做过视频运营的人都知道:真正耗费时间的并不是拍摄,而是后期修改。例如:产品名称变了、活动价格调整了、某些表述需要优化、视频需要适配不同平台等等;
很多情况下,仅仅修改一句话,就要重新录音、重新剪辑甚至重新导出整条视频。随着AI视频编辑技术的发展,现在已经出现了一种新的工作模式:先修改文本,再修改视频。
最近体验了一套AI视频处理流程,发现对于视频二次创作场景确实能节省不少时间。本文从技术工作流角度分享实际操作过程。小鹿播官网---专为录播/无人直播打造的专业软件
长视频改词换句,像改Word一样改视频!
为什么视频二次创作成本一直很高?
传统视频修改流程通常如下:发现问题 → 重新录音 → 导入剪辑软件 → 重新对齐时间轴 → 重新渲染导出;
如果修改内容较多:配音要重做、字幕要重做、时间轴要重新调整等等,一条10分钟的视频,可能仅修改一句话,却需要几十分钟甚至更长时间。
问题的核心在于:
视频内容与声音内容深度绑定。
只要声音发生变化,整个剪辑链路都要重新处理。
AI视频编辑的新思路
目前越来越多AI工具采用的是:视频 → 语音识别 → 文字稿 → 修改文本 → AI生成语音 → 自动合成视频
也就是说:先把视频转换成可编辑文本,再通过文本驱动视频修改。
这种方式与传统剪辑最大的区别在于:
操作对象从时间轴变成了文字。
实操流程
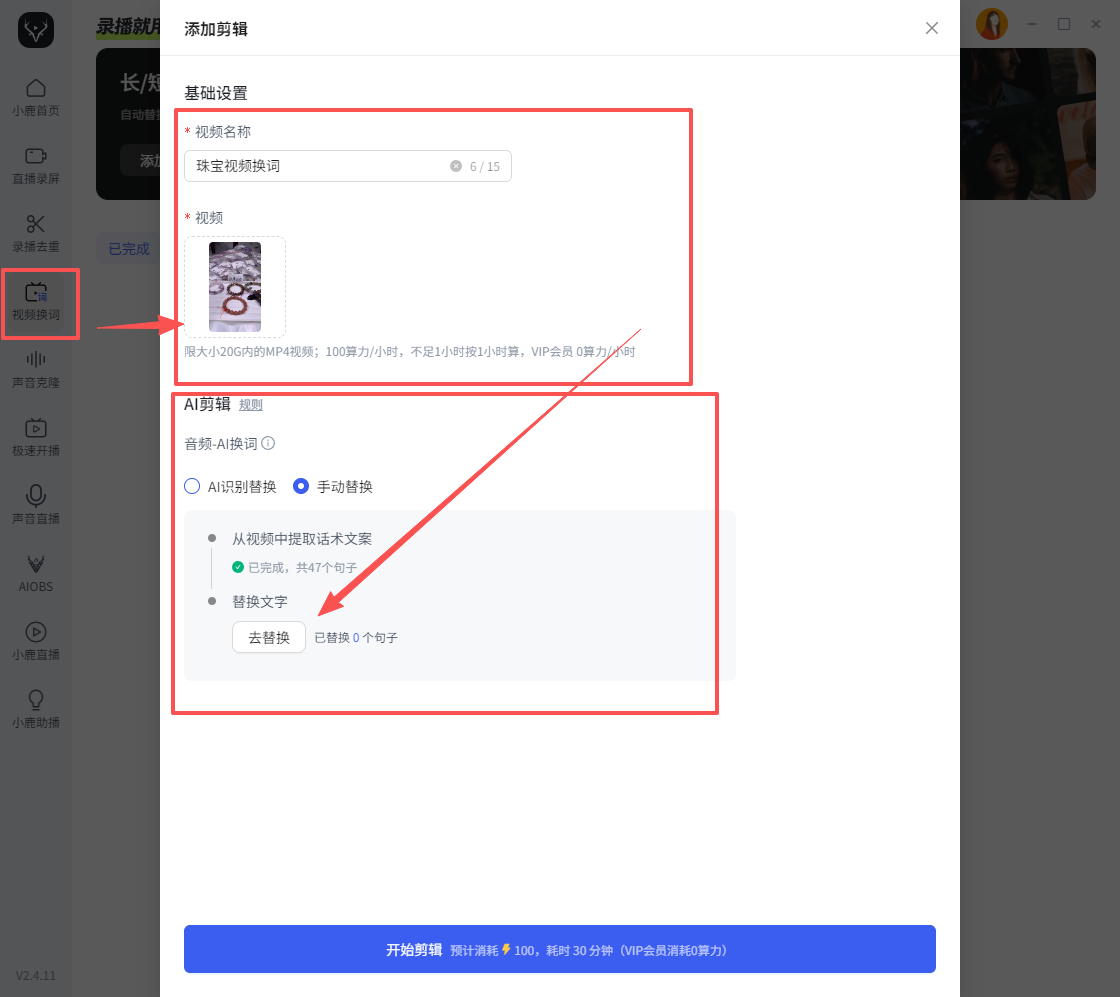
第一步:导入原始视频
将需要修改的视频导入系统。系统自动完成:
- 音频提取
- 语音识别
- 字幕生成
整个过程不需要人工打字幕。对于普通口播视频,识别准确率已经能够满足大部分修改需求。
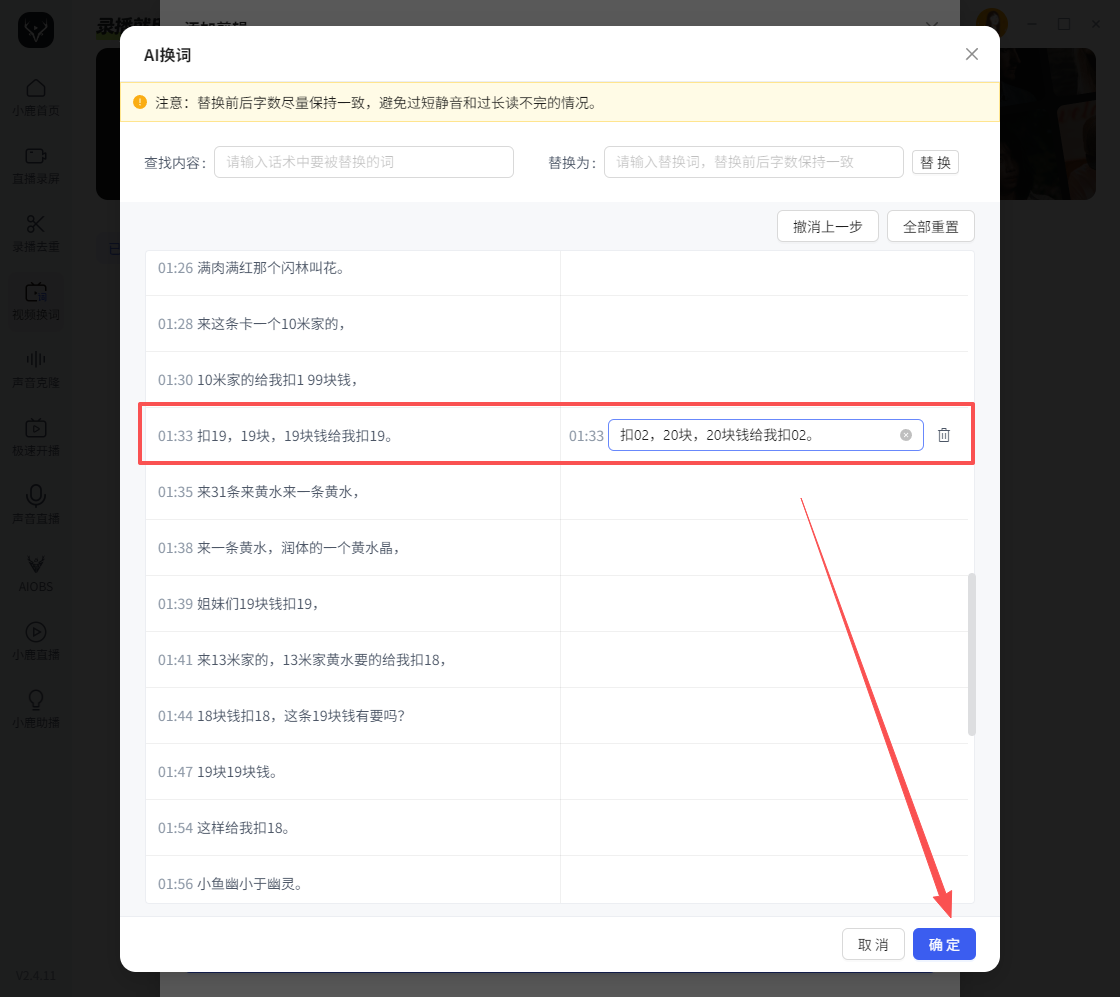
第二步:定位需要修改的内容
识别完成后,可以直接查看完整文稿。
例如原文:本次活动截止到5月31日。
修改为:本次活动截止到6月30日。
不需要重新录音,也不需要重新拍摄,仅需修改对应文字即可。
第三步:AI生成新语音
文本修改完成后,系统会自动生成新的语音片段。
这里涉及两个关键技术:语音克隆 和 智能停顿
以保持原有音色,避免出现前半段是本人声音、后半段是AI声音造成的割裂感;
还会根据主播习惯AI系统自动学习语速、停顿、语气,尽量保持前后内容一致。

视频复用场景
场景一:知识付费课程
课程更新是常见需求。数据更新、案例更新、价格调整等;
过去,重新录课。现在,修改对应内容即可。
场景二:短视频矩阵运营
同一内容往往需要:抖音版本、视频号版本、小红书版本等,不同平台规则不同。通过文本修改可以快速生成多个版本。
场景三:直播切片
很多直播录屏内容都有复用价值。但存在:口误、信息过期、产品变更等问题。AI修改后可以直接形成新的发布素材。
AI视频编辑的发展方向,正在从"剪辑工具"向"内容管理工具"演进。未来的视频修改可能越来越像编辑Word文档:找到对应文字、完成修改、一键生成结果。对于需要长期运营视频内容的人来说,这种基于文本驱动的视频编辑方式,正在成为一种新的生产力工具。