文章目录
-
- 摘要
- [I. 引言](#I. 引言)
- [II. 相关工作](#II. 相关工作)
-
- [A. 5G 毫米波网络及其对 TCP 的挑战](#A. 5G 毫米波网络及其对 TCP 的挑战)
- [B. TCP 性能增强代理](#B. TCP 性能增强代理)
- [III. 面向毫米波的端到端代理架构](#III. 面向毫米波的端到端代理架构)
-
- [A. 代理架构](#A. 代理架构)
- [B. RTT 估计](#B. RTT 估计)
- [C. 与 5G 协议栈的集成](#C. 与 5G 协议栈的集成)
- [D. 窗口管理](#D. 窗口管理)
- [IV. 性能评估](#IV. 性能评估)
-
- [A. ns-3 毫米波模块](#A. ns-3 毫米波模块)
- [B. 场景与参数](#B. 场景与参数)
- [C. 结果](#C. 结果)
- [V. 结论](#V. 结论)
摘要
传输控制协议(Transmission Control Protocol, TCP)是互联网中使用最广泛的传输协议。然而,当 TCP 运行在高带宽的毫米波(millimeter-wave, mmWave)链路上时,其性能并不理想。在这类高频通信中,主要问题包括:(i)对遮挡敏感;(ii)由于视距(Line of Sight, LOS)与非视距(Non Line of Sight, NLOS)之间的转换以及反向转换,链路带宽会发生剧烈波动。特别是,TCP 对端到端连接只有抽象视图,不能恰当地捕获无线毫米波链路的动态特性,其后果是可用资源利用不足。本文提出一种 TCP 代理架构,它无需修改远端发送方即可提升 TCP 流的性能。该代理部署在无线接入网(Radio Access Network, RAN)中,并利用下一代基站(Next Generation Node Base, gNB)处可获得的信息,以最大化吞吐量并最小化时延。
I. 引言
毫米波频段通信代表了无线网络的新前沿 1。如今,大多数无线标准只能使用 6 GHz 以下频谱中很小的一段带宽。毫米波频谱,以及更一般地说 6 GHz 以上的频率,则可以让无线通信利用大量尚未充分开发的频谱块,从而达到很高的数据速率。
毫米波正被用于下一代蜂窝网络,也就是 5G 的研究与标准化中。目前 3GPP 正在以新空口(New Radio, NR)的形式对其进行标准化 2;毫米波也被考虑用于公共安全 3 和车联网通信 4, 5。这些场景中的许多应用都需要高数据速率和低时延,例如用于远程操控自主机器人的实时视频流、虚拟现实应用,或者车辆之间原始传感器数据(如雷达或激光雷达数据)的交换。然而,毫米波技术既具有巨大潜力,也带来了一系列挑战。这些挑战与严苛的传播条件有关,必须在毫米波能够可靠部署之前加以解决。极高的路径损耗可以通过波束成形技术克服,而波束成形又要求协议设计能够考虑方向性(that account for directionality) 6。此外,毫米波容易受到障碍物遮挡,例如建筑、树木,甚至人体本身 7;这会影响服务可用性和可达数据速率。
这些限制不仅影响无线链路的协议栈,也会影响更高层协议(higher layers protocols),例如 TCP。TCP 是互联网中使用最广泛的传输协议,用于多种需要流量控制和可靠传输的应用。然而,当端到端连接的最后一跳基于毫米波无线电时,TCP 会同时遭受吞吐量降低和时延升高的问题 8,不能提供前述应用所需的高数据速率和低时延性能 9。
本文提出 milliProxy 的设计。milliProxy 是一种新的面向毫米波移动网络的 TCP 代理,目标是在低时延下充分获得毫米波链路的高吞吐量收益。它对连接两端主机透明(transparent to the end hosts of the connection),并保持端到端连接语义(respects the end-to-end connection semantics)。其核心思想是在毫米波 RAN 内拆分 TCP 控制环路,从而优化无线链路上的流量控制。该方案基于跨层、数据驱动的方法(a cross-layer, data driven approach),并支持针对毫米波网络中 TCP 运行的多种优化。
本文其余部分组织如下。第 II 节详细讨论 TCP 在毫米波链路上的主要限制,并概述传统无线网络中与 TCP 代理相关的文献。第 III 节描述 milliProxy 的架构。第 IV 节给出性能评估结果。最后,第 V 节总结本文并讨论未来扩展方向。
II. 相关工作
A. 5G 毫米波网络及其对 TCP 的挑战
本节概述在毫米波蜂窝网络中使用 TCP 所面临的主要挑战。得益于极大的可用带宽,毫米波网络有潜力提供 Gbit/s 级的小区数据速率 1;但可靠 5G 毫米波网络的部署很有挑战,主要原因是这些频率上的传播环境十分严苛。高传播损耗可以通过在收发端使用大量天线进行波束成形来补偿,但这要求物理层(Physical layer, PHY)和媒体接入控制层(Medium Access Control, MAC)协议能够处理方向性 6。此外,毫米波频段对多种材料的遮挡都很敏感 7。虽然在 NLOS 条件下仍然可以利用反射进行发送和接收,但从 LOS 切换到 NLOS 时,可达数据速率和可靠性会出现巨大差异;信干噪比(Signal to Interference plus Noise Ratio, SINR)的差异可达到约 30 dB,反向切换时亦然。
因此,即使毫米波拥有大量资源,要完全受益于这些资源仍然很困难,特别是还要考虑端到端性能以及高层协议与毫米波协议栈之间的复杂交互。已有工作 8, 10-14 也展示了这一点。具体而言,与端到端网络中最常用传输协议 TCP 相关的主要问题,是 TCP 对毫米波链路信道质量变化的反应太慢 8, 10, 12。这会造成可用资源利用不足,因为最常用拥塞控制算法的拥塞窗口爬升速度太慢,例如 TCP CUBIC 15 和 TCP NewReno 16,从而限制了可达有效吞吐量(limits the achievable goodput)。与传统 sub-6 GHz 部署相比,这一问题在毫米波链路中更加突出,因为二者在带宽以及可达速率上存在数量级差异;并且如 12 所示,当连接的往返时间(Round Trip Time, RTT)增大时,该问题会更加明显。
另一个后果是缓冲膨胀(bufferbloat)现象 8。当信道条件从 LOS 变为 NLOS 时,物理层提供的数据速率会下降。这会带来问题,因为多余分组会被缓存在无线链路控制层(Radio Link Control, RLC),而 TCP 发送端在主动队列管理(Active Queue Management, AQM)机制或缓冲区溢出丢弃一个或多个分组之前,并不知道链路状态已经变化。于是缓冲区占用量增加,进而端到端时延升高。最后,还可能出现由遮挡和缺少回退链路导致的长时间中断。TCP 会以重传超时响应这些事件,并在每次事件中将慢启动阈值减半。随后当连接恢复时,慢启动阶段的持续时间受到限制,虽然该阶段中拥塞窗口按指数增长;而 TCP 发送端大部分时间会停留在拥塞避免阶段,在该阶段拥塞窗口只线性增长。这会进一步加剧拥塞窗口爬升缓慢的问题。
B. TCP 性能增强代理
自 20 世纪 90 年代第一批支持数据传输的蜂窝网络商用部署以来,TCP 在无线网络上的性能就一直受到关注。虽然 TCP 在毫米波蜂窝网络上会遇到更具挑战性的条件,但仍有必要回顾文献中提升无线链路 TCP 性能的主要方法。
Balakrishnan 等人在 17 中给出了关于该主题的早期全面综述。作者认为,移动网络中 TCP 性能较差的原因在于不可靠信道上的分组丢失。然而,如 11 所示,信道损失可以被重传机制掩蔽。此外,该文考虑的链路数据速率很低,网络中的缓冲区也很小。毫米波网络中的设置非常不同,因为无线链路中已经实现了大缓冲区和重传,以牺牲时延为代价弥补分组丢失,并使网络更容易暴露于 bufferbloat 现象之下。尽管如此,17 的作者比较了不同策略,这些策略有可能适配到毫米波网络中,包括以 TCP Reno 为基线以及 TCP 拆分方法。
在较新的工作 18 中,Liu 等人提出了一种 TCP 代理中间盒,用于在无需修改服务器、客户端和基站协议栈的情况下优化 TCP 性能。他们观察到,在移动网络中常用 HTTP 代理的情况下,采用新的端到端 TCP 拥塞控制机制可能并不有效。此外,他们的方案面向现代 LTE 网络设计。这类网络具有大缓冲区(约 5 MB)和带宽波动,尽管波动幅度没有毫米波网络那么大 1, 9,并且固定网络不是瓶颈。他们的方案是一个可放置在移动运营商核心网任意位置的中间盒,它将 TCP 连接拆分成两段,也就是说不遵守端到端连接语义。(端到端原则强调某些功能应由端主机完成;将 TCP 连接拆分为两个独立片段的代理通常不遵守端到端 TCP 语义,因为 ACK 可能在分组真正到达另一端主机之前就被发送给发送端。) 该中间盒会即时执行一些优化,例如:(i)不使用接收端拥塞窗口信息,因为相对于链路真实可用速率,该窗口可能太小;真实设备中接收缓冲区的实验评估也表明它从未被填满;(ii)通过拦截重复 ACK 改变重传模式;(iii)使用速率估计算法调节拥塞窗口。在这种设计中,从发送端到接收端的 TCP 连接在中间盒处终止,中间盒会为最终接收端缓存分组,直到能够转发它们。
第三种方法见 21,其中 Ren 等人在移动网络基站中引入 TCP 代理。不过,该研究聚焦于 UMTS 架构。他们的方法基于队列控制机制:通过滑模变结构(Sliding Mode Variable Structure, SMVS)控制理论,使基站处的缓冲队列长度保持为相同大小。该代理不遵守端到端 TCP 语义,因为它在代理处终止连接。代理处的通告窗口用于限制服务器发送速率并避免缓冲时延。代理处还使用控制机制,通过推断基站可用带宽,将队列长度保持在参考值附近。
还有一些遵守端到端 TCP 语义的有趣方案:(i)Mobile TCP(M-TCP)22 在感知到即将发生拥塞时冻结 TCP 发送端,以避免分组丢失和连接超时;(ii)同样由 Balakrishnan 等人提出的 Snoop 23 在感知到 TCP 分组丢失时执行本地重传,以提高连接反应能力。相反,I-TCP 24 是一种 TCP 拆分方法,不符合端到端 TCP 语义;它也在无线链路上使用传统 TCP 拥塞控制,因此并未带来很大的性能提升。
25 提出了一种面向毫米波蜂窝网络的性能增强代理。它安装在基站中,并通过向服务器发送提前 ACK 来破坏端到端 TCP 语义。此外,它执行批量重传,即重传被检测为丢失的分组,以及序列号接近丢失分组的那些段。然而,该方法的丢包检测假设链路上只执行混合自动重传请求(Hybrid Automatic Repeat reQuest, HARQ)重传;而一般来说,使用 TCP 时还会采用 RLC 确认模式(Acknowledged Mode, AM)。此外,在性能评估中,25 的作者将应用数据速率限制为 100 Mbit/s,这通常即使在 NLOS 下也可以维持。因此,其性能分析没有考虑毫米波可达到的极高数据速率,也没有考虑 LOS 到 NLOS(或反向)转换带来的大范围速率变化。最后,该研究只关注单个用户的吞吐量和交付率,没有考虑时延,因此也没有考虑 bufferbloat 问题。
III. 面向毫米波的端到端代理架构
本节描述我们面向毫米波的 TCP 代理架构 milliProxy,并突出其相对于第 II 节方案的主要创新。重要的是,milliProxy 对 TCP 流的两个端点都透明,因此它保持 TCP 连接的端到端语义,这与第 II 节中多数已有方案不同。milliProxy 的关键功能包括:(1)能够使用不同且可调的流窗口(Flow Window, FW)策略,将连接控制环路在源服务器和代理处拆分;(2)能够控制代理与用户设备(User Equipment, UE)之间连接部分的最大分段大小(Maximum Segment Size, MSS)。
注:
对端主机透明(transparent to the end hosts) 指服务器和 UE 不需要修改 TCP 协议栈或应用程序,也不需要显式感知网络中部署了 milliProxy。
保持端到端连接语义(end-to-end connection semantics) 指代理不把一条 TCP 连接真正终止并拆成两条独立 TCP 连接,也不在 UE 实际收到数据之前替 UE 向服务器提前确认。换言之,milliProxy 可以调节通告窗口、缓存载荷和控制代理到 UE 段的 MSS,但 ACK 仍应反映接收端的真实接收状态。
不保持端到端语义的代理通常会在
server -> proxy数据到达后就立即替 UE 向 server 返回 ACK;即使 UE 还没有真正收到这些字节,server 也会以为数据已经交付。milliProxy 的路径则是server -> proxy 缓存数据 -> proxy 发给 UE -> UE ACK -> proxy 再把 ACK 反馈给 server。因此,它只是缓存、重分段并通过修改 advertised window 影响 server 的发送速率,而不是替 UE 提前确认数据。拆分 TCP 控制环路(split the TCP control loop) 指把一部分发送速率/窗口控制逻辑下沉到靠近毫米波无线链路的 RAN 内部。远端服务器仍运行传统 TCP,但 milliProxy 可以根据 gNB 侧可获得的 RLC 缓冲区占用量、PHY 估计速率和 RTT 等信息设置流窗口,并通过修改 ACK 中的通告窗口影响服务器发送速率。这样做的目的,是让无线侧的快速 LOS/NLOS 切换、遮挡和速率波动能被更快反映到流量控制中,避免远端 TCP 只依赖端到端 ACK、丢包或 RTT 变化而反应过慢。
路径 MTU 与 MSS(Path Maximum Transmission Unit and MSS) 路径 MTU 是端到端路径中所有链路可承载 IP 包大小的最小值;TCP MSS 通常约等于路径 MTU 减去 IP/TCP 首部。普通以太网 MTU 为 1500 字节时,IPv4 下常见 MSS 为 1500 − 20 − 20 = 1460 1500-20-20=1460 1500−20−20=1460 字节。本文的关键点是:端到端路径可能被中间以太网链路限制为小 MSS,但 milliProxy 到 UE 这一段由代理控制,可以把多个 1460 字节载荷在无线段重新聚合成更大的 TCP 段,从而减少 TCP/IP 首部和 ACK 开销。
A. 代理架构
milliProxy 是一种 TCP 代理,可以作为网络功能实现和部署,并由多个可更新或可替换的模块组成。
- 它可以部署在 gNB 中,从而充分受益于与毫米波协议栈的交互;
- 也可以部署在核心网中的一个节点上,并与 TCP 接收端连接的 gNB 共享带外信息(sharing out-of-band information with the gNB to which the TCP receiver is connected)。
根据代理所在位置,可能需要设计一种机制来处理用户移动性(the need to design a mechanism to cope with the user mobility)。例如,
- 如果代理位于 gNB 中,那么当 UE 执行切换时,网络必须将 milliProxy 的状态从源 gNB 转移到目标 gNB。
- 如果代理位于核心网边缘节点中,则它可以管理多个小区,而无需为每次 UE 切换转发状态。关于这一问题的更多考虑留作未来工作。
代理的基本结构如图 1 所示。对于每条经过安装节点的 TCP 流,都会创建一个代理实例,这样就可以为不同用户或同一用户的不同流启用不同策略(different policies can be enabled for different users, or different flows of the same user)。每个实例都有自己的可定制缓冲区(its own customizable buffer,默认设置为 10 MB)、流窗口模块(flow window module)和 ACK 管理单元。
- 缓冲区用于存储 TCP 分组的载荷,直到这些载荷能够被交付给 TCP 接收端;
- ACK 管理单元则检查传入 ACK,以清除缓冲区中的内容。
- 流窗口策略相当于代理处的拥塞窗口机制(the congestion window mechanism at the TCP sender),也就是控制代理能够转发多少数据。
注:
- 每条 TCP 流一个代理实例(per-flow proxy instance) "安装节点"指部署了 milliProxy 的位置,例如 gNB 或核心网/边缘节点。凡是经过该节点的 TCP 流,milliProxy 都会为它创建一个独立实例;例如,用户 A 的视频流、用户 A 的文件下载流和用户 B 的网页流可以分别对应 instance 1、instance 2 和 instance 3。每个实例都有自己的 buffer、流窗口模块、ACK 管理单元和策略配置,因此可以按用户、业务或连接分别控制,而不是对所有流使用同一套策略。这里的 TCP 流通常可由五元组区分,即源 IP、源端口、目的 IP、目的端口和协议 TCP。
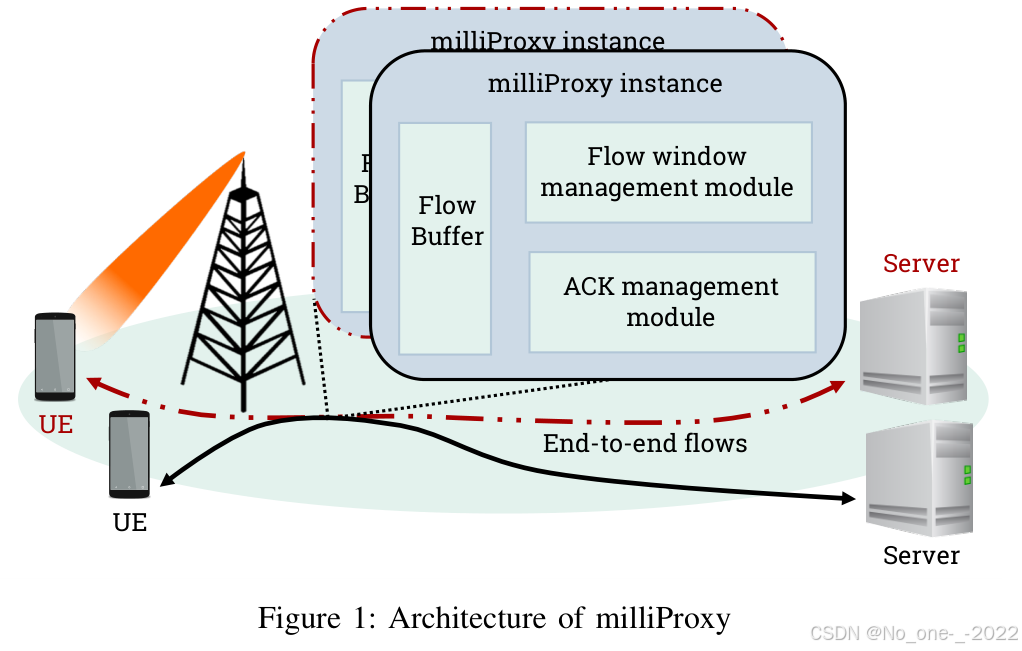
图 1:milliProxy 的架构。
该策略并不硬编码在代理中,而是作为模块加载,这类似于 Linux 内核中 TCP 拥塞控制机制的实现方式 26。代理的 ACK 管理单元会修改每个转发给服务器的 ACK 中的通告窗口(advertised window),从而在 TCP 发送端也强制执行代理的流窗口值。根据 27,TCP 发送端会在其拥塞窗口和收到的通告窗口值之间取最小值,作为可发送的最大字节数。与 10 类似,milliProxy 会把经过其修改的 ACK 中的通告窗口(the advertised window in the modified ACKs)设置为代理计算出的流窗口(the flow window determined at the proxy)。这样,端到端路径中的两个部分都能被纳入控制并分别适配:有线/核心网部分仍由所选的经典 TCP 拥塞控制算法调节;毫米波无线部分则由代理利用跨层信息进行控制,代理通过选择合适的通告窗口值来约束服务器向无线链路注入的数据量。
缓冲区的存在使得可以将代理到 UE 之间连接的 MSS 设置为不同于连接另一部分的 MSS,从而支持进一步优化。如果整个连接的 MSS 受某些中间网络的最大传输单元(Maximum Transmission Unit, MTU)限制,而这些中间网络使用以太网作为链路层技术,也就是 MSS 至多为 1460 字节,那么代理会缓存 1460 字节载荷,并可以发送一个更大的段,将端到端连接中的多个载荷聚合起来。例如,在很短时间内连续收到的 14 个 1460 字节载荷(fourteen 1460-bytes payloads received back-to-back in a small time interval),可以合并成一个 20440 字节的段,并由代理发送给 UE。这会提高连接最后一英里,也就是毫米波无线链路中的传输效率。原因是 TCP/IP 首部开销更小,在上述例子中只使用一个 TCP/IP 首部而不是 14 个;同时 UE 发送 ACK 所需调度的上行资源也更少(fewer uplink resources) 28。注意,在极高带宽连接中,RLC 和 MAC 层(at the RLC and MAC layers of very high-bandwidth connections)通常也会执行聚合以提高传输效率 29, 30;更大的 MSS 也有助于这一过程,因为发送端和接收端需要的拼接与分段操作更少(fewer concatenation and segmentation operations are required)。
注:
- RLC/MAC 层聚合(aggregation/concatenation) 在高带宽无线链路中,如果上层不断交给 RLC/MAC 很多小数据块,低层通常会把多个小块拼进一个更大的无线传输单元中,以减少头部、调度和控制开销。
- 分段(segmentation) 是相反方向的操作:如果上层交下来的数据块太大,超过当前无线传输块能承载的大小,RLC/MAC 需要把它切成多个片段发送。因此,更大的 MSS 不必然减少分段;它是否减少分段,取决于当时无线调度块或 RLC/MAC 可承载数据单元的大小。
- 为什么更大的 MSS 有帮助。 如果 TCP MSS 很小,例如 1460 字节,RLC/MAC 层会看到大量小 TCP 段,并频繁做拼接;如果 milliProxy 已经把多个 payload 聚合成较大的 TCP 段,向下交给 RLC/MAC 的数据单元就更少、更大,更适合高带宽毫米波链路传输。它不是取消 RLC/MAC 层聚合,而是让低层少做碎片化的小块处理。
- 对原句的严格理解。 "更少的拼接与分段操作"更稳妥地说,应理解为更大的 MSS 减少了低层需要处理的上层数据单元数量,因此通常能减少拼接相关开销;至于分段操作是否减少,则依赖无线链路状态和调度粒度。在高带宽毫米波链路中,如果调度块足够大,较大的 MSS 才更可能同时减少拼接和分段相关处理。
- MSS 并不是越大越好。 如果 MSS 过大,当前无线调度块装不下,RLC/MAC 仍然需要把它切成多个片段;一旦发生丢包或重传,还可能增加头阻塞和恢复成本。本文强调的是在毫米波高带宽场景下,适当增大 proxy-UE 段的 MSS,通常可以减少小包处理和 ACK 开销。
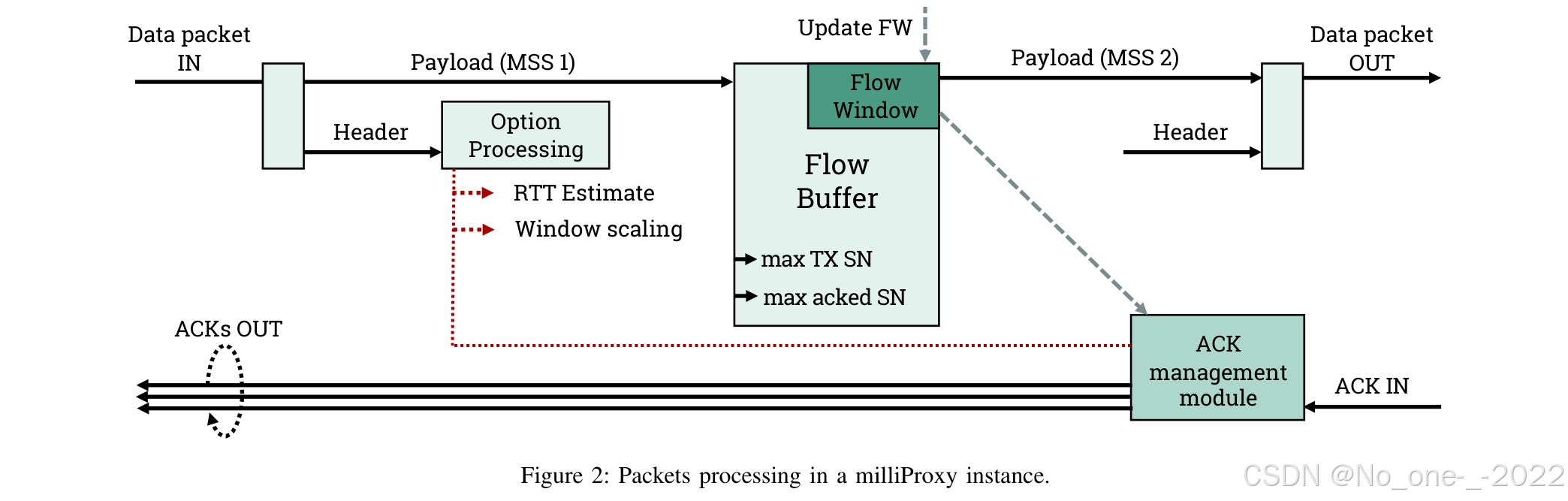
图 2:milliProxy 实例中的分组处理过程。
图 2 展示了分组如何被 milliProxy 处理。按照设计,milliProxy 对 UE,也就是 TCP 接收端完全透明。它会拦截它所处理的流中的所有分组,并将数据分组的载荷(the payload of data packets)存储在代理缓冲区中(the proxy buffer)。分组首部中的任何选项都会被处理,例如用于估计 RTT(下文会描述)或处理通告窗口缩放(handle the advertised window scaling)。只要流窗口允许,载荷就会作为更大段的一部分发送出去。当收到 ACK 时,代理检查其序列号,并将缓冲区中对应字节标记为已接收,随后这些字节会被丢弃,从而允许流窗口前移。因此,代理会向 TCP 发送端发送与原始收到分组数量相对应的若干 ACK;该数量近似等于代理到 UE 连接的 MSS 与服务器到代理连接的 MSS 之比。在每个 ACK 中,通告窗口值都会被覆盖为代理中的流窗口值。
注:
- TCP header options。 这里的 "options" 指 TCP 首部中的可选控制字段,不是应用数据 payload。milliProxy 处理这些字段,是为了正确理解连接状态并修改后续 ACK。
- RTT 估计。 如果 TCP 报文携带 timestamp option,milliProxy 可以读取其中的时间戳字段,例如 T S v a l TS_{\mathrm{val}} TSval 和 T S e c h o TS_{\mathrm{echo}} TSecho,用来估计路径时延。后文的 RTT estimation 小节会展开这一点。
- 通告窗口缩放(advertised window scaling)。 TCP 首部中的窗口字段本身只有 16 bit,在高带宽网络中通常需要 window scaling option 才能表示更大的接收窗口。由于 milliProxy 会把 ACK 中的通告窗口改成自己的流窗口,它必须知道缩放因子,否则服务器可能会把窗口值解释错。
- max TX SN 与 max acked SN。 图中的 SN 是 sequence number,即 TCP 序列号。
max TX SN可以理解为代理已经向 UE 发出的最高序列号,max acked SN可以理解为 UE 已经通过 ACK 确认收到的最高序列号。milliProxy 用这两个边界判断 buffer 中哪些数据已经发送、哪些已经被接收端确认;已经确认的数据可以从 buffer 中清除,尚未确认的数据则需要继续保留。- ACK 方向处理。 UE 返回的 ACK 进入 ACK management module 后,代理会根据 ACK 序列号更新
max acked SN,清除 Flow Buffer 中已确认的数据,并把要转发给服务器的 ACK 中的 advertised window 改成当前 Flow Window。这里说"允许 flow window 前移"更准确地说,是 ACK 释放了已确认数据占用的发送空间,使允许发送的序列号区间沿 TCP 序列号方向向后滑动;这不等于窗口大小一定变大。服务器收到修改后的 ACK 后,实际可发送量仍受 min ( c w n d , a d v e r t i s e d w i n d o w ) \min(\mathrm{cwnd},\ \mathrm{advertised\ window}) min(cwnd, advertised window) 限制,因此 milliProxy 可以通过通告窗口间接控制服务器继续向无线侧注入多少数据。- Update FW。 图 2 上方的 "Update FW" 表示更新 Flow Window,而不是一个 TCP 标准字段或数据包。milliProxy 会根据当前无线侧和连接状态重新计算允许从 Flow Buffer 发往 UE 的数据量;可能使用的信息包括 RTT 估计、RLC 缓冲区占用量、PHY 层估计速率、UE 链路状态,以及 ACK 返回后释放出的窗口空间。后文 Window Management 小节给出的示例策略是基于 BDP 计算 w = ⌊ R T T min R e ⌋ w=\lfloor \mathrm{RTT}{\min}R_e\rfloor w=⌊RTTminRe⌋,当 RLC 缓冲区占用量 B B B 较大时再使用 w = max { ⌊ R T T min R e ⌋ − 2 B , 0 } w=\max\{\lfloor \mathrm{RTT}{\min}R_e\rfloor-2B,0\} w=max{⌊RTTminRe⌋−2B,0} 变得更保守。可以把 Update FW 理解为 milliProxy 的"无线侧限速器更新动作"。
B. RTT 估计
RTT 可以使用 TCP 时间戳选项 31 进行估计。该选项是对称的,即 TCP 发送端的数据分组和接收端的 ACK 中都会添加该选项。它总长度为 10 字节,包含两个时间戳。第一个时间戳 T S v a l TS_{\mathrm{val}} TSval 是发送该分组的端主机时钟值;第二个时间戳 T S e c h o TS_{\mathrm{echo}} TSecho 是最近从另一个端主机收到的分组中的 T S v a l TS_{\mathrm{val}} TSval。为提升 TCP 在吞吐量和安全性方面的性能,31 建议使用该选项。
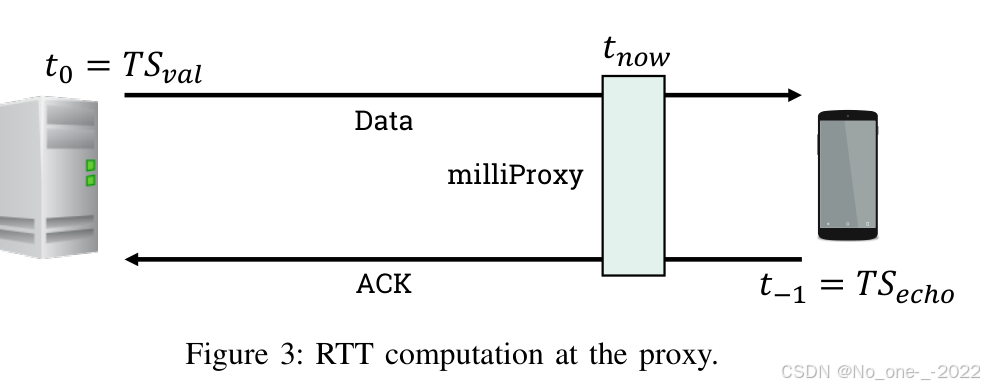
图 3:代理处的 RTT 计算。
如果两个端主机共享同一时钟,则 RTT 估计由以下两个阶段组成:
- 阶段 1:估计 UE 到服务器的上行路径时延。 如图 3 所示,milliProxy 实例先估计从 UE 到服务器路径上的时延。服务器发送给 UE 的数据分组中,时间戳 T S e c h o TS_{\mathrm{echo}} TSecho 对应于 UE 发送 ACK 的时间 t − 1 t_{-1} t−1;同一分组中的 T S v a l TS_{\mathrm{val}} TSval 对应于服务器发送该数据分组的时间 t 0 t_0 t0。由于毫米波网络可以支持非常高的分组速率,服务器在接收与 T S e c h o TS_{\mathrm{echo}} TSecho 对应的 ACK 之后,通常很快就会发送携带 T S v a l TS_{\mathrm{val}} TSval 的下一个数据分组,因此二者之间的等待时间可以忽略。于是,上行路径时延可估计为 T U E → s e r v e r = t 0 − t − 1 T_{\mathrm{UE}\to\mathrm{server}} = t_0 - t_{-1} TUE→server=t0−t−1。
- 阶段 2:估计服务器到 UE 的下行路径时延。 类似地,可以利用 ACK 分组携带的时间戳值估计下行路径时延 T s e r v e r → U E T_{\mathrm{server}\to\mathrm{UE}} Tserver→UE。
最后,将两个方向的路径时延相加,得到估计 RTT:
R T T e = T s e r v e r → U E + T U E → s e r v e r . \mathrm{RTT}e = T{\mathrm{server}\to\mathrm{UE}} + T_{\mathrm{UE}\to\mathrm{server}}. RTTe=Tserver→UE+TUE→server.
注:
阶段 1 估计式的适用条件。 更完整地写,服务器侧看到的时间差并不总是纯粹的上行路径时延,而应表示为:
t 0 − t − 1 = T U E → s e r v e r + T s e r v e r w a i t i n g t_0 - t_{-1} = T_{\mathrm{UE}\to\mathrm{server}} + T_{\mathrm{server\ waiting}} t0−t−1=TUE→server+Tserver waiting
其中, t − 1 t_{-1} t−1 是 UE 发送 ACK 的时间; t 0 t_0 t0 是服务器发送后续 data 包的时间; T U E → s e r v e r T_{\mathrm{UE}\to\mathrm{server}} TUE→server 是 ACK 从 UE 到服务器的真实上行路径时延; T s e r v e r w a i t i n g T_{\mathrm{server\ waiting}} Tserver waiting 是服务器收到 ACK 之后,到真正发送下一个 data 包之间的等待时间。
论文将 T U E → s e r v e r T_{\mathrm{UE}\to\mathrm{server}} TUE→server 近似为 t 0 − t − 1 t_0 - t_{-1} t0−t−1,隐含前提是毫米波高带宽场景下分组发送速率很高,服务器收到 ACK 后几乎立刻发送下一个数据包,即 T s e r v e r w a i t i n g ≈ 0 T_{\mathrm{server\ waiting}} \approx 0 Tserver waiting≈0。如果服务器应用层暂时没有数据、TCP 流是短流/突发流,或者发送端受到 pacing、调度、发送缓存等因素影响,那么 t 0 − t − 1 t_0 - t_{-1} t0−t−1 会混入服务器等待时间,从而高估真实上行路径时延。
如果两个端主机没有共享同一时钟,或者不支持 TCP 时间戳选项,则可以使用 32 中报告的其他方法来估计 RTT。
C. 与 5G 协议栈的集成
代理被配置为从所连接的 5G gNB 收集一些统计信息。根据代理的位置,数据收集可以有时延,也可以无时延:
- 如果代理安装在 gNB 中,则信息可以即时获取;
- 如果它位于核心网或边缘网中的某个节点,则需要一些信令,这会引入额外时延。
借助这些信息,可以启用跨层方法,这对于设计由毫米波链路性能和统计信息驱动的流窗口管理算法很有用。
还可以从 gNB 的协议栈中获取与每个用户相关的更多信息。
-
第一项是 RLC 缓冲区占用量 B B B,它可以被视为拥塞事件及相应时延增加的信号。
-
第二项是 UE 与 gNB 之间 PHY 层数据速率的估计值。
- 在 18 中,该速率通过测量之前若干时隙中传输的字节数并除以时隙持续时间来得到。然而,这种方法对 TCP 源注入网络的实际速率很敏感;如果源速率没有饱和连接,就可能低估可用速率。这一限制在毫米波网络中尤其相关,因为 TCP 源需要很长时间才能充分利用可用资源。
- 相反,在我们之前的工作 10, 33 中,我们依赖 MAC 层自适应调制编码(Adaptive Modulation and Coding, AMC)模块提供的信息。已知某个 UE 的信道质量后,可以计算调制与编码方案,预测调度器在下一个时隙中可为该用户分配多少字节(with full buffer assumption,假设满缓冲),再除以时隙持续时间,从而得到不受源速率影响的可达数据速率 R e R_e Re。
-
跨层设置中还可以获取另一个有用指标,即 UE 的 SINR,它可用于指示链路状态。例如,如果 SINR 低于某个阈值,代理就会知道 UE 处于中断状态。
注:
with full buffer assumption,假设满缓冲。 这里并不是说 UE 或 gNB 的 RLC 缓冲区真的已经满了,而是为了估计可达速率而采用的理想化条件:假设该 UE 的发送队列中始终有足够多的数据等待发送,因此无线链路一旦有可用资源,就一定能被数据填满。
在这个假设下, R e R_e Re 衡量的是当前信道质量、MCS 和调度资源所能支持的无线侧最大可达速率,而不是 TCP 源端当前实际注入网络的速率。这样可以避免因为 TCP 源尚未打满链路而低估 UE 与 gNB 之间的可用速率。
D. 窗口管理
流窗口管理是 milliProxy 的核心组成部分。本文提出一种基于带宽时延积(Bandwidth-Delay Product, BDP)计算的方案。其他 FW 管理策略的实现和测试留作未来工作。
在基于 BDP 的方案中,FW 管理模块使用三类跨层数据:RLC 缓冲区占用量 B B B、估计数据速率 R e R_e Re 和估计 RTT R T T e \mathrm{RTT}_e RTTe。其中 R T T e \mathrm{RTT}e RTTe 会被滤波,并按照 10, 33-35 的方法选择最小值 R T T min \mathrm{RTT}{\min} RTTmin,这样 RLC 层或中间缓冲区中的排队时延就不会被计入。随后流窗口计算为:
w = ⌊ R T T min R e ⌋ . w = \lfloor \mathrm{RTT}_{\min} R_e \rfloor. w=⌊RTTminRe⌋.
注:
R T T e \mathrm{RTT}_e RTTe 会被滤波。 这里的滤波不是物理层的信号滤波,而是对连续测得的 RTT 估计值做平滑或筛选,避免一次性的 ACK 抖动、调度波动或瞬时排队时延直接影响流窗口计算。
R T T min \mathrm{RTT}_{\min} RTTmin 的范围。 按前文 RTT estimation 小节的定义, R T T e = T s e r v e r → U E + T U E → s e r v e r \mathrm{RTT}e = T{\mathrm{server}\to\mathrm{UE}} + T_{\mathrm{UE}\to\mathrm{server}} RTTe=Tserver→UE+TUE→server,因此这里的 R T T min \mathrm{RTT}_{\min} RTTmin 更准确地说是 server 与 UE 之间的基线端到端 RTT,而不是只包含 UE 与 gNB 之间无线一跳的 RTT。它与无线侧可达速率 R e R_e Re 共同构成一个基于 BDP 的流窗口估计。
为什么选择最小 RTT。 当前测得的端到端 RTT 可能已经包含 RLC 队列或中间节点缓冲区带来的排队时延。如果直接用变大的 RTT 计算 BDP,窗口 w w w 也会变大,可能继续向无线侧注入更多数据并加重排队。因此论文取滤波后的最小 RTT,尽量用"没有明显排队时"的基线 RTT 来计算窗口。
当 RTT 估计尚不可用时,也就是在接收 SYN 分组后的第一个 ACK 中,流窗口被任意初始化为一个较大的值 400 MB。此外,当 RLC 缓冲区占用量超过预定义值(例如 2 MB)时,可以使该策略更保守。在这种情况下,流窗口设置为:
w = max { ⌊ R T T min R e ⌋ − 2 B , 0 } . w = \max\{\lfloor \mathrm{RTT}_{\min} R_e \rfloor - 2B,\ 0\}. w=max{⌊RTTminRe⌋−2B, 0}.
注:
原文的 w w w 是一个复用变量。 按论文描述,Flow Window 一方面决定 proxy 何时、能从 Flow Buffer 向 UE 继续转发多少数据;另一方面 ACK management 会把发回 server 的 ACK 中的 advertised window 覆写为这个 Flow Window。因此原文中的 w w w 同时承担了本地无线侧放行窗口和反馈给 TCP sender 的 advertised window 两个角色。这样实现简单,但如果 proxy 部署在 gNB 上,把二者都理解为同一个精确窗口会有概念混淆。
更严谨的两窗口理解。 可以把无线侧本地控制窗口记为 W R A N W_{\mathrm{RAN}} WRAN,它控制 proxy 已经发给 UE 但尚未被 ACK 的数据量,主要由无线侧信息决定,例如 RLC 缓冲区占用量 B R L C B_{\mathrm{RLC}} BRLC、PHY/MAC 估计速率 R e R_e Re、无线侧最小 RTT 或本地 ACK delay。概念上可写为 W R A N = R e T R A N , m i n − α B R L C + W_{\mathrm{RAN}} = R_e T_{\\mathrm{RAN,min}} - \\alpha B_{\\mathrm{RLC}}^+ WRAN=ReTRAN,min−αBRLC+,目标是避免 RLC/PDCP/gNB 侧缓存持续堆积。
另一个窗口可记为 W a d v W_{\mathrm{adv}} Wadv,它是写入 ACK 的 advertised window,用来限制 server 还能向整条路径注入多少未确认数据。server 实际可发送量仍受 min { c w n d s e n d e r , W a d v } \min\{\mathrm{cwnd}{\mathrm{sender}}, W{\mathrm{adv}}\} min{cwndsender,Wadv} 限制。它可以粗略理解为 W a d v ≈ W R A N + Q p r o x y t a r g e t + I f i x e d t a r g e t W_{\mathrm{adv}} \approx W_{\mathrm{RAN}} + Q_{\mathrm{proxy}}^{\mathrm{target}} + I_{\mathrm{fixed}}^{\mathrm{target}} Wadv≈WRAN+Qproxytarget+Ifixedtarget,其中 Q p r o x y t a r g e t Q_{\mathrm{proxy}}^{\mathrm{target}} Qproxytarget 是希望保留在 proxy buffer 中的目标缓存量, I f i x e d t a r g e t I_{\mathrm{fixed}}^{\mathrm{target}} Ifixedtarget 是 server 到 proxy 固定网络路径上可能存在的目标在途数据量。
这里的 RLC 缓冲区不是 milliProxy 的 Flow Buffer。 B B B 表示 gNB 协议栈中 RLC 层的缓冲区占用量,也就是数据已经被 milliProxy 放行到无线接入网侧,但还没有被无线链路及时发送给 UE。它变大通常说明无线侧发送能力跟不上数据注入速度,例如链路质量下降、遮挡进入 NLOS、调度资源不足或无线侧排队增加。
原文公式是 BDP-based 简化策略。 当 B B B 超过预定义阈值(例如 2 MB)时,milliProxy 会把按 BDP 算出的窗口再减去 2 B 2B 2B,减少继续从 Flow Buffer 向无线侧放行的数据量,避免继续把数据推入已经积压的 gNB RLC 队列。这里的 − 2 B -2B −2B 更像启发式惩罚项,系数 2 不是由 BDP 公式严格推导出的物理常数,而是经验性的保守修正;系数太小可能收缩不够快,太大又可能使无线链路利用不足。
控制范围与局限。 如果 milliProxy 部署在 gNB 上,它能直接控制的是从 Flow Buffer 向 gNB/RLC/UE 无线侧继续放行多少数据,并根据 UE 返回的 ACK 更新已确认序列号;它只能通过修改 ACK 中的 advertised window 间接限制服务器未来继续注入多少数据。已经从服务器发出、仍在 server 到 proxy 路上的数据无法被立即撤回,固定网或核心网中的队列以及服务器自身的拥塞窗口 c w n d \mathrm{cwnd} cwnd 也不由 proxy 直接控制。因此,如果用端到端 R T T min \mathrm{RTT}_{\min} RTTmin 和无线速率 R e R_e Re 计算出的同一个 w w w 直接作为无线侧放行窗口,可能偏大;如果只用无线侧 RTT 计算 w w w 并直接写入 advertised window,又可能让 server 发送不足,导致 proxy buffer 供不上高速毫米波链路。原文将二者合并,是一种简化的跨层窗口控制,而不是严格分离无线侧控制和 sender 侧控制。
IV. 性能评估
A. ns-3 毫米波模块
为评估 milliProxy 在端到端场景中的性能,我们在 ns-3 36 中实现了该代理。ns-3 是一个开源网络仿真器,也具有毫米波蜂窝协议栈。37, 38 对毫米波模块进行了完整描述:该模块在 gNB 和 UE 中提供类似 3GPP 的完整协议栈,包括基于动态时分双工(Time Division Duplexing, TDD)方案的自定义 PHY/MAC 层实现,该方案面向低时延通信设计 39;协议栈还包括 RLC、分组数据汇聚协议(Packet Data Convergence Protocol, PDCP)和无线资源控制(Radio Resource Control, RRC)层。信道模型基于 3GPP 面向 6 GHz 以上频率的信道模型 40,并对移动用户计算得到的信道冲激响应之间的时间相关性进行建模,以考虑空间一致性。
B. 场景与参数
主要仿真参数见表 I。本文重点在单用户场景中测试 milliProxy 的性能,以评估代理架构对信道变化的响应能力,尤其是从 LOS 到 NLOS 以及反向变化的响应能力。为对这些变化建模,在仿真场景中随机部署若干障碍物,位置位于 gNB 与 UE 之间。其中 gNB 坐标为 ( 25 , 100 ) m (25, 100)\ \mathrm{m} (25,100) m,UE 从 ( 0 , 0 ) m (0,0)\ \mathrm{m} (0,0) m 以速度 v v v 移动到 ( 50 , 0 ) m (50,0)\ \mathrm{m} (50,0) m。随着用户移动,它会经历多次转换,并且每次仿真运行中每个 LOS 或 NLOS 阶段的持续时间都是随机的。图 4 给出了一个场景示例。所有结果均对 50 次独立仿真运行求平均。
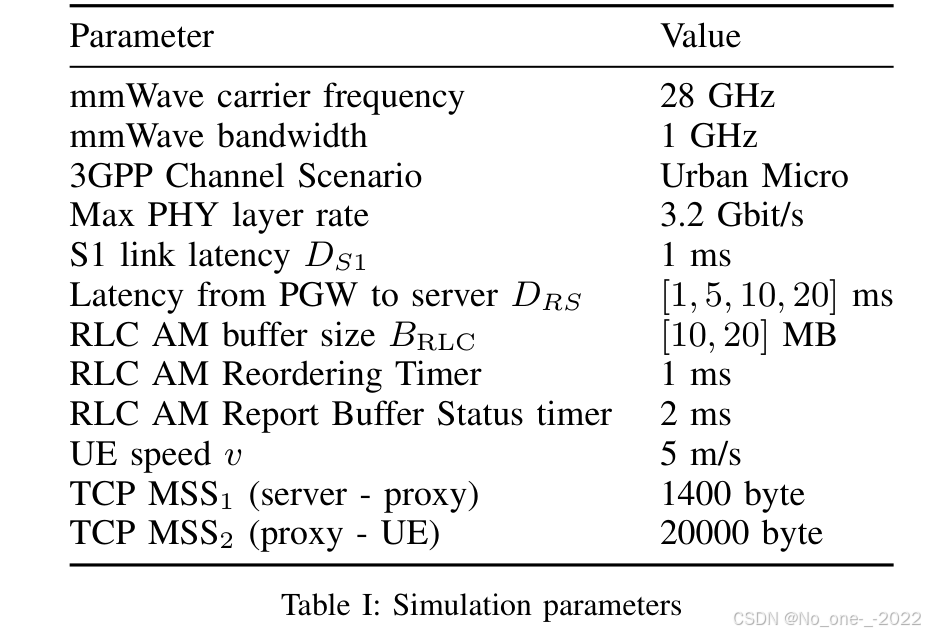
表 I:仿真参数。
图 4:随机生成的仿真场景。三个灰色矩形代表建筑、车辆、树木等障碍物。
C. 结果
图 5 比较了部署和不部署 milliProxy 时的有效吞吐量和 RAN 时延,并考虑不同 RLC 缓冲区大小 B R L C B_{\mathrm{RLC}} BRLC 以及固定网络时延。可以看到,milliProxy 在有效吞吐量和时延方面都表现更好。在最高 D R S D_{\mathrm{RS}} DRS 下,它的有效吞吐量提升最高可达 2.24 倍,同时伴随 1.98 倍的时延降低;在边缘服务器场景中,也就是 D R S = 1 m s D_{\mathrm{RS}}=1\ \mathrm{ms} DRS=1 ms 时,它能在有效吞吐量相近的情况下将时延降低 43 倍。因此,milliProxy 能有效减轻 bufferbloat 问题的影响:当信道从 LOS 状态切换到 NLOS 状态时,milliProxy 可以更快降低 TCP 发送速率,从而避免额外排队时延。另一方面,当信道质量改善时,milliProxy 能够(i)跟踪物理层可用数据速率,并且(ii)及时通知 TCP 发送端资源可用性已经提高,这确实会带来更高的有效吞吐量。milliProxy 的性能与缓冲区大小无关,因为它能够将缓冲区占用量以及相应 RLC 排队时延保持在最低水平。如图 5 所示,并且如 28 中详细讨论的那样,不使用代理的传统方法在使用更大缓冲区时会以更高 RAN 时延为代价获得更高有效吞吐量。
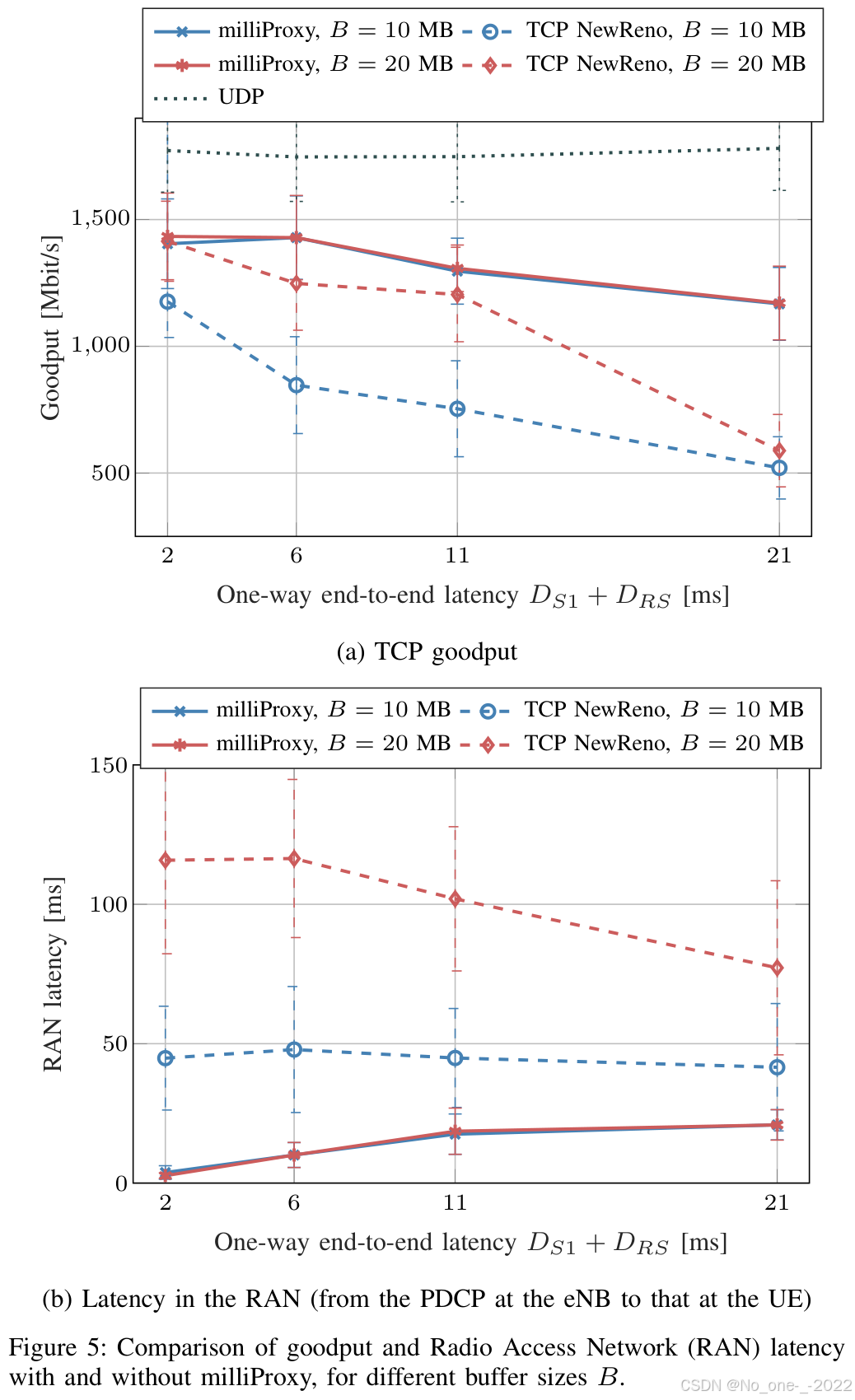
图 5:在不同缓冲区大小 B B B 下,使用与不使用 milliProxy 时的有效吞吐量和无线接入网(RAN)时延比较。
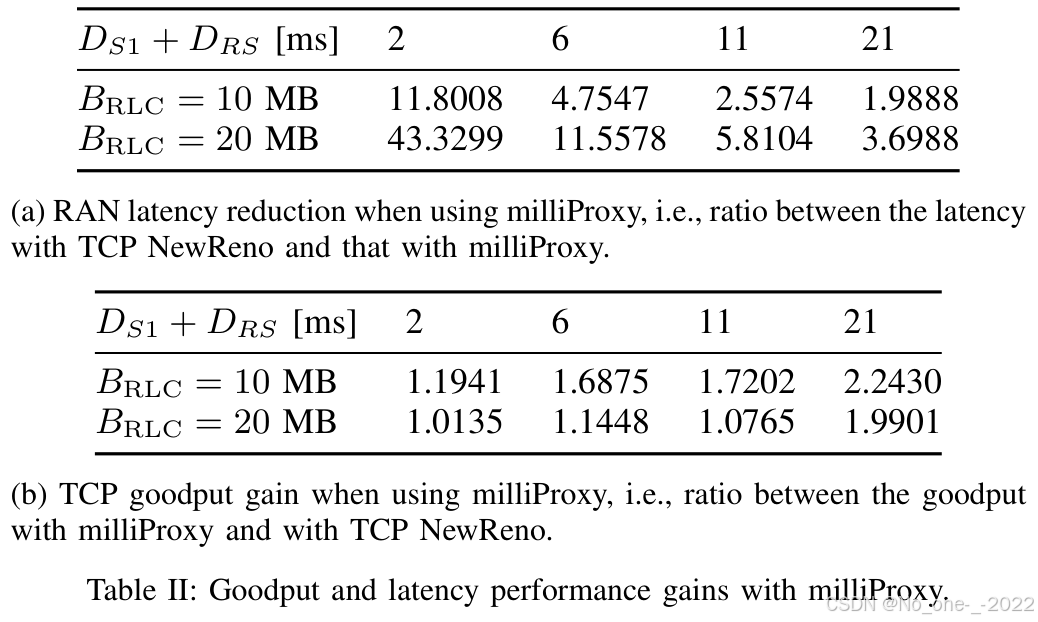
表 II:使用 milliProxy 时的有效吞吐量与时延性能增益。
图 6 比较了 milliProxy 的不同配置选项。我们特别关注有效吞吐量和时延对于跨层信息获取时延 D i n f o D_{\mathrm{info}} Dinfo 的敏感性。若 milliProxy 部署在 gNB 中,则 D i n f o = 0 D_{\mathrm{info}}=0 Dinfo=0;若安装在核心网或边缘网节点中,则 D i n f o > 0 D_{\mathrm{info}}>0 Dinfo>0。我们考虑 D i n f o = 3 m s D_{\mathrm{info}}=3\ \mathrm{ms} Dinfo=3 ms,也就是假设部署在核心网/边缘网中的代理与 gNB 之间的时延小于 3 ms。如图 6 所示,两种测试配置在有效吞吐量和时延方面表现相近,这说明 milliProxy 对部署在边缘网络或 gNB 中的不同可能位置具有鲁棒性。
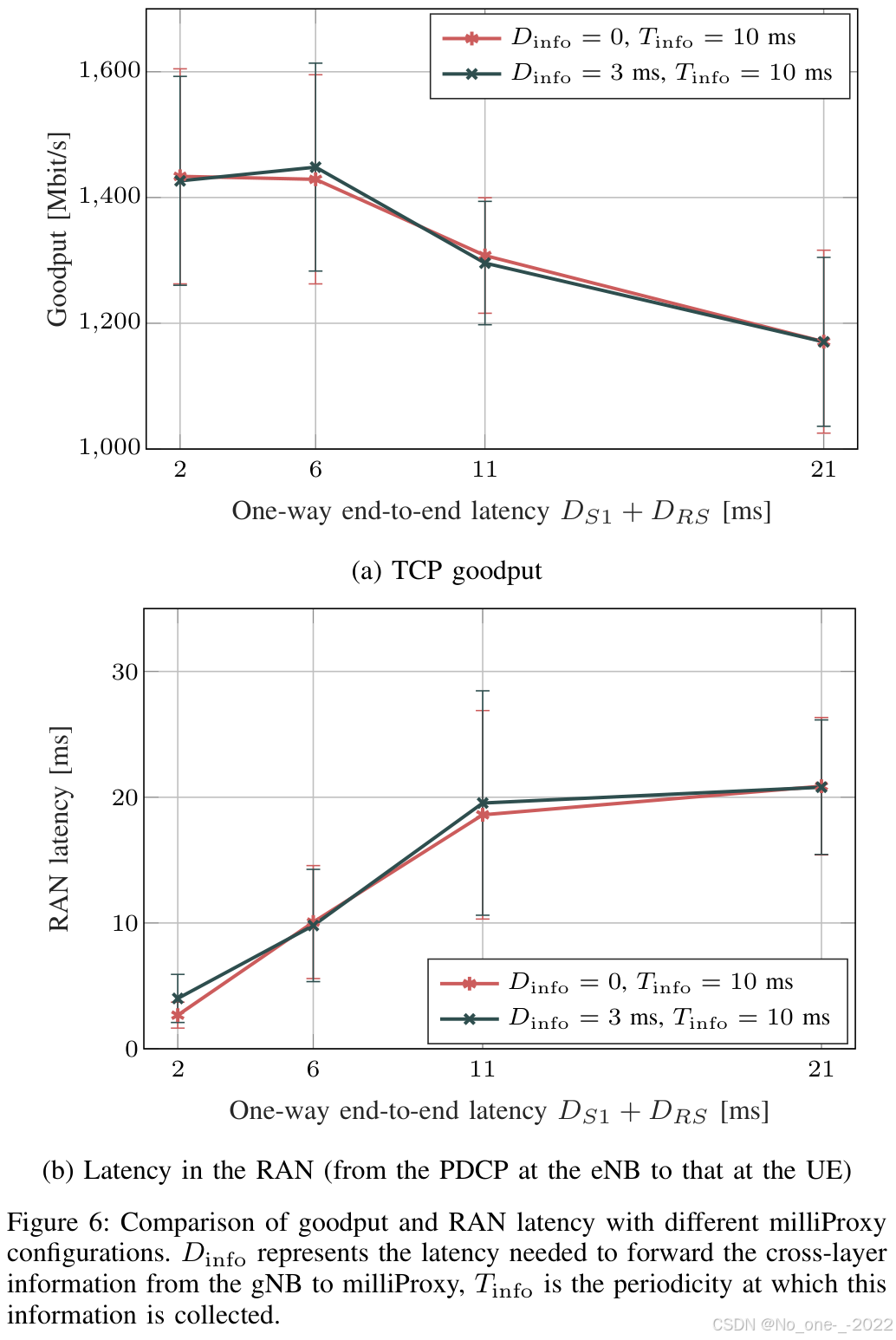
图 6:不同 milliProxy 配置下有效吞吐量和 RAN 时延的比较。 D i n f o D_{\mathrm{info}} Dinfo 表示将跨层信息从 gNB 转发到 milliProxy 所需的时延, T i n f o T_{\mathrm{info}} Tinfo 是采集该信息的周期。
V. 结论
本文介绍了 milliProxy,这是一种旨在提升毫米波蜂窝网络中 TCP 性能的新型代理。我们描述了在毫米波链路上使用 TCP 的主要挑战,以及文献中的主要代理设计。milliProxy 将 TCP 控制环路拆分为两个片段,同时保持 TCP 的端到端语义。它采用模块化设计,使连接的两个部分,也就是有线部分和无线部分,可以使用不同的 MSS 值和流窗口管理算法。窗口控制策略可以受益于 milliProxy 与毫米波网络协议栈之间的交互,从而支持跨层方法。我们展示了基于端到端连接 BDP 的 FW 策略如何相对于传统 TCP NewReno 将时延最多降低 10 倍,或将有效吞吐量最多提升 2 倍,并且该策略对 milliProxy 在网络中的放置位置具有鲁棒性。
milliProxy 是一种在毫米波网络中让 TCP 同时达到高有效吞吐量和低时延的可选方案。作为未来工作的一部分,我们将在 ns-3 中更广泛的场景下测试代理性能,分析多用户场景以及不同流窗口策略下的性能,并考虑在真实系统中实现该方案。