引言:为什么要谈 harness / loop / hook
当我们谈论一个 Agent 系统的设计,三个角度几乎绕不开:
- Agent Harness(智能体骨架)
- :宿主进程如何承载 Agent,从输入捕获、上下文封装到结果回写的"外壳"。
- Agent Loop(智能体回路)
- :Agent 在面对不确定输入时,如何一步步收敛到一个可交付结果的"主循环"。
- Hook(钩子/切面)
- :在 Loop 的关键节点上挂载可观测、可介入、可容错的"切面"。
主流 Agent 框架在这三个维度上常见的做法是:把 Loop 写成固定的 ReAct 模板,把 Harness 做成 CLI 或 Server 包装,把 Hook 做成 LangGraph Edge 或 Tool Pre/Post Callback。这套范式在做"通用对话+工具调用"时很顺,但当任务本身具有强结构性(比如"从一句话生成一个完整的部门管理模块"),就会暴露三个问题:
- Loop 的步骤数量和组合方式应该由意图驱动,而不是写死的模板。
- 异构步骤(NLP 推理 / DSL 生成 / Java 代码生成 / 编译集成)应该被统一抽象,而不是各跑各的轨道。
- 人类介入(确认设计、修改字段、重跑某一段)应该是一等公民的 Hook,而不是补丁。
Ooder 在最近一轮重构中,把原本的 NlpPipeline + NlpDesignOrchestrator + NlpProjectIntegrator 三轨硬编码流程,重新组织为基于 SceneGroup 的场景编排核。这篇文章会从 harness、loop、hook 三个角度逐层拆解这套设计。
第一视角 · Agent Harness:分层骨架
Ooder 的 Harness 不是单一的进程外壳,而是一个由三层结构组成的承载体系:
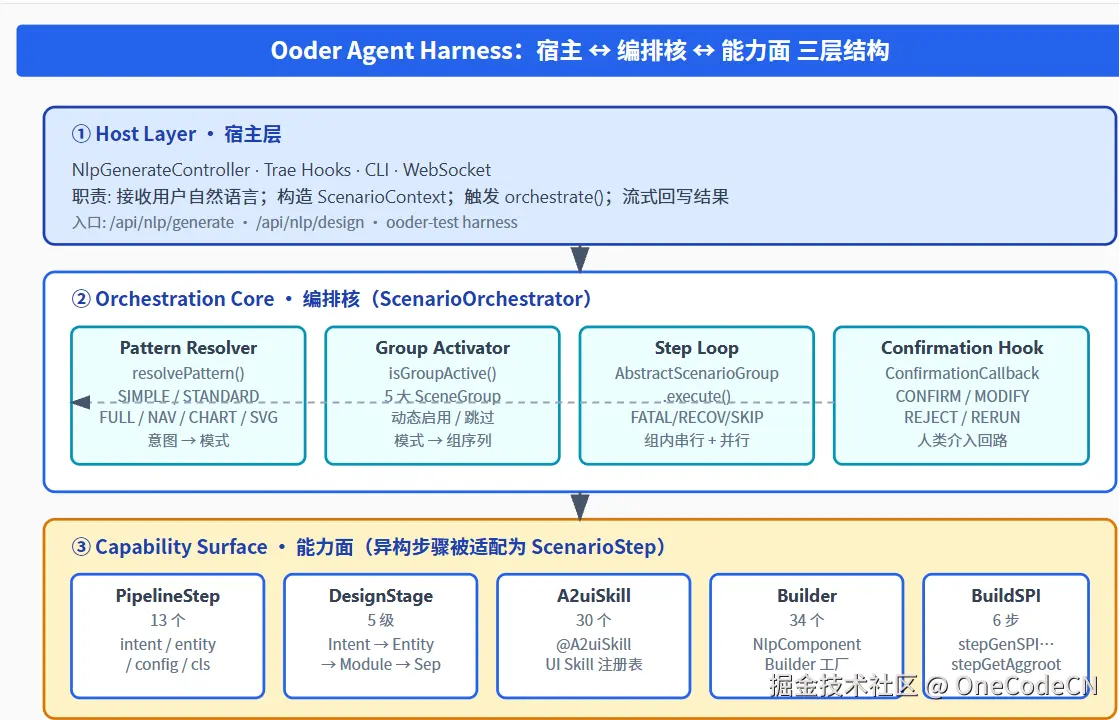
图 1 · Ooder Agent Harness 的三层结构:宿主层、编排核、能力面
① Host Layer · 宿主层
承担"接住外部请求、流式回写"的职责。Ooder 的宿主层有三种典型形态:
- HTTP Controller
- :NlpGenerateController 暴露 /api/nlp/generate 等 REST 端点;
- 测试 Harness
- :ooder-nlp-harness 跑闭环用例(llm-chat → four-separation → genCode → build);
- Trae Hooks
- :在 IDE/Agent 上下文里嵌入 PostToolUse / UserPromptSubmit 等切面,把用户的自然语言带回 harness。
宿主层的核心动作只有一个:把异构入参翻译成 ScenarioContext,然后调用编排核。
javascript
// NlpGenerateController#generate
ScenarioContext context = new ScenarioContext(query, null, null);
context.putAccumulated("projectName", projectName);
context.putAccumulated("autoSave", autoSave);
context.putAccumulated("channelCode", channelCode);
ScenarioOrchestrationResult result = scenarioOrchestrator.orchestrate(context);② Orchestration Core · 编排核
编排核 ScenarioOrchestrator 是整个 Harness 的"大脑",由四个协作组件构成:
| 组件 | 职责 | 关键方法 |
|---|---|---|
| Pattern Resolver | 把意图(systemType + buildLevel)映射到 6 种编排模式之一 | resolvePattern()· OrchestrationPattern.fromIntent() |
| Group Activator | 根据模式决定哪些 SceneGroup 激活/跳过 | pattern.isGroupActive(groupId) |
| Step Loop | 组内串行/并行执行 ScenarioStep,处理失败策略 | AbstractScenarioGroup.execute() |
| Confirmation Hook | 当组结果标记 needConfirm 时暂停等待用户决策 | ConfirmationCallback.confirm() |
③ Capability Surface · 能力面
能力面是 Ooder 编排核的精髓所在:将4 类 88+ 个异构步骤统一适配为同一个 ScenarioStep 接口:
- 13 个 NlpPipelineStep
- (intent_classification、entity_extraction、cls_audit...)→ PipelineStepAdapter
- 5 个 DesignStage
- (IntentUnderstanding → DesignAssembly)→ DesignStageAdapter
- 30 个 @A2uiSkill
- (基于注解的 UI Skill 注册表)→ A2uiSkillAdapter
- 34 个 NlpComponentBuilder
- (基于工厂的组件构建器)→ ComponentBuilderAdapter
- 6 步 AggRootBuildSPI
- (genSPI → genView → ... → getAggroot)→ BuildStepAdapter
每个 Adapter 都不是简单的方法转发,而是承担两个关键职责:
- 上下文转换
- :在 ScenarioContext 与原生上下文(NlpPipelineContext / DesignStageContext)之间双向同步;
- 元数据声明
- :通过 getRequiredCapabilities() / getProducedOutputs() / getRequiredInputs() 让编排器知道步骤间的依赖关系。
javascript
public interface ScenarioStep {
String getStepId(); // 全局唯一标识
String getGroupId(); // 所属场景组(SG-UNDERSTAND...)
int getOrder(); // 组内执行顺序
boolean isEnabled(ScenarioContext ctx); // 动态启用判断
StepResult execute(ScenarioContext ctx, StepResult previousResult);
FailureStrategy getFailureStrategy(); // FATAL / RECOVERABLE / SKIPABLE
List<String> getRequiredCapabilities();
List<String> getProducedOutputs();
List<String> getRequiredInputs();
}当能力面被压平为同一个接口,编排核才有可能用 同一套 Loop + Hook 去驱动数十种异构能力 ------ 这就是 SceneGroup 设计能跨越 NLP / DSL / 代码生成 / 编译四个维度的根本原因。
第二视角 · Agent Loop:场景驱动的运行回路
大多数 Agent 框架的 Loop 长这样:Plan → Tool → Observe → Plan' → ...。Ooder 的 Loop 长这样:Resolve Pattern → Activate Groups → Run Group Sequence → Quality Loop → Integrate。
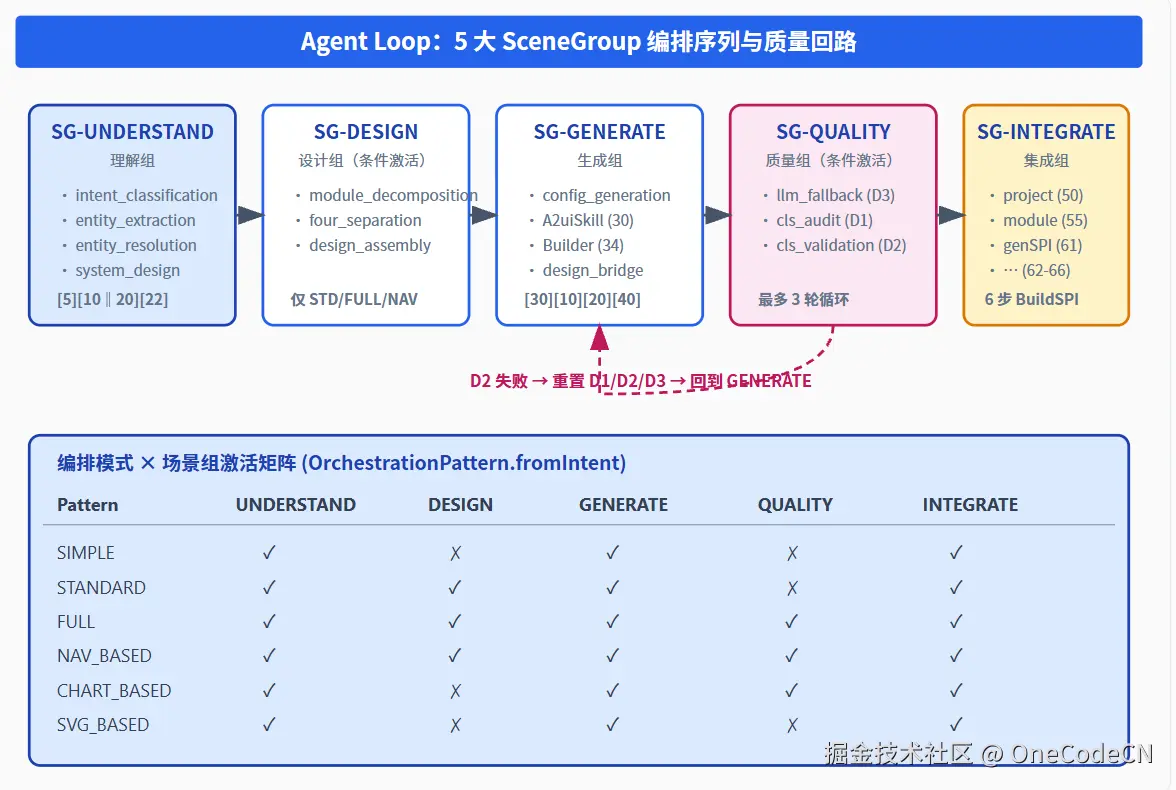
图 2 · 5 大 SceneGroup 编排序列、质量回路与编排模式激活矩阵
2.1 五大场景组:把异构步骤纵向切片
| 场景组 | 语义 | 包含步骤 | 关键 Order |
|---|---|---|---|
| SG-UNDERSTAND | 理解用户意图与实体 | system_design / intent_classification / entity_extraction / entity_resolution | 5 / 10 ‖ 20 / 22 |
| SG-DESIGN | 架构设计与四分离 | module_decomposition / four_separation / design_assembly | 25 / 4 / 5 |
| SG-GENERATE | 配置生成与组件构建 | config_generation / A2uiSkill × 30 / Builder × 34 / design_bridge | 30 / 10‖20 / 40 |
| SG-QUALITY | 四分离审计与场景校验 | llm_fallback / cls_audit / cls_validation | 35 / 45 / 48 |
| SG-INTEGRATE | 项目集成与构建 | project_integration / module_integration / 6 步 BuildSPI | 50 / 55 / 61~66 |
2.2 编排模式:Loop 的形状由意图决定
同样是"创建一个部门管理",根据 LLM 推断出的 systemType 与 buildLevel,Loop 的形状会发生显著变化。这是 OrchestrationPattern.fromIntent() 的真正威力:
javascript
public static OrchestrationPattern fromIntent(String systemType, String buildLevel) {
if (systemType == null) return STANDARD;
switch (systemType) {
case "NAV_BASED": return NAV_BASED; // 全场景组激活
case "CHART_BASED": return CHART_BASED; // 跳过 DESIGN
case "SINGLE_MODULE": return SVG_BASED; // 跳过 DESIGN + QUALITY
default: // CRUD_BASED
if ("SIMPLE".equals(buildLevel)) return SIMPLE;
if ("STANDARD".equals(buildLevel)) return STANDARD;
return FULL;
}
}对照图 2 下半部分的激活矩阵:
- "创建一个表单" → SIMPLE:只走 Understand → Generate → Integrate,跳过 Design 和 Quality;
- "创建部门管理(含字段)" → STANDARD:加上 Design,但不开质量回路;
- "创建复杂 CRM 系统(带导航)" → NAV_BASED:所有 5 组全开,含 3 轮质量循环;
- "画一个流程拓扑图" → SVG_BASED:跳过 Design、Quality,只走 Understand → Generate(svg) → Integrate。
这是 SceneGroup 与传统 Step DAG 最关键的差异:**Loop 的形状不是预定义的 DAG,而是由意图推导出来的"模式"映射到固定的场景组序列。**这种设计使得新增一种系统类型只需要新增一个 OrchestrationPattern 枚举值,而不是重画 DAG。
2.3 质量回路:内嵌于 Loop 的反馈循环
真正能体现 SceneGroup 是"Agent Loop"而不是"管道"的地方,是 QualityGroup 的内部回路:
javascript
// QualityGroup#execute
do {
result = super.execute(context);
loopCount++;
StepResult validation = context.getStepResult("cls_validation");
if (validation == null || validation.isSuccess()) break;
// D2 验证未通过 → 重置 D1/D2/D3 → 回到 GENERATE
context.clearStepResults("llm_fallback", "cls_audit", "cls_validation");
} while (loopCount < MAX_VALIDATION_LOOPS); // 最多 3 轮关键设计点: ScenarioContext.clearStepResults() 在清理 stepResults 的同时,同步清理 accumulatedData 中由该步骤写入的 key。这保证了重试时不会读到上一轮的脏数据 ------ 这是审计阶段发现并修复的一个隐蔽 bug。
这个质量回路的语义和 ReAct 中的"Observe → Replan"是一致的:当观察结果不达标时,回退到生成阶段重做。但 Ooder 把它固化在 Group 内部 ,而不是暴露给 LLM 自由决策,从而让回路是有界、可验证、可观测的。
第三视角 · Hook:可观测、可控制、可介入
Hook 是 Ooder 编排核的"关节",决定了系统在 Loop 跑动时能被多深入地观察、多精细地控制。整套设计有四类 Hook,分布在 Harness 的不同层次。
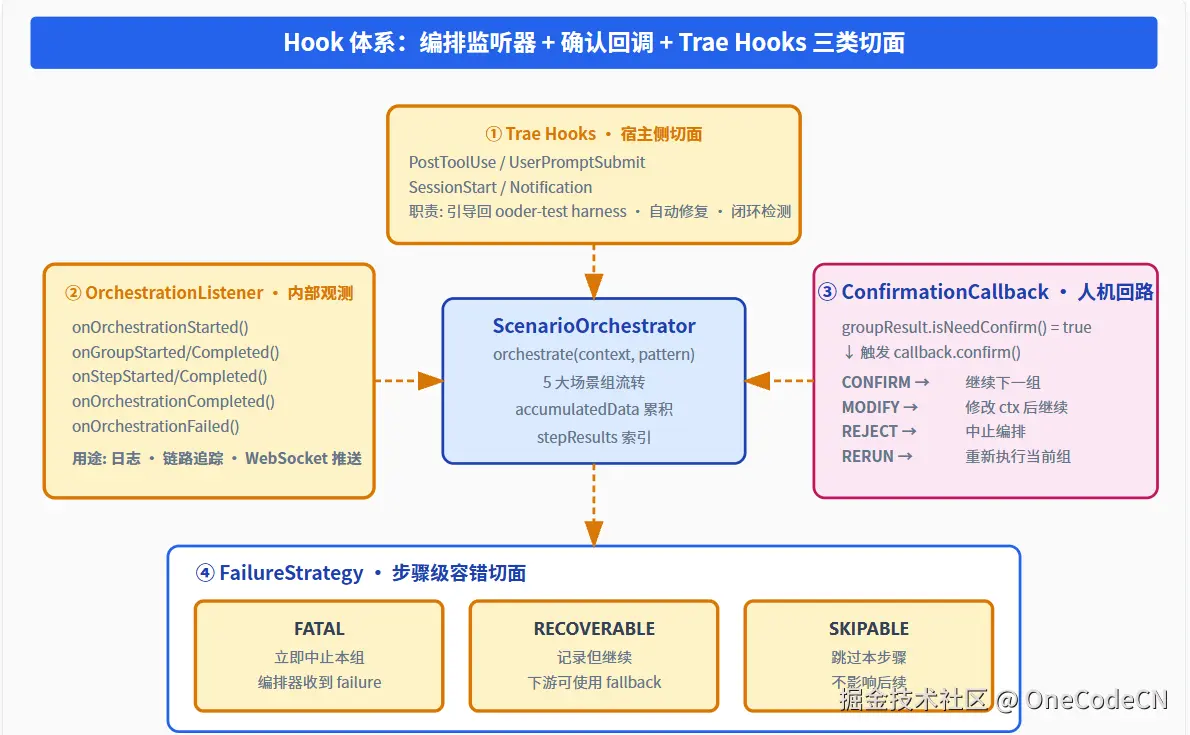
图 3 · 四类 Hook 在编排核中的位置:宿主切面、内部观测、人机回路、步骤容错
3.1 OrchestrationListener · 内部观测切面
这是最直白的一类 Hook,任何观察者都可以注册到编排器,接收 7 种生命周期事件:
javascript
public interface ScenarioOrchestrationListener {
void onOrchestrationStarted(ScenarioContext ctx, OrchestrationPattern pattern);
void onGroupStarted(String groupId, ScenarioContext ctx);
void onGroupCompleted(String groupId, ScenarioGroupResult result);
void onStepStarted(String stepId, String groupId, ScenarioContext ctx);
void onStepCompleted(String stepId, String groupId, StepResult result);
void onOrchestrationCompleted(ScenarioOrchestrationResult result);
void onOrchestrationFailed(String error, ScenarioContext ctx);
}典型用途包括:
- 日志/链路追踪
- :每个 step 入参出参写入分布式 trace;
- WebSocket 流式推送
- :实时把 step 进度推到前端,让用户看到"理解中...设计中...生成中...";
- 性能埋点
- :通过 StepResult.executionTimeMs 做 P95 监控。
3.2 ConfirmationCallback · 人机回路 Hook
这是 Ooder 区别于纯自动化 Agent 的关键设计:当某个 SceneGroup 的结果标记为 needConfirm=true(典型场景:设计阶段完成、需要用户确认架构图),编排器会暂停 Loop,调用 ConfirmationCallback,等待 4 种决策之一:
| Decision | 语义 | 行为 |
|---|---|---|
| CONFIRM | 用户确认通过 | 继续执行下一组 |
| MODIFY | 用户修改部分内容 | 修改写回 ScenarioContext,继续下一组 |
| REJECT | 用户拒绝 | 立即中止整个编排 |
| RERUN | 用户希望重做 | 重新执行当前组 |
javascript
// ScenarioOrchestratorImpl
if (groupResult.isNeedConfirm() && confirmationCallback != null) {
Decision decision = confirmationCallback.confirm(group.getGroupId(), context, groupResult);
switch (decision) {
case REJECT: return ScenarioOrchestrationResult.failure(...);
case RERUN: groupResult = group.execute(context); break;
case MODIFY:
case CONFIRM:
default: // 继续
}
}这种设计把"人类介入"提升为编排核的一等公民,而不是上层应用通过 polling 或 WebSocket 临时拼出来的能力。当一个 Agent 系统需要可信交付时(特别是会写文件、改数据库的场景),这种在 Loop 内置的确认 Hook 是必须的。
3.3 FailureStrategy · 步骤级容错切面
每个 ScenarioStep 都声明自己的失败策略,编排器据此决策"出错时往哪走":
| 策略 | 行为 | 典型用例 |
|---|---|---|
| FATAL | 立即中止本组并向上抛失败 | system_design、llm_fallback、project_integration、stepGenSPI |
| RECOVERABLE | 记录失败但继续执行后续步骤 | intent_classification、config_generation、cls_validation |
| SKIPABLE | 跳过本步骤,不影响下游 | entity_resolution、design_bridge、cls_audit |
失败策略是每个步骤自己声明的(在 Adapter 中通过 mapFailureStrategy() 静态映射),编排器只是按照声明执行,这让容错策略和业务逻辑解耦。
3.4 Trae Hooks · 宿主侧切面
位于 Harness 的最外层、Spring 应用之外的环境(如 Trae IDE)通过 .trae/hooks/*.json 注册四类钩子:
- SessionStart
- :会话启动时校验三服务(aiserver/studio/ooder-test)健康;
- UserPromptSubmit
- :用户提交 prompt 时把上下文转写到 ooder-nlp-harness;
- PostToolUse
- :工具调用后做闭环校验(NLP → 四分离 → genCode → build 通跑);
- Notification
- :异常通知和自动修复触发。
Trae Hooks 不直接进入编排核,而是在 Harness 之外把 Agent 的输入/输出引导回闭环测试管线(参见 .trae/skills/ooder-nlp-harness/SKILL.md)。这是把"编排核 + Skill 闭环测试"做成一个可持续演进系统的关键。
从硬编码双轨到 SceneGroup 编排:演进对比
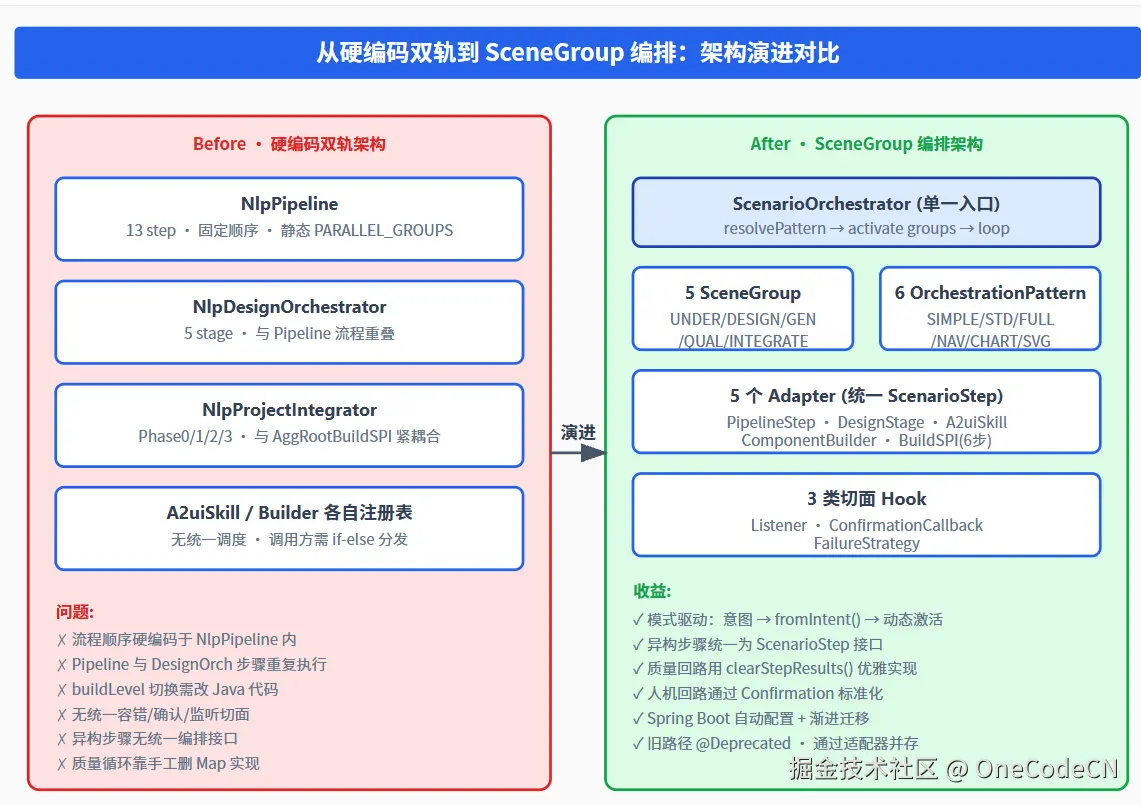
图 4 · 重构前后的架构对比
重构前的痛点
- 双轨重叠
- :NlpPipeline(13 step)与 NlpDesignOrchestrator(5 stage)在意图理解和实体建模上有重复执行;
- 硬编码顺序
- :步骤顺序写在 Pipeline 内部,新增系统类型(NAV/CHART/SVG)需要改主循环代码;
- 异构无共主
- :30 个 Skill 用注解注册、34 个 Builder 用工厂注册、5 个 Stage 用 OrderHandler 注册,调用方需要 if-else 分发;
- 容错不统一
- :每个步骤自己 try-catch,没有统一的 FATAL/RECOVERABLE/SKIPABLE 语义;
- 质量回路靠手撕 Map
- :cls_validation 失败后手动 map.remove("cls_audit"),容易漏清 accumulatedData 导致脏读。
重构后的关键改进
- 单一入口
- :宿主层只调用 scenarioOrchestrator.orchestrate(ctx),模式由意图自动推导;
- 意图驱动激活
- :6 个 OrchestrationPattern × 5 个 SceneGroup 形成 fromIntent 矩阵,新增系统类型只需扩枚举;
- 异构压平
- :5 个 Adapter 把 88+ 个异构步骤适配成同一个 ScenarioStep,编排核不感知底层差异;
- 容错标准化
- :每个步骤声明 FailureStrategy,AbstractScenarioGroup 按策略统一处理;
- 质量回路 API 化
- :ScenarioContext.clearStepResults(stepIds) 同时清理 stepResults 和 accumulatedData;
- 渐进迁移
- :旧接口 @Deprecated 标注,NlpOrchestrator.orchestrateViaScenario() 在 Bean 不可用时降级到旧路径,业务零停机。
端到端示例:一句话到一份可编译模块
以"创建一个部门管理,包含部门名称、部门编码、负责人、上级部门、创建时间字段"为例,看完整 Loop 是怎么跑的。
Step 0 · Harness 接收
javascript
POST /api/nlp/generate
{ "input": "创建一个部门管理,包含...", "projectName": "Demo", "autoSave": true,
"channel": "channel1_module_independent" }Step 1 · Pattern 推导(resolvePattern)
关键词"管理" → 系统级嫌疑 → 但只描述了单个模块 → 命中 STANDARD 模式:激活 UNDERSTAND + DESIGN + GENERATE + INTEGRATE,跳过 QUALITY。
Step 2 · SG-UNDERSTAND 组
- system_design
- (order=5):判定为 CRUD_BASED · STANDARD;
- intent_classification
- (10) + entity_extraction(20) 并行:抽取出 moduleName="DepartmentManagement", caption="部门管理", fields=name, code, leader, parent, createTime;
- entity_resolution
- (22):moduleEnglishName 转拼音、字段类型推断(leader→User引用、parent→自引用、createTime→Datetime)。
Step 3 · SG-DESIGN 组
- module_decomposition
- :单模块,跳过分解;
- four_separation
- :将字段切分为 Properties / Styles / Events / Behaviors;
- design_assembly
- :拼装为 Designer 可识别的 JSON。
Step 4 · SG-GENERATE 组
- config_generation
- (30):生成 genJson;
- A2uiSkillAdapter(skill_form)
- (20):根据 componentType=FORM 命中 FormSkill,生成 UI 配置;
- design_bridge
- (40):把 genJson 转换成 Designer 预览 payload。
这一步如果有 ConfirmationCallback,编排器会暂停等待用户在 Designer 上点确认 → 用户点 CONFIRM → Loop 继续。
Step 5 · SG-INTEGRATE 组
- project_integration
- (50):保存模块到 VFS(Phase 0);
- module_integration
- (55):处理菜单、外键引用;
- BuildStepAdapter
- 6 步链式调用 AggRootBuildSPI:
- stepGenSPI(61) → 生成 Entity 接口和 DTO;
- stepGenView(62) → 生成 View 层;
- stepGetRepository(63) → 生成 VO/DO/RepositoryService;
- stepGetAgg(64) → 生成 AggregateRoot;
- stepGenAPI(65) → 绑定 ESB;
- stepGetAggroot(66) → 全量编译 + 保存 ViewMeta。
Step 6 · 结果回写
编排器返回 ScenarioOrchestrationResult,宿主层将其转换为 NlpDesignResult(含 className、modulePath、saved 等字段),HTTP 端点流式返回给前端。
注意: 整个 Loop 中,宿主层从未感知"4 类 88+ 异构步骤"的存在 ------ 它只看到一个 ScenarioOrchestrator + 5 个 SceneGroup。这就是分层抽象的红利。
设计哲学:为什么是 SceneGroup 而不是 Step DAG
读到这里,一个自然的问题是:为什么不用 LangGraph 那种 Step DAG,或者 Temporal 那种 Workflow Activity?
论点 1:DAG 优化的是依赖,SceneGroup 优化的是语义边界
当步骤数到达 80+ 时,画 DAG 反而是负担:节点和边的拓扑爆炸,重构代价高昂。SceneGroup 把节点按语义 而不是依赖分组(理解、设计、生成、质量、集成),让每一组内部维护自己的 DAG(PARALLEL_GROUPS),组与组之间是顺序的。这种"宏观线性、微观并行"的结构对人类工程师非常友好。
论点 2:意图驱动 > 完全自由的 LLM 调度
让 LLM 自由决策"下一步用哪个工具"是 ReAct 的精髓,但在有强结构约束的工程任务 中(如代码生成),完全自由的 LLM 调度会带来不可预期的执行路径。Ooder 的折中是:意图由 LLM 推断,但 Loop 结构由模式映射。这既保留了灵活性,又保证了可观测、可重放、可审计。
论点 3:人机回路是产品要求,不是补丁
真正交付到客户手上的 Agent 系统几乎都需要人机协作(确认设计、修改字段、回滚错误)。SceneGroup 把 ConfirmationCallback 内置到 Loop 关节点,让"用户介入"成为编排核的一等公民,而不是上层 UI 通过轮询拼出来的。
论点 4:渐进式迁移高于一切
Ooder 已经有 13 个 PipelineStep + 5 个 DesignStage + 6 步 BuildSPI 在生产环境跑了一年多。任何新架构必须能包住而不是替换 这些既有资产。SceneGroup 通过 5 个 Adapter 实现"包"而不是"重写",老路径标 @Deprecated 但仍然可用,新路径通过 Spring Boot 自动配置无侵入注册。这种迁移策略让重构能在不停机不破坏既有调用方的情况下落地。
展望:从编排核到 Agent OS
SceneGroup 当前的形态解决了 Ooder 自身的编排问题,但它的边界值得继续推:
- 跨进程 Loop
- :当 Step 涉及外部 LLM/工具调用,可以把 ScenarioStep 接入 RPC 或 MCP,让 SceneGroup 同时编排本地 Java 步骤和远程 Agent。
- Loop 持久化
- :在 ConfirmationCallback 等待用户决策时,把 ScenarioContext 序列化到存储;用户重新打开页面时反序列化继续,等同于 Temporal 的 Durable Workflow。
- SceneGroup as Skill
- :让一组 SceneGroup 自己变成一个更大编排的 ScenarioStep,形成组合式编排(一个"系统级生成"由 N 个"模块级生成"组合而成)。
- 反馈学习闭环
- :把 Listener 收集的 stepResults 喂回 LLM,自动调整 OrchestrationPattern.fromIntent() 的权重 ------ 让"模式选择"本身可学习。
从这个角度看,SceneGroup 编排核更像一个面向结构化任务的 Agent OS 内核:
- 进程
- = ScenarioContext
- 调度器
- = ScenarioOrchestrator
- 系统调用
- = ScenarioStep(适配 88+ 异构能力)
- 中断
- = ConfirmationCallback
- 信号
- = OrchestrationListener
- 用户态切面
- = Trae Hooks
当我们用"操作系统"的视角看 Agent 框架,会发现现在大多数框架都还停留在"shell 脚本"阶段 ------ 每个任务都重新写一遍 if/else 调度。SceneGroup 这种把语义边界、意图驱动、人机回路、容错策略一次性烧进内核的设计,可能是面向"工程级 Agent 系统"必须迈出的一步。
这篇文章是从 harness、loop、hook 三个视角拆解 SceneGroup 的尝试。如果你正在设计自己的 Agent 编排核,希望这套结构能给你一点不同于"Step DAG / ReAct" 主流叙事的视角。
Ooder A2UI · 编排核架构系列 · agent-sdk-core 2.5.0
关键词:SceneGroup · ScenarioOrchestrator · OrchestrationPattern · Agent Loop · Hook