本篇目标 :理解 Linux 为什么要把物理内存划分为不同的 zone,zone 如何参与 buddy allocator、GFP 分配、NUMA fallback、内存回收和热插拔,以及
ZONE_DMA、ZONE_NORMAL、ZONE_MOVABLE、ZONE_DEVICE等 zone 分别解决什么问题。
1. 问题背景:物理内存并不完全等价
从最朴素的视角看,物理内存似乎只是一段连续的 PFN:
text
PFN 0 ............................... max_pfn如果所有硬件都能访问所有物理地址,所有内核代码都能直接读写所有页面,所有页面都能自由迁移和释放,那么内核只需要一个全局空闲页池就够了。
但真实系统不是这样。
Linux 需要同时处理几类约束:
| 约束 | 典型问题 |
|---|---|
| DMA 地址能力 | 老设备只能 DMA 到低地址内存,不能访问全部 RAM |
| CPU 直接映射能力 | 32-bit 内核线性映射空间有限,不能永久映射所有高端内存 |
| 内存热插拔 | 要提高 memory offline 成功率,避免不可迁移页散落各处 |
| 大页和连续内存 | THP、HugeTLB、CMA 需要减少外部碎片 |
| 设备内存 | GPU VRAM、DAX、P2PDMA 需要 struct page,但不是普通 RAM |
| NUMA 拓扑 | 本地节点优先,必要时再跨节点 fallback |
这些约束有一个共同点:不是所有 page 都能被所有使用者等价地消费。
Linux zone 体系就是为了解决这个问题:
zone 是在一个 NUMA node 内部,按硬件可达性、内核映射能力和使用策略划分出来的物理页集合。
它不是虚拟地址空间概念,也不是进程级概念,而是 page allocator 管理物理页时的一层约束边界。
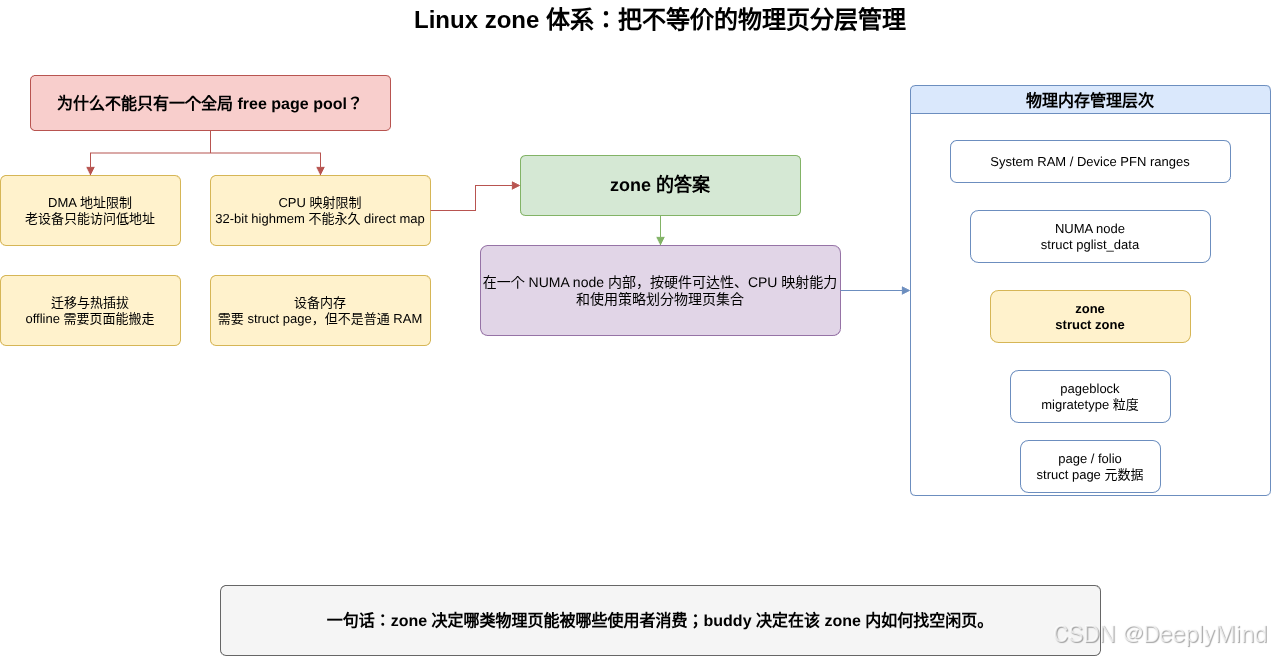
2. zone 在整体内存模型中的位置
Linux 的物理内存管理大致有三层:
text
系统物理内存
-> NUMA node / pgdat
-> zone
-> pageblock
-> page / folio对应到核心数据结构:
text
pglist_data // 一个 NUMA node
node_zones[] // 该 node 内的各个 zone
struct zone // DMA / NORMAL / MOVABLE / DEVICE ...
free_area[] // buddy allocator 的空闲链表
struct page // 具体物理页struct pglist_data 描述一个 NUMA 节点,struct zone 描述这个节点内部某一类物理页。也就是说,zone 不是全局唯一的一段内存,而是每个 node 都可能有一组 zone:
text
Node 0
ZONE_DMA
ZONE_DMA32
ZONE_NORMAL
ZONE_MOVABLE
Node 1
ZONE_NORMAL
ZONE_MOVABLE分配页面时,内核通常先确定 node,再确定最高可接受的 zone,然后在 zonelist 中按顺序尝试分配。
3. enum zone_type:zone 类型的源码定义
zone 类型定义在 include/linux/mmzone.h:
c
enum zone_type {
#ifdef CONFIG_ZONE_DMA
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
ZONE_DMA32,
#endif
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
#ifdef CONFIG_ZONE_DEVICE
ZONE_DEVICE,
#endif
__MAX_NR_ZONES
};这些 zone 不是所有架构都会同时存在。它们受 Kconfig、体系结构和内存布局共同影响。
| Zone | 是否常见 | 核心用途 |
|---|---|---|
ZONE_DMA |
依架构而定 | 给只能访问很低物理地址的 DMA 设备使用 |
ZONE_DMA32 |
64-bit 系统常见 | 给 32-bit DMA mask 设备使用,通常覆盖 4GB 以下内存 |
ZONE_NORMAL |
最核心 | 普通可直接映射 RAM,内核主要分配来源 |
ZONE_HIGHMEM |
32-bit 时代常见 | CPU 不能永久直接映射的高端内存 |
ZONE_MOVABLE |
热插拔/反碎片场景 | 尽量只放可迁移页,便于 offline 和 compaction |
ZONE_DEVICE |
HMM/DAX/P2PDMA | 为设备物理地址提供 struct page 服务 |
这里最重要的不是记住名字,而是理解分类标准:
text
ZONE_DMA / DMA32 -> 设备 DMA 地址可达性
ZONE_NORMAL -> 普通内核可直接使用 RAM
ZONE_HIGHMEM -> CPU 内核虚拟地址映射能力
ZONE_MOVABLE -> 页面迁移和热插拔策略
ZONE_DEVICE -> 设备内存的 page 元数据服务4. struct zone:zone 管理什么
struct zone 也定义在 include/linux/mmzone.h。它不是只保存一个起止 PFN,而是 page allocator、回收、压缩、统计共同使用的管理对象。
几个关键字段可以这样理解:
c
struct zone {
unsigned long _watermark[NR_WMARK];
long lowmem_reserve[MAX_NR_ZONES];
struct pglist_data *zone_pgdat;
struct per_cpu_pages __percpu *per_cpu_pageset;
unsigned long zone_start_pfn;
atomic_long_t managed_pages;
unsigned long spanned_pages;
unsigned long present_pages;
const char *name;
struct free_area free_area[NR_PAGE_ORDERS];
spinlock_t lock;
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
};可以把它分成几类职责:
| 字段 | 作用 |
|---|---|
zone_start_pfn |
zone 覆盖的起始 PFN |
spanned_pages |
zone 跨越的 PFN 数量,包含 holes |
present_pages |
实际存在的物理页数量 |
managed_pages |
buddy allocator 真正管理的页数 |
free_area[] |
buddy 各 order 的空闲链表 |
_watermark[] |
分配水位线,控制何时唤醒回收/拒绝分配 |
lowmem_reserve[] |
防止高端分配耗尽低端关键 zone |
per_cpu_pageset |
每 CPU 页缓存,减少频繁加 zone lock |
vm_stat[] |
zone 级统计,比如空闲页、活动页、回收状态 |
三个 page 数量容易混淆:
text
spanned_pages = zone 覆盖的 PFN 范围,可能包含洞
present_pages = 真正存在的物理页
managed_pages = present_pages 中交给 buddy 管理的页对普通 RAM zone 来说,managed_pages 是 page allocator 最关心的数;对 ZONE_DEVICE 来说,有 struct page 并不等于进入 buddy,因此不能简单把 present 理解为 allocatable。
5. buddy allocator 如何嵌在 zone 里
Linux 的伙伴系统不是一个全局结构,而是每个 zone 都有自己的 buddy 空闲链表:
c
struct zone {
struct free_area free_area[NR_PAGE_ORDERS];
};
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
};free_area[order] 管理大小为 2^order 个 page 的连续空闲块;每个 order 内再按 migratetype 分链表,降低碎片。
简化后是这样:
text
ZONE_NORMAL
order-0: [page] [page] [page] ...
order-1: [2 pages] [2 pages] ...
order-2: [4 pages] ...
...
每个 order 又分:
MIGRATE_UNMOVABLE
MIGRATE_RECLAIMABLE
MIGRATE_MOVABLE
MIGRATE_CMA
MIGRATE_ISOLATE这说明 zone 和 buddy 的关系非常直接:
zone 决定从哪类物理内存分配,buddy 决定在这类物理内存内部如何找空闲页。
例如:
c
alloc_pages(GFP_KERNEL, 0);通常会从 ZONE_NORMAL 分配普通内核页。
c
alloc_pages(GFP_DMA32, 0);则要求页面来自 32-bit DMA 可达范围,最高 zone 会变成 ZONE_DMA32。
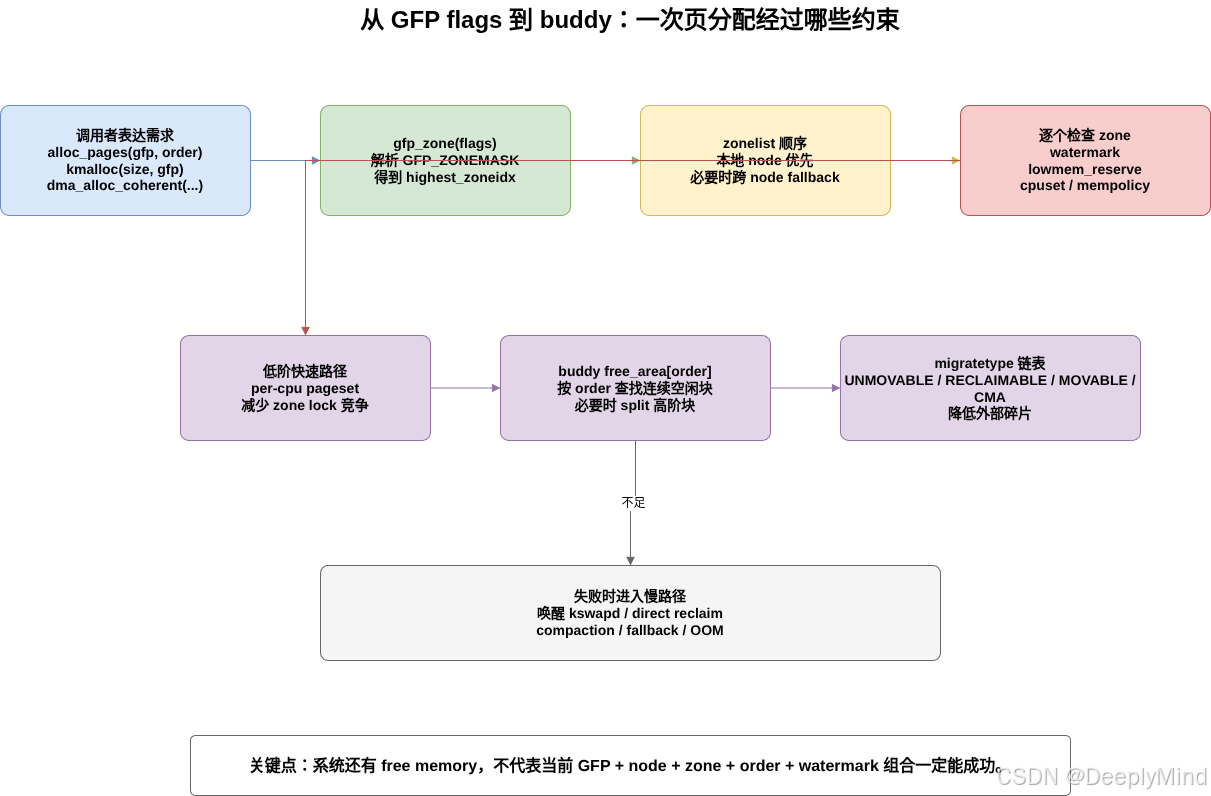
6. GFP flags 如何选择 zone
调用者通常不会直接说"我要 ZONE_NORMAL 的页",而是通过 GFP flags 表达需求。
与 zone 选择直接相关的是这几个 flag:
c
#define __GFP_DMA
#define __GFP_HIGHMEM
#define __GFP_DMA32
#define __GFP_MOVABLE
#define GFP_ZONEMASK (__GFP_DMA | __GFP_HIGHMEM | __GFP_DMA32 | __GFP_MOVABLE)include/linux/gfp.h 中的 gfp_zone() 会根据这些 bit 算出最高可用 zone:
c
static inline enum zone_type gfp_zone(gfp_t flags)
{
enum zone_type z;
int bit = (__force int)(flags & GFP_ZONEMASK);
z = (GFP_ZONE_TABLE >> (bit * GFP_ZONES_SHIFT)) &
((1 << GFP_ZONES_SHIFT) - 1);
VM_BUG_ON((GFP_ZONE_BAD >> bit) & 1);
return z;
}源码注释里给出的 fallback 顺序是:
text
MOVABLE => HIGHMEM => NORMAL => DMA32 => DMA这句话的含义是:如果请求允许使用较高 zone,分配失败时可以向更低、更受限的 zone fallback。但这也意味着低端 zone 是稀缺资源,需要保护。
典型映射可以粗略理解为:
| GFP 用法 | 目标含义 |
|---|---|
GFP_KERNEL |
普通内核分配,通常来自 ZONE_NORMAL |
GFP_DMA |
需要非常低地址 DMA 可达页 |
GFP_DMA32 |
需要 4GB 以下 DMA 可达页 |
GFP_HIGHUSER / GFP_HIGHUSER_MOVABLE |
用户页可来自 highmem/movable 区域 |
GFP_MOVABLE |
分配可迁移页,允许 ZONE_MOVABLE 或 movable pageblock |
注意:ZONE_DEVICE 不是 GFP 可直接选择的普通分配 zone。源码中也明确说:
c
/* ZONE_DEVICE is not a valid GFP zone specifier */设备页通常由 memremap_pages() 建立 struct page,再由设备驱动自己的 allocator 管理。
7. 水位线:zone "内存紧张"
每个 zone 都有自己的水位线:
c
enum zone_watermarks {
WMARK_MIN,
WMARK_LOW,
WMARK_HIGH,
WMARK_PROMO,
NR_WMARK
};它们用于决定分配、回收和 kswapd 行为:
| 水位线 | 含义 |
|---|---|
WMARK_MIN |
最低保留水位,低于它通常不能给普通分配使用 |
WMARK_LOW |
低于它会唤醒 kswapd 异步回收 |
WMARK_HIGH |
kswapd 回收到这个水位附近可以休眠 |
WMARK_PROMO |
NUMA memory tiering 中用于 promotion 的额外水位 |
分配器不会只看"还有多少 free pages",还会检查当前 zone 是否满足 watermark。简化逻辑是:
text
如果 zone 空闲页 >= 对应 watermark + 保留量
可以分配
否则
尝试回收、压缩、fallback 或失败这让内核避免把关键 zone 用到完全枯竭。例如 ZONE_DMA 很小,如果普通分配随便 fallback 到 DMA 区域,老 DMA 设备真正需要低地址页时就会失败。
lowmem_reserve[] 正是为这种场景服务的:它给低端 zone 留出保护量,防止高端分配把低端内存吃光。
8. zonelist:从哪个 node、哪个 zone 开始尝试
在 NUMA 系统上,分配器不仅要选择 zone,还要选择 node。内核会为每个 node 构建 zonelist,大致表达:
text
优先本地 node 的合适 zone
-> 本地 node 的 fallback zone
-> 其他 node 的合适 zone
-> 其他 node 的 fallback zone简化例子:
text
Node 0 发起 GFP_KERNEL 分配:
Node0 ZONE_NORMAL
Node0 ZONE_DMA32
Node0 ZONE_DMA
Node1 ZONE_NORMAL
Node1 ZONE_DMA32
Node1 ZONE_DMA真实顺序会受 NUMA distance、memory policy、cpuset、zonelist order 等影响。
这体现了 Linux page allocator 的两个基本目标:
- 尽量分配满足约束的本地内存,减少远端访问开销。
- 本地内存不足时允许 fallback,提高成功率。
如果调用者使用 __GFP_THISNODE,则会限制在指定 node 内分配,不再走常规跨节点 fallback。
将上面的内容做个总结如下图:
9. 各类 zone 的设计需求和使用场景
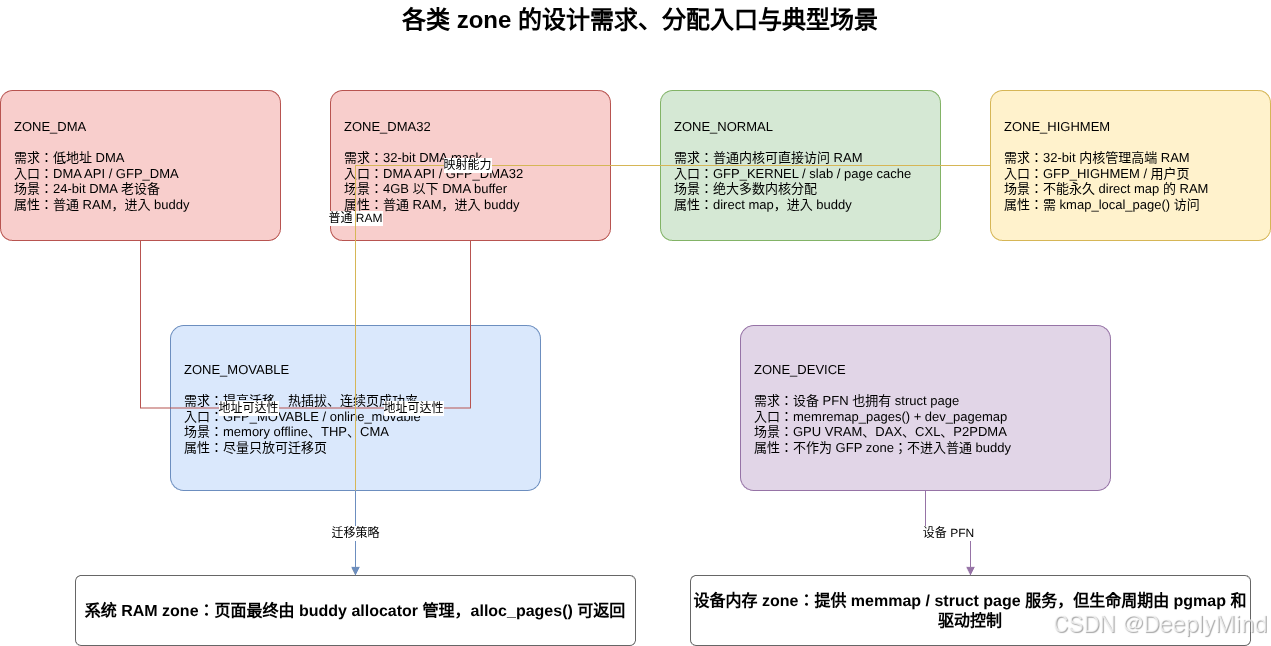
9.1 ZONE_DMA:为低地址 DMA 设备保留空间
ZONE_DMA 的历史背景是一些设备只能寻址非常低的物理地址。例如传统 ISA DMA 常见限制是 24-bit 地址,也就是 16 MB 以下。
它解决的问题是:
text
设备 DMA 地址线太短
-> 无法访问高地址 RAM
-> 必须从低地址物理页分配 DMA buffer使用场景通常不是普通驱动手写 alloc_pages(GFP_DMA),而是通过 DMA API 表达设备的 DMA mask,由 DMA mapping 层选择合适的内存或 bounce buffer。
c
dma_set_mask_and_coherent(dev, DMA_BIT_MASK(24));ZONE_DMA 很小,应该被视为稀缺资源。普通内核分配不应该主动使用它。
9.2 ZONE_DMA32:服务 32-bit DMA mask 设备
在 64-bit 系统上,很多 PCI 设备只能做 32-bit DMA,只能访问 4 GB 以下地址。ZONE_DMA32 就是给这类设备准备的。
典型需求:
text
系统 RAM 远大于 4 GB
设备 DMA mask 只有 32 bit
DMA buffer 必须位于 4 GB 以下相比 ZONE_DMA,ZONE_DMA32 更常见,也更贴近现代系统。
驱动仍然应该优先使用 DMA API,而不是直接依赖 zone:
c
ret = dma_set_mask_and_coherent(dev, DMA_BIT_MASK(32));
buf = dma_alloc_coherent(dev, size, &dma_handle, GFP_KERNEL);底层分配路径会根据设备约束和平台能力处理地址限制。
9.3 ZONE_NORMAL:普通内核可直接访问内存
ZONE_NORMAL 是最核心、最常见的 zone。内核可以通过 direct map 直接访问其中的页面,绝大多数内核对象、页表页、slab、文件缓存和匿名页最终都可能来自这里。
常见分配:
c
page = alloc_pages(GFP_KERNEL, order);
ptr = kmalloc(size, GFP_KERNEL);GFP_KERNEL 并不字面写着 ZONE_NORMAL,但在常见 64-bit 系统上,它的主要来源就是普通 RAM zone。
9.4 ZONE_HIGHMEM:32-bit 内核的高端内存
ZONE_HIGHMEM 是 32-bit 时代的产物。32-bit 内核虚拟地址空间有限,无法把所有物理内存永久映射到内核地址空间。
所以 highmem 页的特点是:
text
有 struct page
可以给用户空间使用
但内核不能长期直接 dereference
需要临时 kmap/local kmap 后访问典型访问方式:
c
void *addr = kmap_local_page(page);
/* access addr */
kunmap_local(addr);在 64-bit 系统上,内核通常可以 direct map 全部 RAM,因此 ZONE_HIGHMEM 基本不再出现。
9.5 ZONE_MOVABLE:提高可迁移性和热插拔成功率
ZONE_MOVABLE 的目标不是满足硬件地址限制,而是满足"这些页以后最好能搬走"的策略需求。
它主要服务几个场景:
| 场景 | 为什么需要 movable |
|---|---|
| memory hot-remove | offline 一个 memory block 前,需要迁走其中页面 |
| THP / HugeTLB | 减少不可迁移页造成的外部碎片 |
| CMA | 为设备保留可回收、可迁移的连续物理内存 |
| virtio-mem / balloon | 虚拟化环境中动态增减内存 |
ZONE_MOVABLE 尽量只接收可迁移页,例如用户匿名页、page cache 页。不可迁移的内核对象、页表页、长期 pin 页不应该长期留在这里。
这也是为什么长期 GUP pin 会和 movable 语义冲突:一旦页面被长期 pin,它就不再容易迁移,memory offline 或 compaction 可能失败。
9.6 ZONE_DEVICE:设备内存进入 page 模型
ZONE_DEVICE 和前面几个 zone 的性质不同。它不是为了让 alloc_pages() 分配普通 RAM,而是为了给设备物理地址范围建立 struct page。
典型来源包括:
| 类型 | 例子 |
|---|---|
MEMORY_DEVICE_PRIVATE |
GPU VRAM,CPU 不能直接访问 |
MEMORY_DEVICE_COHERENT |
CPU/设备一致性访问的设备内存 |
MEMORY_DEVICE_FS_DAX |
持久内存文件系统 DAX |
MEMORY_DEVICE_GENERIC |
DAX 类通用设备内存 |
MEMORY_DEVICE_PCI_P2PDMA |
PCI BAR 中用于 P2P DMA 的内存 |
设备驱动通常通过:
c
ptr = memremap_pages(&pgmap, numa_node_id());把设备 PFN range 注册进内核,让 pfn_to_page() / page_to_pfn() 等机制可用。
但 ZONE_DEVICE 页不会像普通 RAM 那样 online 到 buddy allocator。它们的生命周期由 dev_pagemap 和驱动回调控制。
10. zone 与 migratetype:两个维度不要混淆
zone 和 migratetype 经常一起出现,但它们不是同一层概念。
text
zone:这页属于哪类物理地址/策略区域
migratetype:这页所在 pageblock 适合放哪类可迁移性的分配zone 是大范围分类:
text
ZONE_DMA / ZONE_DMA32 / ZONE_NORMAL / ZONE_MOVABLE / ZONE_DEVICEmigratetype 是 buddy 内部反碎片分类:
text
MIGRATE_UNMOVABLE
MIGRATE_RECLAIMABLE
MIGRATE_MOVABLE
MIGRATE_CMA
MIGRATE_ISOLATE例如 ZONE_NORMAL 内部也可以有 MIGRATE_MOVABLE pageblock;ZONE_MOVABLE 则是更强的区域级策略,尽量让整个 zone 都只承载可迁移页。
可以这样记:
zone 决定能不能用这段物理内存,migratetype 决定如何减少这段内存内部的碎片。
11. zone 初始化:从 memblock 到 buddy
启动早期,buddy allocator 还没有完全建立,内核先用 memblock 描述可用物理内存和保留区域。
大致流程是:
text
固件 / bootloader 提供内存地图
-> memblock 记录 usable / reserved ranges
-> 架构代码确定各 zone PFN 边界
-> 初始化 node 和 zone
-> 初始化 memmap / struct page
-> 把可管理页面释放进 buddyzone 边界由架构和配置决定。例如 x86-64 常见布局可以粗略理解为:
text
低地址
ZONE_DMA 传统 DMA 低地址范围
ZONE_DMA32 4GB 以下范围
ZONE_NORMAL 其余普通 RAM
ZONE_MOVABLE 可选,从普通 RAM 中划出
高地址内存热插拔时也会涉及 zone:新增内存可以 online 到 ZONE_NORMAL 或 ZONE_MOVABLE;而 ZONE_DEVICE 则通过 memremap_pages() 使用 hotplug 的部分机制建立 memmap,但不把页面 online 成普通 buddy 页。
12. 使用方法:内核代码应该如何表达需求
多数内核代码不应该直接操作 zone,而应该通过合适 API 表达约束。
12.1 普通内核内存
c
ptr = kmalloc(size, GFP_KERNEL);
page = alloc_page(GFP_KERNEL);用于可以睡眠的普通内核上下文。
12.2 原子上下文分配
c
ptr = kmalloc(size, GFP_ATOMIC);这不是选择某个特殊 zone,而是告诉分配器不能睡眠、不能常规回收。
12.3 DMA buffer
优先使用 DMA API:
c
ret = dma_set_mask_and_coherent(dev, DMA_BIT_MASK(32));
buf = dma_alloc_coherent(dev, size, &dma_handle, GFP_KERNEL);不要把 GFP_DMA / GFP_DMA32 当成通用解决方案。DMA API 才知道设备 mask、IOMMU、cache coherency、bounce buffering 等平台细节。
12.4 用户页或可迁移页
c
page = alloc_page(GFP_HIGHUSER_MOVABLE);适合用户空间页、page cache 等可以回收或迁移的页面。
12.5 高端内存页访问
c
void *addr = kmap_local_page(page);
/* use addr */
kunmap_local(addr);只在可能存在 highmem 的平台上需要特别关心。
12.6 设备内存注册
c
struct dev_pagemap pgmap = {
.type = MEMORY_DEVICE_PRIVATE,
.range = range,
.nr_range = 1,
.ops = &ops,
.owner = owner,
};
memremap_pages(&pgmap, numa_node_id());这是 ZONE_DEVICE 的典型入口,不是 alloc_pages()。
13. 典型调试入口
观察 zone 状态时,最常用的是 /proc/zoneinfo:
bash
cat /proc/zoneinfo它会列出每个 node、每个 zone 的 watermarks、managed pages、free pages、per-cpu pageset 等信息。
快速看各 zone 空闲情况:
bash
cat /proc/buddyinfo输出按 node/zone/order 展示空闲块数量,适合判断是否存在高阶连续页不足:
text
Node 0, zone Normal 123 456 78 9 0 ...查看内存总览:
bash
cat /proc/meminfo查看 NUMA 分布:
bash
numactl --hardware对 zone 问题,常见判断思路是:
| 现象 | 可能方向 |
|---|---|
DMA / DMA32 空闲很低 |
低地址 DMA 资源紧张,检查 DMA mask 和驱动分配 |
| 高阶 order 长期为 0 | 外部碎片严重,关注 compaction、movable、CMA |
| memory offline 失败 | 区域里存在不可迁移页或长期 pin 页 |
| 本地 node 分配失败但系统还有内存 | NUMA policy、cpuset、zonelist、水位线限制 |
| DAX/HMM 页行为异常 | 检查 ZONE_DEVICE、dev_pagemap 和 pgmap owner/ops |
14. zone 体系的设计取舍
zone 体系的优点是把硬件约束和策略约束前置到 page allocator:
- DMA 设备可以得到可寻址的低地址页
- 普通内核分配不会轻易耗尽低端保留区
- 32-bit highmem 可以纳入统一 page 管理
- movable 区域提高热插拔和连续页分配成功率
- device memory 可以拥有
struct page,但不伪装成普通 RAM
它的代价是 allocator 变复杂了。一次 page 分配不只是"找空闲页",还要同时考虑:
text
GFP flags
-> highest zoneidx
-> NUMA node / zonelist
-> watermark
-> lowmem reserve
-> migratetype
-> reclaim / compaction / fallback这也是为什么很多内存问题不能只看系统总 free memory。总内存还有剩余,不代表某个 zone、某个 node、某个 order、某种 DMA 约束下的分配一定能成功。
15. 与 HMM 的关系
从 HMM 视角看,zone 体系提供了一个关键扩展点:Linux 已经有办法把"不是完全等价的物理页"放进统一 page allocator / memmap 框架中。
ZONE_DEVICE 正是沿着这个思路继续扩展:
text
经典 zone:
这也是 RAM,但地址能力/迁移策略不同
ZONE_DEVICE:
这有 struct page,但不一定是 RAM,也不一定进 buddy所以理解 ZONE_DEVICE 前,先理解普通 zone 的设计边界非常重要:
ZONE_DMA/ZONE_DMA32说明 zone 可以表达硬件可达性ZONE_HIGHMEM说明 zone 可以表达 CPU 映射能力ZONE_MOVABLE说明 zone 可以表达迁移策略ZONE_DEVICE则进一步说明 zone 可以表达"有 page 元数据,但不是普通系统内存"
这就是 HMM 能复用 Linux MM 的原因之一:它没有把设备内存放在完全私有的驱动世界里,而是让设备 PFN 进入现有的 page / PFN / zone 语义框架,再用 dev_pagemap 和 memory_type 保留设备差异。
16. 本篇小结
Linux zone 体系解决的是一个基础问题:物理页并不完全等价,page allocator 必须知道哪些页面适合哪些使用者。
它的设计可以概括为:
- 按 node 管理 NUMA 拓扑
- 在 node 内按 zone 表达地址、映射和迁移约束
- 在 zone 内用 buddy 管理不同 order 的连续空闲页
- 用 GFP flags 把调用者需求映射到合适的 zone
- 用 watermark 和 lowmem reserve 保护关键内存区域
- 用 migratetype 降低 zone 内部碎片
- 用
ZONE_DEVICE把设备物理地址纳入struct page模型
一句话总结:
zone 不是简单的内存分段,而是 Linux 把硬件限制、内核映射能力、迁移策略和设备内存语义压进 page allocator 的边界层。
17. 关键代码路径
| 文件 | 核心内容 |
|---|---|
include/linux/mmzone.h |
enum zone_type、struct zone、watermark、per-cpu pageset |
include/linux/gfp_types.h |
__GFP_DMA、__GFP_DMA32、__GFP_HIGHMEM、__GFP_MOVABLE |
include/linux/gfp.h |
gfp_zone()、GFP_ZONE_TABLE、zone fallback 关系 |
mm/page_alloc.c |
buddy allocator、zonelist、watermark 检查、fallback、per-cpu page cache |
mm/mm_init.c |
boot-time memmap 和 zone 初始化相关路径 |
mm/memory_hotplug.c |
memory online/offline、ZONE_NORMAL / ZONE_MOVABLE 热插拔 |
mm/memremap.c |
ZONE_DEVICE、memremap_pages()、dev_pagemap 注册路径 |
Documentation/mm/physical_memory.rst |
Linux 物理内存、node、zone、pageblock 的官方说明 |
Documentation/mm/page_allocation.rst |
page allocator 和 buddy 行为说明 |