DataWhisperer V3:我把一个 Text-to-SQL Demo,继续升级成了带 RAG、Milvus、评测中心和对话式体验的数据分析智能体
项目信息
- GitHub:https://github.com/chenpan979/DataWhisperer
- 当前版本:V3.9.1
- V1 标签:https://github.com/chenpan979/DataWhisperer/releases/tag/v1.0.0
- V2 标签:https://github.com/chenpan979/DataWhisperer/releases/tag/v2.0.0
- V3 标签:建议在 GitHub Releases 中选择最新的
v3.x标签查看 - 项目方向:Text-to-SQL、RAG、Milvus、DashScope Embedding、模型评测、数据分析智能体
前两篇文章里,我记录了 DataWhisperer 的 V1 和 V2。
V1 解决的是:自然语言查数这条链路能不能真正跑通。
V2 解决的是:提示词能不能治理,SQL 出错能不能自动修复,能力有没有基础评测。
到了 V3,我想做的事情变了:不只是让它"能查数",而是让它更像一个真实公司里会出现的数据分析智能体产品。
一、为什么还要继续做 V3?
一个 Text-to-SQL 项目,第一眼看起来好像就是:
text
用户问一句中文
模型生成 SQL
数据库执行查询
返回结果这条链路 V1 已经跑通了。
但真实业务里,问题往往没有这么简单。
比如用户问:
text
最近 6 个月 GMV 趋势怎么样?这里的关键不只是写 SQL,而是系统要知道:
- GMV 到底是什么意思?
- GMV 和销售额是不是一回事?
- 是否包含退款?
- 应该用订单表,还是订单明细表?
- 时间维度按下单时间还是支付时间?
- 用户想看趋势,应该返回折线图还是表格?
如果系统只知道数据库 schema,不知道业务指标口径,生成出来的 SQL 很可能"语法正确,但业务不对"。
这就是 V3 的核心出发点:
DataWhisperer 不能只理解表结构,还要开始理解业务语言。
所以 V3 我主要围绕三个方向升级:
- RAG 指标口径增强:让模型生成 SQL 前,先检索业务指标定义。
- 产品化控制台:把 AI 查数、数据结构、RAG 知识库、测试集管理、评测中心做成完整工作台。
- 可评测、可展示、可迭代:不仅能演示,还能用测试集和评测中心证明能力没有退化。
二、V3 这次最大的变化:从"查表"走向"懂指标"
V1 的输入大概是:
text
数据库表结构 + 用户问题V3 之后,输入变成:
text
数据库表结构 + 检索到的业务指标口径 + 用户问题也就是说,用户问"GMV、客单价、订单数、复购率"这类业务词时,系统会先去知识库里找对应定义,再把定义注入到 SQL 生成 prompt 里。
整体链路变成:
text
用户中文问题
-> 读取 MySQL 表结构
-> 检索业务指标口径
-> 组合 schema + metric context + prompt
-> 生成只读 SQL
-> 安全校验
-> 执行查询
-> 推荐图表
-> 生成分析结论
-> 返回可视化结果这一步看起来只是多了一个"检索",但意义很大。
因为它让系统从一个"会写 SQL 的工具",开始变成一个"知道业务规则的数据分析助手"。
三、RAG 指标口径库:先用 Markdown 管知识,再用向量库做检索
我没有一上来就把知识库做得很复杂,而是先从最稳定、最容易维护的方式开始:用 Markdown 维护指标口径。
目录大概是这样:
text
knowledge/
metrics/
gmv.md
sales_amount.md
avg_order_value.md
order_count.md
repurchase_rate.md每个指标文件里会写清楚:
- 指标名称
- 别名
- 关键词
- 相关表
- 相关字段
- 业务含义
- 计算口径
- SQL 建议
- 注意事项
比如"客单价"可能不只是一个字段,而是:
text
客单价 = 销售额 / 订单数量如果模型不知道这个定义,它可能会去猜一个不存在的 avg_order_value 字段。
但如果先检索到指标口径,再注入 prompt,模型就更容易生成符合业务定义的 SQL。
这里我的设计原则是:
Markdown 是知识源,Milvus 是索引层。
也就是说,真正可维护、可审查的业务定义仍然放在 Markdown 里;Milvus 只是把这些内容向量化后用于检索。
这样做有两个好处:
- 知识源不丢失,人可以直接看、直接改。
- 向量索引可以随时重建,不会变成黑盒数据。
四、从本地检索到 Milvus:一步步增强,而不是一步到位
V3 不是一口气把所有东西都堆上去,而是分阶段做的。
V3.0:本地指标口径库
先把 GMV、销售额、客单价、订单数、复购率这些常见业务指标写成 Markdown。
这个阶段重点不是技术炫技,而是先把"业务知识可以被系统读取"这件事做出来。
V3.1:混合检索
只靠关键词匹配不够。
比如用户可能不会说"客单价",而是说:
text
哪个地区平均每单消费最高?所以我加入了轻量 hybrid retrieval:
- 关键词 / 别名精确命中
- 本地 n-gram 相似度补充召回
这样可以覆盖一部分自然语言的模糊表达。
V3.2:指标检索评测集
检索做出来以后,不能只靠"看起来能用"。
所以我新增了指标检索评测集,用来检查:
- 问题是否命中正确指标
- 是否误召回禁止指标
- 检索报告能否正常序列化
- 同义表达是否能被召回
这也是我觉得大模型项目里很重要的一点:
只要能力会持续迭代,就必须有评测。
V3.3:接入 Milvus 向量数据库
在本地 hybrid 检索稳定以后,我继续接入 Milvus。
Milvus 在这里的作用是:作为指标口径的向量索引层。
当配置为 Milvus 检索时,系统会优先走向量检索;如果 Milvus 没启动、客户端没安装或索引没同步,则可以自动回退到本地检索。
这个兜底非常重要。
因为项目要能演示、能跑测试、能给别人 clone 下来体验,就不能因为一个外部服务没启动而整个系统不可用。
V3.4:DashScope text-embedding-v4
V3.4 继续升级 embedding。
我把指标向量化从本地 hashing 升级为 DashScope 的 text-embedding-v4。
相关配置大概是:
env
DASHSCOPE_API_KEY=你的 DashScope API Key
DASHSCOPE_API_BASE=https://dashscope.aliyuncs.com/compatible-mode/v1
DASHSCOPE_MODEL=qwen-plus
DASHSCOPE_EMBEDDING_MODEL=text-embedding-v4
DASHSCOPE_EMBEDDING_DIMENSION=1024
EMBEDDING_PROVIDER=dashscope
METRIC_RETRIEVAL_PROVIDER=milvus但我仍然保留了本地 hashing 兜底。
原因很简单:工程项目不能只在"配置完美"的环境里运行。
五、V3.5:做一个真正像产品的控制台
V1/V2 的界面更像一个开发者调试台。
到了 V3.5,我开始把它往"公司内部数据智能体产品"的方向做。
控制台被拆成几个工作区:
- AI 查数
- 数据结构
- RAG 知识库
- 测试集管理
- 评测中心
这里我想表达一个想法:
真正的数据分析智能体,不应该只有一个输入框。
它还需要管理数据结构资料、业务知识资料、评测测试集、质量报告和运行结果。
数据结构页面
这个页面用于上传和管理:
- 表结构说明
- 字段说明
- 建表 SQL
- 数据字典
- CSV / JSON / Markdown / TXT / Excel 等资料
当前版本先完成上传、列表、预览、删除。
后续可以继续扩展:
- 自动解析建表 SQL
- 自动补充字段说明
- CSV / Excel 入库
- 和真实 schema 管理打通
RAG 知识库页面
这个页面用于管理:
- 业务口径
- FAQ
- 分析规则
- SQL 样例
- 指标解释文档
现在它先是一个资料管理入口。
后续可以继续接入:
- 自动切片
- embedding
- Milvus 同步
- RAG 检索增强
虽然这一步看起来像"只是做了上传页面",但其实很重要。
因为真实产品里,知识库必须有一个给人维护的入口。否则 RAG 永远停留在开发者手动改文件的阶段。
六、V3.6:让 AI 分析过程更像真实助手
做完资料管理之后,我继续优化 AI 查数体验。
一个数据分析智能体,如果用户点了"运行分析"以后页面什么都不动,会非常没有安全感。
所以 V3.6 我加入了几个体验细节。
1. 分析过程时间线
系统会展示从理解问题到生成结果的完整链路:
text
理解问题
读取数据结构
检索指标口径
生成 SQL
执行查询
生成图表
生成结论默认收起,用户想看时再展开。
这样既不会打扰主结果,又能在需要解释时展示完整过程。
2. 分析结论逐字输出
分析结论不是等全部完成后突然出现,而是像对话助手一样逐步输出。
这个细节可以明显降低等待感。
3. 追问建议
每次分析完成后,系统会生成一些后续问题,例如:
- 看看贡献最高和最低的商品
- 分析某个地区为什么增长
- 对比本月和上月变化
- 继续拆分到品类或商品维度
这让用户不只是得到一个答案,而是被引导继续分析。
4. 图表交互
图表支持悬停查看数据、缩放、保存和点击反馈。
对数据分析产品来说,图表不是装饰,而是用户理解数据的主要入口。
七、V3.7:评测中心,让项目从"能演示"变成"可度量"
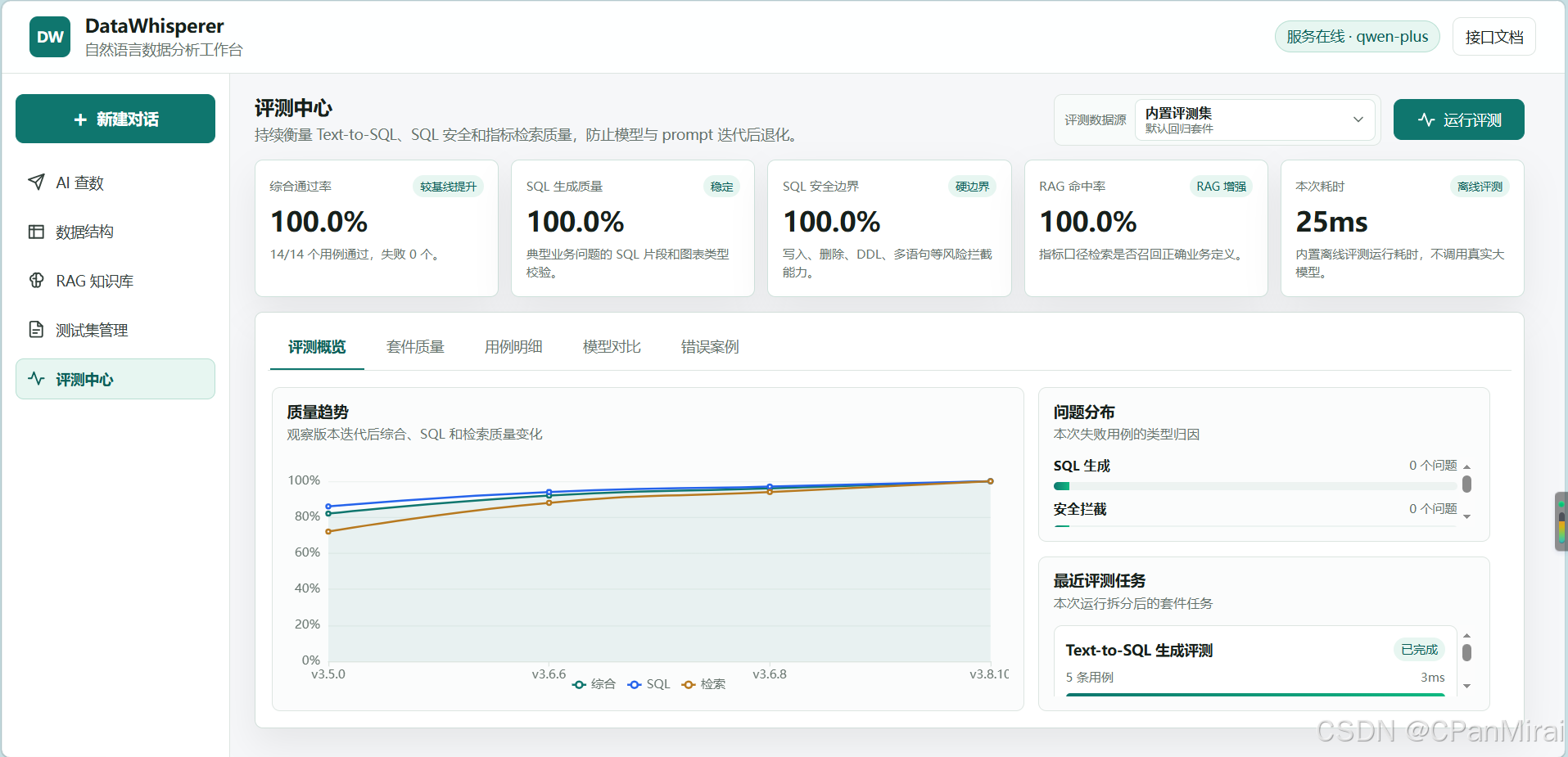
我觉得 V3 里很有价值的一块是评测中心。
因为很多大模型项目看起来都很酷,但很难回答一个问题:
text
你怎么证明它这次改完没有变差?所以我做了一个 Evaluation Center。
它覆盖三类评测:
- Text-to-SQL 生成质量
- SQL 安全边界
- RAG / 指标口径检索命中率
前端会展示:
- 综合通过率
- SQL 生成质量
- SQL 安全边界
- RAG 命中率
- 本次耗时
- 质量趋势
- 问题分布
- 最近评测任务
- 用例明细
- 模型对比
- 错误案例
这部分的意义是:
大模型能力不能只靠感觉,要能被测试、被比较、被追踪。
自定义测试集管理
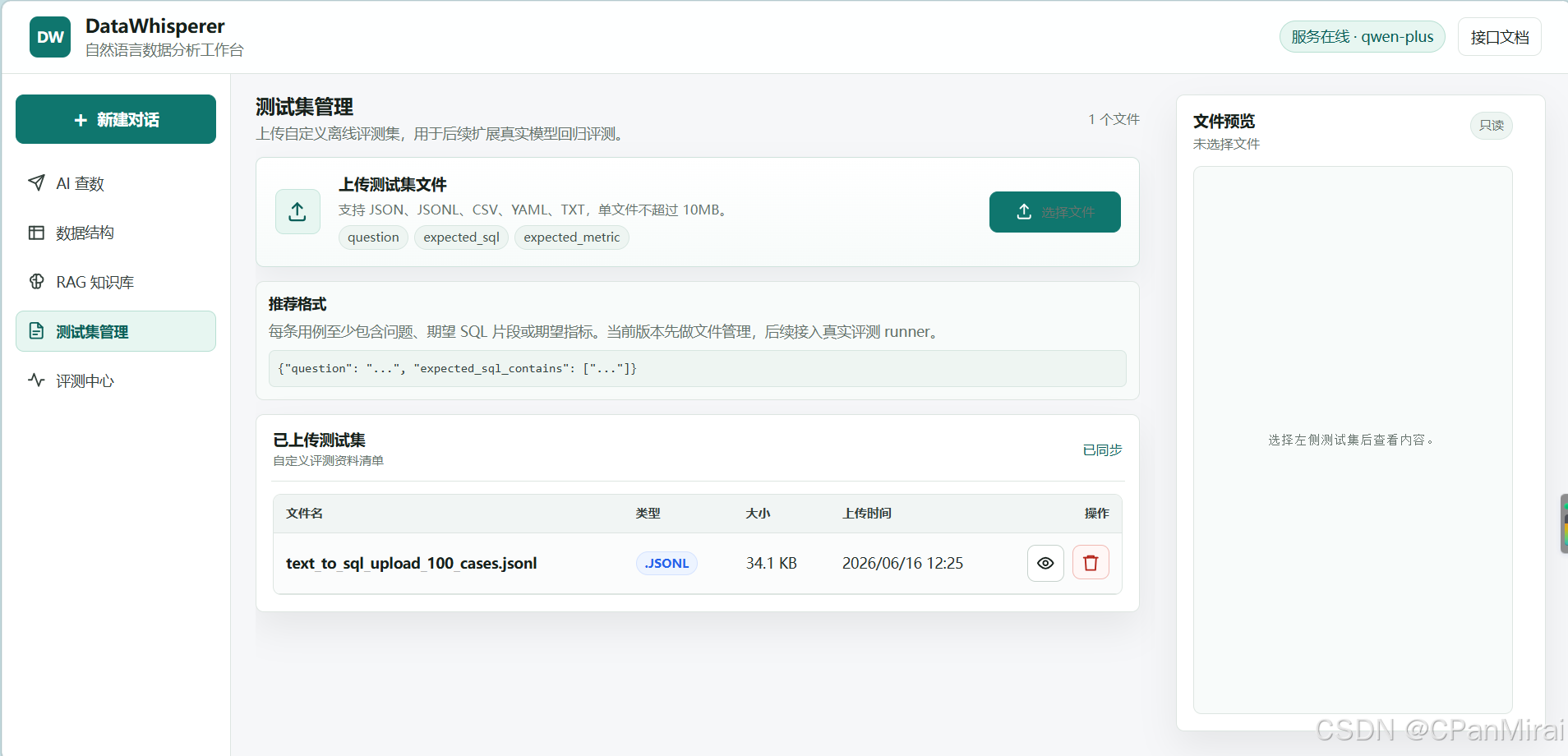
后来我又单独做了测试集管理页面。
用户可以上传自己的测试集文件,然后在评测中心选择这个文件运行评测。
支持的格式包括:
- JSON
- JSONL
- CSV
- TXT
- YAML
我还准备了一份 100 条 Text-to-SQL 回归测试集样例,可以用于演示和压测。
这样项目就不只是"内置几个固定问题",而是可以让用户带着自己的问题来测试系统。
CSDN 插图建议:这里放"评测中心"和"测试集管理页面"的截图。
八、V3.8:把结果变成可以拿走的资产
很多数据分析工具有一个问题:页面上看着还行,但结果很难带走。
比如:
- 图表想放进 PPT
- 表格想复制到 Word
- SQL 想给同事审阅
- 分析结论想整理到报告
所以 V3.8 我重点做了"结果资产化"。
图表导出
图表支持:
- 复制 PNG
- 下载 SVG
- 复制 ECharts 配置
PNG 适合快速贴到文档里,SVG 适合二次编辑,ECharts 配置适合开发者继续复用。
表格导出
表格支持:
- 复制 Word 友好的 HTML 表格
- 复制 Markdown
- 下载 CSV
这样用户可以把查询结果直接带到 Word、Typora、Excel 或其他文档工具里。
SQL 审阅
SQL 页面不只是展示代码,而是加入了:
- 原始问题
- 生成说明
- 只读范围校验
- 语法结构校验
- 数据库执行验证
- LIMIT 结果限制
- 书写规范提示
并且 SQL 代码内部会生成中文注释,解释每段 SQL 的作用。
这对两类人有帮助:
- 业务用户:知道系统大概在查什么。
- SQL 人员:可以更快审阅模型生成的查询逻辑。
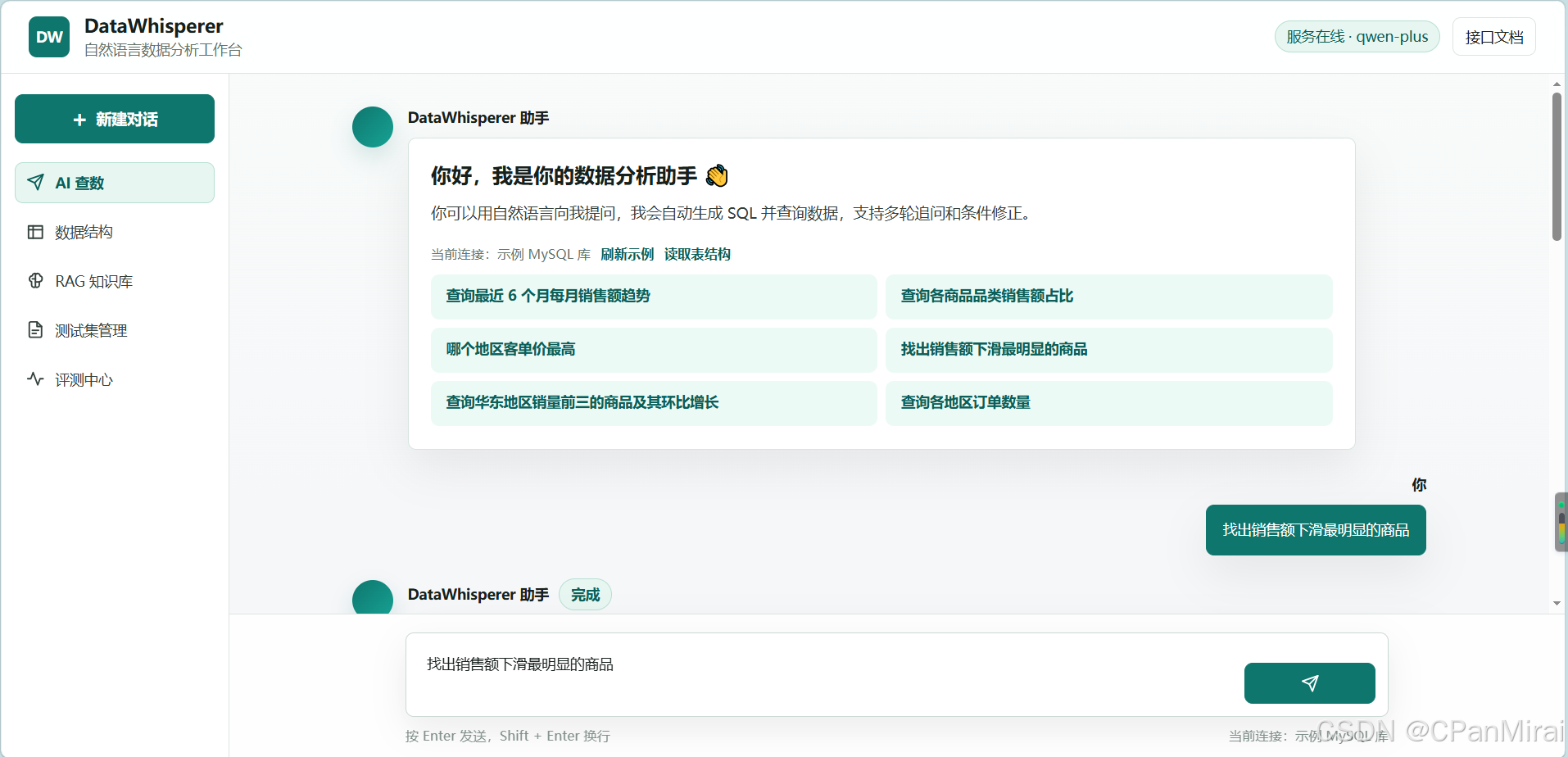
九、V3.9:把 AI 查数改成对话式体验
V3.9 是最近我比较满意的一次交互升级。
之前的 AI 查数页面更像一个表单:
text
输入问题 -> 点击按钮 -> 右侧显示结果这个模式能用,但不够自然。
现在我把它改成了对话式体验:
- 左侧是产品导航和"新建对话"
- 中间是 DataWhisperer 助手欢迎卡片
- 用户可以直接点推荐问题
- 底部是固定输入框
- Enter 发送,Shift + Enter 换行
- 分析结果以助手消息卡片展示
- 结论、图表、表格、SQL、分析过程和追问建议都在同一条回复里
欢迎文案也调整得更像一个数据分析助手:
text
你好,我是你的数据分析助手 👋
你可以用自然语言向我提问,我会自动生成 SQL 并查询数据,支持多轮追问和条件修正。推荐问题现在点击后会直接发送,不再只是填入输入框。
这个小改动很细,但对首次体验很重要。
用户第一次打开页面时,不需要思考"我该问什么、点哪里、怎么运行",直接点一个问题就能看到完整效果。
十、整体架构
V3 之后,DataWhisperer 的整体结构可以理解成这样:
text
用户问题
|
v
FastAPI API
|
v
DataAnalysisOrchestrator
|
+-- Schema Tool:读取数据库结构
+-- Metric Retriever:检索指标口径
| +-- Local Hybrid Retriever
| +-- Milvus Vector Retriever
|
+-- PromptRegistry:读取版本化 prompt
+-- SQL Tool:生成并校验 SQL
+-- SQL Repair:失败后自动修复一次
+-- Query Tool:执行只读查询
+-- Chart Tool:推荐图表
+-- Insight Tool:生成业务结论
|
v
统一响应:SQL + 表格 + 图表 + 结论 + 过程 + 追问建议
|
v
中文 Web 控制台前端控制台则分成:
text
AI 查数
数据结构
RAG 知识库
测试集管理
评测中心这样整个项目不再只是一个接口 Demo,而是更接近一个完整的数据智能体工作台。
十一、V1、V2、V3 的区别
简单对比一下:
| 版本 | 核心目标 | 关键词 |
|---|---|---|
| V1 | 跑通自然语言查数闭环 | Text-to-SQL、SQL 安全、查询执行、图表、结论 |
| V2 | 补工程化能力 | PromptOps、SQL 修复、基础评测、可追踪 |
| V3 | 走向真实产品 | RAG、Milvus、Embedding、资料管理、评测中心、对话式体验 |
如果用一句话总结:
text
V1:能不能跑通?
V2:能不能治理和评测?
V3:能不能理解业务,并像产品一样交付给用户?十二、我觉得 V3 最值得讲的几个点
如果后面面试或者项目展示,我会重点讲这几个点。
1. RAG 不是为了堆概念,而是解决业务口径问题
Text-to-SQL 里最容易被忽视的是:SQL 对不对,不只看语法,还要看业务口径。
所以 V3 的 RAG 不是随便传文档,而是围绕"指标定义"这个明确问题来做。
2. Milvus 只是索引,不是知识源
我没有把所有业务知识都直接交给向量库。
知识源仍然是 Markdown,Milvus 只负责检索加速和语义召回。
这让系统更可维护,也更容易解释。
3. 有兜底,项目才适合展示
Milvus 不可用时可以回退到本地检索。
DashScope Embedding 没配置时可以回退到本地 hashing。
没有大模型 Key 时部分示例可以走演示规则。
这些兜底不是偷懒,而是为了保证项目在不同环境下都能稳定演示。
4. 评测中心让项目更像工程项目
大模型项目很容易变成"今天看起来还行"。
评测中心的意义是把效果变成可观察的数据。
通过率、错误案例、趋势、测试集,这些东西比单纯截图更能说明项目质量。
5. 对话式体验让用户更愿意使用
技术能力很重要,但用户第一眼看到的是界面。
V3.9 把 AI 查数改成对话式工作台,就是为了让用户感觉它不是一个调试页面,而是一个真的可以提问、追问、拿结果的数据助手。
十三、当前测试情况
当前项目保留了比较完整的基础测试。
测试覆盖包括:
- API 契约
- SQL 安全校验
- 图表推荐
- PromptRegistry
- SQL 自动修复
- Text-to-SQL 评测
- 指标检索评测
- Milvus 检索兜底
- DashScope Embedding 客户端
- 文件上传、预览、删除
- 评测中心接口
- 自定义测试集解析
当前本地测试结果:
text
pytest: 51 passed
ruff: All checks passed这也是我希望项目呈现出来的状态:
不只是能跑,而且有基本质量保障。
十四、后续计划
V3 已经让 DataWhisperer 从 MVP 走到了比较完整的产品雏形。
后面我还想继续做:
- RAG 上传文件自动切片
- RAG 文件同步 Milvus
- 数据结构文件自动解析 schema
- SQL 样例库检索增强
- 更真实的 LLM 评测
- 多模型对比
- MCP 工具化
- 多智能体协作
如果继续往产品方向做,DataWhisperer 可以变成一个"企业内部数据分析 Copilot":
text
业务用户负责提问
系统负责理解指标、生成 SQL、查询数据、解释结果
数据团队负责维护指标口径、数据字典和评测集这也是我做这个项目的长期目标。
十五、总结
V3 对我来说,不只是加了几个功能。
它更像是一次方向变化:
text
从一个能跑通的 Text-to-SQL Demo
升级成一个带业务知识、向量检索、质量评测和产品化交互的数据分析智能体V1 让我把自然语言查数链路跑通。
V2 让我开始理解大模型工程化:提示词治理、SQL 修复、评测集。
V3 则让我更清楚地意识到:真正有价值的大模型应用,不只是调用模型,而是把模型放进一套完整的业务系统里。
它需要数据结构,需要业务口径,需要安全边界,需要评测体系,也需要一个用户愿意打开的界面。
DataWhisperer 还没有结束。
后面我会继续围绕 RAG、MCP、多智能体和真实评测去迭代,让它越来越接近一个真正可以落地的数据分析智能体产品。
如果你也在做 Text-to-SQL、RAG、模型评测或数据分析智能体,欢迎看看这个项目: