
🎯 博主简介
CSDN 「新星创作者」 ,人工智能技术领域博主,码龄 5 年 ,累计发布
190+ 篇原创文章,博客总访问量30万+浏览。
🚀 持续更新 AI 前沿实战知识,专注于 AI 技术实战、RAG 系统、Agent 应用开发与大模型工程化落地。目前主要更新方向包括:
- 🦞 最新 OpenClaw 教程 ---从入门到精通|AI 智能助手/自动化/Skills 实战(原 Clawdbot/Moltbot)
- ✨ Agent 记忆系统 --- 长期记忆、上下文管理与个性化智能体设计
🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥以下系列正在火热更新中🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥- 📘 图解机器学习合集 --- 用图解方式系统梳理机器学习核心概念,持续更新中
同时也会持续分享 AI 编程、Java 后端、Spring 生态、Transformer、大模型基础、计算机视觉 等方向内容,内容会尽量结合自己的学习记录、项目实践和踩坑经验来整理。
📱GZH:安逸Ai(科技前沿新闻,Github热门项目,最新免费资料...)- 网页观看完整系列合集:🌐 Anyi AI 学习资源站

数据、特征、标签:机器学习到底在学什么?
上篇我们说了,机器学习就是让计算机从数据中自己发现规律。
但你有没有想过这个问题:
模型拿到一堆数据后,它到底在学什么?
你以为它在"看"数据本身?
Naive。
它看的不是数据,是数据的"特征"。
特征:数据的"灵魂照片"
给你一张图片。
原始文件可能是几百万个像素点。每个像素有RGB三个值,每个值从0到255。
你说模型看到这个能学会"这是猫"?
相当于给你一本天书,每个字你都认识,但连起来完全不知道啥意思。
特征工程要做的,就是把这本天书翻译成人能看懂的内容。
猫有什么特征?
尖耳朵、胡子、瞳孔是竖着的、会喵喵叫。
把这些特征提取出来,喂给模型,它才能学会判断。
模型学习的不是像素,而是像素背后的规律。
我之前做过一个图像分类项目,同一批猫狗照片,换了特征提取方法后准确率直接从72%跳到89%。这事让我深刻认识到------同样一组数据,特征工程做得好不好,直接决定模型的天花板在哪。
数值特征:让不同量级的东西能"公平对话"
假设你在预测房价。
有两个特征:面积(50-200平米)、房间数(1-5个)。
面积动不动就是几十上百,房间数最大才5。
如果直接丢给模型,模型会怎么想?
"面积影响大,房间数影响小。"
但实际上房间数可能同样重要。
问题出在哪儿?
量级不一样,模型就会厚此薄彼。
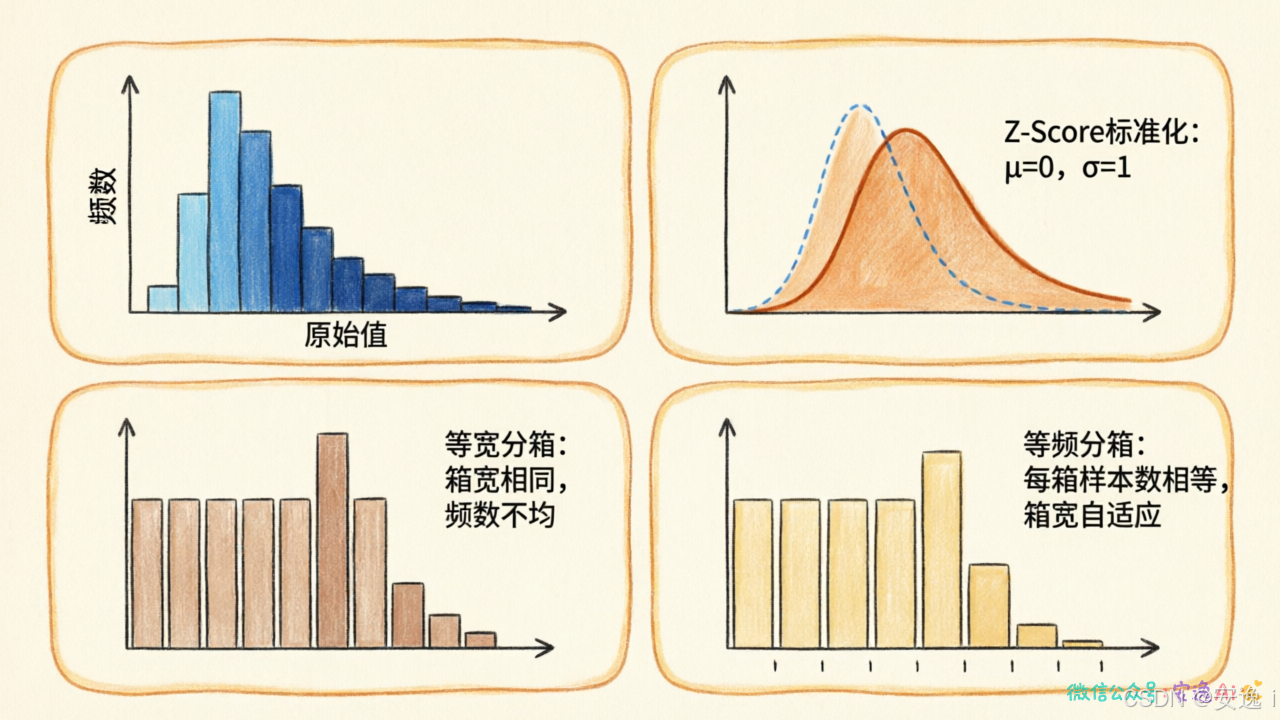
解决方案是归一化,把数值缩放到同一个范围,比如0到1。面积大的被压缩,房间数小的被放大,处理后模型才能公平地看待每个特征。
还有偏态分布的问题。比如收入数据,大部分人月入几千,但有几个亿万富翁。直接用会把少数异常值的影响放大,这时候需要对数变换,把跨度大的数据压缩。
还有一个实用技巧:分箱。
把连续值切成一段一段的。比如把年龄段分成"未成年、青年、中年、老年"。原来模型要记住每个年龄的规律,现在只需要记住4个区间。简单多了,效果反而可能更好。
类别特征:把"文字"翻译成"数字"
模型只认识数字,但现实数据里到处都是文字。
城市:北京、上海、广州、深圳
职业:医生、教师、工程师
这些怎么喂给模型?
标签编码------给每个类别编个号。北京=1,上海=2,广州=3,深圳=4。简单,占用内存小。
但有个问题:模型会以为深圳"比"北京大两倍。明明是并列关系,被你搞成了层级关系。
虚假的大小关系,会误导模型。
独热编码------把每个类别变成一列,用0和1表示。
北京:1,0,0,0
上海:0,1,0,0
这样模型就知道它们是平等的。但有个副作用:维度爆炸。全国几百个城市,就变成几百列。绝大部分都是0。
我的经验是:类别之间没有顺序关系,用独热;类别数量少,用独热;类别数量特别多(比如几万个商品ID),用目标编码或频率编码。根据统计规律来压缩维度,而不是硬编码。
文本和时间:最难啃的骨头
文本是种特殊的数据。
"这个电影太好看了"和"这个电影太烂了"。
字面上80%相同,意思完全相反。
传统方法叫TF-IDF。统计每个词在当前文档出现多少次,在其他文档出现多少次。高频出现但其他文档少见的词,就是关键词。
比如这篇影评,"太好看了"出现1次,"电影"出现1次。"电影"可能每篇影评都会出现,权重低。"太好看了"更能代表正面情绪。
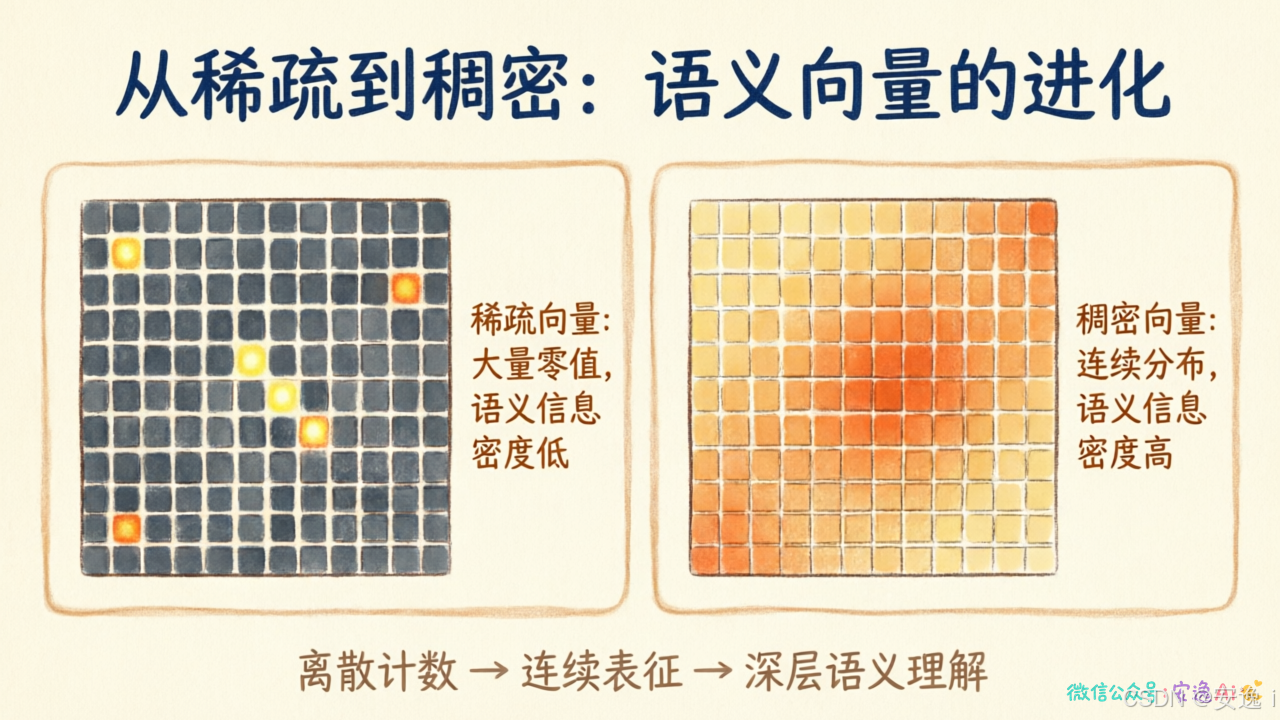
但TF-IDF太浅了------它只知道"看了"这个词,不知道你说的是"电影好看"还是"电影难看"。
现代方法用句子嵌入,把整句话压缩成一个向量。这个向量捕获了语义信息。"太好看了"和"太烂了"的向量方向相反,模型就能区分了。
这就是为什么现在推荐系统那么准------它理解你说的话了,不只是数词频。
时间特征也有讲究。
日期不能直接丢给模型。你说2024年1月1日和2024年12月31日,数值上差364,但它们其实是相邻的两天。
怎么办?做周期编码。把小时拆成正弦和余弦两个分量。这样0点和23点,在模型眼里是"相邻"的------因为它们的正弦余弦值几乎一样。捕获季节性模式,道理就这么简单。
数据质量:缺胳膊少腿怎么办?
真实数据总有各种问题。缺失值,最常见。用户懒得填,表单有bug,数据丢了。
怎么处理?三种思路。
直接删------简单粗暴,但浪费数据。相当于考试遇到不会的题,直接整张卷子不交了。
猜一个填进去------均值、中位数、众数,看情况用。最常见,效果还行,但终究是"猜"的。
用模型预测------用其他特征来预测这个缺失的值。准确率更高,但实现复杂。相当于带参考书补做,比瞎猜强多了。
还有异常值。房价预测里混入了一个0元的房子。用户输错了?恶意刷单?不管什么原因,这个数据会严重干扰模型。
检测方法:3σ原则(数值离均值超过3个标准差)、箱线图(超过1.5倍四分位距)、密度方法(看周围有没有邻居)。
发现了怎么办?删除、替换、或者单独建模。看业务场景决定。
特征选择:Less is More
特征是不是越多越好?
还真不是。
多了会有问题:冗余(两个特征说同一件事)、噪声(不相关信息干扰)、维度灾难(维度越高,需要的数据量指数增长)。
怎么办?删。
删除低方差特征------大家都是同一个值,没信息量。
删除高相关特征------身高和体重相关性0.9,留一个就够了。
用模型自带的重要性评分,比如XGBoost能告诉你每个特征贡献了多少。
或者用SHAP值,解释每个特征对单次预测的影响。
好的特征工程,是让模型用最少的原料,做出最好的预测。
就像写简历。HR没时间看十页纸,把最核心的优势放第一页,反而更容易被记住。
机器学习真正学的是什么?
现在回答开篇的问题。
模型学的不是数据本身,而是特征和标签之间的映射关系。
数据是原料,特征是加工后的食材,模型是厨师。同样的数据,特征工程做得好,模型就能化腐朽为神奇;做得差,再好的算法也是巧妇难为无米之炊。
所以下次有人吹嘘"我们用了最先进的人工智能模型",你可以问一句:你们的特征工程是怎么做的?这往往才是真正拉开差距的地方。
好了,特征工程搞懂了,数据也准备好了。但还有一个关键问题:
这些数据怎么划分?训练用多少?验证用多少?测试用多少?
比例不对,可能导致过拟合,可能导致评估结果不准确。下一期我们就来聊聊这个看似简单、但踩坑无数的问题。