了车能不能开,非功能性需求决定了这车开起来舒不舒服、安不安全、能不能上高速、冬天会不会熄火。
遗憾的是,在大量需求规格说明书里,NFR 的待遇通常是三种:
- 压根没写------只写了功能列表,对性能、安全、可靠性一概不论
- 写了等于没写------"系统要快""要稳定""要安全",全是模糊词,无法验证
- 脱离现实------拍脑袋写"99.999% 可用率",运维成本直接吞噬项目预算
本文从 NFR 的八大核心类别出发,逐项梳理怎么定义、怎么检测、出了问题怎么修,最后给出一个真正能落地的 NFR 模板。
二、NFR 的八大核心类别
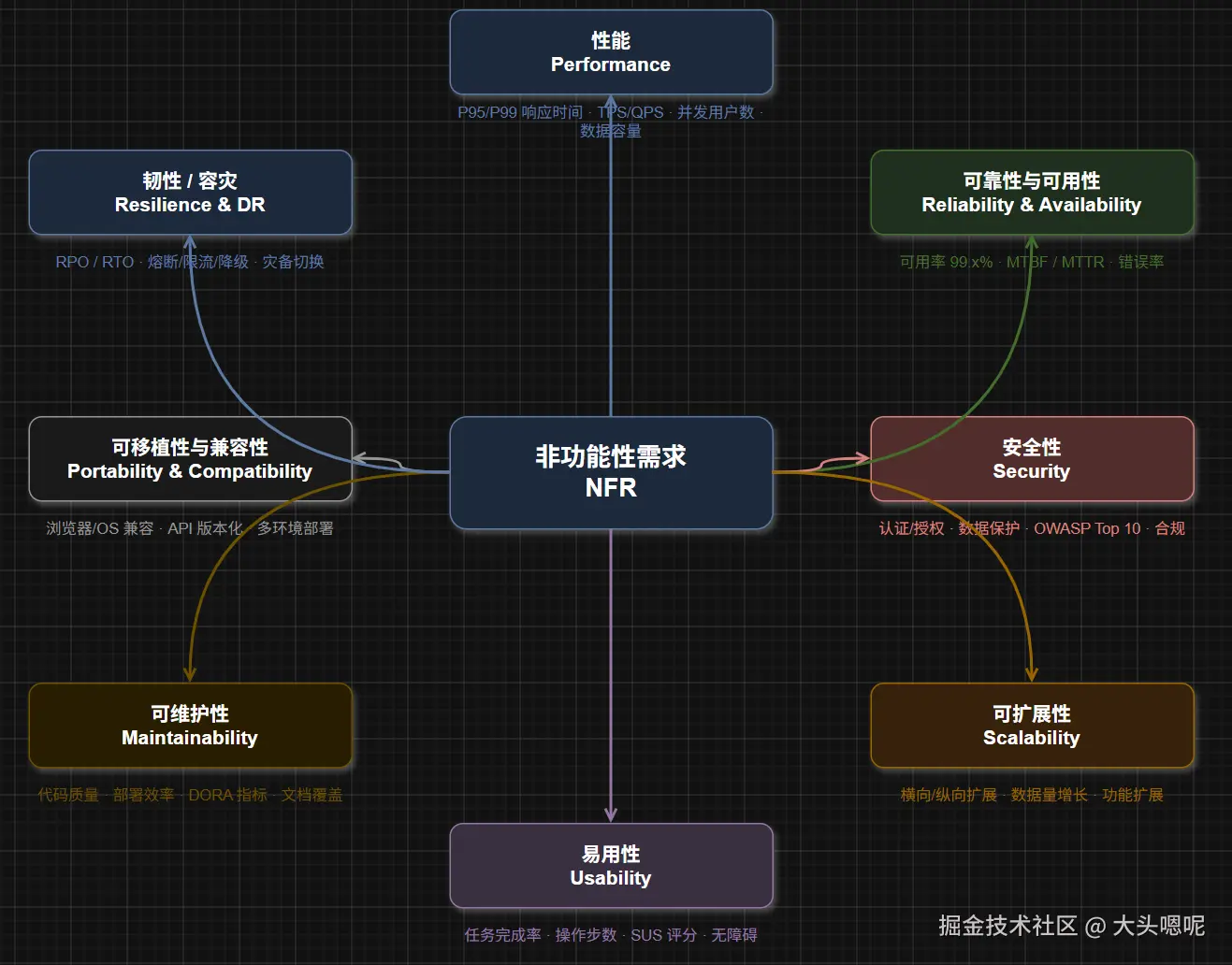
按 IEEE 830 / ISO/IEC 25010 软件质量模型框架,NFR 通常分为以下八类:
2.1 性能(Performance)
最常见的 NFR,也是最容易写模糊的一类。
| 子维度 | 典型指标 | 糟糕写法 | 好写法 |
|---|---|---|---|
| 响应时间 | 页面加载、接口返回 | "系统要快" | "首页加载 P95 ≤ 2s;API 单次查询 P99 ≤ 500ms" |
| 并发能力 | 同时在线、同时操作 | "支持很多人用" | "支持 5000 并发用户,峰值 8000 不会崩溃" |
| 吞吐量 | TPS/QPS | "处理速度要高" | "订单创建 TPS ≥ 200,查询 QPS ≥ 1000" |
| 容量 | 数据量、存储量 | "数据量大了也要能用" | "单表 1000 万行时查询不降速;总存储支持 50TB" |
关键原则:必须量化、必须带条件、必须区分平均值和极端值。 P95 ≤ 2s 远比"平均 ≤ 1.5s"有意义------平均数会掩盖长尾问题。
怎么检测
| 检测维度 | 方法 | 工具 |
|---|---|---|
| 接口响应时间 | 压测 + 日常监控 | JMeter、wrk/wrk2、k6、Gatling、Locust |
| 页面加载速度 | 真实浏览器模拟 + CDN 层指标 | Lighthouse、WebPageTest、Chrome DevTools Performance |
| 慢查询 | APM 自动抓取 + 数据库慢查询日志 | SkyWalking、Pinpoint、Jaeger;MySQL slow_log、PG pg_stat_statements |
| P50/P95/P99 分布 | Metrics 系统直方图(不是平均值!) | Prometheus + Grafana(histogram_quantile)、Datadog、阿里云 ARMS |
| 资源瓶颈定位 | 压测中观察 CPU/内存/IO/网络 | top/htop、pidstat、iotop、nethogs;Arthas(Java 专属) |
性能问题用平均值诊断是盲人摸象。P99 才能看到那 1% 用户经历了什么。Prometheus 的
histogram_quantile(0.99, ...)是标准做法。
常见问题与修复
| 问题 | 根因 | 修复方向 | 具体手段 |
|---|---|---|---|
| 接口响应慢 | 数据库查询慢 | 优化查询 | 加索引、改写 SQL、分页查询避免 LIMIT offset, N(用游标分页)、避免 SELECT * |
| 减少查询量 | 缓存(Redis/Memcached)、预计算、读从库 | ||
| N+1 查询 | 批量加载 | DataLoader 模式、JOIN 替代循环查、Hibernate @BatchSize |
|
| 序列化开销大 | 简化返回 | 只返回必要字段(DTO 精简)、换 Protobuf/FlatBuffers 替代 JSON | |
| 页面加载慢 | 前端资源过大 | 压缩拆分 | Tree-shaking、Code splitting、图片 WebP/懒加载、Gzip/Brotli |
| 缓存策略 | CDN 部署、强缓存 + 协商缓存、Service Worker 预缓存 | ||
| 首屏依赖多 | 减少阻塞 | 关键 CSS 内联、JS defer/async、SSR/SSG 替代 CSR | |
| 并发吞吐低 | 锁竞争严重 | 减锁/无锁 | 乐观锁替代悲观锁、CAS 操作、读写锁、分段锁(ConcurrentHashMap 思路) |
| 异步化 | 消息队列削峰(Kafka/RabbitMQ)、异步任务(CompletableFuture/协程) | ||
| 连接池耗尽 | 调优池参数 | HikariCP 调 maxPoolSize、HTTP 连接池调 maxConnections、设置合理超时 | |
| 内存泄漏/GC频繁 | 对象无法回收 | 定位+修复 | jmap/heap dump → MAT 分析;Arthas profiler;修复未关闭资源、ThreadLocal 未清理 |
| GC 调优 | 选择合适 GC(G1/ZGC/Shenandoah)、调堆大小和 GC 频率阈值 |
2.2 可靠性与可用性(Reliability & Availability)
这两个经常被混在一起说,但严格讲是不同的:
| 可靠性(Reliability) | 可用性(Availability) | |
|---|---|---|
| 定义 | 系统在规定条件下、规定时间内不失效的能力 | 系统在需要时可被访问的概率 |
| 典型指标 | MTBF(平均无故障时间)、MTTR(平均恢复时间) | 可用率(如 99.9%、99.99%) |
| 关注点 | 多久会坏一次 | 坏了之后多久能恢复 |
| 类比 | 车多久抛锚一次 | 抛锚后多久能修好上路 |
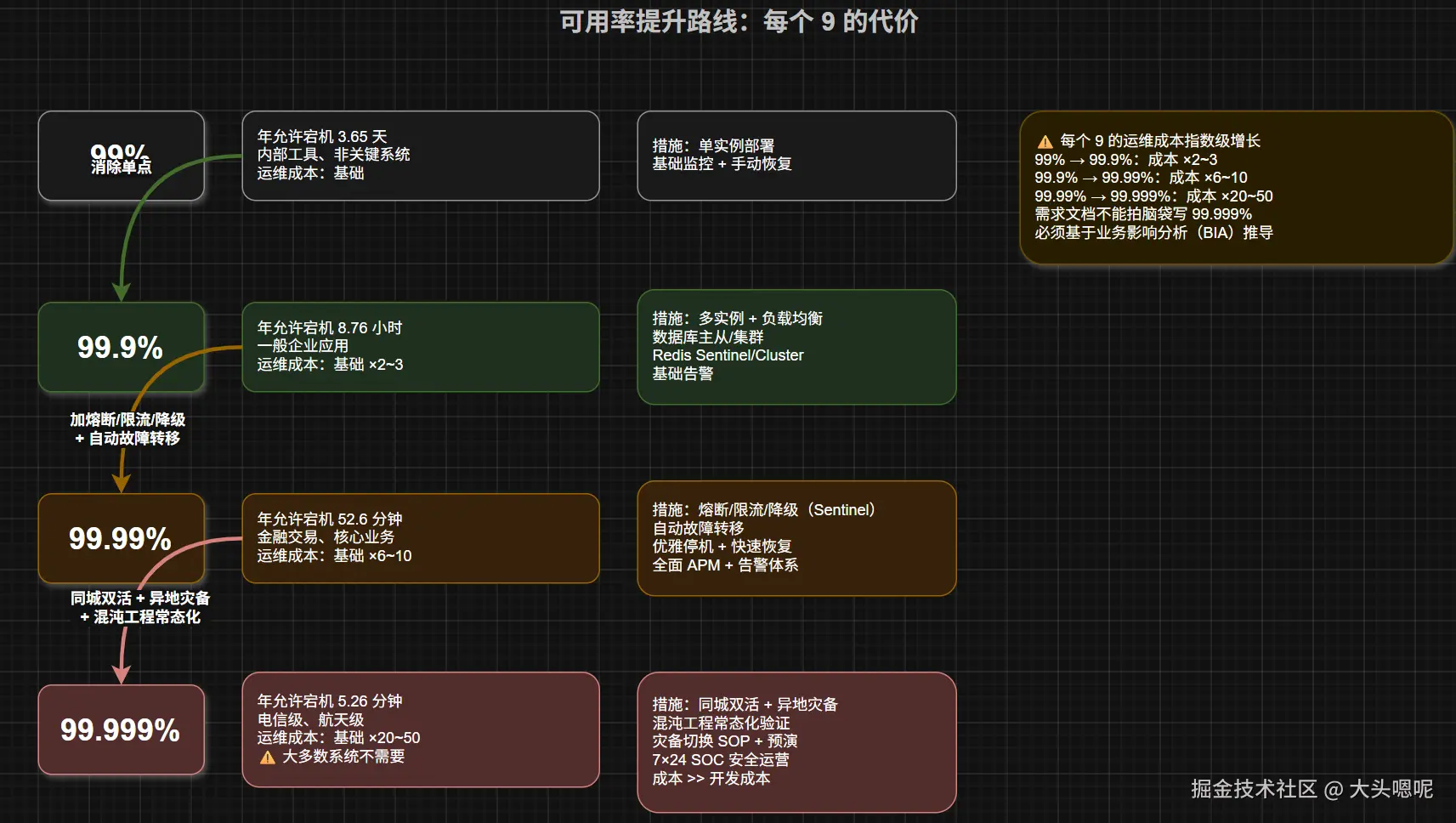
可用率的"9"文化:
| 可用率 | 年允许宕机时间 | 适合什么系统 |
|---|---|---|
| 99%(两个9) | 3.65 天 | 内部工具、非关键系统 |
| 99.9%(三个9) | 8.76 小时 | 一般企业应用 |
| 99.99%(四个9) | 52.6 分钟 | 金融交易、核心业务 |
| 99.999%(五个9) | 5.26 分钟 | 电信级、航天级 |
每个"9"的成本是指数级增长的。三个9到四个9,运维成本可能翻 3 倍。需求文档里不能随便写"99.99%"------要写清楚业务理由和成本承受范围。
怎么检测
| 检测维度 | 方法 | 工具 |
|---|---|---|
| 可用率计算 | (总时间 - 宕机时间) / 总时间 |
Prometheus uptime metric、UptimeRobot(外部探测)、Pingdom |
| MTBF/MTTR | 从故障记录中统计 | JIRA/ServiceNow 故障记录;Opsmetrics 自建统计 |
| 错误率监控 | HTTP 5xx 比率、业务异常率 | Prometheus rate(http_5xx[5m])、Sentry(前端异常)、Grafana 告警 |
| 混沌工程 | 主动注入故障验证系统反应 | Chaos Mesh(K8s)、Chaos Monkey(Spring Cloud)、LitmusChaos |
| 全链路压测 | 模拟真实流量压到极限 | JMeter + TCPCopy 录制回放、阿里云 PTS |
| 健康检查 | 定时探测服务存活 | Spring Boot Actuator、K8s liveness/readiness probe、Consul health check |
混沌工程的核心逻辑:不要等故障发生才发现扛不住,主动制造故障来验证。Netflix 的 Chaos Monkey 就是这个理念的开创者。
常见问题与修复
| 问题 | 根因 | 修复 |
|---|---|---|
| 服务宕机无感知 | 缺监控/告警 | Prometheus + Alertmanager 告警规则、Grafana dashboard、PagerDuty/钉钉告警 |
| 健康检查缺失 | K8s liveness probe(重启不健康 Pod)、readiness probe(摘除不就绪实例) | |
| 单点故障 | 关键服务只有 1 实例 | 多实例部署 + 负载均衡;数据库主从/集群;Redis Sentinel/Cluster |
| 级联崩溃 | 下游故障拖垮上游 | 熔断 (Hystrix/Sentinel/Resilience4j):失败率超阈值断开调用;降级 :返回兜底数据而非报错;限流:入口限流(Guava RateLimiter/Sentinel) |
| 超时设置不当 | 设置连接超时 + 读超时 + 重试超时;超时后快速失败 | |
| 重启恢复慢 | 启动依赖多/初始化重 | 懒加载(按需初始化)、预热脚本、并行初始化、K8s preStop hook 优雅停机 |
| 数据丢失 | 写入未持久化/磁盘故障 | WAL(Write-Ahead Log);数据 replica ≥ 2;fsync 策略合理配置;定期备份 + 验证备份可恢复 |
2.3 安全性(Security)
安全需求是最容易被"一句话概括"然后出大事的类别。
| 子维度 | 典型需求 |
|---|---|
| 认证 | 密码必须使用 BCrypt 哈希(cost ≥ 12);敏感操作需 MFA |
| 授权 | 权限模型选型(RBAC/ABAC/混合);数据隔离策略 |
| 数据保护 | 传输层 TLS 1.2+;存储层敏感字段加密;日志脱敏 |
| 审计 | 关键操作留痕,不可删除,保留 ≥ 180 天 |
| 合规 | 个人信息处理符合《个人信息保护法》;数据跨境需评估 |
| 抗攻击 | 防 SQL 注入/XSS/CSRF;限流策略(单 IP ≥ 100次/min 封禁) |
常见错误:安全需求只写了"系统要安全",没写具体要防什么、怎么防、达到什么级别。安全需求的核心不是"绝对安全"(不可能),而是定义风险可接受的范围。
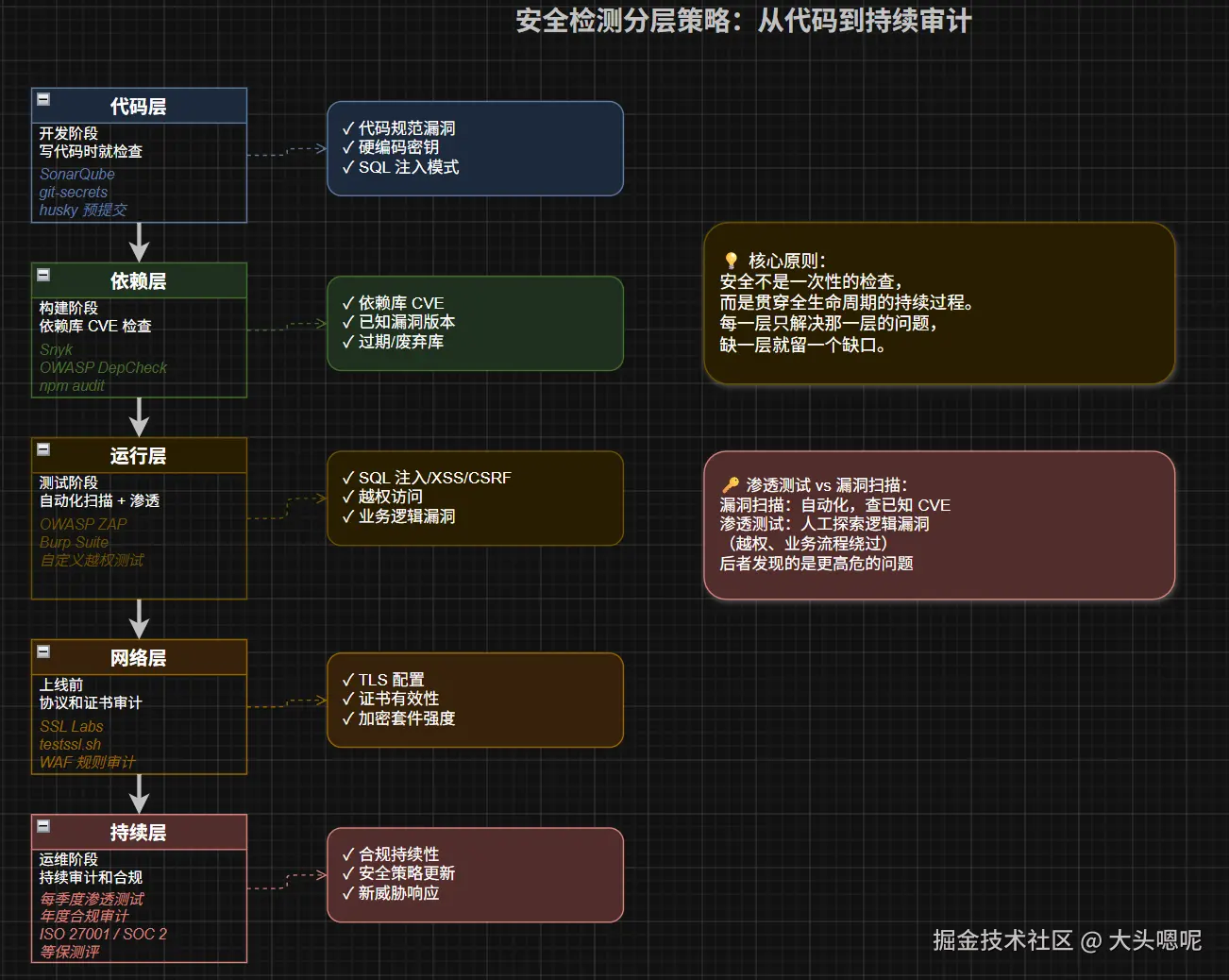
怎么检测
| 检测维度 | 方法 | 工具 |
|---|---|---|
| SQL 注入/XSS/CSRF | 自动化漏洞扫描 | OWASP ZAP、Burp Suite(专业版)、Snyk、SonarQube(规则检查) |
| 依赖漏洞 | 依赖库版本 CVE 检查 | Snyk、OWASP Dependency-Check、npm audit、Maven OWASP plugin |
| 密码存储安全 | 代码审计 + 配置检查 | 手动审查(是否用 BCrypt/Argon2)、git-secrets 防硬编码密码 |
| 权限漏洞 | 渗透测试 + 逻辑审查 | Burp Suite 手动渗透、自定义自动化测试(越权场景覆盖) |
| HTTPS/TLS 配置 | 协议和证书验证 | SSL Labs(ssllabs.com 在线检测)、testssl.sh(命令行) |
| 日志脱敏 | 日志审计 | ELK 中设敏感词过滤规则、人工抽查日志样本 |
| 合规审计 | 定期合规检查 | ISO 27001 审计框架、SOC 2 审计、国内等保测评工具 |
渗透测试 vs 漏洞扫描:漏洞扫描是自动化地检查已知 CVE 和模式;渗透测试是人手动探索逻辑漏洞(如越权、业务流程绕过),后者发现的往往是更高危的问题。
常见问题与修复
| 问题 | 根因 | 修复 |
|---|---|---|
| SQL 注入 | SQL 拼接用户输入 | 永远用参数化查询(PreparedStatement/ORM);输入校验白名单;WAF 防护(兜底) |
| XSS | 未转义用户输入输出到页面 | 输出编码(HTML/CSS/JS context 各有对应编码);CSP 策略限制脚本来源;Vue/React 默认转义,但 v-html/dangerouslySetInnerHTML 要格外小心 |
| CSRF | 无防伪令牌 | CSRF Token(Spring Security 默认启用);SameSite Cookie 设 Lax/Strict |
| 密码明文/MD5 | 哈希算法不安全 | 迁移到 BCrypt(cost ≥ 12)或 Argon2;双哈希迁移策略 |
| 越权访问 | 只校验角色不校验归属 | 水平越权 :查数据加 WHERE user_id = 当前用户;垂直越权:每个接口校验角色 + 操作权限;ABAC/ReBAC 增强细粒度控制 |
| 敏感数据泄露 | 日志/响应含明文敏感字段 | 日志脱敏(手机号 → 138****1234);API 返回 DTO 精简字段;数据库加密存储(AES-256 + KMS) |
| 硬编码密钥 | 开发者把密钥写进代码 | 环境变量/配置中心(Spring Cloud Config Vault)/密钥管理服务(AWS KMS/阿里云 KMS);git-secrets/husky 预提交扫描 |
| TLS 配置弱 | 支持旧协议/弱加密套件 | 禁用 TLS 1.0/1.1,只用 TLS 1.2+;禁用弱套件(RC4/DES);HSTS 强制 HTTPS |
| 依赖库有 CVE | 长期不升级依赖 | Snyk/DepCheck CI 扫描流程;发现高危 CVE → 升级或找替代库;锁定依赖版本(lockfile) |
2.4 可扩展性(Scalability)
| 子维度 | 说明 | 典型指标 |
|---|---|---|
| 纵向扩展 | 单机加 CPU/内存能撑多久 | "单节点从 4C8G 升到 16C32G,吞吐提升 ≥ 3 倍" |
| 横向扩展 | 加机器能不能线性增长 | "加 1 个节点,吞吐量提升 ≥ 80% 理论值" |
| 数据扩展 | 数据量从 10G 到 10T 行不行 | "数据量增长 10 倍,查询延迟增长 ≤ 30%" |
| 功能扩展 | 加新功能会不会影响旧功能 | "新模块上线不影响核心链路 P99 延迟" |
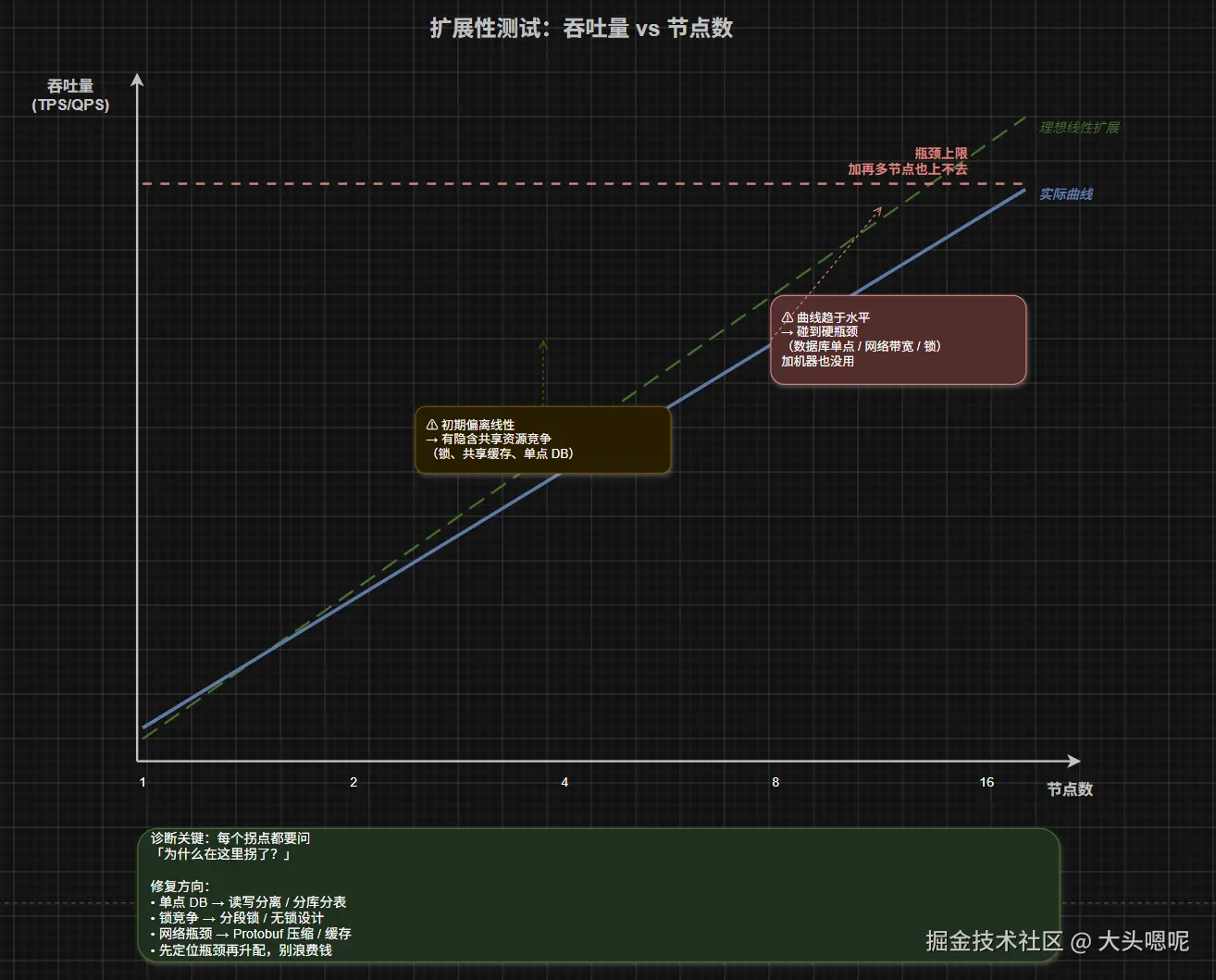
横向扩展最关键的问题是:有没有瓶颈节点? 如果数据库是单点的,加了 100 台应用服务器也没用------请求全堆在数据库上。扩展性需求必须指出哪些组件是瓶颈、瓶颈怎么解决。
怎么检测
| 检测维度 | 方法 | 工具 |
|---|---|---|
| 横向扩展效果 | 逐步加节点压测,看吞吐是否线性增长 | JMeter/k6 集群模式;记录 N 节点 vs 吞吐曲线 |
| 纵向扩展效果 | 单节点升配压测对比 | 同上,对比 4C8G vs 8C16G vs 16C32G |
| 数据量增长影响 | 不同数据量级下跑同一查询集 | 造数据脚本(10万/100万/1000万/1亿行);对比 QPS 和延迟 |
| 瓶颈节点定位 | 压测时看各层资源水位 | Prometheus 监控各组件 CPU/内存/连接数/队列深度 |
| 扩展性架构审查 | 代码/架构 Review | 检查是否有状态耦合、全局锁、单点依赖 |
常见问题与修复
| 问题 | 根因 | 修复 |
|---|---|---|
| 加机器吞吐不增 | 瓶颈在数据库单点 | 数据库读写分离;分库分表(ShardingSphere/MyCat);引入缓存层减少 DB 压力 |
| 瓶颈在共享资源(排队锁) | 拆锁(分段锁、细粒度锁);无锁设计(CAS/原子操作);乐观锁替代悲观锁 | |
| 瓶颈在网络带宽 | 内网通信压缩(Protobuf);减少不必要的网络调用(本地缓存/batch) | |
| 单机升配无效 | CPU 已不是瓶颈(是 IO/锁/等待) | 先定位瓶颈再做升配决策------盲目升配是浪费钱 |
| 数据量大了查询崩 | 索引不再有效/全表扫描 | 合理索引设计;覆盖索引避免回表;分库分表按时间/地域分片;冷热数据分离 |
| JOIN 太复杂 | 简化 JOIN(冗余字段反范式设计);ES 做宽表搜索;数据预聚合 | |
| 功能扩展影响旧功能 | 模块耦合严重 | 模块化拆分(DDD 限界上下文);事件驱动解耦;接口隔离原则;灰度发布验证 |
| 新模块上线拖慢全局 | 共享资源被抢占 | 资源隔离(K8s namespace + resource limit);线程池隔离(Sentinel);独立部署 |
2.5 易用性(Usability)
不只是"界面好看",更核心的是用户能不能高效完成任务。
| 子维度 | 典型指标 |
|---|---|
| 学习成本 | 新用户完成核心操作 ≤ 3 次尝试 / ≤ 5 分钟 |
| 操作效率 | 常规任务操作步骤 ≤ N 步 |
| 错误率 | 用户误操作率 ≤ 5% |
| 可访问性 | 符合 WCAG 2.1 AA 级(视障/听障适配) |
| 多端适配 | 移动端核心功能覆盖率 ≥ 90% |
| 国际化 | 支持 ≥ 3 种语言,UI 文案可配置 |
易用性需求的特别之处:它需要用户测试来验证,不是开发团队自己就能评判的。
怎么检测
| 检测维度 | 方法 | 工具 |
|---|---|---|
| 任务完成率 | 给用户一个任务,看能不能完成 | UserTesting、Maze、Hotjar(录屏+热力图) |
| 操作步数 | 核心流程点击/操作计数 | Telemetry 埋点统计;Maze 路径分析 |
| 错误率 | 用户误操作频次 | 前端错误追踪(Sentry);A/B 测试对比新旧方案错误率 |
| 满意度 | 用户主观评价 | SUS 问卷(System Usability Scale,10题标准量表);NPS 调研 |
| 学习成本 | 新用户首次完成任务耗时 | 新手测试(invite 非产品人员做任务);Maze 时间指标 |
| 热力图 | 用户在哪里点、在哪里迷路 | Hotjar、FullStory、Microsoft Clarity(免费) |
| 无障碍 | WCAG 合规自动检测 | axe(浏览器插件)、Lighthouse Accessibility 评分、Pa11y(CI 集成) |
易用性检测最大的误区:开发团队自己测自己的产品。你对自己设计的界面太熟悉了,"直觉好用"只对你成立。必须找非产品团队的真实用户来测。
SUS 量表是易用性量化的标准方法------10 道题、5 分制,评分 ≥ 80 为优秀,60-80 为可接受,< 60 为差。它提供了一个跨产品可比较的评分体系,不是团队内部"感觉还行",而是有数据支撑的判断。
常见问题与修复
| 问题 | 根因 | 修复 |
|---|---|---|
| 用户找不到功能 | 信息架构混乱/入口不显眼 | 重新梳理导航层级;核心功能入口置顶/加大;用户旅程图分析断点 |
| 操作步骤太多 | 流程设计冗余 | 合并步骤(表单合并、智能默认值);批量操作支持;一键操作 |
| 频繁误操作 | 界面暗示模糊/缺少确认 | 关键操作加二次确认(不要滥用);危险操作用红色警示;操作可撤销优于确认对话框 |
| 表单填完提交失败 | 校验滞后/提示不清 | 实时校验(输入时即反馈);校验信息具体("手机号应为11位数字"而非"格式错误") |
| 新用户不会用 | 缺引导 | 首次使用引导流程(onboarding tour);空状态引导文案;操作提示 tooltip |
| 移动端体验差 | PC 设计直接缩放到手机 | 移动端独立设计;触摸友好(按钮 ≥ 44px);手势操作替代长流程 |
| 无障碍不合规 | 从未考虑视障/听障用户 | 语义化 HTML;ARIA 属性;键盘可操作全部功能;颜色对比度 ≥ 4.5:1 |
2.6 可维护性(Maintainability)
| 子维度 | 典型指标 |
|---|---|
| 代码可读性 | 代码规范覆盖率 ≥ 95%(lint 工具检测) |
| 模块化 | 单模块修改不影响 ≥ 5 个其他模块 |
| 可观测性 | 核心链路日志覆盖率 100%;异常自动告警 ≤ 1 分钟 |
| 部署效率 | 单次发布 ≤ 30 分钟;回滚 ≤ 10 分钟 |
| 文档覆盖 | 核心模块设计文档覆盖率 ≥ 80% |
| 技术债务 | 已知技术债务的修复周期 ≤ 2 个迭代 |
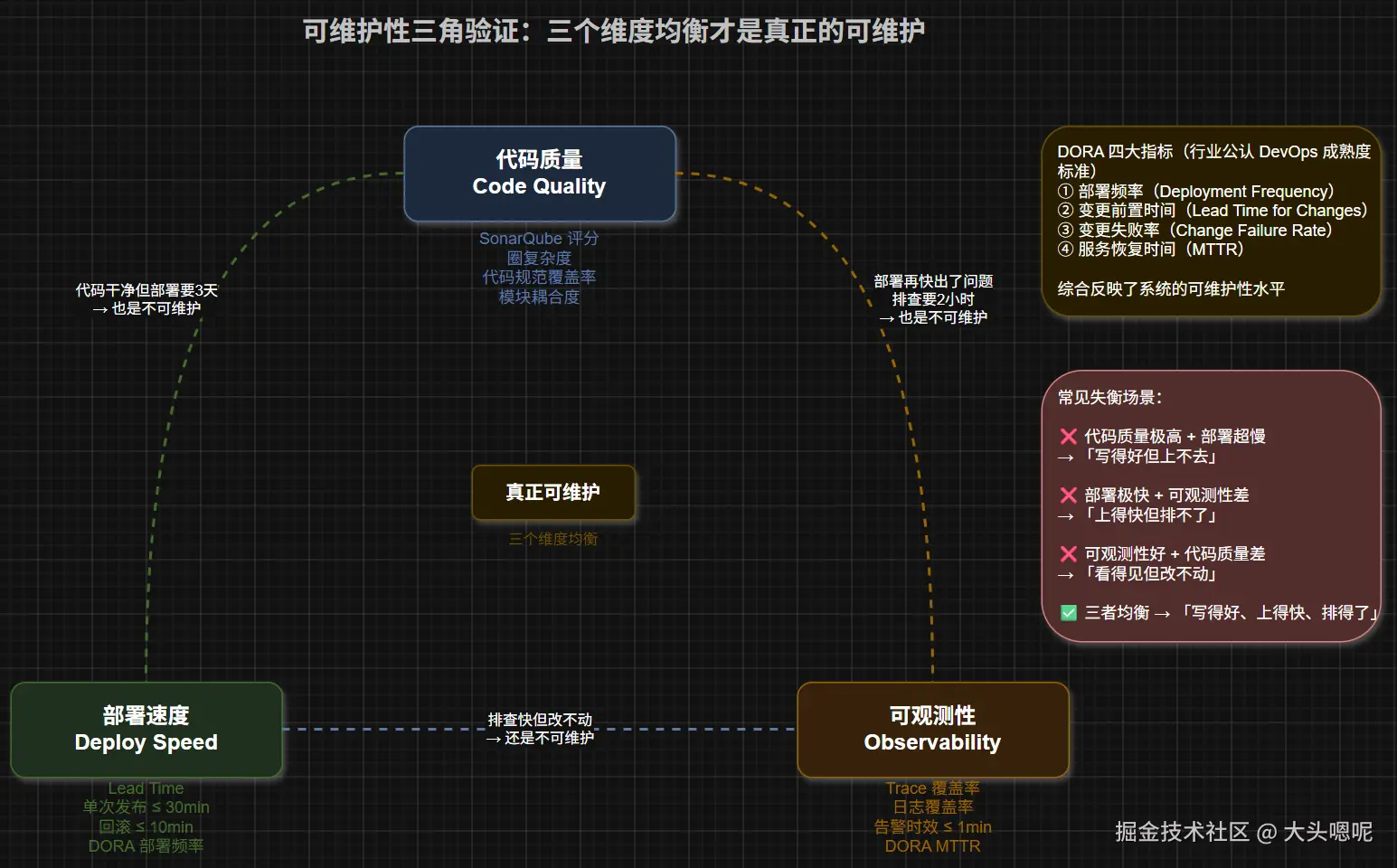
一个常被忽略的指标:平均变更前置时间(Lead Time for Changes)------从代码提交到上线的时长,直接反映系统的可维护性。
怎么检测
| 检测维度 | 方法 | 工具 |
|---|---|---|
| 代码质量 | 自动化静态分析 | SonarQube(Bugs/Vulnerabilities/Code Smells/覆盖率)、ESLint、Pylint |
| 圈复杂度 | 函数分支复杂度检测 | SonarQube、Lizard(多语言)、IDEA 内建分析 |
| 模块耦合度 | 依赖关系分析 | SonarQube 依赖图、Structure101(Java)、Madge(JS 模块依赖图) |
| 可观测性 | 日志/链路/指标覆盖度检查 | 人工 Review:核心链路是否都有 Trace、关键指标是否有 Metric、异常是否都有告警 |
| 部署速度 | 测量 CI/CD 流水线耗时 | Jenkins/GitLab CI pipeline 时长统计;GitHub Actions Insights |
| 文档覆盖 | 文档与代码对应度 | 人工 Review;Swagger/OpenAPI 文档自动化生成率 |
| 变更前置时间 | 从 commit 到 production 的时间 | DORA 四大指标之一;JIRA + CI 数据统计 |
DORA 四大指标(Google DevOps 研究团队提出,行业公认衡量 DevOps 成熟度):
- 部署频率(Deployment Frequency)
- 变更前置时间(Lead Time for Changes)
- 变更失败率(Change Failure Rate)
- 服务恢复时间(MTTR)
常见问题与修复
| 问题 | 根因 | 修复 |
|---|---|---|
| 代码质量差 | 缺规范/缺检查 | SonarQube 设 Quality Gate(不达标不让合并);代码 Review 强制执行;统一 lint config |
| 圈复杂度高 | 函数太长/分支太多 | 单一职责拆函数;卫语句替代嵌套 if;策略模式替代 switch-case |
| 改一处坏一片 | 模块耦合严重 | 依赖倒置(DIP);接口隔离;事件驱动解耦;DDD 限界上下文划分 |
| 上线慢 | 手动部署/流程长 | CI/CD 自动化(Jenkins/GitLab CI/GitHub Actions);容器化(Docker/K8s);蓝绿/金丝雀发布 |
| 测试耗时 | 测试分层(单元快→集成中→E2E慢);并行测试;只对变更模块跑测试 | |
| 故障排查慢 | 缺 Trace/缺日志 | APM(SkyWalking/Jaeger);结构化日志(JSON 格式);日志分级策略 |
| 告警泛滥 | 告警分级(P0-P3);告警降噪(合并同类、抑制级联);On-call 轮值 | |
| 改不动 | 技术债堆积 | 定期"技术债日"(每迭代留 20% 时间还债);债务登记;重构渐进式(Strangler Fig 模式) |
| 文档缺失 | 没人写/写了不更新 | API 文档自动化(Swagger/OpenAPI);架构决策记录(ADR);README 必填检查 |
2.7 可移植性与兼容性(Portability & Compatibility)
| 子维度 | 典型需求 |
|---|---|
| 浏览器兼容 | Chrome / Firefox / Safari / Edge 最近 2 个主版本 |
| 操作系统 | Windows 10+ / macOS 12+ / Ubuntu 20.04+ |
| 移动端 | iOS 14+ / Android 10+ |
| 数据迁移 | 支持从旧版本数据无损迁移 |
| API 兼容 | 公开 API 版本化,变更需 ≥ 6 个月过渡期 |
| 部署环境 | 支持私有云 / 公有云 / 混合云部署 |
怎么检测
| 检测维度 | 方法 | 工具 |
|---|---|---|
| 浏览器兼容 | 跨浏览器自动化测试 | Selenium Grid、Playwright(多浏览器)、BrowserStack/Sauce Labs |
| 移动端兼容 | 多设备真机/模拟器测试 | Appium、BrowserStack App Live、Android Emulator + iOS Simulator |
| API 兼容 | 接口变更影响分析 | OpenAPI Diff(对比两版 API 变化)、Spring Cloud Contract(消费者驱动契约测试) |
| 数据迁移 | 旧版→新版数据迁移验证 | 自建迁移脚本 + 数据校验脚本(行数/关键字段 checksum 对比) |
| 多环境部署 | 在不同云/OS 上部署测试 | Docker 镜像保证环境一致性;Terraform/Pulumi 多云部署模板;Ansible 多 OS 配置 |
| 响应式适配 | 不同屏幕尺寸 UI 测试 | Playwright 视口切换、Lighthouse Mobile 评分、Responsively App |
常见问题与修复
| 问题 | 根因 | 修复 |
|---|---|---|
| 某浏览器崩 | CSS/JS 兼容差异 | Can I Use 查兼容性;Autoprefixer 自动加厂商前缀;Polyfill(core-js)补缺失 API;Babel 转译新语法 |
| 旧版 API 客户端报错 | 接口变更未兼容 | API 版本化 (URL path /v1/ /v2/ 或 Header);变更公告 + ≥ 6 月过渡期;Contract Test |
| 数据迁移丢数据 | 字段映射遗漏/类型转换错误 | 迁移前后数据校验(行数、checksum、抽样对比);灰度迁移(先迁 10% 验证);回滚脚本就绪 |
| 换环境跑不起来 | 环境依赖硬编码 | 配置外部化(环境变量/配置中心);Docker 统一运行环境;避免依赖特定 OS 路径/时区/编码 |
| 新 OS 版本不兼容 | 用了废弃 API | 跟踪 OS/API 版本更新;及时迁移到新 API;CI 矩阵测试(多 OS 版本并行跑) |
2.8 韧性/容灾(Resilience & Disaster Recovery)
这是近年来越来越被重视的类别,尤其对云原生系统。
| 子维度 | 典型指标 |
|---|---|
| 故障隔离 | 单服务故障不引发级联崩溃(限流/熔断/降级) |
| 降级策略 | 核心功能可用率 ≥ 99.9%;非核心功能降级时核心不受影响 |
| 数据恢复 | RPO ≤ 15 分钟(数据丢失量) |
| 服务恢复 | RTO ≤ 30 分钟(从宕机到恢复) |
| 备份策略 | 全量备份每周 1 次;增量备份每 6 小时 |
| 灾备切换 | 同城双活 / 异地灾备切换 ≤ 5 分钟 |
RPO(Recovery Point Objective) :允许丢失多长时间的数据。RPO=0 意味着零数据丢失,成本极高。 RTO(Recovery Time Objective):允许多长时间恢复服务。RTO=0 意味着零中断,基本不可能。
怎么检测
| 检测维度 | 方法 | 工具 |
|---|---|---|
| 熔断/限流验证 | 注入高负载/故障看是否正确断开 | Sentinel dashboard 看熔断触发;手动触发压测超阈值观察 |
| 降级效果 | 关闭下游服务看上游是否降级 | Chaos Mesh 杀 Pod/断网络;手动停下游观察兜底逻辑 |
| 级联故障隔离 | 同时注入多故障看是否级联 | Chaos Mesh 组合场景(Pod kill + 网络延迟 + CPU 压力) |
| RPO 验证 | 模拟数据丢失看能恢复到哪个时间点 | 测试环境故意删数据 → 从备份恢复 → 对比丢失量 |
| RTO 验证 | 模拟宕机看多久恢复 | Chaos Mesh 杀整体服务 → 测量自动恢复时间;灾备切换演练 |
| 备份有效性 | 定期 restore drill | 从备份恢复到测试环境 → 运行业务验证 → 记录恢复时间 |
| 灾备切换 | 真实切换演练 | 年度灾备演练(非纸上谈兵);记录切换耗时和业务恢复率 |
恢复演练最大的坑:备份做了但从来没验证能不能恢复。很多团队在灾难发生时才发现备份文件损坏、恢复脚本过期、数据格式不兼容------这些在演练中都能提前暴露。
常见问题与修复
| 问题 | 根因 | 修复 |
|---|---|---|
| 无熔断保护 | 没配熔断规则 | 接入 Sentinel/Resilience4j:设慢调用比例阈值、异常比例阈值、熔断恢复时间 |
| 限流不住 | 限流粒度太粗/阈值太高 | 多级限流:全局 QPS → 单 IP → 单用户 → 单接口;Sentinel 热点参数限流 |
| 降级无兜底 | 降级只返回错误页 | 返回缓存数据 / 默认值 / 简化版功能 / 引导稍后重试 |
| 故障级联 | 服务间无隔离 | 线程池隔离;信号量隔离;超时快速失败;断路器阻断级联 |
| RPO 不达标 | 备份频率低/同步延迟大 | 提高增量备份频率;数据库实时同步到异地(MySQL binlog/PG 逻辑复制) |
| RTO 不达标 | 恢复流程手动/无预案 | 自动化恢复脚本;K8s HPA + PDB;灾备切换 SOP 文档化 + 预演 |
| 备份恢复失败 | 备份损坏/脚本过时 | 定期 restore drill(每季度 ≥1 次);备份校验(checksum);恢复脚本纳入 CI |
| 数据不一致 | 主从同步延迟 | 关键写入走主库即时读;半同步复制;Raft/Paxos 协议 |

三、NFR 最大的三个坑
坑 1:模糊词------"快""稳定""安全"
❌ "系统响应要快" ❌ "系统要稳定运行" ❌ "要保证数据安全"
这些词没有可验证性。验收时没法说"不够快"------因为"快"没有标准。
修正公式:指标 + 条件 + 阈值 + 约束
✅ "API 响应时间 P95 ≤ 500ms,在 2000 并发用户条件下,连续运行 72 小时不超标"
坑 2:脱离现实的指标------"99.999%可用"
五个 9 意味着全年只能宕机 5 分钟。对于大多数企业系统,这不仅没必要,运维成本还会吞噬整个项目预算。
正确做法:根据**业务影响分析(BIA)**推导可用率要求,而不是拍脑袋写数字。
坑 3:NFR 之间互相打架
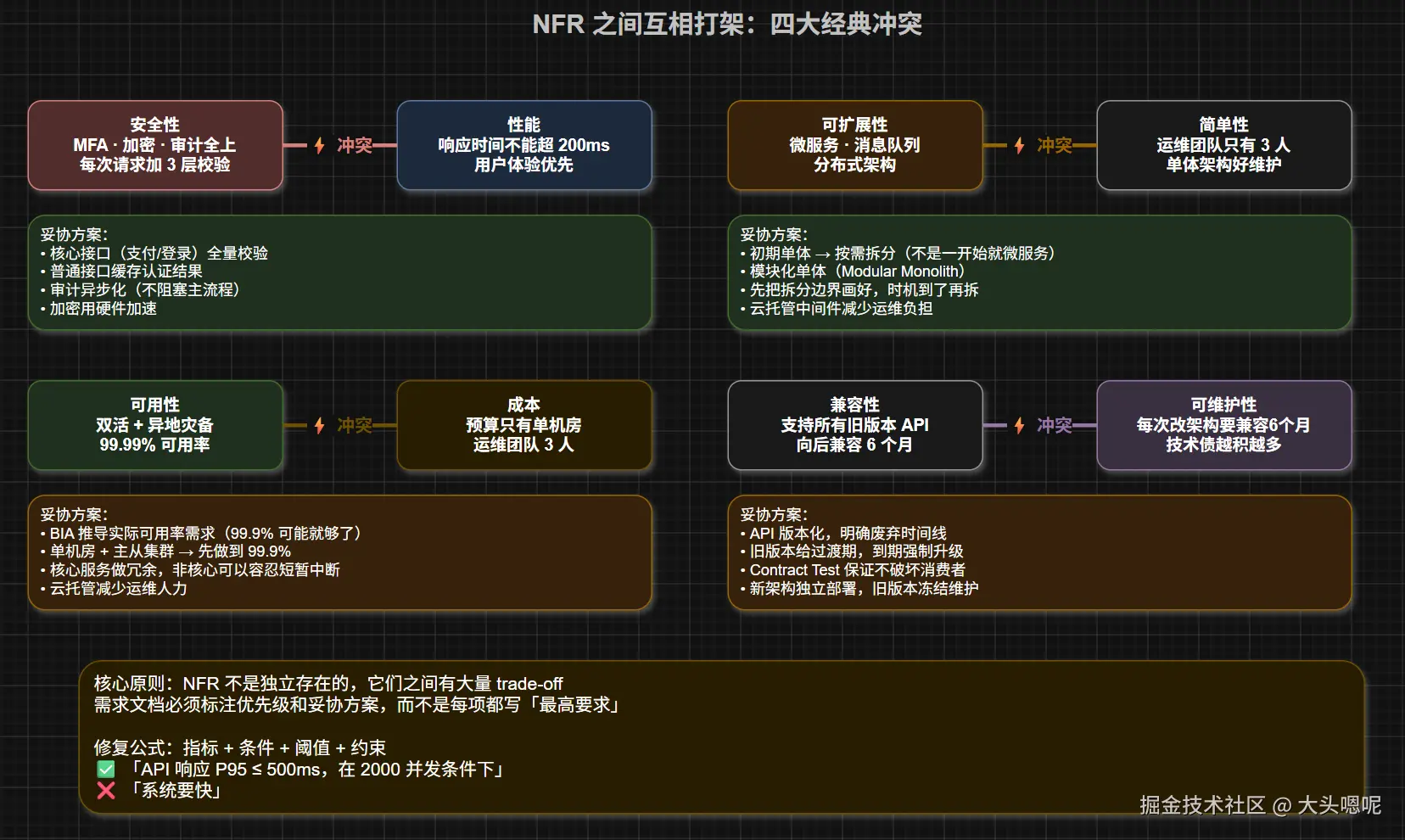
最经典的冲突:
| 冲突 | 一方 | 另一方 |
|---|---|---|
| 安全 vs 性能 | MFA、加密、审计全上 | 响应时间不能超 200ms |
| 可用 vs 成本 | 双活 + 异地灾备 | 预算只有单机房 |
| 扩展 vs 简单 | 微服务、消息队列 | 运维团队只有 3 人 |
| 兼容 vs 维护 | 支持所有旧版本 API | 每次改架构要兼容 6 个月 |
NFR 不是独立存在的,它们之间有大量 trade-off。需求文档必须标注优先级和妥协方案,而不是每项都写"最高要求"。
四、一个真正能落地的 NFR 模板
markdown
### [类别名称] --- [优先级: P0/P1/P2]
**目标**:一句话说清楚要达到什么效果
**具体指标**:
- 指标1: 值 + 条件 + 验证方式
- 指标2: 值 + 条件 + 验证方式
**妥协与约束**:
- 与 [某NFR] 的冲突处理:当 [条件] 时,优先 [某方]
- 成本上限:[金额/人力]
**验证方法**:
- 压测工具 + 测试场景
- 或:用户测试 + 评分标准
**不满足时的处理**:
- P0 不满足 → 不上线
- P1 不满足 → 上线后 N 个迭代内修复
- P2 不满足 → 接受现状,持续优化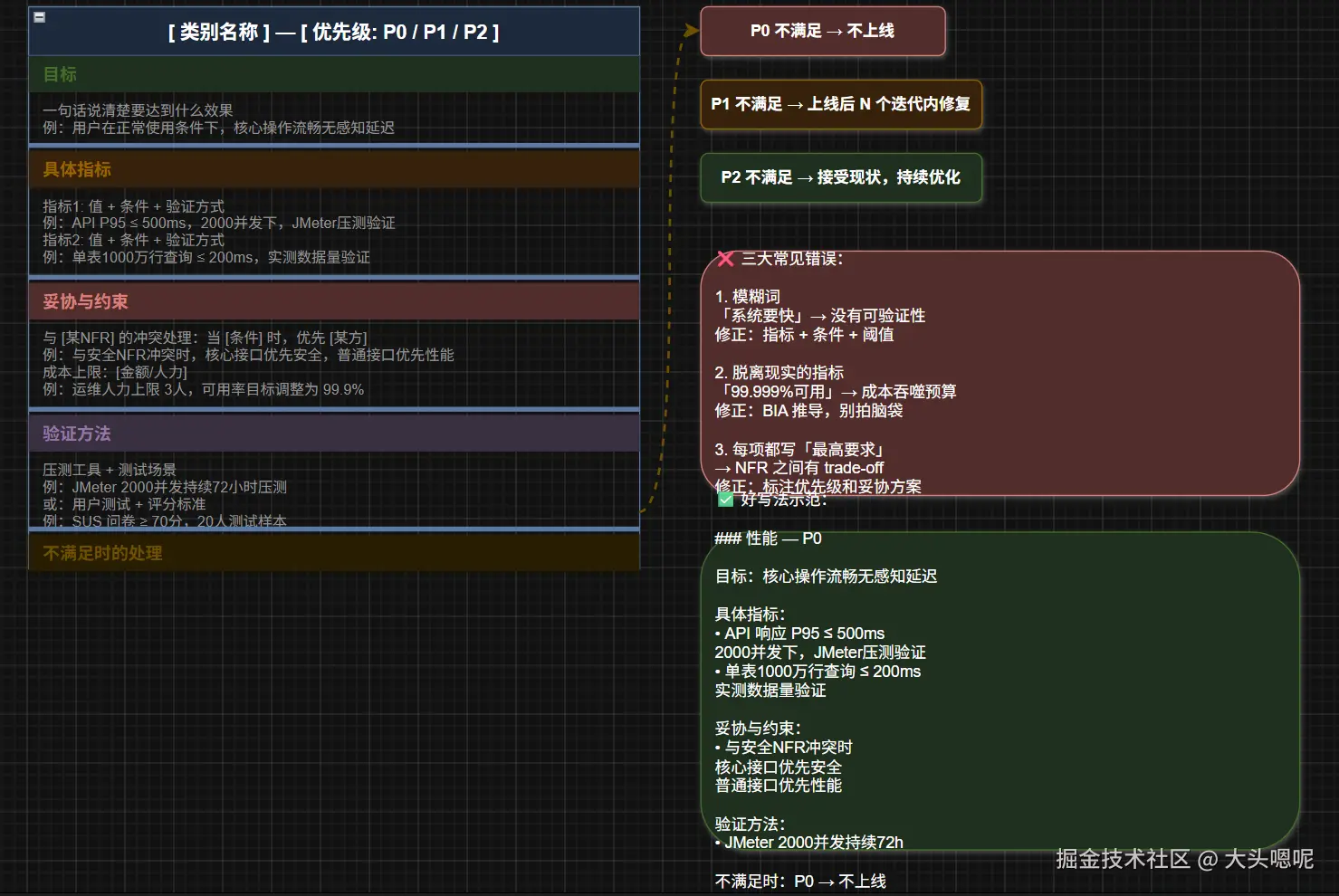
五、全局工具速查表
| 类别 | 核心检测工具 | 核心修复手段 |
|---|---|---|
| 性能 | JMeter/k6 + Prometheus + APM | 索引优化、缓存、异步化、连接池调优 |
| 可靠可用 | Prometheus + Chaos Mesh + Sentry | 多实例、熔断/限流/降级、健康检查、自动恢复 |
| 安全 | OWASP ZAP + Snyk + SonarQube | 参数化查询、编码输出、BCrypt、越权校验、TLS 升级 |
| 扩展 | 压测曲线分析 + Prometheus 水位 | 分库分表、缓存、无锁设计、模块解耦 |
| 易用 | Maze + Hotjar + SUS 问卷 + Lighthouse | 信息架构优化、实时校验、onboarding、无障碍 |
| 维护 | SonarQube + DORA 指标 + APM | CI/CD、代码规范 Gate、技术债管理、文档自动化 |
| 兼容 | Playwright/BrowserStack + API Diff | Polyfill、API 版本化、Docker 环境统一、数据校验迁移 |
| 韧性/容灾 | Chaos Mesh + Restore Drill + 灾备演练 | 多级防御、备份+校验、自动化恢复、灾备 SOP |
六、总结
NFR 不是需求规格说明书的"附录"或"补充说明",而是决定系统上线后命运的核心部分。
回顾全文,三个核心观点:
- NFR 必须可验证------模糊词等于没写,每个指标都要量化、带条件、有检测方法
- NFR 之间有 trade-off------不要每项都写"最高要求",要标注优先级和妥协方案
- NFR 的检测和修复有成熟工具链------不需要从零开始,选对应类别的主流工具即可
最后再强调一次那句话:
功能性需求决定了产品能不能交付,非功能性需求决定了交付后能不能活下来。
如果这篇文章对你有帮助,欢迎点赞、收藏、关注 👍