需求评审那天,产品指着屏幕上一棵密密麻麻的树说:「加个搜索,简单吧?」
我点头。不就是输入关键词、高亮一下嘛,半小时的活。
三天后,我还在跟虚拟滚动较劲。
第一版:搜索框接上了,树一动不动------状态更新了,压根没喂给渲染层,等于装了个没接线的门铃。第二版:过滤法上线,搜是能搜了,但树被剪成秃子,用户要在树上增删改查,节点都没了改个锤子。第三版:学浏览器 Ctrl+F,树不动、只高亮、自动展开路径、滚动定位。方案漂亮,虚拟滚动直接拍脸------视口外的节点连 DOM 都不存在,
scrollIntoView找了个空气。一个搜索框,逼出了四个方案、踩了六个坑、挖到 rc-virtual-list 的
scrollTo源码才收场。这篇文章,就是这场仗的战场记录。
一、起点:大数据量树与虚拟滚动
业务场景中,树形组件动辄上千甚至上万个节点。如果老老实实把每个节点都渲染成 DOM,浏览器直接卡死。
所以第一件事:开启虚拟滚动。
tsx
<Tree virtual height={600} />虚拟滚动的原理大家都懂:只渲染可视区域内的节点,视口外的不创建 DOM。但这恰恰是后面所有坑的根源------你没法操作一个不存在的 DOM。
二、第一版方案:过滤法------树被「剪枝」,增删改查全废了
搜索最直觉的实现:递归遍历,把不匹配的节点删掉。
tsx
const filterTree = (nodes, keyword) => {
return nodes
.map((node) => {
const children = filterTree(node.children || [], keyword);
const matched = [node.name, node.code, node.version].some((v) =>
v?.toLowerCase().includes(keyword),
);
if (!matched && !children.length) return null;
return { ...node, children };
})
.filter(Boolean);
};
<Tree treeData={filterTree(treeData, keyword)} />;搜索确实生效了。但致命问题马上暴露:
这棵树不是只读的
用户需要在树上做新增子节点、编辑、删除等操作。过滤后不匹配的分支全部消失,用户搜了一个关键词,结果整棵树只剩几条匹配项。
这时候用户想对某个不匹配的节点做操作?节点都不在了,操作按钮也没了。
更麻烦的是:filterTree 每次返回全新引用,每次按键都做一次深拷贝 + 全量递归,上千节点的树每次输入都卡顿。
结论
过滤法适用于只读展示 。但凡树上有增删改查操作,就不能用------你不能因为搜索就把用户要操作的节点删了。
三、转向 Ctrl+F:原树不变 + 高亮 + 定位 + 导航
参考浏览器的 Ctrl+F,重新定义需求:
- 原树数据完整保留,搜索时不删任何节点
- 匹配节点高亮(黄色背景),当前定位项用更深的颜色区分
- 匹配路径自动展开,其他路径收缩
- 自动滚动定位到第一个匹配项,视觉居中
- 支持上一个/下一个导航(Enter 键切换)
- 用户可手动展开/收缩任意节点,不被搜索逻辑覆盖
下面逐个讲实现中的技术细节。
四、高亮渲染:多段匹配与「当前项」区分
4.1 不是简单 indexOf,是循环切分
一个节点名称可能是 "轴承-6203-轴承6203",搜索 "6203" 会命中两处。简单做法只高亮第一处,但用户会以为漏了。
正确做法是 while 循环切分,把所有命中段都标记:
tsx
const HighlightText = ({ text, keyword, isCurrentMatch }) => {
if (!text || !keyword.trim()) return <>{text ?? ''}</>;
const kw = keyword.trim().toLowerCase();
const parts = [];
let remaining = text;
let partIndex = 0;
while (remaining) {
const idx = remaining.toLowerCase().indexOf(kw);
if (idx === -1) {
parts.push(remaining); // 剩余不匹配的部分
break;
}
if (idx > 0) parts.push(remaining.slice(0, idx)); // 匹配前的普通文本
parts.push(
<span
key={partIndex++}
className={`search-highlight ${
isCurrentMatch ? 'search-highlight--current' : ''
}`}
>
{remaining.slice(idx, idx + kw.length)}
</span>,
);
remaining = remaining.slice(idx + kw.length); // 继续切剩余部分
}
return <>{parts}</>;
};
4.2 两层高亮:匹配项 vs 当前定位项
搜索可能命中 10 个节点,但用户当前定位在第 3 个。如果颜色一样,用户分不清哪个是「当前」。
less
// 普通匹配:亮黄
.search-highlight {
background-color: #ffe58f;
border-radius: 2px;
padding: 0 1px;
}
// 当前定位项:橙色,文字变白
.search-highlight--current {
background-color: #faad14;
color: #fff;
}
// 当前定位节点整行淡橙背景
.tree-node-matched {
background-color: rgba(250, 173, 20, 8%);
border-radius: 4px;
}三层视觉层级:普通匹配(黄)→ 当前定位文字(橙底白字)→ 当前定位整行(淡橙背景)。用户一眼就知道自己在第几个。
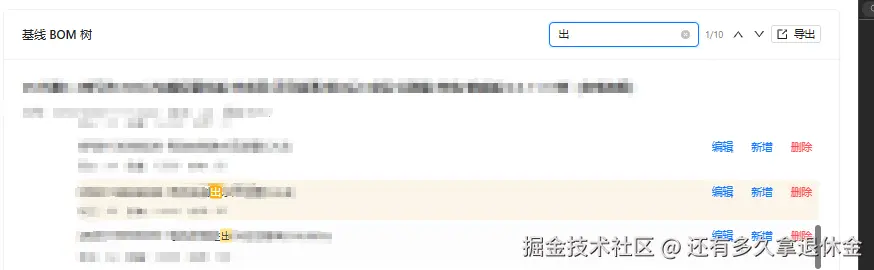
五、匹配路径展开与用户手动操作
5.1 只展开匹配祖先
不展开全部,只展开「子树中含匹配项」的节点。实现上用 ancestorKeys 传参法,一次遍历同时收集匹配 key 和展开 key:
tsx
const collectExpandKeysForMatches = (nodes, keyword) => {
const result = [];
const traverse = (items, ancestorKeys) => {
for (const node of items) {
const currentPath = [...ancestorKeys, node.key];
const matched = [node.name, node.code, node.version].some((v) =>
v?.toLowerCase().includes(keyword),
);
if (matched) {
// 命中节点 → 把所有祖先加入展开列表
ancestorKeys.forEach((key) => {
if (!result.includes(key)) result.push(key); // 去重
});
}
if (node.children?.length) {
traverse(node.children, currentPath);
}
}
};
traverse(nodes, []);
return result;
};5.2 用户手动收缩不被自动展开覆盖
这是最容易踩的坑。假设搜索命中了节点 A(在第 3 层),自动展开了 A 的祖先链路。用户觉得展开太多干扰视线,手动收缩了 A 的父节点 P。
问题 :下一次 searchExpandedKeys 重算时,P 又被自动加回展开列表------用户的收缩操作被「吞掉」了。
解法 :用 ref 记录用户主动收缩的节点 key,自动展开时排除它们:
tsx
const manuallyCollapsedRef = useRef<Set<Key>>(new Set());
// 合并展开 key:自动展开路径(排除用户收缩的)+ 用户手动展开的
const searchExpandedKeys = useMemo(() => {
if (!keyword.trim()) return expandedKeys;
const autoExpandKeys = collectExpandKeysForMatches(treeData, keyword);
// 关键:排除用户主动收缩的节点
const filteredAutoExpandKeys = autoExpandKeys.filter(
(key) => !manuallyCollapsedRef.current.has(key),
);
// 合并:自动展开 + 用户手动展开的
const merged = new Set([...filteredAutoExpandKeys, ...expandedKeys]);
return Array.from(merged);
}, [treeData, keyword, expandedKeys]);在 onExpand 回调中检测收缩操作并记录:
tsx
onExpand={(keys) => {
const newKeys = new Set(keys);
const oldKeys = new Set(searchExpandedKeys);
// old 有、new 没有 → 用户主动收缩了
oldKeys.forEach((key) => {
if (!newKeys.has(key)) {
manuallyCollapsedRef.current.add(key;
}
});
// new 有、old 没有 → 用户主动展开了,从收缩记录中移除
newKeys.forEach((key) => {
if (!oldKeys.has(key)) {
manuallyCollapsedRef.current.delete(key);
}
});
onExpandedKeysChange(keys);
}}关键词变化时清空收缩记录------新一轮搜索,一切重新计算:
tsx
const prevKeywordRef = useRef(keyword);
if (prevKeywordRef.current !== keyword) {
prevKeywordRef.current = keyword;
manuallyCollapsedRef.current = new Set(); // 清空
}六、为什么不能用 useEffect 重置?
问题
搜索匹配了 5 个节点,用户点「下一个」导航到第 3 个。此时用户修改了搜索词,匹配数变成 2 个。如果 currentMatchIndex 还是 3,访问 matchNodeKeys[3] 就是 undefined------定位到一个不存在的节点。
直觉做法(有 bug)
tsx
useEffect(() => {
setCurrentMatchIndex(0); // keyword 变了重置索引
}, [keyword]);为什么不行? useEffect 在 commit 之后异步执行。这意味着在 keyword 变化后的那一帧渲染 中,currentMatchIndex 还是旧值,matchNodeKeys 已经是新数组------索引越界,定位到错误节点。
正确做法:渲染期间同步重置
用 useRef 在渲染阶段检测 keyword 变化,在渲染期间就重置索引,确保同一帧内 index 和 matchNodeKeys 同步:
tsx
const prevKeywordRef = useRef(keyword);
// 这不是 useEffect,是渲染期间的同步逻辑
if (prevKeywordRef.current !== keyword) {
prevKeywordRef.current = keyword;
setCurrentMatchIndex(0); // React 会丢弃本次渲染,用新值重新渲染
}这段代码放在组件函数体中(不在任何 effect 或回调里),React 检测到 setState 会立即中断当前渲染、用新 state 重新渲染。这样 currentMatchIndex 和 matchNodeKeys 在同一次渲染中就是同步的。
防御性索引:safeMatchIndex
即使上面做了同步重置,仍然加一层防御:
tsx
// 始终 clamp 到合法范围,避免任何边界情况导致越界
const safeMatchIndex = matchCount > 0 ? currentMatchIndex % matchCount : 0;用取模而不是 Math.min,这样即使 currentMatchIndex 莫名其妙变成 10、matchCount 是 5,也能安全回绕到 0。
七、虚拟滚动下的精准定位------最大的坑
7.1 为什么虚拟滚动下定位这么难
虚拟列表只渲染可视区域内的节点。假设匹配的第 1 个节点在展开后排在第 800 个位置,当前视口显示第 1~30 个,那这个匹配节点根本不存在于 DOM 中。
你没法对不存在的 DOM 调用 scrollIntoView。
7.2 踩坑过程
尝试一:scrollIntoView + 重试
tsx
const tryScroll = () => {
const el = document.querySelector('.tree-node-matched');
if (el) {
el.scrollIntoView({ block: 'center' });
return;
}
if (retryCount++ < 10) setTimeout(tryScroll, 100);
};失败:虚拟列表不会主动渲染视口外的节点,重试 100 次也找不到 DOM 元素。
尝试二:Tree scrollTo + setTimeout 100ms + scrollIntoView
tsx
setTimeout(() => {
treeRef.current?.scrollTo({ key: firstKey });
setTimeout(() => {
document
.querySelector('.tree-node-matched')
·1 ?.scrollIntoView({ block: 'center' });
}, 50);
}, 100);失败 :100ms 不够稳定,expandedKeys 更新后虚拟列表需要重新计算「展开后的扁平化节点列表」(rc-tree 内部会把树拍平成数组传给 rc-virtual-list),这个计算和渲染的时机不确定。
7.3 最终方案:scrollTo 的 align + offset 参数
关键发现 :Ant Design Tree 的 scrollTo API 不只接受 key,还支持 align 和 offset 参数。这组参数能让虚拟列表一步到位地定位到目标位置,不需要额外的 DOM 操作。
tsx
useEffect(() => {
if (!currentMatchKey) return;
// 等待 expandedKeys 渲染完成后再滚动
const timer = setTimeout(() => {
treeRef.current?.scrollTo({
key: currentMatchKey,
align: 'top', // 节点先对齐到列表顶部
offset: 300, // 再向下偏移 height/2(600/2=300),视觉居中
});
}, 50);
return () => clearTimeout(timer);
}, [currentMatchKey, searchExpandedKeys]);7.4 align + offset 的原理
rc-virtual-list 的 scrollTo 内部逻辑:
- 根据
key在展开后的扁平化列表 中找到目标节点的index - 计算该节点在虚拟列表中的
offsetTop(前面所有节点高度之和) - 根据
align参数决定scrollTop的计算方式:'top':scrollTop = offsetTop(节点贴顶)'bottom':scrollTop = offsetTop - (viewportHeight - nodeHeight)(节点贴底)'auto':只在节点不可见时才滚动,可见时不滚动
- 应用
offset参数:scrollTop += offset(正值向下偏移,负值向上偏移)
所以 align: 'top' + offset: 300 的效果是:
ini
scrollTop = offsetTop(目标节点) + 300
= offsetTop + viewportHeight / 2节点从顶部向下偏移半个视口高度,恰好出现在视口正中央。
7.5 为什么比 scrollTo + scrollIntoView 组合更好?
| 方案 | 操作链路 | 风险 |
|---|---|---|
| scrollTo + scrollIntoView | Tree API 滚动 → 等 DOM 渲染 → querySelector → scrollIntoView | 两步操作,中间有 DOM 查询,时序依赖复杂 |
| scrollTo(align + offset) | Tree API 一步到位 | 单次 API 调用,无 DOM 查询,无额外渲染 |
scrollIntoView 还有个隐藏问题:它会滚动所有可滚动祖先容器 ,如果 Tree 外层还有 overflow: auto 的容器,可能引起非预期的滚动联动。scrollTo 只操作 Tree 自己的虚拟列表容器,不干扰外部布局。
7.6 为什么用 setTimeout 50ms 而不是双 rAF?
之前版本试过双 requestAnimationFrame:
tsx
requestAnimationFrame(() => {
requestAnimationFrame(() => {
treeRef.current?.scrollTo({ key, align: 'top', offset: 300 });
});
});双 rAF 的本意是等 React commit + 浏览器布局完成。但实际发现:
currentMatchKey变化时,searchExpandedKeys通常已经计算完毕(useMemo同步计算)- 但 rc-tree 内部还需要根据新的
expandedKeys重新生成扁平化节点列表,这个操作在 rc-tree 的useMemo/useEffect中完成 setTimeout 50ms比双 rAF(约 32ms)多出的十几毫秒,恰好覆盖了 rc-tree 内部的扁平化计算
实测 50ms 是一个稳定的甜点值。太小(如 16ms)偶尔会定位不到,太大(如 200ms)用户能感知到延迟。
八、完整的搜索导航交互
8.1 上一个/下一个导航
tsx
const [currentMatchIndex, setCurrentMatchIndex] = useState(0);
const goToNextMatch = useCallback(() => {
if (matchCount === 0) return;
setCurrentMatchIndex(
(prev) => (prev >= matchCount - 1 ? 0 : prev + 1), // 回环
);
}, [matchCount]);
const goToNextMatch = useCallback(() => {
if (matchCount === 0) return;
setCurrentMatchIndex((prev) => (prev >= matchCount - 1 ? 0 : prev + 1));
}, [matchCount]);回环设计:到最后一个再点「下一个」回到第 1 个,和浏览器 Ctrl+F 行为一致。
8.2 Enter 键导航 + 计数显示
tsx
<Input
value={keyword}
onChange={(e) => onKeywordChange(e.target.value)}
onPressEnter={goToNextMatch} // Enter 切换到下一个
/>;
{
keyword.trim() && (
<>
<span className="search-count">
{matchCount > 0 ? `${safeMatchIndex + 1}/${matchCount}` : '0/0'}
</span>
<Button icon={<UpOutlined />} onClick={goToPrevMatch} />
<Button icon={<DownOutlined />} onClick={goToNextMatch} />
</>
);
}显示 3/12 表示当前在第 3 个、共 12 个匹配。搜索无结果时显示 0/0,导航按钮禁用。
8.3 导航时的滚动
用户点「下一个」时,currentMatchIndex 变化 → currentMatchKey 变化 → 触发第七节的 useEffect → scrollTo 定位到新节点。整条链路自动联动,无需额外代码。
九、大数据量性能优化
9.1 虚拟滚动 + height 固定
tsx
<Tree virtual height={600} />height 必须是固定数值,不能是 100% 或 auto------rc-virtual-list 需要根据 height 计算每屏渲染多少节点。
9.2 useMemo 缓存匹配结果
tsx
const matchNodeKeys = useMemo(
() => collectMatchNodeKeys(treeData, keyword),
[treeData, keyword],
);只在 treeData 或 keyword 变化时重新计算,不在每次渲染都全量遍历。
9.3 节点组件 memo 化的陷阱
tsx
const TreeNodeTitle = memo(({ node, keyword, isCurrentMatch, ... }) => {
// ...
});注意 :memo 只在 keyword 不变时有效。一旦 keyword 变了,所有节点都会重渲染 ------因为 keyword 是每个节点的 prop。
更优的做法:把 keyword 通过 React Context 传递,而不是作为 prop 传入。这样 memo 比较时看不到 keyword 变化,只有 isCurrentMatch 变化的节点才会重渲染。
但这也有代价:Context 变化会触发所有 consumer 重渲染,和直接传 prop 效果一样。所以如果树节点数在几百以内,直接传 prop + memo 就够了,不必过度优化。
9.4 树转 DataNode 的缓存
tsx
const displayTreeData = useMemo(() => {
if (!treeData?.length) return [];
return convertToTreeData(treeData); // 递归转换,开销大
}, [treeData]);convertToTreeData 是递归转换,上千节点时开销不小,必须 useMemo。
十、踩坑总结
| 坑 | 根因 | 解法 |
|---|---|---|
| 过滤后树被剪枝,无法增删改查 | filterTree 删了不匹配节点 | 改用 Ctrl+F 思路:原树不变,只高亮 |
| 搜索时用户手动收缩被覆盖 | searchExpandedKeys 每次重算覆盖用户操作 | manuallyCollapsedRef 记录收缩操作,展开时排除 |
| keyword 变化后定位到错误节点 | useEffect 异步重置 index,有一帧不同步 | 渲染期间用 ref 同步检测并重置 |
| 索引越界访问 undefined | matchCount 变小但 index 没同步 | safeMatchIndex = index % matchCount 防御性取模 |
| scrollIntoView 找不到元素 | 虚拟列表未渲染视口外节点 | 用 Tree scrollTo API(内部操作虚拟列表) |
| scrollTo 定位到列表边缘不居中 | scrollTo 默认 align 不居中 | align: 'top' + offset: height/2 实现视觉居中 |
| scrollTo 时机不稳定 | expandedKeys 更新后 rc-tree 扁平化计算有延迟 | setTimeout 50ms 等待扁平化完成 |
十一、技术演进路线
less
大数据量树 → 必须开虚拟滚动(视口外节点无 DOM)
↓
搜索用过滤法 → 树被剪枝 → 增删改查全废
↓
改用 Ctrl+F 思路 → 原树不变 + 高亮 + 路径展开 + 导航
↓
用户手动收缩被覆盖 → manuallyCollapsedRef 隔离
↓
keyword 变化后 index 错位 → 渲染期间 ref 同步重置
↓
虚拟滚动下定位失败 → scrollTo(align:'top', offset:height/2)核心洞察 :虚拟滚动下的搜索定位,表面是「怎么滚动到某个位置」,本质是时序控制 ------展开 state 更新 → rc-tree 扁平化计算 → 虚拟列表渲染 → scrollTo 定位,每一步都有时间差,必须等上一步完成才能进行下一步。align + offset 参数把这个时序从「两步操作」简化为「一次 API 调用」,是最优雅的解法。