多路召回架构------精确→覆盖→语义三层召回与 RRF 融合实战
系列第 7 篇。前面六篇把「ES 怎么找文档、怎么打分、怎么调权」讲完了,都是单路召回视角。但医药搜索的真实场景里,单路召回根本不够------用户搜「阿莫西林」,可能要匹配「阿莫西林胶囊」「羟氨苄青霉素」(通用名别名)、「Amoxicillin」(中英文混输)。一条路走到底,召回的天花板很低。这篇讲我们落地的一套三层召回架构:精确→覆盖→语义,以及 RRF 多路融合机制。
一、为什么需要多路召回
1.1 单路 BM25 的困境
用户搜「阿莫西林 0.25g」,BM25 召回:
- 命中了「阿莫西林胶囊 0.25g*24 粒」------文本匹配,没问题
- 漏掉了「羟氨苄青霉素 0.25g」------这是阿莫西林的通用名别名,BM25 看不到
- 漏掉了「amoxicillin capsules 0.25g」------英文名,分词后和「阿莫西林」没有重叠词项
BM25 的天花板:必须在倒排索引中有共同词项。语义相关的词(「阿莫西林」和「羟氨苄青霉素」)在 BM25 的世界里是完全无关的。
1.2 单路向量召回的困境
换成纯向量召回(dense vector):
- 能召回「羟氨苄青霉素」------语义相似度抓住了
- 但「阿莫西林」和「阿莫西林克拉维酸钾」的向量距离几乎一样------精确度不如 BM25
- 「感康」和「感冒灵」在向量空间里很近,但这是两种完全不同的药------过度泛化
向量召回的天花板:语义泛化会导致精确度下降,区分不了近似但不相同的实体。
1.3 出路的思路
不是 BM25 vs 向量二选一,而是两者同时召回,各取所长。BM25 保证精确匹配的优先性,向量召回补充语义相关的长尾商品。再加一层精确命中兜底------形成三层架构。
二、三层召回架构全景
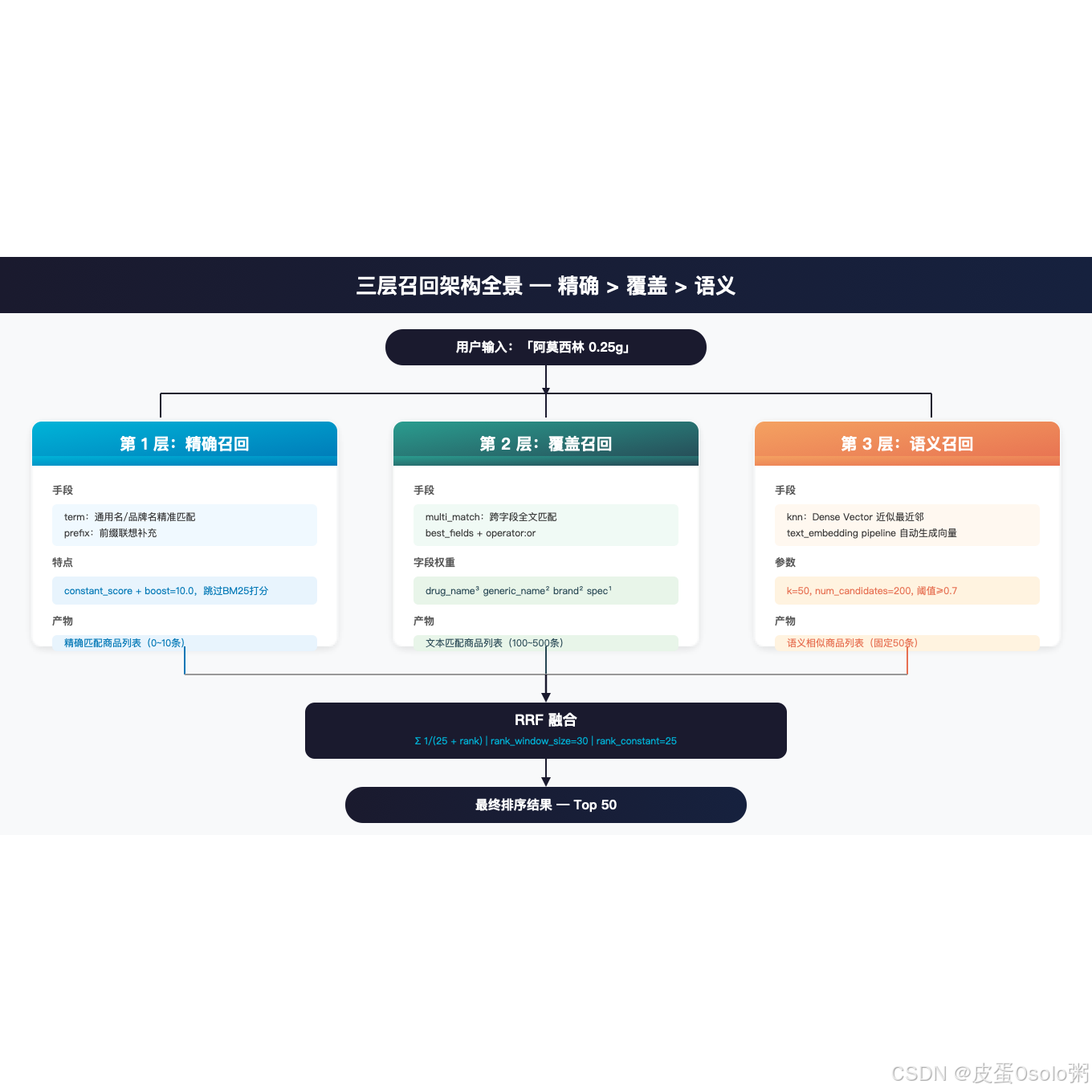
第一层:精确召回(Exact Match)
目的:用户输入和商品名/通用名/批准文号精确匹配------这一层的召回必须是「就是它」,零容忍误召回。
| 手段 | 适用字段 | 示例 |
|---|---|---|
term 查询 |
通用名、品牌名 | 「阿莫西林」→ 通用名字段精准匹配 |
prefix 查询 |
输入联想 | 「阿莫」→ 前缀匹配补充 |
wildcard 查询 |
批准文号 | 「国药准字H*」→ 模式匹配 |
| 拼音/别名倒排 | 别名字段 | 「amx」→ 别名索引命中 |
json
{
"query": {
"bool": {
"should": [
{ "term": { "generic_name.keyword": "阿莫西林" } },
{ "term": { "brand_name.keyword": "阿莫西林" } },
{ "prefix": { "generic_name.keyword": "阿莫西林" } },
{ "term": { "alias": "amoxicillin" } }
],
"minimum_should_match": 1
}
}
}关键设计 :精确召回的 boost 设得高(如 10.0),确保精确匹配的结果在融合阶段不会被覆盖层淹掉。
第二层:覆盖召回(BM25 Full Text)
目的:保证只要有文本重叠的都能回来,保障召回的基本盘。
json
{
"query": {
"multi_match": {
"query": "阿莫西林 0.25g",
"fields": [
"drug_name^3",
"generic_name^2",
"brand_name^2",
"indications^0.5",
"specification^1"
],
"type": "best_fields",
"operator": "or"
}
}
}字段权重设计思路:
drug_name^3:商品名称权重最高generic_name^2:通用名次之brand_name^2:品牌名同等specification^1:规格信息重要但不主导indications^0.5:适应症信息是辅助,权重低
第三层:语义召回(Dense Vector)
目的:捕获文本不重叠但语义相关的商品------这是 BM25 完全做不到的。
json
{
"knn": {
"field": "drug_name_vector",
"query_vector": [0.12, -0.34, ...],
"k": 50,
"num_candidates": 200
}
}向量生成 :我们用的是 ES 8.x 的 text_embedding pipeline,写入时自动通过 _inference 端点调用嵌入模型生成向量:
json
// ingest pipeline
{
"processors": [
{
"inference": {
"model_id": "text-embedding-3-small",
"target_field": "drug_name_vector",
"field_map": { "drug_name": "text_field" }
}
}
]
}写入时一个文档,ES 自动生成向量。查询时同理,knn 查询接收文本、在 query 阶段自动转为向量再做 ANN 检索。
三、三层召回如何协作------不是简单并列
3.1 层级关系
用户输入
│
├── 第 1 层:精确召回(term/prefix/wildcard)
│ 条件:必须匹配,boost=10.0
│ 产物:精确匹配的商品列表(通常 0~10 条)
│
├── 第 2 层:覆盖召回(BM25)
│ 条件:宽松匹配,boost=1.0
│ 产物:文本匹配的商品列表(通常 100~500 条)
│
└── 第 3 层:语义召回(Dense Vector)
条件:k=50, num_candidates=200
产物:语义相似的商品列表(固定 50 条)层级关系不是简单的「三个 query 加起来」。核心设计逻辑:
- 第 1 层必须命中------精确匹配的商品无条件排前面,不管 BM25 分多低
- 第 2 层是基本盘------保证万无一失,啥都能召回
- 第 3 层是增量------补充 BM25 召不回的语义相关商品
3.2 为什么不是并列三路?
如果把三个 query 平级放在 should 里:
json
{ "should": [
{ "term": { ... } },
{ "match": { ... } },
{ "knn": { ... } }
]}那精确匹配的优势会因为 BM25 打分过高而被淹没。比如:
- 精确匹配「阿莫西林校准片」vs「阿莫西林」
- 「阿莫西林校准片」在
drug_name字段有更多匹配,BM25 分更高 - 结果「校准片」(不相关的商品)排在了「阿莫西林」(用户想要的)前面
解决方案 :精确匹配不给它们走 BM25 的机会,用 ES 的 constant_score + 高 boost 直接赋予固定高分,跳过文本相关性计算。
四、RRF 融合机制------多路召回的粘合剂
4.1 问题:不同路的分数不可比
| 召回路径 | 分数范围 | 打分逻辑 |
|---|---|---|
| 精确匹配 | 0 或 10(固定) | constant_score |
| BM25 | 0~30 | 词频、长度归一化 |
| 向量 | 0.0~1.0(余弦相似度) | 向量距离 |
这三路的分数没有任何可比性。 BM25 的 5 和向量的 0.8 谁更好?没法比。直接按分数排序,排序结果没有意义。
4.2 RRF 的解法
Reciprocal Rank Fusion(RRF)的核心思想:不看分数,看排名。

RRF_score(d) = Σ 1 / (k + rank_i(d))其中:
k:平滑常数,防止排名太靠前的文档主导结果(默认 60,我们设 25)rank_i(d):文档 d 在第 i 路召回中的排名(从 1 开始)
计算示例:
| 文档 | BM25 排名 | 向量排名 | 精确匹配排名 | RRF 分数 |
|---|---|---|---|---|
| 商品 A | 1 | 5 | - | 1/(25+1) + 1/(25+5) = 0.072 |
| 商品 B | 3 | 1 | - | 1/(25+3) + 1/(25+1) = 0.074 |
| 商品 C | 2 | 3 | 1 | 1/(25+2) + 1/(25+3) + 1/(25+1) = 0.117 |
商品 C 因为在三路都排名靠前,RRF 分数最高。B 虽然在 BM25 只有第 3,但向量第 1,综合分高于 A。
4.3 ES 8.x 的 RRF 配置
json
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"bool": {
"should": [
{ "term": { "generic_name.keyword": { "value": "阿莫西林", "boost": 10.0 } } },
{ "term": { "brand_name.keyword": { "value": "阿莫西林", "boost": 10.0 } } }
]
}
}
}
},
{
"standard": {
"query": {
"multi_match": {
"query": "阿莫西林",
"fields": ["drug_name^3", "generic_name^2", "brand_name^2"]
}
}
}
},
{
"knn": {
"field": "drug_name_vector",
"query_vector_builder": {
"text_embedding": {
"model_id": "text-embedding-3-small",
"model_text": "阿莫西林"
}
},
"k": 50,
"num_candidates": 200
}
}
],
"rank_window_size": 30,
"rank_constant": 25
}
}
}4.4 参数调优效果
我们从默认参数调整到生产参数后的对比:
| 参数 | ES 默认 | 我们的配置 | 调整原因 |
|---|---|---|---|
rank_constant (k) |
60 | 25 | 降低使排名权重更敏感,精确匹配的第 1 名优势更明显 |
rank_window_size |
100 | 30 | 只考虑每路前 30 名的排名,后面的一视同仁------减少尾部噪音 |
num_candidates |
- | 50(knn),200(ANN) | 200 候选集足够覆盖语义空间,50 个结果的上限控制耗时 |
实际性能数据:
BM25 单路:194ms
向量召回单路:2.21s
RRF 三路融合:~2.5s性能分析:瓶颈在向量召回(2.21s),不在 RRF 本身。RRF 的排名融合只在 30 × 50 的矩阵上做数学运算,微秒级别。
五、多路召回的去重与归一化
5.1 文档去重
三路可能召回同一个文档(BM25 命中了,向量也命中了)。RRF 天然处理了去重------同一个文档在不同路上的排名各自贡献分数。
但需要注意:ES 的 rank_window_size 对去重的影响。如果 BM25 某文档排第 31 名(不在 rank_window 内),但向量路排第 1 名------BM25 这一路对它来说就是没有贡献的。这不是 bug,而是有意为之:不在窗口内的排名被视为「未命中」,不参与 RRF 计算。
5.2 score 的置信度衰减
同一个文档被 3 路都命中 vs 只被 1 路命中------前者更「可信」。RRF 天然实现了这个效果:被越多路召回、排名越靠前,RRF 分数越高。
这是 RRF 相比「各路子查询 should 加分」的重大优势------不需要手动调 boost,排名靠前自然贡献更多。
六、坑与解法
6.1 向量召回延迟问题
现象:整个请求 2.5 秒,其中 2.21 秒在等向量召回。
根因 :model_text 需要在 query 阶段调用外部嵌入模型生成查询向量,有一轮网络 I/O。
解法:
- 查询向量缓存:高频查询词(如「阿莫西林」)预计算向量,查询时直接复用,省掉 inference 调用
- HNSW 参数调优 :减少
num_candidates、增加ef_search------权衡精度和速度 - 异步召回:向量召回可以异步执行,先返回 BM25+精确匹配的结果,向量召回结果追加补充(需要客户端支持多轮渲染)
6.2 精确匹配过度严格
现象:用户搜「阿莫西林胶囊」,精确匹配第 1 层没命中(因为精确匹配的 term 查询要求字段值和查询完全一致)。
解法 :精确匹配不只是 term,扩展为「精确匹配层」:
term:完全一致prefix:前缀匹配match_phrase:短语包含
6.3 RRF 融合后排序异常
现象:某不相关商品因为向量召回排名靠前,RRF 综合分偏高,排在 BM25 高相关商品前面。
根因:向量模型的泛化能力太强,把不相关的商品带进来了。
解法:
- 向量相似度阈值:低于 0.7 的向量结果直接丢弃,不进入 RRF
- 精确匹配层兜底:精确命中的,不管 RRF 分数多少,直接排前面
- 增加后处理过滤:业务规则过滤(如过期商品、禁售商品)
七、Java 侧的适配
在 Spring AI + Java Client 中实现 RRF 的配置:
java
// 构建 RRF retriever
RetrieverBuilderContainer rrfRetriever = RetrieverBuilder.of(r -> r
.rrf(rrf -> rrf
.retrievers(List.of(
// 第 1 路:精确匹配
RetrieverBuilder.of(r1 -> r1
.standard(s -> s
.query(Query.of(q -> q
.bool(b -> b
.should(List.of(
Query.of(qt -> qt.term(t -> t
.field("generic_name.keyword")
.value(v -> v.stringValue("阿莫西林"))
.boost(10.0f)
))
))
))
))
)),
// 第 2 路:BM25
RetrieverBuilder.of(r2 -> r2
.standard(s -> s
.query(Query.of(q -> q
.multiMatch(mm -> mm
.query("阿莫西林")
.fields(List.of("drug_name^3", "generic_name^2"))
))
))
)),
// 第 3 路:向量
RetrieverBuilder.of(r3 -> r3
.knn(k -> k
.field("drug_name_vector")
.k(50)
.numCandidates(200)
.queryVectorBuilder(qv -> qv
.textEmbedding(te -> te
.modelId("text-embedding-3-small")
.modelText("阿莫西林")
))
))
))
)
.rankWindowSize(30)
.rankConstant(25)
))
);
SearchRequest request = SearchRequest.of(s -> s
.index("drugs")
.retriever(rrfRetriever._toRetriever())
);注意:ES 8.x 的 retriever API 在 Java Client 中可能还没有完美的类型化支持,必要时用 withJson() 方式兜底。
八、面试怎么讲
面试官:你们召回怎么做的?BM25 够吗?
标准答题思路:
1. 先讲为什么单路不够:BM25 需要文本重叠,向量需要语义但容易泛化。两者互补,所以多路。
2. 画三层架构:精确层(免召回错误)→ 覆盖层(BM25 保底)→ 语义层(向量补充),不是并列三路而是层级设计。
3. 讲 RRF :三路分数不可比,用排名融合。公式讲清楚 1/(k+rank),以及 rank_constant 从 60 调 25 的原因。
4. 丢数据:BM25 194ms,向量 2.21s,RRF 融合 ~2.5s。瓶颈在向量 inference,不在融合。
5. 丢坑:向量泛化过度导致不相关商品排前------用相似度阈值 + 精确层兜底解决。
九、小结
| 记住这些 | 细节 |
|---|---|
| 三层架构 | 精确(term/prefix)→ 覆盖(BM25)→ 语义(向量),不是并列是层级 |
| 精确层策略 | constant_score + 高 boost,跳过 BM25 打分 |
| RRF 公式 | Σ 1/(k+rank),不看分数看排名 |
| 参数调优 | k=25(更敏感)、rank_window_size=30(减少尾部噪音) |
| 性能数据 | BM25 194ms,向量 2.21s,瓶颈在向量不在 RRF |
| 坑 | 向量泛化过度→相似度阈值;延迟→查询向量缓存 |
下一篇预告 :第 8 篇------排序三阶段:粗排→精排→重排,ESPreRankingCommand 开发经验。