目录
- 一、分析(目标+抓包+定位+结论)
- [二、Python 实现](#二、Python 实现)
-
- [2.1 最小验证版(扣 JS / 纯 Python 两条路)](#2.1 最小验证版(扣 JS / 纯 Python 两条路))
- [2.2 封装版(OOP + 多线程 + loguru 日志)](#2.2 封装版(OOP + 多线程 + loguru 日志))
- 三、总结
免责声明:本文内容仅用于合法授权范围内的技术学习、安全研究、逆向分析方法交流与风控防护理解,不针对任何网站、产品或服务提供绕过、攻击、滥用或破坏性使用建议。文中涉及的接口分析、参数加解密、调试定位、代码复现、数据请求等内容,仅用于说明相关技术原理和分析流程。读者应在遵守相关法律法规、平台规则、robots 协议、用户协议以及获得合法授权的前提下进行学习和实验。请勿将本文中的方法、脚本或思路用于未授权访问、批量采集、账号撞库、绕过风控、破坏验证码体系、规避平台限制、侵犯数据权益、商业化滥用或影响线上系统稳定性的行为。对于真实网站案例,读者不应直接复制代码对线上服务进行高频请求或非授权调用。若相关网站、产品方、权利方或平台认为本文内容存在不适宜公开展示之处,可通过评论区、私信或作者主页提供的联系方式联系我;核实后将及时删除、替换或调整相关内容。读者因不当使用本文内容造成的任何法律责任、业务风险或经济损失,均由使用者自行承担,与作者无关。
一、分析(目标+抓包+定位+结论)
需求:抓取申万宏源证券新闻中心的公司新闻,循环采集前 3 页,提取每条新闻的标题、发布时间,并拼出详情页链接。目标页面:
text
https://www.swhysc.com/swhysc/news/company抓包:F12 打开 DevTools,切到 Network,清空请求记录。这类列表数据通常是 Ajax 动态加载的,所以过滤 Fetch/XHR,然后翻页触发请求,定位数据包:
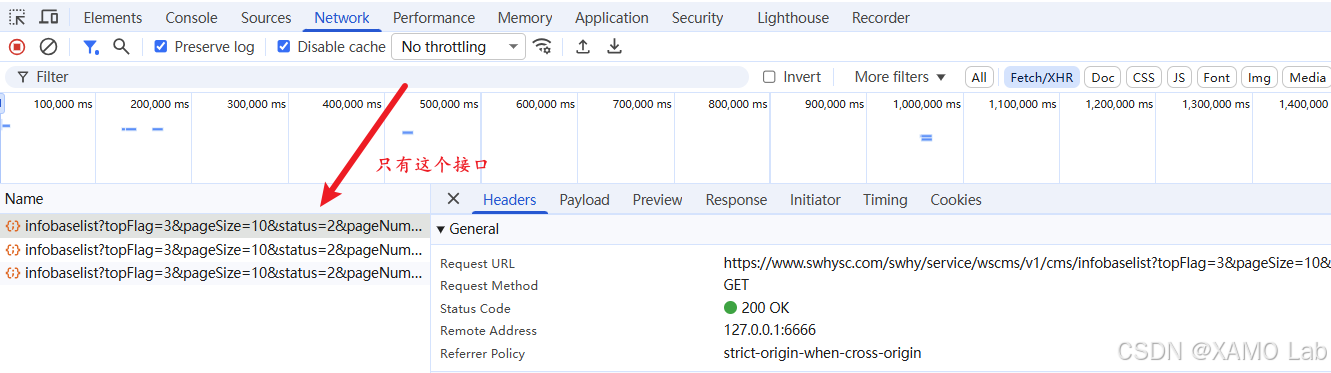
捕获到目标接口,是一个 GET 请求:
text
GET https://www.swhysc.com/swhy/service/wscms/v1/cms/infobaselist多次翻页对比 Query String 参数:
text
topFlag=3&pageSize=10&status=2&pageNum=2&channelId=00010002000100030001
topFlag=3&pageSize=10&status=2&pageNum=3&channelId=00010002000100030001
topFlag=3&pageSize=10&status=2&pageNum=4&channelId=00010002000100030001参数含义梳理:
| 参数 | 含义 | 说明 |
|---|---|---|
pageNum |
页码 | 翻页时唯一变化的参数 |
pageSize |
每页条数 | 固定 10 |
channelId |
栏目频道 ID | 决定抓哪个板块 ,公司新闻为 00010002000100030001 |
topFlag / status |
置顶标记 / 发布状态 | 固定值,前端写死 |
关于 channelId :它唯一对应一个新闻栏目,这里写死成公司新闻的 00010002000100030001 即可。如果要抓新闻中心下的其他板块(如 媒体聚焦、研究报告 等),只需在对应页面抓包拿到那个板块的 channelId 替换即可,解密逻辑完全通用。
精简请求头 :观察请求头没有发现自定义校验字段。保险起见,右键接口 → Copy → Copy as cURL (bash),粘贴到 curlconverter.com 转成 Python 代码,在 PyCharm 里逐步删头测试。结果是:不带 Cookie 也能请求,服务端对请求头没有严格校验,只保留一个 User-Agent 即可。剩下的核心问题就只有一个------响应体是密文,需要解密。
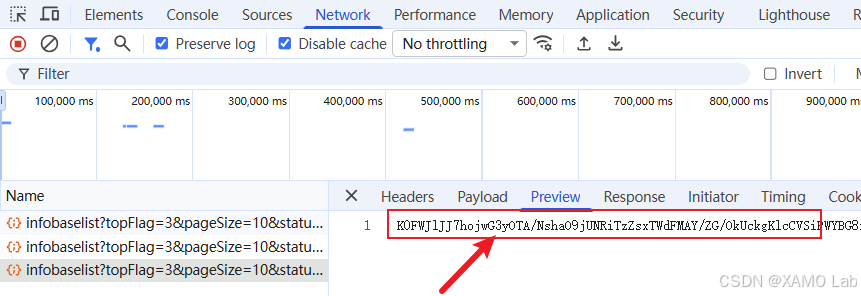
定位解密函数:响应解密一般有两条思路:
- Hook
JSON.parse,从「解密后必然会 parse 成对象」这个点反向回溯; - 直接全局搜索
decrypt/AES这类关键字。
对于这种业务体量较大的站点,JSON.parse 的调用点遍布各处,断点命中后噪声很大、回溯成本高。所以这里优先用第二种------直接搜 decrypt:
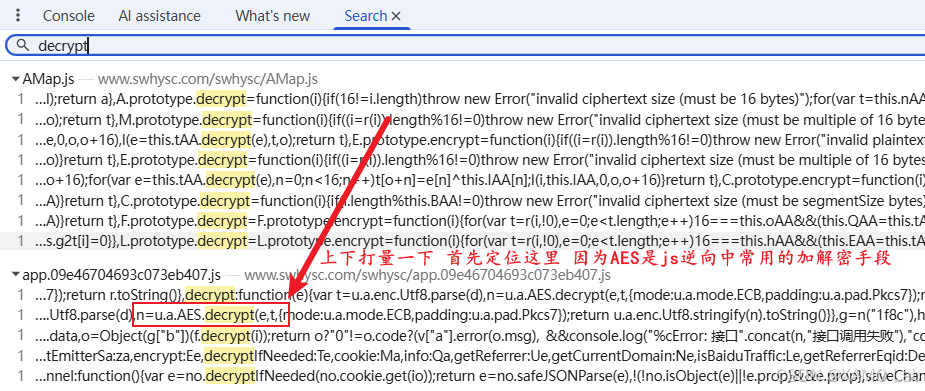
点进去,命中的就是加解密工具对象 f(同时定义了 encrypt 和 decrypt),解密函数如下:
javascript
f = {
// 加密:请求方向用(本案例用不到,但能佐证 Key 和模式)
encrypt: function(e) {
var t = u.a.enc.Utf8.parse(d) // 密钥:把字符串 d 当作 UTF-8 字节
, n = u.a.enc.Utf8.parse(e)
, r = u.a.AES.encrypt(n, t, {
mode: u.a.mode.ECB,
padding: u.a.pad.Pkcs7
});
return r.toString()
},
// 解密:响应方向用 ------ 这就是我们要还原的入口
decrypt: function(e) { // e = 服务端返回的 Base64 密文
var t = u.a.enc.Utf8.parse(d) // t = 密钥(来自字符串 d)
, n = u.a.AES.decrypt(e, t, { // CryptoJS 收到字符串密文时默认按 Base64 解析
mode: u.a.mode.ECB, // ECB 模式 → 无需 IV
padding: u.a.pad.Pkcs7 // PKCS7 填充
});
return u.a.enc.Utf8.stringify(n).toString() // 字节 → UTF-8 明文字符串
}
}u.a 即 CryptoJS(页面引入了 npm.crypto-js 这个 bundle,展开对象能看到 AES/MD5/enc 等完整算法集)。
断点验证 :在 decrypt 内打断点,翻页触发请求,看是否命中:
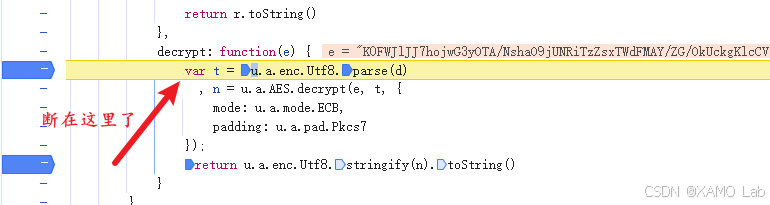
断点命中说明这里确实是解密入口。为了确认无误,做两重验证:
- 切到 Network 面板,对比该接口返回的密文,和断点处入参
e是否一致(一致则确认解密就发生在此处。对比时留意首尾空格、引号等,避免误判); - 在
return u.a.enc.Utf8.stringify(n).toString()处再下一个断点,F8 放行后在 Console 查看返回值是否就是页面上的新闻数据。
结果明显就是我们要的新闻列表,定位完成:
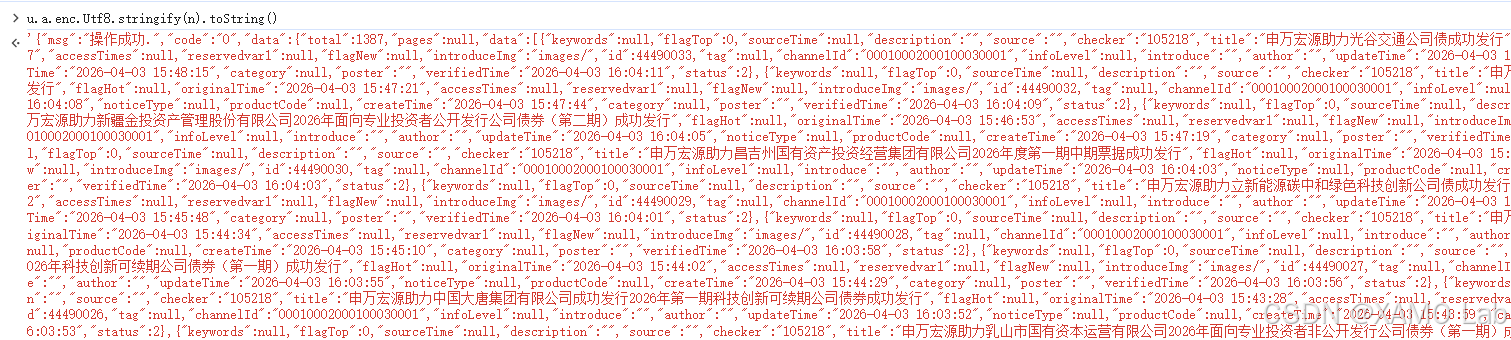
算法与密钥分析 :解密的算法参数已经很清楚了------AES / ECB / PKCS7 ,ECB 模式没有 IV,唯一的未知量就是密钥 d。
javascript
var t = u.a.enc.Utf8.parse(d)
, n = u.a.AES.decrypt(e, t, {
mode: u.a.mode.ECB,
padding: u.a.pad.Pkcs7
});
// 模式 ECB(无 IV)、填充 Pkcs7、密钥 = 字符串 d 的 UTF-8 字节
// 调试时直接在控制台打印 d,发现每次都是固定字符串 "rewin-swhysc1234"(16 字节,对应 AES-128)直接在断点处打印 d 就能拿到密钥 "rewin-swhysc1234",到这一步逆向其实已经可以收工。但 d 并不是明文写死的,而是用一段「类摩斯电码映射」拼出来的------顺手往上追溯一下它的来历,这也是本案例唯一有点意思的地方:
javascript
// p 是一张「码 → 字符」的映射表(形似摩斯电码,但映射关系是网站自定义的,并非标准摩斯)
p = new Map;
p.set("-.", "a"), p.set(".---", "b"), p.set(".-.-", "c"), p.set(".--", "d"),
p.set("--..", "e"), p.set("--.-", "f"), p.set("..-", "g"), p.set("----", "h"),
p.set("--", "i"), p.set("-...", "j"), p.set(".-.", "k"), p.set("-.--", "l"),
p.set("..", "m"), p.set(".-", "n"), p.set("...", "o"), p.set("-..-", "p"),
p.set("..-.", "q"), p.set("-.-", "r"), p.set("---", "s"), p.set(".", "t"),
p.set("--.", "u"), p.set("---.", "v"), p.set("-..", "w"), p.set(".--.", "x"),
p.set(".-..", "y"), p.set("..--", "z"),
p.set(".....", "0"), p.set("-....", "1"), p.set("--...", "2"), p.set("---..", "3"),
p.set("----.", "4"), p.set("-----", "5"), p.set(".----", "6"), p.set("..---", "7"),
p.set("...--", "8"), p.set("....-", "9");
// d:把下面这个码数组逐个查表,再拼接成最终的密钥字符串
var d = ["-.-", "--..", "-..", "--", ".-", "-", "---", "-..", "----", ".-..", "---", ".-.-", "-....", "--...", "---..", "----."]
.map(function(e) {
return p.get(e) || e // 查表命中则取映射字符;查不到(如单独的 "-")则原样保留该码
})
.join("");逐项还原这个映射过程,密钥就出来了(注意第 6 个码 "-" 不在表里,靠 p.get(e) || e 的兜底逻辑原样保留,正好充当中间的连字符):
text
"-.-"→r "--.."→e "-.."→w "--"→i ".-"→n "-"→-(兜底原样保留) "---"→s
"-.."→w "----"→h ".-.."→y "---"→s ".-.-"→c "-...."→1 "--..."→2 "---.."→3 "----."→4
拼接结果: r e w i n - s w h y s c 1 2 3 4 → "rewin-swhysc1234"和直接打印 d 得到的值完全一致,密钥确认无误。
结论:本站只做了响应加密,且是「标准 CryptoJS + 硬编码密钥」的最简形态,没有魔改、没有请求签名。汇总如下:
| 环节 | 结论 |
|---|---|
| 接口 | GET /swhy/service/wscms/v1/cms/infobaselist,参数 pageNum 翻页、channelId 定栏目 |
| 请求头 | 无特殊校验,仅需 User-Agent |
| 加密方向 | 仅响应加密(请求是明文 Query 参数) |
| 算法 | AES / ECB / PKCS7,密文为 Base64 |
| 密钥 | 固定字符串 "rewin-swhysc1234"(16 字节 AES-128),由自定义码表派生 |
| 解密入口 | app.js 中工具对象 f 的 f.decrypt(在 axios 响应拦截器中被调用) |
算法标准、无魔改,复现有两条路:直接引 CryptoJS 用 execjs 调用,或用 Python(pycryptodome)整段改写。下一节给出 Python 实现。
二、Python 实现
2.1 最小验证版(扣 JS / 纯 Python 两条路)
逆向到手后,第一步不是写框架,而是用最少的代码把「请求 → 解密 → 明文」这条链路跑通,确认密钥、模式、数据结构都对得上。算法是标准 CryptoJS、无魔改,两条复现路线都可行:扣 JS 用 execjs 调用,或纯 Python 改写。
路线一:扣 JS + execjs 调用 。把 decrypt 连同密钥 d 的派生逻辑原样搬到本地 swhysc.js,只需把 u.a 替换成本地引入的 CryptoJS:
javascript
p = new Map;
p.set("-.", "a"),
p.set(".---", "b"),
p.set(".-.-", "c"),
p.set(".--", "d"),
p.set("--..", "e"),
p.set("--.-", "f"),
p.set("..-", "g"),
p.set("----", "h"),
p.set("--", "i"),
p.set("-...", "j"),
p.set(".-.", "k"),
p.set("-.--", "l"),
p.set("..", "m"),
p.set(".-", "n"),
p.set("...", "o"),
p.set("-..-", "p"),
p.set("..-.", "q"),
p.set("-.-", "r"),
p.set("---", "s"),
p.set(".", "t"),
p.set("--.", "u"),
p.set("---.", "v"),
p.set("-..", "w"),
p.set(".--.", "x"),
p.set(".-..", "y"),
p.set("..--", "z"),
p.set(".....", "0"),
p.set("-....", "1"),
p.set("--...", "2"),
p.set("---..", "3"),
p.set("----.", "4"),
p.set("-----", "5"),
p.set(".----", "6"),
p.set("..---", "7"),
p.set("...--", "8"),
p.set("....-", "9");
var d = ["-.-", "--..", "-..", "--", ".-", "-", "---", "-..", "----", ".-..", "---", ".-.-", "-....", "--...", "---..", "----."].map((function (e) {
return p.get(e) || e
}
)).join("")
// console.log(d)
const CryptoJS = require('./CryptoJS')
function decryptRes(e) {
// u.a刚刚说了就是 CryptoJS
// var t = u.a.enc.Utf8.parse(d)
var t = CryptoJS.enc.Utf8.parse(d)
// , n = u.a.AES.decrypt(e, t, {
, n = CryptoJS.AES.decrypt(e, t, {
// mode: u.a.mode.ECB,
mode: CryptoJS.mode.ECB,
// padding: u.a.pad.Pkcs7
padding: CryptoJS.pad.Pkcs7
});
// return u.a.enc.Utf8.stringify(n).toString()
return CryptoJS.enc.Utf8.stringify(n).toString()
}
// 测试成功
console.log(decryptRes('K0FWJlJJ7hojwG3yOTA/NshaO9jUNRiTzZsxTWdF.....省略'));Python 端用 execjs 加载 swhysc.js 并调用 decryptRes:
python
# -*- coding: utf-8 -*-
"""
@File : swhysc.py
@Author : XAMO Lab
@Date : 2026/6/12 13:58
@Blog : https://blog.csdn.net/xw1680
@Tool : PyCharm
@Desc :
"""
import requests
import subprocess
from functools import partial
subprocess.Popen = partial(subprocess.Popen, encoding='utf-8')
import execjs
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'
' AppleWebKit/537.36 (KHTML, like Gecko) Chrome/149.0.0.0 Safari/537.36',
}
params = {
'topFlag': '3',
'pageSize': '10',
'status': '2',
'pageNum': '2',
'channelId': '00010002000100030001',
}
response = requests.get(
'https://www.swhysc.com/swhy/service/wscms/v1/cms/infobaselist',
params=params,
# cookies=cookies,
headers=headers,
)
print(response.text)
ctx = execjs.compile(open('./swhysc.js', 'r', encoding='utf-8').read())
result = ctx.call('decryptRes', response.text)
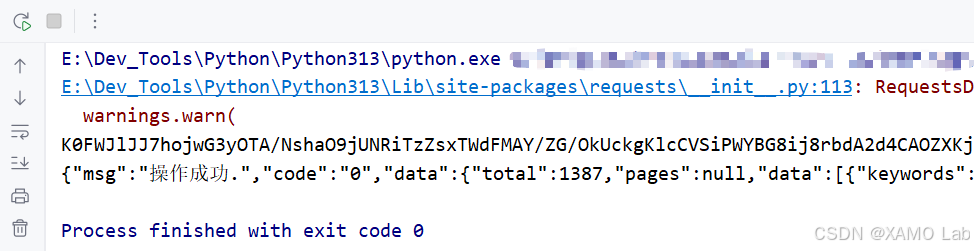
print(result)测试结果:

路线二:纯 Python(pycryptodome) 。既然确认是标准 AES/ECB/PKCS7、密钥也还原成了固定字符串,就没必要再带着 Node.js------直接用 pycryptodome 整段改写,密钥写死 rewin-swhysc1234 即可(省去码表派生那一步):
python
# 我省略了生成 d 的过程
# -*- coding: utf-8 -*-
"""
@File : swhysc_python_pure.py
@Author : XAMO Lab
@Date : 2026/6/12 15:40
@Blog : https://blog.csdn.net/xw1680
@Tool : PyCharm
@Desc :
"""
import base64
import requests
from Crypto.Cipher import AES
from Crypto.Util.Padding import unpad
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'
' AppleWebKit/537.36 (KHTML, like Gecko) Chrome/149.0.0.0 Safari/537.36',
}
params = {
'topFlag': '3',
'pageSize': '10',
'status': '2',
'pageNum': '2',
'channelId': '00010002000100030001',
}
response = requests.get(
'https://www.swhysc.com/swhy/service/wscms/v1/cms/infobaselist',
params=params,
# cookies=cookies,
headers=headers,
)
print(response.text)
aes = AES.new(key=b'rewin-swhysc1234', mode=AES.MODE_ECB)
print(unpad(aes.decrypt((base64.b64decode(response.content))), AES.block_size).decode('utf-8'))测试结果,一样能解密成功:
上面两段都只是验证「思路成立」的一次性脚本,直接拿来交付并不合适,问题很明显:
- 密钥、URL、栏目 ID、请求头全是散落的魔法值,换个栏目就得改源码;
- 只解密、不提取------还没把标题、发布时间、详情链接结构化出来;
- 没有异常处理,某页超时或返回非 0 code 直接崩;
print调试、串行请求,跑批时既慢又无法追溯。
2.2 封装版(OOP + 多线程 + loguru 日志)
把逻辑收敛成一个类:配置项集中管理、解密独立成方法、ThreadPoolExecutor 并发翻页、loguru 做分级日志和异常追踪,并完成字段提取(标题 / 发布时间 / 详情链接)。换栏目只改 channel_id,换页数只改 pages。
python
# -*- coding: utf-8 -*-
"""
@File : swhysc_news_spider.py
@Author : XAMO Lab
@Date : 2026/6/12 16:19
@Blog : https://blog.csdn.net/xw1680
@Tool : PyCharm
@Desc :
"""
"""申万宏源证券新闻中心采集(AES/ECB 响应解密 + 多线程)
接口: GET https://www.swhysc.com/swhy/service/wscms/v1/cms/infobaselist
响应: Base64 密文,AES-128 / ECB / PKCS7,密钥固定为 "rewin-swhysc1234"
(密钥在 app.js 中由自定义码表派生得到,运行时恒定,这里直接写死)
"""
import base64
import json
from concurrent.futures import ThreadPoolExecutor, as_completed
from typing import Any, Dict, List
import requests
from Crypto.Cipher import AES
from Crypto.Util.Padding import unpad
from loguru import logger
class SwhyscNewsSpider:
"""申万宏源证券新闻中心爬虫"""
API_URL = "https://www.swhysc.com/swhy/service/wscms/v1/cms/infobaselist"
DETAIL_PREFIX = "https://www.swhysc.com/swhysc/news/company/detail/"
AES_KEY = b"rewin-swhysc1234" # 逆向得到的固定密钥(AES-128)
def __init__(self, channel_id: str = "00010002000100030001",
page_size: int = 10, max_workers: int = 3) -> None:
"""
:param channel_id: 栏目频道 ID,默认公司新闻;换板块只需替换此值
:param page_size: 每页条数
:param max_workers: 并发线程数
"""
self.channel_id = channel_id
self.page_size = page_size
self.max_workers = max_workers
self.session = requests.Session()
# 实测服务端无特殊请求头校验,仅需 User-Agent
self.session.headers.update({
"User-Agent": (
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/149.0.0.0 Safari/537.36"
),
})
def _decrypt(self, ciphertext: str) -> Dict[str, Any]:
"""AES/ECB/PKCS7 解密响应(Base64 密文)→ dict"""
raw = base64.b64decode(ciphertext)
plaintext = unpad(AES.new(self.AES_KEY, AES.MODE_ECB).decrypt(raw), AES.block_size)
return json.loads(plaintext.decode("utf-8"))
def fetch_page(self, page: int) -> List[Dict[str, str]]:
"""请求单页并解密,返回结构化新闻列表"""
params = {
"topFlag": 3,
"pageSize": self.page_size,
"status": 2,
"pageNum": page,
"channelId": self.channel_id,
}
resp = self.session.get(self.API_URL, params=params, timeout=15)
resp.raise_for_status()
result = self._decrypt(resp.text)
# 接口约定:code == "0" 为成功(注意是字符串 "0",失败时形如 "-0801000")
if str(result.get("code")) != "0":
logger.warning("page={} 接口异常 code={} msg={}",
page, result.get("code"), result.get("msg"))
return []
rows = result.get("data", {}).get("data", []) # 列表在 data.data 里
news_list = [
{
"title": item.get("title"),
"publish_time": item.get("originalTime"), # 页面展示的发布时间
"url": self.DETAIL_PREFIX + str(item.get("id")), # 用 id 拼详情页
}
for item in rows
]
logger.success("page={} 解密成功,获取 {} 条新闻", page, len(news_list))
return news_list
def run(self, pages: int = 3) -> List[Dict[str, str]]:
"""并发采集前 pages 页"""
logger.info("开始采集 | 栏目={} | 共 {} 页 | 并发 {}",
self.channel_id, pages, self.max_workers)
all_news: List[Dict[str, str]] = []
with ThreadPoolExecutor(max_workers=self.max_workers) as executor:
future_map = {executor.submit(self.fetch_page, p): p for p in range(1, pages + 1)}
for future in as_completed(future_map):
page = future_map[future]
try:
all_news.extend(future.result())
except Exception as exc: # 单页异常隔离,不影响其他页
logger.error("page={} 请求失败: {}", page, exc)
logger.info("采集完成,共 {} 条", len(all_news))
return all_news
if __name__ == "__main__":
spider = SwhyscNewsSpider()
news = spider.run(pages=3)
for idx, item in enumerate(news, 1):
logger.info("[{}] {} | {} | {}",
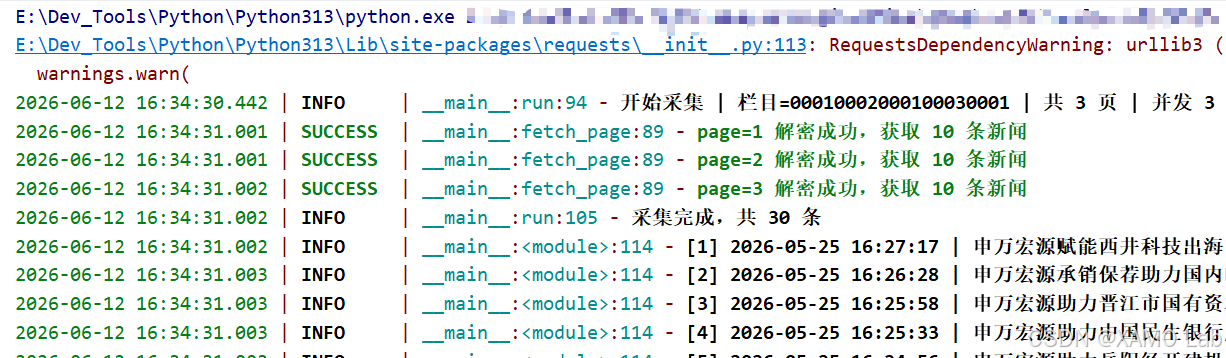
idx, item["publish_time"], item["title"], item["url"])运行效果(loguru 自带彩色分级日志 + 结构化结果):
封装版相比验证版的改进点:
| 维度 | 验证版(9.2.1) | 封装版(9.2.2) |
|---|---|---|
| 配置 | 魔法值散落各处 | 集中为类属性 / 构造参数,换栏目改一处 |
| 解密 | 裸函数 | 独立 _decrypt 方法,职责单一 |
| 提取 | 只打印整段明文 | 结构化为 标题 / 发布时间 / 详情链接 |
| 并发 | 串行单页 | ThreadPoolExecutor 并发翻页 |
| 日志 | print |
loguru 分级日志(INFO/SUCCESS/WARNING/ERROR),自带定位与时间戳 |
| 健壮性 | 出错即崩 | raise_for_status + code 校验 + 单页异常隔离,不影响其他页 |
关于 originalTime 字段 :解密后每条记录有 originalTime、createTime、updateTime、verifiedTime 等多个时间。originalTime 对应页面展示的「发布时间」,故取它;需要其他口径换字段即可。关于并发数 :申万宏源是券商官网,max_workers=3 偏保守。前 3 页只有 3 个请求,并发收益不明显;但采集页数多(几十页)时能显著缩短总耗时。无论如何不建议开太高,避免给目标站点造成压力。
三、总结
| 环节 | 要点 |
|---|---|
| 抓包 | GET 请求,响应体为 Base64 密文;请求头无校验,仅需 User-Agent |
| 定位 | 全局搜 decrypt 直接命中工具对象 f,比 Hook JSON.parse 噪声小 |
| 算法 | AES / ECB / PKCS7,密文 Base64(CryptoJS 收字符串默认按 Base64 解析) |
| 密钥 | 固定 "rewin-swhysc1234",由自定义码表(`p.get(e) |
| 复现 | 标准 CryptoJS 无魔改,pycryptodome 直接还原;AES.MODE_ECB 无需 IV |
| 翻页 | pageNum 控制页码,channelId 控制栏目,二者解耦 |
本案例的核心收获:
- ECB 模式是对称加密里最简单的形态------没有 IV,密钥即全部。看到
mode.ECB时,Python 端AES.new(key, AES.MODE_ECB)不要传 IV。 - 密钥即使经过「码表派生 / 字符变换」等花样包装,只要它在运行时是确定值,直接在断点处打印拿到结果即可,不必死磕派生过程;但理解派生逻辑能帮你判断它会不会动态变化。
- 业务体量大的站点优先搜
decrypt/AES等关键字定位,比 HookJSON.parse精准;后者更适合搜不到关键字、或函数名被混淆的场景。 - 逆向脚本和交付代码是两个阶段:先用最小脚本验证结论,再封装成带配置、日志、并发、异常处理的可维护版本。