如何用 Bright Data Web Scraper API + Coze 搭建 Reddit 行业情报聚合 Bot(2026 实战指南)
最近我越来越觉得,很多团队不是缺信息,是缺一个每天稳定把信息整理好的人。
比如你每天早上要看 AI agent、TikTok Shop、cross border ecommerce 这些关键词。打开 Reddit,翻帖子,看评论,判断大家到底在兴奋什么、吐槽什么、担心什么,再整理几句发到飞书群。一天两天还行,连续做一周,人就开始烦了。如果你也想把这件事自动化,可以先从这里准备 Bright Data 账号,Bright Data 专属注册链接。
这篇文章我只做一个很具体的东西。
用 Bright Data Web Scraper API + 扣子 Coze,搭一个 Reddit 行业情报聚合 Bot。它属于市场情报自动化的 starter 版,不是先铺竞品价格、关键词排名、多个社媒平台这些场景,而是先把「Reddit 社区讨论」这一条链路跑通。
关键词也很明确,bright data coze 教程、bright data api coze 接入、coze 工作流 web scraping、Reddit 数据采集、市场情报自动化 coze。
Bright Data Web Scraper API 是什么?
它是一种预构建数据采集服务,可以从 Reddit、LinkedIn、电商平台和社交媒体获取结构化数据,不需要你自己处理反爬、页面解析和字段清洗。
为什么 Coze 原生工具还不够
Coze 本身已经很适合做 Bot 和工作流编排,但如果要做长期市场情报,只靠原生搜索会有几个问题。
| 能力 | Coze 原生搜索 | 接入 Bright Data API 后 |
|---|---|---|
| 数据来源 | 通用搜索结果为主 | 可以指定 Reddit 数据集和关键词采集方式 |
| 数据结构 | 常需要二次整理 | 直接返回标题、正文、评论、点赞、社区等字段 |
| 批量采集 | 适合轻量查询 | 适合多关键词、定期跑、沉淀日报 |
| 调试与复用 | 结果波动时不好排查 | trigger、progress、snapshot 每一步都能检查 |
为什么选 API 方案?
因为这个场景本身就很适合代码节点,Bright Data 的数据采集是异步任务,要先触发采集,拿到 snapshot_id,再轮询状态,最后下载结果。把这几步写进 Coze,逻辑更清楚,也方便后面做错误处理和飞书推送。
所以这次的思路很明确,Coze 负责把流程串起来,Bright Data 负责把 Reddit 数据拿回来。
为什么不用自己写 Reddit 爬虫
如果只是临时抓一两个页面,自己写脚本当然也能跑。
但长期做 Reddit 数据采集,麻烦很快就会出现。反爬机制、速率限制,尤其是 HTTP 429,账号风控,页面结构变化,任何一个都可能让脚本突然失效。
更麻烦的是,这些问题通常不是业务问题。
你本来想做行业情报,结果时间全花在维护采集系统上。
Bright Data Web Scraper API 的价值就在这里,它已经把数据采集基础设施封装好了。开发者只需要关注关键词、采集范围、结果字段和后续分析,不需要每天和 Reddit 页面结构搏斗。
坦率讲,这才是我愿意把它接进 Coze 的原因。
Coze 管流程。
Bright Data 管数据。
LLM 管总结。
整体架构
回到这个 starter 版 Bot,我只选 Reddit。
Reddit 特别适合做「社区讨论信号」。你能看到真实用户和从业者在聊什么,哪些观点被顶上去,哪些话题看起来热闹但评论区并不买账。
第一版 Bot 最怕的不是功能少,而是每个平台字段都不一样,最后调试时间全花在清洗数据上。先用 Reddit 跑通,一条链路足够完整。等它稳定以后,再考虑是否扩展到其他平台,才比较稳。
这次用的是 Reddit - Posts - discover by keyword,dataset_id 是 gd_lvz8ah06191smkebj4。
不过这里有个很真实的小坑。
我在 Coze 里跑了一次,关键词是 AI agent,采集 3 条帖子。结果能拿到标题、链接、点赞和评论数,但 3 条都是空内容帖,没有正文。
所以第一版工作流不能只做「采集成功」判断,还要做「有效内容」判断。
我的建议是,先用 Reddit - Posts - discover by keyword 找帖子。如果返回里有 description_markdown 或 comments,就直接交给 LLM。如果有效内容为 0,就让日报明确标注「标题级分析」。后续增强版再把 Top 3 的 URL 传给 Reddit - Posts - collect by URL 补采。
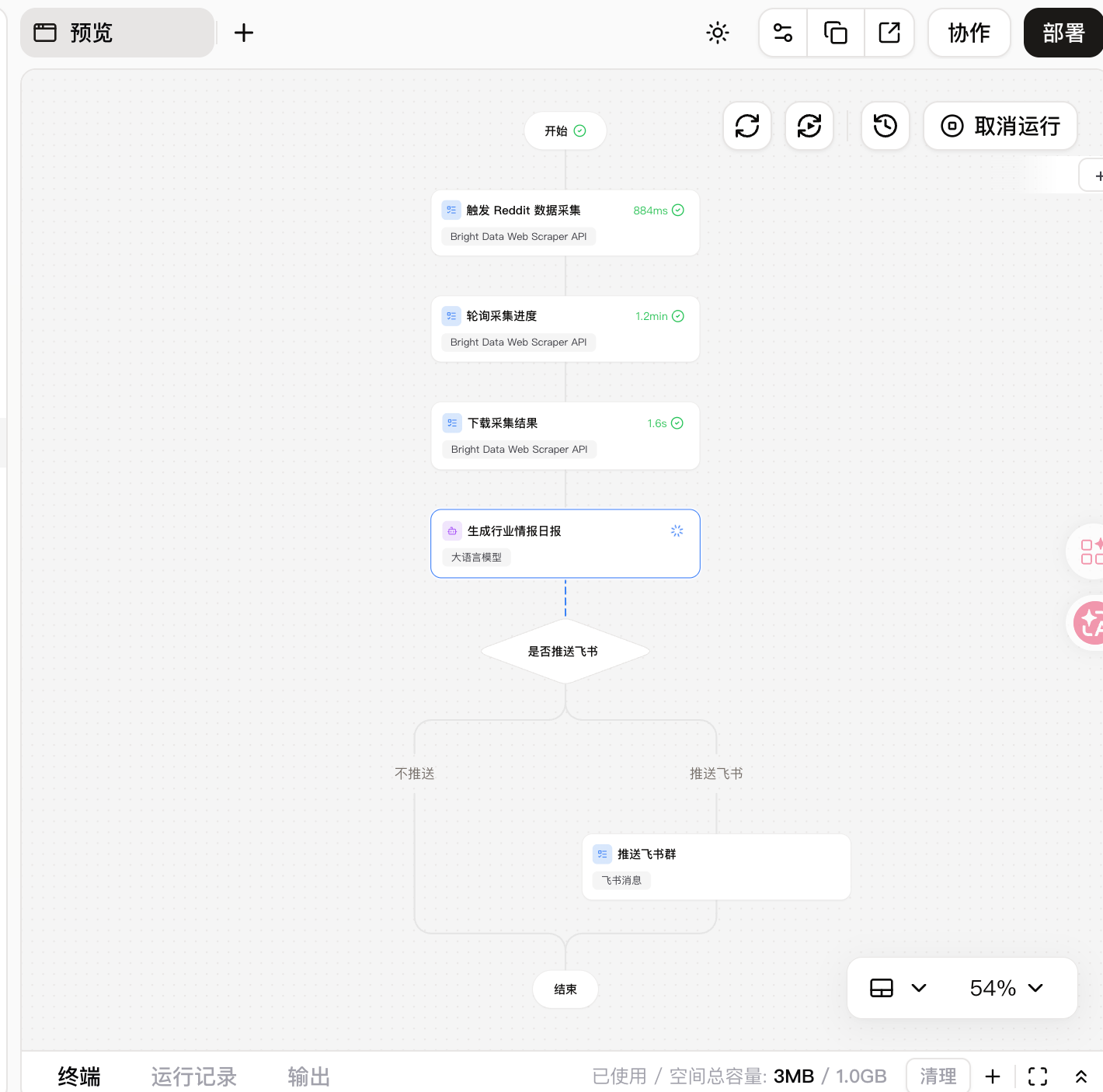
整个链路大概是这样。
#mermaid-svg-BAZIKIf6WZzVkMOY{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}@keyframes edge-animation-frame{from{stroke-dashoffset:0;}}@keyframes dash{to{stroke-dashoffset:0;}}#mermaid-svg-BAZIKIf6WZzVkMOY .edge-animation-slow{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 50s linear infinite;stroke-linecap:round;}#mermaid-svg-BAZIKIf6WZzVkMOY .edge-animation-fast{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 20s linear infinite;stroke-linecap:round;}#mermaid-svg-BAZIKIf6WZzVkMOY .error-icon{fill:#552222;}#mermaid-svg-BAZIKIf6WZzVkMOY .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-BAZIKIf6WZzVkMOY .edge-thickness-normal{stroke-width:1px;}#mermaid-svg-BAZIKIf6WZzVkMOY .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-BAZIKIf6WZzVkMOY .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-BAZIKIf6WZzVkMOY .edge-thickness-invisible{stroke-width:0;fill:none;}#mermaid-svg-BAZIKIf6WZzVkMOY .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-BAZIKIf6WZzVkMOY .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-BAZIKIf6WZzVkMOY .marker{fill:#333333;stroke:#333333;}#mermaid-svg-BAZIKIf6WZzVkMOY .marker.cross{stroke:#333333;}#mermaid-svg-BAZIKIf6WZzVkMOY svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-BAZIKIf6WZzVkMOY p{margin:0;}#mermaid-svg-BAZIKIf6WZzVkMOY .label{font-family:"trebuchet ms",verdana,arial,sans-serif;color:#333;}#mermaid-svg-BAZIKIf6WZzVkMOY .cluster-label text{fill:#333;}#mermaid-svg-BAZIKIf6WZzVkMOY .cluster-label span{color:#333;}#mermaid-svg-BAZIKIf6WZzVkMOY .cluster-label span p{background-color:transparent;}#mermaid-svg-BAZIKIf6WZzVkMOY .label text,#mermaid-svg-BAZIKIf6WZzVkMOY span{fill:#333;color:#333;}#mermaid-svg-BAZIKIf6WZzVkMOY .node rect,#mermaid-svg-BAZIKIf6WZzVkMOY .node circle,#mermaid-svg-BAZIKIf6WZzVkMOY .node ellipse,#mermaid-svg-BAZIKIf6WZzVkMOY .node polygon,#mermaid-svg-BAZIKIf6WZzVkMOY .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-BAZIKIf6WZzVkMOY .rough-node .label text,#mermaid-svg-BAZIKIf6WZzVkMOY .node .label text,#mermaid-svg-BAZIKIf6WZzVkMOY .image-shape .label,#mermaid-svg-BAZIKIf6WZzVkMOY .icon-shape .label{text-anchor:middle;}#mermaid-svg-BAZIKIf6WZzVkMOY .node .katex path{fill:#000;stroke:#000;stroke-width:1px;}#mermaid-svg-BAZIKIf6WZzVkMOY .rough-node .label,#mermaid-svg-BAZIKIf6WZzVkMOY .node .label,#mermaid-svg-BAZIKIf6WZzVkMOY .image-shape .label,#mermaid-svg-BAZIKIf6WZzVkMOY .icon-shape .label{text-align:center;}#mermaid-svg-BAZIKIf6WZzVkMOY .node.clickable{cursor:pointer;}#mermaid-svg-BAZIKIf6WZzVkMOY .root .anchor path{fill:#333333!important;stroke-width:0;stroke:#333333;}#mermaid-svg-BAZIKIf6WZzVkMOY .arrowheadPath{fill:#333333;}#mermaid-svg-BAZIKIf6WZzVkMOY .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-BAZIKIf6WZzVkMOY .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-BAZIKIf6WZzVkMOY .edgeLabel{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-BAZIKIf6WZzVkMOY .edgeLabel p{background-color:rgba(232,232,232, 0.8);}#mermaid-svg-BAZIKIf6WZzVkMOY .edgeLabel rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-BAZIKIf6WZzVkMOY .labelBkg{background-color:rgba(232, 232, 232, 0.5);}#mermaid-svg-BAZIKIf6WZzVkMOY .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-BAZIKIf6WZzVkMOY .cluster text{fill:#333;}#mermaid-svg-BAZIKIf6WZzVkMOY .cluster span{color:#333;}#mermaid-svg-BAZIKIf6WZzVkMOY div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-BAZIKIf6WZzVkMOY .flowchartTitleText{text-anchor:middle;font-size:18px;fill:#333;}#mermaid-svg-BAZIKIf6WZzVkMOY rect.text{fill:none;stroke-width:0;}#mermaid-svg-BAZIKIf6WZzVkMOY .icon-shape,#mermaid-svg-BAZIKIf6WZzVkMOY .image-shape{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-BAZIKIf6WZzVkMOY .icon-shape p,#mermaid-svg-BAZIKIf6WZzVkMOY .image-shape p{background-color:rgba(232,232,232, 0.8);padding:2px;}#mermaid-svg-BAZIKIf6WZzVkMOY .icon-shape .label rect,#mermaid-svg-BAZIKIf6WZzVkMOY .image-shape .label rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-BAZIKIf6WZzVkMOY .label-icon{display:inline-block;height:1em;overflow:visible;vertical-align:-0.125em;}#mermaid-svg-BAZIKIf6WZzVkMOY .node .label-icon path{fill:currentColor;stroke:revert;stroke-width:revert;}#mermaid-svg-BAZIKIf6WZzVkMOY :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;} 推送
不推送
输入行业关键词
Coze 工作流
代码节点触发 Reddit keyword 采集
下载 discover 结果
LLM 生成行业情报日报
是否推送飞书
飞书群机器人推送
结束
开始前准备什么
需要准备的东西不多。
- Coze 账号,用来创建 Workflow
- Bright Data 账号,用来获取 API Token
- Reddit keyword 数据集,
gd_lvz8ah06191smkebj4 - 飞书群机器人 Webhook,用来接收日报
Bright Data 账号可以从这里注册,Bright Data 注册链接。使用"tao20"即赠20美元试用。
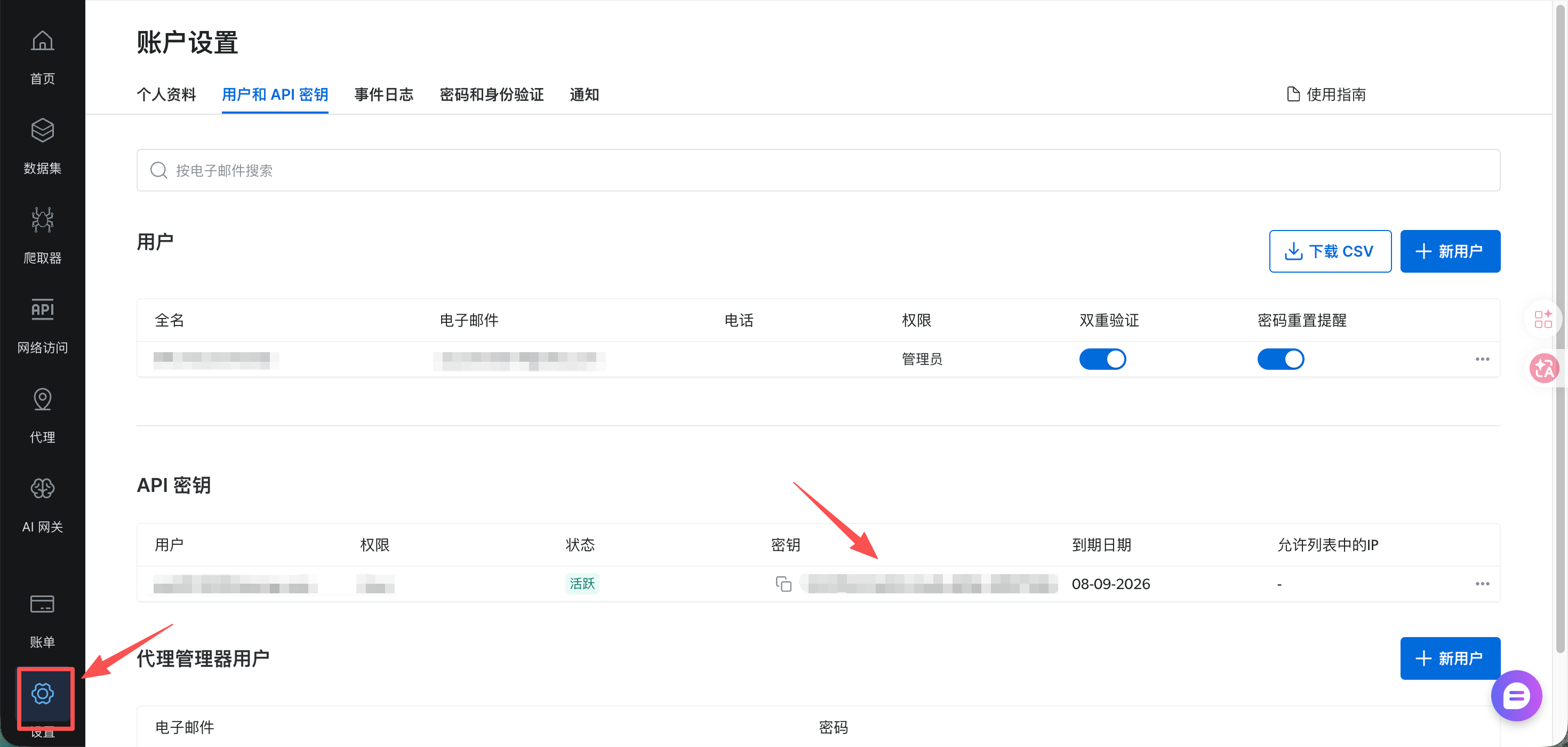
在设置-用户与API密钥处找到自己的YOUR_BRIGHTDATA_API_KEY。
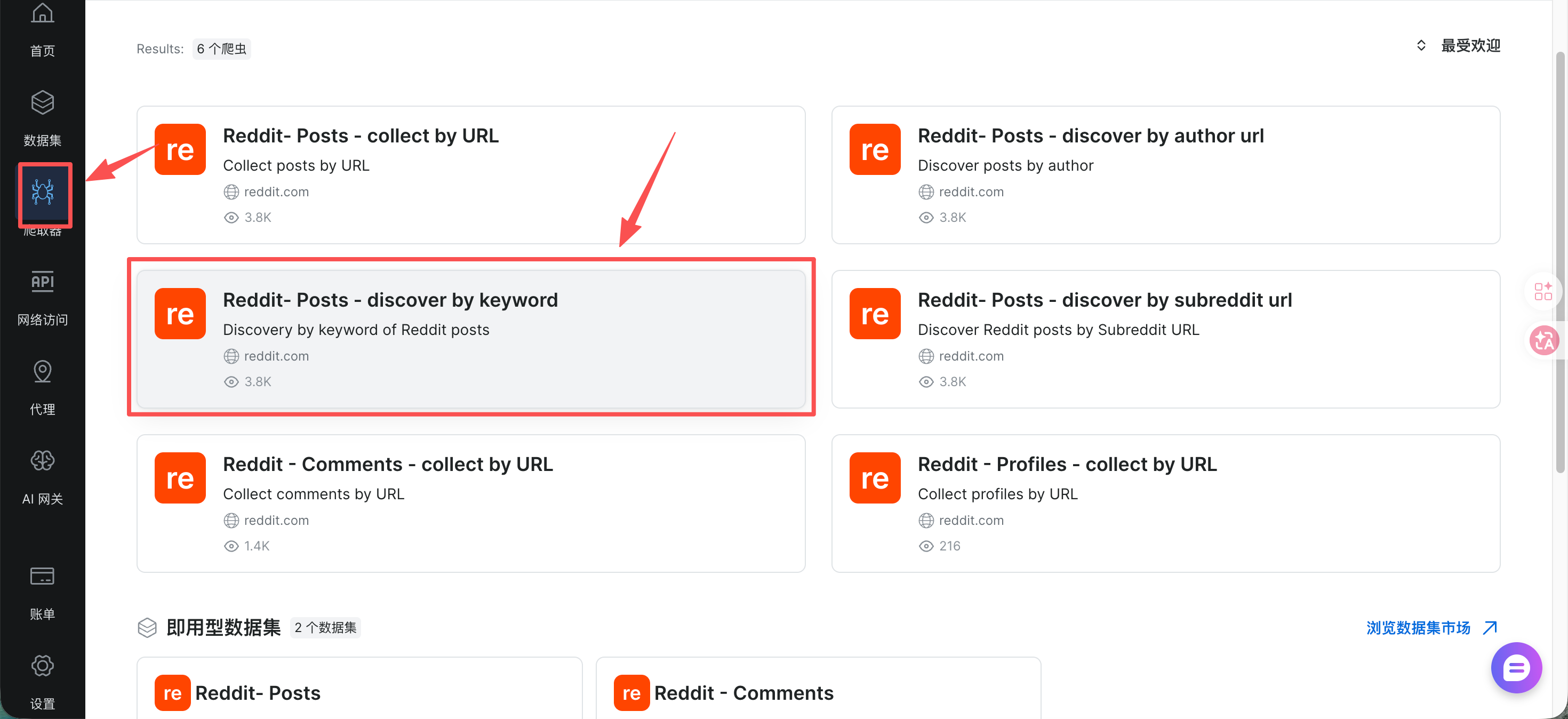
在爬取器-社交媒体中找到Reddit,然后点击Reddit- Posts - discover by keyword,再选择爬虫API。
Bright Data 控制台提供 Python、Node.js、cURL 等多种语言示例代码,按需获取即可。
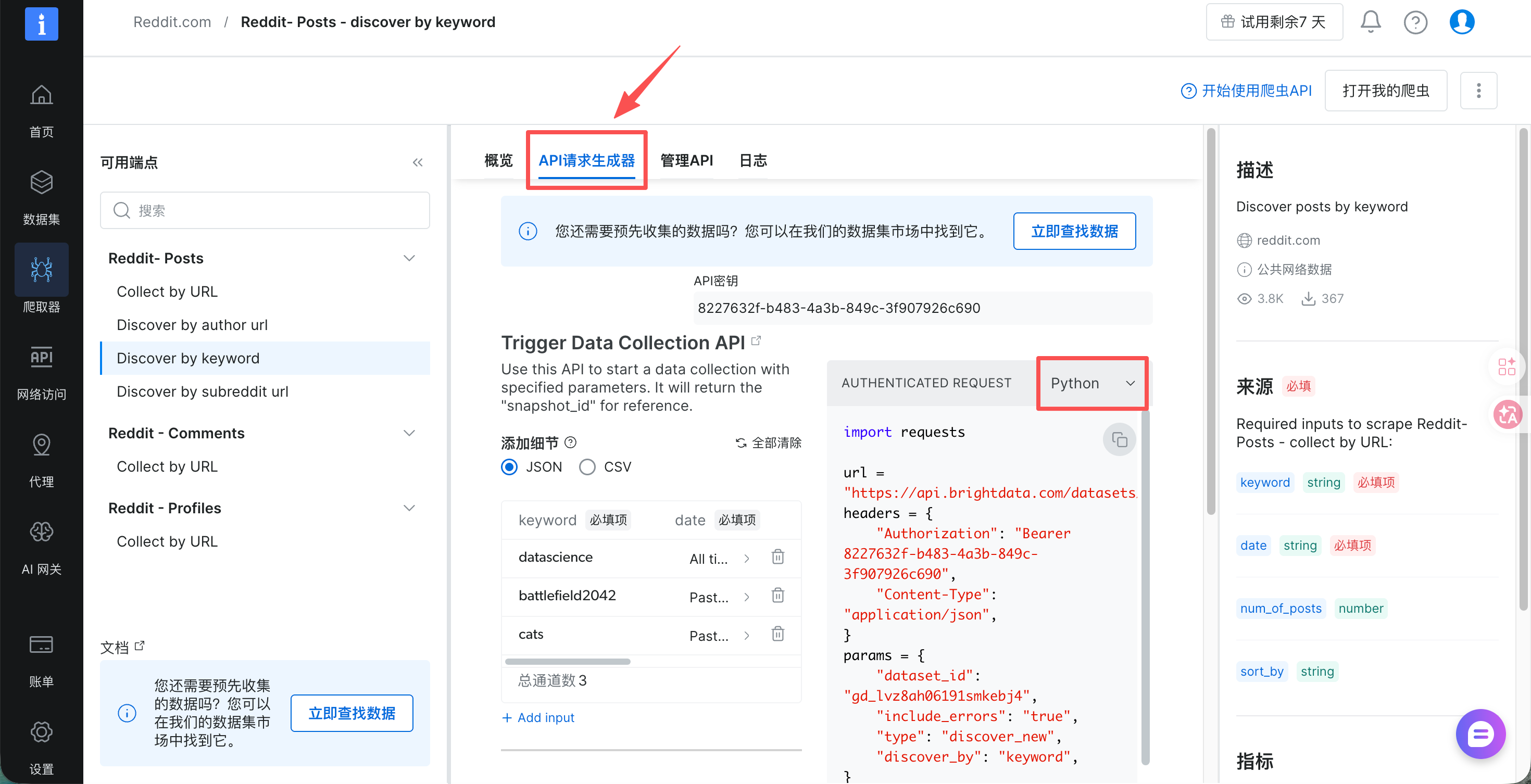
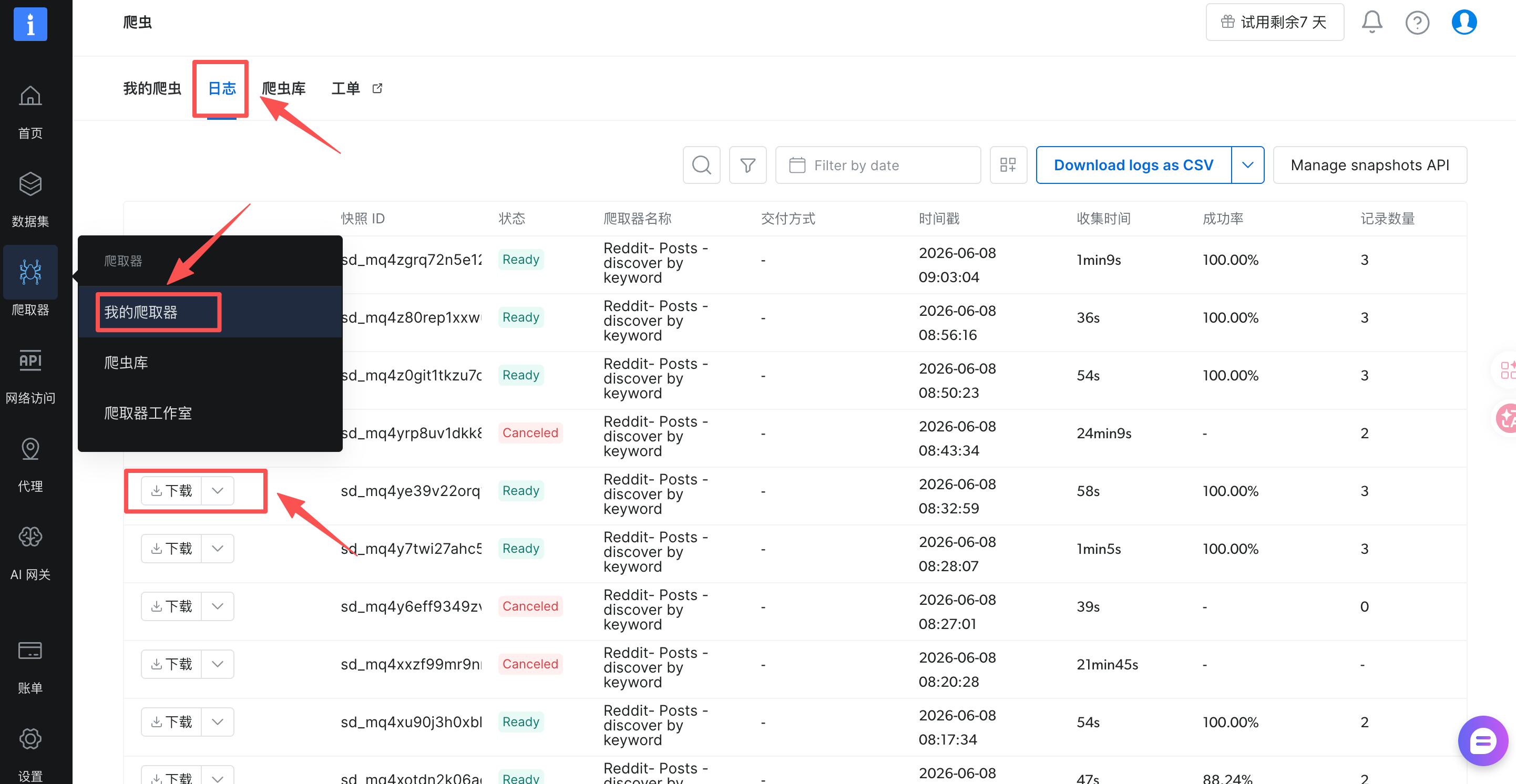
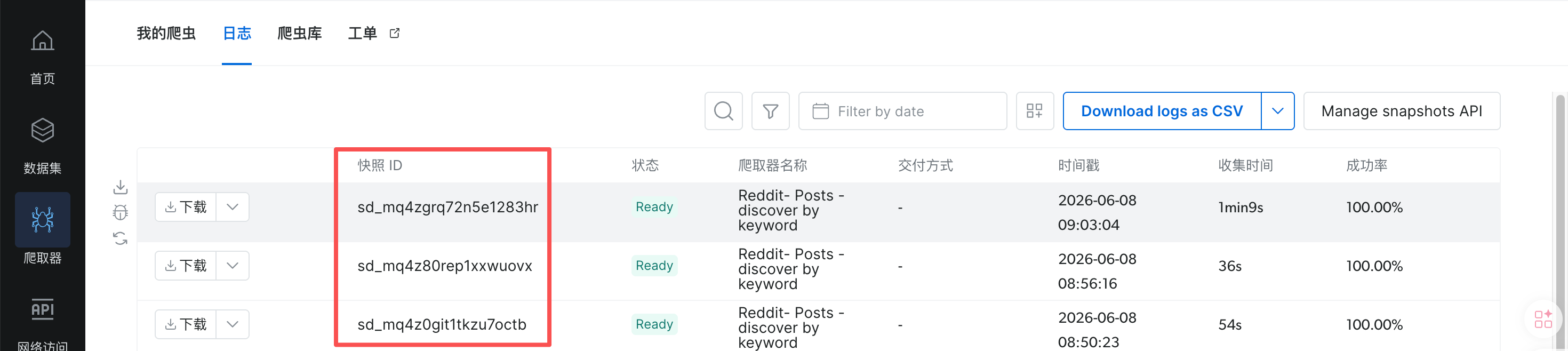
如果想获取具体的下载内容,可以在我的爬虫器-日志中进行下载。
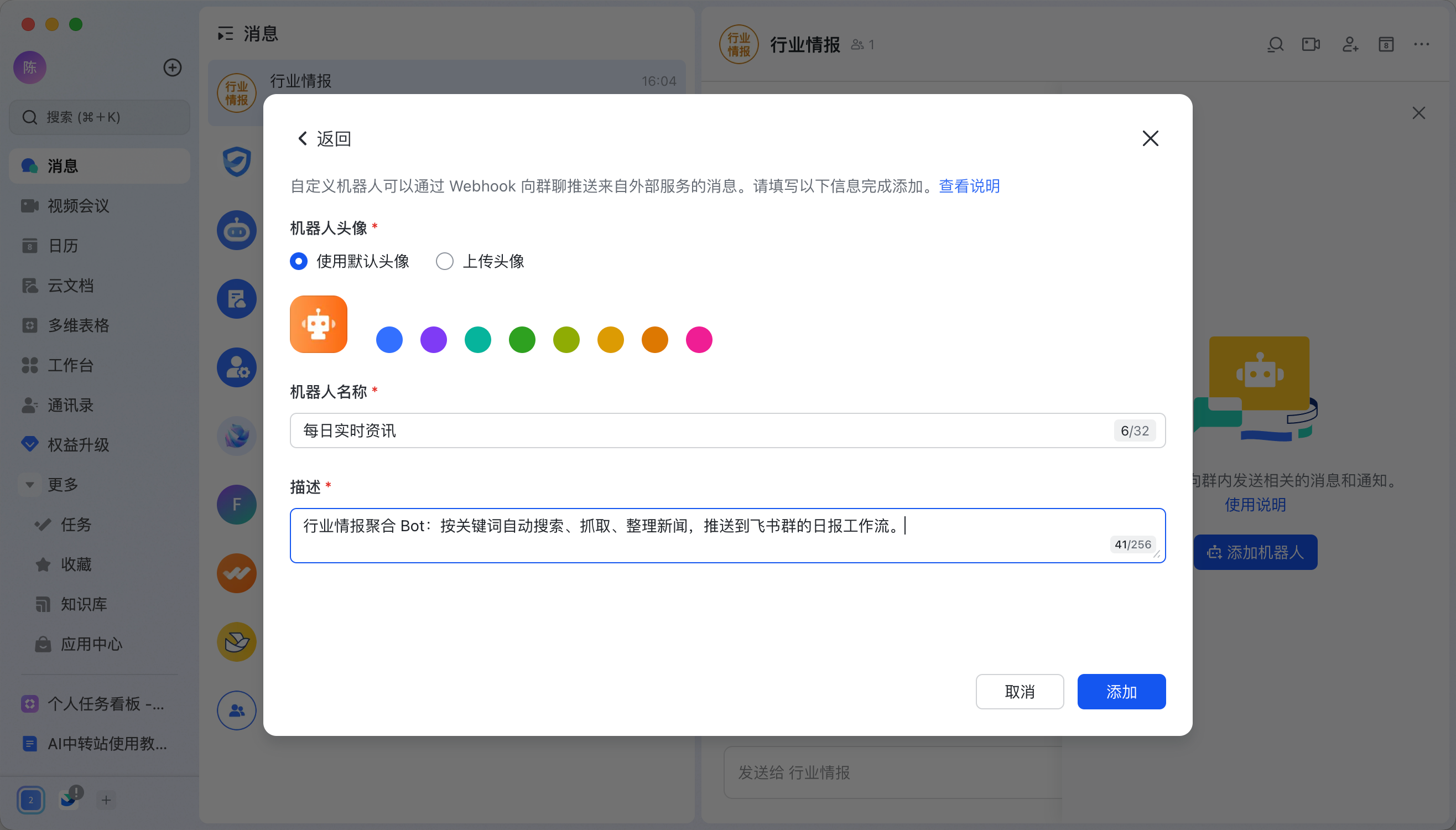
飞书机器人创建很简单,在群聊中右上角...处点击设置,然后添加机器人即可。
这个 Bot 怎么搭
我建议先做一个可以手动运行的版本。
在 Coze 里新建 Workflow,输入先放这几个字段。
json
{
"keywords": "AI agent",
"reddit_date": "Past month",
"reddit_sort_by": "Hot",
"num_of_posts": 10
}第一个代码节点负责触发 Bright Data 采集。
Reddit 的请求参数核心是这些。
json
{
"dataset_id": "gd_lvz8ah06191smkebj4",
"type": "discover_new",
"discover_by": "keyword",
"payload": [
{
"keyword": "AI agent",
"date": "Past month",
"num_of_posts": 10,
"sort_by": "Hot"
}
]
}Bright Data Web Scraper API 是异步采集流程,这块一定不要只复制 progress 代码。
完整流程是三步。
先调用 trigger 发起采集,拿到 snapshot_id。
再调用 progress/{snapshot_id} 等状态变成 ready。
最后调用 snapshot/{snapshot_id} 下载结果。
在 Coze 里,我建议把代码拆成三个小节点。
第一个代码节点只负责触发 Reddit 采集,并返回 snapshot_id。
第二个代码节点只负责轮询状态,如果还在 running,就等待几秒再查。如果状态是 failed,就把错误信息直接输出,不要继续往下跑。
第三个代码节点只负责下载 snapshot,并把 Reddit 数据整理成统一数组。
第四步交给 LLM 节点生成日报。
当前工作流截图里,节点顺序是「触发 Reddit 数据采集」→「轮询采集进度」→「下载采集结果」→「生成行业情报日报」→「是否推送飞书」→「推送飞书群」。如果发现有效内容为 0,就在日报里标注标题级分析,后续再加 collect by URL 补采节点。
这样做的好处很明显。
一旦失败,你能知道到底是 trigger 失败,还是 progress 没 ready,还是 snapshot 下载失败。否则所有逻辑塞进一个大代码节点,调试起来会非常难受。
字段也建议先收窄。
Reddit 先保留 title、url、user_posted、community_name、description_markdown、comments、num_upvotes、num_comments、date_posted。
如果本次只有标题和链接,日报里要明确写「本次为标题级分析」。
怎么让 LLM 真的像情报分析
LLM 节点不要让它自由发挥,提示词要限制死。
text
你是一个行业情报分析助手。
只根据输入的 Reddit 帖子、正文和评论生成日报,不要编造。
Reddit 代表社区讨论信号,请重点分析用户真实观点、争议点和高互动内容。
请合并重复信息,提炼 3 条最重要的趋势。
每条趋势都要说明证据来自哪条帖子或评论。
如果 Reddit 采集失败,必须在日报里说明,不要假装成功。
如果只有标题和链接,没有正文和评论,必须标注为标题级分析。
输出中文,适合飞书群阅读。这里有个判断逻辑很重要。
Reddit 不只是看标题。
标题能告诉你话题是什么,正文能告诉你作者为什么这么说,评论区才经常决定这个观点是不是被社区接受。比如一个帖子说「企业其实不想要 AI agent」,如果评论区也在反复讲「客户要的是稳定结果,不是自主性」,那这就不是一个孤立观点,而是一个值得写进日报的社区共识。
所以 LLM 节点里要把 description_markdown 和 comments 都喂进去。
实际推送效果如下,能看到数据采集概览、趋势判断、证据帖子和数据质量说明。
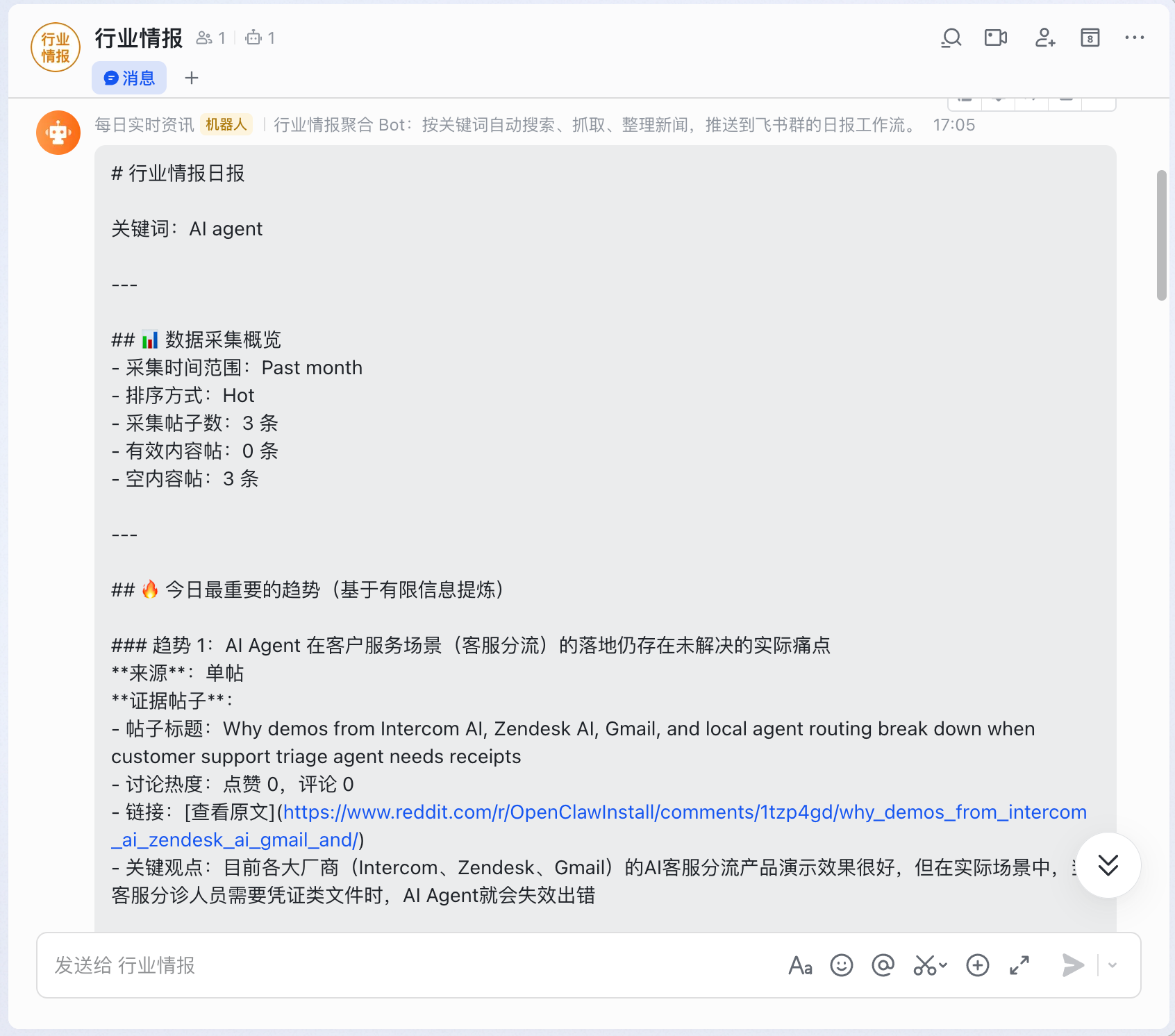
这次配套交付物只保留一个项目包,也就是主题一里的「行业新闻聚合 Bot」单场景版本。
text
行业情报聚合Bot.tar.gz读者拿到之后,不需要从零搭节点,直接在 Coze 里导入这个项目包就行。
项目目录大概是这样。
text
行业情报聚合Bot/
├─ .env
├─ config/
├─ scripts/
├─ src/
├─ assets/
└─ README.md最重要的是 .env。
导入之后先打开 .env,把里面的占位符换成自己的 Key。这里不要偷懒,也不要把真实 Key 写进 README 或截图里。
bash
BRIGHT_DATA_API_KEY=YOUR_BRIGHTDATA_API_KEY
FEISHU_WEBHOOK_URL=YOUR_FEISHU_WEBHOOK_URLconfig/ 放工作流配置,scripts/ 和 src/ 放采集、轮询、下载代码,assets/ 放截图素材。README 里会写清楚怎么注册 Bright Data、怎么导入项目、怎么配置飞书 Webhook。注册链接也会放进去,Bright Data 专属注册链接。
物料下载链接:gitHub链接
拿到交付物后,只需要导入项目包,改 .env,再把关键词换成自己的行业词,就能先手动跑一版。
这也是我觉得项目包比单独丢一份 workflow JSON 更好的地方。
大家不用照着文章重新搭一遍,而是直接给一个能直接导入、直接改配置、直接运行的起点。
成本这块怎么算
这个 Bot 省下来的不是一次搜索的时间,而是每天重复搜索、整理和转发的时间。
一个人每天花 20 分钟看 Reddit,一个月就是 6 到 8 个小时。更现实的是,人会漏看,会忘记发,会因为临时会议打断。
Bot 不会。
Bright Data 按采集使用量计费,Coze 负责流程,飞书负责通知。对小团队来说,最大的价值是稳定。
它每天都用同一种格式,把社区讨论信号推到同一个地方。
这就够了。
FAQ
Bright Data 可以免费使用吗?
可以。Bright Data 提供免费试用,同时部分产品如 Discover API 和 Bright Data MCP 可免费使用。本文用到的 Web Scraper API 建议先用试用额度跑通最小流程。
Reddit 数据采集是否需要自己维护爬虫?
不需要。Web Scraper API 已经提供现成的 Reddit 数据采集能力,你只需要配置关键词、时间范围、排序方式和采集数量。
Coze 可以直接采集 Reddit 吗?
可以做搜索和工作流编排,但要稳定获取结构化 Reddit 数据,尤其是标题、链接、评论、互动数据和正文,还是更适合结合 Bright Data API。
什么时候需要 collect by URL?
当 discover by keyword 返回的帖子缺少正文或评论时,可以进一步通过 URL 补采完整内容。当前工作流先保留这个判断,后续可以把 Top 3 URL 接到 Reddit - Posts - collect by URL。
总结
我越来越喜欢这种小而具体的 AI 工作流。
它没有那么炫,但非常实用。
这次的 Reddit 行业情报聚合 Bot,本质上就是把「每天刷 Reddit」这件事,改造成一条自动化流水线。Bright Data 把数据拿回来,Coze 把流程串起来,LLM 把内容整理成人话,飞书把结果推到团队面前。
如果你想复现,不要一开始就做很多平台。
先选 Reddit。
先手动跑一次。
先让飞书收到第一份日报。
跑通以后,再考虑多关键词、多 subreddit、多平台和定时任务。
注册链接我再放一次,Bright Data 专属注册链接,使用折扣码"tao20",就能获得20美元试用金。
等第二天早上飞书自动弹出那份日报的时候,你会有一种很朴素的爽感。
因为你知道,从今天开始,这件小事不用你亲手刷了。