AI Infra 的知识点------K8s 调度、GPU 切分、RDMA、大模型并行、Go 底层------单独看都很零散,背完就忘。但它们其实围绕同一个真实目标在协同:给你 1000 张 A100,搭一个让全公司算法团队都能用、还要把利用率榨干的算力调度平台。本文以这个项目为主线,把这些技术从孤立的名词,还原成解决具体业务痛点的工具,最终拼成一张完整的架构地图。
项目目标:把上亿的显卡变成能用的平台
这样一个平台之所以难,在于它横跨三个陡峭的技术栈,且每一层都要深入到源码级:极深的 K8s 架构功底(手写 CRD、定制调度器、玩转 Volcano/Kueue)、硬核的底层硬件与网络(MIG、显存隔离、RDMA、InfiniBand),以及前沿的大模型训练框架(DeepSpeed、Megatron 的 3D 并行通信逻辑)。
把这三层落到工程实践上,整个平台的搭建可以拆成四场环环相扣的战役:算力切分、跨卡通信、集群大脑、调度器底盘。下面逐一拆解每一层要解决的业务痛点,以及背后的关键技术。
战役一:算力池化与切分------把昂贵的 GPU 掰碎了卖
痛点:原生 Kubernetes 的调度器有"整数强迫症"。在它眼里 GPU 要么给 1 整张、要么不给,绝不能给 0.5 张。可现实是:团队 A 做数据预处理用不上整卡,团队 B 做推理只要 2GB 显存。按整卡分配,几千万的算力就这么躺着浪费,利用率常年趴在 30%。
破局的基础设施 是 Device Plugin。每台 GPU 机器上以 DaemonSet 跑一个插件,通过宿主机的 UNIX Socket 建立 gRPC,向 Kubelet 注册并"上报军情"。官方插件只会说"我这台有 8 个 nvidia.com/gpu";而增强版(如 HAMi)会把一张 80GB 的 A100 虚拟成 nvidia.com/gpumem(按 MB 计的显存)和 nvidia.com/gpucores(按 % 计的算力)两种全新的扩展资源。有了它,调度器才认得带细粒度请求的 Pod。
接下来,针对不同业务线,有三套切分组合拳:
| 方案 | 隔离层级 | 核心原理 | 显存隔离 | 切分灵活度 | 适用场景 |
|---|---|---|---|---|---|
| Time-Slicing | 进程级(软) | CUDA Context 时间片轮转 | ❌ 无 | 按副本数 | 测试/调试,能用就行 |
| HAMi | 用户态 API 劫持 | LD_PRELOAD 替换 libcuda.so |
✅ 有 | 极细(可到 0.5GB) | 高性价比线上推理 |
| MIG | 硬件物理切分 | 硅片层切 SM/L2/显存通道 | ✅✅ 物理隔离 | 死板(固定 Profile) | VIP 核心链路 |
三者各有取舍。
- Time-Slicing 最易部署,老卡也能用,但零显存隔离------一个 Pod 内存泄漏(OOM),同卡的邻居会被一波带走(连坐),且上下文切换带来不可控的尾延迟,绝不能用于实时推理。
- HAMi 的魔法在于"善意的谎言":它在容器启动前把底层
libcuda.so换成代理库,当 PyTorch 喊"我要 5GB 显存"时被拦截,HAMi 一查配额只有 2GB,就冷酷地返回 OOM------尽管物理卡上还剩几十 GB。它实现了不错的显存隔离,且对业务代码 100% 透明。- MIG 是 Ampere(A100/H100)专属的纯硬件切割,把一颗 GPU 物理切成最多 7 个独立小实例,每个有专属 SM、L2 缓存和显存带宽,隔离最彻底,但切分规格锁死、改切分必须重置整张卡甚至重启机器。
一个高频混淆:HAMi、NVIDIA vGPU、MIG 到底什么关系
业内常把所有 GPU 虚拟化统称 "vGPU",导致概念极其混乱。一句话区分:HAMi 是在软件应用层"骗"程序,NVIDIA vGPU 是在系统底层"物理切"设备,MIG 是在硅片层"切芯片"。
| 维度 | HAMi(开源 API 劫持) | NVIDIA vGPU(商业) | MIG(硬件实例) |
|---|---|---|---|
| 工作位置 | 用户态,贴着容器 | 内核态 / Hypervisor | 硅片硬件层 |
| 实现 | 劫持 libcuda.so |
SR-IOV / mdev 虚拟出 PCIe 设备 | 物理切分芯片资源 |
| 隔离 | 中(软) | 极高(硬,VM 级) | 极高(硬,实例级) |
| 切分粒度 | 极灵活,任意小数 | 按官方 Profile | 死板,固定档位 |
| 平台 | 天生为 K8s/容器 | 天生为虚拟机 | 裸金属/容器 |
| 成本 | 免费开源 | 昂贵 License + 买卡 | 仅限 A100+ 新卡 |
| 驱动 | 宿主机装一次 | 宿主机 + Guest 都要装 | 宿主机装一次 |
选型上:公有云厂商要把卡切给互不信任的租户、或要跑云桌面(VDI),就得花大价钱上 NVIDIA vGPU(虚拟机级强隔离 + 防侧信道);企业内部智算中心、大家有基本互信,用 HAMi 即可,还能切出 vGPU 切不出来的 0.5GB 粒度;要绝对零延迟抖动的核心推理,直接上 MIG。值得一提的是,Ampere 之后 NVIDIA 也把两者融合了------可以先用 MIG 切硬件、再用 vGPU 透传给虚拟机,达到安全与性能隔离的巅峰。
架构师的最终交付 不是让业务团队去懂这些,而是在 K8s 前加一层 Mutating Admission Webhook 做"隐形调度":检测到 env: testing 自动调度到 Time-Slicing 节点池;type: inference 且显存 < 40GB 自动改写 YAML 进 HAMi 池;priority: vip 进 MIG 专属池。利用率就能从 30% 飙到 80% 以上。
战役二:跨卡通信------不让几亿的显卡在等网络
痛点:底层卡切得再好,模型太大一张装不下时,就要千卡联动。而卡与卡之间的网络一旦成了"堵车的老城区",你买的 A100 全在发呆等数据,算力直接归零。这就是"通信墙"。
大模型训练靠 3D 并行:节点内做张量并行(TP) ------把一个超大矩阵乘法切开给多卡同算,每算完一层就要在几微秒内互换数据;节点间做流水线并行(PP)和数据并行(DP)。其中最频繁、最苛刻的是 TP 的集合通信(AllReduce)。
如果用传统 TCP/IP,会上演一场灾难:节点 A 的 GPU 想发 1GB 梯度给节点 B 的 GPU,数据路线是------A 的显存 → 拷到 A 的 CPU 内存 → CPU 陷入内核态塞进 TCP/IP 协议栈 → 拷到网卡 → 上网络 → B 网卡 → 拷到 B 的 CPU 内存 → CPU 解析协议 → 拷到 B 的显存。数据被疯狂拷贝六七次,CPU 累瘫,上下文切换频繁,延迟高达毫秒级。
进化路线分三级:
- RDMA(远程直接内存访问) :思路极其暴力------直接干掉 CPU 和内核。网卡自带硬件网络引擎,可隔空读写远端机器的内存,全程不需要对端 CPU 参与,实现零拷贝,延迟降到微秒级。主流的 RoCE v2 把 InfiniBand 传输层封装进 UDP/IP,跑在标准以太网上,性价比极高。但以太网天生"尽力而为"会丢包,而 RDMA 对丢包极敏感,所以必须配 PFC(基于优先级的流控)+ ECN(显式拥塞通知) 打造"无损以太网"。顺带破一个常见误区:RDMA 并非只能跑在专用 InfiniBand 上,RoCE/iWARP 让标准以太网也能享受它。
- GPUDirect RDMA(GDR):普通 RDMA 虽绕开 CPU,但数据仍要去主板内存中转一趟。GDR 通过底层 PCIe Switch 直接架桥,让网卡跨过 PCIe 总线直接读写 GPU 显存,100% 绕开两台机器的 CPU 和主板内存。这是 NCCL 能跑出几百 GB/s 带宽的绝对基石。
分布式训练数据传输比较
物理层:PCIe / NVLink / NVSwitch / InfiniBand 各管一段
记住一个空间概念:前三个解决"机箱内"通信,最后一个解决"跨机箱"通信。
| 技术 | 位置 | 带宽量级 | 什么时候用 |
|---|---|---|---|
| PCIe | 主板插槽 | ~64 GB/s | CPU↔GPU 下发指令;低成本单卡推理 |
| NVLink | 显卡间桥接器 | ~600 GB/s | 单机 2--4 卡点对点高速互联 |
| NVSwitch | HGX 基板交换芯片 | 全互联 | 单机 8 卡,专为张量并行(TP) |
| InfiniBand | 机箱外网卡+交换机 | 200G≈25 GB/s | 跨节点,用于 DP/PP,支持 GDR |
NVLink 是点对点的:2 卡一条线,4 卡两两互连要 6 条线,8 卡要 28 条------主板根本布不下。所以 8 卡服务器(如 DGX)改用 NVSwitch,8 张卡全连到交换芯片上,彼此就像一张 640GB 显存的"超级巨型 GPU"。这也解释了为什么 TP 只能在单机 8 卡内做:它通信太频繁、对延迟零容忍,只有 NVSwitch 锁死的节点内部扛得住;强行跨节点,缓慢的 IB 带宽会让效率断崖式下跌。而 DP/PP 对延迟容忍度高一点,可以走 InfiniBand 出机箱。
Ring AllReduce:为什么敢堆万卡
数据并行的梯度同步靠 Ring AllReduce。它的天才之处用一个公式就能看懂。设单卡待同步数据量为 SS S、卡数为 NN N,算法分两阶段,每阶段单卡收发的数据量恰好都是:
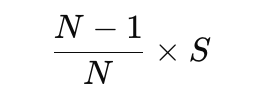
Scatter-Reduce 阶段 :把 S 切成 NN 份(每份 S/N),每张卡只负责算出其中一块的最终和。为收集齐这一块,需要在环里传 N−1 步,每步只向右邻居发一个分块,于是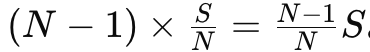 。
。
All-Gather 阶段 :此时每张卡手里有一块完美结果,再顺时针传遍全网,同样 N−1 步,数据量同为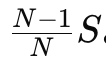 。
。
两阶段相加,单卡总通信量为:
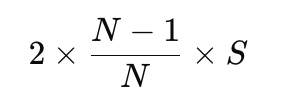
关键来了:当 N极大(比如一万张卡),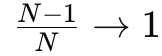 ,单卡总通信量 ≈2S,永远趋近固定值,绝不随卡数膨胀。这就是大模型敢于疯狂堆 GPU 的底层通信支撑。
,单卡总通信量 ≈2S,永远趋近固定值,绝不随卡数膨胀。这就是大模型敢于疯狂堆 GPU 的底层通信支撑。
AllReduce 与 AllGather 分别什么时候触发
- AllReduce ------ 反向传播末尾(代号:年底对账) 。DDP 中 8 张卡模型相同、数据不同,各自算出局部梯度后,必须在
loss.backward()末尾把梯度求平均再发回每张卡,保证下一步更新后模型完全一致。 - AllGather ------ 前向/反向开始的瞬间(代号:拼图游戏)。FSDP/ZeRO-3 中每张卡只存 1/N1/N 1/N 的参数省显存,但前向计算时手里权重不全,于是触发 AllGather 把碎片拼成完整层,算完立刻把借来的权重当垃圾扔掉(以通信换显存)。TP 中跨卡矩阵乘法算出的是残缺激活向量,也要靠 AllGather 拼接成完整向量给下一层。
更高阶的考量是计算与通信重叠(Overlap):反向传播从最后一层倒着算回第一层,当某层梯度刚算完就在后台立即触发 AllReduce,前台 GPU 毫不等待地继续算上一层。把通信时间藏到计算背后,才能把算力利用率(MFU)拉满------这正是衡量一个训练平台"吞吐与计算效率"是否到位的核心指标。
战役三:集群大脑------教 K8s 认识 AI 任务并管好资源
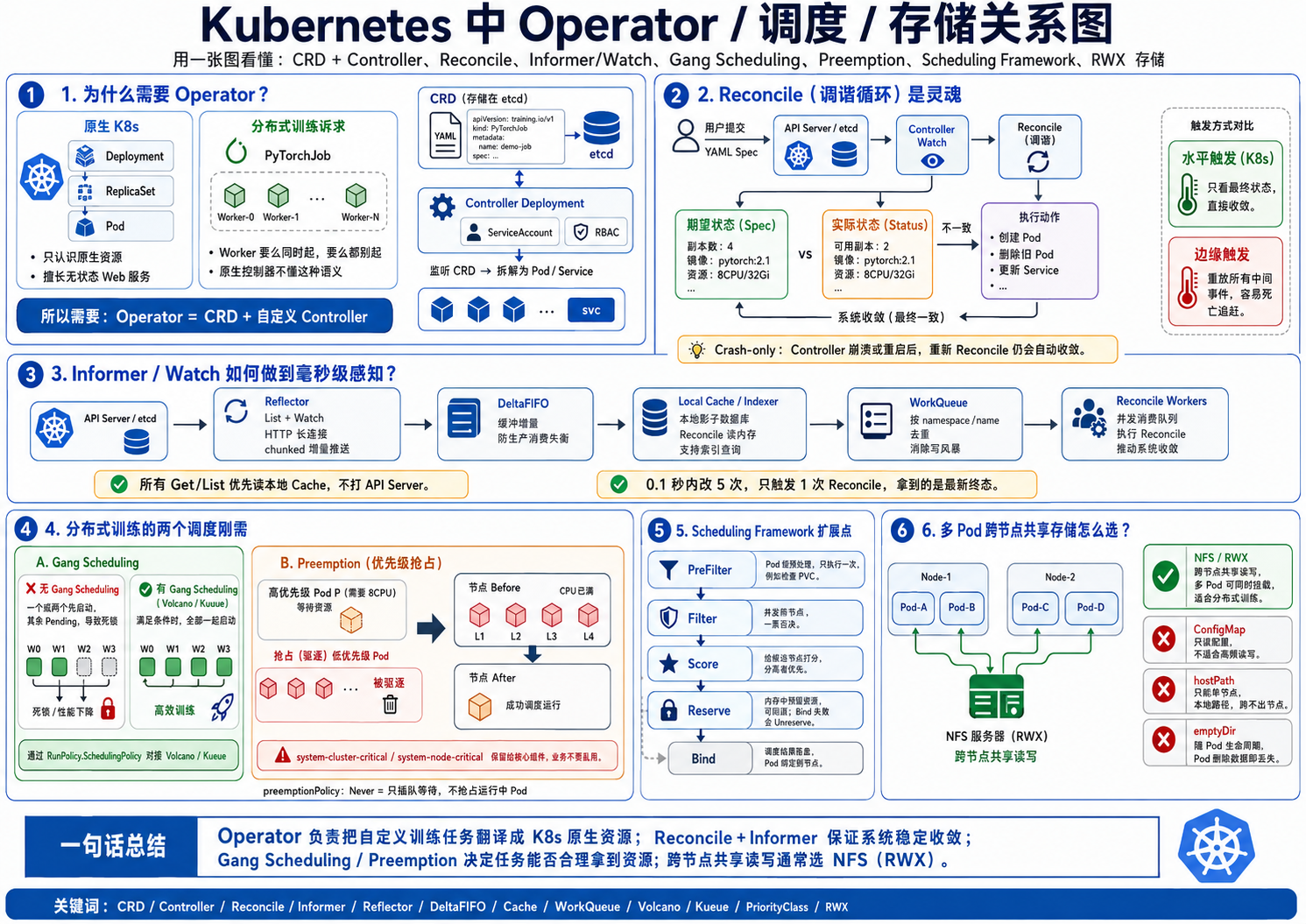
原生 K8s 只认识 Deployment 这种无状态 web 服务,根本不懂"PyTorchJob 要么所有 Worker 同时起、要么一个都别起"的诉求。要补齐这块,核心是 Operator 模式 = CRD + 自定义 Controller。
为什么必须自己写 Operator? 内置的 kube-controller-manager 只管原生资源(Deployment、ReplicaSet 等),完全不认识你自定义的 CRD。你提交的 PyTorchJob 如果没有对应 Operator,就只是躺在 etcd 里的一段死数据。你必须把 Controller 打包成镜像、以 Deployment 部署在集群内,配一个 ServiceAccount 并用 RBAC 精确授权,让它去监听并把 CRD 拆解成底层真正的 Pod 和 Service。
Reconcile 循环(调谐循环)是灵魂。K8s 是声明式的:你提交 YAML 声明"我期望永远有 3 个 Pod",至于怎么创建、中途死了怎么办,全交给 Controller。它通过长连接 Watch 监听变化,一旦发现资源变动,就对比"期望状态(Spec)"和"实际状态(Status)",不一致就执行动作(拉新 Pod / 删旧 Pod),不断逼近期望。
这里有个理解 K8s 为何如此稳健的终极密码------水平触发(Level Triggering)vs 边缘触发(Edge Triggering)。打个比方:你在地铁里反复改空调温度 26→20→28→24。边缘触发像录音机,网络一恢复就疯狂复现这一串过程;水平触发像理性的温控器,只看你的最终设定(24 度)和房间现状(30 度),中间你按了多少次它根本不在乎,直接制冷到 24。
所以断网半小时丢了一万个事件,K8s 是真的直接略过 ,只根据恢复那一刻的最新期望和最新实际来动作,只保证最终一致性。这避免了"死亡追赶"------如果非要按顺序处理积压的一万个事件,控制器会疯狂创建/删除 Pod 把 CPU 打满,而用户早就不要这些中间状态了。(补充:那一万次修改并非连渣不剩,它们作为短生命周期的 K8s Events 留在 etcd 里,可用 kubectl get events 审计,但绝不影响控制环。)这正是"面向崩溃设计(Crash-only)"的基石:Operator 无论在哪崩、重启多少次,重跑一次 Reconcile 系统就自动收敛。
Informer/Watch:毫秒级感知而不打挂 ETCD。如果每个控制器都每秒轮询一次 API Server,几万 Pod 的集群里 etcd 三秒就被打挂。client-go 的 Informer 用四大组件解决了这个分布式难题:
- Reflector(List-Watch) :启动先 List 拉全量,然后发起带
?watch=true的 HTTP 请求。它利用 HTTP/1.1 的 Chunked 分块传输,TCP 连接建好后永不挂断,etcd 一有变化就顺着长连接把增量 Push 过来------没有建连延迟的纯异步推送,这是毫秒级感知的根本。 - DeltaFIFO:增量缓冲队列,解决生产/消费速率不匹配,防内存溢出。
- Local Cache(Indexer) :进程内维护一份与 etcd 一致的"影子数据库"。你在 Reconcile 里调的所有
Get()/List()100% 读本地内存,不发任何网络请求------这就是几万 Operator 狂读、API Server 稳如老狗的原因(消除读风暴)。 - WorkQueue :0.1 秒内某 Pod 被改 5 次,不会触发 5 次 Reconcile;队列只放它的
namespace/name并去重,Reconcile 拿到 key 去 Cache 查到的永远是最新终态(消除写风暴)。
两个调度刚需 :分布式训练必须 Gang Scheduling(协同调度) ,确保所有 Worker"同生共死"防死锁------通过 CRD 的 RunPolicy.SchedulingPolicy 对接 Volcano/Kueue 实现。资源紧张时靠 Preemption(优先级抢占) :高优先级 Pod 调度失败会驱逐节点上的低优先级 Pod 腾资源。PriorityClass 是集群级(非命名空间)资源,核心字段 value 是 int32,越大越优先;system-cluster-critical/system-node-critical 是保留给 CoreDNS、kube-proxy 等系统组件的,业务千万别乱用 ,否则资源紧张时你的业务可能把集群核心组件杀掉、同归于尽。若配 preemptionPolicy: Never,则高优先级 Pod 只在队列里插队等待,绝不抢占正在运行的低优先级 Pod。
调度框架(Scheduling Framework)的四个扩展点 决定了自定义调度逻辑能插在哪里:PreFilter(Pod 级预处理,一个调度周期只执行一次,如检查 PVC 是否存在)→ Filter(并发执行,节点间独立,一票否决式踢掉不满足的节点)→ Score(给候选节点打分,分数越高越优 )→ Reserve(内存里预留资源防超卖,绝对可回滚 ,后续 Bind 失败会调 Unreserve 退还)。
存储 上,多 Pod 跨节点共享读写(RWX / ReadWriteMany)只能用 NFS :ConfigMap 是只读配置不能当存储卷高频读写;hostPath 跨不出单节点;emptyDir 生命周期与单 Pod 绑定、Pod 一删数据就清空。
战役四:调度器自身的底盘------Go 与存储
这套高并发调度器通常用 Go 手写,几万 Pod 状态疯狂变化,控制面不能卡顿。Go 的 GPM 模型 :G 是协程、M 是 OS 线程、P 是逻辑处理器(默认数量等于 GOMAXPROCS),只有 M 绑定 P 才能执行 G。两个机制保证它高效:Work Stealing ------P 把本地队列(最多 256 个 G)跑空后,会先从全局队列拿、再去别的 P 队列"偷"一半,保证多核负载均衡;Handoff ------某 M 执行的 G 陷入系统调用阻塞时,runtime 会把 P 从它身上剥离、唤醒或新建一个 M 接管,避免该 P 上其他 G 饿死。这里破一个常见错误:Go 的协程栈不是固定 8KB,而是从 2KB 起的可伸缩连续栈,递归过深会自动扩容(拷贝旧栈到两倍大的新内存),因此远不像 C/Java 固定栈那样容易溢出。

Channel 的"三崩"安全规则 要刻进 DNA:关闭 nil channel 会 panic;重复关闭已关闭的 channel 会 panic;向已关闭的 channel 发送数据会 panic。而从已关闭的 channel 读取不会 panic,会立即返回零值且第二个返回值 ok 为 false------这正是判断 channel 是否关闭的标准做法。
Context 是程序的神经系统 :context.Background() 和 context.TODO() 底层都是 emptyCtx,无值、无超时、永不取消,是所有链路的根;取消信号向下传播 ,父 Context 一取消,派生的所有子 Context 连锁取消,这是治理 goroutine 泄漏的终极武器;WithTimeout 后必须紧跟 defer cancel(),否则定时器资源会驻留内存造成泄漏;WithValue 只该传请求级元数据 (TraceID、Token),不能传订单号等核心业务参数------因为它收 interface{}、废掉了编译期类型安全、造成隐式依赖且断言失败会 panic,业务参数老老实实写进函数签名。
尾声:数据的一次奇妙旅行
把所有知识点串起来,想象你在千卡集群上跑一个千亿参数的 Megatron 模型:
- 准备(PCIe):K8s 调度器下发指令,CPU 将初始权重经 PCIe 塞进显存。
- 切分(HAMi):若切一小块做推理,HAMi 在底层骗过 CUDA。
- 节点内狂奔(NVLink/NVSwitch):做核心矩阵乘法切块(TP)时,8 张卡经 NVSwitch 疯狂交换数据,快到彼此像一张 640GB 的超级 GPU。
- 跨节点同步(InfiniBand/RDMA):单机算完一部分,需和几十米外机柜里的机器同步梯度(DP)。网卡经 PCIe 直接探进显存拿数据,转成光信号,通过 InfiniBand 和 Ring AllReduce 瞬间传遍数据中心。
把这条旅行链路在脑海里走通------从 PCIe 到 HAMi、从 NVLink/NVSwitch 到 InfiniBand/RDMA------你就握住了整个智算中心调度的完整心智模型。它的价值不在于记住某个孤立的名词,而在于能画出这台机房的物理布线图和数据流向图,并清楚每一项技术分别在解决"算力浪费、通信瓶颈、调度失控、底盘卡顿"中的哪一个问题。当这四层在脑子里连成一个闭环,那些原本零散的黑话,就成了你设计系统时随手就能调用的积木。
这套知识体系需要时间沉淀,而最务实的落地路径,是把文中反复出现的 HAMi、Volcano 这些完全开源的项目克隆下来,先在自己的环境里搭起来跑通,再去读源码。当你亲手把一张物理卡切给多个 Pod、亲眼看到 Reconcile 循环如何死死咬住期望状态不放,这些原理才会真正长进你的技术体系里,而不是停留在文档的字面上。