PhysX-Anything:从单张图像生成可直接用于仿真的物理3D资产
原文链接:https://arxiv.org/abs/2511.13648
项目主页:https://physx-anything.github.io

图1. 给定单张真实世界图像,PhysX-Anything能够生成细节丰富的物理3D物体,同时恢复其关节结构与物理属性,并导出可直接部署在物理引擎中的URDF和XML文件。
摘要
3D建模正从静态视觉表示向可直接用于仿真与交互的物理化、关节化资产转变。然而,现有的大多数3D生成方法忽略了关键的物理属性与关节特性,从而限制了其在具身智能领域的实用性。为填补这一空白,我们提出了PhysX-Anything------首个可直接用于仿真的物理3D生成框架。该框架仅需单张野外图像作为输入,即可生成高质量、具备显式几何结构、关节特性与物理属性的仿真就绪3D资产。具体而言,我们提出了首个基于视觉语言模型(VLM)的物理3D生成模型,并设计了一种新型3D表示方法,能够高效地对几何信息进行分词。该方法将分词数量减少了193×,使得在标准VLM的分词预算内实现显式几何学习成为可能,且在微调过程中无需引入任何特殊分词,同时显著提升了生成质量。此外,为克服现有物理3D数据集多样性有限的问题,我们构建了全新的PhysX-Mobility数据集。该数据集将现有物理3D数据集的物体类别扩展了2倍以上,包含超过2000个带有丰富物理标注的常见真实世界物体。在PhysX-Mobility数据集与野外图像上的大量实验表明,PhysX-Anything具备优异的生成性能与强大的泛化能力。进一步在类MuJoCo仿真环境中开展的基于仿真的实验验证了我们的仿真就绪资产可直接用于接触密集型机器人策略学习。我们相信PhysX-Anything将为广泛的下游应用,尤其是具身智能与基于物理的仿真领域,提供强有力的支撑。
1. 引言
在机器人、具身智能与交互式仿真等众多下游应用中,对可直接在仿真器中运行的高质量物理3D资产的需求日益增长。然而,现有的大多数3D生成方法要么聚焦于全局3D几何与视觉外观10,12,14,26,28,31,要么专注于建模物体层级与精细结构的部件感知生成30,33。尽管这些方法在视觉效果上表现出色,但生成的资产通常缺乏密度、绝对尺度、关节约束等关键物理与关节信息。这与真实世界应用的需求存在巨大差距,使得这些资产难以直接部署在仿真器或物理引擎中。
与此同时,少量工作开始探索关节化物体的生成11,16,20,21。然而,由于大规模高质量标注3D数据集的稀缺,这类方法大多采用基于检索的范式:它们先检索现有的3D模型,再为其附加合理的运动,而非合成完全新颖的、具备物理依据的资产。因此,这类方法仅能提供有限的关节信息,对野外图像的泛化能力较差,且仍然缺少真实仿真所需的物理属性。尽管已有研究尝试学习3D资产的变形行为7,8,15,17,但它们通常假设物体由均质材料构成,或忽略了部分关键物理属性。即便是能够直接生成物理3D资产的PhysXGen3,也尚未支持在标准仿真器或物理引擎中即插即用式部署25,27,从而限制了其在下游具身智能与控制任务中的实际应用价值。
为弥合合成3D资产与真实下游应用之间的鸿沟,我们提出了PhysX-Anything------首个仿真就绪的物理3D生成范式。如图1所示,仅需单张野外图像作为输入,PhysX-Anything即可生成高质量的仿真就绪3D资产。具体而言,我们引入了首个基于VLM的统一生成模型,能够联合预测几何结构、关节结构与关键物理属性。同时,为解决VLM有限的分词预算与精细3D几何复杂度之间的内在矛盾,我们设计了一种新型3D表示方法,能够高效地对几何信息进行分词。该表示方法将分词数量减少了193×,使得直接学习显式几何结构成为可能,且在微调过程中无需引入特殊分词与新的分词器。基于VLM生成的粗粒度几何,我们进一步开发了可控流Transformer与解码器,用于合成细粒度几何以及对应的URDF与XML结构,最终生成可直接导入标准仿真器的仿真就绪资产。
此外,为显著丰富现有物理3D数据集3的多样性,我们通过收集PartNet-Mobility27中的资产并对其物理属性进行精细标注,构建了全新的PhysX-Mobility数据集。该数据集涵盖47个类别,包含马桶、风扇、相机、咖啡机、订书机等常见真实世界物体,大幅拓宽了物理3D资产的类别覆盖范围。在PhysX-Mobility数据集、野外图像上的综合实验以及用户研究表明,与近期的前沿方法相比,PhysX-Anything实现了更优的生成质量与更强的泛化能力。进一步地,为验证资产在标准仿真器与物理引擎中的可执行性,我们在类MuJoCo仿真器中开展了实验,结果表明我们的仿真就绪资产可直接用于接触密集型任务的机器人策略学习,例如安全操作眼镜等易碎物体。我们相信本工作将为3D生成、具身智能与机器人领域的未来研究开辟新的可能性与方向。
综上,我们的主要贡献如下:
- 我们提出了PhysX-Anything,首个仿真就绪的物理3D生成范式。仅需单张野外图像作为输入,即可生成高质量的仿真就绪3D资产,推动了基于物理的3D内容创作的前沿发展,并为仿真与具身智能领域的下游应用解锁了新的可能性。
- 我们提出了基于VLM的统一生成流水线与新型物理3D表示方法。我们的表示方法在保留显式几何结构的同时实现了高倍率的几何分词压缩,且在微调过程中无需引入任何特殊分词。
- 我们构建了全新的基于物理的3D数据集PhysX-Mobility,将现有物理3D数据集的类别多样性提升了2倍以上,包含超过2000个相机、咖啡机、订书机等常见真实世界物体。
- 通过在PhysX-Mobility数据集与野外图像上的全面评估,我们证明了PhysX-Anything具备优异的生成质量与强大的泛化能力。此外,我们验证了生成的仿真就绪资产可直接部署在仿真环境中,从而赋能具身智能与机器人操作等下游应用。
2. 相关工作
2.1 3D生成模型
作为3D生成领域最早的范式之一,生成对抗网络(GANs)在该领域早期占据核心地位6,13。然而,它们在复杂多样的场景中难以维持稳定且鲁棒的生成性能。随后,DreamFusion22引入了SDS损失,利用2D扩散模型的强大先验实现了令人印象深刻的文本驱动3D生成质量。尽管如此,基于优化的方法仍然存在多面"杰纳斯问题"以及优化效率低下的缺陷。近年来,前馈方法凭借其出色的效率与鲁棒性成为3D生成领域的主流2,4,5,10,14,24,28,29。除了基于扩散的模型外,多项研究将自回归建模引入3D生成领域9,23。受视觉语言模型(VLMs)优异性能的启发,近期的方法开始采用VLMs生成3D资产。为限制分词长度,LLaMA-Mesh26采用了简化的网格表示,MeshLLM12在此基础上构建了"部件-组装"流水线以进一步提升生成质量。与使用简化网格表示不同,ShapeLLM-Omni31采用3D VQ-VAE压缩分词序列长度,但代价是需要引入额外的特殊分词和针对几何的新分词器,这使得训练流程变得复杂。
与现有工作不同,为更好地释放VLMs在3D生成中的潜力,我们提出了一种新型高效表示方法,能够在保留显式结构信息的同时大幅压缩分词序列。此外,我们的方法在微调过程中不引入任何额外的特殊分词,从而避免了对大规模任务特定预训练数据集的需求,也消除了为仿真就绪物理3D生成训练新分词器的开销。
2.2 关节化与物理3D物体生成
关节化物体生成因其广泛的应用场景受到越来越多的关注。现有的大多数方法基于检索范式:它们首先定义一个源库,然后从中检索网格来构建关节化3D资产11,16。其他工作采用图结构表示18,20,将关节化物体的运动学图与扩散模型相结合,实现无纹理的形状生成。然而,这些方法难以鲁棒地泛化到新结构、未见过的类别以及复杂纹理。DreamArt21则尝试从视频生成输出中优化关节化3D物体,但它需要手动标注的部件掩码,且在处理具有大量可动部件的物体时会变得不稳定。URDF-Anything19能够直接生成URDF文件,但它依赖于鲁棒的点云输入,且难以生成3D资产的精细纹理。尽管已有研究尝试学习3D资产的物理变形7,8,15,17,但它们要么将所有物体视为均质材料,要么忽略了部分关键物理属性。为推动3D生成向物理真实性发展,PhysXGen3首次提出了一个统一框架,能够直接生成具备绝对尺寸、密度等关键物理属性的3D资产。尽管其在物理3D生成中表现出良好的性能,但合成资产与现代物理仿真器的要求之间仍存在巨大差距,导致其在下游任务中的直接可用性有限。
为充分发挥合成3D资产的下游应用价值,我们提出了首个3D生成范式,能够从单张真实世界图像生成配备显式物理属性的高质量仿真就绪3D资产。我们在表1中将PhysX-Anything与现有方法进行了对比,结果凸显了我们的方法是唯一同时支持关节化、物理建模、强泛化性与仿真就绪部署的方法。我们相信本方法为利用合成数据赋能相关应用提供了新的方向。
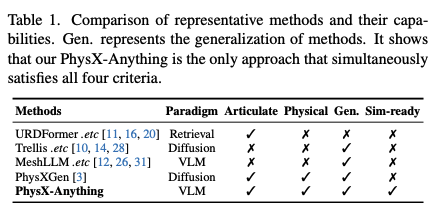
表1. 代表性方法及其能力对比。Gen.表示方法的泛化能力。结果表明,我们提出的PhysX-Anything是唯一同时满足所有四项标准的方法。
3. 方法
在本节中,我们详细介绍PhysX-Anything的整体范式,如图3所示。该方法采用由全局到局部的流水线。具体而言,给定一张真实世界图像,PhysX-Anything通过多轮对话依次生成整体物理描述和每个部件的几何信息。为缓解过长提示导致的上下文遗忘问题,在生成各部件几何信息时,我们仅保留整体信息。也就是说,不同部件的几何描述是基于共享的整体信息独立生成的。最后,通过对物理表示进行解码,PhysX-Anything能够输出六种常用格式的仿真就绪物理3D资产。
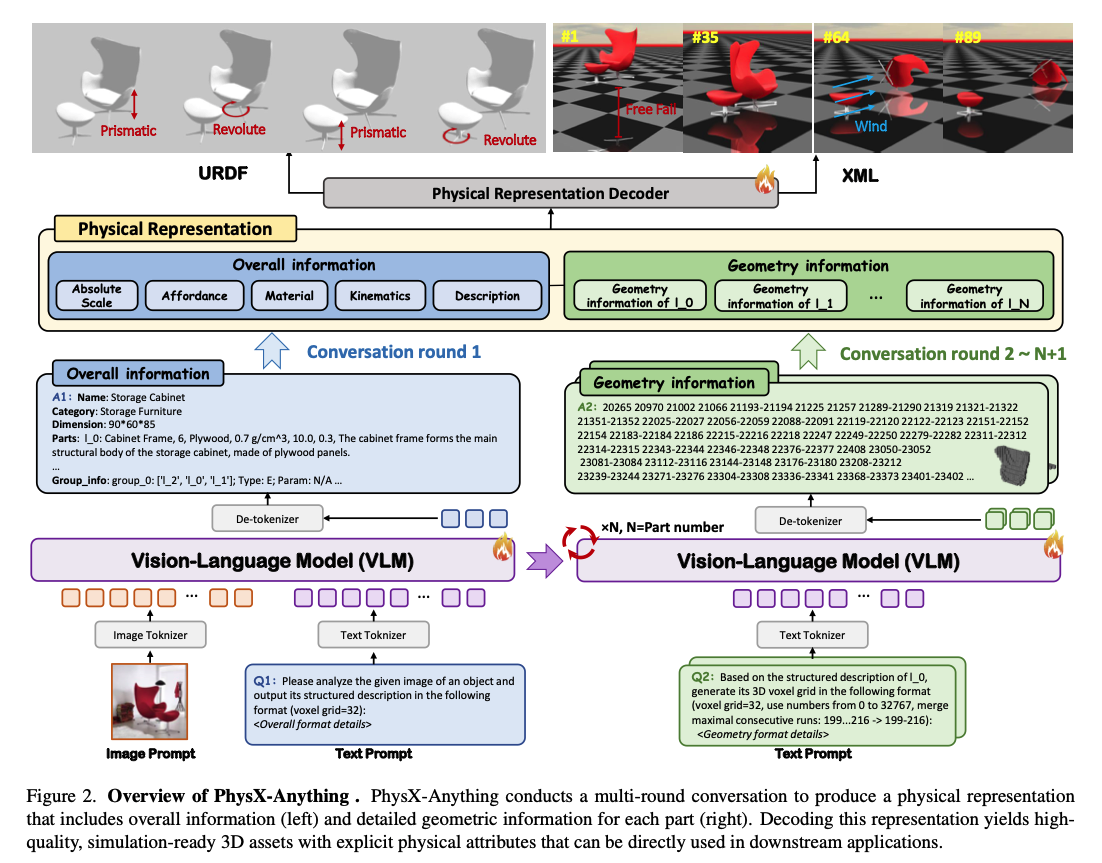
图2. PhysX-Anything整体架构。PhysX-Anything通过多轮对话生成包含整体信息(左)和各部件详细几何信息(右)的物理表示。对该表示进行解码后,可得到高质量、具备显式物理属性的仿真就绪3D资产,能够直接用于下游应用。
图3. 不同表示方法的分词数量对比。通过采用基于体素的表示方法结合专用的合并策略,我们的方法相比原始网格格式将分词数量减少了193×。
3.1 物理表示
此前,为降低基于VLM的框架中原始3D网格的分词长度,大多数3D生成方法12,26采用基于顶点量化的文本序列化表示。然而,由此产生的分词序列仍然过长。尽管3D VQ-GAN31能够进一步压缩几何分词,但它需要在微调过程中引入额外的特殊分词和自定义分词器,这使得训练和部署变得复杂。
为解决这些局限性,我们提出了一种新型3D表示方法,能够在保留显式几何结构的同时大幅降低分词长度,且无需引入任何额外的分词器。受基于体素的表示方法在保真度与效率之间出色权衡的启发28,我们基于体素构建我们的表示方法。然而,直接编码高分辨率体素仍然会产生VLM无法承受的分词数量,即使将几何映射到压缩空间后亦是如此。因此,我们采用由粗到精的策略进行几何建模:VLM在 32 3 32^3 323体素网格上运行以捕获粗粒度几何,而下游解码器将该粗形状细化为高保真几何。通过这种方式,我们既保留了3D体素显式结构的优势,又避免了过度的分词消耗。如图3所示,仅将网格转换为粗体素就将分词数量减少了74×。为进一步消除稀疏体素数据中的冗余,我们将 32 3 32^3 323网格线性化为0到 32 3 − 1 32^3-1 323−1的索引,并仅对被占据的体素进行序列化。最后,通过合并相邻的被占据索引并使用连字符"−"连接连续范围,我们在保持显式几何结构的同时实现了更高的分词压缩率(193×)。
对于整体信息,我们遵循文献3采用树状结构、对VLM友好的表示方法。与标准URDF文件相比,我们的JSON格式提供了更丰富的物理属性和文本描述,从而便于VLM进行理解和推理。此外,为保持运动学结构与几何之间的一致性,我们将关键运动学参数转换到体素空间,包括运动方向、轴位置、运动范围以及相关的关节特性。
3.2 视觉语言模型与物理表示解码器
基于上述物理3D资产的表示方法,我们采用Qwen2.51作为基础模型,并在我们的物理3D数据集上对VLM进行微调。通过定制的多轮对话,PhysX-Anything能够同时生成高质量的全局描述(整体物理与结构属性)和局部信息(部件级几何)。为获得更精细的几何,我们受ControlNet32启发设计了可控流Transformer。在流Transformer架构28的基础上,我们引入了基于Transformer的控制模块,该模块以粗体素表示作为扩散模型的引导,从而指导细粒度体素几何的合成。因此,可控流Transformer的训练目标可表示为:
L g e o = E t , x 0 , ϵ , c , V l o w ∥ f θ ( x t , c , V l o w , t ) − ( ϵ − x 0 ) ∥ 2 2 , (1) \mathcal{L}{geo }=\mathbb{E}{t, x_{0}, \epsilon, c, V^{low }}\left\\left\\\| f_{\\theta}\\left(x_{t}, c, V\^{low }, t\\right)-\\left(\\epsilon-x_{0}\\right)\\right\\\| _{2}\^{2}\\right, \tag{1} Lgeo=Et,x0,ϵ,c,Vlow fθ(xt,c,Vlow,t)−(ϵ−x0) 22,(1)
其中, V l o w V^{low} Vlow、 x 0 x_{0} x0、 ϵ \epsilon ϵ、 c c c、 t t t和 f θ f_{\theta} fθ分别表示粗体素表示、细粒度体素目标、高斯噪声、图像条件、时间步以及由 θ \theta θ参数化的可控流Transformer。带噪声样本 x t x_{t} xt通过在 x 0 x_{0} x0和 ϵ \epsilon ϵ之间插值得到,即 x t = ( 1 − t ) x 0 + t ϵ x_{t}=(1-t) x_{0}+t \epsilon xt=(1−t)x0+tϵ。
给定细粒度体素表示,我们采用预训练的结构化隐扩散模型28生成3D资产,包括网格表面、辐射场和3D高斯。然后,我们应用最近邻算法,基于体素分配将重建的网格分割为部件级组件。最后,通过将全局结构信息与细粒度体素几何相结合,PhysX-Anything能够生成URDF、XML和部件级网格,实现仿真就绪的物理3D生成。
图4. 物理表示解码器的详细结构。给定粗粒度几何,采用可控流Transformer生成细粒度几何信息。随后,格式解码器将整体物理信息与细化后的几何相结合,生成六种不同格式的资产。
4. 实验
在本节中,我们展示了在PhysX-Mobility数据集与野外图像上的实验结果。更多细节请参见补充材料。
4.1 在PhysX-Mobility数据集上的评估
我们将PhysX-Anything与最相关的前沿方法URDFormer11、ArticulateAnything16和PhysXGen3进行了对比。如表2所示,PhysX-Anything在几何与物理两类指标上均持续取得最优性能。得益于VLM强大的先验知识,PhysX-Anything在绝对尺度预测上实现了显著提升(将误差从43.44降至0.30,即相比PhysXGen取得了超过99%的相对改进)。此外,由于VLM本身对文本友好,PhysX-Anything在描述性指标上也获得了最高分,这表明我们的方法不仅能够生成物理上合理的属性,还能生成连贯的部件级文本描述,体现了对物体结构与功能的深刻理解。
表2. 在PhysX-Mobility数据集上与其他方法的定量对比。PhysX-Anything在所有指标上均持续优于所有前沿方法,尤其在物理属性指标上取得了大幅提升。
除定量对比外,我们在图5中进一步展示了定性结果。结果清晰地凸显了PhysX-Anything在泛化能力上的优势,尤其是与基于检索的方法11,16相比。凭借强大的VLM先验与高效的表示方法,PhysX-Anything生成的物理属性也比PhysXGen3更加合理。
图5. PhysX-Mobility测试集上的定性结果。与其他方法相比,PhysX-Anything生成的高质量仿真就绪物理3D资产具备更准确的几何结构、关节特性与物理属性。
4.2 野外评估
基于VLM的评估。为评估在真实世界场景中的泛化能力,我们使用类别关键词从互联网收集了约100张野外图像。这些真实世界图像涵盖了最常见的日常物品类别。为避免VLM对特定物理属性的判断不可靠,我们将基于VLM的评估重点放在几何与关节质量上。如表4所示,PhysX-Anything在几何(VLM评分)与运动学参数(VLM评分)两项指标上的得分均显著高于所有对比方法,表明其对真实输入的泛化能力明显更优。
表3. 野外评估的用户研究结果。野外案例的用户偏好结果表明,PhysX-Anything显著优于其他方法,在几何质量与物理合理性上均取得了明显的提升幅度。
真实图像的用户研究。为补充野外环境下物理属性的VLM评估,我们开展了用户研究,结果总结于表3。每位志愿者在0到5分的范围内对生成结果进行评分,同时考虑几何结构与所有物理属性。我们共收集了14位志愿者的1568份有效评分,并对分数进行了归一化。结果表明,PhysX-Anything的输出与人类偏好的契合度远高于其他方法,证实了其在几何与物理属性两方面均具备鲁棒的生成性能。图6中真实场景的可视化结果进一步凸显了PhysX-Anything相较于其他方法的优越性,在多样且具有挑战性的野外案例中展现出更准确的几何结构、关节特性与物理属性。
图6. 野外图像上的定性结果。给定单张真实世界图像作为输入,PhysX-Anything能够在多样的物体类别上生成具备真实几何结构、关节特性与物理属性的高质量仿真就绪3D资产。此外,结果也凸显了PhysX-Anything强大的泛化能力。
表4. 基于VLM的野外评估结果。来自GPT-5的定量结果也证实了PhysX-Anything在几何与关节特性方面具备优异的生成性能。
4.3 消融研究
为分析我们所提表示方法的有效性,我们针对不同设计开展了消融研究,如图3所示。需要注意的是,原始网格与顶点量化表示所需的分词数量过大,会导致内存不足问题,无法进行端到端训练。因此,我们重点对比了其余三种紧凑表示方法。如表5所示,随着分词压缩率的提高,PhysX-Anything即使对于复杂结构也能捕获完整且精细的几何信息,而其他表示方法受限于分词预算,性能出现明显下降。图7中的定性结果进一步表明,我们的PhysX-Anything对于几何结构具有挑战性的物体能够生成更鲁棒的结果。
表5. 不同表示方法的对比。不同3D表示方法的定量结果清晰地证明了我们提出的表示方法在几何保真度与物理属性两方面均具备优越性。
图7. 不同表示方法的消融研究。我们对比了不同3D表示方法的生成性能,验证了我们提出的表示方法的有效性与效率。
4.4 仿真中的机器人策略学习
为验证我们的方法对下游任务的支撑潜力,我们在类MuJoCo仿真器34中开展了实验,如图8所示。我们生成的仿真就绪3D资产(包括水龙头、橱柜、打火机、眼镜等日常物品)可直接导入仿真器,并用于接触密集型机器人策略学习。该实验不仅证明了我们生成的资产具备高度物理合理的行为与准确的几何结构,还凸显了其在广泛的下游机器人与具身智能应用中赋能与启发新方向的巨大潜力。
图8. 在PhysX-Anything生成的仿真就绪3D资产上进行的机器人操作实验。结果表明,我们生成的仿真就绪资产在多样任务中均表现出高度物理合理的行为与准确的几何结构,为机器人策略学习提供了新的方向。
5. 结论
在本文中,我们旨在通过提出PhysX-Anything------首个仿真就绪的物理3D生成范式,充分释放合成3D资产在真实世界应用中的潜力。通过基于VLM的统一流水线与定制化的3D表示方法,PhysX-Anything在保留显式几何结构的同时实现了大幅分词压缩(超过193×),使得高效且可扩展的物理3D生成成为可能。此外,为丰富现有物理3D数据集的多样性,我们通过精心收集并标注带有丰富物理属性的常见真实世界物体,构建了PhysX-Mobility数据集。该数据集包含47个最常见的真实生活类别,并附有详细的物理属性标注。在PhysX-Mobility数据集与野外场景上的综合实验证明了PhysX-Anything在仿真就绪物理3D生成方面具备优异的性能与强大的泛化能力。进一步地,基于仿真的实验凸显了其在下游机器人策略学习中的应用潜力。我们相信PhysX-Anything将推动3D视觉、具身智能与机器人领域涌现出更多新的研究方向。