NLP 领域最经典的模型 ------Word2Vec,通过 "猜词游戏",让计算机自己学会每个词的语义,把文字变成有用的数字向量。
计算机天生只会算数字,不会认字。我们说 "苹果"、"香蕉",计算机根本不懂这是什么意思。那怎么让计算机 "看懂" 人类的语言呢?
从最原始的词袋法,到 One-hot 编码,再到 2013 年革命性的 Word2Vec,NLP 领域花了很多年才找到一个好方案。
在 Word2Vec 出现之前,人们用两种办法把文字转成数字:
方法 1:统计词袋模型
最简单的想法:统计每个词在句子里出现几次。
比如有 3 句话:
句子1:我 爱 吃 苹果
句子2:我 爱 吃 香蕉
句子3:苹果 香蕉 都 好吃
就会得到这样的数字表格
| 词 | 句子 1 | 句子 2 | 句子 3 |
|---|---|---|---|
| 我 | 1 | 1 | 0 |
| 爱 | 1 | 1 | 0 |
| 吃 | 1 | 1 | 0 |
| 苹果 | 1 | 0 | 1 |
| 香蕉 | 0 | 1 | 1 |
- "苹果" 和 "香蕉" 都是水果,语义非常接近,但在这个表格里完全是两个无关的东西
- 词越多,列数越多,10000 个词就要 10000 列,计算机跑不动
方法 2:One-hot 独热编码
稍微进步一点:每个词对应一个向量,只有自己的位置是 1,其他都是 0。
我 → 1, 0, 0, 0, 0
爱 → 0, 1, 0, 0, 0
吃 → 0, 0, 1, 0, 0
苹果 → 0, 0, 0, 1, 0
香蕉 → 0, 0, 0, 0, 1
- 5 个词 = 5 维,4960 个词 = 4960 维!维度爆炸
- "苹果" 和 "香蕉" 的向量距离还是很远,完全没有语义关联
词嵌入(Word Embedding)
2013 年 Google 的 Tomas Mikolov 提出了 Word2Vec,彻底改变了这个局面!
把高维的稀疏向量,压缩成低维的稠密向量。
原来(4960维):苹果 → 0,0,0,...,1,...,0
现在(300维):苹果 → 0.12, -0.34, 0.78, 0.21, ...
训练完之后你会发现:向量距离近 = 语义相近!
苹果 向量:0.5, 0.8, 0.1
香蕉 向量:0.48, 0.79, 0.12 ← 和苹果很近!都是水果
我 向量:-0.2, 0.1, -0.5 ← 和水果很远
Word2Vec 的两大训练模型
Word2Vec 有如图两种训练思路
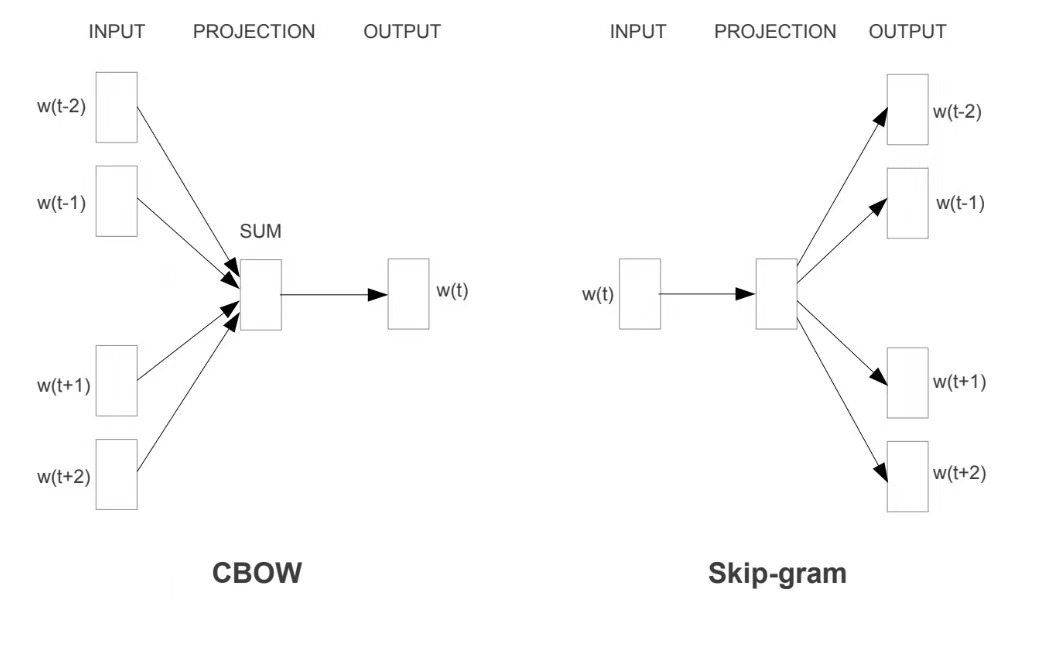
1. CBOW(连续词袋模型)
用上下文的词,来预测中间的词
举个例子,句子:
我 爱 吃 苹果 香蕉
- 给你:
我、爱、苹果、香蕉(前后各 2 个词)- 猜:中间那个词是什么?
- 正确答案:
吃
2. Skip-gram(跳字模型)
用中间的词,来预测上下文的词
还是这个句子:
我 爱 吃 苹果 香蕉
- 给你:
吃(中间那个词)- 猜:它前后应该出现什么词?
- 正确答案:
我、爱、苹果、香蕉
CBOW 神经网络结构详解
CBOW的完整神经网络结构:
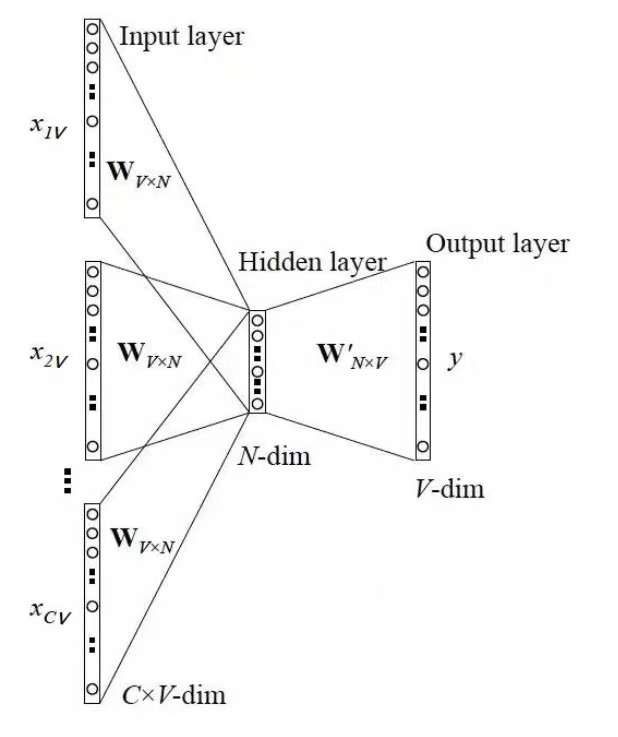
- 输入层:4 个上下文词,每个词是 4960 维的 one-hot 向量
- 隐藏层:300 维(这就是我们最终词向量的维度)
- 输出层:4960 维,对应每个词的概率
假设:词汇量 4960 个,词向量维度 300,上下文 4 个词

**输入:**4个词 × 每个词4960维 = 4×4960 的矩阵 (4 个 one-hot 向量)
乘第一个矩阵 W(4960×300):4×4960 × 4960×300 = 4×300 (每个 one-hot 向量,经过矩阵乘法,变成了 300 维的稠密向量)
**求和取平均:**4个300维向量,加起来除以4 = 1×300 (CBOW 关键的一步:把 4 个上下文词的信息融合成一个向量)
**乘第二个矩阵 W'(300×4960):**1×300 × 300×4960 = 1×4960 (再映射回词汇表大小,每个位置对应一个词的得分。)
第一个矩阵 Wv*N就是我们最终要的词向量。做语义相似度、文本分类、命名实体识别,用的都是这个矩阵里的向量。

W 矩阵是 4960 行 × 300 列:
每一行 = 对应那个词的 300 维词向量
第 1 行 = 第 1 个词的向量
第 2 行 = 第 2 个词的向量
...
第 4960 行 = 第 4960 个词的向量
训练过程中,模型需要一个 "老师" 告诉它:这次猜得准不准,差了多少。这就是损失函数,CBOW 用的是 softmax + 交叉熵损失。
模型最后输出 4960 个数字,每个数字代表一个词的 "得分"。
softmax 把所有得分转成正数(取 e 的 x 次方)并做归一化,让所有得分加起来等于 1,输出的就是每个词的概率。
预测概率 = 0.99(很准) → -log(0.99) ≈ 0.01(损失很小)
预测概率 = 0.01(很烂) → -log(0.01) ≈ 4.6(损失很大)
- 预测越准,损失越小,奖励模型
- 预测越错,损失越大,惩罚模型
模型就是根据这个损失,反过来调整矩阵参数,越猜越准。
CBOW 完整的训练流程:
- 准备输入:把 4 个上下文词转成 one-hot 编码
- 词嵌入:每个词乘矩阵 W,得到各自的 300 维向量
- 信息融合:4 个向量加起来,变成 1 个 300 维向量
- 映射输出:再乘矩阵 W',得到 4960 维的得分
- 概率化:softmax 把得分转成每个词的概率
- 取最大值:概率最大的那个词,就是模型的预测
- 算损失:和真实答案对比,算出这次猜得差了多少
- 反向传播:根据损失调整 W 和 W' 两个矩阵,下次更准
循环往复,训练几百轮,W 矩阵里的词向量就越来越准确。
下面用一段demo来讲解他的实际应用流程
导入库 + 超参数设置
python
import torch # 导入PyTorch核心库
import torch.nn as nn # 神经网络模块
import torch.nn.functional as F # 激活函数等功能
import torch.optim as optim # 优化器
from tqdm import tqdm # 进度条显示
import numpy as np # 数值计算
# 注意:上下文窗口的一半,例如:(前2, 后2)
# 1:就是只取前后各1个词,所以总共有(1+1)个上下文词
CONTEXT_SIZE = 2 # 窗口大小:表示前后各取2个词作为上下文,共4个词文本预处理 + 词表构建
把文字变成计算机能处理的数字。
python
raw_text = """We are about to study the idea of a computational process.
Computational processes are abstract beings that inhabit computers.
As they evolve, processes manipulate other abstract things called data.
The evolution of a process is directed by a pattern of rules called a program.
People create programs to direct processes. In effect,
we conjure the spirits of the computer with our spells.""".split()
vocab = set(raw_text) # 去重得到所有不重复的词
vocab_size = len(vocab) # 词汇表大小
word_to_idx = {word: i for i, word in enumerate(vocab)} # 给每个词分配编号,建立词到索引的映射
idx_to_word = {i: word for i, word in enumerate(vocab)} # 索引到词的映射split() 分词:按空格把长文本切成单词列表,raw_text 变成一个 Python 列表 'We', 'are', 'about', 'to', 'study', ...
set() 去重:自动剔除重复单词,得到词表,len(vocab):统计一共有多少个不同的单词
原文本:"我 爱 吃 苹果 苹果 香蕉"
去重后:{"我", "爱", "吃", "苹果", "香蕉"}
词汇量:5
注:大小写问题,"Process" 和 "process" 会被当成两个不同的词,真实项目中一般会先 .lower() 全部转小写,再去重,set() 是无序的每次运行,单词的顺序可能不一样,真实项目中要固定随机种子,保证每次运行编号一致
字典推导式构建双向映射:
enumerate() 同时拿到 索引 + 元素
python
for i, word in enumerate(["苹果", "香蕉", "我"]):
print(i, word)
# 输出:
# 0 苹果
# 1 香蕉
# 2 我神经网络只能处理数字,必须把词转成编号,词表映射的代码中,我们用到了 字典推导式,遍历所有单词,自动生成 {单词: 编号} 字典
enumerate(vocab):遍历词表,每次取出一组 (索引i, 单词word)
word: i:指定字典的键是单词,值是对应的数字索引
- 训练时用
word_to_idx:把输入的单词转成编号,喂给神经网络 - 预测后用
idx_to_word:把模型输出的编号,转回人类能看懂的单词
进网络用 word_to_idx,出网络用 idx_to_word
构造 CBOW 训练样本
数据准备步骤,我们要用一个滑动窗口,在长句子上滑过去,每个位置都生成一个「用前后 4 个词猜中间 1 个词」的训练样本。
python
data = []
for i in range(CONTEXT_SIZE, len(raw_text) - CONTEXT_SIZE):
context = (
[raw_text[i - j - 1] for j in range(CONTEXT_SIZE)] + # 前面的词
[raw_text[i + j + 1] for j in range(CONTEXT_SIZE)] # 后面的词
)
target = raw_text[i] # 中间的目标词
data.append((context, target))初始化空列表,用来存放所有训练样本,每个样本的格式是:
(上下文词列表, 中心目标词)滑动窗口的起始和结束,为什么不从 0 开始,不从最后结束?
单词位置:0 1 2 3 4 5 6 ... N-3 N-2 N-1
↑ ↑
从这里开始 到这里结束
CONTEXT_SIZE len - CONTEXT_SIZE中心词在位置 0:前面没有 2 个词,取不到
中心词在位置 N-1:后面没有 2 个词,取不
举个例子:
总词数 = 50,CONTEXT_SIZE = 2
遍历范围:
range(2, 48)→ i = 2, 3, 4, ..., 47一共 46 个中心词位置
提取上下文词
取前面的 2 个词,当 CONTEXT_SIZE = 2,j = 0, 1:
j=0 →
i - 0 - 1 = i-1→ 前 1 个词j=1 →
i - 1 - 1 = i-2→ 前 2 个词
结果:[raw_text[i-2], raw_text[i-1]]
取后面的 2 个词,当 CONTEXT_SIZE = 2,j = 0, 1:
j=0 →
i + 0 + 1 = i+1→ 后 1 个词j=1 →
i + 1 + 1 = i+2→ 后 2 个词
结果:[raw_text[i+1], raw_text[i+2]]
当前位置 i 的单词,就是我们要预测的中心目标词 。把 (上下文, 中心词) 这个训练样本,加入数据集。
工具函数 + 设备选择
把单词列表转成 PyTorch 张量(神经网络的输入格式),自动选择最快的计算设备(GPU/CPU)
python
def make_context_vector(context, word_to_idx):
idxs = [word_to_idx[w] for w in context]
return torch.tensor(idxs, dtype=torch.long)
print(make_context_vector(data[0][0], word_to_idx)) # 示例
device = torch.device('cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu')
print(device)神经网络只认数字张量,必须将单词列表先转成数字,再转成 PyTorch 张量
输入 :context = 上下文单词列表,如 ["We", "are", "to", "study"] ,word_to_idx = 词→编号的映射字典
把每个单词转成编号
"We"→0
"are"→1
"to"→3
"study"→4
结果:idxs = [0, 1, 3, 4]
dtype=torch.long:PyTorch 的nn.Embedding层,只接受torch.long类型的索引作为输入。
data[0] = 第一个训练样本
data[0][0] = 第一个样本的上下文单词列表
输出示例:
tensor([26, 46, 20, 22])这就是 4 个上下文词对应的编号张量。
CBOW 模型定义
用 PyTorch 搭建 CBOW 神经网络
python
class CBOW(nn.Module):
def __init__(self, vocab_size, embedding_dim):
super(CBOW, self).__init__()
self.embeddings = nn.Embedding(vocab_size, embedding_dim) # 词嵌入层
self.linear1 = nn.Linear(embedding_dim, 128) # 第一个全连接层
# self.linear1 = nn.Linear((CONTEXT_SIZE * 2 *embedding_dim, 128) # 把所有上下文4个词向量首尾连成长向量
# 如果你需要区分上下文词的位置(比如:左边第一个词、右边第一个词语义权重不同),比如改进型模型、需要学习位置特征时才用拼接;纯基础词向量训练完全没必要。
self.linear2 = nn.Linear(128, vocab_size) # 输出层
def forward(self, inputs):
embeds = self.embeddings(inputs) # [4, 10]
embeds = torch.sum(embeds, dim=0).unsqueeze(0) # [1, 10],标准CBOW
out = F.relu(self.linear1(embeds))
out = self.linear2(out)
log_probs = F.log_softmax(out, dim=1)
return log_probs模型遵循这个固定结构:
python
class 模型名(nn.Module): # 1. 继承nn.Module
def __init__(self, 参数): # 2. __init__:定义网络层
super().__init__() # 必须调用父类初始化
self.层名 = 层定义
def forward(self, 输入): # 3. forward:写前向传播逻辑
数据流动过程
return 输出__init__ 方法:定义网络层
继承和初始化
def __init__(self, vocab_size, embedding_dim):
super(CBOW, self).__init__()vocab_size:词汇表大小(49)embedding_dim:词向量维度(10)super():初始化父类nn.Module
词嵌入层
self.embeddings = nn.Embedding(vocab_size, embedding_dim)这就是训练的词向量矩阵
形状:vocab_size × embedding_dim = 49 × 10
- 每一行 = 一个单词的词向量
- 输入:单词编号(如 26)
- 输出:对应的 10 维词向量
第一个全连接层
self.linear1 = nn.Linear(embedding_dim, 128)形状:10 → 128
- 输入:10 维(求和后的上下文向量)
- 输出:128 维特征
- 做非线性特征提取
拼接法 vs 求和法
python
# 拼接法(维度随窗口变大)
# self.linear1 = nn.Linear(CONTEXT_SIZE * 2 * embedding_dim, 128)
# 4个词 × 10维 = 40维输入
# 求和法(标准CBOW)
self.linear1 = nn.Linear(embedding_dim, 128)
# 4个词求和 = 10维输入,维度固定为什么推荐求和法?
- 维度固定,改窗口大小不用改网络
- 参数少,训练快,不易过拟合
- 符合 CBOW"词袋" 思想,不关心顺序
输出层
self.linear2 = nn.Linear(128, vocab_size)形状:128 → 49
- 输入:128 维特征
- 输出:49 维(每个词的得分)
- 后面接 softmax 转成概率
forward 方法:前向传播
我们一步步看维度变化(参数:4 个上下文词,10 维词向量)
词嵌入
embeds = self.embeddings(inputs) # shape: [4, 10]- 输入:4 个单词的编号
[26, 46, 20, 22] - 输出:4 个 10 维词向量
- 形状:
4 × 10
求和融合
embeds = torch.sum(embeds, dim=0).unsqueeze(0) # shape: [1, 10]torch.sum(embeds, dim=0):4 个向量逐元素相加[4, 10] → [10](4 个 10 维向量加起来变成 1 个 10 维)
.unsqueeze(0):增加 batch 维度[10] → [1, 10](PyTorch 要求必须有 batch 维度)
这就是 CBOW:把 4 个上下文词的信息,融合成 1 个向量
第一层全连接 + 激活
out = F.relu(self.linear1(embeds))[1, 10] → [1, 128],ReLU 激活:把负数变成 0,引入非线性
第二层全连接
out = self.linear2(out)[1, 128] → [1, 49],输出 49 个得分,对应 49 个词
log_softmax
log_probs = F.log_softmax(out, dim=1)log_softmax 对比 softmax ,数值更稳定,避免溢出,和后面的NLLLoss是黄金搭档,数学上等价效果一样,输出每个词的对数概率
维度变化完整流程图
输入: [4] (4个单词编号)
↓
embedding: [4, 10] (4个词向量)
↓
sum + unsqueeze: [1, 10] (融合成1个向量)
↓
linear1 + relu: [1, 128] (特征提取)
↓
linear2: [1, 49] (映射到词汇表)
↓
log_softmax: [1, 49] (每个词的概率)
输出: [1, 49]训练循环
模型真正 "学习" 的过程。通过几百轮的反复训练,让词向量越来越准确。
python
model = CBOW(vocab_size, 10).to(device) # 创建模型,词向量维度=10
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器
loss_function = nn.NLLLoss() # 负对数似然损失
losses = []
for epoch in tqdm(range(200)): # 训练200轮
total_loss = 0
for context, target in data: # 遍历每个训练样本
# 1. 准备数据
context_vector = make_context_vector(context, word_to_idx).to(device)
target = torch.tensor([word_to_idx[target]]).to(device)
# 2. 前向传播:模型预测
train_predict = model(context_vector)
# 3. 计算损失
loss = loss_function(train_predict, target)
# 4. 反向传播 + 参数更新
optimizer.zero_grad() # 清空梯度
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新权重
total_loss += loss.item()
losses.append(total_loss)
# print(losses)
print(f"Epoch {epoch + 1}, Loss: {total_loss:.4f}")
# 拿到预测概率最大的词索引创建模型并移到设备
model = CBOW(vocab_size, 10).to(device)创建 CBOW 模型,词向量维度 = 10,.to(device):把模型参数移到 GPU/CPU,模型和数据必须在同一个设备!
优化器:Adam
optimizer = optim.Adam(model.parameters(), lr=0.001)优化器根据计算出来的梯度,更新模型的参数(就是词向量矩阵)
model.parameters():要更新的所有参数(embedding 矩阵、两个 Linear 层的权重)lr=0.001:学习率,每次更新的步长大小- Adam 是目前最常用、最稳定的优化器
损失函数:NLLLoss
loss_function = nn.NLLLoss()损失函数计算 "模型预测" 和 "真实答案" 之间的差距有多大
NLLLoss = Negative Log Likelihood Loss(负对数似然损失),和前面的log_softmax是黄金搭档,专门用于多分类任务
训练循环外层:轮次(Epoch)
for epoch in tqdm(range(200)):把所有训练样本完整过一遍,叫做 1 轮(Epoch)
训练 200 轮 = 所有样本反复学习 200 次,tqdm():显示进度条,直观看到训练进度,一般训练 100-500 轮,损失下降到平稳就可以停了
训练循环内层:遍历每个样本,每个样本就是:(上下文4个词, 中心词)
准备数据
context_vector = make_context_vector(context, word_to_idx).to(device)
target = torch.tensor([word_to_idx[target]]).to(device)把单词转成张量,并移到设备上:
- 上下文:
[26, 46, 20, 22] - 中心词:
[5](真实答案的编号)
前向传播(模型猜答案)
train_predict = model(context_vector)输入上下文,模型输出每个词的概率:
[0.01, 0.02, ..., 0.56, ..., 0.01]
↑
模型猜是第56个词计算损失,loss 越大 = 猜得越差;loss 越小 = 猜得越准
反向传播
# 1. 清空上一轮的梯度
optimizer.zero_grad()
# 2. 反向传播:计算每个参数的梯度
loss.backward()
# 3. 更新参数:根据梯度调整词向量
optimizer.step()zero_grad():把上次算的梯度清零,不然会累加,backward():从 loss 往回算,每个参数该调大调小,step():真正调整参数(词向量矩阵更新)
累计损失并打印
total_loss += loss.item()loss是张量,.item()取出纯 Python 数字,把这一轮所有样本的损失加起来
losses.append(total_loss)
print(f"Epoch {epoch + 1}, Loss: {total_loss:.4f}")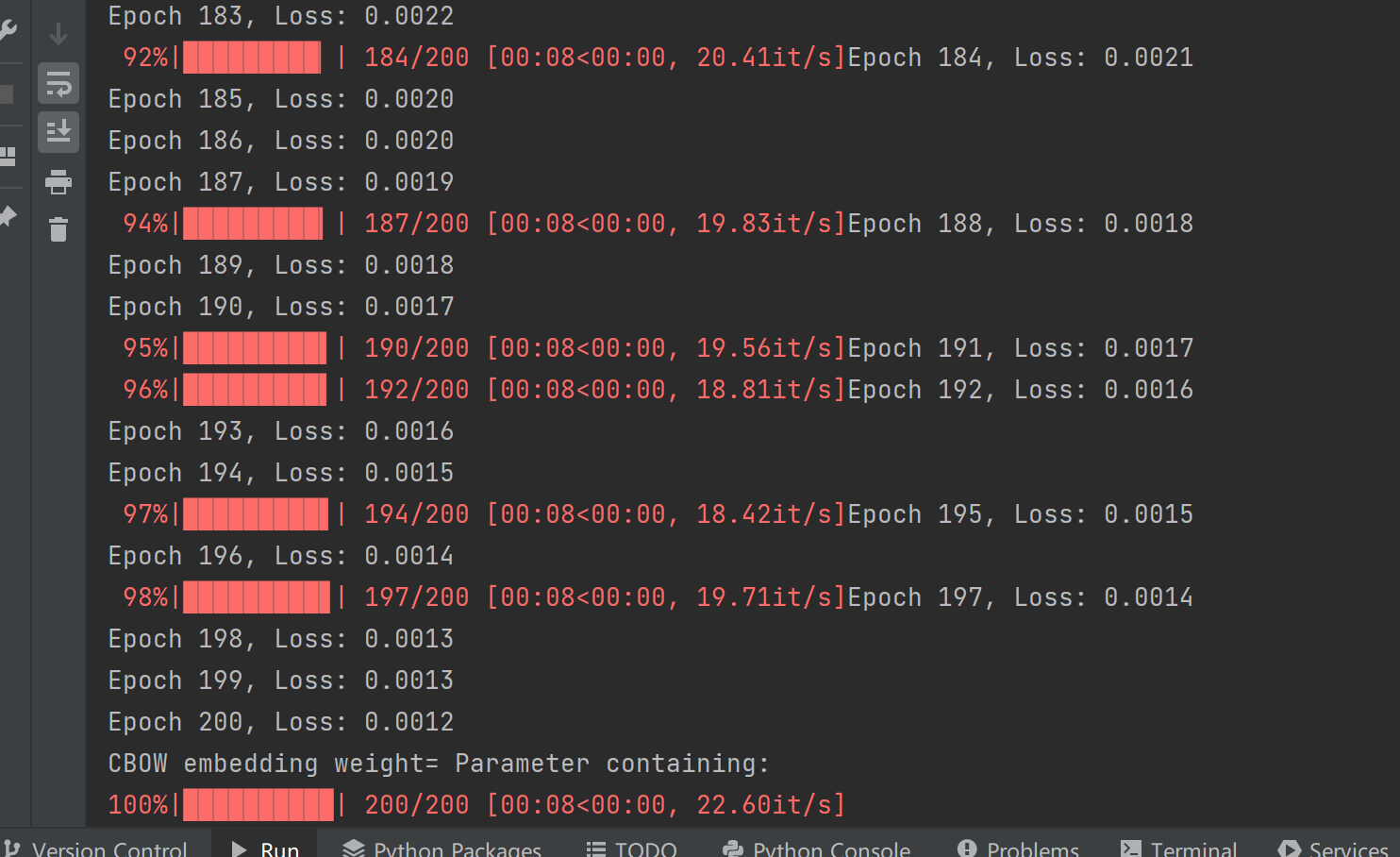
模型测试提取词向量
验证模型效果,并提取最终的词向量
python
# 测试样本上下文
context = ['People', 'create', 'to', 'direct'] # People create programs to direct
context_vector = make_context_vector(context, word_to_idx).to(device)
# 预测部分
model.eval() # 进入测试模式
predict = model(context_vector)
max_idx = predict.argmax(1) # dim=1表示每一行中的最大值对应的索引号,dim=0表示每一列中的最大值对应的索引号
# 获取词向量权重矩阵
print("CBOW embedding weight=", model.embeddings.weight) # GPU
# .detach():断开梯度计算,不参与反向传播;.cpu()移到CPU;转numpy数组
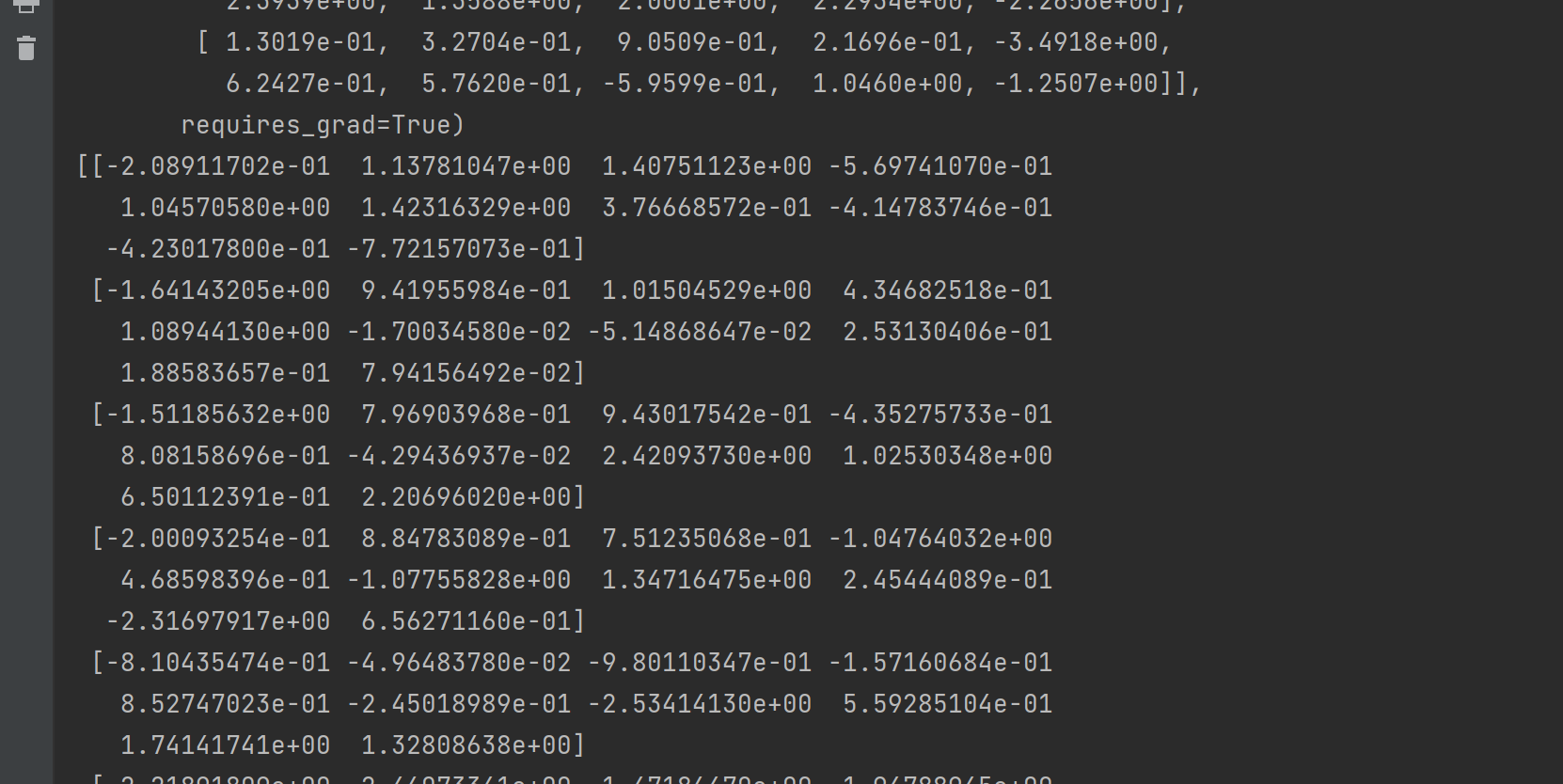
W = model.embeddings.weight.cpu().detach().numpy()
print(W)
# 生成 单词-词向量 字典
word_2_vec = {}
for word in word_to_idx.keys():
# 权重矩阵一行对应一个单词的词向量
word_2_vec[word] = W[word_to_idx[word], :]准备测试数据
context = ['People', 'create', 'to', 'direct']
context_vector = make_context_vector(context, word_to_idx).to(device)我们手动构造一个测试样本:
- 上下文:
People, create, to, direct - 正确的中心词应该是:
programs
原句:People create programs to direct processes
给模型前后 4 个词,看它能不能猜出中间是
programs
切换到测试模式
model.eval()训练模式:Dropout、BatchNorm 等层会生效,测试模式:关闭所有训练专属层,固定参数,推理 / 测试前必须加,否则结果不稳定
模型预测并取最大值
predict = model(context_vector)
max_idx = predict.argmax(1)predict:输出 49 个词的概率分布.argmax(1):取概率最大的那个词的索引dim=1:在 "词" 这个维度取最大值
然后我们可以打印看看:
print("预测的中心词:", idx_to_word[max_idx.item()])如果训练得好,应该输出:programs
提取词向量
W = model.embeddings.weight.cpu().detach().numpy()| 步骤 | 作用 | 少了会怎么样 |
|---|---|---|
.cpu() |
GPU 张量移到 CPU | GPU 张量不能直接转 numpy,报错! |
.detach() |
断开计算图,去掉梯度 | 报错:Can't call numpy () on Tensor that requires grad |
.numpy() |
PyTorch 张量转 numpy 数组 | 还是张量格式,无法保存 |
W 的形状:49 × 10(词汇量 × 词向量维度)
构建词向量字典(方便使用)
word_2_vec = {}
for word in word_to_idx.keys():
word_2_vec[word] = W[word_to_idx[word], :]效果:
word_2_vec["People"] = [0.12, -0.34, ...] # 10维向量
word_2_vec["create"] = [0.56, 0.78, ...]以后用的时候直接:vec = word_2_vec["computer"],非常方便
保存和加载词向量
python
# 将训练好的词向量保存为npz格式(numpy专用存储格式)
np.savez('word2vec实现.npz', file_1=W)
# 读取npz文件
data = np.load('word2vec实现.npz')
# 打印文件内存储的数组名
print(data.files)保存为 npz 格式
np.savez('word2vec实现.npz', file_1=W)
为什么用 npz?
- 压缩存储:体积比 txt 小很多
- 可存多个数组:可以同时存词向量、词表等
- 加载快:二进制格式,比读 txt 快几十倍
- 跨平台:脱离 PyTorch 也能用
加载 npz 文件
data = np.load('word2vec实现.npz')
print(data.files) # 输出:['file_1']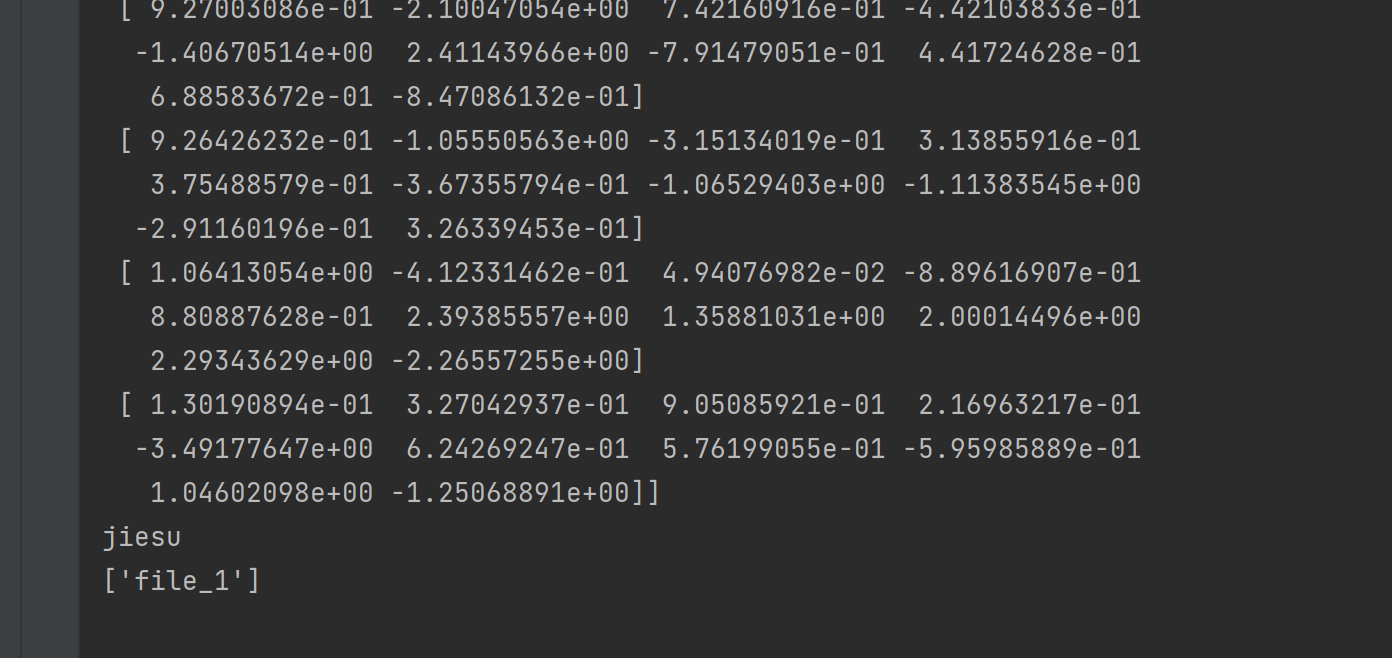
使用:
W_loaded = data['file_1'] # 取出词向量矩阵