模块1:内核基础(核心:内核是管家,应用是住户)
一句话总述:
内核 = Linux的超级管家 ,掌管CPU、内存、磁盘、网络所有硬件;
你的Web应用 = 普通住户,没有硬件权限,所有操作必须找管家(内核)帮忙。
1. 用户态 / 内核态
1. 基础角色定位
-
用户态(User Mode)
普通应用程序的运行环境,权限受限 ,不能直接操作硬件、内核内存、进程调度等核心资源。
你写的 C/Rust/Go 业务程序、普通可执行文件,全都跑在用户态。
-
内核态(Kernel Mode)
操作系统内核的专属特权态,拥有最高硬件/系统权限,负责管理内存、进程、磁盘、网卡、中断等所有底层资源。
用户态程序绝对不能直接执行内核代码。
-
libc / C标准库(clib)
运行在用户态 的通用函数库,是应用程序 ↔ 操作系统内核 之间的中间封装层,也是绝大多数程序的默认桥梁。
2. 核心调用链路(最关键逻辑)
标准执行流程:
应用程序(用户态) → libc库函数(用户态) → 触发系统调用 → 切换到内核态(内核执行) → 结果返回用户态
简单拆解每一层作用:
- 应用层 :开发者只调用
printf/fread/malloc/socket等常用接口,不用关心操作系统差异; - libc层 (中间人)
- 对原始系统调用做封装,简化使用;
- 增加缓存、内存池、缓冲区,减少频繁态切换(优化性能);
- 做跨系统兼容(Linux/BSD 系统调用号、接口不同,libc 统一抹平差异);
- 系统调用 :用户态进入内核态的唯一合法入口 ,通过
syscall/软中断等指令完成用户态 ↔ 内核态切换; - 内核层:真正完成硬件/资源操作,执行完毕后切回用户态。
3. 经典案例(之前举例过的场景)
案例1:文件读写 fread / read
- 你代码写
fread()→ 这是 libc 函数(用户态) - libc 内部维护缓冲区,数据不足时,主动调用 Linux 原生
read系统调用 - CPU 切换到内核态,内核文件系统读取磁盘数据
- 执行完毕,切回用户态,数据逐级返回应用
案例2:内存分配 malloc
malloc属于 libc,大部分逻辑在用户态- 小块内存:libc 自己维护内存池,不进内核(避免开销)
- 内存池耗尽:才调用
brk/mmap系统调用,进入内核向操作系统申请堆内存
4. 重点细节
-
态切换有性能开销
用户态 和 内核态 切换时,需要保存/恢复寄存器、切换页表, ==>成本不低<==。 这也是 libc 要做缓冲区、内存池的核心原因:少进内核 = 少切换 = 更快。 -
libc 不是内核
libc 全程运行在用户空间,它只是"翻译+代理",本身没有硬件权限。
-
高级语言与 libc 的关系
Rust、Go 等语言的标准库,在 Linux 下底层依然依赖 libc ;同时也支持绕过 libc,直接裸调用系统调用(嵌入式、高性能底层开发常用)。
-
边界区分
- 直接写汇编调用系统调用:跳过 libc,应用直连内核;
- 常规 C 程序:一定走 libc 过渡。
✅ Web开发关联:
Tokio/Axum的异步核心,就是减少用户态↔内核态的切换次数 , 因为 成本不低,切换越少,并发越高!
同理 Golang 重构运行时 的意义也是 减少 切换内核态的次数!
2. 虚拟内存 / 物理内存 / 页表
✅ 大白话比喻:
- 物理内存:真实的内存条(比如16G,唯一的实物);
- 虚拟内存 :内核给每个进程画的「专属假内存」,每个进程都觉得自己独占8G内存;
- 页表 :内核的翻译小本本,把进程的「假地址」翻译成「真实物理地址」。
✅ 核心本质:
内核用虚拟内存隔离进程,A进程永远碰不到B进程的内存,安全又稳定。
✅ Web开发关联:
10个Web服务进程同时运行,互相不干扰内存,就是虚拟内存+页表的功劳。
✅ Rust代码演示(两个进程,变量地址相同,物理内存不同):
rust
// 演示:每个进程有独立虚拟地址,打印同一个变量地址值一样
fn main() {
let a = 1024;
// 打印变量的虚拟内存地址
println!("变量a的虚拟地址: {:p}", &a);
println!("变量值: {}", a);
}教学重点 :运行两次这个程序,输出的虚拟地址完全一样!但物理内存地址不同,内核通过页表翻译,这就是虚拟内存的魔法。
3. mmap(内存映射)
- 文件硬盘:硬盘
- 内核缓冲区: 内存条上,落在 内核 专属 虚拟地址 空间(所有进程共用一套内核地址),操作系统全局统一管理。
- 用户态缓冲区: 内存条上,落在 进程用户态 虚拟地址 空间,是你 Rust/Go 代码里自己申请的数组、Vec 内存;
✅ 传统 read 两次拷贝:
磁盘 →【DMA 硬件搬运】→ 内核缓冲区 →【CPU 内存拷贝】→ 用户缓冲区
聪明的 计算机学者 发现,
内核缓冲区→【CPU 内存拷贝】→用户缓冲区这一步有点 脱裤子放屁的意思, 因为 都在 同一条内存条里, 没有必要 再 复制一次, 借助前面讲的 页表 技术, 可以将核缓冲区的地址 映射 到用户缓冲区, 让进程 直接 使用就可以了, 所以 就有了 mmap 技术, 可以减少一次 IO。
✅ mmap 一次拷贝:
【将 内核缓冲区 和 用户态缓冲区 做好 内存映射】→ 磁盘 → 【DMA 硬件搬运】→ 内核缓冲区 →【用户 进程 通过 内存映射 直接使用 位于 内核缓存区 的 数据】
✅ Web开发关联:
Nginx、Axum静态文件服务,全靠mmap!比普通read/write快几倍。
✅ Rust代码演示(用memmap2映射文件):
toml
# Cargo.toml 依赖
[dependencies]
memmap2 = "0.9"
rust
use memmap2::Mmap;
use std::fs::OpenOptions;
fn main() -> std::io::Result<()> {
// 打开文件
let file = OpenOptions::new().read(true).open("test.txt")?;
// mmap:将文件映射到内存
let mmap = unsafe { Mmap::map(&file)? };
// 直接读内存 = 读文件内容
println!("文件内容(mmap读取): {}", String::from_utf8_lossy(&mmap[..]));
Ok(())
}4. 进程调度 / task_struct / PID / FD
✅ 大白话比喻:
- 进程调度 :班主任(内核)管理全班学生(进程),
轮流用黑板(CPU); - task_struct :内核里每个进程的档案本,记录PID、内存、打开的文件、状态;
- PID :进程的身份证号(唯一);
- FD(文件描述符) :进程打开的「文件/网络连接」的门牌号(Linux一切皆文件:网络socket=FD,文件=FD)。
✅ Web开发关联:
你的Web服务启动后有PID,每一个HTTP客户端连接,都是一个FD!Tokio就是管理这些FD实现高并发。
✅ Rust代码演示(获取PID、打印FD):
rust
use std::os::unix::io::AsRawFd;
fn main() {
// 1. 获取当前进程PID(身份证)
let pid = std::process::id();
println!("当前进程PID: {}", pid);
// 2. 获取标准输出的FD(门牌号)
let stdout = std::io::stdout();
println!("标准输出的文件描述符FD: {}", stdout.as_raw_fd());
}5. VFS虚拟文件系统 / inode
✅ 大白话比喻:
- VFS :内核的万能文件接口 !不管你用ext4硬盘、U盘、网络存储,应用看到的都是一样的
open/read/write; - inode :文件的身份证 !记录文件大小、权限、物理位置。文件名只是别名,inode才是唯一标识。
✅ Web开发关联:
你用std::fs读文件,根本不用管文件存在哪个磁盘,VFS帮你适配,内核通过inode找到文件。
✅ Rust代码演示(获取文件inode):
rust
use std::fs::metadata;
fn main() -> std::io::Result<()> {
let meta = metadata("test.txt")?;
// 获取文件inode号
println!("文件inode: {}", meta.ino());
Ok(())
}6. 硬中断 & 软中断
场景设定
CPU = 驿站店长,正在专心整理货架(运行你的业务程序)
各种硬件设备 = 快递员、打印机、取件客户
1. 硬中断(硬件主动打断店长)
触发逻辑:外部硬件主动发紧急信号,强制打断当前工作
快递员骑着车到驿站门口,疯狂按门铃 (硬件电信号),不管店长现在在忙什么,必须立刻停手开门。
店长开门只做1秒极速操作 :
把快递全部扔进驿站临时筐里,在本子写一句「有快递待分拣」,马上关门,回去继续整理货架。
硬中断核心特点对应:
- 触发源:外部硬件(快递员=网卡/键盘/硬盘)主动敲门,不受店长控制
- 处理极短:只做标记、暂存数据,绝不做耗时活
- 随机抢占:店长干活中途随时会被打断
- 不能久留:门铃一直响,拖久了外面一堆快递员堵门(系统丢包、外设卡顿)
2. 软中断(延后处理耗时工作,内核内部执行)
触发逻辑:没有外部门铃,是店长自己看到本子标记,抽空处理
店长回到货架整理一会,手上活暂时告一段落,看到本子写着「快递待分拣」,才开始处理复杂工作:
拆快递、分楼栋、录入取件码、发短信通知客户,这一整套耗时流程,就是软中断。
软中断核心特点对应:
- 没有外部硬件信号,是硬中断留下的待办任务
- 处理耗时业务:分拣、录入、发短信(对应解析数据包、IO回调、定时唤醒)
- 不会抢占正在执行的硬中断,等硬件紧急信号处理完才执行
完整连贯流程(网卡收包真实映射)
- 网线数据包到达网卡 → 快递员上门按门铃 → 硬中断触发
- 店长(CPU)停下手上工作,开门把包裹丢进筐,记个待办标记,立刻关门回去干活(硬中断极速收尾)
- 等关门、无新快递敲门时,店长按本子标记分拣快递、通知客户 → 软中断执行完整业务逻辑
补充区分易错点
- 为什么分拣不能放开门的时候做?
开门时门外还有一堆快递员等着(其他硬件中断),开门太久堵门,快递全堆积丢失;对应硬中断耗时过长会屏蔽其他外设中断,导致丢包、鼠标键盘卡顿。 - 你写的定时任务怎么套这个例子?
墙上闹钟(硬件时钟芯片)每分钟叮一下门铃(时钟硬中断),店长记一句「5分钟后通知客户取件」;到点后店长空闲时执行通知操作,通知动作就是定时器软中断。
7. CPU的 使用率 & 负载
一句话总结关系:
- CPU使用率:CPU忙不忙;
- CPU负载:有多少活等着CPU干;
两者独立,不能互相推导,排查性能问题必须结合两个指标一起看。
一、两者分别是什么
1. CPU使用率(us、sy、id、iowait 这类指标)
定义 :统计一段时间内CPU真正在干活的时间占总时长的百分比 ,衡量CPU的忙碌程度。
计算逻辑 :使用率 = CPU执行任务的时间 / 统计总时间 × 100%
| 指标 | CPU状态 | 核心场景 | 业务意义 |
|---|---|---|---|
| %us | 运行用户程序 | 代码循环、加密、运算 | 业务计算密集,程序本身耗CPU |
| %sy | 运行内核逻辑 | 系统调用、进程切换、中断 | 系统底层开销大,锁竞争/频繁IO调用 |
| %iowait | 空闲但等IO | 大量文件读写、数据库磁盘查询 | IO瓶颈,磁盘/存储拖慢系统 |
| %id | 完全空闲 | 系统负载低,无任务 | CPU算力富余,机器资源闲置 |
%us 用户态
应用程序自己的业务代码占用CPU,比如循环计算、业务逻辑、数值运算,运行在用户态进程上下文。
%sy 内核态
程序发起系统调用、内核调度、软硬中断、内存管理等内核逻辑消耗CPU,运行在内核上下文(进程上下文/中断上下文)。
%id 空闲
CPU完全无事可做,没有就绪任务,处于空转休眠状态,这段时间不计入任何业务消耗。
%iowait
-
iowait 属于空闲类时间,但和纯id空闲有本质区别:
id:系统完全没有待运行的进程;iowait:有进程,但全部卡在IO阻塞,无计算任务可跑。
-
iowait高的典型场景:磁盘慢、大量随机读写、数据库慢查询、大量文件读写。
-
计算关系:
us + sy + iowait + id + irq + softirq + steal = 100%
额外补充top里配套的2个中断指标(和sy关联)
- %irq 硬中断
网卡、键盘、磁盘硬件触发硬中断时CPU消耗的时间,属于内核态硬件紧急处理。 - %soft 软中断
网络收包、定时器等延后处理软中断占用的CPU时间,同样属于内核范畴,统计在sy之外单独展示。
2. CPU负载(load average,uptime/top最前面3个数字)
定义 :统计CPU等待队列里的就绪进程总数,代表系统待处理任务的排队长度,反映任务拥堵程度。
- 三个数值分别代表:1分钟、5分钟、15分钟平均排队任务数
- 核心规则(多核CPU):
4核机器,负载=4 → CPU刚好饱和,无排队;
负载>4 → 进程排队等待CPU,出现拥堵;
负载<4 → CPU有空闲算力。 - 通俗例子:4个工位(4核CPU),门口排队6个人 → 负载≈6,2个人要等工位空出来。
模块2:进程
1. fork / exec 黄金搭档
1-1、核心前置结论:
- Linux 没有「直接创建一个新进程并运行程序」的系统调用!
- 想运行一个新程序(比如
ls、nginx、你的Go/Rust二进制),必须先fork克隆,再exec替换,这是Linux进程创建的唯一标准流程。 - 两个函数分工极端清晰:
fork:造进程壳子(创建PID、复制进程环境,不换程序)exec:换进程灵魂(替换程序代码,不造新进程)
1-2、 fork()
fork 是Linux内核提供的唯一创建新进程 的系统调用。
它会克隆当前运行的进程(父进程) ,生成一个几乎完全一样的子进程。
1-3、exec()
exec 不是一个函数,是一组系统调用(execl, execv, execve 等)。
它不创建新进程!不改变PID!
它的作用:把当前进程的所有程序内容(代码、数据、堆栈、虚拟内存)全部清空,替换成一个新的程序。
- 调用
exec→ 切换内核态; - 内核废弃当前进程的旧页表;
- 读取新程序的 ELF文件(二进制可执行文件);
- 把新程序的代码、数据加载到进程的虚拟内存空间;
- 创建新的页表,初始化堆栈;
- 切回用户态,直接从新程序的入口(main函数)开始执行。
1-4、黄金组合:fork() + exec() 为什么必须一起用?
这是Linux的设计精髓,我用你在终端输入 ls 命令的真实流程讲透:
你打开终端 → 运行的是 bash 进程(PID=1234)
你输入 ls 回车,底层执行:
- bash 进程调用
fork()
克隆出一个子进程(PID=5678),和bash完全一样; - 子进程调用
exec()
清空自己,替换为/bin/ls程序; - 子进程运行 ls 命令,列出文件;
- ls 执行完毕,子进程退出;
- 父进程 bash 继续等待,显示命令行提示符。
直接用 exec 会怎么样 ?
如果bash直接调用 exec ls:
→ bash进程会被替换成ls,ls执行完,终端直接关闭!
→ 所以必须fork克隆一个子进程,让子进程去exec,父进程毫发无损。
✅ Nginx 示例:
Nginx主进程用fork生成子进程,主进程管理,子进程处理HTTP请求。
✅ Rust演示(用nix库调用fork):
toml
# Cargo.toml
[dependencies]
nix = { version = "0.28", features = ["process", "unistd"] }
rust
use nix::unistd::{fork, ForkResult};
fn main() {
match unsafe { fork() } {
Ok(ForkResult::Parent { child }) => println!("父进程,子进程PID: {}", child),
Ok(ForkResult::Child) => println!("我是子进程!"),
Err(_) => println!("fork失败"),
}
}2. 进程间通信
一句话总述:进程是独立房间,不能直接串门,内核提供串门工具。
✅ 极简总结:
- 管道(匿名管道 Pipe):父子进程单向传话,仅亲缘进程可用
- 命名管道(FIFO):无血缘进程也能单向通信,文件作媒介
- 消息队列:内核维护消息盒子,多进程收发结构化消息
- 共享内存:最快IPC,多进程映射同一块物理内存,需手动加锁
- 信号量:专门做同步互斥,配合共享内存使用
- Socket:跨本机/跨机器通用,本地Unix Socket、网络TCP/UDP Socket
Unix域套接字:本机最快进程通信(比TCP快,不用网络协议栈),Docker/K8s用它;
2-1. 匿名管道 Pipe(父子进程单向通信)
通俗理解
父亲开了一根单向水管 ,一头写、一头读;可以 父->子 和 子->父 的方向,让有亲缘进程用,数据读完就销毁,无法反复读。
特点:单向、仅亲缘、内存临时、字节流无边界。
Rust 代码示例(std::process + pipe)
rust
use std::io::{Read, Write};
use std::process::{Command, Stdio};
fn main() {
// 创建管道:子进程标准输出绑定管道写端,父进程持有读端
let mut child = Command::new("echo")
.arg("来自子进程管道消息:hello pipe")
.stdout(Stdio::piped())
.spawn()
.expect("创建子进程失败");
// 获取管道读句柄
let mut pipe_reader = child.stdout.take().unwrap();
let mut buf = String::new();
pipe_reader.read_to_string(&mut buf).unwrap();
println!("父进程从管道读到:{}", buf);
// 等待子进程退出
child.wait().unwrap();
}运行输出:
父进程从管道读到:来自子进程管道消息:hello pipe2-2. 命名管道 FIFO(任意进程单向通信)
通俗理解
在磁盘建一个特殊管道文件 ,不占实际存储空间,任何进程都能打开读写;分两个终端/两个程序,一个写一个读。
特点:无亲缘限制、持久文件、单向字节流。
Rust 示例(依赖 nix 库操作FIFO)
Cargo.toml
toml
[dependencies]
nix = "0.28"写端程序 fifo_write.rs
rust
use nix::unistd::{close, write};
use nix::sys::stat::{mkfifo, Mode};
use std::ffi::CString;
use std::os::unix::io::AsRawFd;
use std::fs::OpenOptions;
const FIFO_PATH: &str = "/tmp/my_fifo";
fn main() {
// 创建命名管道文件,不存在才创建
let c_path = CString::new(FIFO_PATH).unwrap();
if mkfifo(&c_path, Mode::S_IRUSR | Mode::S_IWUSR).is_err() {
eprintln!("管道已存在,跳过创建");
}
// 打开管道写端
let file = OpenOptions::new()
.write(true)
.open(FIFO_PATH)
.unwrap();
let fd = file.as_rawFd();
let msg = b"命名管道FIFO测试消息";
write(fd, msg).unwrap();
println!("写入FIFO完成");
close(fd).unwrap();
}读端程序 fifo_read.rs
rust
use nix::unistd::{close, read};
use std::fs::OpenOptions;
use std::os::unix::io::AsRawFd;
const FIFO_PATH: &str = "/tmp/my_fifo";
fn main() {
let file = OpenOptions::new()
.read(true)
.open(FIFO_PATH)
.unwrap();
let fd = file.as_rawFd();
let mut buf = [0u8; 128];
let len = read(fd, &mut buf).unwrap();
let msg = String::from_utf8_lossy(&buf[0..len]);
println!("FIFO读到:{}", msg);
close(fd).unwrap();
}使用:先跑读端,新开终端跑写端,读端立刻收到消息。
2-3. 消息队列 MsgQueue(内核消息盒)
通俗理解
操作系统内核开辟一个全局消息信箱 ,所有进程都能投递/取出带类型标记的消息;消息会排队存储,就算进程退出消息还在,可异步收发。
特点:有消息边界、多进程并发、内核持久、支持消息分类筛选。
Rust 示例(nix 操作SystemV消息队列)
Cargo.toml 同上,依赖 nix
rust
use nix::sys::msg::{msgget, msgsnd, msgrcv, MsgBuf, IPC_CREAT};
use nix::sys::ipc::IPC_RMID;
use std::ffi::c_void;
// 消息结构体
#[repr(C)]
struct Msg {
mtype: i64, // 消息类型,用于筛选
text: [u8; 64],
}
fn main() {
// 获取/创建消息队列,key自定义
let msq_id = msgget(0x1234, IPC_CREAT | 0o666).unwrap();
// 1. 发送消息
let mut send_buf = Msg {
mtype: 1,
text: *b"消息队列测试内容\0",
};
msgsnd(msq_id, &send_buf as *const Msg as *const c_void, 16, 0).unwrap();
println!("消息投递成功");
// 2. 接收类型=1的消息
let mut recv_buf = Msg { mtype: 0, text: [0;64] };
msgrcv(
msq_id,
&mut recv_buf as *mut Msg as *mut c_void,
64,
1, // 只取类型1消息
0,
).unwrap();
let text = String::from_utf8_lossy(&recv_buf.text);
println!("读取消息:{}", text.trim_end_matches('\0'));
// 删除消息队列
nix::sys::msg::msgctl(msq_id, IPC_RMID, None).unwrap();
}2-4. 共享内存 SharedMemory(最快IPC)
通俗理解
操作系统划出一块公共内存区域 ,多个进程都把这块内存映射到自己虚拟地址空间,直接读写,没有内核拷贝开销,速度第一。
致命问题:无同步机制,多进程同时写会数据错乱,必须搭配信号量/互斥锁使用。
Rust 示例(SystemV共享内存 + nix)
rust
use nix::sys::shm::{shmget, shmat, shmdt, shmctl, IPC_CREAT};
use nix::sys::ipc::IPC_RMID;
use std::ffi::c_void;
const MEM_SIZE: usize = 128;
fn main() {
// 创建共享内存段
let shm_id = shmget(0x5678, MEM_SIZE, IPC_CREAT | 0o666).unwrap();
// 映射到当前进程地址空间
let shm_ptr = shmat(shm_id, None, 0).unwrap() as *mut u8;
// 写入共享内存
let data = b"共享内存高速通信";
unsafe {
for (i, &b) in data.iter().enumerate() {
*shm_ptr.add(i) = b;
}
}
// 另一个进程可读取,这里本地演示读
unsafe {
let mut buf = Vec::with_capacity(MEM_SIZE);
for i in 0..data.len() {
buf.push(*shm_ptr.add(i));
}
let s = String::from_utf8(buf).unwrap();
println!("共享内存读取:{}", s);
}
// 解除映射
unsafe { shmdt(shm_ptr as *const c_void).unwrap(); }
// 删除共享内存
shmctl(shm_id, IPC_RMID, None).unwrap();
}2-5. 信号量 Semaphore(同步工具,不传输业务数据)
通俗理解
相当于银行叫号机计数器,专门控制多进程访问共享资源的顺序,解决共享内存并发冲突;不传递业务消息,只做互斥/同步。
- 二元信号量(0/1)= 互斥锁,同一时间只允许1个进程操作共享内存
- 计数信号量:允许N个进程同时访问资源
Rust 极简示例(二元信号量锁)
rust
use nix::sys::sem::{semget, semop, SemBuf, IPC_CREAT};
use nix::sys::ipc::IPC_RMID;
fn main() {
// 创建1个信号量集合
let sem_id = semget(0x9999, 1, IPC_CREAT | 0o666).unwrap();
// 初始化信号量值为1(可用,代表锁空闲)
let init_op = SemBuf::new(0, 1, 0);
semop(sem_id, &[init_op]).unwrap();
// P操作:减1,获取锁(值为0则阻塞等待)
let lock = SemBuf::new(0, -1, 0);
semop(sem_id, &[lock]).unwrap();
println!("拿到信号量锁,操作共享资源");
// V操作:加1,释放锁
let unlock = SemBuf::new(0, 1, 0);
semop(sem_id, &[unlock]).unwrap();
println!("释放信号量锁");
// 销毁信号量
nix::sys::sem::semctl(sem_id, 0, IPC_RMID, None).unwrap();
}2-6. Unix域Socket(本地全双工IPC,最通用)
通俗理解
本地文件 形式的套接字,和网络TCP 逻辑一模一样,但不走网卡、只在内核转发;双向通信 ,无进程血缘限制,支持多客户端连接,本机IPC首选。
对比管道:管道单向,Socket双向;对比共享内存:自带流控,不用手动同步。
Rust 示例(Unix Socket 服务端+客户端)
Cargo.toml
toml
[dependencies]
tokio = { version = "1.0", features = ["full"] }server.rs(服务端)
rust
use tokio::net::UnixListener;
use tokio::io::{AsyncReadExt, AsyncWriteExt};
#[tokio::main]
async fn main() {
let sock_path = "/tmp/unix_ipc.sock";
// 清理残留socket文件
let _ = std::fs::remove_file(sock_path);
let listener = UnixListener::bind(sock_path).unwrap();
println!("Unix Socket服务启动,等待客户端连接");
loop {
let (mut stream, _addr) = listener.accept().await.unwrap();
tokio::spawn(async move {
let mut buf = [0; 128];
let len = stream.read(&mut buf).await.unwrap();
let msg = String::from_utf8_lossy(&buf[0..len]);
println!("服务端收到:{}", msg);
stream.write_all(b"服务端响应:Unix Socket双向通信成功").await.unwrap();
});
}
}client.rs(客户端)
rust
use tokio::net::UnixStream;
use tokio::io::{AsyncReadExt, AsyncWriteExt};
#[tokio::main]
async fn main() {
let mut stream = UnixStream::connect("/tmp/unix_ipc.sock").await.unwrap();
stream.write_all(b"客户端消息:你好本地Socket").await.unwrap();
let mut buf = [0; 128];
let len = stream.read(&mut buf).await.unwrap();
println!("客户端收到响应:{}", String::from_utf8_lossy(&buf[0..len]));
}使用:先运行server,新开终端跑client,双向收发消息。
总结:6种IPC对比速记(Markdown表格)
| IPC方式 | 通信方向 | 是否需亲缘进程 | 速度 | 适用场景 |
|---|---|---|---|---|
| 匿名管道 | 单向 | 必须父子 | 中 | 父子进程简单临时传输 |
| FIFO命名管道 | 单向 | 无限制 | 中 | 任意本地程序简单单向传数据 |
| 消息队列 | 双向 | 无限制 | 中 | 结构化消息、异步离线收发 |
| 共享内存 | 双向直接读写 | 无限制 | 最快 | 大数据高速传输,必须加锁同步 |
| 信号量 | 无数据传输 | 无限制 | - | 配套共享内存做并发互斥 |
| Unix Socket | 全双工双向 | 无限制 | 快 | 本机多进程通用通信,替代管道 |
3. 状态
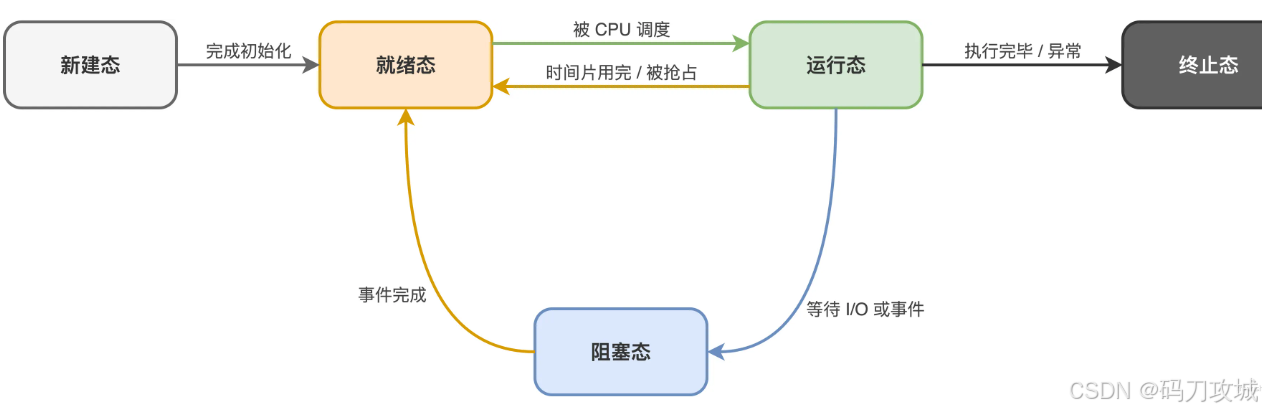
进程状态通俗理解(银行办业务类比)
- 新建态:刚取完号还在填基础信息,还没真正进入等待大厅。操作系统正在给进程分配 PID 和 PCB。
- 就绪态:坐在大厅里资料都齐了,就等叫号。CPU 一空闲就能立马上去运行。
- 运行态:叫到号了,正在柜台办业务,占用着 CPU 执行指令。单核 CPU 同一时刻只能有一个进程在运行,多核可以并行跑多个。
- 阻塞态:办到一半柜员说身份证复印件没带,得去旁边复印或者等家里人送来。这时候就算柜台空出来了也没法办,必须等复印好了才能重新回去排队,不能直接插队继续。
- 终止态:业务办完了,或者因为异常被赶走了,进程结束,资源被回收。
模块3:IO
1、五大 IO 模型
核心前置:一次IO分为两个阶段
等待数据:硬件把数据读到内核缓冲区(网卡/磁盘准备数据)拷贝数据:内核缓冲区 → 用户程序内存
1)阻塞IO(Blocking IO)
调用read/recv后线程全程卡死:
- 阶段1(等数据):数据没到,线程休眠阻塞,什么都做不了;
- 阶段2(拷贝数据):数据就绪后,线程继续阻塞,等内核把数据完整拷贝到用户空间;
- 全程两阶段都阻塞,单个线程只能处理1个连接,并发差。
2)非阻塞IO(Non-Blocking IO)
文件句柄设置O_NONBLOCK标志,调用read不会卡死:
- 阶段1(等数据):数据没准备好,内核直接返回
EAGAIN错误,线程立刻返回,可以去处理别的业务;但业务代码必须循环轮询反复调用read询问"数据好了没",CPU空转浪费; - 阶段2(拷贝数据):一旦内核有数据,本次read会阻塞,直到拷贝完成;
- 缺点:轮询占用大量CPU,极少单独使用。
3)IO多路复用(IO Multiplexing,select/poll/epoll)
一个线程通过select/epoll同时监控成千上百个文件连接:
- 阶段1(等数据):线程调用多路复用函数阻塞等待,只要任意一个连接数据就绪,函数才返回;不用自己循环轮询所有fd;
- 阶段2(拷贝数据):收到就绪通知后,再调用read读取数据,拷贝阶段依然阻塞;
- 优势:单线程管理海量连接,是后端服务最主流模型(nginx、redis、tokio底层)。
4)信号驱动IO(SIGIO)
给文件描述符注册信号回调:
- 阶段1(等数据):线程完全不用阻塞/轮询,内核数据就绪后,主动给进程发送SIGIO信号,触发提前写好的回调函数;线程中间可以自由执行其他业务;
- 阶段2(拷贝数据):回调内部调用read读取,拷贝阶段会阻塞;
- 短板:信号处理机制复杂,多连接场景容易信号风暴,工程极少使用。
5)异步IO(AIO / libaio / io_uring)
真正全程不阻塞,两阶段全部交给内核完成:
- 阶段1(等数据)、阶段2(拷贝数据):都由内核后台异步执行;
- 用户线程发起read请求后直接返回,不用等待;内核完成「等数据+拷贝到用户内存」整套流程后,主动通知程序;
- 区别于多路复用:多路复用只通知"数据准备好了",还要自己read拷贝;异步IO直接把数据拷好给你。
通俗一句话区分
- 阻塞IO:点奶茶,站柜台一动不动等做好、打包完才走;
- 非阻塞IO:隔30秒跑去柜台问一次"好了吗",没好就回去玩手机,反复跑;
- IO多路复用:
你包下奶茶店前台窗口,坐在窗口边玩手机,一次性下单 100 杯奶茶,全程不能离开窗口。
店员不会单独打电话,只要任意一杯奶茶做完,就拍你肩膀提醒:「12 号、37 号奶茶好了」。
你放下手机,依次走到取餐台,一杯一杯亲手拿奶茶(read 拷贝,拿的时候不能玩手机),拿完继续坐回窗口等下一批通知。 核心:等待阶段你被固定束缚在窗口(epoll_wait阻塞),不能去做别的无关大事。 - 信号驱动IO:
你下单 100 杯奶茶,留手机号,直接出门逛街、看电影,完全离开店铺。
任意一杯奶茶做好,店员直接打你手机,电话铃声打断你看电影;
你只能暂停电影,打车回店里,亲手取走做好的奶茶,取完再回去继续逛街。 核心:等待阶段你完全自由,在执行其他业务;通知是被动打断你当前工作,不是你专门蹲点等待。 - 异步IO:填地址让店员做好直接送货上门,全程不用你去柜台。
2、同步 & 异步
核心区别在于:调用方发起操作后,是否需要原地阻塞等待结果返回,才能执行后续逻辑。
1. 同步调用
发起请求后,调用方必须原地干等,整个操作流程不结束、拿不到最终结果,就无法执行后面任何代码。
生活化类比:去银行柜台办转账业务,你站在窗口不能离开,柜员录入信息、核验、扣款全部完成,把回执交给你之后,你才能走掉去做别的事。
代码特征:函数调用返回前,线程全程阻塞;所有同步IO模型(阻塞IO、IO多路复用、非阻塞轮询、信号驱动IO)都属于同步体系。
2. 异步调用
发起请求后函数立刻返回,调用方线程可以继续执行其他业务逻辑;当底层操作100%全部完成后,内核/服务会通过回调函数、事件通知、Future/Promise、信号 等机制主动推送结果给调用方。
生活化类比:手机点外卖,下单支付完页面立刻关闭,你马上回去写代码、刷视频;骑手取餐、配送全部完成送到楼下后,主动打电话通知你取餐。
代码特征:等待数据 + 内核拷贝数据两个阶段均由内核后台完成,全程不阻塞用户线程,典型代表是Linux io_uring、Rust tokio完全异步IO、Java CompletableFuture。
3、阻塞 & 非阻塞
阻塞 和 非阻塞 描述的是调用方在等待数据就绪阶段的线程状态:线程是原地干等、被操作系统挂起放弃CPU,还是调用后立刻返回、可以先去执行其他业务。
1. 阻塞
发起IO请求后线程直接被操作系统挂起,彻底失去CPU时间片,什么业务都无法执行;必须等到硬件数据完全就绪,才会唤醒线程继续往下执行。
举例:调用普通read读取网络数据,远端数据还没到达内核缓冲区时,线程直接卡住休眠,CPU不会分配任何时间片给该线程,期间无法执行任何代码。
生活化类比:你去快递站取件,快递还没分拣出来,工作人员让你站在窗口原地等待,不能离开去买水、玩手机,全程不能做别的事。
2. 非阻塞
发起IO请求后函数会立刻返回,无论内核缓冲区有没有准备好数据:
- 如果数据还没就绪:返回
EAGAIN/EWOULDBLOCK错误码,告知当前无数据; - 如果数据已经就绪:直接读取并返回有效数据。
调用方拿到返回结果后,线程不会被挂起、不会丢失CPU使用权,可以先去处理其他业务逻辑,空闲时再循环调用read轮询询问内核"数据是否就绪"。
生活化类比:快递站有自助查询机,你去查件,如果包裹还没分拣完成,机器立刻提示"暂无包裹",你可以先去超市、买奶茶,过几分钟再来查询一次。
| 组合 | 说明 | 典型场景 |
|---|---|---|
| 同步阻塞 | 调用read无数据就挂起线程,全程等待 | 普通socket、文件默认读写 |
| 同步非阻塞 | read立刻返回,业务循环轮询查询数据 | O_NONBLOCK 单fd轮询 |
| 同步非阻塞多路复用 | epoll_wait阻塞等待就绪通知,再同步read | Nginx、Redis底层 |
| 异步非阻塞 | 内核完成等待+拷贝后主动通知,全程不阻塞 | io_uring、libaio |
Web开发者最大短板 :你们只用Tokio封装好的异步,不懂底层epoll!
一句话总述:IO = 应用等内核读数据(网络/磁盘),等的方式分4种。
1. 阻塞IO
✅ 比喻:奶茶店点单,站在柜台死等 ,啥也不干;
✅ 缺点:一个连接占一个线程,并发极低。
2. 非阻塞IO
✅ 比喻:点单后每隔10秒问一次 ,不用死等,但一直问很累;
✅ 缺点:循环询问消耗CPU。
3. epoll(神!Web高并发基石)
✅ 比喻:把所有订单交给店员,店员做好了主动喊你 ,你不用死等、不用反复问;
✅ 核心本质:Linux IO多路复用,事件驱动 ;
✅ Web关联:Nginx、Tokio、Axum、Redis 全靠epoll,支撑百万并发连接!
4. io_uring
✅ 新一代epoll,比epoll更快,批量处理IO,未来主流;
✅ Tokio正在适配io_uring,性能再翻倍。
✅ Rust演示(mio = Tokio底层,极简epoll事件监听):
toml
[dependencies]
mio = { version = "1.0", features = ["net"] }
rust
use mio::{Events, Interest, Poll, Token};
use std::net::TcpListener;
// epoll核心演示:监听网络事件
fn main() -> std::io::Result<()> {
let mut poll = Poll::new()?;
let mut events = Events::with_capacity(10);
let listener = TcpListener::bind("127.0.0.1:8080")?;
// 把socket注册到epoll
poll.registry().register(&listener, Token(0), Interest::READABLE)?;
println!("epoll监听8080端口,等待连接...");
// 内核主动通知事件
loop {
poll.poll(&mut events, None)?;
for _ in events.iter() {
println!("收到客户端连接!epoll工作正常");
}
}
}模块4:Linux权限(Docker/容器底层原理!)
一句话总述:容器 = namespace(隔离) + cgroup(限制)
1. UID / GID
- UID:用户身份证(root=0,普通用户=1000);
- GID:用户组身份证,权限按用户/组划分。
2. Capability
拆分root权限:不用给应用root权限,只给「绑定80端口」的小权限。
3. cgroup(资源限制)
✅ 比喻:给学生定规矩,最多用2根笔、1张纸 ;
✅ 作用:限制进程CPU、内存、带宽,防止Web服务占满服务器。
4. namespace(环境隔离)
✅ 比喻:给学生造一个独立教室 ,他以为自己独占整栋楼;
✅ 作用:隔离PID、网络、文件、用户 → 这就是容器!
✅ 教学金句:
容器不是虚拟机!容器就是一个被namespace隔离、cgroup限制的普通Linux进程!
模块5:工具链 + ELF + 编译原理
1. 必备工具(Web排查神器)
给学生直接记:
strace:看进程所有系统调用(查服务卡顿);perf:查CPU性能瓶颈;gdb:调试进程;lsof:看进程打开的FD(网络连接/文件);readelf:看ELF文件信息。
2. ELF 文件
Linux的可执行文件格式(=Windows的exe),存代码、依赖、数据。
3. 静态编译 / 动态编译
- 动态编译:共享系统库,文件小,换机器可能缺库;
- 静态编译 :把所有依赖打包进程序,到处运行 ;
✅ Rust特色:默认静态编译!所以Rust二进制文件拷贝到任意Linux机器都能跑,不用装依赖。
总结
- 内核是管家,应用是住户,用户态↔内核态切换是性能关键;
- epoll是Web高并发的灵魂,Tokio/Axum/Nginx全靠它;
- 容器=隔离(namespace)+限制(cgroup),不是虚拟机;
- Linux一切皆文件,FD是文件/连接的门牌号,inode是文件身份证;
- Rust默认静态编译+epoll异步,天生适合Linux高并发Web服务。
这套讲解通俗、有比喻、有代码、有实战关联,学生完全能听懂,你讲起来也轻松!