数据窗口
下列查询汇总了2005年5月至8月期间每月电影租借付款总额
bash
select quarter(payment_date) quarter,month(payment_date) month_nm,sum(amount) monthly_sales from payment
where year(payment_date) = '2005' group by quarter(payment_date),month(payment_date);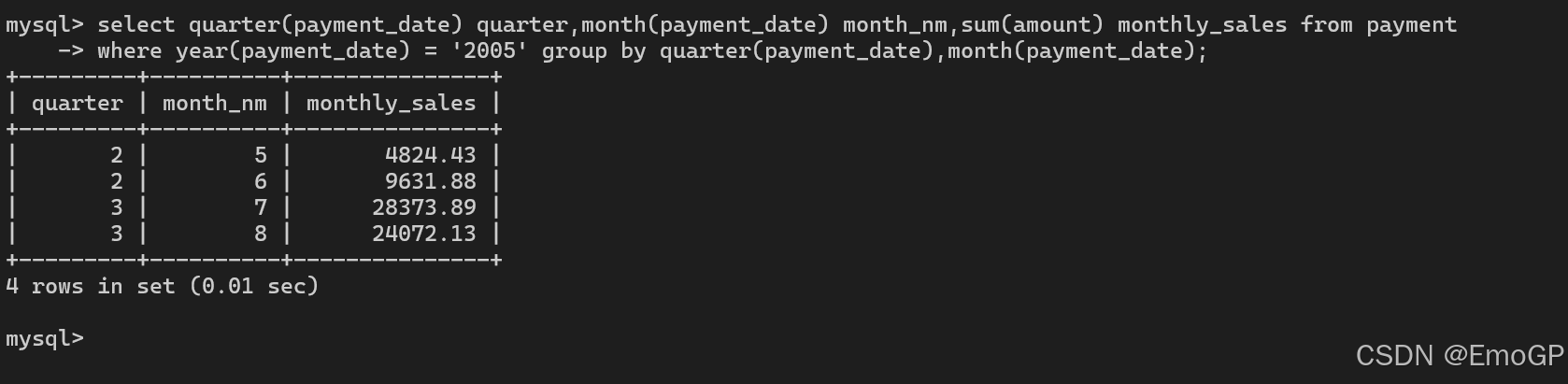
为了能以编程的方式确定最大值,需要在每行添加额外的列,显示每个季度和整个期间内的最大值
bash
select quarter(payment_date),month(payment_date),sum(amount),max(sum(amount)) over(),max(sum(amount)) over(partition by quarter(payment_date))
from payment
where year(payment_date) = '2005' group by quarter(payment_date),month(payment_date);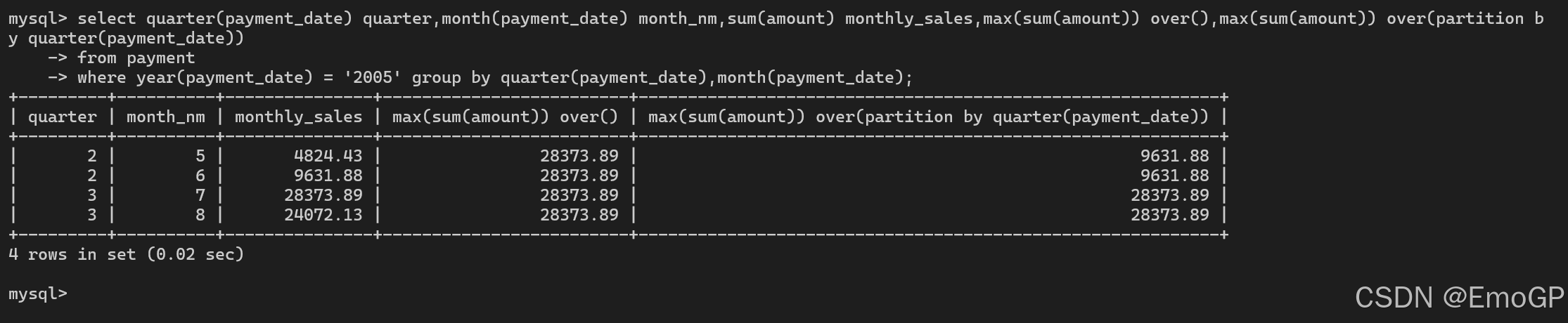
窗口是使用over子句和可选的partition by次子句来定义的,在之前的查询中,两个分析函数都含有over子句,但是第一个over子句是空的,表示窗口应该包含整个结果集,而第二个over子句则指定窗口应该只包含同一季度的行
本地化排序
除了将结果集划分入数据窗口供分析函数使用之外,还可以指定一个排序的顺序。例如,如果要为每个月定义一个等级,其中1代表销售额最高的月份,需要指定哪一列(或几列)用于排名
select quarter(payment_date) quarter,month(payment_date) month_nm,sum(amount) monthly_sales,rank() over(order by sum(amount) desc) from payment where year(payment_date) = '2005' group by quarter(payment_date),month(payment_date)
order by 1,2;

在某些情况下,你可能希望在同一个分析函数调用中使用partition by 和 order by次子句。例如,可以为每个季度提供不同的排名,而不是对整个结果集采用单一的排名
bash
select quarter(payment_date) quarter,month(payment_date) month_nm,sum(amount) monthly_sales,
rank() over(partition by quarter(payment_date) order by sum(amount) desc) from payment where year(payment_date) = '2005' group by quarter(payment_date),month(payment_date)
order by 1,2;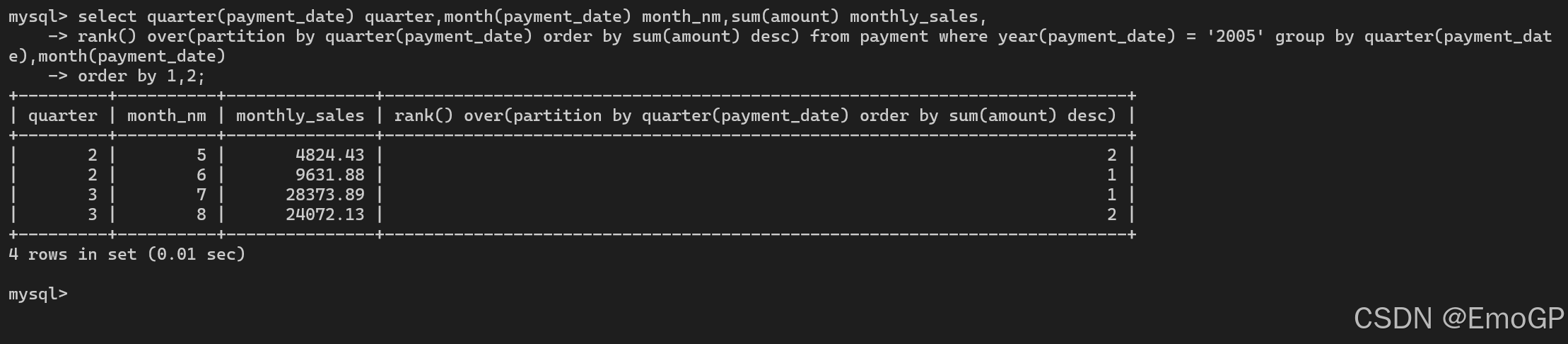
排名
排名函数
SQL标准提供了多个排名函数,各自采用了不同的方法来处理并列的情况
row_number:为每一行返回一个唯一的排名,如果出现并列的情况,则任意分配排名
rank:在出现并列的情况下,返回相同的排名,会在排名中产生空隙
dense_rank:在出现并列的情况下,返回相同的排名,不会在排名中产生空隙
假设市场部想找出租借电影数量最多的10位客户,为其提供一部免租借费电影。下列查询列出了每位客户租借电影的数量并按照降序对结果进行了排序:
bash
select customer_id,count(*) cnt from rental group by customer_id order by 2 desc limit 20;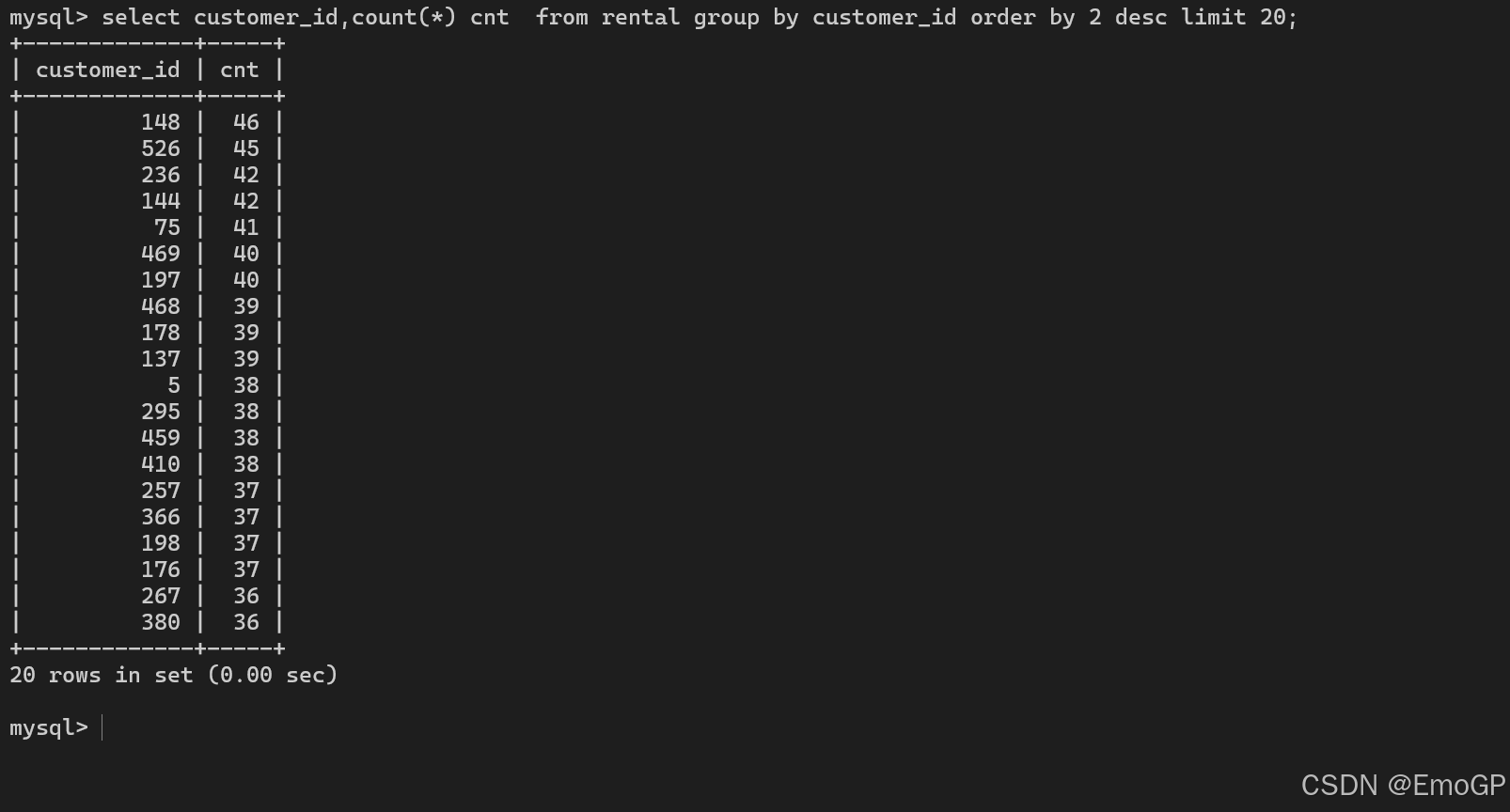
下面使用不同的排名函数:
bash
select customer_id,count(*) cnt,row_number() over(order by count(*) desc),rank() over(order by count(*) desc),
dense_rank() over(order by count(*) desc)
from rental group by customer_id order by 2 desc limit 20;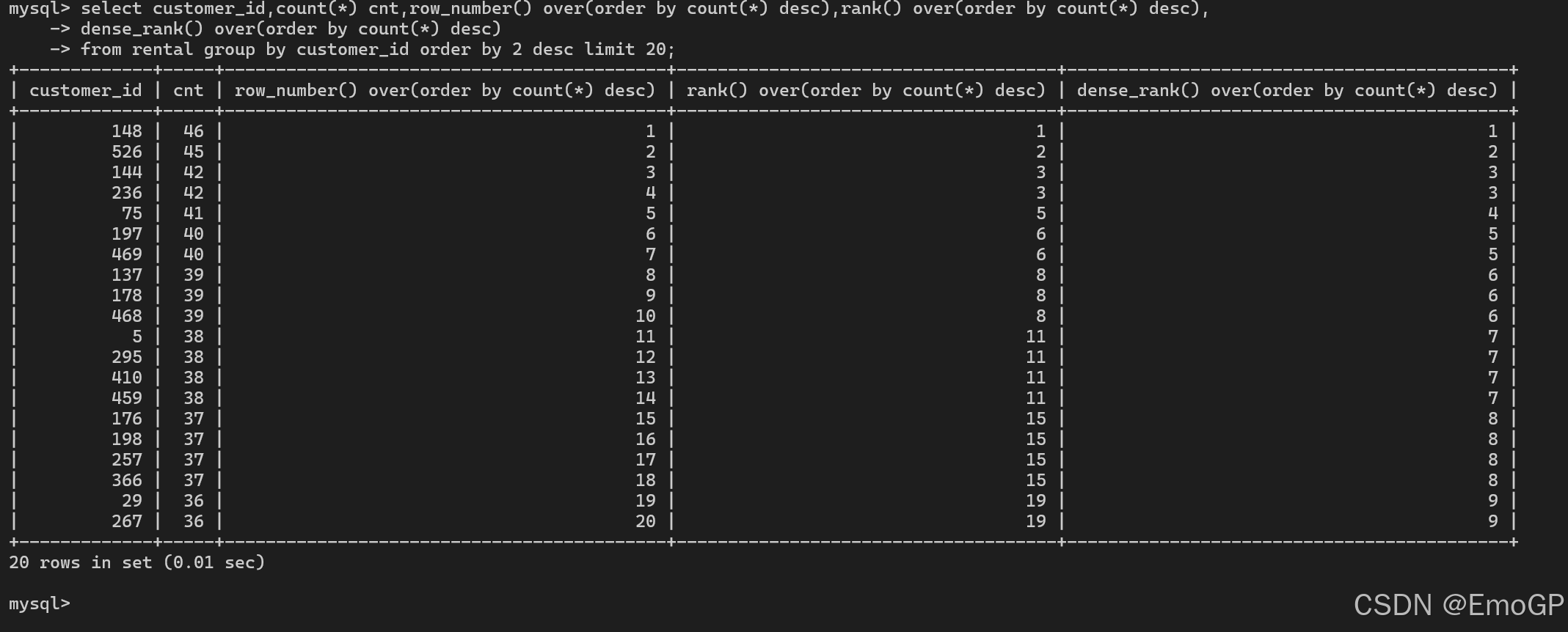
rank():并列会跳号
dense_rank():并列不跳号(名次密集/连续)
row_number():绝对不并列
报表函数
除了排名,分析函数的另一种常见用法是找出离群值(outlier)(例如最大值或最小值)或生成整个数据集的汇总值/平均值。对于此类用途,可以使用聚合函数(min、max、avg、sum和count),但不是将其与group by子句并用,而是搭配over子句。下面的示例生成支付金额在10美元或以上的客户的月度金额和总金额
bash
select monthname(payment_date) payment_month,amount,sum(amount) over(),sum(amount) over(partition by monthname(payment_date))
from payment where amount >= 10;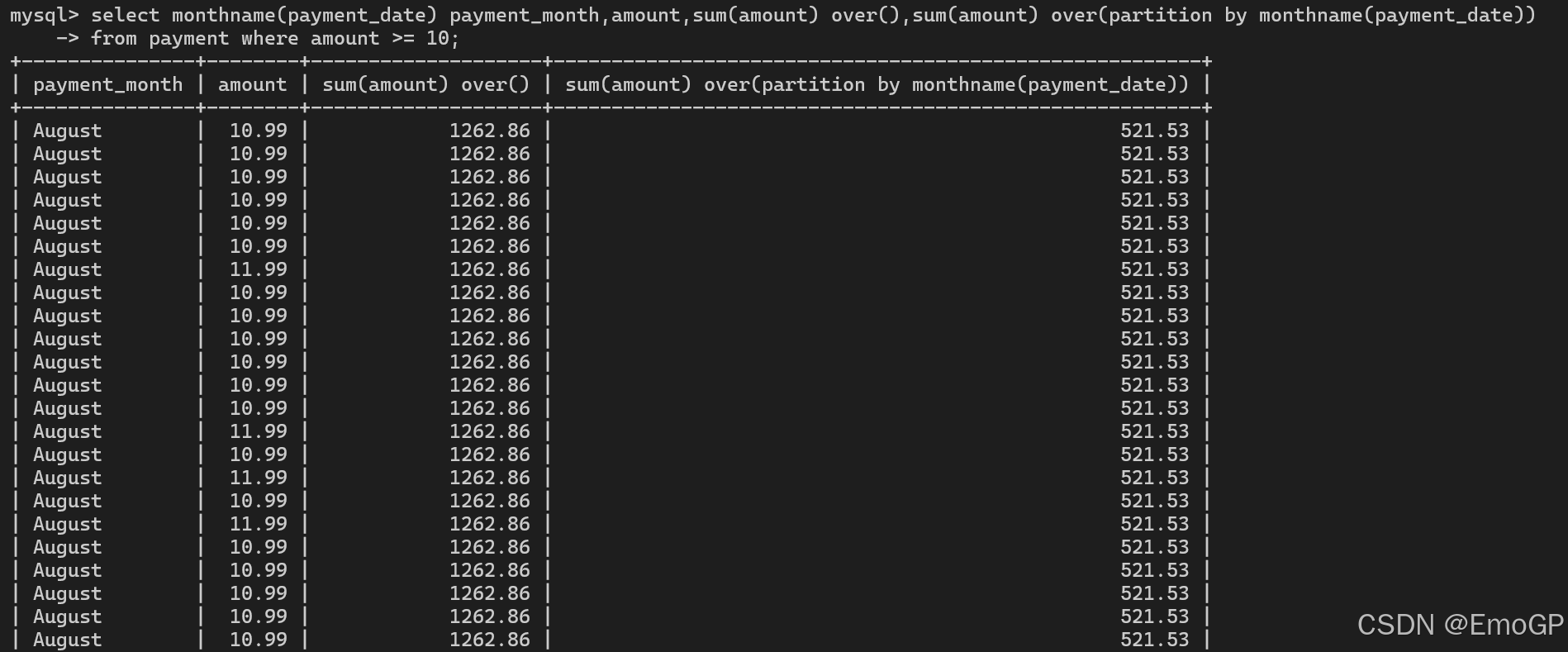
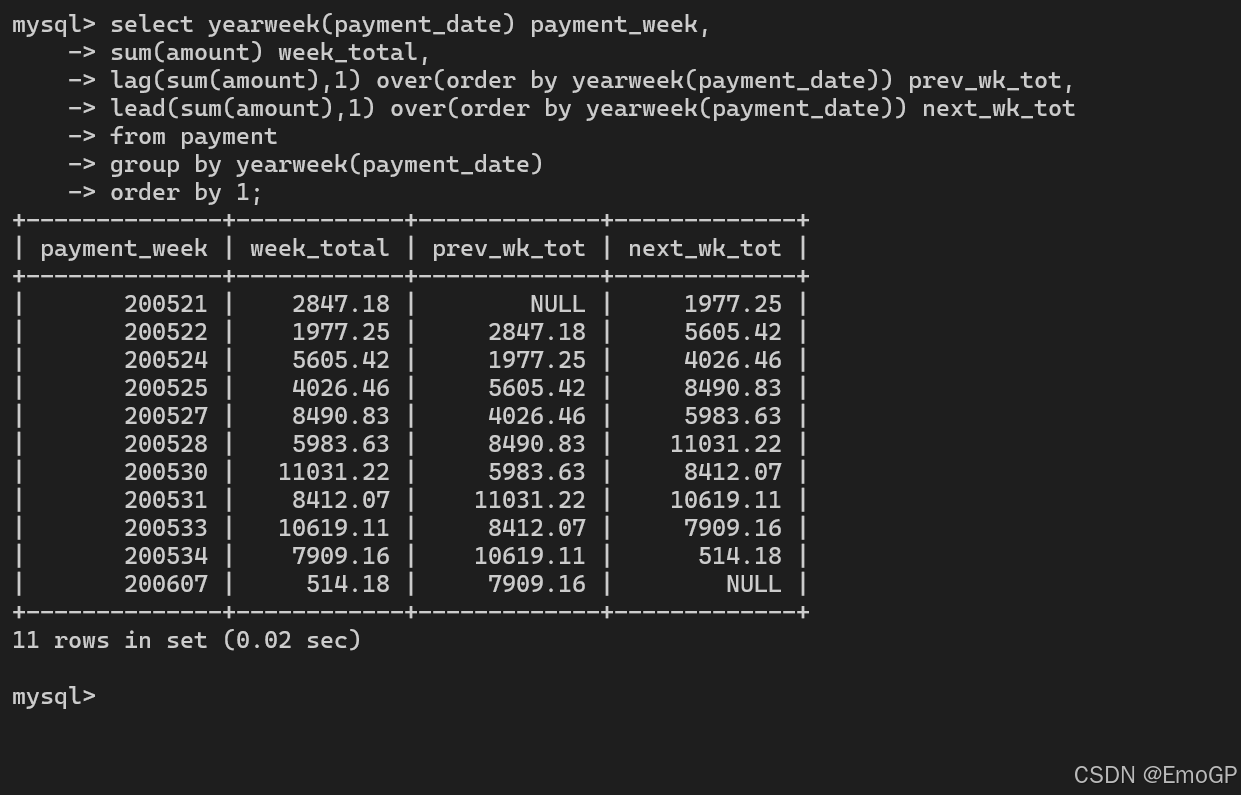
lag和lead
LAG():向前看(获取历史数据 / 上一行)。
LEAD():向后看(获取未来数据 / 下一行)。
列值拼接
在 MySQL 中,GROUP_CONCAT() 是一个非常实用的聚合函数,专门用于将同一个分组内的多个值拼接成一个字符串。它通常与 GROUP BY 子句配合使用,是解决"一对多"数据展示(例如:一个学生选了多门课、一个店铺有多个设备)的绝佳利器。
bash
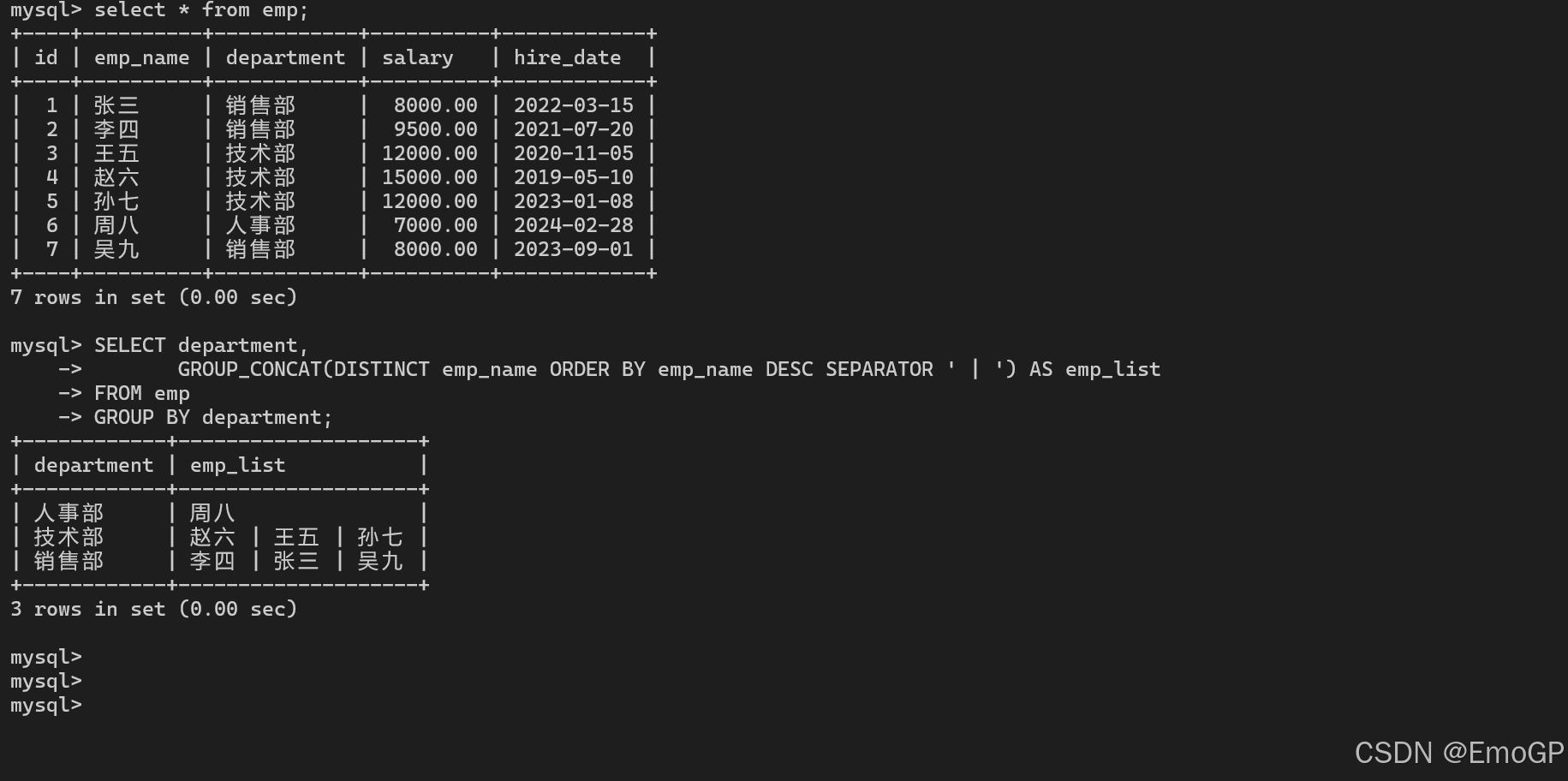
SELECT department,
GROUP_CONCAT(DISTINCT emp_name ORDER BY emp_name DESC SEPARATOR ' | ') AS emp_list
FROM emp
GROUP BY department;