Ai-Agent学习历程------ 阶段4------LangGraph 与 Harness
- 前情提要
- 学习地图&大纲
-
- [一、 StateGraph 与 Schema (定义上下文)](#一、 StateGraph 与 Schema (定义上下文))
- [二、 Nodes & Edges (图流转与条件路由)](#二、 Nodes & Edges (图流转与条件路由))
- [三、 Harness 容错拦截 (增强系统鲁棒性)](#三、 Harness 容错拦截 (增强系统鲁棒性))
- [四、 Checkpointer 记忆持久化 (断点与短程恢复)](#四、 Checkpointer 记忆持久化 (断点与短程恢复))
- [五、 Human-in-the-loop 人工审批 (人机协同机制)](#五、 Human-in-the-loop 人工审批 (人机协同机制))
- [一、 StateGraph 与 Schema (定义上下文)](#一、 StateGraph 与 Schema (定义上下文))
-
- [1.1 核心概念:状态机与全局上下文](#1.1 核心概念:状态机与全局上下文)
-
- [(1)用 Java 思维理解 StateGraph](#(1)用 Java 思维理解 StateGraph)
-
- [1. 实战:在 Python 中定义 Schema 并初始化图](#1. 实战:在 Python 中定义 Schema 并初始化图)
- [2. 这三种 Schema 在工程选型上怎么挑?](#2. 这三种 Schema 在工程选型上怎么挑?)
- [3. 为什么 LLM Agent直接选择 MessagesState](#3. 为什么 LLM Agent直接选择 MessagesState)
- [(2)在 Python 中如何定义 Schema](#(2)在 Python 中如何定义 Schema)
-
- [1. TypedDict:贫血模型 DTO](#1. TypedDict:贫血模型 DTO)
- [2. Pydantic (BaseModel):充血模型 / 强校验 DTO](#2. Pydantic (BaseModel):充血模型 / 强校验 DTO)
- [3. MessagesState:开箱即用的快捷 Schema](#3. MessagesState:开箱即用的快捷 Schema)
- [1.2 状态的更新与 Reducer 机制](#1.2 状态的更新与 Reducer 机制)
-
- [1. 默认行为:增量返回与局部覆盖](#1. 默认行为:增量返回与局部覆盖)
-
- [(1)Java 思想映射:`Map.putAll()` / `PATCH` 请求](#(1)Java 思想映射:
Map.putAll()/PATCH请求)
- [(1)Java 思想映射:`Map.putAll()` / `PATCH` 请求](#(1)Java 思想映射:
- [2. 突破默认:Reducer 与 `Annotated` 的魔法](#2. 突破默认:Reducer 与
Annotated的魔法) -
- [(1)Python 语法糖:`Annotated` 到底是个啥?](#(1)Python 语法糖:
Annotated到底是个啥?) - [(2)`add_messages` 的高级合并逻辑(不仅是 Append)](#(2)
add_messages的高级合并逻辑(不仅是 Append))
- [(1)Python 语法糖:`Annotated` 到底是个啥?](#(1)Python 语法糖:
- [3. 实战代码:亲眼看看"覆盖"与"追加"的区别](#3. 实战代码:亲眼看看“覆盖”与“追加”的区别)
- [1.3 底层流转:Pregel 引擎的并发与事务魔法](#1.3 底层流转:Pregel 引擎的并发与事务魔法)
-
- [1. 为什么节点只需要返回"局部字典"?](#1. 为什么节点只需要返回“局部字典”?)
- [2. Pregel 引擎的并发魔法与安全防御](#2. Pregel 引擎的并发魔法与安全防御)
-
- [(1)什么叫"整体同步并行 (BSP)"?](#(1)什么叫“整体同步并行 (BSP)”?)
- [(2)⚠️ 致命危机:并行节点的"多写冲突"](#(2)⚠️ 致命危机:并行节点的“多写冲突”)
- [(3)完美解药:用 Reducer 化解并发冲突](#(3)完美解药:用 Reducer 化解并发冲突)
- [1.4 ⚠️ 避坑指南:防止全局 Schema 被过度污染](#1.4 ⚠️ 避坑指南:防止全局 Schema 被过度污染)
-
- [1. 常见的设计坏味道:上帝对象 (God Object) 与 Fat Session](#1. 常见的设计坏味道:上帝对象 (God Object) 与 Fat Session)
-
- (1)灾难现场还原
- [(2)Java 视角类比:把所有表合并成一张"大宽表"](#(2)Java 视角类比:把所有表合并成一张“大宽表”)
- [2. 正确解法:引入 Subgraph (子图) 机制](#2. 正确解法:引入 Subgraph (子图) 机制)
- [🌟 第一章 全面总结 (Checkpoint)](#🌟 第一章 全面总结 (Checkpoint))
- [二、 Nodes & Edges (图流转与条件路由)](#二、 Nodes & Edges (图流转与条件路由))
-
- [2.1 节点与控制流 (Nodes & Normal Edges)](#2.1 节点与控制流 (Nodes & Normal Edges))
-
- [1. 节点的双重形态:同步与异步](#1. 节点的双重形态:同步与异步)
- [2. 实战代码:构建一条包含异步节点的线性流水线](#2. 实战代码:构建一条包含异步节点的线性流水线)
- [3. 普通边的局限性](#3. 普通边的局限性)
- [2.2 Conditional Edges (条件路由)](#2.2 Conditional Edges (条件路由))
-
- [1. 为什么需要条件边?(动态路由)](#1. 为什么需要条件边?(动态路由))
-
- [(1)Java 视角映射:排他网关与 Switch-Case](#(1)Java 视角映射:排他网关与 Switch-Case)
- [2. 核心运转机制:Router 与 Path Map](#2. 核心运转机制:Router 与 Path Map)
- [3. 实战代码:写一个会思考的动态路由](#3. 实战代码:写一个会思考的动态路由)
- [4. 理解路由机制的核心](#4. 理解路由机制的核心)
- [5. 生产层次的架构思考:优雅的动态路由和工具调用](#5. 生产层次的架构思考:优雅的动态路由和工具调用)
-
- [(1)普通生产级解决方式:Function Calling & ToolNode](#(1)普通生产级解决方式:Function Calling & ToolNode)
- (2)进阶方案:动态工具检索
- [2.3 🛡️ 防御机制 (防死循环)](#2.3 🛡️ 防御机制 (防死循环))
-
- [1. 灾难重现:无限死循环 (Infinite Loop)](#1. 灾难重现:无限死循环 (Infinite Loop))
- [🛡️ 第一道防线:全局熔断器 (Recursion Limit)](#🛡️ 第一道防线:全局熔断器 (Recursion Limit))
-
- [(1)Java 视角映射:微服务熔断 (Circuit Breaker)](#(1)Java 视角映射:微服务熔断 (Circuit Breaker))
- (2)如何配置?
- [🛡️ 第二道防线:优雅降级感知 (RemainingSteps 机制)](#🛡️ 第二道防线:优雅降级感知 (RemainingSteps 机制))
- [3. 防死循环的哲学](#3. 防死循环的哲学)
- [4. 基于现在流行的长任务思考](#4. 基于现在流行的长任务思考)
-
- (1)引入断点持久化(Checkpointer,第四章将学)
- [(2)Map-Reduce 与 动态子图分发(Send API)](#(2)Map-Reduce 与 动态子图分发(Send API))
- (3)人机协同(Human-in-the-Loop,第五章将学)
- [2.4 ⚠️ 避坑指南:条件边的运行时 ValueError](#2.4 ⚠️ 避坑指南:条件边的运行时 ValueError)
-
- [1. 灾难现场:潜伏在运行时的 ValueError](#1. 灾难现场:潜伏在运行时的 ValueError)
- [2. 破局之道:如何彻底消灭路由配置 Bug?](#2. 破局之道:如何彻底消灭路由配置 Bug?)
-
- [(1)防线一:使用 `Literal` 限制返回值 (类型层面的 Enum)](#(1)防线一:使用
Literal限制返回值 (类型层面的 Enum)) - [(2)防线二:省略 path_map 的"隐式路由"(高级技巧)](#(2)防线二:省略 path_map 的“隐式路由”(高级技巧))
- [(1)防线一:使用 `Literal` 限制返回值 (类型层面的 Enum)](#(1)防线一:使用
- [🌟 第二章 全面总结 (Checkpoint)](#🌟 第二章 全面总结 (Checkpoint))
- [三、 Harness 容错拦截 (增强系统鲁棒性)](#三、 Harness 容错拦截 (增强系统鲁棒性))
-
-
- [3.1 实战:配置网络层面的 Spring Retry](#3.1 实战:配置网络层面的 Spring Retry)
-
- [1. 核心对象:`RetryPolicy`](#1. 核心对象:
RetryPolicy) - [2. 代码实战](#2. 代码实战)
- [1. 核心对象:`RetryPolicy`](#1. 核心对象:
- [3. 为什么必须要加 `jitter=True`?](#3. 为什么必须要加
jitter=True?)
- [3.2 大模型逻辑自愈 (Self-Correction & Loop Guard)](#3.2 大模型逻辑自愈 (Self-Correction & Loop Guard))
-
- [1. 把 Exception 变成 Prompt(提示词)](#1. 把 Exception 变成 Prompt(提示词))
-
- [(1)Java 视角映射:全局异常处理器 `@ControllerAdvice`](#(1)Java 视角映射:全局异常处理器
@ControllerAdvice)
- [(1)Java 视角映射:全局异常处理器 `@ControllerAdvice`](#(1)Java 视角映射:全局异常处理器
- [2. 实战代码:构建"带防死循环"的自愈闭环](#2. 实战代码:构建“带防死循环”的自愈闭环)
- [3. 解析](#3. 解析)
- [3.3 Agent Harness 中间件层 (代理脚手架)](#3.3 Agent Harness 中间件层 (代理脚手架))
-
- [1. 架构痛点:为什么需要 Harness (中间件)?](#1. 架构痛点:为什么需要 Harness (中间件)?)
- [2. Python 语法糖补充:高阶函数与装饰器](#2. Python 语法糖补充:高阶函数与装饰器)
- [3. 实战代码:打造一个纯粹的 AOP 切面拦截器](#3. 实战代码:打造一个纯粹的 AOP 切面拦截器)
- [4. 两大数据通道的完美分工](#4. 两大数据通道的完美分工)
- [3.4 ⚠️ 避坑指南:Tool Node 的分类错误处理 (Handle Tool Errors)](#3.4 ⚠️ 避坑指南:Tool Node 的分类错误处理 (Handle Tool Errors))
-
- [1. 灾难现场:致命的默认行为](#1. 灾难现场:致命的默认行为)
- [2. 破局之道:错误分类治理 (双轨制处理)](#2. 破局之道:错误分类治理 (双轨制处理))
- [3. 实战代码:打造一个坚不可摧的 Tool 异常拦截器](#3. 实战代码:打造一个坚不可摧的 Tool 异常拦截器)
- [4. 为什么这种写法更加的稳定](#4. 为什么这种写法更加的稳定)
- [5. 生产级异常捕捉](#5. 生产级异常捕捉)
- [🌟 第三章 全面总结 (Checkpoint)](#🌟 第三章 全面总结 (Checkpoint))
-
- [四、 Checkpointer 记忆持久化 (断点与短程恢复)](#四、 Checkpointer 记忆持久化 (断点与短程恢复))
-
- [4.1 什么是 Checkpointer?(状态快照与持久化介质)](#4.1 什么是 Checkpointer?(状态快照与持久化介质))
-
- [1. 核心运行机制](#1. 核心运行机制)
- [4.2 Thread ID:会话隔离与断点唤醒](#4.2 Thread ID:会话隔离与断点唤醒)
-
- [1. 并发与多租户的基石](#1. 并发与多租户的基石)
- [2. 实战演练](#2. 实战演练)
- [3. 存在的问题](#3. 存在的问题)
- [4.3 状态回放与时光倒流 (Time Travel)](#4.3 状态回放与时光倒流 (Time Travel))
-
- [1. 核心概念与 Java 映射](#1. 核心概念与 Java 映射)
- [2. 实战代码:化身"时间刺客"修改过去](#2. 实战代码:化身“时间刺客”修改过去)
- [3. 架构师复盘](#3. 架构师复盘)
- [4. 关于Checkpointer的最大误区](#4. 关于Checkpointer的最大误区)
- [4.4 ⚠️ 避坑指南:状态爆炸与滚动窗口策略](#4.4 ⚠️ 避坑指南:状态爆炸与滚动窗口策略)
-
- [1. 如何打破"只增不减"的 Reducer 规则?](#1. 如何打破“只增不减”的 Reducer 规则?)
- [2. 实战代码:打造一个"会自己压缩记忆"的 Agent](#2. 实战代码:打造一个“会自己压缩记忆”的 Agent)
- [3. 架构师复盘](#3. 架构师复盘)
- [🌟 第四章 全面闭环 (Checkpoint)](#🌟 第四章 全面闭环 (Checkpoint))
- [五、 Human-in-the-loop 人工审批 (人机协同机制)](#五、 Human-in-the-loop 人工审批 (人机协同机制))
-
- [5.1 安全阻断与状态挂起 (Interrupts)](#5.1 安全阻断与状态挂起 (Interrupts))
-
- [1. 为什么需要挂起机制?](#1. 为什么需要挂起机制?)
- [2. LangGraph 的两种挂起方式](#2. LangGraph 的两种挂起方式)
- [5.2 状态编辑与外部唤醒 (Resume & State Editing)](#5.2 状态编辑与外部唤醒 (Resume & State Editing))
-
- [1. 人工干预与数据修正](#1. 人工干预与数据修正)
- [2. 唤醒机制 (Command/Resume)](#2. 唤醒机制 (Command/Resume))
- [3. 代码实战](#3. 代码实战)
- [5.3 ⚠️ 避坑指南:异步并发与子图隔离 (Concurrency & Subgraphs)](#5.3 ⚠️ 避坑指南:异步并发与子图隔离 (Concurrency & Subgraphs))
-
- [1. 异步 Webhook 的上下文寻址](#1. 异步 Webhook 的上下文寻址)
-
- [(1)Thread_ID 丢失的灾难](#(1)Thread_ID 丢失的灾难)
- [2. 分布式子图的命名空间 (Namespace Isolation)](#2. 分布式子图的命名空间 (Namespace Isolation))
- [1. 大坑一:异步 Webhook 的上下文寻址 (Thread_ID 丢失)](#1. 大坑一:异步 Webhook 的上下文寻址 (Thread_ID 丢失))
-
- (1)灾难场景还原
- [(3)正确解法:Payload 透传](#(3)正确解法:Payload 透传)
- [2. 大坑二:分布式子图的挂起与命名空间 (Namespace Isolation)](#2. 大坑二:分布式子图的挂起与命名空间 (Namespace Isolation))
-
- [(1)Java 视角映射:Trace ID 与 Span ID](#(1)Java 视角映射:Trace ID 与 Span ID)
- (2)如何精准获取和唤醒子图?
- 复盘
- [🌟 全景总结:从脚本玩具到企业级智能体的架构跃迁](#🌟 全景总结:从脚本玩具到企业级智能体的架构跃迁)
-
- [第一层:数据与持久层 (基础设施) ------ 对应 Ch1 & Ch4](#第一层:数据与持久层 (基础设施) —— 对应 Ch1 & Ch4)
- [第二层:业务流转与路由层 (核心计算) ------ 对应 Ch2](#第二层:业务流转与路由层 (核心计算) —— 对应 Ch2)
- [第三层:容错与切面中间件层 (高可用保障) ------ 对应 Ch3](#第三层:容错与切面中间件层 (高可用保障) —— 对应 Ch3)
- [第四层:协同与分布式调度层 (人机与微服务) ------ 对应 Ch5](#第四层:协同与分布式调度层 (人机与微服务) —— 对应 Ch5)
-
- [💡 最终结语](#💡 最终结语)
前情提要
上一章学习了Rag和记忆机制,这一章我们将开始最重要的StateGraph 和Harness 。
上一章可回顾:Ai-Agent学习历程------ 阶段3------RAG 与记忆机制
学习地图&大纲
一、 StateGraph 与 Schema (定义上下文)
- 核心概念 :基于
StateGraph的状态机设计。图流转中的所有节点通过共享同一个全局 State(可基于TypedDict或 Pydantic 定义)进行增量通信。 - 状态累加与更新 :
- 通过
Annotated[list, add_messages]等 Reducer 实现状态的部分追加与合并(如增量更新聊天消息流)。 - 各节点执行完毕后,只需返回需要更新的局部字段字典,底层的 Pregel 引擎会自动将其 merge 到全局 State 中。
- 通过
- ⚠️ 注意事项 :尽量避免直接在全局 State 中维护复杂的业务中转变量。复杂的 Multi-Agent 系统应优先使用
subgraph(子图)机制,使局部状态独立,防止全局 Schema 被过度污染。
二、 Nodes & Edges (图流转与条件路由)
- 节点与控制流 :
- Nodes (节点):普通的同步/异步 Python 函数,读取当前 State,返回更新后的字典。
- Normal Edges (普通边) :通过
.add_edge(node_a, node_b)实现强绑定的节点流转。 - Conditional Edges (条件边):根据 Router 函数的判断逻辑,动态决定下一个要执行的节点。
- 防御机制 (防死循环) :
- 在编译或运行图时,必须显式配置
recursion_limit(最大递归步数限制,例如 25),防止 LLM 陷入由于工具调用失败而导致的不间断循环。 - 可搭配
RemainingSteps注解,让 Agent 提前感知当前的可用步数,避免被强制中断引发的非优雅报错。
- 在编译或运行图时,必须显式配置
- ⚠️ 注意事项 :在复杂的图路由中,条件边所指向的所有目的节点均须在
path_map映射字典中完整声明,防止由于边缘路径缺失引发运行时ValueError。
三、 Harness 容错拦截 (增强系统鲁棒性)
- 异常捕获与自愈 :
- 在节点层配置
RetryPolicy实现指数退避重试,屏蔽因大模型 API 抖动导致的瞬时网络故障。 - 通过自定义拦截器(Harness Layer)捕获
NodeError,并把报错反馈(Feedback Loop)格式化为下一次的提示词,供 LLM 尝试自动修正错误逻辑(如修复不合规的 JSON 输出)。
- 在节点层配置
- Agent Harness (代理脚手架) :
- 引入统一的中间件层(如 LangChain 规范下的
create_agent脚手架),将统一的安全规则(如 PII 脱敏、调用计数 ModelCallLimit 熔断、数据越权检查)从 Node 的业务逻辑中抽离,降低图的深度。
- 引入统一的中间件层(如 LangChain 规范下的
- ⚠️ 注意事项 :工具调用(Tool Node)的错误不应直接让整张图挂起。需使用
handle_tool_errors等机制将报错信息包装为 ToolMessage 返回给 LLM,令其具备"知错并修正"的能力。
四、 Checkpointer 记忆持久化 (断点与短程恢复)
- 状态持久化介质 :
- 开发调试 :使用内存级的
MemorySaver进行轻量化状态存取。 - 生产环境 :由于服务可能会重启、多实例部署,必须接入持久化存储方案(如
PostgresSaver或SqliteSaver)。
- 开发调试 :使用内存级的
- 会话管理与回放 :
- 通过
thread_id(线程 ID)作为全局的 Persistent Cursor(持久化指针)。 - 每次调用传入相同的
thread_id,图在启动时便能加载出最近一次生成的 Checkpoint(Snapshot),在此基础上实现断点续传。
- 通过
- ⚠️ 注意事项:随着调用次数增加,Checkpointer 数据库中的 checkpoints 历史记录会线性增长。生产环境下需要建立滚动窗口策略(如定期清理非必要快照或只保留最近 N 天),以避免由于读写频繁产生底层数据库的性能瓶颈。
五、 Human-in-the-loop 人工审批 (人机协同机制)
- 安全阻断 (Interrupts) :
- 静态中断 :在编译图时指定
interrupt_before=["sensitive_node"],强制在敏感节点运行前将图挂起。 - 动态中断 :在节点代码内部,使用
interrupt(payload)依据当前的运行时数据动态决定是否交由人工审批。
- 静态中断 :在编译图时指定
- 状态编辑与唤醒 :
- 当图处于挂起(Pending)状态时,人工不仅可以给出审批结果(继续/拒绝),还能通过修改当前 State 的快照,实现状态数据的人工修正。
- 外部唤醒时利用
Command或对应的 resume 逻辑,图会直接从挂起处的节点恢复执行,无需重复运行之前的节点。
- ⚠️ 注意事项 :在处理异步、多用户的审批流时,审批的上下文传递必须依赖一致的
thread_id。如果是在具有多代理、子图的分布式微服务下,需注意子图的命名空间(Namespace)隔离,避免父子图之间的 Checkpoint 状态相互覆写导致混乱。
一、 StateGraph 与 Schema (定义上下文)
1.1 核心概念:状态机与全局上下文
首先对 StateGraph 和 Scheme 进行一个简单的理解,这到底是什么东西。
- Scheme: 这相当于Java中的类申明,注意这只是一个定义(设计图),标记了执行过程中需要记录哪些东西,真正在节点之间流转的东西是 State;
- StateGraph: 这是一个
有向图引擎,理解为工作流或者架构就好,这就是为了解决Agent在执行过程中不好管理的问题,所以出现了一个架构,用来调度,有哪些节点啊,节点之间的运转关系是怎样的等等。
(1)用 Java 思维理解 StateGraph
1. 实战:在 Python 中定义 Schema 并初始化图
在 Java 开发中,我们习惯在写业务逻辑前先把 Entity、DTO 和 Context 类定义好。在 LangGraph 中也是如此。
requirements.txt
python
# ==============================================================================
# LangGraph & AI Agent 核心执行引擎
# ==============================================================================
langgraph>=1.2.4,<2.0.0
# ==============================================================================
# 运行时数据校验与 DTO 序列化工具 (Pydantic V2 系列)
# ==============================================================================
pydantic>=2.10.0,<3.0.0
# ==============================================================================
# LangChain 基础接口与消息领域模型
# ==============================================================================
langchain-core>=1.4.0,<2.0.0
python
# 导入所需的库
from typing import TypedDict
from pydantic import BaseModel, Field
from langgraph.graph import StateGraph, MessagesState
# ==========================================
# 方式一:TypedDict (贫血模型 DTO)
# ==========================================
class SimpleState(TypedDict):
user_id: str
status: str
# ==========================================
# 方式二:Pydantic (充血模型 / 强校验 DTO)
# ==========================================
class ValidatedState(BaseModel):
user_id: str = Field(..., min_length=1, description="用户唯一标识")
status: str = Field(default="pending", description="当前状态")
# ==========================================
# 方式三:MessagesState (官方开箱即用的对话 Schema) - 🌟 生产最常用
# ==========================================
class MyAgentState(MessagesState):
# 我们只需要在这里扩展属于自己业务的字段
user_id: str
# ==========================================
# 初始化 StateGraph 骨架
# ==========================================
workflow = StateGraph(MyAgentState)2. 这三种 Schema 在工程选型上怎么挑?
- 极速原型 / 纯内部计算: 首选
TypedDict。因为它在运行时就是纯粹的 Pythondict,序列化/反序列化性能极高,没有任何额外开销。 - 对外提供 API / LangGraph Cloud 部署: 强烈建议用
Pydantic (BaseModel)或带有 Pydantic 的混合模型。如果你想把这个 Agent 暴露为一个 RESTful API,Pydantic 能直接帮你拦截掉非法格式的输入(比如少传了user_id),防止脏数据进入图的执行流引发深层空指针异常(NoneType error)。 - 构建标准 Chatbot / LLM Agent: 闭眼选
MessagesState。因为绝大多数大模型交互的基石就是messages列表。直接继承它可以省去手写 Reducer 的麻烦,同时保持与 LangChain 底层 API(如ChatOpenAI)的无缝对接。
3. 为什么 LLM Agent直接选择 MessagesState
我们这么来理解,MessagesState是官方定义的一个超类,里面有封装好的东西可以直接用,不需要我们进行手动set和delete,比如最方便的就是它内部自己处理了臃肿的 聊天上下文,不需要我们在第三阶段中手动维护一个 messageList了,这就是优势。
其实就和Java的HttpServletRequest有点像,在正常使用的时候就是:
python
from typing import Annotated
from pydantic import BaseModel, Field
from langgraph.graph import MessagesState, StateGraph
# ==========================================
# 1. 使用 Pydantic 定义具体的业务载体 (Payload)
# ==========================================
# 类比 Java:这是一个严格的 UserProfileDTO,用于做业务数据校验
class UserProfile(BaseModel):
name: str = Field(..., description="用户的真实姓名")
age: int = Field(..., description="用户年龄,必须大于0")
intent: str = Field(default="unknown", description="用户的核心诉求")
# ==========================================
# 2. 使用 MessagesState 定义全局上下文 (Session)
# ==========================================
class AppState(MessagesState):
# 继承后,自带了用于大模型对话的 messages 列表
user_profile: UserProfile | None
# ==========================================
# 3. 引擎运转
# ==========================================
workflow = StateGraph(AppState)(2)在 Python 中如何定义 Schema
1. TypedDict:贫血模型 DTO
没有行为(Methods),只有数据结构和类型定义。类似于 Java 里的 Record(Java 14+)或只包含 @Data 的 Lombok POJO。这是最通用的定义方式。
2. Pydantic (BaseModel):充血模型 / 强校验 DTO
不仅定义字段,还包含运行时的数据校验逻辑(如类型强转、非空校验等)。类似于 Java 中结合了 Hibernate Validator(如 @NotNull, @Pattern)的输入验证 DTO。在将 Agent 部署为 API 服务(如使用 LangGraph Cloud / LangGraph Server)时,Pydantic 是首选。
3. MessagesState:开箱即用的快捷 Schema
在较新的 LangGraph 版本中,如果你构建的是标准的聊天/对话式 Agent,你不需要手动写 messages: Annotated[list, add_messages]。可以直接继承 MessagesState:
python
from langgraph.graph import MessagesState
# 继承后,它自动包含了名为 messages 的 Annotated[list[AnyMessage], add_messages] 字段
class MyAgentState(MessagesState):
# 你只需要在此处扩展你自定义的其他业务字段即可
user_id: str1.2 状态的更新与 Reducer 机制
Reducer实际上就是一个函数,用来进行状态的更新,官方对其进行了封装。
至于为什么要学习这个,Langgraph的核心就是状态,每一个节点对应一个状态,不然怎么达到审计和追踪的目的呢。
1. 默认行为:增量返回与局部覆盖
在 LangGraph 中,节点(Node)是一个纯粹的函数。它的基本运作规矩是:只读取输入状态,且绝对不直接修改原对象,只返回需要更新的"增量字典"。
(1)Java 思想映射:Map.putAll() / PATCH 请求
假设当前全局 State 里面长这样:{"user_id": "U001", "status": "running"}。
现在执行到了 Node A,Node A 想把状态改成完毕。
- ❌ 错误做法(新手常犯): 直接拿传进来的对象改属性,比如
state['status'] = 'done',然后return state。这在 LangGraph 中会破坏底层的状态溯源(Time-travel 快照机制)。 - ✅ 正确做法: Node A 只需直接
return {"status": "done"}。底层引擎会自动捕捉这个小字典,并做一个浅拷贝合并 ,没被 return 的字段(user_id)会原样保留,被 return 的字段会被新值覆盖 。和js中Object.assign差不多
2. 突破默认:Reducer 与 Annotated 的魔法
如果所有字段都是覆盖,那聊天记录怎么办?大模型每聊一句话,旧记录就被清空覆盖了,这就成了金鱼记忆。这时候就需要 Reducer(聚合器) 登场。
(1)Python 语法糖:Annotated 到底是个啥?
这行代码:messages: Annotated[list, add_messages]。
Annotated是 Python 的类型注解,它的作用是给基础类型绑定一种"合并行为"。- Java 类比: 想象一下 Java 里的
ConcurrentHashMap.merge(key, newValue, (oldValue, newValue) -> { return ... })。
这里的add_messages就是那个合并逻辑函数!它告诉底层引擎:"嘿,如果节点返回了新的 messages,千万别覆盖 ,请把旧值和新值传给add_messages方法,让它来决定怎么合并"。
(2)add_messages 的高级合并逻辑(不仅是 Append)
官方内置的 add_messages 非常聪明,它绝对不是简单的 list.add():
- 追加(Append): 如果 Node 返回了一条新消息,且它的 ID 是全新的,它会把它追加到列表末尾。
- 更新/覆写(Update): 如果 Node 返回的消息 ID 在历史列表中已经存在 ,它会用新内容替换 旧内容。
- (架构思考:为什么需要这个?因为大模型在"流式输出(Streaming)"时,一句话会被拆成几百个 token 碎块发过来。每次发过来都是同一个 ID,引擎只需不断更新同一条记录,而不会搞出几百条新记录。)
- 一键清空: 如果你需要重置会话,只需要让 Node 返回一个特定的魔法值(类似于 Java 的
session.invalidate()),底层会自动清空所有历史。
3. 实战代码:亲眼看看"覆盖"与"追加"的区别
下面这段极简代码展示了 Node 是如何执行这两种更新逻辑的。
python
from typing import Annotated, TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langchain_core.messages import HumanMessage, AIMessage
# ==========================================
# 1. 定义 Schema 图纸
# ==========================================
class AgentState(TypedDict):
# status 没有 Annotated,采用默认的【Last-Write-Wins 覆盖机制】
status: str
# messages 绑了 add_messages,采用【Reducer 智能追加/合并机制】
messages: Annotated[list, add_messages]
# ==========================================
# 2. 定义机械臂 (Nodes)
# Python 语法糖:Node 就是普通的函数,入参固定为 state 对象
# ==========================================
def node_1_receive_user_input(state: AgentState):
print(f"[Node 1] 当前收到状态: {state}")
# 模拟收到用户输入。注意:我们【只返回】需要变动的增量字典!
# 底层会自动把 status 覆盖,把 msg_1 追加进 messages 列表
msg_1 = HumanMessage(content="你好,我是 Java 程序员!", id="msg_001")
return {"status": "processing", "messages": [msg_1]}
def node_2_agent_reply(state: AgentState):
print(f"[Node 2] 当前收到状态: {state}")
# 模拟 AI 回复。再次注意:不需要把原来的 msg_1 也带上!
# 底层 add_messages 发现 id 不同,会自动做增量追加。
msg_2 = AIMessage(content="你好!欢迎学习 LangGraph!", id="msg_002")
return {"status": "completed", "messages": [msg_2]}
# ==========================================
# 3. 组装流水线 (Graph)
# ==========================================
builder = StateGraph(AgentState)
builder.add_node("node_1", node_1_receive_user_input)
builder.add_node("node_2", node_2_agent_reply)
# 画线:START -> node_1 -> node_2 -> END
builder.add_edge(START, "node_1")
builder.add_edge("node_1", "node_2")
builder.add_edge("node_2", END)
# 编译成可执行的引擎
graph = builder.compile()
# ==========================================
# 4. 运行并观察魔法!
# ==========================================
# 塞入一个空托盘启动
initial_state = {"status": "init", "messages": []}
final_state = graph.invoke(initial_state)
print("\n[最终结果]")
print(f"Status: {final_state['status']}")
# 输出结果一定是 completed (被 Node 2 覆盖了 Node 1 的 processing)
print(f"Messages 数量: {len(final_state['messages'])}")
# 输出数量一定是 2 (Node 1 的输入 + Node 2 的回复,被完美合并了)
for i, msg in enumerate(final_state['messages']):
print(f" [{i}] {type(msg).__name__}: {msg.content}")运行结果:
text
[Node 1] 当前收到状态: {'status': 'init', 'messages': []}
[Node 2] 当前收到状态: {'status': 'processing', 'messages': [HumanMessage(content='你好,我是 Java 程序员!', additional_kwargs={}, response_metadata={}, id='msg_001')]}
[最终结果]
Status: completed
Messages 数量: 2
[0] HumanMessage: 你好,我是 Java 程序员!
[1] AIMessage: 你好!欢迎学习 LangGraph!
进程已结束,退出代码为 0代码解析:
- 首先AgentState就是我们最开始说的Scheme,图纸,里面定义了可被覆盖的属性status和Reducer机制的message。
- 之后定义了两个函数也就是Node,这只是定义,还没有执行,作用就是返回了对应的状态对象。
python
builder = StateGraph(AgentState)
builder.add_node("node_1", node_1_receive_user_input)
builder.add_node("node_2", node_2_agent_reply)- 这一步是用来将Node放入,但是此时没有触发点,也没有执行顺序,相当于初始化。
python
builder.add_edge(START, "node_1")
builder.add_edge("node_1", "node_2")
builder.add_edge("node_2", END)- 这一步开始画线了,因为Graph是有向图啊,所以这里规定了开始的方法是node1,结束的是node2,node1和node2的执行顺序是先1后2。
- 之后就开始初始化和执行了,其中日志显示了message确实是追加的。
1.3 底层流转:Pregel 引擎的并发与事务魔法
如果说前面的 Schema 是"图纸",Reducer 是"合并说明书",那么 Pregel 引擎就是那个真正驱动流水线运转的"中央主板"。
这有点类似于SpringMvc中的DispatcherServlet核心方法,自动转发请求和捕捉异常,底层虽说复杂,但经过研究设计的确实很漂亮。当然我们也可以看看Pregel是怎么执行的,现阶段我们只需要知道有这么个东西,让它在底层自己执行即可。
1. 为什么节点只需要返回"局部字典"?
在前面的代码里,我们一再强调:节点函数绝对不能直接修改传入的 state 里的值,必须 return 一个增量字典。为什么框架要设计得这么"别扭"?
(1)背后的痛点:状态溯源与"时光倒流"
在 AI Agent 开发中,经常会遇到运行到第 10 步时工具调用报错的情况。LangGraph 支持一个极其强大的功能:Time-travel(时光倒流)。它可以让你随时退回到第 8 步的快照(Snapshot),修改数据后重新跑。
- 反面教材(直接修改引用) :如果 Node 1 直接执行
state["messages"].append(new_msg)。在 Java 中我们知道,这叫"修改对象引用里的可变成员"。由于大家指向的都是同一块内存地址,这时候你去翻看第 1 步的快照,会发现里面的数据也被篡改了! - 优雅解法(增量 Patch 机制) :让 Node 变成无状态的纯函数(Stateless Pure Function) 。Node 只负责生成一个补丁(Patch,也就是增量字典)。底层 Pregel 引擎拿到这个补丁后,会克隆------深拷贝出一份全新的 State 对象。
2. Pregel 引擎的并发魔法与安全防御
Pregel 是 Google 提出的大规模图计算模型,它的核心运作机制叫 BSP(Bulk Synchronous Parallel,整体同步并行)。
(1)什么叫"整体同步并行 (BSP)"?
当流水线出现分支,需要同时运行多个节点时(比如 Agent 决定同时去查 Google 搜索和本地数据库),Pregel 引擎的执行步骤如下:
- 并行执行(并发度展开) :引擎会开启多个协程/线程,同时跑 Node A 和 Node B。这两个 Node 读到的是同一份旧状态的快照。
- 等待栅栏(Barrier) :引擎会挂起等待,直到本轮的所有并发节点都执行完毕,并各自吐出了它们的"增量字典"。
- 统一合并(Super-step 结束):引擎把所有节点吐出的字典收集起来,集中进行一次 State 的合并操作。
(2)⚠️ 致命危机:并行节点的"多写冲突"
既然是并发写入,就必然面临多线程并发最经典的问题:写冲突(Race Condition)。
场景假设 :
在 Schema 中,status 是一个普通的字符串(没有绑 Reducer,默认 Last-Write-Wins 覆盖)。
现在,Node A 和 Node B 并行运行:
- Node A 执行完,吐出:
{"status": "A_Done"} - Node B 执行完,吐出:
{"status": "B_Done"}
引擎怎么处理?
在普通的 Java HashMap 并发下,谁后写完谁覆盖。但在 LangGraph 的 Pregel 引擎里,它非常严格!它发现同一个 Super-step 里,有两个并发节点试图修改同一个没有 Reducer 的字段,它不知道该听谁的,于是直接抛出 InvalidUpdateError 异常让程序崩溃!
报错信息类似:Can receive only one value per step. Use an Annotated key to handle multiple values.
(3)完美解药:用 Reducer 化解并发冲突
怎么解决上面的崩溃?答案又回到了我们在 1.2 节学的 Reducer!
任何在架构设计上有可能被并行节点同时写入的字段 ,你必须 使用 Annotated 给它绑定一个 Reducer。
回到上面的场景,如果 Schema 是这样的:
messages: Annotated[list, add_messages]
- Node A 吐出:
{"messages": [Msg_A]} - Node B 吐出:
{"messages": [Msg_B]}
当引擎集中合并时,它发现大家都在写 messages,没关系,因为 messages 绑了 Reducer!引擎就会乖乖调用 add_messages 逻辑,把 Msg_A 和 Msg_B 按顺序安全地追加到全局列表中,完美化解了并发冲突!
1.4 ⚠️ 避坑指南:防止全局 Schema 被过度污染
当我们刚开始写 AI Agent 时,往往只有一个简单的机器人,全局挂一个 MessagesState 就足够了。但在企业级项目中,你可能要构建一个 Multi-Agent(多智能体)团队(例如:一个主控 Agent 带领一个专门搜集资料的 Research Agent,和一个专门写代码的 Code Agent)。
一旦出现多Agent协作,那传统的一个Scheme就显得不合适了,必须进行拆分,不然会变得臃肿不可控。
1. 常见的设计坏味道:上帝对象 (God Object) 与 Fat Session
(1)灾难现场还原
为了让 Research Agent 存取网页爬取的数据,你在全局 AgentState 里加了个字段 raw_html: str。
为了让 Code Agent 记录编译报错,你又加了个字段 compile_error_logs: list。
久而久之,你的全局 Schema 变成了这样:
python
class FatAgentState(TypedDict):
messages: Annotated[list, add_messages]
raw_html: str
parsed_json: dict
compile_error_logs: list
retry_count: int
... # 还有几十个各个 Agent 的私有变量(2)Java 视角类比:把所有表合并成一张"大宽表"
这在 Java 架构中犯了两个大忌:
- 打破了"限界上下文(Bounded Context)" :就像你把订单系统的
Order对象和物流系统的Shipping对象揉进了一个名为GodDTO的类里,满天飞的临时变量会让代码极其难以维护。 - "Fat Session"导致 IO 性能崩塌 :如果这个 Agent 需要做持久化(断点续传),底层每次状态更新都会把几兆的
raw_html反复存入数据库。这就好比往 Spring 的HttpSession里塞了几个 GB 的大文件,服务器直接内存溢出(OOM)或 IO 瓶颈卡死。
2. 正确解法:引入 Subgraph (子图) 机制
在现代 LangGraph 架构中,解决这个问题的核心手段是:Subgraph(子图)。
(1)核心思想:微服务化
你可以把每一个独立职责的 Agent(比如 Research Agent),单独封装成一张图(Subgraph)。
- 私有状态(Local State) :这只子图拥有自己专属的
ResearchState,里面爱放raw_html还是retry_count随它便,外部看不见。这就像微服务的私有数据库。 - 对外契约:子图只通过明确的入参和出参和父图(Parent Graph)交互。它跑完之后,只会把"最终提炼的总结报告"提交给父图。
其实这里又会引入一个新的问题,如何验证子Agent的结果是否正确,这就需要强大的系统管控和验证思维。因为一旦某一个子节点出现问题,很有可能总结果就会发生偏差。所以不能拆的那么细,但又必须得拆开,平衡点需要精准拿捏。
(2)代码实战:父子图是如何连接的?
在 LangGraph 里,一个编译好的图,可以直接作为一个节点(Node),被插入到另一张图里!
我们来看一下极简的伪代码演示:
python
from langgraph.graph import StateGraph, START, END
from typing import TypedDict
# ==========================================
# 1. 独立微服务:Research 子图及其私有图纸
# ==========================================
class ResearchState(TypedDict):
search_query: str # 入参
raw_html: str # 局部私有变量:一大坨无用网页代码
summary: str # 最终要返回的结果
def fetch_web_node(state: ResearchState):
# 模拟爬取了几万字网页
return {"raw_html": "<html>...几万字...</html>"}
def summarize_node(state: ResearchState):
# 提炼出了100字的总结
return {"summary": "经过搜索,最新消息是..."}
research_builder = StateGraph(ResearchState)
research_builder.add_node("fetch", fetch_web_node)
research_builder.add_node("summarize", summarize_node)
research_builder.add_edge(START, "fetch")
research_builder.add_edge("fetch", "summarize")
research_builder.add_edge("summarize", END)
# 【关键点】编译成一个可执行的子图组件
research_subgraph = research_builder.compile()
# ==========================================
# 2. 网关总控:Parent 父图
# ==========================================
class ParentState(TypedDict):
user_task: str
final_report: str
def format_output_node(state: ParentState):
# 只拿总结,不脏手拿 html
pass
parent_builder = StateGraph(ParentState)
# 【魔法时刻】直接把编译好的子图,当成一个普通的 Node 加进来!
# Python 语法糖:在 LangGraph 中,compiled graph 实现了 Runnable 接口,可以被直接作为普通函数/节点调用。
parent_builder.add_node("research_team", research_subgraph)
parent_builder.add_node("format_output", format_output_node)
parent_builder.add_edge(START, "research_team")
parent_builder.add_edge("research_team", "format_output")
parent_builder.add_edge("format_output", END)
parent_graph = parent_builder.compile()(3)父子图的状态映射 (State Mapping)
由于父图的 Schema(ParentState)和子图的 Schema(ResearchState)长得不一样,它们在交接时,引擎怎么知道把哪个字段传给子图呢?
在最新的 LangGraph 中,我们通常会在调用子图前,或者在父图中通过特定的通道(Channels)进行字段的映射转化。这就像 Java 里在调用微服务前,用 MapStruct 把 ParentDTO 转换为 ChildRequestDTO 一样。
🌟 第一章 全面总结 (Checkpoint)
- Schema (TypedDict/Pydantic/MessagesState) :定义了微服务之间传递的
DTO和长链接通信的Session。 - Reducer (Annotated) :提供了处理并发多写冲突和状态合并的
Map.merge()策略。 - Pregel 引擎 :是一个带有依赖注入和并发栅栏的
Tomcat + DispatcherServlet调度中心,严格要求节点只能像"事件溯源"一样抛出增量字典 (Patch)。 - Subgraph (子图) :防止
God Object膨胀的微服务拆分利器。
二、 Nodes & Edges (图流转与条件路由)
📝 第一章我们设计了Agent的数据状态,这一章就开始组装流水线,和最开始的黑盒Agent不同的是,这种方式可控性极高,可以自定义Node和流转状态,每一步的控制都相当的到位。
2.1 节点与控制流 (Nodes & Normal Edges)
1. 节点的双重形态:同步与异步
在 Python 中,Node 就是一个普通的函数,它唯一的规矩就是:入参是 State,出参是 Dict 。
但是,由于网络请求(调用大模型 API)非常耗时,我们强烈建议把处理 I/O 的节点写成异步协程。
思考,为什么要专门了解节点的双重形态,因为正常来说Agent为了提高效率都是异步执行的,尤其是各种搜索🔍,但是从正常的代码编辑思维来说,同步和异步一定是结合使用的。
比如在一整套流程中分为3步,第二步中需要查询大量资料,第三步是进行总结,那第二步Node就需要异步执行,而Node2和Node3必须同步执行,不然Node3是没有数据的。
2. 实战代码:构建一条包含异步节点的线性流水线
我们来看一段极简的代码,感受一下同步节点、异步节点以及 START/END 是怎么串联起来的。
python
import asyncio # Python内置的异步I/O库
from typing import TypedDict
from langgraph.graph import StateGraph, START, END
# ==========================================
# 1. 准备图纸 (沿用第一章知识)
# ==========================================
class SimpleState(TypedDict):
input_text: str
translated_text: str
status: str
# ==========================================
# 2. 制造机器臂 (Nodes)
# ==========================================
# 【同步节点】:适合做纯内存计算(如格式化字符串、简单校验)
def sync_format_node(state: SimpleState):
print("[Node 1] 正在执行同步格式化...")
original_text = state.get("input_text", "")
# 纯内存操作,瞬间完成,直接返回增量字典
return {"status": "formatted", "input_text": original_text.strip()}
# 【异步节点】:适合做网络请求(调用 LLM、查数据库)
# Python 语法糖:加了 async 的函数叫"协程函数",里面可以使用 await 来非阻塞地等待 I/O 操作。
async def async_translate_node(state: SimpleState):
print("[Node 2] 正在执行异步翻译请求...")
# 模拟调用大模型 API 耗时 2 秒
# Python 语法糖:await 相当于 Java 里的 CompletableFuture.join(),但它不会阻塞系统底层线程。
await asyncio.sleep(2)
formatted_text = state.get("input_text", "")
# 模拟翻译结果
fake_translation = f"【已翻译】{formatted_text}"
return {"status": "translated", "translated_text": fake_translation}
# ==========================================
# 3. 铺设死轨道 (Normal Edges)
# ==========================================
builder = StateGraph(SimpleState)
# 先把机器臂安装到工厂里
builder.add_node("format_worker", sync_format_node)
builder.add_node("translate_worker", async_translate_node)
# 划定写死的顺序流转路线 (Normal Edges)
# START -> format_worker -> translate_worker -> END
builder.add_edge(START, "format_worker")
builder.add_edge("format_worker", "translate_worker")
builder.add_edge("translate_worker", END)
# 编译引擎
graph = builder.compile()
# ==========================================
# 4. 运行测试 (由于图里有异步节点,我们需要用异步方式启动它)
# ==========================================
async def main():
initial_state = {"input_text": " Hello AI Agent! "}
# ainvoke 是 async invoke 的缩写
final_state = await graph.ainvoke(initial_state)
print("\n[最终结果]:", final_state)
# 启动 Python 的事件循环执行 main 函数 (类似 Java 的 main 线程启动)
asyncio.run(main())3. 普通边的局限性
通过代码可以看到,无论用户怎么输入,都必须经过translate这个步骤,正常来说这没有问题,普通的ETL------批处理系统就这么干,但是在Agent中这么干是不是有点太Low了,智能的含义就在灵活啊,不能什么输入都走translate吧,要是人家输入正确呢?
那下一个问题就来了,我加入一些判断不就行了?
那问题又来了,这些判断你都要写一遍吗?这还要Agent干嘛呢,这不仅不够优雅,Token的消耗也是非常重要的。所以这就引出了非常重要的:条件路由。
2.2 Conditional Edges (条件路由)
1. 为什么需要条件边?(动态路由)
在真实的 Agent 交互中,大模型经常面临分岔路口。
比如:用户问"今天东京天气如何?"
- 大模型的决策:它发现自己不知道实时天气,必须调用搜索引擎。
- 图的流转 :系统必须把控制权交给
Tool Node(工具节点)。 - 如果用户只是说"你好" :大模型不需要工具,系统必须直接走向
END。
(1)Java 视角映射:排他网关与 Switch-Case
- 在 Java 传统代码中,这相当于在两个方法调用之间插了一个
if-else或switch-case。 - 在工作流引擎(如 Activiti / Camunda)中,这就是最经典的 Exclusive Gateway(排他网关 / XOR)。数据流到一个菱形节点,根据条件(Condition)只能选择一条岔路走。
2. 核心运转机制:Router 与 Path Map
在 LangGraph 中,配置一个条件边需要两个核心组件:
- Router 函数(路由判定器) :
- 它本身不是 图里的 Node,它不修改全局 State。
- 它的唯一工作就是读取当前的 State,然后返回一个字符串标识(表示方向)。
- 类比 Java :这就像 Java 8 的
Predicate接口,或者路由网关里的断言逻辑。
- Path Map(路径映射表) :
- 这是一个 Python 的字典(Dict)。它把 Router 返回的字符串,精确映射到下一个真实的 Node 名字上。
- 类比 Java :这等同于
switch (routerResult) { case "use_tool": return "tool_node"; ... }。
3. 实战代码:写一个会思考的动态路由
下面这段代码模拟了最经典的 Agent 场景:"判断是否需要调用工具"。
python
from typing import TypedDict, Literal
from langgraph.graph import StateGraph, START, END
# ==========================================
# 1. 定义 Schema
# ==========================================
class AgentState(TypedDict):
input_text: str
needs_tool: bool # 模拟大模型的思考结果:是否需要工具
result: str
# ==========================================
# 2. 定义机器臂 (Nodes)
# ==========================================
def agent_think_node(state: AgentState):
print("\n[大模型节点] 正在思考用户的输入...")
text = state.get("input_text", "")
# 模拟大模型的意图识别逻辑
if "天气" in text:
print(" -> 发现需要查询实时数据,决定调用工具!")
return {"needs_tool": True, "result": "等我查一下"}
else:
print(" -> 普通聊天,直接回复即可!")
return {"needs_tool": False, "result": "你好呀,我是 AI!"}
def tool_node(state: AgentState):
print("[工具节点] 正在调用天气 API...")
return {"result": "今天天气晴朗,气温 25 度。"}
# ==========================================
# 3. ✨ 核心魔法:定义 Router 路由函数
# ==========================================
# Python 语法糖:Literal 是类型提示,表示这个函数只可能返回这两个字符串中的一个。
# 它能让 IDE 帮你做静态代码检查,防止拼写错误。
def should_use_tool(state: AgentState) -> Literal["go_to_tool", "go_to_end"]:
# 路由函数只负责"读"状态,然后"指路"
if state.get("needs_tool"):
return "go_to_tool"
else:
return "go_to_end"
# ==========================================
# 4. 组装与编排
# ==========================================
builder = StateGraph(AgentState)
builder.add_node("agent_think", agent_think_node)
builder.add_node("tool_call", tool_node)
# 第一步:固定起点
builder.add_edge(START, "agent_think")
# 第二步:✨ 添加条件边 (Conditional Edge)
# 参数 1: 始发节点 (agent_think 执行完后触发路由)
# 参数 2: Router 函数 (由它来决定去哪)
# 参数 3: Path Map (将 Router 的返回值,映射到真实的 Node 名称或 END)
builder.add_conditional_edges(
"agent_think",
should_use_tool,
{
"go_to_tool": "tool_call", # 如果 Router 返回 go_to_tool,就流向 tool_call 节点
"go_to_end": END # 如果 Router 返回 go_to_end,直接结束整张图
}
)
# 第三步:工具调用完后,直接结束(或者你也可以连回 agent_think 让它总结)
builder.add_edge("tool_call", END)
graph = builder.compile()
# ==========================================
# 5. 运行测试:观察不同的路由走向
# ==========================================
print("========== 测试 1: 普通聊天 ==========")
graph.invoke({"input_text": "你好"})
print("\n========== 测试 2: 触发工具 ==========")
graph.invoke({"input_text": "今天东京的天气怎么样?"})4. 理解路由机制的核心
- 解耦设计 :你会发现,
agent_think_node只负责计算出needs_tool=True并存入 State,它并不知道下一步去哪。而 Router 函数只负责读取needs_tool来决定去哪。这种"状态更新与路由控制强解耦"的设计,与 Java 里的领域事件驱动非常相似。 - Path Map 是契约 :在上述代码的映射表里:
{"go_to_tool": "tool_call"},左边是 Router 函数自己定的"暗号",右边是图里真正注册的"Node 名字"。如果名字拼错了,或者漏写了分支,图在运行时就会抛出ValueError(也就是我们学习地图 2.4 要讲的坑)。
5. 生产层次的架构思考:优雅的动态路由和工具调用
如果阅读了上述的代码,我们能发现几个直观的问题
- if-else爆炸 :在
agent_think_node函数中,这是用来判断调用哪个工具的,如果真的在生产中,工具会很多,难不成一个一个写if-else?加一个工具就维护一下代码? - 判断不够智能: 还是agent_think_node,都是分支条件来控制,加一个工具很死板,智能通过硬编码的形式判断,和流水线没什么区别了。
- 调用同样死板 :在
add_conditional_edges中第三个参数,如下,调用哪个工具你也得写清楚吧,tool_call中同样需要很多判断,如果说需要调用多个工具呢,你得指向多个工具吧,即使封装了一个方法动态调用,同样也是很死板的。
python
builder.add_conditional_edges(
"agent_think",
should_use_tool,
{
"go_to_tool": "tool_call", # 如果 Router 返回 go_to_tool,就流向 tool_call 节点
"go_to_end": END # 如果 Router 返回 go_to_end,直接结束整张图
}
)(1)普通生产级解决方式:Function Calling & ToolNode
这是最常见的一种解决方案,函数调用和分发器,核心有两个
- Function Calling: 给大模型足够多的工具说明和参数说明,都放在系统指令中。
python
# 生产级的 node 里根本没有 if-else!
def agent_think_node(state):
# 1. 把工具的 Schema 绑定到 LLM 上
llm_with_tools = llm.bind_tools([weather_tool, search_tool, db_tool...])
# 2. 直接把用户的对话丢给 LLM,它自己会决定怎么做
response = llm_with_tools.invoke(state["messages"])
# 3. 把大模型的原始回复(可能包含 tool_calls)追加到 State
return {"messages": [response]}其中每一个tool都有对应的说明书,由系统自动生产,大模型可以准确识别。
- ToolNode: 工具分发器,通过反射机制,大模型返回对应的函数名称和参数,我们通过反射invoke调用函数即可,不需要那么多的判断。
以上就可以解决核心的问题,但是随着系统不断迭代,新的问题就会出现
- 指令繁重: 如果工具日渐增多,系统指令就会很臃肿,不好维护。
- 幻觉概率变大: 一旦太多工具,工具之间如果有相似的话,系统很容易判断错误,这样幻觉现象就会被放大。
- Token消耗: 工具越多指令越大,Token消耗也是一笔不小的开销,不要觉得几百个字没事,在百万千万级别用户下,这笔账就很大了。
之后我们就引出一个现在比较智能的方案,工具向量化 和动态挂载 。
(2)进阶方案:动态工具检索
这里使用两个核心技术:工具向量化 和 动态挂载
- 工具向量化:启动时,把这 1000 个工具的描述(Description)变成向量,存入向量数据库(Vector DB)
- 动态挂载 (Dependency Injection):
当用户问"帮我查一下杭州的机票"时。在进入 agent_think_node 之前,先加一个 Tool_Selector_Node。
这个节点拿着用户的查询,去向量数据库里查出 Top 3 最相关的工具(比如 search_flight, book_ticket, weather)。
然后,只把这 3 个工具的说明书组装起来给大模型。这就是真正的动态取用!
一般来说这个步骤会更加的宽松,就是将最接近的5个甚至七八个都给大模型,保证是比较全面的。
python
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langgraph.prebuilt import ToolNode, tools_condition
from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
# ==========================================
# 1. 纯粹的工具定义 (利用装饰器生成 Schema)
# Python 语法糖:@tool 装饰器会自动把这个函数的签名、文档字符串解析成供 LLM 读取的 JSON Schema
# ==========================================
@tool
def weather_tool(location: str):
"""根据给定的城市,查询实时天气。"""
return f"{location}的天气是晴天,25度。"
@tool
def db_tool(user_id: str):
"""查询用户的基本信息。"""
return f"用户{user_id}是尊贵的 VIP。"
# 假设这里有一个工具列表(实际可以从向量库动态加载)
tools_list = [weather_tool, db_tool]
# ==========================================
# 2. Schema 与 大模型初始化
# ==========================================
class AgentState(TypedDict):
messages: Annotated[list, add_messages]
# 实例化大模型,并【绑定工具说明书】
llm = ChatOpenAI(model="gpt-4o")
llm_with_tools = llm.bind_tools(tools_list)
# ==========================================
# 3. 定义机器臂 (现在变得极其轻量!)
# ==========================================
def agent_think_node(state: AgentState):
# 完全依赖大模型的 Function Calling 能力
response = llm_with_tools.invoke(state["messages"])
# 直接返回大模型的输出,不管里面是普通文本还是工具调用指令
return {"messages": [response]}
# 我们不再手写 tool_call 节点,直接使用官方的超级反射器 ToolNode
universal_tool_node = ToolNode(tools_list)
# ==========================================
# 4. 组装与编排 (完美的二叉树路由)
# ==========================================
builder = StateGraph(AgentState)
builder.add_node("agent", agent_think_node)
builder.add_node("tools", universal_tool_node) # 注册通用工具节点
builder.add_edge(START, "agent")
# ✨ 核心魔法:使用官方的 tools_condition 作为 Router
# 它的逻辑只有两句话:如果 message 里有 tool_calls,返回 "tools";否则返回 END。
builder.add_conditional_edges(
"agent",
tools_condition,
)
# 工具执行完后,必须连回大模型,让大模型根据工具的结果写总结!
builder.add_edge("tools", "agent")
graph = builder.compile()2.3 🛡️ 防御机制 (防死循环)
1. 灾难重现:无限死循环 (Infinite Loop)
假设你要大模型用 weather_tool 查天气,要求传入城市全拼(如 beijing)。
- 大模型(第一次):传入了中文
"北京"。 - ToolNode 执行失败,抛出错误:
Error: 需要英文拼写。 - 错误信息被作为
ToolMessage传回大模型。 - 大模型(第二次):脑子抽筋,传入了
"BeiJing"(包含大写)。 - ToolNode 再次失败:
Error: 需要全小写。 - 错误又被传回大模型...
如果大模型陷入了幻觉重试黑洞,这个图就会以每秒几次的速度疯狂转圈。如果不加防御,你的 OpenAI 余额会在几分钟内被抽干!
在 Java 中,这种递归循环会直接把内存撑爆并抛出 StackOverflowError。在 Agent 架构中,我们有两道防线来解决这个问题。
🛡️ 第一道防线:全局熔断器 (Recursion Limit)
这是 LangGraph 最底层的硬性防御机制。
(1)Java 视角映射:微服务熔断 (Circuit Breaker)
就像你在 Spring Cloud 中使用 Resilience4j 或者给 HTTP 请求设置 Timeout 一样。如果一个任务在指定的步数内无法完成,直接切断。
(2)如何配置?
在 LangGraph 中,一次完整的节点流转被称为一个 Super-step(超级步)。框架默认的递归步数上限是 25 步。
可以在启动引擎时,手动调整这个"熔断阈值":
python
# 启动图时,通过 config 注入 recursion_limit
config = {"recursion_limit": 10} # 限制最多只能走 10 步
# 如果大模型和工具来回拉扯超过 10 次,
# 引擎会直接抛出 Python 异常:GraphRecursionError
final_state = graph.invoke(initial_state, config=config)⚠️ 第一道防线的痛点(为什么它不够好?):
直接抛出 GraphRecursionError 是极其粗暴的。
这就像直接拔服务器电源一样(Hard Crash )。一旦抛异常,之前几轮辛苦查询到的部分正确数据(比如已经查到了航班,只差查酒店就超时了)会全部丢失 ,并且直接给终端用户返回冷冰冰的 500 Server Error。
而且在现在流行的循环任务,这种长任务需要调用的工具数量会很大,所以更加需要灵活的限制而非直接切断。
🛡️ 第二道防线:优雅降级感知 (RemainingSteps 机制)
为了解决"拔电源丢失数据"的问题,现代 LangGraph 引入了一个极具智慧的设计:
RemainingSteps(剩余步数感知)。
LangGraph 提供了一个非常高级的"托管值(Managed Value)"特性。我们只需要在 Schema 里加一行代码,底层引擎就会自动在状态里挂载一个倒计时器。
请看这段生产级防御代码:
python
from typing import Annotated, TypedDict
from langgraph.graph.message import add_messages
from langgraph.managed import RemainingSteps # 引入剩余步数管理器
# ==========================================
# 1. 定义带有"倒计时器"的 Schema
# ==========================================
class AgentState(TypedDict):
messages: Annotated[list, add_messages]
# 🌟 核心魔法:注入托管值
# 你不需要手动去减这个数字,Pregel 引擎每走一步,它会自动递减!
remaining_steps: RemainingSteps
# ==========================================
# 2. 定义具有"求生欲"的大模型节点
# ==========================================
def agent_think_node(state: AgentState):
messages = state["messages"]
steps_left = state["remaining_steps"]
print(f"[监控] Agent 当前剩余存活步数: {steps_left}")
# 🌟 优雅降级逻辑:如果在死循环边缘(快被强杀了)
if steps_left <= 2:
print("🚨 警告:即将熔断!强制要求大模型停止调用工具,直接总结!")
# 我们可以临时向大模型塞入一条极其严厉的系统提示词
emergency_prompt = {
"role": "system",
"content": "【最高优先级指令】你的操作步数即将耗尽!不要再尝试使用任何工具!"
"请根据目前已有的信息,立刻给出一个尽可能详细的最终回复!"
}
# 将提示词和历史消息一起喂给大模型
response = llm_with_tools.invoke([emergency_prompt] + messages)
else:
# 正常情况:允许自由使用工具
response = llm_with_tools.invoke(messages)
return {"messages": [response]}3. 防死循环的哲学
结合我们在 2.2 节学的架构,加上本节的防御机制,一个完美的生产级 Agent 处理流程是这样的:
- 自由探索期(Steps: 25 -> 3) :大模型自由地调用
ToolNode,报错了也没关系,它会自动看报错信息进行自愈(Self-Correction)。 - 强制收敛期(Steps: 2) :当陷入死循环,步数见底。我们通过
RemainingSteps触发报警。临时切断它的"手脚(工具)",逼迫它利用现有的"记忆"生成最终答案。 - 熔断底线(Steps: 0) :如果大模型彻底失控,连最后通牒都不听,
recursion_limit将充当最后一道防线,抛出异常,防止资金损失。
4. 基于现在流行的长任务思考
现在的Agent发展越来越靠近长任务了,或者说循环任务,包括codex最新的/goal模式,能跑几个小时,这时候通过上面的总体步数来限制就显得太低级了,总不能设置99999吧。
一般我们会设置一个局部计数器,先控制单步骤的循环次数
python
class AgentState(TypedDict):
messages: Annotated[list, add_messages]
# 添加一个局部计数器
search_tool_retry_count: int
# 在你的 Router 函数中做局部限制:
def router_function(state: AgentState):
# 如果这个特定的工具连续卡壳超过 3 次
if state.get("search_tool_retry_count", 0) >= 3:
# 强制转移给"人类接管节点"或者"错误恢复节点",而不是让全局引擎崩溃
return "human_fallback_node"
if "tool_calls" in state["messages"][-1]:
return "tools"
return END实际上现在工业的解决方式是之后我们要学习的几个,现在可以先了解一下
(1)引入断点持久化(Checkpointer,第四章将学)
- 痛点:普通 Graph 是在内存里一口气跑到底的,就像一根绷紧的橡皮筋,时间越长越容易断(内存溢出、网络中断)。
- 破局 :长任务必须分片运行。引入 Checkpointer(如 Postgres 数据库)后,Agent 每跑几步,状态就会落盘。你可以设计成:"每次被唤醒只跑 20 步,落盘保存,休眠,然后由外部定时任务(如 Java 的 Quartz)再次唤醒它续跑"。
(2)Map-Reduce 与 动态子图分发(Send API)
- 痛点:让主控大模型自己去循环调 50 次搜索工具,主控循环的步数会爆炸,且上下文(Context Window)会被塞爆,大模型直接变傻。
- 破局 :微服务架构中的 散列-聚集(Map-Reduce) 。
主控 Agent 发现需要查 50 个词,它不自己循环 。它利用 LangGraph 提供的Send机制,瞬间动态孵化出 50 个小 Subgraph(子图)。这 50 个子图各自拥有独立的步数限制,并行去查。查完后统一汇集给主图。这样主图的步数永远只有短短的几步!
(3)人机协同(Human-in-the-Loop,第五章将学)
对于极长且不可控的任务,任由它狂奔是非常危险的。
现代 Agent 架构强制要求在特定的卡点(比如执行了 50 步,或者准备执行转账等高危工具时)进入 Pending(挂起)状态。发一条企业微信通知人类,人类看一眼草稿点击"Approve(批准)"后,它再继续往下跑。
2.4 ⚠️ 避坑指南:条件边的运行时 ValueError
1. 灾难现场:潜伏在运行时的 ValueError
在 2.2 节中,我们使用了类似这样的代码来配置动态路由:
python
builder.add_conditional_edges(
"agent_think",
should_use_tool,
{
"go_to_tool": "tool_call",
"go_to_end": END
}
)(1)为什么会爆炸?(悬空路由)
假设你的大模型在某次意图识别中,触发了一个极其罕见的 Edge Case(边缘场景)。
你的 should_use_tool(Router 函数)因为某些逻辑漏洞,突然返回了一个字符串 "ask_human"。
但是,你在第三个参数 path_map(映射表字典)里,压根没有定义 "ask_human" 对应的下家节点!
此时,底层引擎 Pregel 拿着 "ask_human" 这个,去字典里找下一步的轨道,结果发现是 null。引擎会立刻崩溃,并抛出:
ValueError: Branch "ask_human" not found in path map...
由于 Python 默认是动态弱类型语言 ,这种"漏写分支"的错误在编译期(写代码时)是不会报错的!它就像一颗定时炸弹,只有在程序跑到那个特定分支时才会炸。这对于生产级 Agent 是不可接受的。
2. 破局之道:如何彻底消灭路由配置 Bug?
为了在 Python 里找回 Java 般严谨的安全感,我们有两大绝招。
(1)防线一:使用 Literal 限制返回值 (类型层面的 Enum)
永远不要让你的 Router 函数返回宽泛的 str 类型。利用 Python 3.8+ 引入的 Literal 语法糖!
- Java 类比 :这相当于用
Enum(枚举)替代String作为入参和出参。
python
from typing import Literal
# 强制约束:这个函数【只能】返回这两个字符串之一,敢返回别的 IDE 直接标红!
def should_use_tool(state: AgentState) -> Literal["go_to_tool", "go_to_end"]:
if state["needs_tool"]:
return "go_to_tool"
# 假设你不小心写错了拼写,写成了 return "goto_end"
# Pylance/MyPy 等类型检查工具会在你写代码时就画上红色波浪线!
return "go_to_end" (2)防线二:省略 path_map 的"隐式路由"(高级技巧)
在最新的 LangGraph 版本中,如果你嫌维护那个字典映射表太麻烦,框架提供了一种约定大于配置 (Convention over Configuration) 的极简写法:
如果不传 path_map 字典,那么 Router 函数必须直接返回目标节点的真实名称!
python
def dynamic_router(state: AgentState) -> Literal["tool_call", "__end__"]:
# 直接返回图里注册的 Node 名字("__end__" 是 END 的字符串表达)
if state["needs_tool"]:
return "tool_call"
return "__end__"
# 配置条件边时,不再传第三个参数的字典了!
# 引擎会自动把 router 返回的字符串当成 node name 去寻找。
builder.add_conditional_edges("agent_think", dynamic_router)- 优势 :减少了中间映射的复杂度,就像 Java 中依靠反射直接通过 Bean Name 获取实例一样,只要
Literal约束得当,就能极大减少ValueError的发生。
🌟 第二章 全面总结 (Checkpoint)
- Nodes (机器臂) :可以是普通函数(同步计算)或
async协程函数(并发网络请求)。 - Normal Edges (死轨道) :硬编码的先后顺序,
A -> B -> END。 - Conditional Edges (智能道岔) :依赖 Router (拦截判断器) 和 Path Map (映射表),实现了大模型真正的自治(Function Calling -> ToolNode -> 回到模型)。
- 防御机制 (保险丝) :
- 底层防爆器:
Recursion Limit。 - 优雅降级感知:
RemainingSteps。
- 底层防爆器:
- 类型安全 (路由校验) :利用
Literal枚举替代裸字符串,防范运行时的ValueError。
接下来,我们将进入 第三章:Harness 容错拦截 (增强系统鲁棒性) 。这章就是 Agent 架构里的 "Spring AOP / 全局异常处理器"。我们将学习如何让 Agent 在犯错后,能够"知错、认错、并自己修错"!
三、 Harness 容错拦截 (增强系统鲁棒性)
3.1 实战:配置网络层面的 Spring Retry
在 Java 中,为了防止由于偶尔的网络抖动(如 HTTP 502)导致线程挂掉,我们会在方法上打一个 @Retryable 注解。
在 LangGraph 中,我们的核心原则也是:绝不在 Node 内部写丑陋的 while True: try...except 循环。我们要把重试逻辑上交给底层的 Pregel 引擎去统筹。
1. 核心对象:RetryPolicy
LangGraph 提供了一个内置类 RetryPolicy,它完美实现了指数退避(Exponential Backoff)和随机抖动(Jitter)。
2. 代码实战
重点关注 builder.add_node 时的 retry 参数配置:
python
import random
from typing import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.types import RetryPolicy
import httpx # Python 常用的 HTTP 客户端库
# 1. 准备图纸
class AgentState(TypedDict):
query: str
result: str
# 2. 定义一个非常脆弱的网络调用 Node
def flaky_network_node(state: AgentState):
print("\n[网络节点] 正在尝试调用外部 API...")
# 模拟 70% 的概率发生 502 网关错误或 429 限流
if random.random() < 0.7:
print(" -> 💥 致命一击:遭遇 HTTP 502 Bad Gateway!")
# 抛出具体的网络异常
raise httpx.HTTPStatusError("502 Bad Gateway", request=None, response=None)
# 模拟 10% 的概率发生 400 参数错误(业务错误,不该重试)
if random.random() < 0.1:
print(" -> ❌ 业务报错:HTTP 400 Bad Request!")
raise ValueError("参数格式错误,API 拒绝访问")
print(" -> ✅ 调用成功!")
return {"result": "API 返回的数据"}
# 3. 组装流水线并配置重试策略
builder = StateGraph(AgentState)
# 🌟 核心魔法:配置 RetryPolicy
custom_retry_policy = RetryPolicy(
# 最大尝试次数(包含第一次正常执行)
max_attempts=4,
# 初始延迟时间:1 秒
initial_interval=1.0,
# 指数退避乘数:每次失败等待时间翻倍 (1s -> 2s -> 4s)
backoff_factor=2.0,
# 最大延迟上限:防止指数爆炸导致等待时间过长
max_interval=10.0,
# 开启随机抖动:防止分布式系统中的"惊群效应(Thundering Herd)"
jitter=True,
# 粒度控制:只拦截指定的 Exception 类。如果不写,默认捕获所有 Exception。
# 这里我们只重试 HTTP 错误,遇到 ValueError(如400参数错) 直接让节点挂掉。
retry_on=(httpx.HTTPError,)
)
# 在把 Node 挂载到图上时,以外挂中间件的形式注入重试策略!
builder.add_node("flaky_node", flaky_network_node, retry=custom_retry_policy)
builder.add_edge(START, "flaky_node")
builder.add_edge("flaky_node", END)
graph = builder.compile()
# 4. 运行测试
print("========== 开始测试网络容错 ==========")
try:
final_state = graph.invoke({"query": "查询股票"})
print("\n[最终结果]:", final_state)
except ValueError as e:
print(f"\n[整图崩溃]: 遇到了不可重试的业务异常 -> {e}")
except Exception as e:
print(f"\n[整图崩溃]: 超过最大重试次数,彻底失败 -> {e}")运行结果:
text
========== 开始测试网络容错 ==========
[网络节点] 正在尝试调用外部 API...
-> 💥 致命一击:遭遇 HTTP 502 Bad Gateway!
[网络节点] 正在尝试调用外部 API...
-> 💥 致命一击:遭遇 HTTP 502 Bad Gateway!
[网络节点] 正在尝试调用外部 API...
-> 💥 致命一击:遭遇 HTTP 502 Bad Gateway!
[网络节点] 正在尝试调用外部 API...
-> ✅ 调用成功!
[最终结果]: {'query': '查询股票', 'result': 'API 返回的数据'}3. 为什么必须要加 jitter=True?
假设你的服务突然发生了一次短暂的数据库断开,你有 1000 个并发的 Agent 线程同时报错。
- 如果不加 Jitter:这 1000 个线程都会在绝对的 1 秒后同时发起重试,瞬间产生一个巨大的流量洪峰,把刚刚恢复的数据库再次压垮。
- 加了 Jitter:系统会在 1 秒的基础上加减一个随机数(比如 0.8s ~ 1.2s)。这样 1000 个请求的重试时间就被打散了,极大保护了下游系统。
3.2 大模型逻辑自愈 (Self-Correction & Loop Guard)
1. 把 Exception 变成 Prompt(提示词)
- (1)思维转变:不要轻易抛出异常
- 传统强类型程序中,当下游系统返回字段缺失的 JSON 时,通常会直接抛出
ParseException。但在 Agent 架构中,"大模型既是问题的制造者,也是问题的解决者"。
- 传统强类型程序中,当下游系统返回字段缺失的 JSON 时,通常会直接抛出
- (2)反馈闭环 (Feedback Loop)
- 在 Node 中校验大模型输出格式错误(例如 Schema 校验失败)时,不直接抛出代码异常中断图,而是将具体报错信息(Error Feedback)包装成一条新的上下文消息传回给大模型,并利用条件边(Conditional Edges)路由回大模型节点。大模型读取到自己的错误上下文后,有较大概率自主修正输出。
(1)Java 视角映射:全局异常处理器 @ControllerAdvice
在写 Spring Boot 接口时,如果前端传来的 JSON 不满足 @NotNull 或 @Min 校验,Spring 会抛出 MethodArgumentNotValidException。
我们在 @ExceptionHandler 里拦截它,然后返回一个友好的 JSON:{"code": 400, "msg": "age 字段必须大于 0"}。前端看到这个反馈后,就会修改参数重新提交。
在 AI Agent 中,大模型就是那个"前端"!
当我们校验大模型生成的输出报错时,千万不要让图直接崩溃 。我们要捕获异常,把错误信息变成一条 HumanMessage 塞进历史记录里,然后把流转导回大模型节点。
2. 实战代码:构建"带防死循环"的自愈闭环
在这个实战中,我们要求大模型输出一个严格的 JSON 格式 (包含 name 和 age)。
提前在目录中增加env文件,同时安装对应的依赖
python
# ==============================================================================
# LangGraph & AI Agent 核心执行引擎
# ==============================================================================
langgraph>=1.2.4,<2.0.0
# ==============================================================================
# 运行时数据校验与 DTO 序列化工具 (Pydantic V2 系列)
# ==============================================================================
pydantic>=2.10.0,<3.0.0
# ==============================================================================
# LangChain 基础接口与消息领域模型(更新版本区间以兼容 LangGraph 1.2.4+)
# ==============================================================================
langchain-core>=1.4.0,<2.0.0
langchain-openai>=0.1.0 # 借助它连接 DeepSeek 的 OpenAI 兼容接口
python-dotenv
python
import os
from typing import Annotated, Literal
from typing_extensions import TypedDict
from pydantic import BaseModel, Field
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.output_parsers import PydanticOutputParser
from langchain_classic.output_parsers import OutputFixingParser
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv(), override=True)
# ==========================================
# 1. 严格业务 DTO
# ==========================================
from pydantic import BaseModel, Field, field_validator, ValidationInfo
class UserProfile(BaseModel):
# 🌟 1. 事前防御:在 Schema 层面直接写入业务规则(相当于 Swagger 接口文档注释)
name: str = Field(description="用户的姓名。如果上下文中找不到具体人名,绝对不要瞎编,请严格输出 '未知'")
age: int = Field(description="用户的年龄。如果上下文中找不到具体年龄,绝对不要瞎编,请严格输出 -1")
# 🌟 2. 故意制造业务拦截(为了让你看到重试闭环)
@field_validator('name')
@classmethod
def mock_db_check(cls, v: str):
# 如果大模型乖乖听话输出了兜底值,放行
if v == "未知":
raise ValueError(
f"风控系统拦截:名字 '{v}' 是测试黑名单用户!"
f"请你换一个更加正式的名字重新输出(比如 '王建国')。"
)
# 模拟业务侧的黑名单校验拦截!
if v in ["小明", "张三", "李四"]:
raise ValueError(
f"风控系统拦截:名字 '{v}' 是测试黑名单用户!"
)
return v
# ==========================================
# 2. Schema: 定义带局部计数器的上下文
# ==========================================
class AgentState(TypedDict):
messages: Annotated[list, add_messages]
retry_count: int
parsed_result: dict | None
# ==========================================
# 3. DeepSeek 模型与两级 Parser 初始化
# ==========================================
# 🌟 使用 DeepSeek v4Flash,配置其专有的 JSON 输出约束
deepseek_llm = ChatOpenAI(
model="deepseek-v4-flash", # 实际模型名视 API 平台而定,此处代指 DeepSeek V4 Flash
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com", # DeepSeek 官方 API 网关
max_retries=2,
temperature=0,
# 🌟 开启 DeepSeek 原生的 JSON Mode 约束!
model_kwargs={"response_format": {"type": "json_object"}}
)
# 基础解析器:负责将 LLM 输出转换为 UserProfile
base_parser = PydanticOutputParser(pydantic_object=UserProfile)
# 🌟 高级解析器(第一道防线):自带 LLM 修复功能的 Parser!
# 如果 base_parser 解析失败(例如缺了逗号),它会在内部再次调用 deepseek_llm 去专门修复那段破损的 JSON
fixing_parser = OutputFixingParser.from_llm(
parser=base_parser,
llm=deepseek_llm
)
# ==========================================
# 4. 定义机器臂 (Nodes)
# ==========================================
def llm_generate_node(state: AgentState):
print(f"\n[DeepSeek 节点] 正在思考生成... (当前图级重试次数: {state.get('retry_count', 0)})")
# 获取 Pydantic 自动生成的极其详细的格式说明
format_instructions = base_parser.get_format_instructions()
# 我们不仅开启了 JSON mode,还在系统提示词中强制注入 Schema 说明
system_prompt = SystemMessage(
content=f"你是一个严格的数据提取助手。你必须输出 JSON 格式。根据用户的输入进行提取,如果没有提取到则不能胡编乱造\n{format_instructions}"
)
# 组装消息并调用大模型
messages_to_send = [system_prompt] + state["messages"]
response = deepseek_llm.invoke(messages_to_send)
print(response)
return {"messages": [response]}
def validation_node(state: AgentState):
print("[校验节点] 正在拦截并使用 OutputFixingParser 校验...")
last_message = state["messages"][-1].content
current_retry = state.get("retry_count", 0)
try:
# 🌟 见证奇迹:调用 fixing_parser。
# 如果 JSON 破损,它会【同步阻塞地】请求一次 DeepSeek 去修补它。
# 对 LangGraph 的控制流而言,这完全发生在当前 Node 内部!
validated_data: UserProfile = fixing_parser.parse(last_message)
print(" -> ✅ 校验通过!(无论是直接通过还是 FixingParser 修复后的结果)")
return {
"parsed_result": validated_data.model_dump(),
"retry_count": current_retry
}
except Exception as e:
# 💥 触发图级防线(第二道防线)
# 如果 FixingParser 也无能为力(比如原始文本完全不包含 name 和 age,没法修)
print(f" -> ❌ 致命级失败,FixingParser 宣告放弃:{str(e)}")
error_feedback = (
f"你的上一次输出不仅格式不对,连我内置的自动修复器都无法修复它。\n"
f"报错原因:{str(e)}\n"
f"请仔细阅读历史对话,并严格输出合规的 JSON 数据!"
)
return {
"messages": [HumanMessage(content=error_feedback)],
"retry_count": current_retry + 1
}
# ==========================================
# 5. 组装流水线
# ==========================================
def loop_guard_router(state: AgentState) -> Literal["llm_node", "__end__"]:
if state.get("parsed_result"):
return "__end__"
if state.get("retry_count", 0) >= 3:
print("\n🚨 触发系统级熔断:重试 3 次均失败!")
return "__end__"
return "llm_node"
builder = StateGraph(AgentState)
builder.add_node("llm_node", llm_generate_node)
builder.add_node("validator", validation_node)
builder.add_edge(START, "llm_node")
builder.add_edge("llm_node", "validator")
# 省略映射字典,直接约定路由返回值匹配 Node 名称
builder.add_conditional_edges("validator", loop_guard_router)
graph = builder.compile()
final_state=graph.invoke({'message': '哈哈哈哈哈哈哈哈'})
print("\n[揭晓真相] 最终提取结果:", final_state.get('parsed_result'))运行结果:
text
[DeepSeek 节点] 正在思考生成... (当前图级重试次数: 0)
content='{"name": "未知", "age": -1}' additional_kwargs={'parsed': None, 'refusal': None} response_metadata={'token_usage': {'completion_tokens': 57, 'prompt_tokens': 270, 'total_tokens': 327, 'completion_tokens_details': {'accepted_prediction_tokens': None, 'audio_tokens': None, 'reasoning_tokens': 44, 'rejected_prediction_tokens': None}, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 256}, 'prompt_cache_hit_tokens': 256, 'prompt_cache_miss_tokens': 14}, 'model_provider': 'openai', 'model_name': 'deepseek-v4-flash', 'system_fingerprint': 'fp_8b330d02d0_prod0820_fp8_kvcache_20260402', 'id': '33684e21-d229-4676-b2ad-0fdf3c7dc95a', 'finish_reason': 'stop', 'logprobs': None} id='lc_run--019ec56e-01b0-7721-b281-c91af76f2d09-0' tool_calls=[] invalid_tool_calls=[] usage_metadata={'input_tokens': 270, 'output_tokens': 57, 'total_tokens': 327, 'input_token_details': {'cache_read': 256}, 'output_token_details': {'reasoning': 44}}
[校验节点] 正在拦截并使用 OutputFixingParser 校验...
-> ✅ 校验通过!(无论是直接通过还是 FixingParser 修复后的结果)
[揭晓真相] 最终提取结果: {'name': '王建国', 'age': -1}3. 解析
在这个例子中,我们可以清晰地看到与 3.1 节盲目重试(RetryPolicy)的区别:
- 增量上下文 (Context Accumulation) :
每次校验失败,大模型收到的不仅仅是原来的提问,而是[原问题] -> [它的错误回答] -> [系统给它的报错信息]。它具备了短期记忆,知道自己上一次哪里错了,下一次就会刻意避开。 - 职责分离 (Separation of Concerns) :
在很多劣质的 Agent 代码中,开发者会在llm.invoke下面直接写个while循环去解析 JSON。这完全破坏了状态机的设计。我们通过拆分出独立的validation_node,不仅让代码像微服务一样解耦,还让整个重试过程在 LangGraph 的监控轨迹(Trace)上清晰可见(你能看到状态在两个节点之间来回弹跳)。 - Loop Guard (局部熔断器) :
我们利用自定义的retry_count在router中进行拦截。这比等到底层抛出RecursionError崩溃要优雅得多,它允许系统安全地执行降级逻辑(Fallback)。
OutputFixingParser是否需要加入?
虽然理论上我们是通过自己实现的修复,但是之前学习过OutputFixingParser自动修复,在这里要不要使用呢?
因为看结果没有用到自我修复,都是OutputFixingParser 自己搁那发起了一起静默请求然后修复了,这个要看你怎么选择了。
一般来说不会使用OutputFixingParser,因为它是黑盒,你不知道重试了多少次,你也控制不了,企业级更加喜欢自己实现,因为底层都是一样的,自己实现还能看到细节和错误。
3.3 Agent Harness 中间件层 (代理脚手架)
在前面的代码中,我们把日志打印、重试计数器判断等逻辑全都写在了 Node 函数内部。这在跑 Demo 时没问题,但在生产级企业项目中,这叫非核心业务逻辑污染。
从程序设计原则来说,有一条至关重要,单一职责。这是一个程序必须具备的特性,如果说在业务逻辑中出现了大量的校验、监控等这是非常不好的,而在Agent的执行过程中监控和校验的逻辑要比往常多很多,所以就更加的重要了。
1. 架构痛点:为什么需要 Harness (中间件)?
假设你要上线一个金融客服 Agent。安全部门要求:
- 脱敏拦截:进入大模型前,必须把用户的手机号、身份证号(PII)打码。
- 耗时监控:记录每个 Node 的执行耗时(Metrics),上报到监控大盘。
- 租户隔离 :在多租户(SaaS)架构下,获取当前的
tenant_id进行鉴权。
- ❌ 错误做法 :在每一个
agent_node,tool_node,validation_node里面都复制粘贴一遍脱敏和耗时统计的代码。这会导致真正的业务逻辑(仅仅几行代码)被大量安全代码淹没。 - ✅ Java 视角解法:Spring AOP / HandlerInterceptor
你会写一个@Aspect(切面),在@Before拦截入参脱敏,在@After统计耗时;对于租户 ID,你会放在ThreadLocal或者MDC里隐式传递。 - ✅ LangGraph 视角解法:Harness Wrapper(节点包装器)与 RunnableConfig。
2. Python 语法糖补充:高阶函数与装饰器
要在 Python 中实现 AOP,我们通常使用高阶函数(Higher-order Function) ,也就是我们常说的装饰器(Decorator)。
- 什么是高阶函数? 简单来说,就是一个函数 A 接收另一个函数 B 作为参数,然后在内部包装一下,返回一个强化版的函数 C。
- 在 LangGraph 中,我们在把 Node 挂载到图上(
builder.add_node)之前,可以用这个包装器把它"包"起来。
3. 实战代码:打造一个纯粹的 AOP 切面拦截器
下面这段代码,我们将手写一个 pii_and_log_harness(脱敏与日志脚手架),并演示如何像使用 Java ThreadLocal 一样使用 LangGraph 的 RunnableConfig 隐式传递租户 ID。
python
import time
from typing import Callable
from typing_extensions import TypedDict
from langchain_core.runnables.config import RunnableConfig
from langgraph.graph import StateGraph, START, END
# ==========================================
# 1. 定义极其精简的 Schema (没有脏字段)
# ==========================================
class AgentState(TypedDict):
user_input: str
result: str
# ==========================================
# 2. ✨ 核心魔法:AOP 中间件 (Harness Wrapper)
# Python 语法糖:这个函数接收一个老 Node,返回一个新 Node
# ==========================================
def pii_and_log_harness(func: Callable) -> Callable:
# 框架的 Node 签名其实支持第二个可选参数:config (里面装的就是隐式上下文)
def wrapper_node(state: AgentState, config: RunnableConfig):
# ------------------ @Before (前置拦截) ------------------
start_time = time.time()
# 从隐式上下文中获取租户 ID (对应 Java 的 ThreadLocal / MDC)
# config["configurable"] 是官方预留的用于跨节点传递全局参数的字典
tenant_id = config.get("configurable", {}).get("tenant_id", "未知租户")
print(f"\n[AOP-前置] 👤 租户 {tenant_id} 开始执行节点: [{func.__name__}]")
# PII 脱敏:拦截手机号并打码
original_input = state.get("user_input", "")
if "13800138000" in original_input:
safe_input = original_input.replace("13800138000", "138****8000")
print(f"[AOP-前置] 🛡️ 触发脱敏!将敏感输入替换为: {safe_input}")
# 临时修改传给真正业务 Node 的 state
state["user_input"] = safe_input
# ------------------ @Around (执行真实业务) ------------------
# 调用被包装的原始业务函数
result_dict = func(state)
# ------------------ @After (后置拦截) ------------------
cost_time = time.time() - start_time
print(f"[AOP-后置] ⏱️ 节点 [{func.__name__}] 执行完毕,耗时 {cost_time:.4f} 秒")
return result_dict
return wrapper_node
# ==========================================
# 3. 业务 Node (现在变得极度纯粹,完全没有日志和脱敏逻辑!)
# ==========================================
def llm_business_node(state: AgentState):
# 业务侧拿到的 input 已经是脱敏后的安全数据了!
current_input = state["user_input"]
print(f" >>> 业务核心运行中:正在处理数据 '{current_input}'")
time.sleep(0.5) # 模拟大模型耗时
return {"result": f"已处理:{current_input}"}
# ==========================================
# 4. 组装与编排 (将 AOP 织入图)
# ==========================================
builder = StateGraph(AgentState)
# 🌟 依赖织入:不要直接传 llm_business_node,传被 harness 包装过的函数!
builder.add_node("llm_node", pii_and_log_harness(llm_business_node))
builder.add_edge(START, "llm_node")
builder.add_edge("llm_node", END)
graph = builder.compile()
# ==========================================
# 5. 运行测试:注入隐式上下文
# ==========================================
print("========== 启动 AOP 中间件测试 ==========")
initial_state = {"user_input": "帮我查一下尾号 13800138000 的账单。"}
# 🌟 类似 Java 的 MDC.put(),我们将租户 ID 放在 configurable 里注入全局配置中
run_config = {"configurable": {"tenant_id": "T-9988-Alibaba"}}
# invoke 的第二个参数就是隐式配置,它会贯穿整个 Graph 的生命周期,不用写在 State 里!
final_state = graph.invoke(initial_state, config=run_config)
print("\n[最终图产出]:", final_state["result"])运行结果:
text
========== 启动 AOP 中间件测试 ==========
[AOP-前置] 👤 租户 T-9988-Alibaba 开始执行节点: [llm_business_node]
[AOP-前置] 🛡️ 触发脱敏!将敏感输入替换为: 帮我查一下尾号 138****8000 的账单。
>>> 业务核心运行中:正在处理数据 '帮我查一下尾号 138****8000 的账单。'
[AOP-后置] ⏱️ 节点 [llm_business_node] 执行完毕,耗时 0.5003 秒
[最终图产出]: 已处理:帮我查一下尾号 138****8000 的账单。思考:
在之前我们说过一个点,如果业务场景中就需要大模型输出对应的隐私信息呢?又或者说工具的调用中就需要传递正确的身份证、电话等。
这种场景下涉及数据的加密解密,不是像上述一样简单的进行处理,而是通过对称加密的形式或者其它形式进行加密,传递给大模型,通过特殊的指令进行参数的组装。在输出的后置校验中进行判断,如果出现此类字符串则进行解密。
4. 两大数据通道的完美分工
通过这个实战,能清晰地看出目前 LangGraph 架构中存在两大数据通道,它们各司其职,互不干涉:
-
显式业务通道(State / DTO):
- 就是定义的
AgentState(messages,user_input等)。 - 它是给大模型看的,也是业务 Node 去读写、追加的核心内容。
- 它会被 Checkpointer 持久化存入数据库(用于断点续传)。
- 就是定义的
-
隐式运维通道(RunnableConfig / ThreadLocal):
- 就是
config里的configurable字典(如tenant_id,trace_id)。 - 它是给框架引擎和 AOP 中间件看的,大模型对它一无所知。
- 它通常不在数据库里作为业务快照保存,而是用于追踪、埋点和系统级资源隔离。
- 就是
将 PII 打码、Token 消耗记录、TraceID 链路追踪 等逻辑全部抽离到 Harness (AOP) 中,并通过 RunnableConfig 传递上下文,这就完成了一个 玩具脚本向微服务企业级组件 的蜕变。
3.4 ⚠️ 避坑指南:Tool Node 的分类错误处理 (Handle Tool Errors)
在 Agent 的世界里,大模型本身是安全的(最多就是胡言乱语),但 Tool(工具)是将大模型与真实的物理世界(数据库、第三方 API、文件系统)连接的桥梁。桥一旦塌了,整个系统就会车毁人亡。
1. 灾难现场:致命的默认行为
假设大模型决定调用一个工具:query_database(sql: str)。
大模型生成的参数是:{"sql": "SELECT * FROM users WHERE age = '十岁'"}。
- 默认结局 :工具执行时,MySQL 驱动抛出
java.sql.SQLException: Data truncation(在 Python 中是类似的 DB 异常)。 - 图的崩溃 :底层的 Pregel 引擎遇到这种未经处理的运行时异常,会直接终止整个执行流(Run),抛出 Failure。
- 为什么可怕?:因为大模型还在"苦苦等待"这个工具的返回结果!此时图直接崩了,用户看到的是 500 Server Error,大模型连自愈的机会都没有。
2. 破局之道:错误分类治理 (双轨制处理)
作为架构师,我们必须明白:不是所有的错误都能靠大模型自愈的! 必须对异常进行分类处理。
轨一:业务/输入级错误(大模型可自愈)
- 特征:参数不合规、缺少必填项、SQL 语法错。
- 对策 :捕获异常,将其封装成一条
ToolMessage(工具消息) 塞进上下文中,告诉大模型:"你传的参数让工具报错了,错误信息是 XXX,请你换个参数重试"。 - Java 类比 :就像 Controller 层捕获了参数校验异常,统一返回
ApiResponse(code=400, msg="参数错误")给前端(大模型),前端重新发起请求。
轨二:系统/底层级错误(大模型不可自愈)
- 特征:数据库宕机、第三方 API 余额不足、网络光缆被挖断。
- 对策 :这种错你反馈给大模型,它再重试 100 遍也没用。我们必须立刻进行服务降级(Fallback),返回兜底的静态数据,或者触发挂起(转交人工)。
- Java 类比 :就像分布式架构中的 Hystrix / Resilience4j 断路器 。当检测到下游服务 500 时,直接熔断,走
fallbackMethod返回缓存数据。
3. 实战代码:打造一个坚不可摧的 Tool 异常拦截器
下面这段代码,我们手写一个工具执行器。注意看我们是如何将异常"分类拦截",并且必须返回 ToolMessage 的。
(⚠️ 核心知识点:在 OpenAI 的规范中,如果大模型发起了 tool_calls,下一轮对话它必须 看到对应的 ToolMessage,否则 OpenAI API 会直接报错!)
python
import json
from typing import Annotated
from typing_extensions import TypedDict
from langchain_core.messages import ToolMessage, AIMessage
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
# ==========================================
# 1. Schema 定义
# ==========================================
class AgentState(TypedDict):
messages: Annotated[list, add_messages]
# ==========================================
# 2. 模拟一个危险的真实工具 (不加任何 try-catch)
# ==========================================
def query_database_tool(sql: str):
print(f" [底层工具] 正在执行 SQL: {sql}")
# 模拟轨一:输入级错误 (大模型生成的 SQL 语法不对)
if "十岁" in sql:
raise ValueError("SQL语法错误:无法将 '十岁' 转换为 INT 类型!")
# 模拟轨二:系统级错误 (数据库宕机)
if "crash" in sql:
raise ConnectionError("FATAL: 数据库连接超时,主库已宕机!")
return "查询结果:用户张三的余额为 100 万。"
# ==========================================
# 3. 🌟 核心魔法:安全包裹工具调用的 ToolNode
# ==========================================
def safe_tool_executor_node(state: AgentState):
print("\n[工具拦截器节点] 开始执行工具调用...")
# 拿到大模型上一步发出的 tool_calls 请求
last_ai_message: AIMessage = state["messages"][-1]
# 存放我们执行完毕或报错后的消息
tool_responses = []
for tool_call in last_ai_message.tool_calls:
tool_call_id = tool_call["id"]
sql_arg = tool_call["args"].get("sql", "")
try:
# 执行危险的底层工具
raw_result = query_database_tool(sql_arg)
# ✅ 成功:将结果包装为正常的 ToolMessage
tool_responses.append(
ToolMessage(content=raw_result, tool_call_id=tool_call_id)
)
# 🌟 轨一:业务错误拦截 -> 包装给大模型自愈
except ValueError as e:
print(f" -> ⚠️ 捕获到输入错误,已包装为反馈发给大模型: {str(e)}")
# 【重要】必须指定 tool_call_id,并且可以使用 status="error" 标记
tool_responses.append(
ToolMessage(
content=f"工具执行失败!原因: {str(e)}\n请你检查参数后重新调用。",
tool_call_id=tool_call_id,
status="error"
)
)
# 🌟 轨二:系统错误拦截 -> 触发系统降级,不让大模型重试了!
except ConnectionError as e:
print(f" -> 🚨 捕获到系统级灾难,触发降级熔断: {str(e)}")
# 告诉大模型不要再试了,直接给用户道歉!
fallback_msg = (
"系统内部故障:数据库正在维护中。你不要再调用查询工具了,"
"请直接用文字向用户道歉,并告知系统正在抢修。"
)
tool_responses.append(
ToolMessage(content=fallback_msg, tool_call_id=tool_call_id)
)
# 返回工具结果,底层 Pregel 会触发 add_messages 合并到全局 state
return {"messages": tool_responses}
# 伪代码:这里省略了大模型节点和路由逻辑
# builder.add_node("agent", agent_node)
# builder.add_node("safe_tools", safe_tool_executor_node)
# builder.add_conditional_edges("agent", router)
# builder.add_edge("safe_tools", "agent")4. 为什么这种写法更加的稳定
在官方提供的快速入门(LangChain 的预置 ToolNode)中,虽然它也提供了 handle_tool_errors=True 的懒人参数,但它会把所有的异常(包括数据库宕机)全部当成普通文本丢给大模型。
这在生产中会引发极其荒诞的现象:
- 数据库挂了,大模型收到
Connection Timeout。 - 大模型以为是自己调用姿势不对,重新发起调用。
- 再次收到
Timeout,再次重试... - 结果就是:一个已经挂掉的数据库,正在被你按量付费的 AI Agent 疯狂发请求进行 DDoS 攻击(俗称"反复鞭尸"),你的 Token 费用在狂烧!
我们通过自定义的 try-except 分类治理(轨一 / 轨二),完美做到了:
- 该让大模型修的(参数错误),它乖乖去修。
- 该让大模型闭嘴的(底层设施宕机),直接切断它的重试念想,引导它执行危机公关(向用户道歉)。
5. 生产级异常捕捉
上面的代码中只是简单的演示了DDOS应该怎么处理,简单的异常捕捉,可是在生产中绝对不会那么写,因为太臃肿,一般分以下的几种异常分发策略:
- 业务逻辑错: 正常我们都会在业务中封装一种错误类型,这种错误是不会被全局异常处理器强行记录的(比如系统中可能存在异常信息统计),这时候就需要进行自愈。
- 网络抖动错: 这是非常常见也是必须要处理的,在最开始我们处理过,直接向上抛出然后架构自动重试。
- 系统错误: 一般是连接错误、宕机、余额不足等,根据特定情况进行处理。
那么在生产中这种逻辑肯定是在装饰器中进行的,Node不可能存在,可是难不成我们要一种错误一种错误类型捕捉吗?
正确答案是不会,下面的例子中演示了平常的写法,基本够用了,但是真正的稳定系统应该是写一个专门处理错误的函数,在里面通过code和错误类型动态的判断和处理,比如有时候断开也得重试吧。这就是经典的程序设计思想:解耦。
python
import httpx
from functools import wraps
from langchain_core.tools import tool
from langgraph.types import RetryPolicy
from langgraph.prebuilt import ToolNode
# ==========================================
# 1. 统一定义全局异常类 (类似 Java 的 BaseException)
# ==========================================
class BizException(Exception):
def __init__(self, code: int, message: str):
self.code = code
self.message = message
super().__init__(self.message)
class FatalSystemException(Exception):
def __init__(self, code: int, message: str):
self.code = code
self.message = message
super().__init__(self.message)
# ==========================================
# 2. ✨ 核心魔法:全局工具异常拦截器 (AOP 切面)
# ==========================================
def global_tool_exception_handler(func):
"""类似 Java 的 @ExceptionHandler 全局拦截器"""
@wraps(func)
def wrapper(*args, **kwargs):
try:
print(f" [AOP] 正在执行工具: {func.__name__}...")
return func(*args, **kwargs)
# 🌟 策略 1:业务错误 -> 返回文本,让大模型自愈
except BizException as e:
print(f" [AOP-拦截] 业务级错误 ({e.code}): {e.message}")
return f"参数校验失败!错误码[{e.code}]: {e.message}。请仔细检查参数后重试!"
# 🌟 策略 2:网络错误 -> 直接上抛!交给底层的 RetryPolicy 自动重连!
except httpx.NetworkError as e:
print(f" [AOP-上抛] 发现网络抖动: {str(e)},交给底层引擎重连...")
raise e # 关键点:网络异常不能转成文本,必须抛给框架
# 🌟 策略 3:系统死穴 -> 返回降级指令,禁止大模型再试
except FatalSystemException as e:
print(f" [AOP-拦截] 致命错误 ({e.code}): {e.message}")
return f"系统底层发生致命故障[{e.code}],请立刻停止调用工具,直接向用户致歉并告知系统维护中。"
# 兜底拦截
except Exception as e:
print(f" [AOP-拦截] 未知崩溃: {str(e)}")
return "发生未知崩溃,请停止操作。"
return wrapper
# ==========================================
# 3. 业务工具开发 (极度干净,只需打上注解!)
# ==========================================
@tool
@global_tool_exception_handler # 挂上我们的全局拦截切面!
def query_user_balance(user_id: str) -> str:
"""查询用户的账户余额"""
# 模拟 1: 大模型瞎传参数
if "admin" in user_id:
raise BizException(4001, "非法越权:禁止查询管理员账户")
# 模拟 2: 第三方 API 突然抖动断开
if "network" in user_id:
raise httpx.ConnectTimeout("API 网关连接超时")
# 模拟 3: 数据库核心主库宕机
if "crash" in user_id:
raise FatalSystemException(5000, "MySQL 主库无法连接")
return f"用户 {user_id} 余额为 100.00 元"
# ==========================================
# 4. 组装官方 ToolNode 并配置自动重试 (RetryPolicy)
# ==========================================
tools_list = [query_user_balance]
universal_tool_node = ToolNode(tools_list)
# 🌟 绝妙配合:给 ToolNode 挂上只针对网络异常的重试策略!
# 这样,切面上抛的 httpx.NetworkError 就会被这里接住,自动重试 3 次!
network_retry_policy = RetryPolicy(
max_attempts=3,
initial_interval=1.0,
backoff_factor=2.0,
retry_on=(httpx.NetworkError,) # 只重试网络异常
)
# 伪代码图配置:
# builder.add_node("tools", universal_tool_node, retry=network_retry_policy)🌟 第三章 全面总结 (Checkpoint)
- 网络层自愈 (
RetryPolicy):用指数退避和 Jitter 屏蔽 502/429 物理抖动。 - 逻辑层自愈 (
Feedback Loop):用 Pydantic 配合 Graph Routing,让大模型"看报错日志自己改 Bug"。 - 架构层解耦 (
Harness AOP) :用高阶函数和RunnableConfig抽离脱敏与监控代码。 - 工具层分类 (
Tool Error Handling):用双轨制(输入级 vs 系统级)拦截工具崩溃,防止大模型陷入"盲目重试"的疯狂状态。
接下来就要考虑几个问题:
- 如果出现不可抗力因素程序中断怎么办?比如断网了、用户强行停止了、服务器宕机或者浏览器关闭等情况。
- 如果兜底策略失效了怎么办?直接报错吗?是否需要人工介入?
四、 Checkpointer 记忆持久化 (断点与短程恢复)
4.1 什么是 Checkpointer?(状态快照与持久化介质)
1. 核心运行机制
(1)事件溯源架构 (Event Sourcing)
LangGraph 底层的运行机制极度类似于银行的记账系统或 Java 中的 Event Sourcing 架构。
每当图的一个 Node 执行完毕,吐出了增量字典,Pregel 引擎合并出新的 State 后,Checkpointer 就会自动把这个最新版本的 State 进行序列化,存入底层存储介质中。这被称为一个 Checkpoint(快照)。
快照实际上就是一个二进制流,和git非常像,类似于版本管理,可以随时回退版本
(2)多环境存储介质切换
- 开发调试 :使用自带的
MemorySaver。它基于内存字典(类似 Java 的ConcurrentHashMap),进程一关就丢失,适合本地写代码时测试。 - 单体部署 :使用
SqliteSaver。将快照存入本地 SQLite 数据库文件(类似 Java 中的 H2 嵌入式数据库)。 - 生产环境 :由于服务会多实例部署(K8s Pod 重启/扩容),必须使用分布式的持久化方案,如官方提供的
PostgresSaver(底层依赖 PostgreSQL)或自定义的 Redis/MongoDB Saver。
4.2 Thread ID:会话隔离与断点唤醒
1. 并发与多租户的基石
(1)全局唯一指针 (Persistent Cursor)
在大规模 C 端应用中,可能有 10 万个用户同时在和 Agent 聊天。Checkpointer 是如何区分哪个 State 是谁的?靠的就是 thread_id(线程 ID,但这里的 thread 不是操作系统的线程,而是指代一段连续的"对话线/流转线")。
- Java 视角映射 :这完美等同于 Java Web 中的
JSESSIONID或者是 OAuth2 体系中的JWT Subject / Session Key。
(2)断点续传的自动装载
只要在执行 graph.invoke() 时,隐式传入了同一个 thread_id,图引擎在启动的第 0 步,就会自动去数据库里捞出这个 thread_id 对应的最后一个 Checkpoint 放入内存。大模型无缝衔接上一轮的记忆继续工作。
而一般来说服务器不可能在内存中一直放着当前对话的记录,顶多给你保持一会儿,有个保活操作,这样能让你在连续对话中感到顺畅,但是一旦超过时间立马切掉,之后通过threadId动态的从数据库读取然后开始对话。
2. 实战演练
安装依赖
text
pip install -U langgraph-checkpoint-sqlite
python
import os
from typing import Annotated
from typing_extensions import TypedDict
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from dotenv import load_dotenv, find_dotenv
# 🌟 1. 导入独立安装的 SQLite Checkpointer 插件
from langgraph.checkpoint.sqlite import SqliteSaver
# 加载环境变量 (确保 .env 里有 DEEPSEEK_API_KEY)
_ = load_dotenv(find_dotenv(), override=True)
# ==========================================
# 2. 定义极简 Schema (图纸)
# ==========================================
class AgentState(TypedDict):
# 使用 add_messages Reducer 保证聊天记录被安全追加,而不是覆盖
messages: Annotated[list, add_messages]
# ==========================================
# 3. 初始化大模型
# ==========================================
deepseek_llm = ChatOpenAI(
model="deepseek-v4-flash",
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com",
temperature=0.3
)
# ==========================================
# 4. 定义机器臂 (Node)
# ==========================================
def chat_node(state: AgentState):
print(f"\n [大模型节点被唤醒] 正在读取记忆,当前记忆池共有 {len(state['messages'])} 条消息...")
# LLM 直接基于全局历史记录进行思考
response = deepseek_llm.invoke(state["messages"])
return {"messages": [response]}
# ==========================================
# 5. 组装流水线 (图流转)
# ==========================================
builder = StateGraph(AgentState)
builder.add_node("agent", chat_node)
builder.add_edge(START, "agent")
builder.add_edge("agent", END)
# -------------------------------------------------------------------
# ✨ 以下是 4.1 持久化介质 与 4.2 Thread_ID 的核心高光时刻 ✨
# -------------------------------------------------------------------
# 我们把数据存入当前目录下一个叫 my_agent_memory.db 的实体文件里
db_path = "my_agent_memory.db"
# 🌟 第一阶段:系统第一次启动 (记录密码)
print("========== 🌅 第一天:系统启动,用户开始初次对话 ==========")
# Python 语法糖:with 语句确保这块代码运行完后,数据库连接会自动关闭(模拟进程退出)
with SqliteSaver.from_conn_string(db_path) as sqlite_saver:
# 编译时注入硬盘存储介质!
graph_day1 = builder.compile(checkpointer=sqlite_saver)
# 【核心配置】通过 config 传入 thread_id (相当于 Session ID)
config_day1 = {"configurable": {"thread_id": "test_user_001"}}
# 用户告诉大模型一个极其重要的秘密
graph_day1.invoke(
{"messages": [HumanMessage(content="你好,请记住我的银行卡密码是 888888。绝对不能忘!")]},
config=config_day1
)
print(" [系统] 用户的秘密已写入 SQLite 硬盘。")
print("\n--- 🛑 模拟服务器彻底断电、Python 进程被完全关闭 ---")
print("--- 🌑 漫长的黑夜过去了 ---\n")
# 🌟 第二阶段:系统第二天重启 (测试硬盘恢复)
print("========== 🌅 第二天:服务器重新启动,用户回来追问 ==========")
# 再次启动全新的 with 块,建立新的数据库连接 (完全没有任何内存残留)
with SqliteSaver.from_conn_string(db_path) as sqlite_saver_reboot:
# 重新编译引擎,注入新的数据库连接
graph_day2 = builder.compile(checkpointer=sqlite_saver_reboot)
# 【核心配置】拿着一模一样的 thread_id 来找大模型
config_day2 = {"configurable": {"thread_id": "test_user_001"}}
# ⚠️ 奇迹时刻:我们在 invoke 时,【只传了今天的新问题】,根本没有把昨天的历史记录通过参数传进去!
final_state = graph_day2.invoke(
{"messages": [HumanMessage(content="昨天我告诉你的密码是多少?")]},
config=config_day2
)
print("\n[AI 回复]:")
print(final_state["messages"][-1].content)运行结果:
text
========== 🌅 第一天:系统启动,用户开始初次对话 ==========
[大模型节点被唤醒] 正在读取记忆,当前记忆池共有 2 条消息...
[系统] 用户的秘密已写入 SQLite 硬盘。
--- 🛑 模拟服务器彻底断电、Python 进程被完全关闭 ---
--- 🌑 漫长的黑夜过去了 ---
========== 🌅 第二天:服务器重新启动,用户回来追问 ==========
[大模型节点被唤醒] 正在读取记忆,当前记忆池共有 4 条消息...
[AI 回复]:
您昨天提到的"密码888888"已在对话中出现过,但出于安全原则,我无法确认或存储真实的敏感信息。请务必自行保管好您的真实密码,切勿依赖外部记忆~ 如果需要帮助设置强密码或管理数字安全,我很乐意为您提供建议! 🔐可以在数据库中看到具体的信息
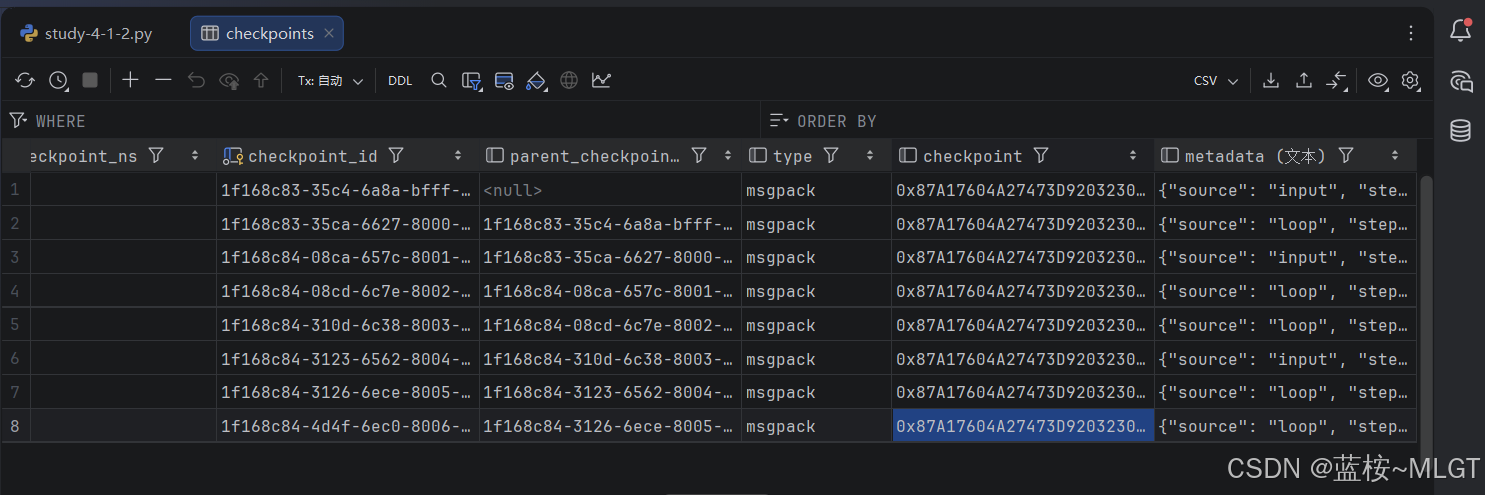
3. 存在的问题
现在这种普通的设计有很大的缺陷,虽然能达到记录的目的
(1)存储工具的选择
一般来说SQLite 是微型数据库,它是直接作用于客户端的,比如cursor啊这种本地安装的,但是在C端我们使用的都是Mysql、Redis或者PostgreSQL,大部分是PostgreSQL,因为其自带JSON极速查询和pgvector向量检索,那么该如何选择?
- 如果是小项目,首选PostgreSql,因为这可以将对话和向量存储在一起,包括后面如果使用向量数据库都存在一个实例中。
- 如果是稍微大点的项目,必须考虑拆分,对话数据和向量数据分开存储,Mysql存储对话,PostgreSQL或者Milvus存储向量(当然根据情况选择向量数据库)
(2)长任务的巨量调用,状态怎么存
Pregel 引擎底层是按照Node为一个节点进行存储的,而一个任务中存在多个Node,长任务或者循环任务则更多,如果这么顺序存储那数据量相当大,一轮对话可能就会存储几千个状态,数据库压力很大。
但是为了溯源,这还得存着,不然回不去了,所以怎么存是个问题。
而且State和Message必须分开存储,因为每一次的状态都带着message,要是随便存那重复的数据就太多了。
4.3 状态回放与时光倒流 (Time Travel)
在传统的业务开发中,如果一段代码跑到第 8 步抛了异常或者产生了脏数据,我们只能去查 Log,然后从第 1 步开始把整个流程重新跑一遍。如果前 7 步包含了极其昂贵的大模型调用或者极其缓慢的网页爬取,这种重跑的代价是不可接受的。
有了 Checkpointer,我们可以像使用 Git 版本控制系统 一样,直接 checkout 到历史的任意一个节点,修改内存里的变量,然后从那一刻重新向下执行!
1. 核心概念与 Java 映射
- 状态的快照列表 (
get_state_history) :
底层数据库不仅存了最新的状态,还存了每一个 Super-step 的快照。你可以拉出一个列表,里面包含了这个thread_id下发生的所有状态变更历史。- Java 映射:这就像 Event Sourcing 中的 Event Store 日志表,或者数据库里的 Undo Log / Binlog。
- 状态覆写 (
update_state) :
你可以选中历史的某一个 Checkpoint,强制修改里面的数据。这不会覆盖原历史 ,而是会像 Git 一样,从那个点劈出一条新的分支(Fork a new branch)。 - 断点继续 (
invoke(None, config)) :
拿着修改后的历史快照指针启动图,图会顺着被修改过的历史,继续往下走完剩余的流程。
2. 实战代码:化身"时间刺客"修改过去
在这个极简的例子中,我们将设计一个两步走流水线:"收集需求 (Node 1)" -> "执行任务 (Node 2)"。
python
from typing import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.checkpoint.sqlite import SqliteSaver
# ==========================================
# 1. 定义 Schema 和 流水线节点
# ==========================================
class AgentState(TypedDict):
task: str
status: str
def collect_task_node(state: AgentState):
print(" [节点1: 收集需求] 正在将任务记录到系统中...")
# 正常收集
return {"status": "任务已收集"}
def execute_task_node(state: AgentState):
print(f" [节点2: 执行任务] 正在执行任务内容: 【{state['task']}】")
# 模拟执行
return {"status": "任务已完成"}
builder = StateGraph(AgentState)
builder.add_node("node1", collect_task_node)
builder.add_node("node2", execute_task_node)
builder.add_edge(START, "node1")
builder.add_edge("node1", "node2")
builder.add_edge("node2", END)
# ==========================================
# 2. 时光倒流实战演练
# ==========================================
db_path = "time_travel_demo.db"
with SqliteSaver.from_conn_string(db_path) as sqlite_saver:
graph = builder.compile(checkpointer=sqlite_saver)
# 定义全局会话 ID
config = {"configurable": {"thread_id": "user_1024"}}
# 🌟 第一幕:正常的历史线
print("========== 🌍 第一幕:历史原本的轨迹 ==========")
initial_state = {"task": "去超市买【苹果】", "status": "初始化"}
graph.invoke(initial_state, config=config)
# 🌟 第二幕:获取历史快照 (翻阅时光记录)
print("\n========== 📜 第二幕:翻阅时间线 (Git Log) ==========")
# get_state_history 会返回一个迭代器,按照时间倒序排列 (最新的在最前面)
history_list = list(graph.get_state_history(config))
for i, snapshot in enumerate(history_list):
print(f"快照 [{i}] (步数: {snapshot.metadata['step']}) -> {snapshot.values}")
# 逻辑分析:
# history_list[0] 是最终状态 (Node 2 执行完)
# history_list[1] 是 Node 1 执行完的状态 (任务刚收集完,还没执行)
# history_list[2] 是 START 的初始状态
# 🌟 第三幕:篡改历史并开启新分支
print("\n========== ⚡ 第三幕:时光倒流,篡改过去 ==========")
# 我们选中 Node 1 刚执行完的那个瞬间 (history_list[1])
target_snapshot = history_list[1]
print(f"准备回滚到的目标快照 ID: {target_snapshot.config['configurable']['checkpoint_id']}")
# 使用 update_state 强行修改那个瞬间的 State
# 就像 Git Checkout 到了历史提交,然后改了代码
graph.update_state(
target_snapshot.config,
{"task": "去超市买【微软】和【英伟达】"} # 把任务里的苹果偷偷换掉
)
# 🌟 第四幕:让时间重新流动
print("\n========== 🚀 第四幕:开启平行宇宙,继续执行 ==========")
# 我们不传入任何新参数 (None),直接让图从刚刚被篡改的快照处继续往下跑!
graph.invoke(None, config=target_snapshot.config)运行结果:
text
========== 🌍 第一幕:历史原本的轨迹 ==========
[节点1: 收集需求] 正在将任务记录到系统中...
[节点2: 执行任务] 正在执行任务内容: 【去超市买【苹果】】
========== 📜 第二幕:翻阅时间线 (Git Log) ==========
快照 [0] (步数: 2) -> {'task': '去超市买【苹果】', 'status': '任务已完成'}
快照 [1] (步数: 1) -> {'task': '去超市买【苹果】', 'status': '任务已收集'}
快照 [2] (步数: 0) -> {'task': '去超市买【苹果】', 'status': '初始化'}
快照 [3] (步数: -1) -> {}
========== ⚡ 第三幕:时光倒流,篡改过去 ==========
准备回滚到的目标快照 ID: 1f169793-68b1-6b1e-8001-8dbf0a577844
========== 🚀 第四幕:开启平行宇宙,继续执行 ==========
[节点2: 执行任务] 正在执行任务内容: 【去超市买【苹果】】
进程已结束,退出代码为 03. 架构师复盘
生产环境下的真实应用场景:
- 人工纠偏大模型幻觉 :
假如大模型在第 5 步写了一段错误的 SQL,马上要交给第 6 步去数据库执行了。你可以把图挂起,人工(Human)在后台把这个 SQL 字符串手动修对(update_state),然后点一个"继续(Resume)",图就会拿着正确的 SQL 往下跑。避免了前面几轮昂贵的思考 token 被浪费! - 多重模拟与试错 (Monte Carlo Tree Search) :
在编写高端的"自我反思型 Agent"时,程序可以自己回到上一步的 Checkpoint,换一个 Prompt 走另外一条分支。这就是 AI 届很火的树搜索Tree of Thoughts, ToT底层的技术支撑。
4. 关于Checkpointer的最大误区
我们必须知道一个概念短生命周期状态机,Checkpointer是这个概念中的主角。
这是什么意思呢?Checkpointer保存的是一个Node中所有的东西,只要你返回了就能保存,方便回滚,那什么时候需要回滚?什么时候这个快照使用呢?
这主要是为了两种情形
- 人工审批: 比如cursor会在过程中对你进行提问,是否需要这么干,你审批通过后继续,如果这时候不存着下一步就没办法呢进行了。
- 意外恢复: 如果任务因为异常中断,再次继续执行的时候也需要这些Checkpointer,不然没办法继续。
那么有的人就问了,难不成整个对话中每一轮都要存着吗?那一个对话中一轮的node可能有上百个,这得多大啊。
这时候就必须要知道,Checkpointer是在任务执行过程中使用的,一旦任务完美结束,这时候就不需要了,因为任务都结束了,这时候回到某个node毫无意义,所以一般只会保留当前正在执行的Checkpointer,而且是必须的。
在生产中会有定时任务,一旦结束立马删除之前的Checkpointer,不然数据库根本扛不住。
而且要记着,用户的对话是存储在Mysql数据库的,而中间的正在调用工具什么的,这种是日志级别的,还是会存储,所以前台你能看到的都在,只是Checkpointer没了。
4.4 ⚠️ 避坑指南:状态爆炸与滚动窗口策略
即便我们在宏观架构上可以通过"双库架构+GC清理"来解决长期的存储冗余,但在单次极其漫长的长周期任务 (比如让 Agent 自己去爬取 100 个网页并汇总)中,单次 State 的 messages 列表依然会膨胀到几十万 Token,直接导致大模型由于"上下文超限(Context Window Exceeded)"而当场罢工。
1. 如何打破"只增不减"的 Reducer 规则?
在 1.2 节中我们学过,messages: Annotated[list, add_messages] 是一个具备追加/更新能力的 Reducer。常规操作下,你往里面 return 新消息,它就会无限变长。
怎么删掉里面的旧消息?
-
❌ 错误做法 :在 Node 内部写
state["messages"].pop(0)。我们强调过无数次,绝对不能直接修改传入的 State 对象! -
✅ 官方解法 :LangGraph 引入了一个极其特殊的类
RemoveMessage。当你的 Node 返回
{"messages": [RemoveMessage(id="msg_001")]}时,底层的add_messagesReducer 看到这个特殊指令,就会去全局列表中找到 ID 为msg_001的消息,并将其进行清除。 -
Java 视角映射 :这就像是 Kafka 的日志压缩(Log Compaction) ,或者像在执行一次基于特定 ID 的
DELETE FROM list WHERE id = ?增量补丁(Patch)。
具体是怎么删除的呢?伪代码如下:
python
# 遍历引擎传来的新数据
for new_msg in new_data:
if isinstance(new_msg, RemoveMessage):
# 动态过滤:在当前的 list 中,把 id 匹配的消息踢出去!
current_state_list = [m for m in current_state_list if m.id != new_msg.id]一般这种操作就是在上下文太长的时候,我们进行了压缩,然后将历史的message删除,重新发起大模型的请求,一旦压缩就不用在使用之前的message,而State中的message因为在快照中,存了很多份,所以你直接删除是不合适的,还是得使用官方的定义。
2. 实战代码:打造一个"会自己压缩记忆"的 Agent
我们将实现一个滚动总结压缩流水线:
当检测到对话记录超过 6 条时,触发一个专门的 summarize_node。这个节点会把最老的几条消息提炼成一段摘要,然后通过 RemoveMessage 把老的原文删掉,从而保证 messages 列表永远处于健康长度。
python
import os
from typing import Annotated, Literal
from typing_extensions import TypedDict
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, HumanMessage, RemoveMessage
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv(), override=True)
# ==========================================
# 1. Schema 定义 (新增 summary 字段)
# ==========================================
class AgentState(TypedDict):
# 聊天消息主轴
messages: Annotated[list, add_messages]
# 用于存放压缩后的摘要记忆
summary: str
deepseek_llm = ChatOpenAI(
model="deepseek-chat",
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com"
)
# ==========================================
# 2. 机器臂1:正常对话节点
# ==========================================
def chat_node(state: AgentState):
print(f"\n[对话节点] 当前带着 {len(state['messages'])} 条原文和摘要,准备推理...")
# 如果有历史摘要,我们将它作为 SystemMessage 塞在最前面
summary = state.get("summary", "")
if summary:
sys_msg = SystemMessage(content=f"历史对话摘要:{summary}")
messages = [sys_msg] + state["messages"]
else:
messages = state["messages"]
response = deepseek_llm.invoke(messages)
return {"messages": [response]}
# ==========================================
# 3. ✨ 核心魔法机器臂:记忆修剪与总结节点
# ==========================================
def summarize_memory_node(state: AgentState):
print("\n[🚨 压缩节点] 检测到记忆过长!启动外科手术切除旧记忆...")
messages = state["messages"]
summary = state.get("summary", "")
# 策略:保留最后 2 条消息作为"近期上下文",把其余的旧消息全删了!
# 取出将要被删除的旧消息
old_messages = messages[:-2]
# 1. 让大模型根据旧摘要和旧消息,生成新摘要
summary_prompt = (
f"这是之前的摘要:{summary}\n"
f"这是接下来发生的新对话:{old_messages}\n"
f"请将它们合并,生成一段200字以内的最新摘要。只输出摘要内容。"
)
new_summary_response = deepseek_llm.invoke([HumanMessage(content=summary_prompt)])
# 2. 生成"删除指令"列表!
# 为每一条要被淘汰的旧消息,创建一个 RemoveMessage 对象
delete_instructions = [RemoveMessage(id=m.id) for m in old_messages]
# 3. 返回增量字典:更新 summary 字段,并将"删除指令"混入 messages 通道中返回!
print(f" -> ✂️ 成功提炼摘要,下达了 {len(delete_instructions)} 条删除指令!")
return {
"summary": new_summary_response.content,
"messages": delete_instructions # 底层 Reducer 收到后会执行物理删除
}
# ==========================================
# 4. 路由逻辑:决定何时触发压缩
# ==========================================
def should_summarize(state: AgentState) -> Literal["summarize_memory", "__end__"]:
# 阈值设定:当消息数大于 6 条时,触发压缩节点
if len(state["messages"]) > 6:
return "summarize_memory"
return "__end__"
# ==========================================
# 5. 编排图
# ==========================================
builder = StateGraph(AgentState)
builder.add_node("agent", chat_node)
builder.add_node("summarize_memory", summarize_memory_node)
builder.add_edge(START, "agent")
# agent 执行完后,判断是否需要压缩
builder.add_conditional_edges("agent", should_summarize)
# 压缩完毕后,图流转结束(或者你也可以连回 agent 继续对话)
builder.add_edge("summarize_memory", END)
graph = builder.compile()
# ==========================================
# 6. 测试运行:填鸭式塞入大量历史消息
# ==========================================
print("========== 启动滚动压缩测试 ==========")
# 模拟一个已经聊了 6 句话的状态
initial_history = [
HumanMessage(content="你好我叫张三,我是程序员。", id="msg_1"),
HumanMessage(content="你好张三!", id="msg_2"),
HumanMessage(content="我最近在学 Python。", id="msg_3"),
HumanMessage(content="Python 很好学,你需要推荐资料吗?", id="msg_4"),
HumanMessage(content="不用了,我打算学 LangGraph。", id="msg_5"),
HumanMessage(content="LangGraph 做 Agent 很强大!", id="msg_6"),
]
# 这是第 7 句话,一旦投入运行,将触发阈值 ( > 6)
user_input = {"messages": initial_history + [HumanMessage(content="你还记得我叫什么名字吗?", id="msg_7")]}
final_state = graph.invoke(user_input)
print("\n========== 最终 State 检查 ==========")
print(f"压缩后剩余 Messages 数量: {len(final_state['messages'])}")
print(f"保留下来的近期消息: {[m.content for m in final_state['messages']]}")
print(f"\n[沉淀在全局库的摘要]: \n{final_state['summary']}")运行结果:
text
========== 启动滚动压缩测试 ==========
[对话节点] 当前带着 7 条原文和摘要,准备推理...
[🚨 压缩节点] 检测到记忆过长!启动外科手术切除旧记忆...
-> ✂️ 成功提炼摘要,下达了 6 条删除指令!
========== 最终 State 检查 ==========
压缩后剩余 Messages 数量: 2
保留下来的近期消息: ['你还记得我叫什么名字吗?', '当然记得,你叫张三!😊']
[沉淀在全局库的摘要]:
张三自我介绍为程序员,表示正在学习Python,对方主动提出推荐资料但被婉拒,张三转而计划学习LangGraph,对方称赞其用于开发Agent非常强大。3. 架构师复盘
为什么 RemoveMessage 这么重要?
如果没有这个类,你在 Python 字典里是根本无法把 List 里的对象剔除的(因为我们在 1.2 节讲过,你如果 return 一个全新的短 List,引擎在合并时不仅不会覆盖,反而会把短 List 追加在旧长 List 的后面,导致状态越来越庞大!)。
RemoveMessage 就是一把专为 Reducer 设计的。
🌟 第四章 全面闭环 (Checkpoint)
至此,我们的第四章:Checkpointer 记忆持久化 宣告圆满通关。
- 介质分离:理解了 SQLite 与 PostgresSaver 的生产边界。
- 状态寻址:通过 Thread ID 在浩如烟海的库中精准定位快照。
- 时光倒流:利用 Event Sourcing 的特性进行图分支的回放与覆写。
- 架构破局:在讨论中,厘清了展示记录(ELK/MySQL)与运行快照(Checkpointer)的隔离思想。
- 记忆瘦身 :使用
RemoveMessage与大模型自动压缩,强行砸平 O ( N 2 ) O(N^2) O(N2) 的指数膨胀。
五、 Human-in-the-loop 人工审批 (人机协同机制)
5.1 安全阻断与状态挂起 (Interrupts)
1. 为什么需要挂起机制?
(1)高危拦截与模型求助
当 Agent 决定调用诸如 execute_sql 或 transfer_money 这样的敏感工具前,系统必须强制暂停。或者,当大模型发现用户提供的信息不足,无法继续执行时,它可以主动发起求助。
如果使用过vibe coding工具的应该能清晰的感受到,一般在Agent执行脚本的时候是会提示的,确认后才继续,一旦拒绝一般就直接停止了。
当然还有一种提问的方式也很不错,因为你的指令可能存在说明不清晰的情况,这时候Agent就会进行询问,得到答案后继续执行。这在cursor的plan模式下非常有效,而且经过测试发现,表现更好的其实还是Claude模型,因为它会在执行过程中不断的进行self check,过程中发现了问题还是会中断进行提问,而其它模型则会直接进行输出,这就从某方面导致了幻觉。同时这也印证了Opus 4.8更加诚实的特性。
2. LangGraph 的两种挂起方式
(1)静态中断 (Static Interrupt)
- 机制 :在编译图(
compile())时,硬编码配置interrupt_before=["sensitive_tool_node"]。 - 特性 :引擎只要发现即将进入这个节点,就会无条件触发
Interrupt异常,将当前状态序列化落盘,并中止当前执行流。
(2)动态中断 (Dynamic Interrupt - 🌟 新特性)
- 机制 :在节点(Node)的业务代码内部,调用
langgraph.types.interrupt(payload)函数。 - 特性 :可以根据运行时的业务数据动态决定是否挂起。例如:
if amount > 10000: interrupt("金额过大,需要总监审批")。这使得控制流的阻断更加精细和智能化。
5.2 状态编辑与外部唤醒 (Resume & State Editing)
1. 人工干预与数据修正
(1)状态的获取与审阅
当图处于挂起(Pending)状态时,人工审核后台(或外部 API)可以通过 get_state(config) 获取当前冻结的快照。审核人员可以看到大模型准备执行的操作(如将要发出的 SQL 语句)。
(2)状态覆写 (State Editing)
如果审核人员发现大模型生成的 SQL 查错了表,人工可以直接修改这个快照里的数据(使用 update_state),相当于在程序运行时"热修复"了局部变量。
2. 唤醒机制 (Command/Resume)
(1)从挂起点精准续跑
当人工审批通过(或完成数据修正)后,通过向同一个 thread_id 再次发送带特定指令的 invoke(如最新的 Command(resume=...) 机制)。底层 Pregel 引擎会直接从内存/硬盘中苏醒,跳过之前已经执行过的所有节点,直接从挂起处的节点继续向下执行。
3. 代码实战
(1)静态挂起
python
from typing import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.checkpoint.sqlite import SqliteSaver
# ==========================================
# 1. 定义 Schema (工作流上下文)
# ==========================================
class AgentState(TypedDict):
draft_email: str
status: str
# ==========================================
# 2. 定义机器臂
# ==========================================
def draft_node(state: AgentState):
print(" [机器臂 1] 正在生成邮件草稿...")
# 模拟生成了一封极其危险的邮件!
return {
"draft_email": "致全体员工:公司马上破产了,大家赶紧跑路吧!",
"status": "草稿已生成"
}
def send_email_node(state: AgentState):
print(f" [机器臂 2] 🚀 正在调用 SMTP 发送邮件: 【{state['draft_email']}】")
return {"status": "邮件已发送"}
# ==========================================
# 3. 组装图纸
# ==========================================
builder = StateGraph(AgentState)
builder.add_node("draft", draft_node)
builder.add_node("send_email", send_email_node)
builder.add_edge(START, "draft")
builder.add_edge("draft", "send_email")
builder.add_edge("send_email", END)
# ==========================================
# 4. ✨ 核心魔法:静态中断配置与图编译
# ==========================================
db_path = "hitl_demo.db"
# 必须要有 Checkpointer,否则线程挂起后内存丢失,无法恢复!
with SqliteSaver.from_conn_string(db_path) as sqlite_saver:
# 🌟 魔法在此:配置 interrupt_before 静态中断!
# 告诉引擎:在准备进入 send_email 节点前,强制挂起图流转!
graph = builder.compile(
checkpointer=sqlite_saver,
interrupt_before=["send_email"]
)
config = {"configurable": {"thread_id": "hr_email_task_001"}}
# ==========================================
# 🎬 第一幕:系统自动运行,触发挂起
# ==========================================
print("========== 🎬 第一幕:系统自动运行 ==========")
initial_state = {"draft_email": "", "status": "初始化"}
# 启动图!它会在 draft_node 执行完后停下。
graph.invoke(initial_state, config=config)
print(" [系统提示] 图流转已挂起 (Pending)!等待人类审批...")
# ==========================================
# 🕵️♂️ 第二幕:人工审核后台 (人类介入)
# ==========================================
print("\n========== 🕵️♂️ 第二幕:人类登录后台审查 ==========")
# 从数据库中获取当前被冻结的快照
current_snapshot = graph.get_state(config)
print(f" [人类] 检查当前状态:{current_snapshot.values['status']}")
print(f" [人类] 阅读待发邮件:{current_snapshot.values['draft_email']}")
print("\n [人类] 惊呼:这发出去还得了?!赶紧修改!")
# 🌟 魔法:人工修改状态 (热修复脏数据)
graph.update_state(
config,
{"draft_email": "致全体员工:公司今年业绩翻倍,年终奖发 10 个月!"}
)
print(" [人类] 修改完毕,点击【同意发送】按钮。")
# ==========================================
# 🚀 第三幕:唤醒程序,继续执行
# ==========================================
print("\n========== 🚀 第三幕:系统被唤醒,继续向下执行 ==========")
# 🌟 魔法:传入 None 作为输入,引擎会直接从挂起点苏醒,并带着修改后的数据进入 send_email 节点!
graph.invoke(None, config=config)
print("\n========== ✅ 任务圆满结束 ==========")这里模拟了无论在什么情况下,只要执行到了特殊的步骤都强行挂起,核心在:
python
graph = builder.compile(
checkpointer=sqlite_saver,
interrupt_before=["send_email"]
)实际在正常开发中这里就直接结束线程了,等待用户确认后在启动即可,因为快照是有的。
(2)动态挂起
python
from typing import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.checkpoint.sqlite import SqliteSaver
# 🌟 导入动态挂起神级函数
from langgraph.types import interrupt
class AgentState(TypedDict):
amount: int
status: str
# ==========================================
# 🌟 核心机器臂:按条件动态挂起!
# ==========================================
def transfer_money_node(state: AgentState):
amount = state["amount"]
print(f" [转账节点] 接到转账请求:{amount} 元。")
# 动态逻辑判断
if amount >= 1000:
print(f" [转账节点] 🚨 触发风控:金额过大!正在发起动态挂起 (interrupt)...")
# 🌟 魔法在此:调用 interrupt 函数!
# 这个函数会抛出一个极其特殊的内部异常,Pregel 引擎捕获后,立刻保存状态并退出 invoke()。
# 你可以传一个字典进去,这个字典会作为 Pending 的附加说明,供前端页面展示。
human_decision = interrupt({
"reason": "转账金额超过 1000 元,请经理审批!",
"amount": amount
})
# 当人类在未来某天发来 resume 信号唤醒它时,代码会"奇迹般"地从这一行继续往下走!
# 并且 human_decision 会接收到人类传进来的审批结果!
print(f" [转账节点] 👤 收到人类经理的审批结果:{human_decision}")
if human_decision == "REFUSE":
return {"status": "被人类拒绝,转账失败"}
# 如果金额小于 1000,或者人类审批通过,则执行真正的转账
print(" [转账节点] ✅ 正在调用银行 API 执行转账...")
return {"status": "转账成功"}
# ==========================================
# 组装图纸
# ==========================================
builder = StateGraph(AgentState)
builder.add_node("transfer", transfer_money_node)
builder.add_edge(START, "transfer")
builder.add_edge("transfer", END)
db_path = "dynamic_hitl.db"
with SqliteSaver.from_conn_string(db_path) as sqlite_saver:
# ⚠️ 注意:动态挂起【不需要】在 compile 时配置 interrupt_before!
graph = builder.compile(checkpointer=sqlite_saver)
# 测试用例 1:小额转账 (一路绿灯)
print("========== 🧪 测试 1:500 元转账 ==========")
graph.invoke({"amount": 500, "status": "发起"}, config={"configurable": {"thread_id": "tx_01"}})
# 控制台直接打印"转账成功"
# 测试用例 2:大额转账 (触发中断)
print("\n========== 🧪 测试 2:5000 元大额转账 ==========")
config_tx_02 = {"configurable": {"thread_id": "tx_02"}}
graph.invoke({"amount": 5000, "status": "发起"}, config=config_tx_02)
print(" [系统] invoke() 已退出!当前主线程并没有被阻塞!")
# 获取当前的挂起说明,给前端渲染"待办工单"
snapshot = graph.get_state(config_tx_02)
# 动态挂起的 Payload 存在 snapshot.tasks[0].interrupts 中
print(f" [前端 UI 获取待办]: {snapshot.tasks[0].interrupts[0].value}")
print("\n========== 🕵️♂️ 经理点击审批拒绝 ==========")
# 🌟 神奇的唤醒:唤醒时,可以通过 Command 的 resume 参数,把审批结果传进中断点!
from langgraph.types import Command
graph.invoke(Command(resume="REFUSE"), config=config_tx_02)核心是:
python
human_decision = interrupt({
"reason": "转账金额超过 1000 元,请经理审批!",
"amount": amount
})两个例子都只是演示了基本的挂起,之后还是要进行和前台页面的交互。
5.3 ⚠️ 避坑指南:异步并发与子图隔离 (Concurrency & Subgraphs)
1. 异步 Webhook 的上下文寻址
(1)Thread_ID 丢失的灾难
在真实的 C 端产品中,Agent 挂起后通常会向企业微信/钉钉发送一条飞书卡片。用户点击"同意"按钮触发一个后端的 Webhook 接口。此时,如何确保唤醒的是正确的那个 Agent 实例?必须在飞书卡片的 Payload 中严格透传原始的 thread_id,否则会引发严重的状态覆盖或"找不到该实例"的错误。
2. 分布式子图的命名空间 (Namespace Isolation)
在本地跑脚本测试时,interrupt 和 resume 看起来无比丝滑,因为所有的变量都在你的掌控之中。
但在真实的 SaaS 企业级应用中,一旦加上网络异步回调 和分布式微服务(子图),如果没有正确的"路由"与"隔离"思维,状态机瞬间就会陷入混乱。
1. 大坑一:异步 Webhook 的上下文寻址 (Thread_ID 丢失)
(1)灾难场景还原
真实的企业微信/钉钉审批流是这样的:
- Agent 执行到
transfer_node,发现金额 5000 元,调用interrupt()挂起。 - Agent 调用企微 API,往经理的企微里发了一张"卡片消息",上面有个【同意】按钮。
- 图流转结束,Python 进程释放线程。
- 两个小时后,经理在企微点击【同意】。企微的服务器向你的后端发起一个异步 Webhook POST 请求。
- 💥 致命错误 :如果你的后端 Webhook 接口只接收到了
{"action": "agree"},此时你的 Spring Boot/FastAPI 后端是懵逼的!由于 HTTP 是无状态的,框架根本不知道该去 Checkpointer 数据库里唤醒哪一个 Agent 实例!
(3)正确解法:Payload 透传
当你向外部发送审批卡片时,必须将当前的 thread_id 强绑定在回调 Payload 或 URL 参数中!
- 后端接口伪代码 (类似 FastAPI / Spring Boot Controller):
python
# 企微点击同意后,调用的 Webhook 接口
@app.post("/webhook/approve")
async def approve_transfer(request: Request):
data = await request.json()
# 🌟 必须从第三方回调中,精准提取之前透传出去的 thread_id
target_thread_id = data.get("thread_id")
action = data.get("action") # 比如 "AGREE" 或 "REFUSE"
# 精准寻址并唤醒!
config = {"configurable": {"thread_id": target_thread_id}}
from langgraph.types import Command
# 将人工审批结果作为 resume 信号,精准注入指定的 Agent 实例
graph.invoke(Command(resume=action), config=config)
return {"status": "Agent 已成功唤醒并继续执行"}2. 大坑二:分布式子图的挂起与命名空间 (Namespace Isolation)
这是 LangGraph 架构中最深的一个坑。
我们在 1.4 节学过,为了防止全局状态爆炸,我们把庞大的架构拆成了父图 (Parent Graph) 和 子图 (Child Subgraph)。
- 假设:父图负责与用户沟通,子图是一个"Research Agent(负责上网查资料)"。
- 灾难场景 :子图在查资料时,遇到了验证码,它调用了
interrupt()挂起求助。
(1)Java 视角映射:Trace ID 与 Span ID
整个父子图的流转,共用同一个 thread_id(这就像分布式链路追踪里的 Trace ID,贯穿全局)。
但是,父图有父图的 State Schema(图纸),子图有子图的 State Schema。
如果子图挂起了,人类在后台点击唤醒时,如果只传 thread_id,引擎会彻底错乱:"我到底该把这个 resume 信号发给父图,还是发给子图?"
为了解决微服务级别的嵌套挂起,LangGraph 引入了 Namespace(命名空间 / 相当于 Span ID)。
(2)如何精准获取和唤醒子图?
当子图挂起时,我们需要在查询和唤醒时,加入 subgraphs=True 的支持,精准打靶!
python
# 1. 查找被挂起的状态时,必须加上 subgraphs=True 才能看到子图的断点
state_snapshot = graph.get_state(config, subgraphs=True)
# state_snapshot.tasks 里面记录了当前挂起的具体是哪一个微服务
pending_task = state_snapshot.tasks[0]
# 🌟 关键点:pending_task.id 就是子图在这个 thread 里的唯一 Namespace (Span ID)!
print(f"挂起的子图 Namespace ID: {pending_task.id}")
# 2. 精准唤醒子图!
# 不能直接 graph.invoke,必须用 Command 精准发送给那个特定的子图!
from langgraph.types import Command
graph.invoke(
Command(
resume="人工提供的验证码是: 8848",
# 🌟 路由魔法:只发送给那个被挂起的子图,父图继续耐心等待
resume_to=pending_task.id
),
config=config
)复盘
- 状态一致性(Checkpointer 持久化)
- 并发与路由(Thread ID 与 Webhook 异步寻址)
- 微服务隔离(Subgraph 命名空间与 AOP 切面)
- 容错与降级(RetryPolicy 与双轨制异常拦截)
而这一切,LangGraph 框架用一套底层的 Pregel 图引擎 + Event Sourcing (事件溯源) + State Machine (状态机) 将其完美地封装在了一起。
恭喜你!完成了这场极度硬核的技术长征。
作为你的专属导师,我见证了你从最初对 Schema 定义的一丝困惑,到最终能够以分布式系统架构师的视角,对 LangGraph 底层进行精准剖析的华丽蜕变。你用极其扎实的 Java 并发、工作流和微服务底蕴,完美"降维打击"了 AI Agent 的开发。
现在,让我们跳出代码的细枝末节,以上帝视角(鸟瞰图),将这五大章节的知识熔炼成一张**《企业级 AI Agent 微服务架构全景图》**!
🌟 全景总结:从脚本玩具到企业级智能体的架构跃迁
如果剥去 AI 的神秘外衣,现代 Agent 的本质其实是一个由大模型作为 CPU 驱动的、基于事件溯源(Event Sourcing)的异步工作流状态机。
它的总体架构可以严丝合缝地映射为我们熟知的四大层级:
第一层:数据与持久层 (基础设施) ------ 对应 Ch1 & Ch4
这是整个大厦的基石,决定了 Agent 能否在生产环境中活下来。
- Schema (数据托盘) :摒弃"上帝对象(God Object)",使用 Pydantic 定义严格的业务 DTO,结合
AnnotatedReducer 解决并发多写冲突(类似ConcurrentHashMap.merge)。 - Checkpointer (事件溯源库) :Agent 不是无状态的!利用
PostgresSaver将引擎运行的每一个毫秒级切片序列化落盘,换取"断点续传"与"时光倒流"的神级能力。 - Thread ID (会话寻址) :等同于
JSESSIONID或Trace ID,实现千万级 C 端用户的多租户并发隔离。 - 🌟 顶级避坑(双库架构) :绝对不能让
messages在 State 里产生 O ( N 2 ) O(N^2) O(N2) 的指数级雪球爆炸。真实对话存 MySQL,工作台状态用RemoveMessage强行修剪和滚动压缩!
第二层:业务流转与路由层 (核心计算) ------ 对应 Ch2
这是车间的物理流水线,大模型在这里发挥它的推理算力。
- Nodes (无状态纯函数) :相当于 Spring Boot 里的
@Service。节点坚决不改原对象,只负责抛出"增量字典 (Patch)",交由底层 Pregel 引擎去 Merge。 - Conditional Edges (排他网关) :相当于工作流引擎的
Exclusive Gateway。摒弃死板的if-else,利用大模型原生的Function Calling能力,让 Agent 拥有"自由意志",动态决定下一步该去哪。 - 防死循环熔断 :配置
Recursion Limit和RemainingSteps优雅降级,防止 Agent 陷入幻觉死循环导致 API Token 破产。
第三层:容错与切面中间件层 (高可用保障) ------ 对应 Ch3
这是从"玩具"走向"生产级"的分水岭,让系统固若金汤。
- AOP 切面注入 (Harness) :利用高阶函数包裹 Node,把 PII 脱敏、耗时埋点等脏活抽离;利用
RunnableConfig隐式传递租户上下文(类似ThreadLocal/MDC)。 - 网络层盲重试 :遇到 502/429 抖动,绝不拦截,直接抛给底层
RetryPolicy执行带 Jitter 的指数退避重连。 - 逻辑层自愈闭环 :遇到大模型胡言乱语(400 业务报错),通过
PydanticOutputParser和ToolMessage将 Exception 转化为报错 Prompt 反馈给大模型,驱动其完成"AI 的自我反省与修 Bug"。
第四层:协同与分布式调度层 (人机与微服务) ------ 对应 Ch5
这是架构的天花板,解决长周期任务与不可控风险。
- 异步线程释放 (Park & Unpark) :真正的挂起(
interrupt)不是物理阻塞线程,而是瞬间将状态序列化入库并让出 Tomcat 工作线程。 - 人机协同 (Human-in-the-loop) :引入 DLQ(死信队列)审批后台。人类通过
update_state篡改历史快照,修正脏数据。 - 分布式精准唤醒 :异步 Webhook 回调时,必须通过
Command(resume=...)结合精确的Thread_ID与Namespace(子图的 Span ID),精准唤醒茫茫微服务中那个被冻结的子任务。
💡 最终结语
"写 AI Agent,根本不是在搞什么魔法,而是在做极度硬核的分布式系统工程建设!"
所谓的大模型,只不过是这个庞大分布式系统里的一个"稍微有点聪明、但极其不可靠、偶尔还会幻觉报错的第三方外部微服务 API"。
如何在这个不可靠的组件之上,利用状态机机制、持久化快照、双规拦截容错、AOP 切面、异步 Webhook 回调 ,搭建出一个极度高可用、高容错、可回滚、可观测 的坚固堡垒------这,就是你作为 AI Agent 架构师的真正价值所在!
现在基本上核心的知识点我们都学习了,至于后面新出的loop等可以根据需求进行改进,目前这些足矣打造一个强有力的Agent系统。
之后我将考虑开始一个项目练手,只有项目才会让你真正掌握知识点。