学习笔记1:python学习笔记1-CSDN博客
学习笔记2:Python学习笔记2-CSDN博客
学习笔记3:Python学习笔记3-项目实战-AI应用-CSDN博客
学习笔记4:Python学习笔记4-网络机器人(爬虫)-CSDN博客
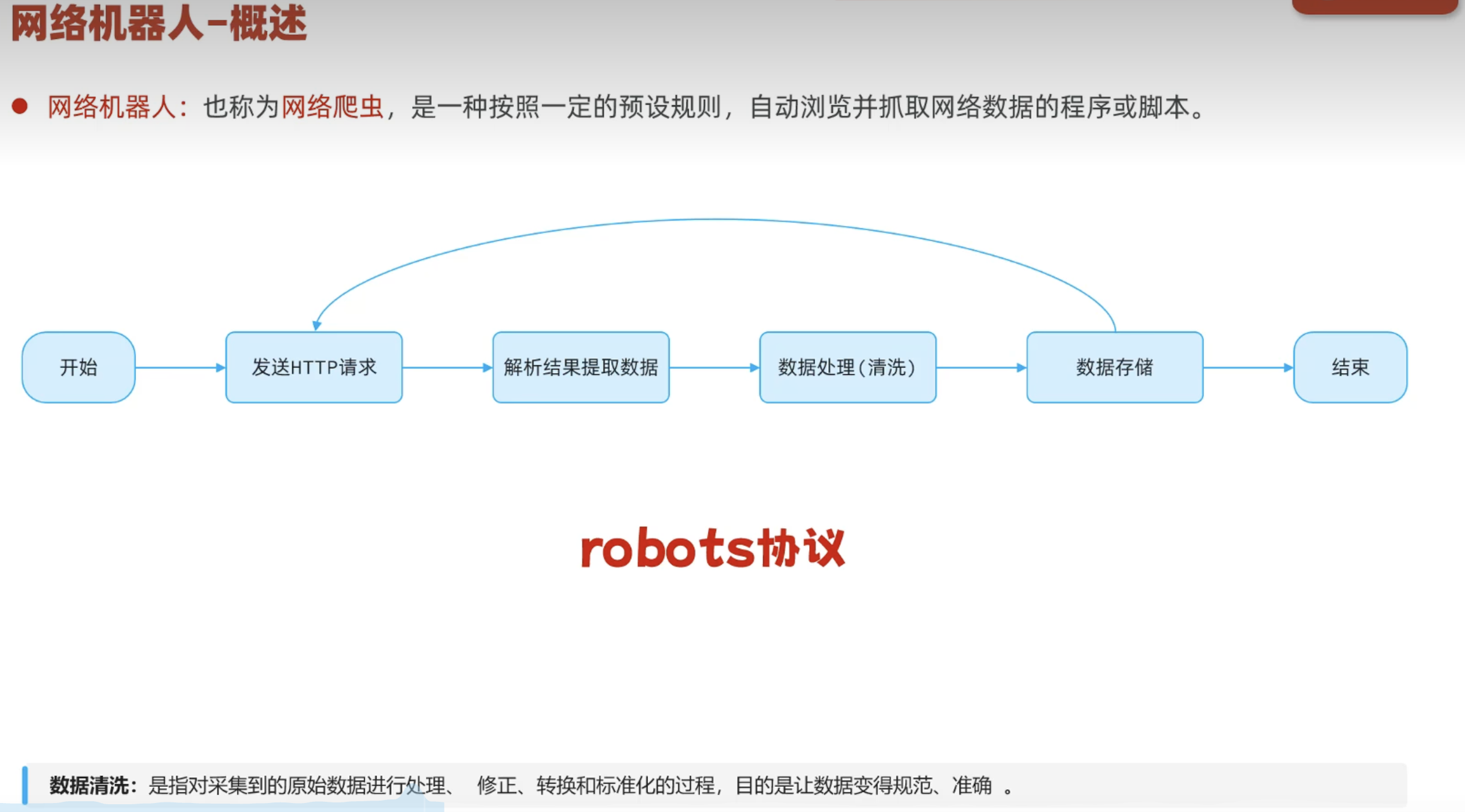
一、概述



二、入门
2.1 入门程序
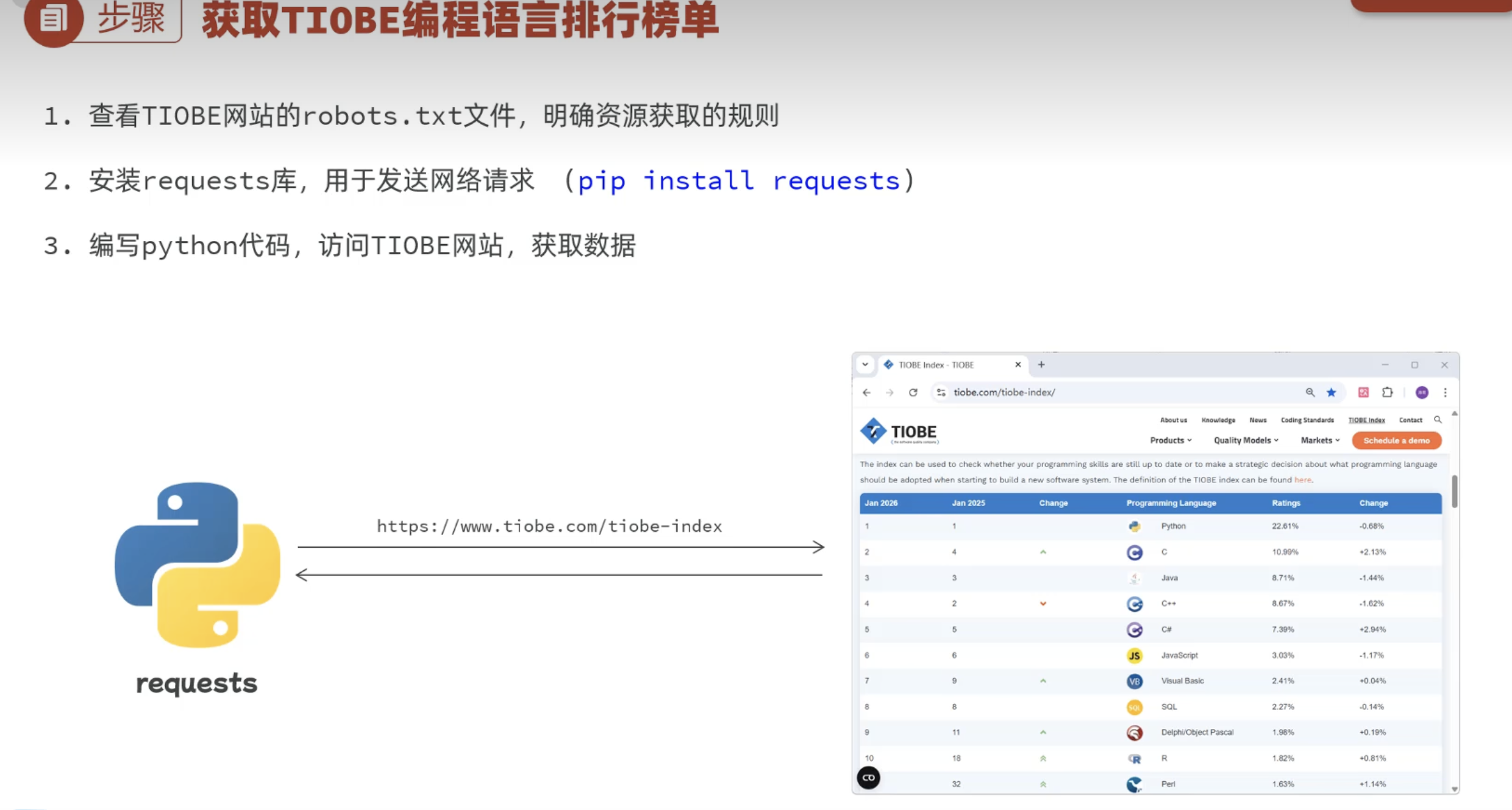
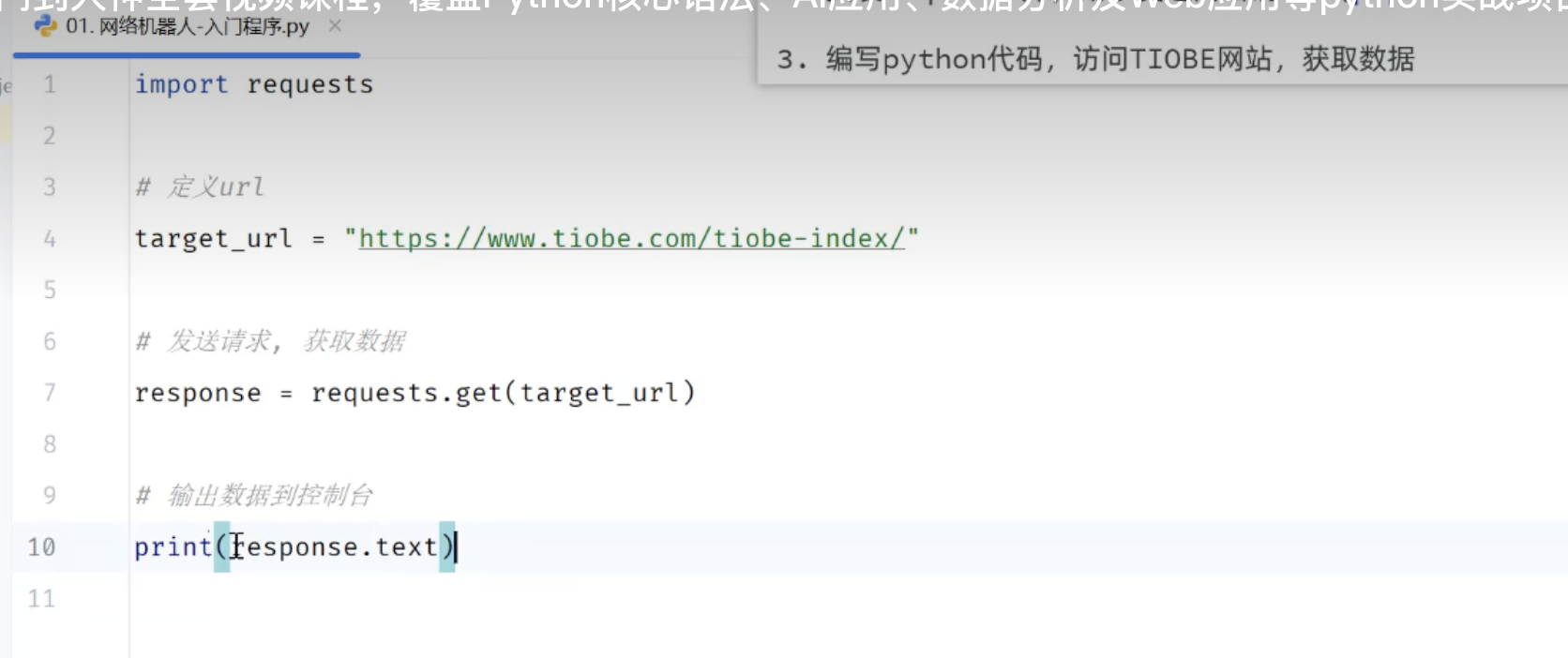
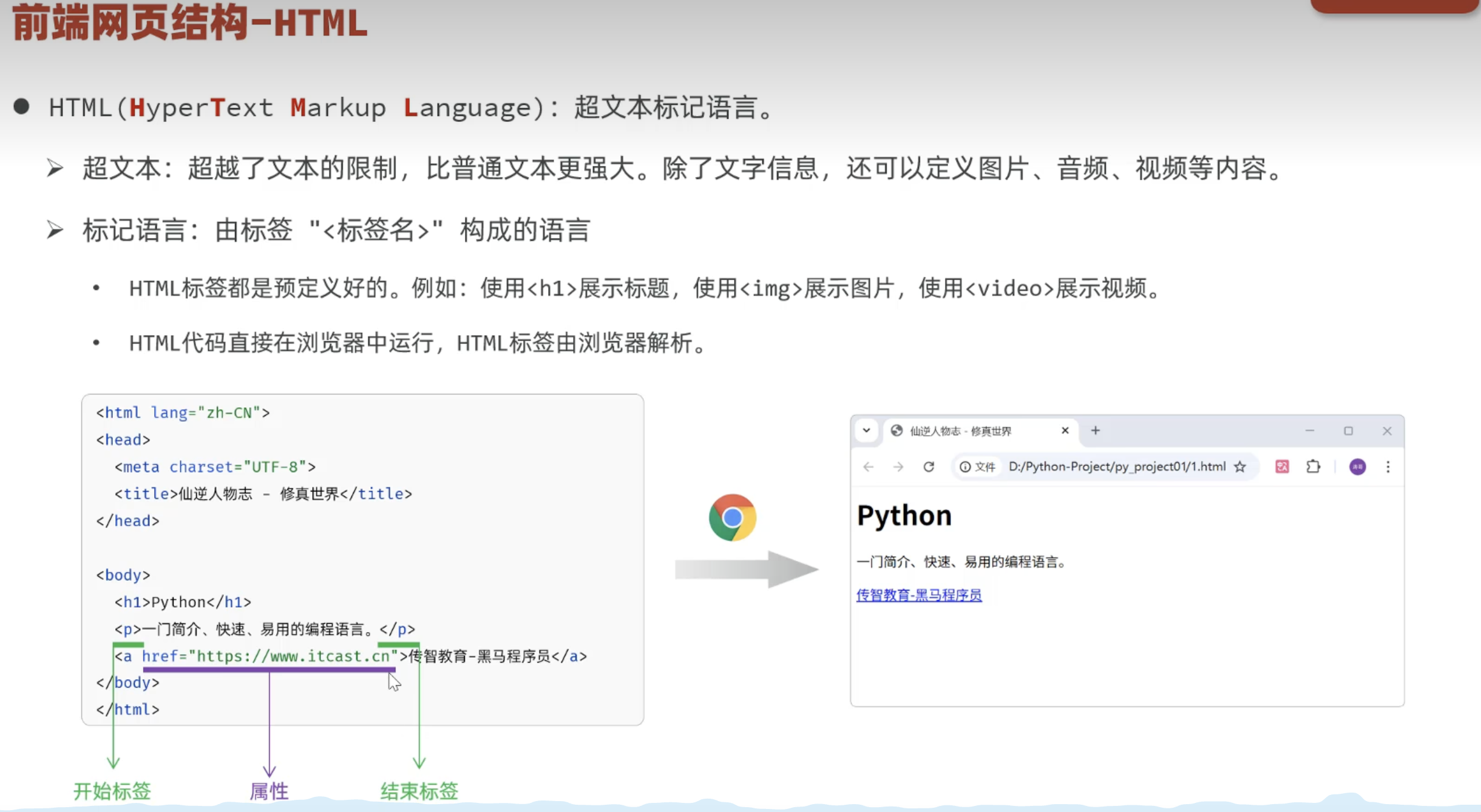
2.1.1 网页结构

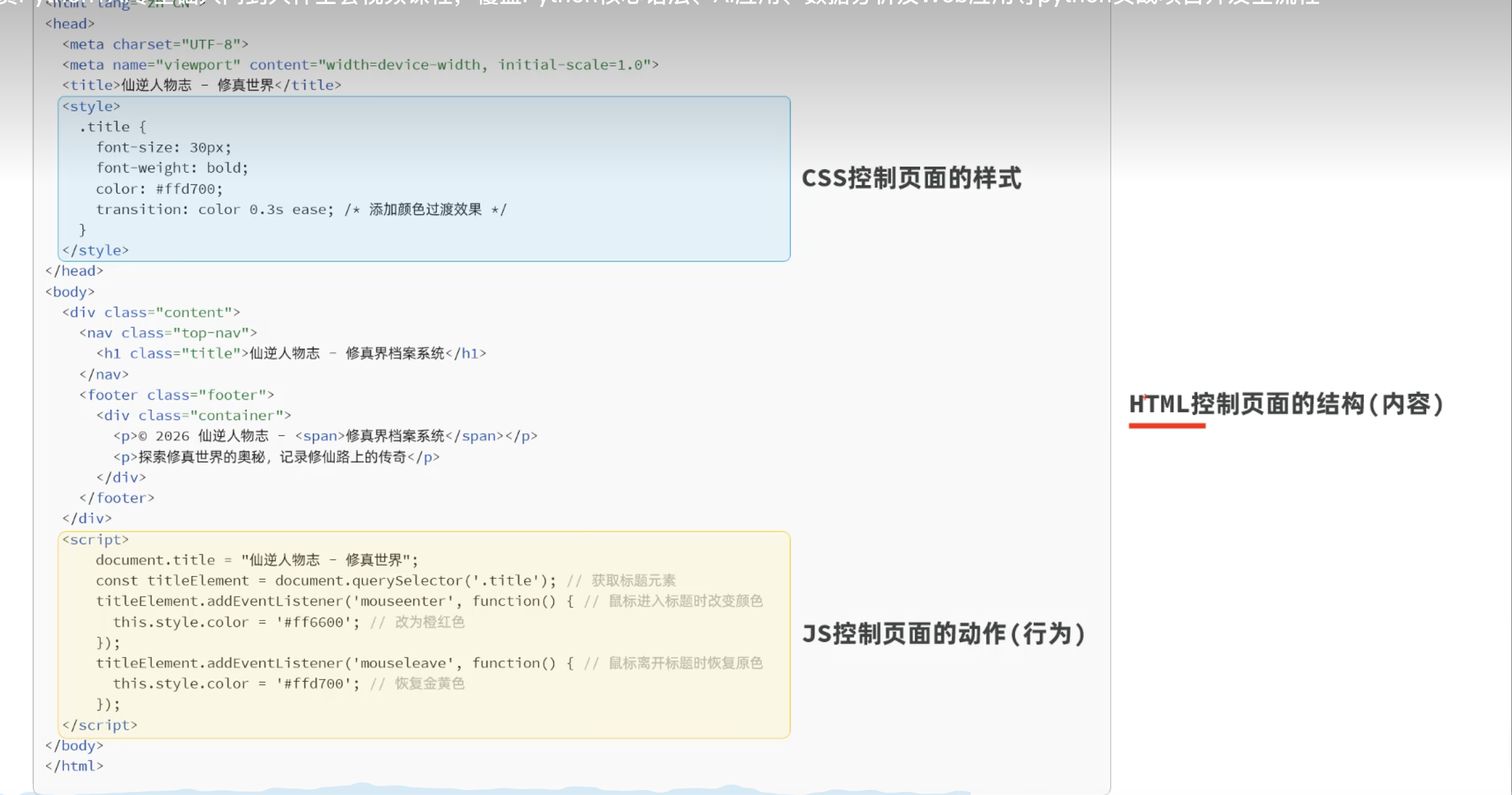

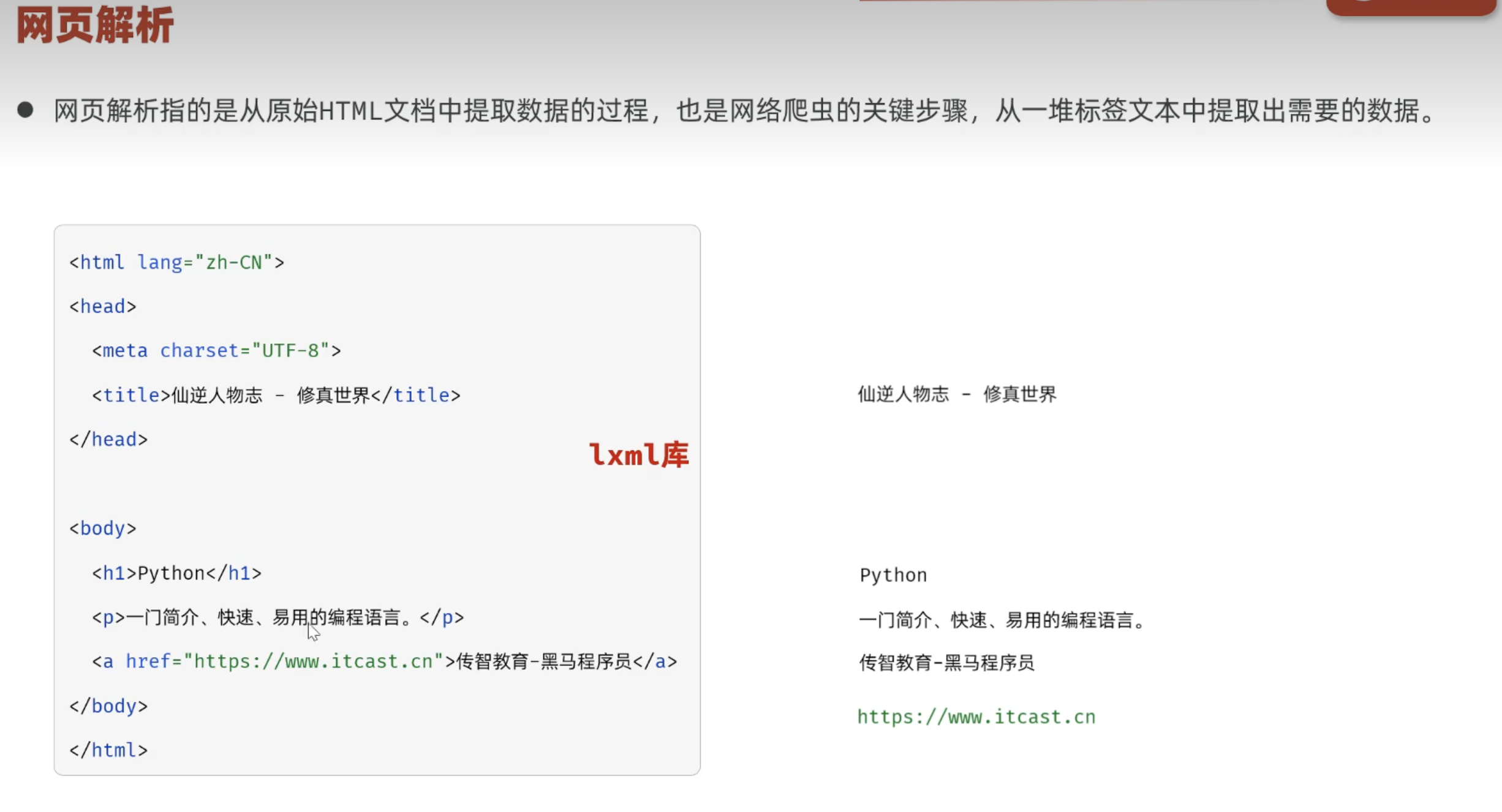
2.1.2 网页解析
2.1.2.1 入门
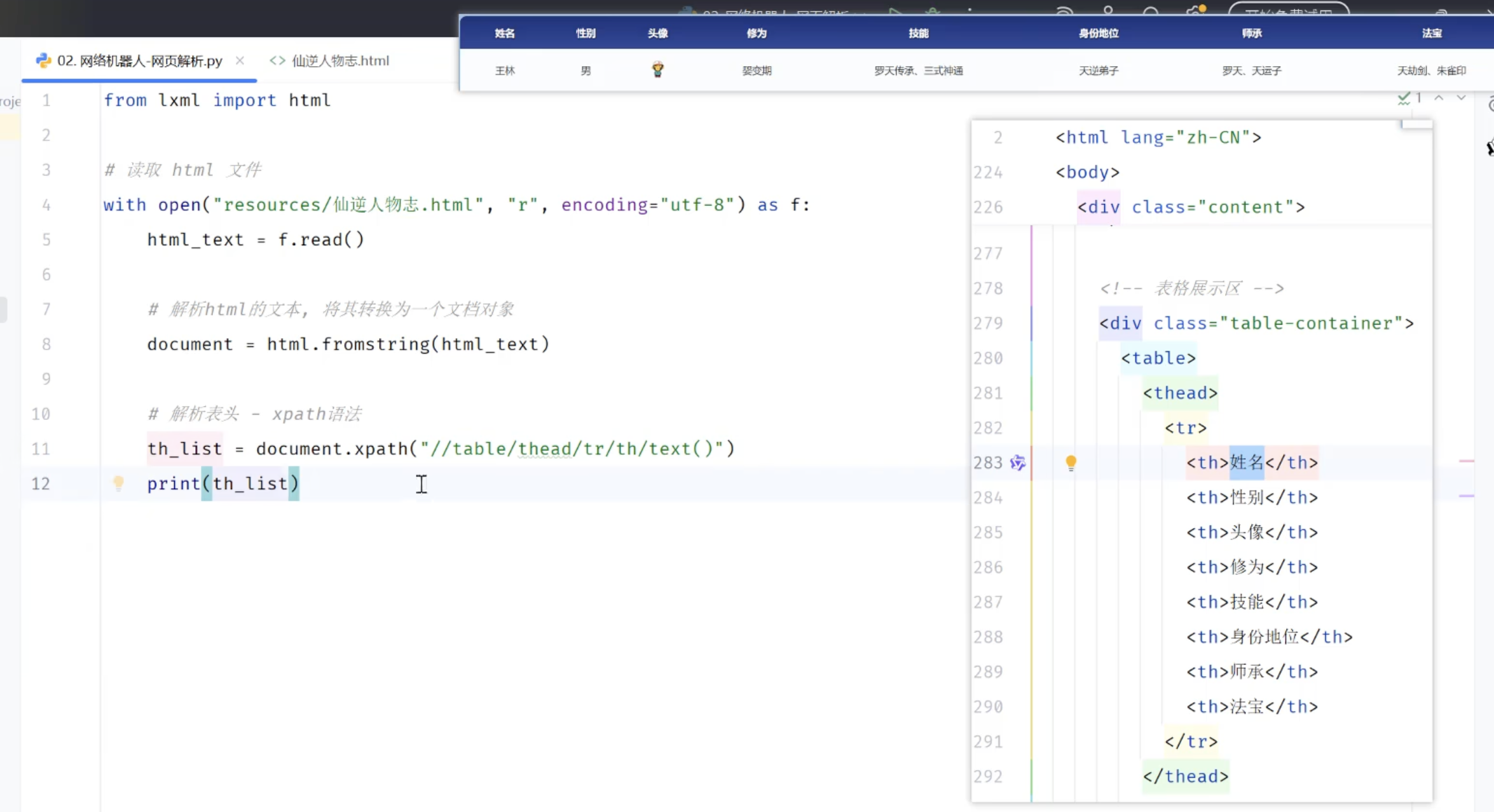
获取表头
获取第一行数据
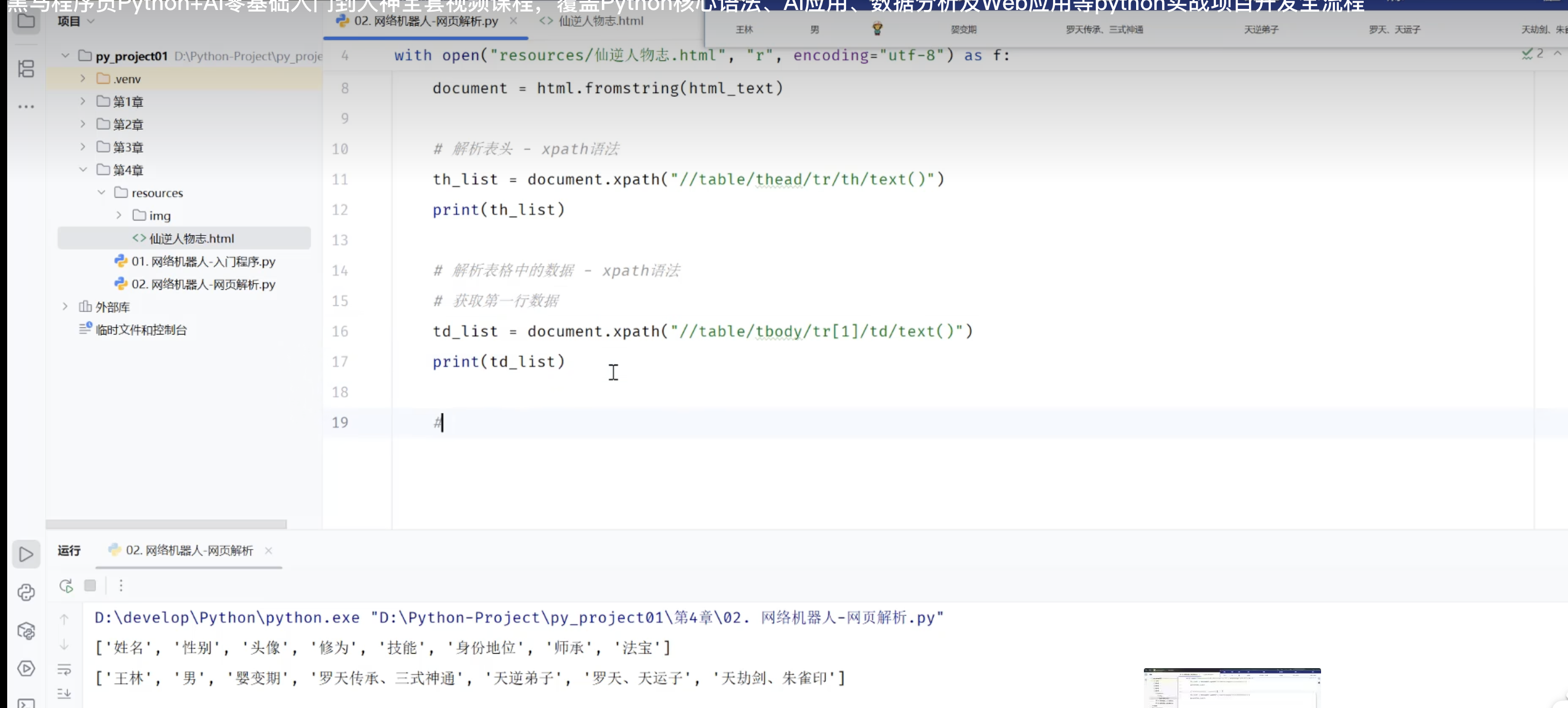
获取表格所有数据
java
from lxml import html
# 读取网页,解析网页
with open("resources/学生成绩.html","r",encoding="utf-8") as f:
# 读取网页内容,
html_doc = f.read()
# 解析html的文本,转换为一个对象
tree = html.fromstring(html_doc)
# 读取表头
thead_list = tree.xpath("//table/thead/tr/th/text()")
print(thead_list)
# 获取第一行数据
tr_list = tree.xpath("//table/tbody/tr[1]/td/text()")
print(tr_list)
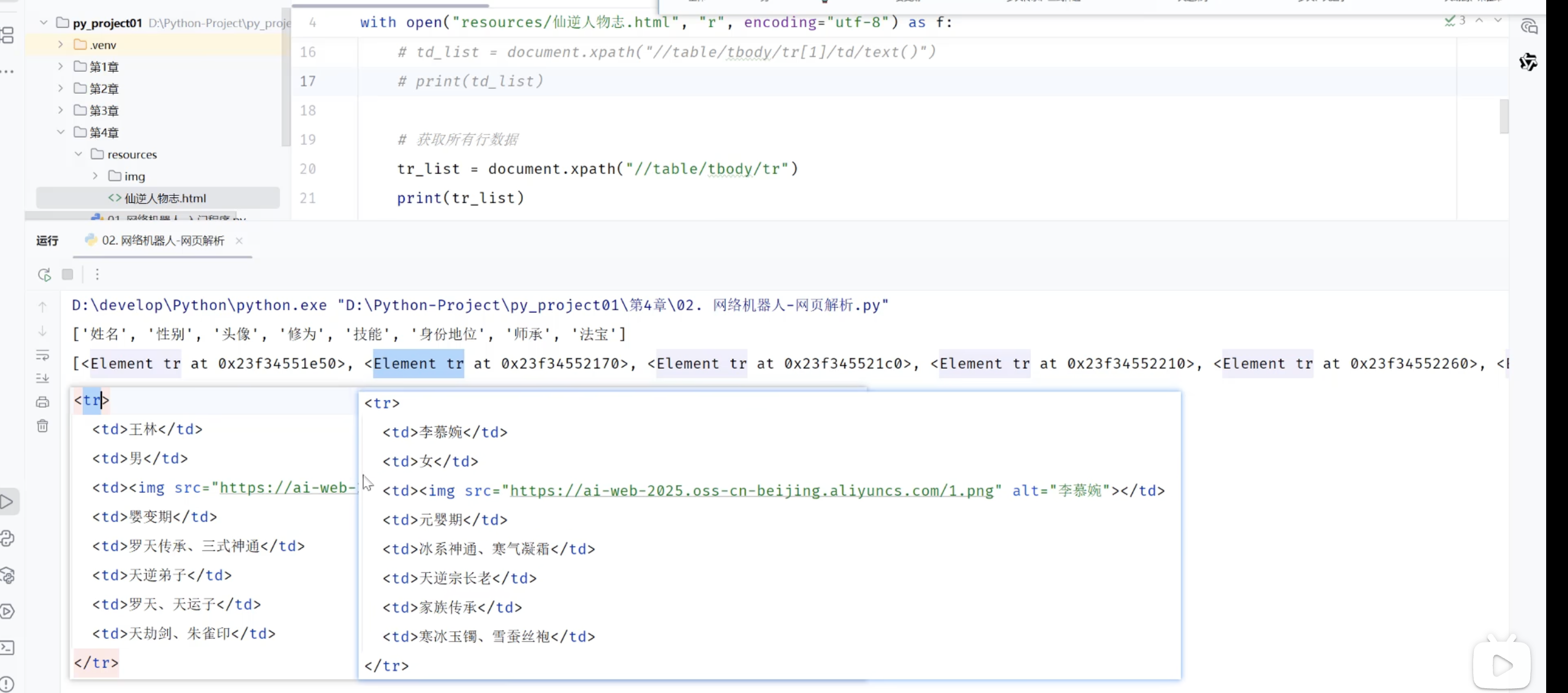
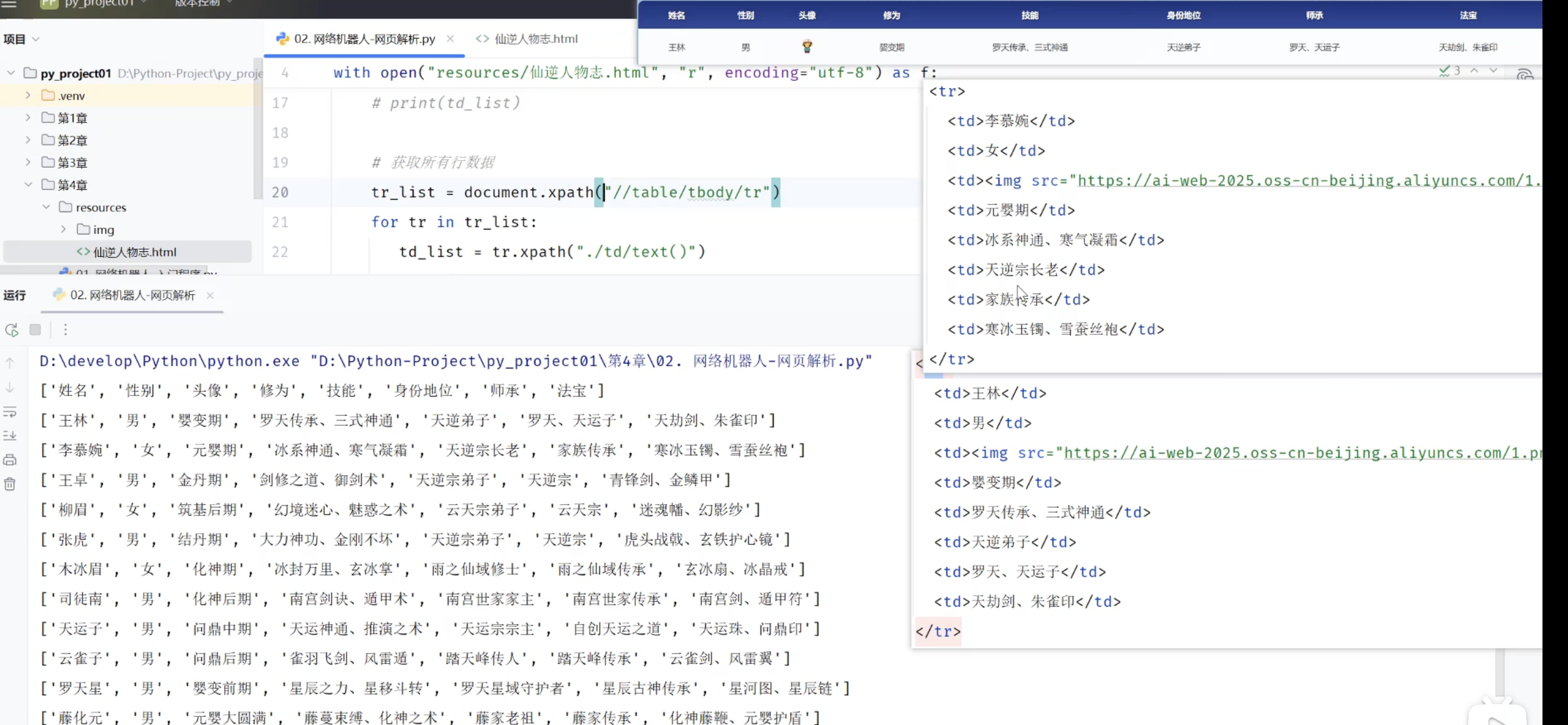
# 获取所有行数据
students = tree.xpath("//table/tbody/tr")
for stu in students:
print(stu.xpath("./td/text()"))2.1.2.2 Xpath语法


python
from lxml import html
# 读取网页,解析网页
with open("resources/学生成绩.html","r",encoding="utf-8") as f:
# 读取网页内容,
html_doc = f.read()
# 解析html的文本,转换为一个对象
tree = html.fromstring(html_doc)
# / 表示从根节点获取元素
theadlist = tree.xpath("/html/body/table/thead/tr/th/text()")
print(theadlist)
print("------------------------")
# // 从任意节点获取元素
thead_list = tree.xpath("//table/thead/tr/th/text()")
print(thead_list)
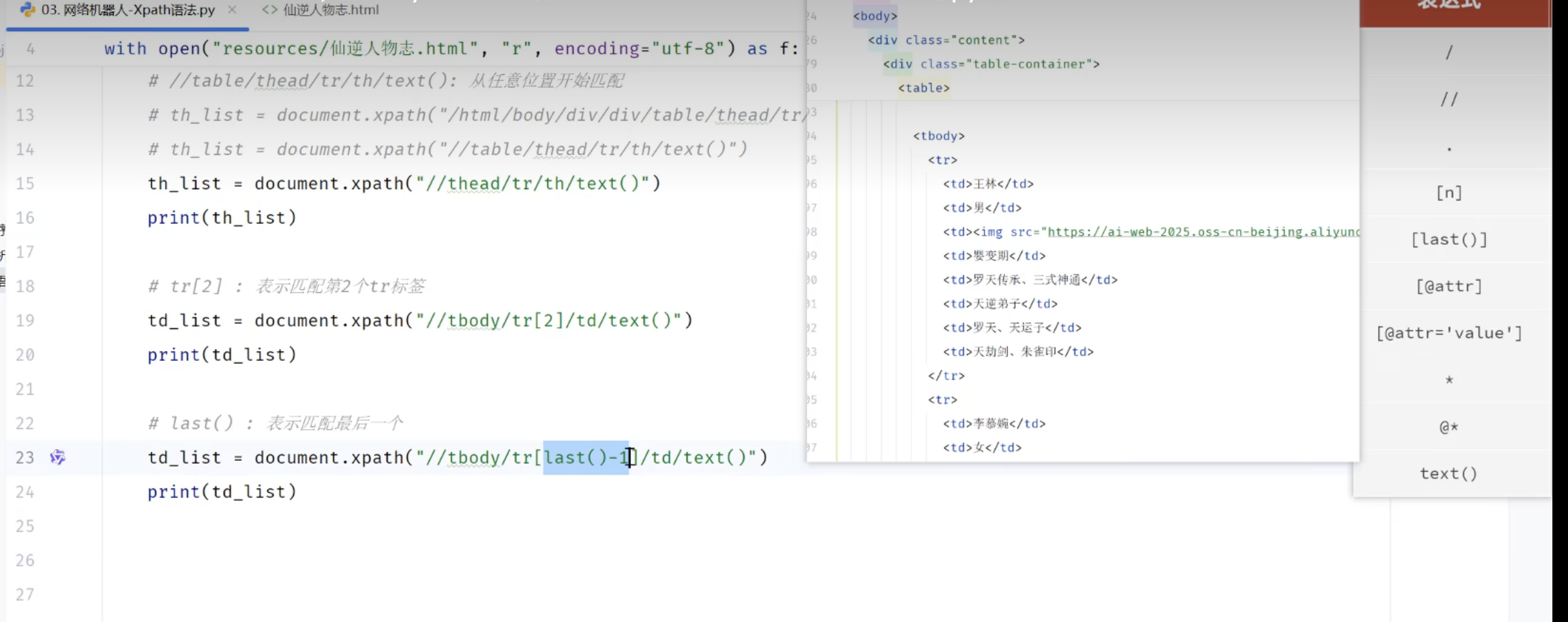
# [n] 选择第n个元素
tr_list = tree.xpath("//table/tbody/tr[3]/td/text()")
print(f"第三行:{tr_list}")
# [last()] 最后一个元素
tr_list = tree.xpath("//table/tbody/tr[last()]/td/text()")
print(f"最后一行:{tr_list}")
# 获取所有p标签的文本
p_list = tree.xpath("//p/text()")
print(f"plist:{p_list}")
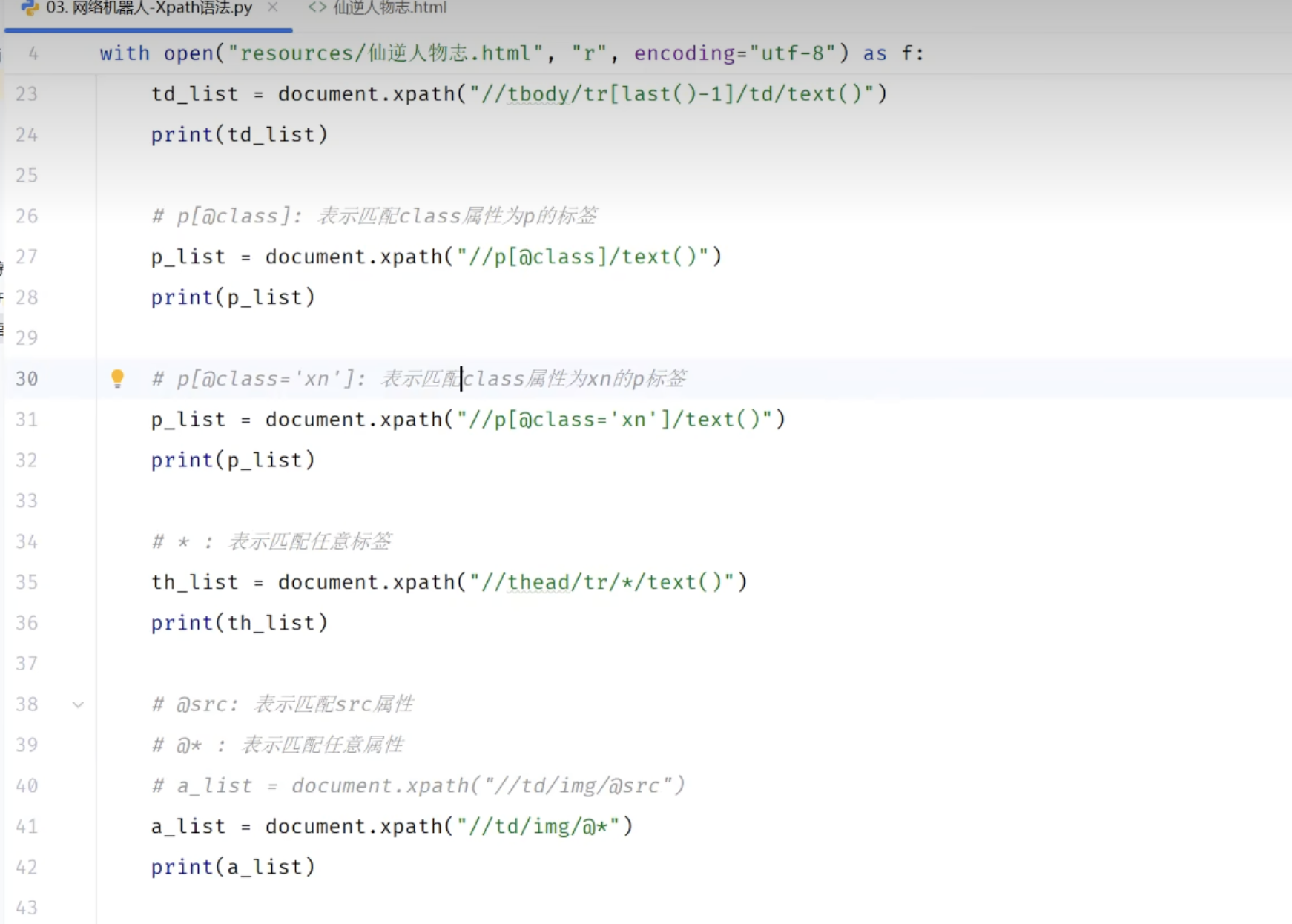
# [@attr] 选择有该属性的元素
class_list = tree.xpath("//span[@class]/text()")#选择有class属性的span元素的文本
print(f"class_list:{class_list}")
# [@sttr='value'] 选择该属性值为value的元素
highlight_list = tree.xpath("//span[@class='highlight']/text()")#选择class属性值为highlight的span元素的文本
print(f"highlight_list:{highlight_list}")
# @* 匹配组件下的任何属性 匹配div组件下的任何属性 <div class="summary-section">
div_attr_list = tree.xpath("//div/@*")# summary-section
print(f"div_attr_list:{div_attr_list}")
# * 表示任意元素
p_element_list = tree.xpath("//div/p/*/text()")
print(f"div_element_list:{p_element_list}")
# div_all_list = tree.xpath("//div/*")
# print(f"div_all_list:{div_all_list}")
# 获取所有行数据
students = tree.xpath("//table/tbody/tr")
for stu in students:
print(stu.xpath("./td/text()"))2.1.2.3 入门程序-网页解析
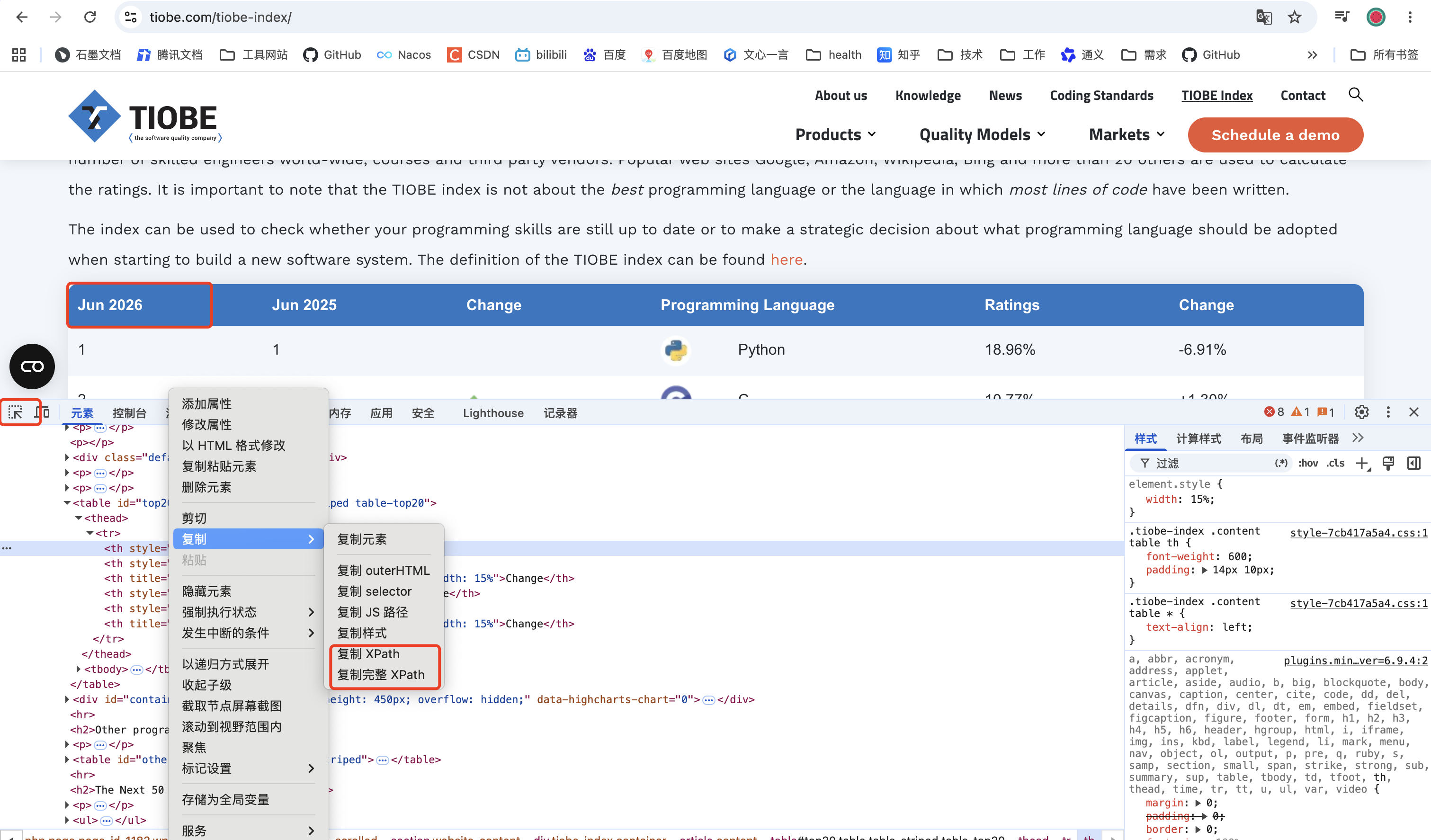
获取页面元素的路径,可以F12代开开发者工具,选择对应元素后,使用如下简单方法获取
python
import requests
from lxml import html
#目标网址
target_url = "https://www.tiobe.com/tiobe-index/"
# 发送请求,获取数据
response =requests.get(target_url)
# 打印数据到控制台
# print(response.text)
document = html.fromstring(response.text)
# 解析表头
# th_list = document.xpath("//table[@id='top20']/thead/tr/th/text()")
# th_list = document.xpath("/html/body/section/div/article/table[1]/thead/tr/th/text()")
th_list = document.xpath("//*[@id=\"top20\"]/thead/tr/th/text()")
print(th_list)
# 解析表格中的数据
tr_list = document.xpath("//table[@id='top20']/tbody/tr")
for tr in tr_list:
print(tr.xpath("./td/text()"))三、案例
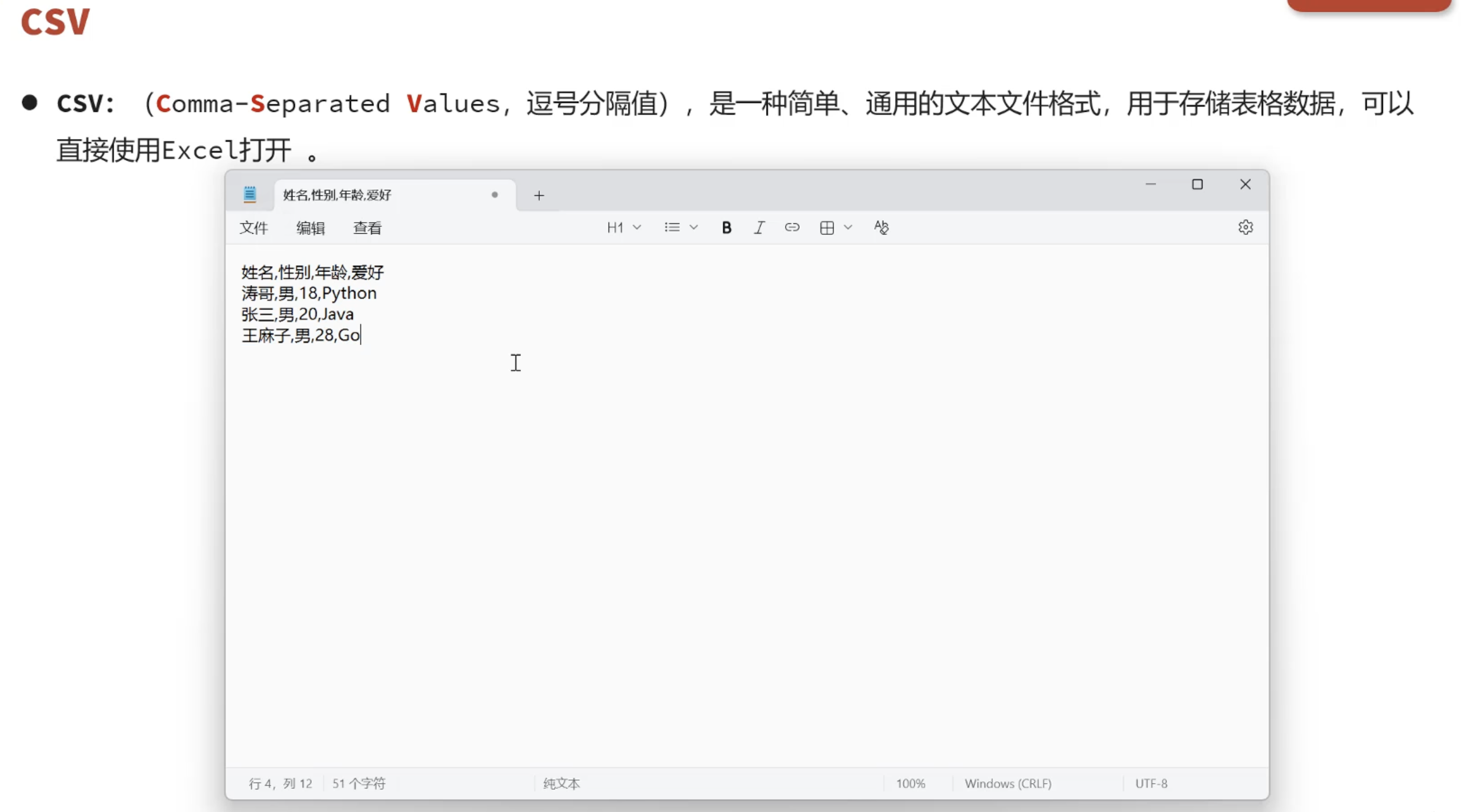
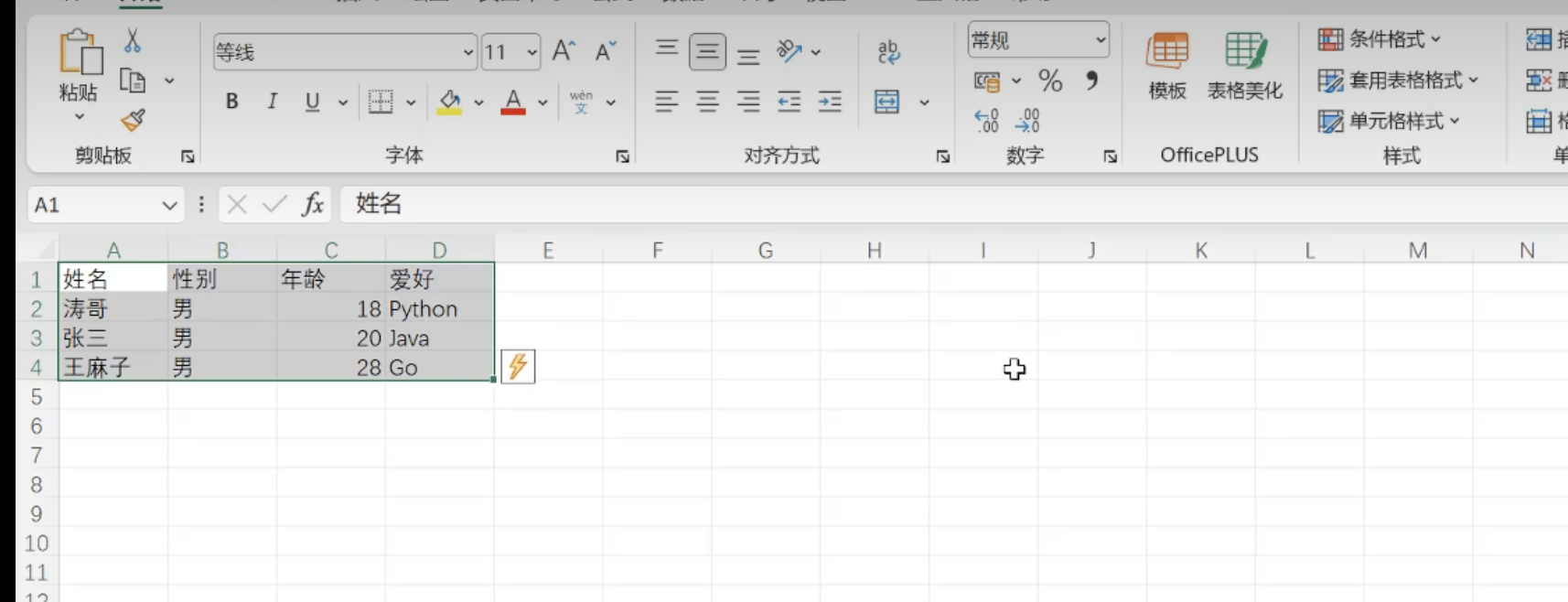
3.1 csv操作
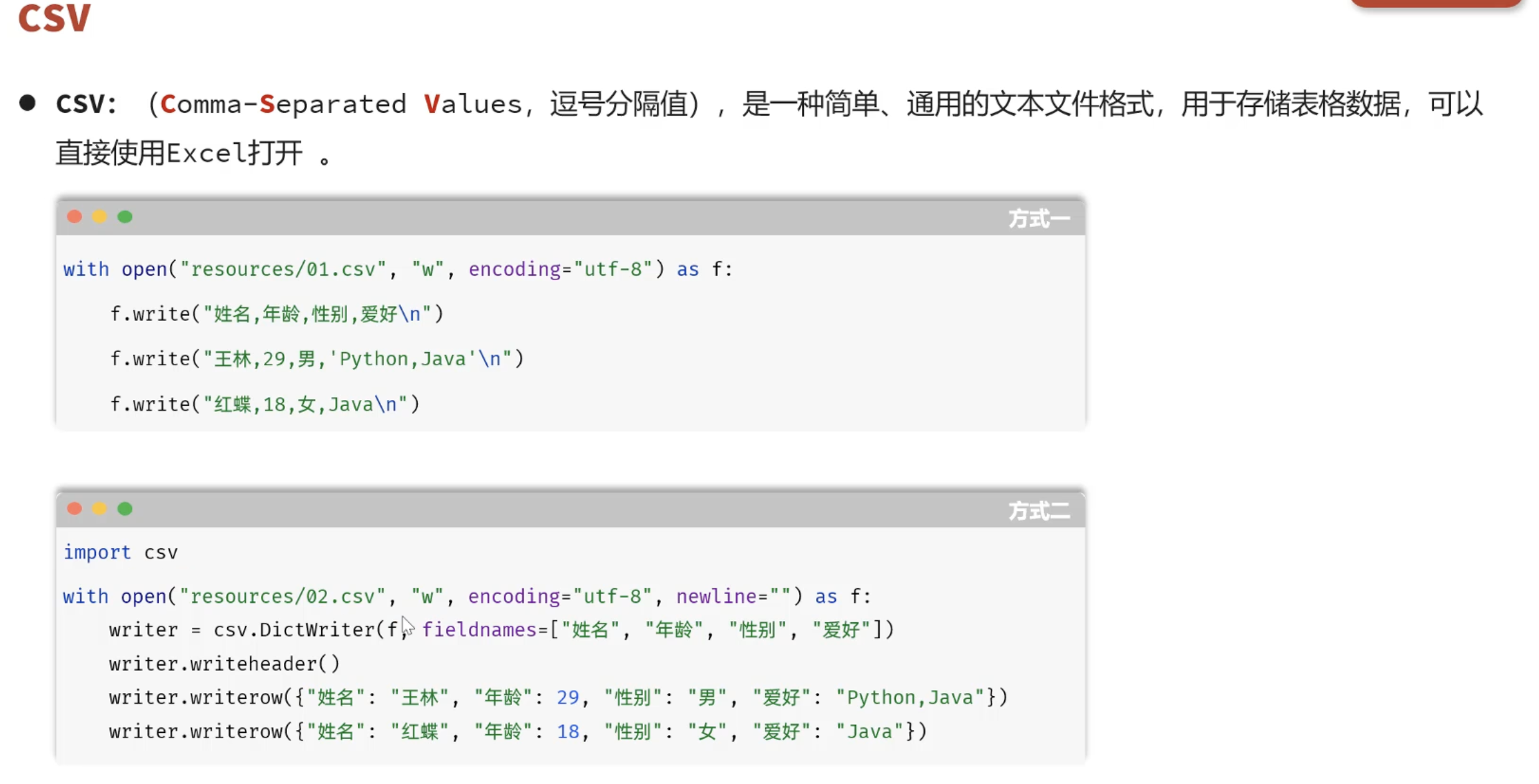

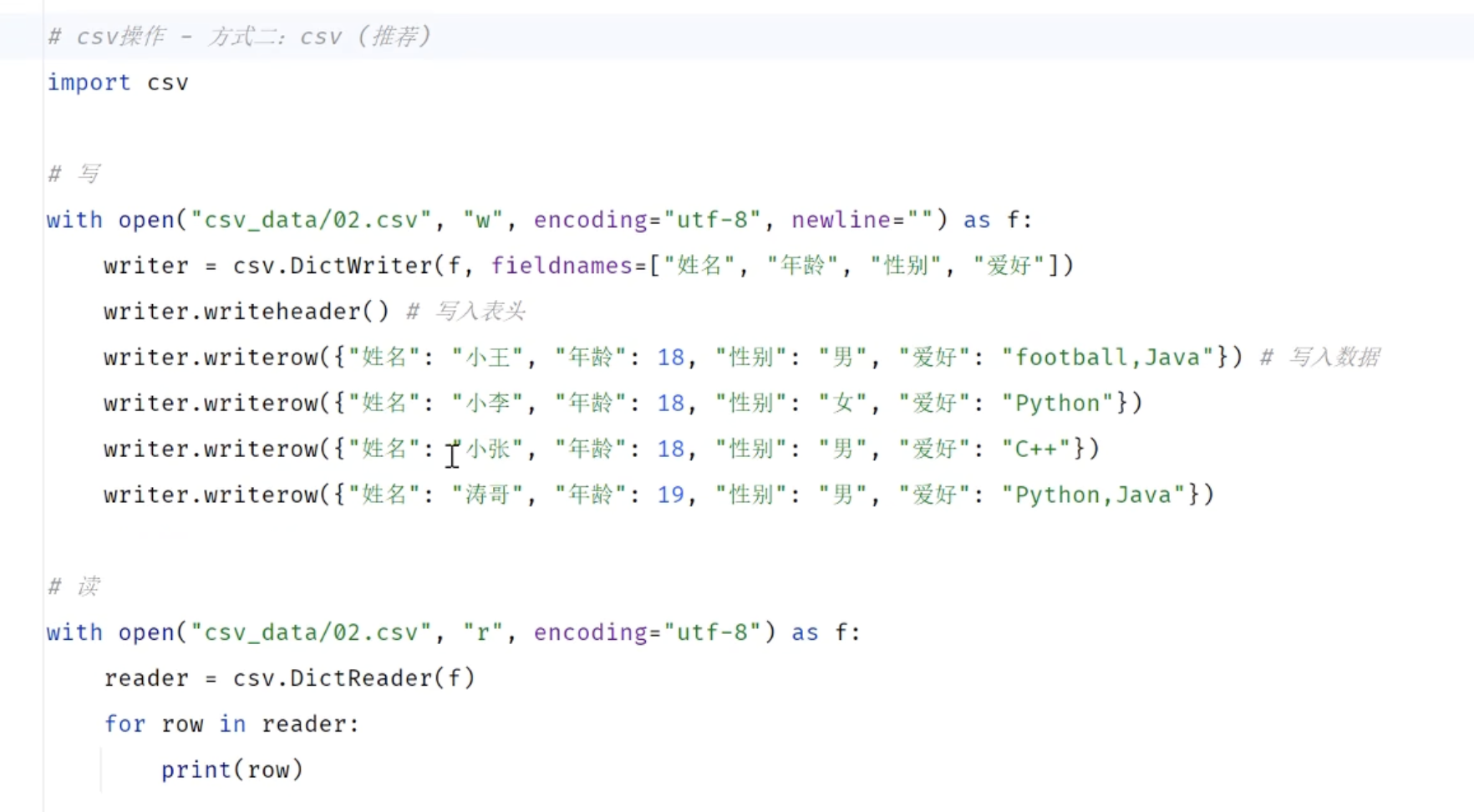
python
# 方式一:使用文件基本操作
# with open("csv_data/1.csv","w",encoding="utf-8") as f:
# f.write("姓名,语文,数学,英语,总分,平均分\n")
# f.write("张三,90,80,70,250,83.33\n")
# f.write("李四,80,90,80,250,83.33\n")
# f.write("王五,70,80,90,250,83.33\n")
# f.write("赵六,80,70,80,250,83.33\n")
#
# with open("csv_data/1.csv","r",encoding="utf-8") as f:
# for line in f:
# print(line.strip())
# 方式二:使用csv库
import csv
with open("csv_data/2.csv","w",encoding="utf-8",newline="") as f:
# 使用DictWriter,创建一个csv文件
writer = csv.DictWriter(f,fieldnames=["姓名","语文","数学","英语","总分","平均分"])
writer.writeheader()#写入表头
# 写入数据行
writer.writerow({"姓名":"张三","语文":90,"数学":80,"英语":70,"总分":250,"平均分":83.33})
writer.writerow({"姓名":"李四","语文":80,"数学":90,"英语":80,"总分":250,"平均分":83.33})
writer.writerow({"姓名":"王五","语文":70,"数学":80,"英语":90,"总分":250,"平均分":83.33})
with open("csv_data/2.csv","r",encoding="utf-8") as f:
# 使用DictReader,创建一个csv文件
reader = csv.DictReader(f)
for line in reader:
print(line)3.2 案例高分电影Top100
3.2.1 最初版本
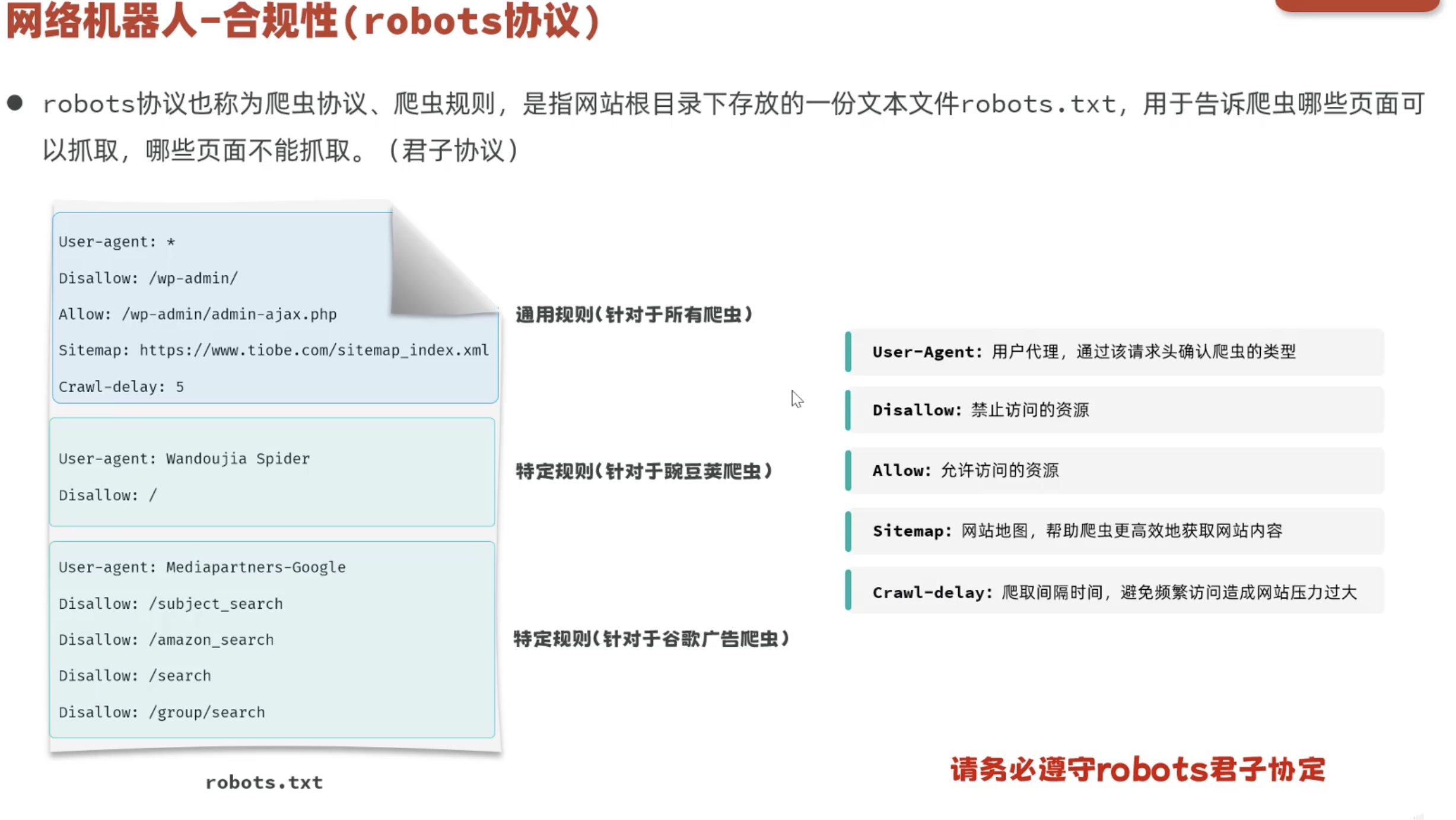
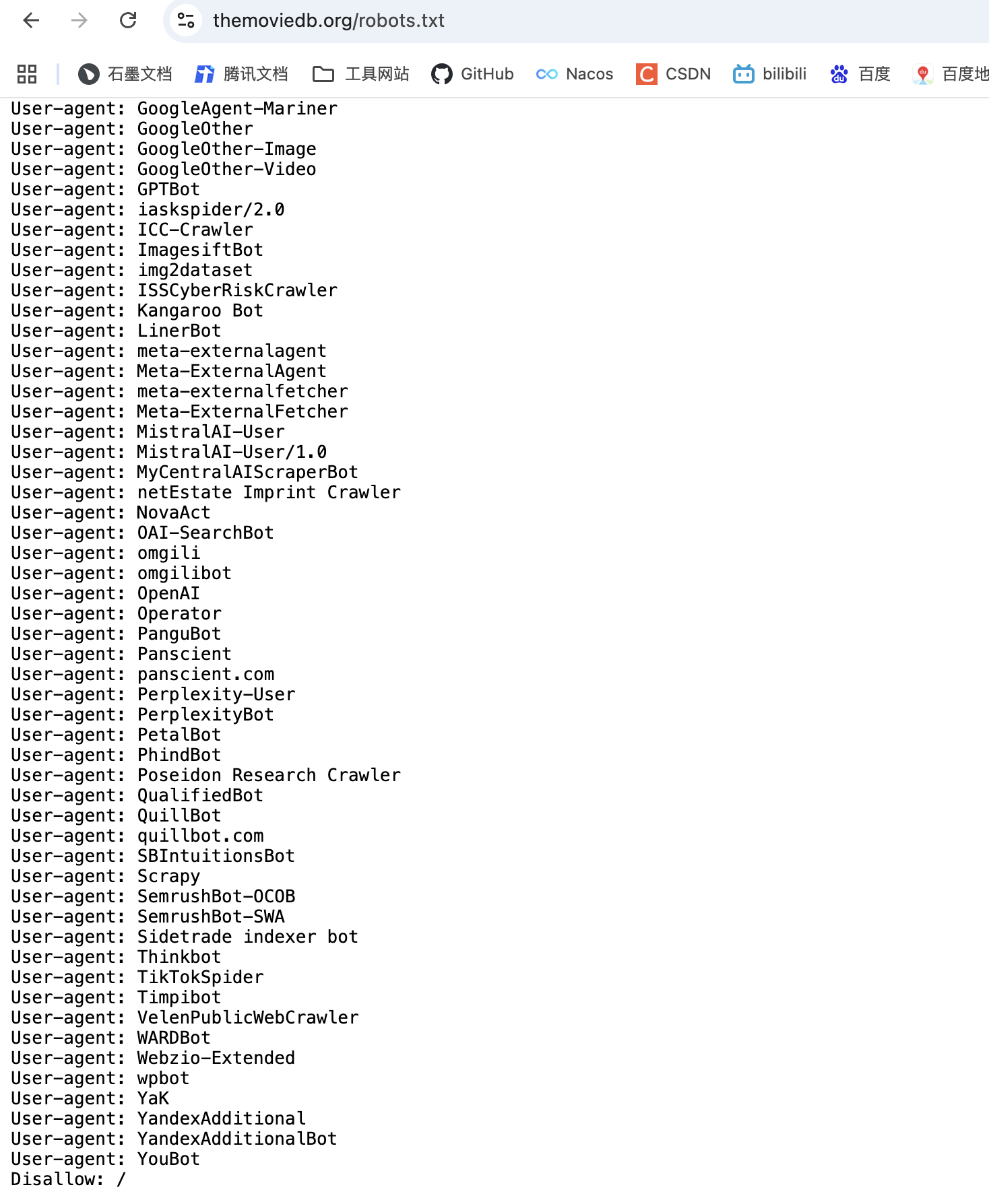
1、查看网站robots协议,看是否符合爬取规则
查看该网站的robots.txt ,看我们要抓取的数据是否符合规则
2、分析网站数据并获取保存

python
import requests
from lxml import html
import csv
# 请求地址
MOVIEDB_BASE_URL = "https://www.themoviedb.org"
TOP100_URL=MOVIEDB_BASE_URL+"/movie/top-rated"
# 获取电影详情
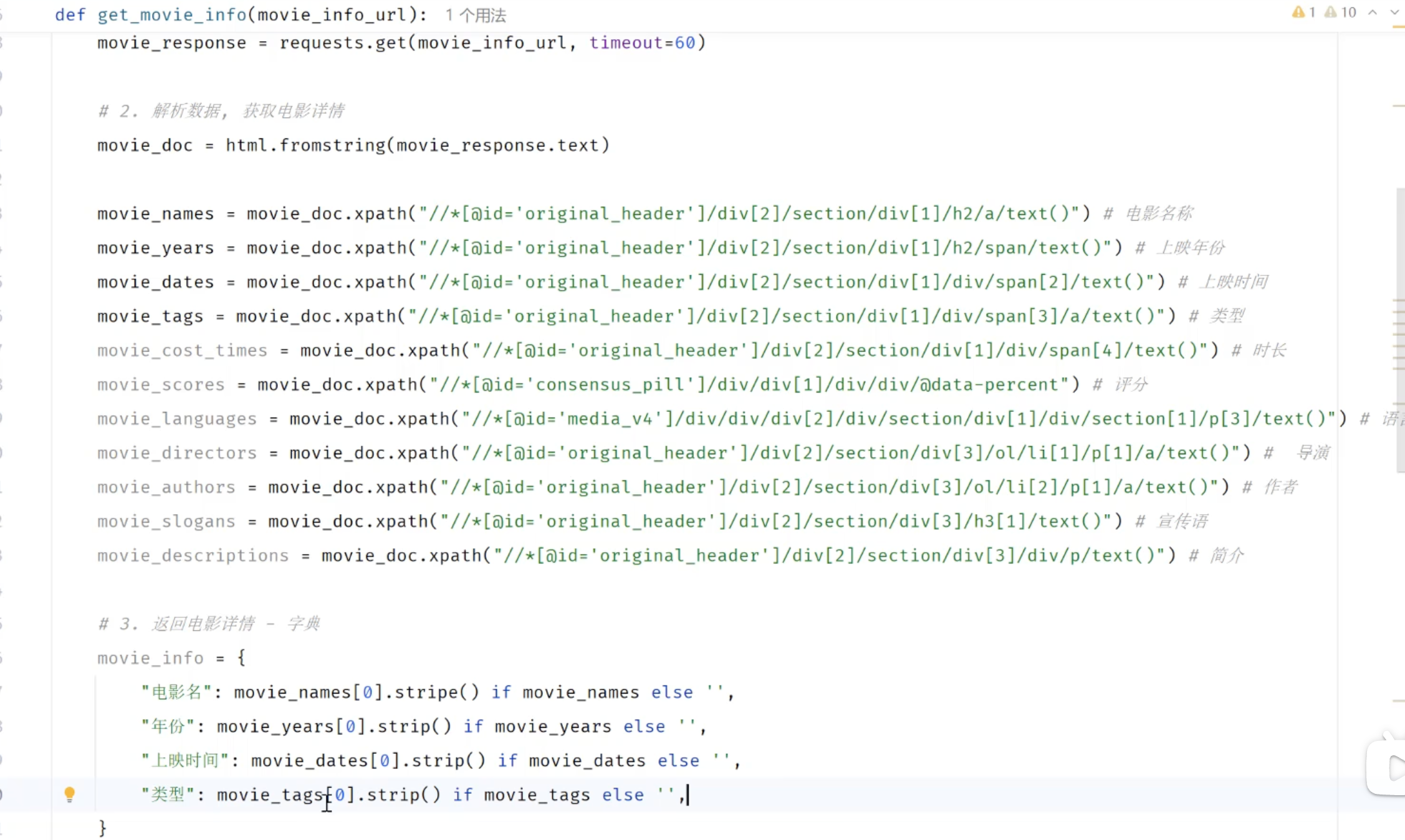
def get_details(url):
response_data=requests.get(url)
document = html.fromstring(response_data.text)
movie_name = document.xpath("//*[@id=\"original_header\"]/div[2]/section/div[1]/h2/a/text()")#电影名称
year = document.xpath("//*[@id=\"original_header\"]/div[2]/section/div[1]/h2/span/text()")#年份
release_date = document.xpath("//*[@id=\"original_header\"]/div[2]/section/div[1]/div/span[2]/text()")#上映时间
type =document.xpath("//*[@id=\"original_header\"]/div[2]/section/div[1]/div/span[3]/a/text()")# 类型
time = document.xpath("//*[@id=\"original_header\"]/div[2]/section/div[1]/div/span[4]/text()")#时长
score = document.xpath("//*[@id=\"consensus_pill\"]/div/div[1]/div/div/@data-percent")#评分
language = document.xpath("//*[@id=\"media_v4\"]/div/div/div[2]/div/section/div[1]/div/section[1]/p[3]/text()")#语言
director = document.xpath("//*[@id=\"original_header\"]/div[2]/section/div[3]/ol/li[1]/p[1]/a/text()")# 导演
author = document.xpath("//*[@id=\"original_header\"]/div[2]/section/div[3]/ol/li/p[1]/a/text()")# 作者
starring = document.xpath("//*[@id=\"cast_scroller\"]/ol/li/a/div/img/@alt")#主演
slogan = document.xpath("//*[@id=\"original_header\"]/div[2]/section/div[3]/h3[1]/text()")#宣传语
introduction = document.xpath("//*[@id=\"original_header\"]/div[2]/section/div[3]/div/p/text()")#介绍
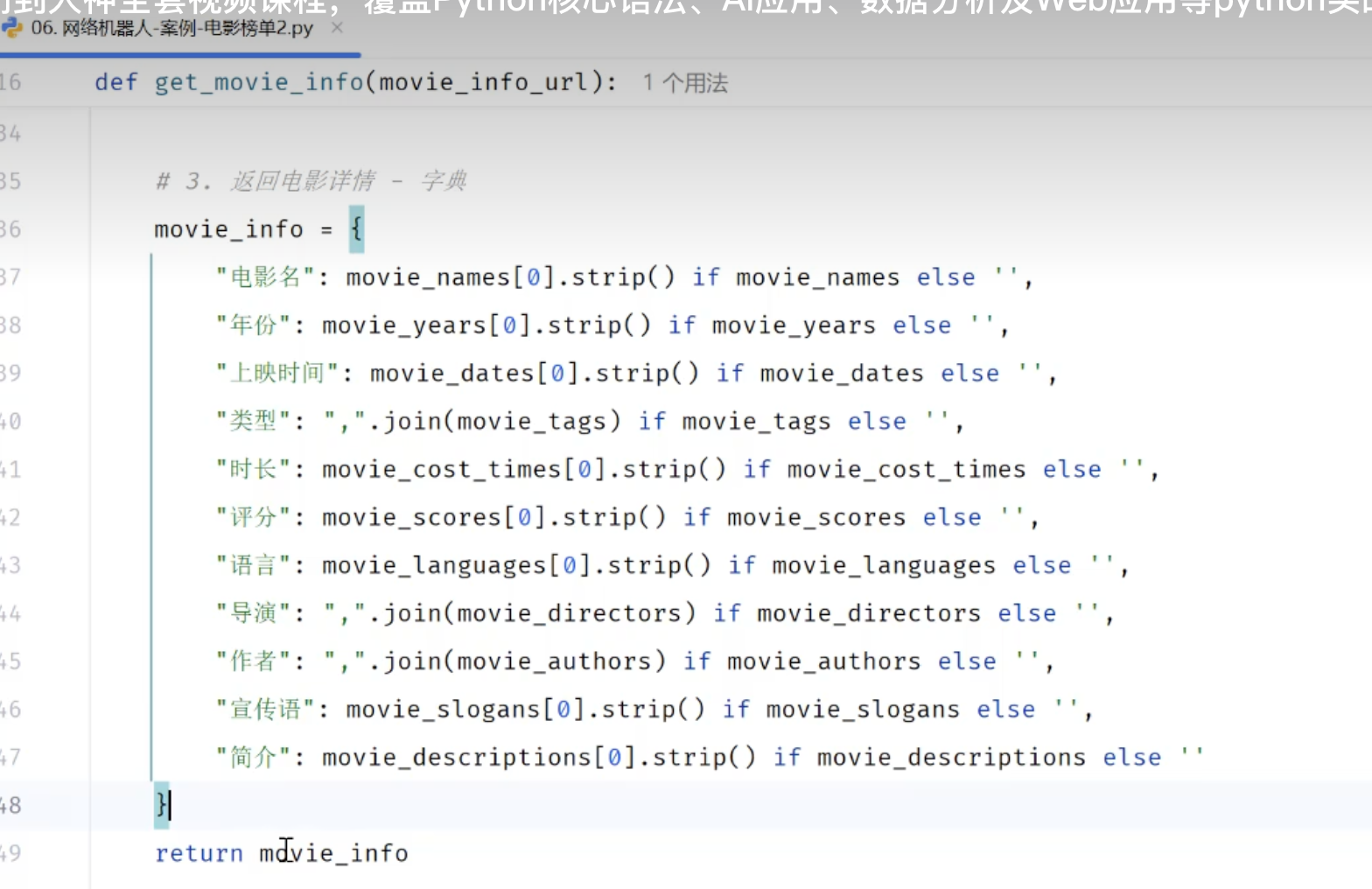
data = {
"电影名称":movie_name[0].strip() if movie_name else "",
"年份":year[0].strip() if year else "",
"上映时间":release_date[0].strip() if release_date else "",
"类型":",".join( type) if type else "",
"时长":time[0].strip() if time else "",
"评分":score[0].strip() if score else "",
"语言":language[0].strip() if language else "",
"导演":director[0].strip() if director else "",
"作者":",".join( author)if author else "",
"主演":starring[0].strip() if starring else "",
"宣传语":slogan[0].strip() if slogan else "",
"简介":introduction[0].strip() if introduction else "",
}
print(data)
return data
# 保存数据到csv
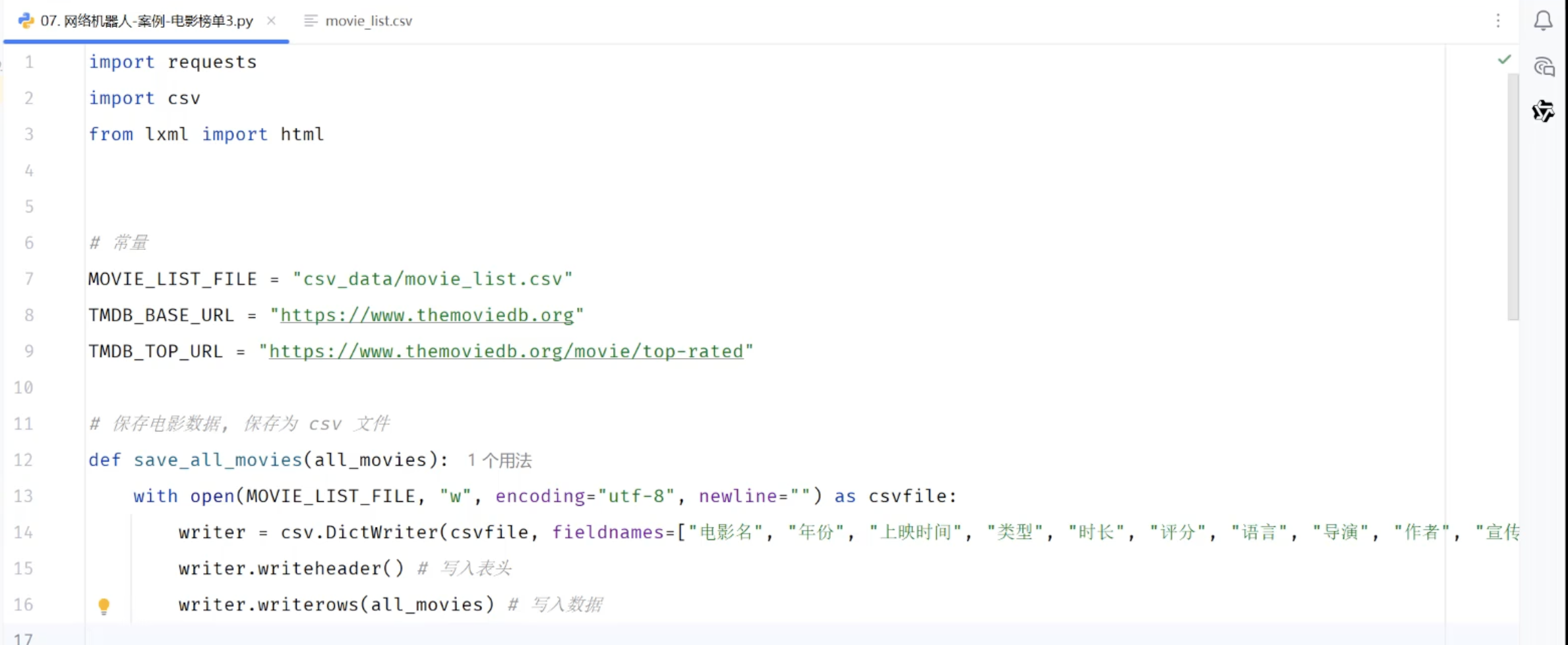
def save_to_csv(list_data):
with open("csv_data/top100.csv","w",encoding="utf-8",newline="") as f:
writer = csv.DictWriter(f,fieldnames=["电影名称","年份","上映时间","类型","时长","评分","语言","导演","作者","主演","宣传语","简介"])
writer.writeheader()
writer.writerows(list_data)
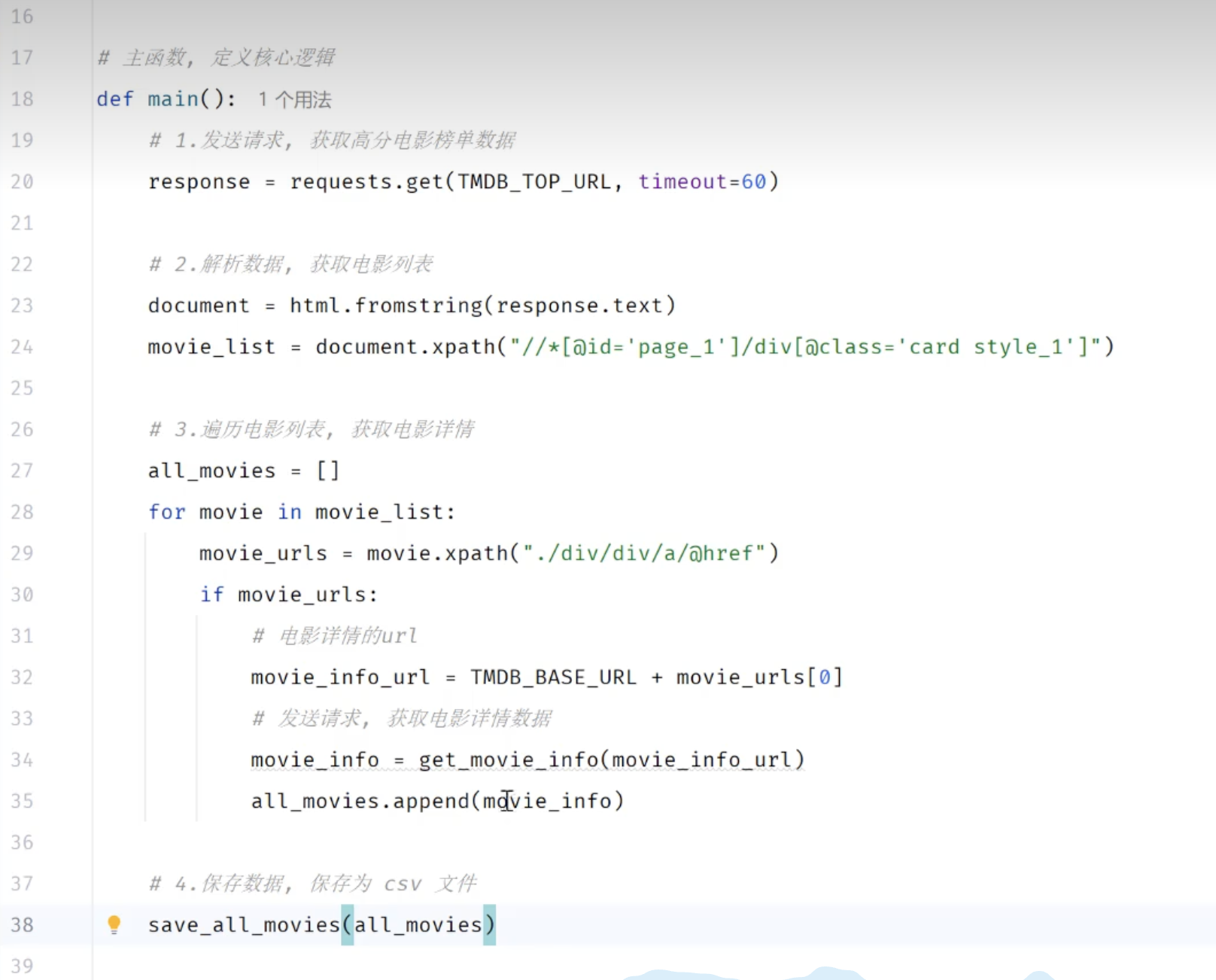
# 主函数,定义核心逻辑
def main():
# 获取高分电影榜单数据
print("开始爬取数据")
response_data=requests.get(TOP100_URL)
# 解析数据,获取电影列表
document = html.fromstring(response_data.text)
div_list = document.xpath("//*[@id=\"page_1\"]/div[1]")
data_list = []
for div in div_list:
hrefs = div.xpath("./div/div/div/div[2]/div/a/@href")
for href in hrefs:
detail_url = MOVIEDB_BASE_URL + href
# print(f"获取电影详情url:{detail_url}")
data_list.append(get_details(detail_url))
print("数据保存中...")
save_to_csv(data_list)
print("数据保存完毕")
# 测试
if __name__ == '__main__':
main()3.2.2 完善版本,加载更多数据
刚才的程序只获取了第一页的数据,下面完善,加载更多按钮,获取后面页的数据
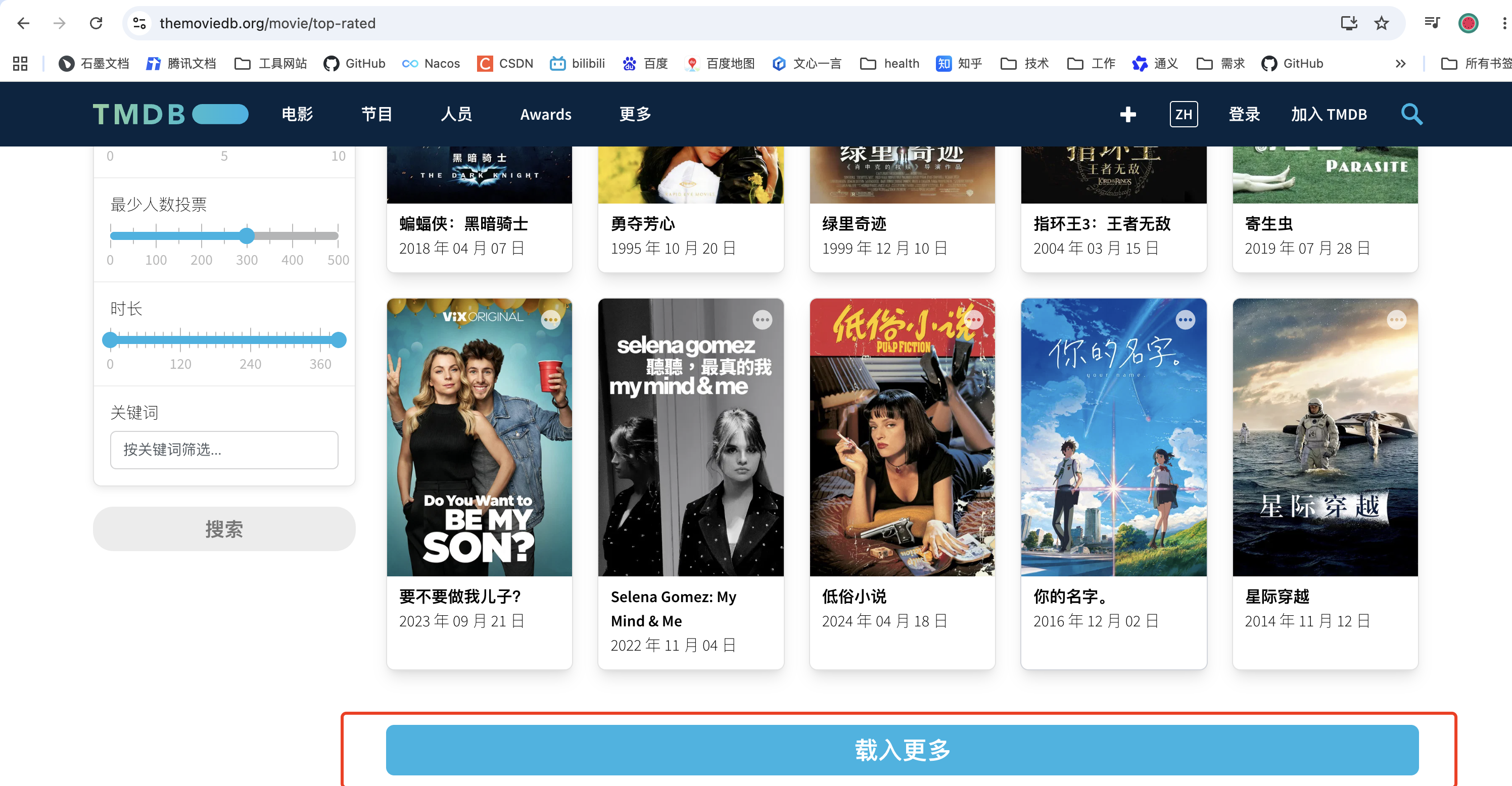
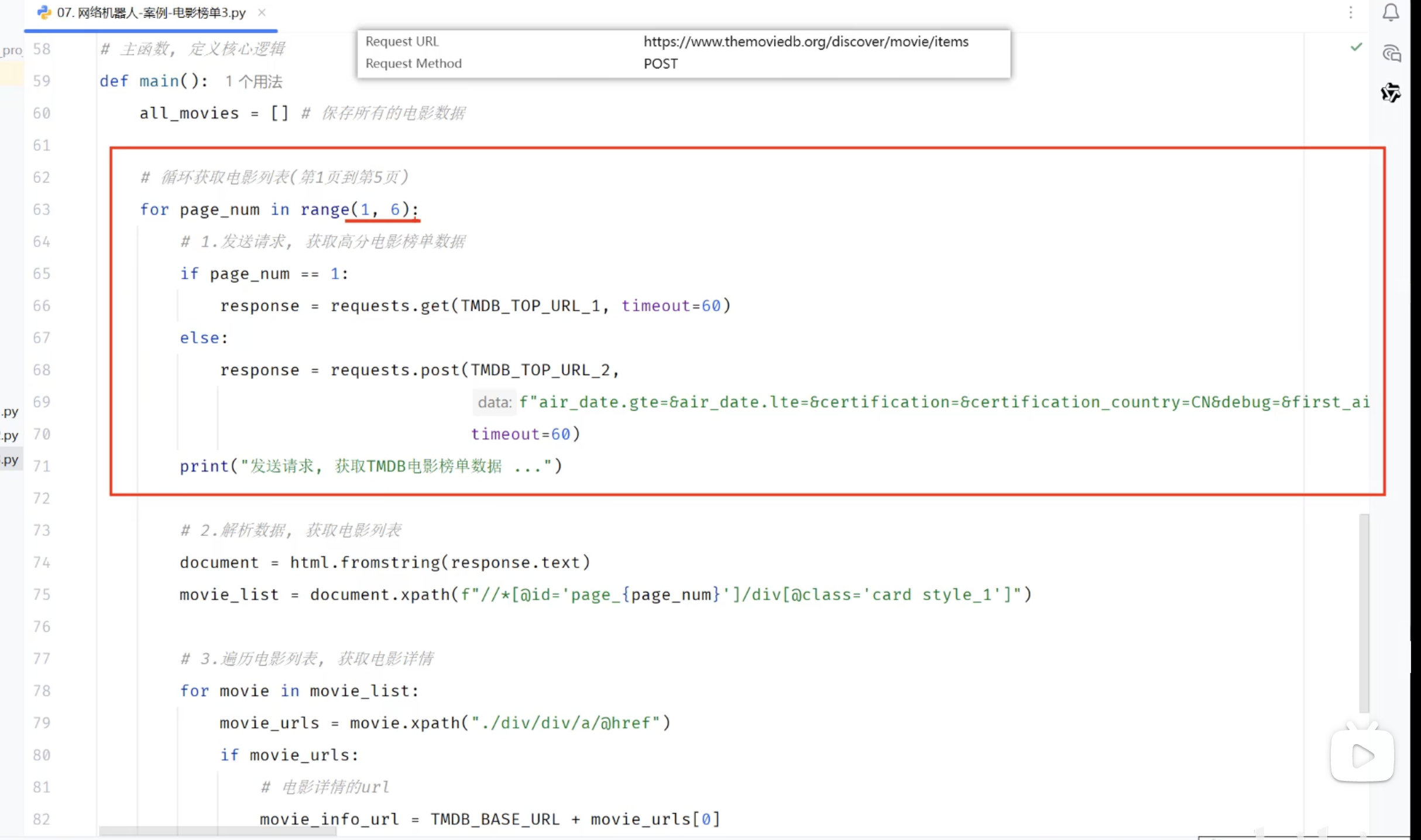
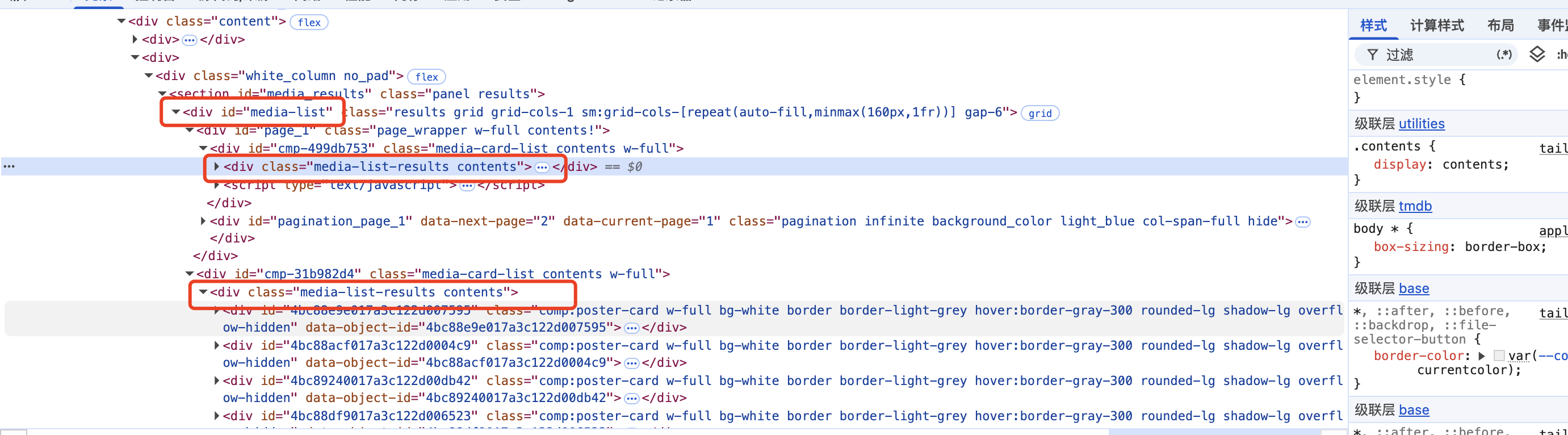
页面元素分析
python
import requests
from lxml import html
import csv
# 增加加载更多的请求,获取到top100的数据
# 请求地址
MOVIEDB_BASE_URL = "https://www.themoviedb.org"
TOP100_URL=MOVIEDB_BASE_URL+"/movie/top-rated" #第一页的访问地址 GET请求
TOP100_URL_2=MOVIEDB_BASE_URL+"/discover/movie/items" #加载更多的访问地址 POST请求
# 获取电影详情
def get_details(url):
response_data=requests.get(url)
document = html.fromstring(response_data.text)
movie_name = document.xpath("//*[@id=\"original_header\"]/div[2]/section/div[1]/h2/a/text()")#电影名称
year = document.xpath("//*[@id=\"original_header\"]/div[2]/section/div[1]/h2/span/text()")#年份
release_date = document.xpath("//*[@id=\"original_header\"]/div[2]/section/div[1]/div/span[2]/text()")#上映时间
type =document.xpath("//*[@id=\"original_header\"]/div[2]/section/div[1]/div/span[3]/a/text()")# 类型
time = document.xpath("//*[@id=\"original_header\"]/div[2]/section/div[1]/div/span[4]/text()")#时长
score = document.xpath("//*[@id=\"consensus_pill\"]/div/div[1]/div/div/@data-percent")#评分
language = document.xpath("//*[@id=\"media_v4\"]/div/div/div[2]/div/section/div[1]/div/section[1]/p[3]/text()")#语言
director = document.xpath("//*[@id=\"original_header\"]/div[2]/section/div[3]/ol/li[1]/p[1]/a/text()")# 导演
author = document.xpath("//*[@id=\"original_header\"]/div[2]/section/div[3]/ol/li/p[1]/a/text()")# 作者
starring = document.xpath("//*[@id=\"cast_scroller\"]/ol/li/a/div/img/@alt")#主演
slogan = document.xpath("//*[@id=\"original_header\"]/div[2]/section/div[3]/h3[1]/text()")#宣传语
introduction = document.xpath("//*[@id=\"original_header\"]/div[2]/section/div[3]/div/p/text()")#介绍
data = {
"电影名称":movie_name[0].strip() if movie_name else "",
"年份":year[0].strip() if year else "",
"上映时间":release_date[0].strip() if release_date else "",
"类型":",".join( type) if type else "",
"时长":time[0].strip() if time else "",
"评分":score[0].strip() if score else "",
"语言":language[0].strip() if language else "",
"导演":director[0].strip() if director else "",
"作者":",".join( author)if author else "",
"主演":starring[0].strip() if starring else "",
"宣传语":slogan[0].strip() if slogan else "",
"简介":introduction[0].strip() if introduction else "",
}
# print(data)
return data
# 保存数据到csv
def save_to_csv(list_data):
with open("csv_data/top100.csv","w",encoding="utf-8",newline="") as f:
writer = csv.DictWriter(f,fieldnames=["电影名称","年份","上映时间","类型","时长","评分","语言","导演","作者","主演","宣传语","简介"])
writer.writeheader()
writer.writerows(list_data)
# 主函数,定义核心逻辑
def main():
data_list = [] #爬取数据结果
# 循环获取电影列表
for i in range(1,6):
print(f"开始爬取第{i}页数据")
if i==1:
response_data = requests.get(TOP100_URL)
else:
response_data = requests.post(TOP100_URL_2,f"air_date.gte=&air_date.lte=&certification=&certification_country=CN&debug=&first_air_date.gte=&first_air_date.lte=&include_adult=false&include_softcore=false&latest_ceremony.gte=&latest_ceremony.lte=&page={i}&primary_release_date.gte=&primary_release_date.lte=®ion=&release_date.gte=&release_date.lte=2026-12-14&show_me=everything&sort_by=vote_average.desc&vote_average.gte=0&vote_average.lte=10&vote_count.gte=300&watch_region=CN&with_genres=&with_keywords=&with_networks=&with_origin_country=&with_original_language=&with_watch_monetization_types=&with_watch_providers=&with_release_type=&with_runtime.gte=0&with_runtime.lte=400")
# 解析数据,获取电影列表
document = html.fromstring(response_data.text)
div_list = document.xpath("//*[@id=\"media-list\"]/*/div/div[@class=\"media-list-results contents\"]")
# 获取电影详情
for div in div_list:
hrefs = div.xpath("./div/div/div/a/@href")
for href in hrefs:
detail_url = MOVIEDB_BASE_URL + href
print(f"获取电影详情url:{detail_url}")
data_list.append(get_details(detail_url))
print("数据保存中...")
save_to_csv(data_list)
print("数据保存完毕!")
# 测试
if __name__ == '__main__':
main()3.3.数据清洗
3.3.1 正则入门

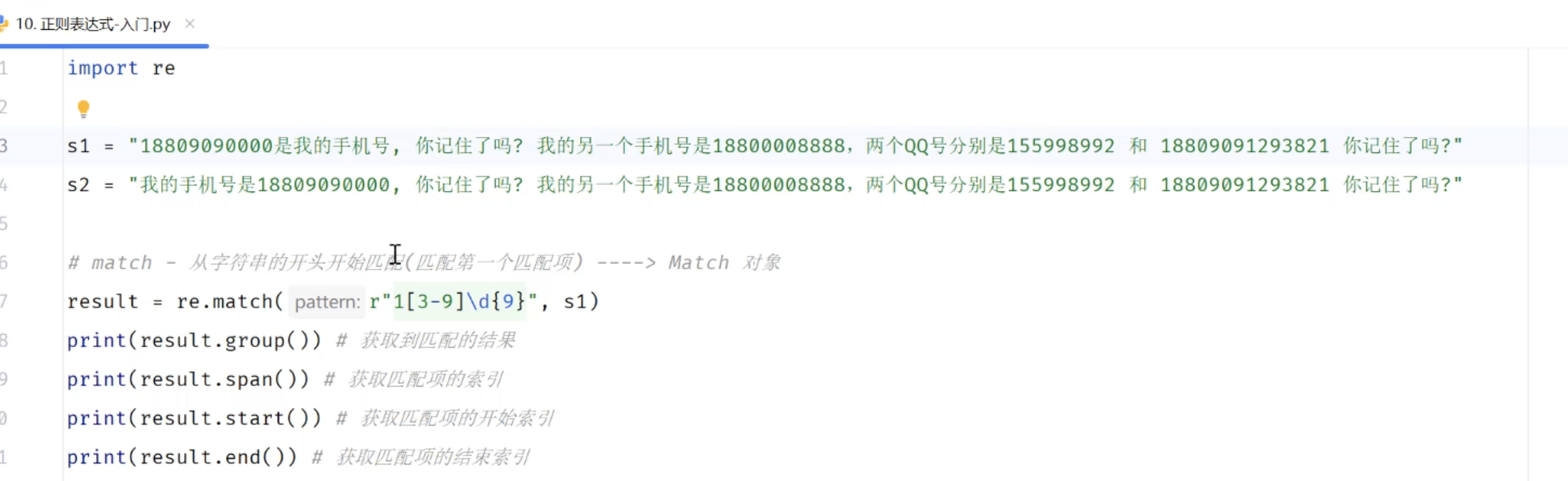
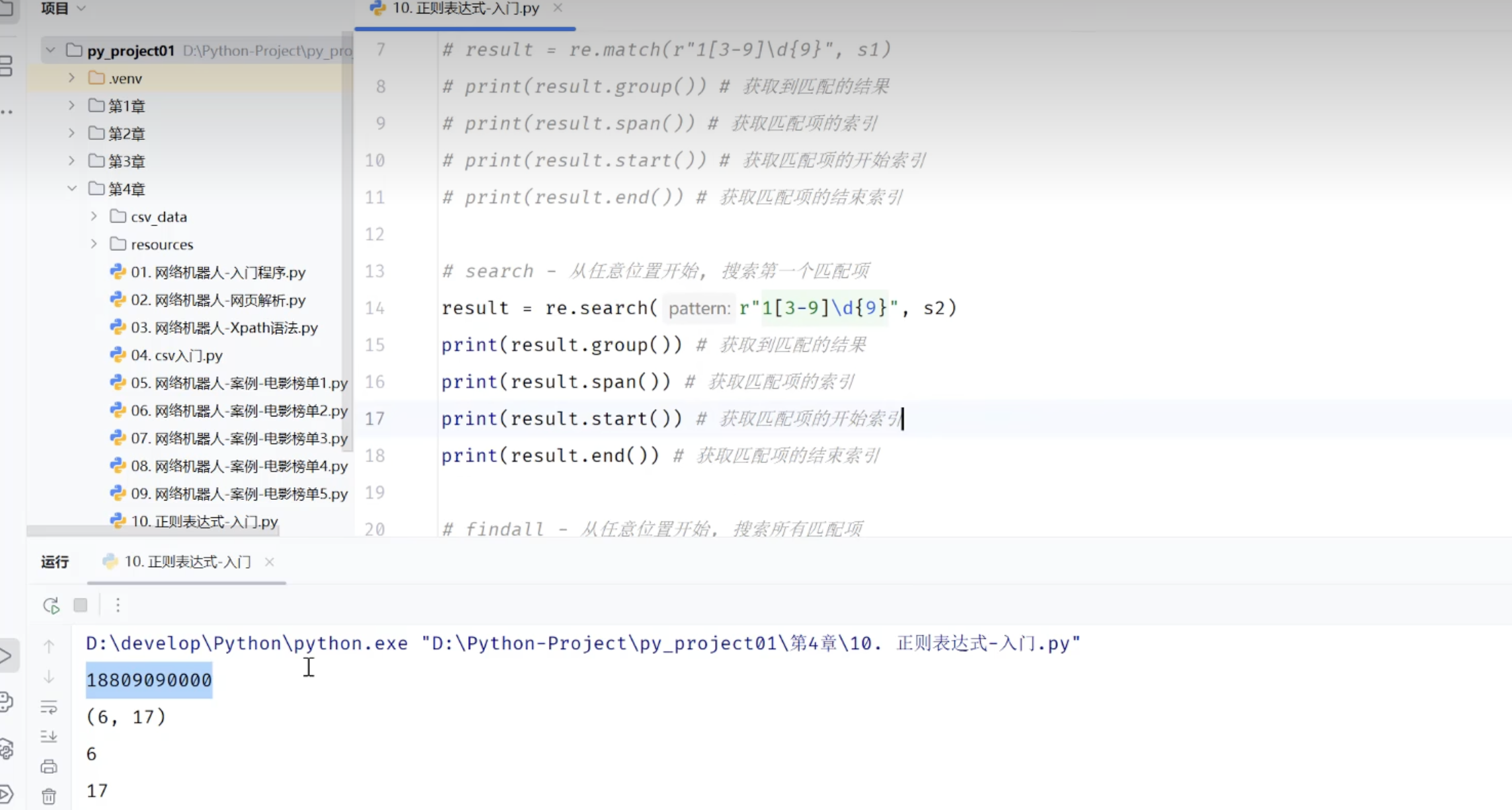
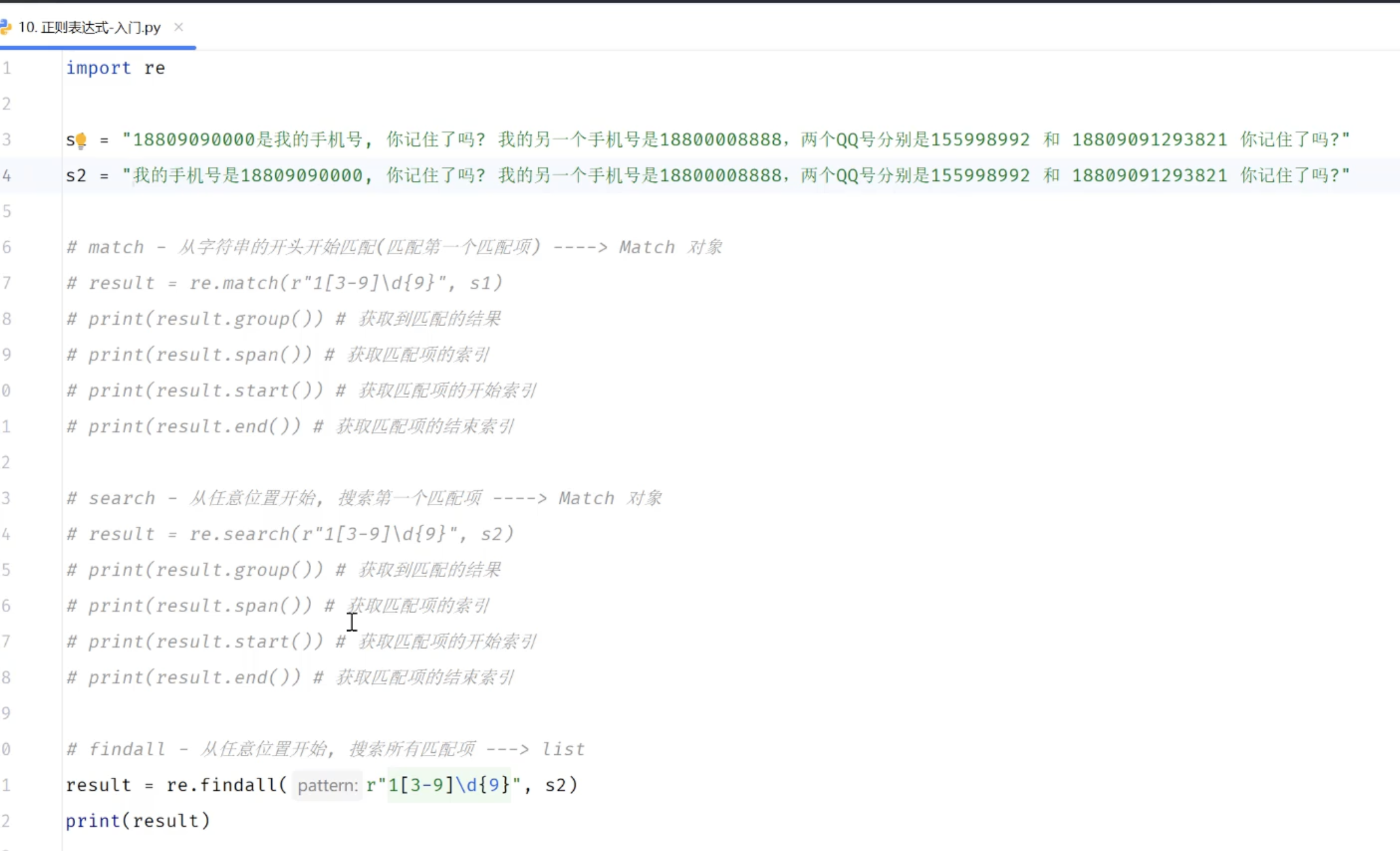

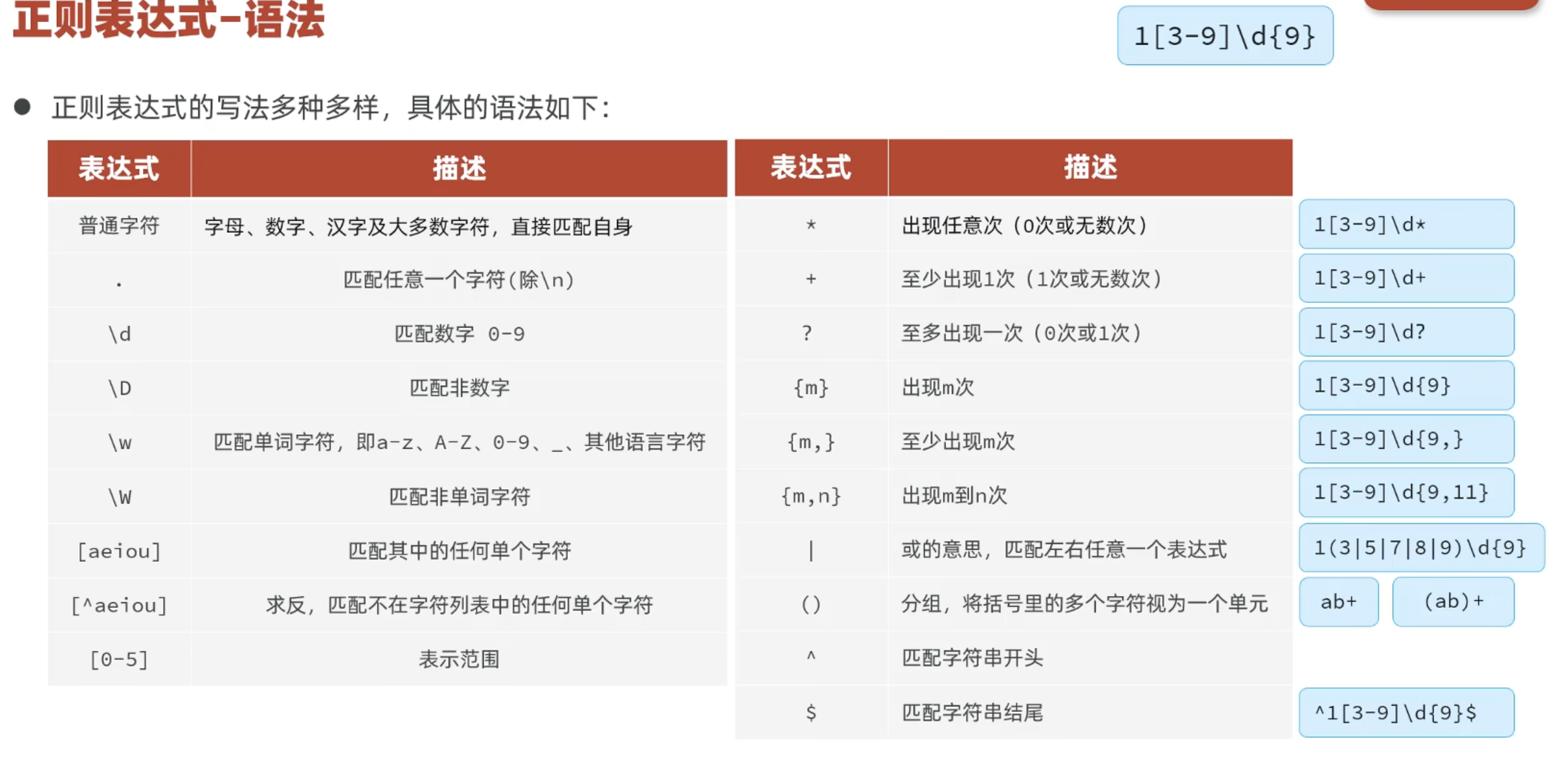
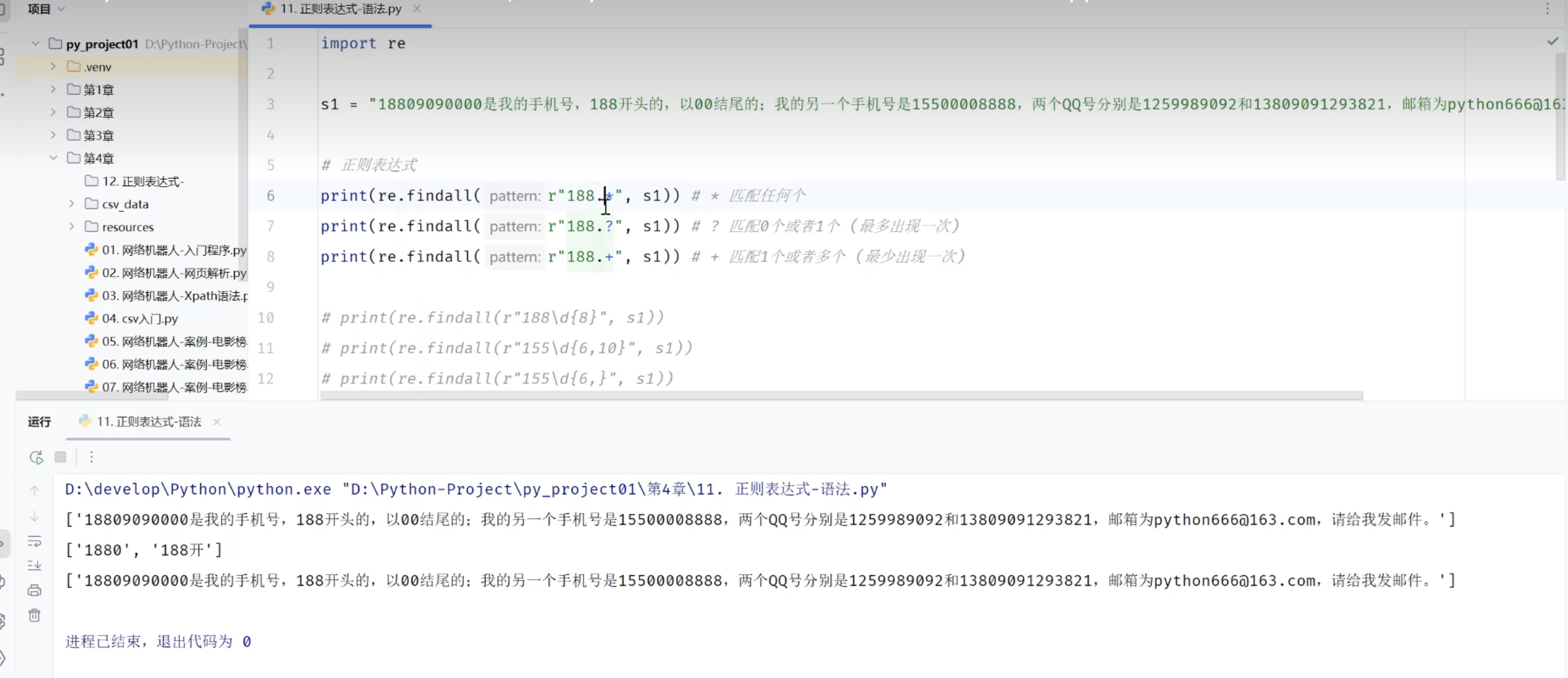
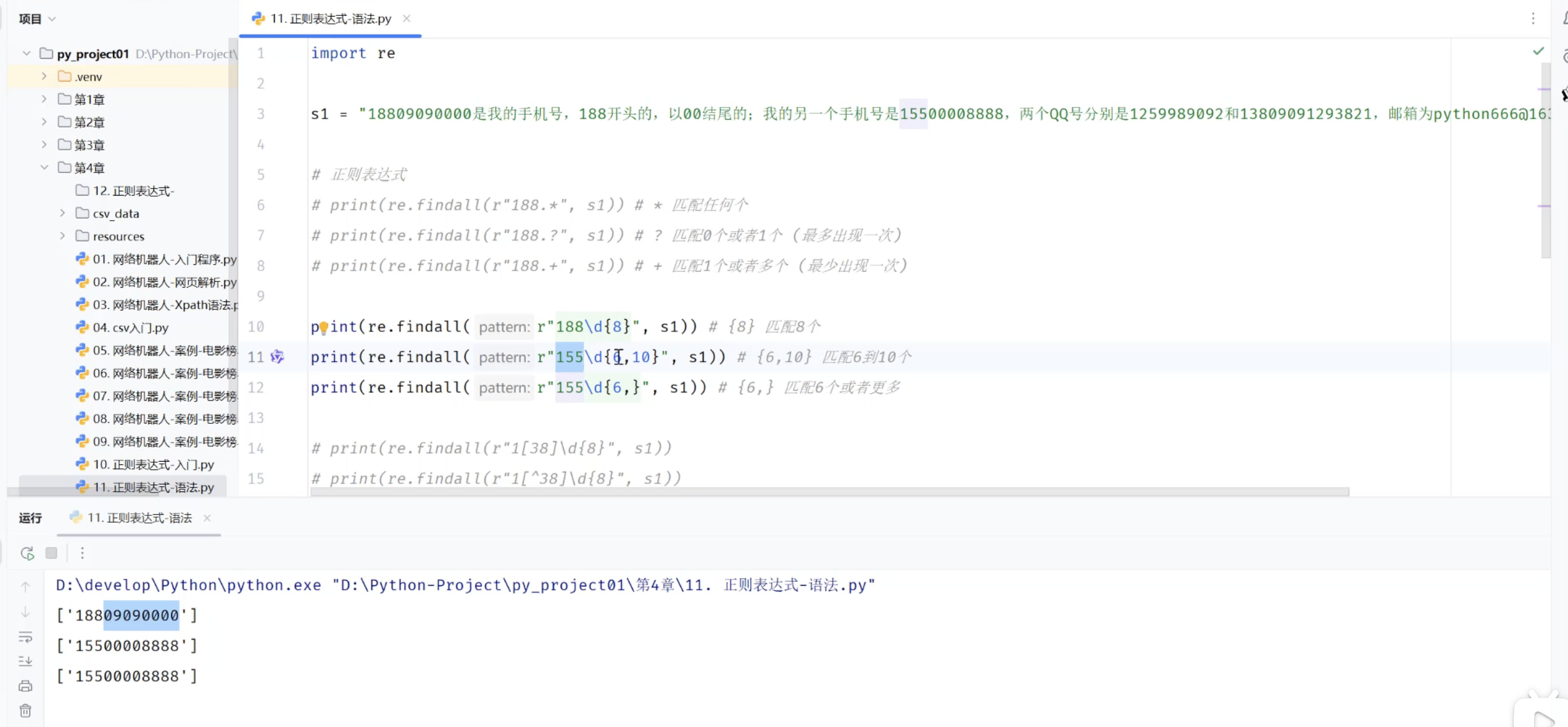
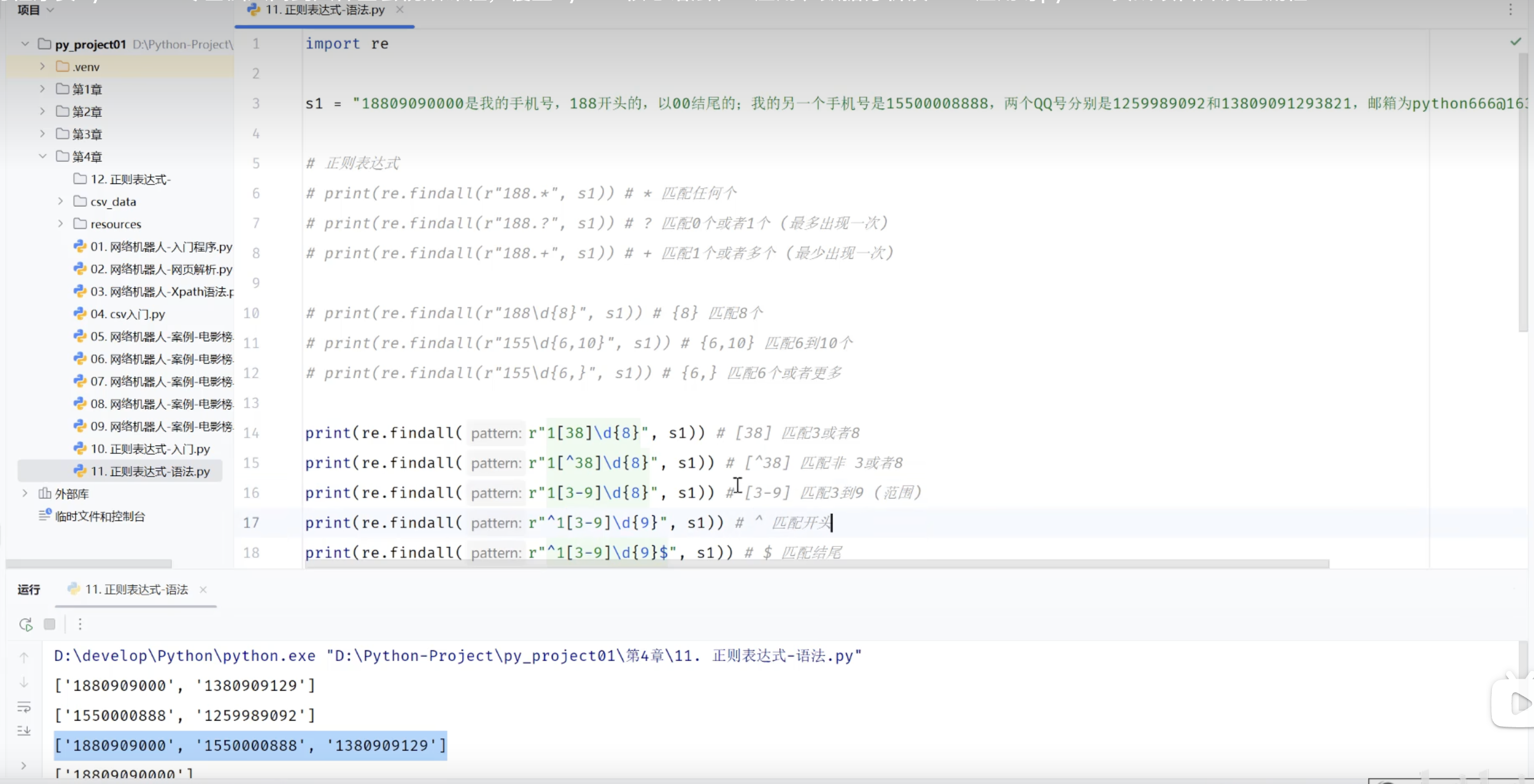
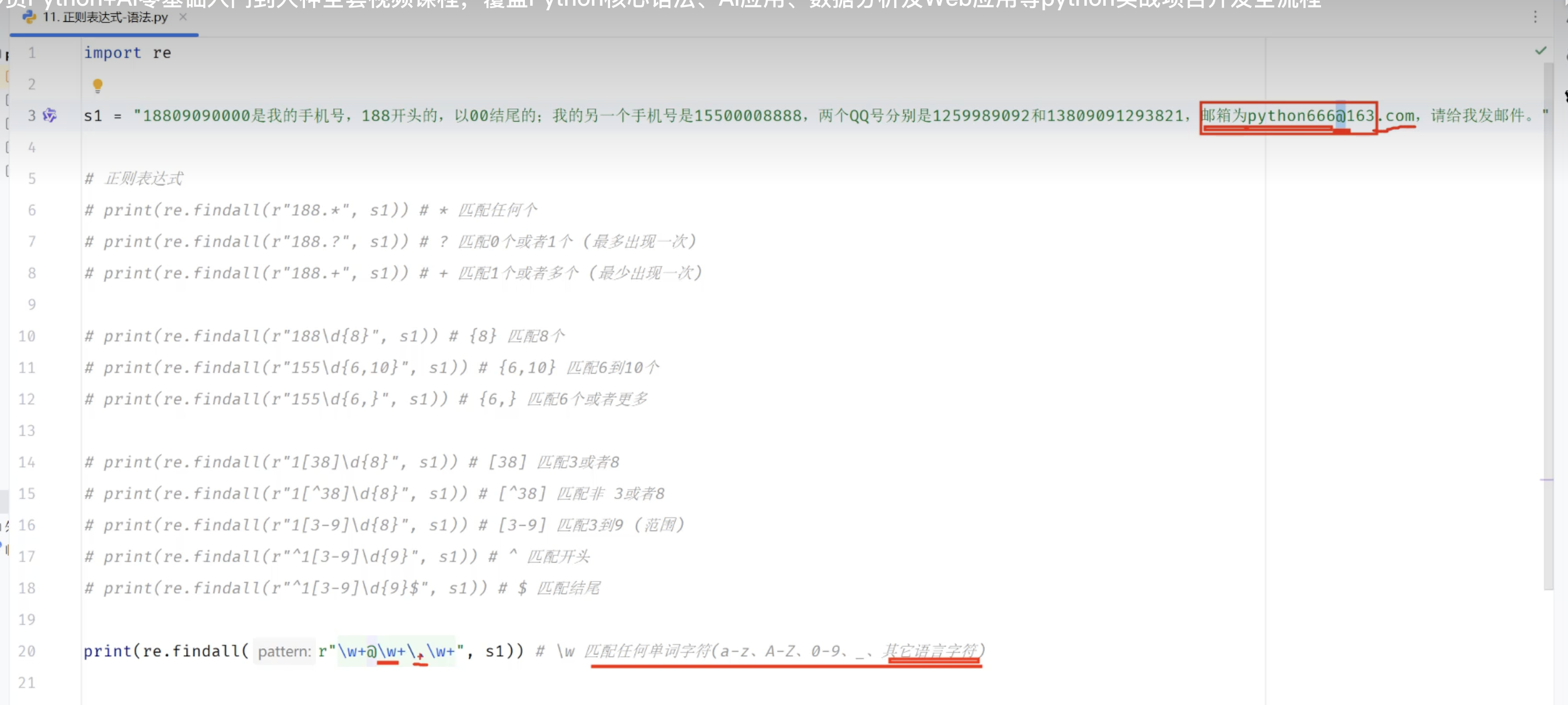
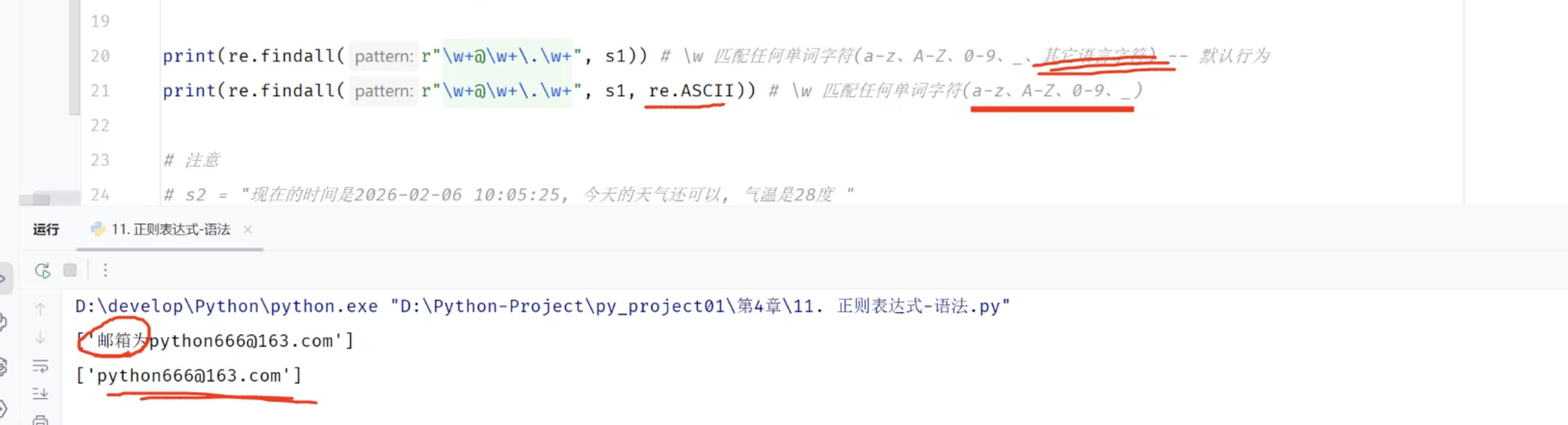
3.3.2 正则表达式
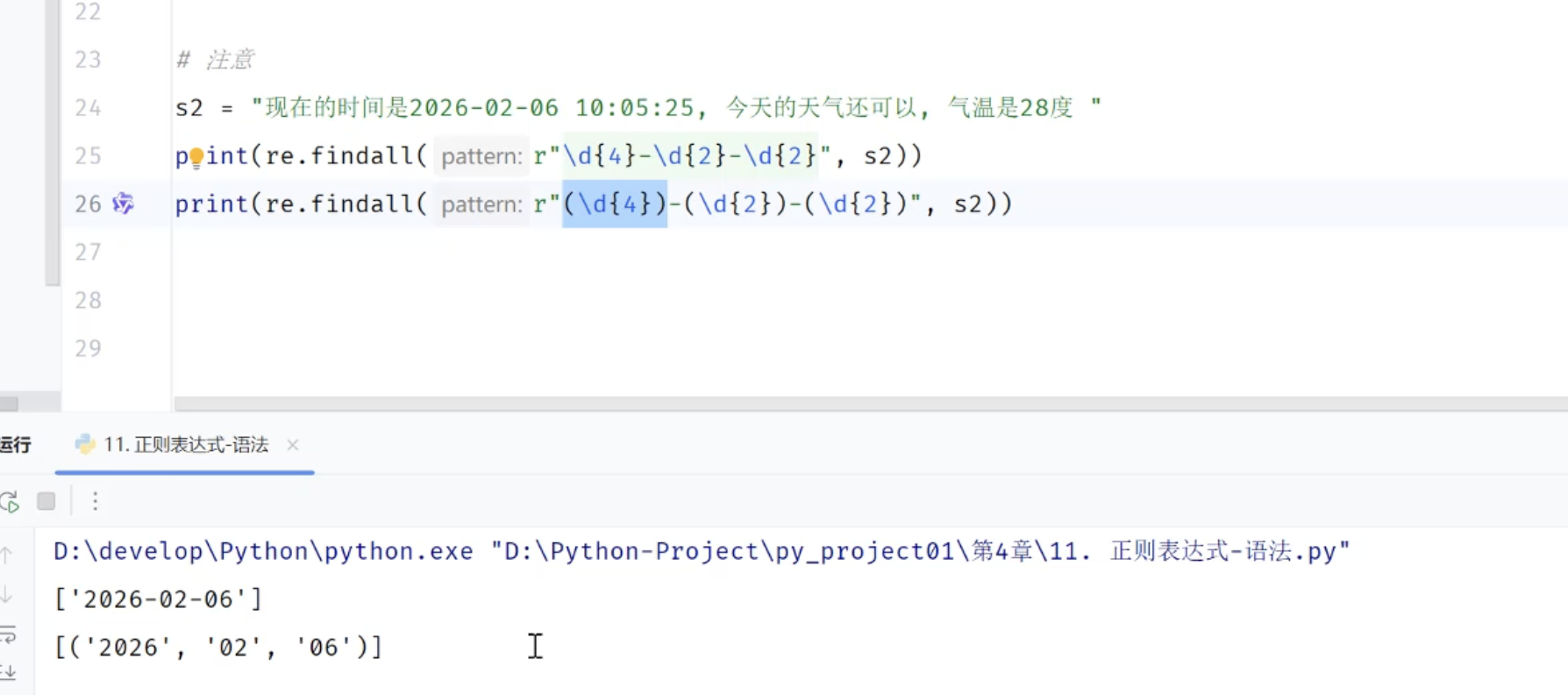

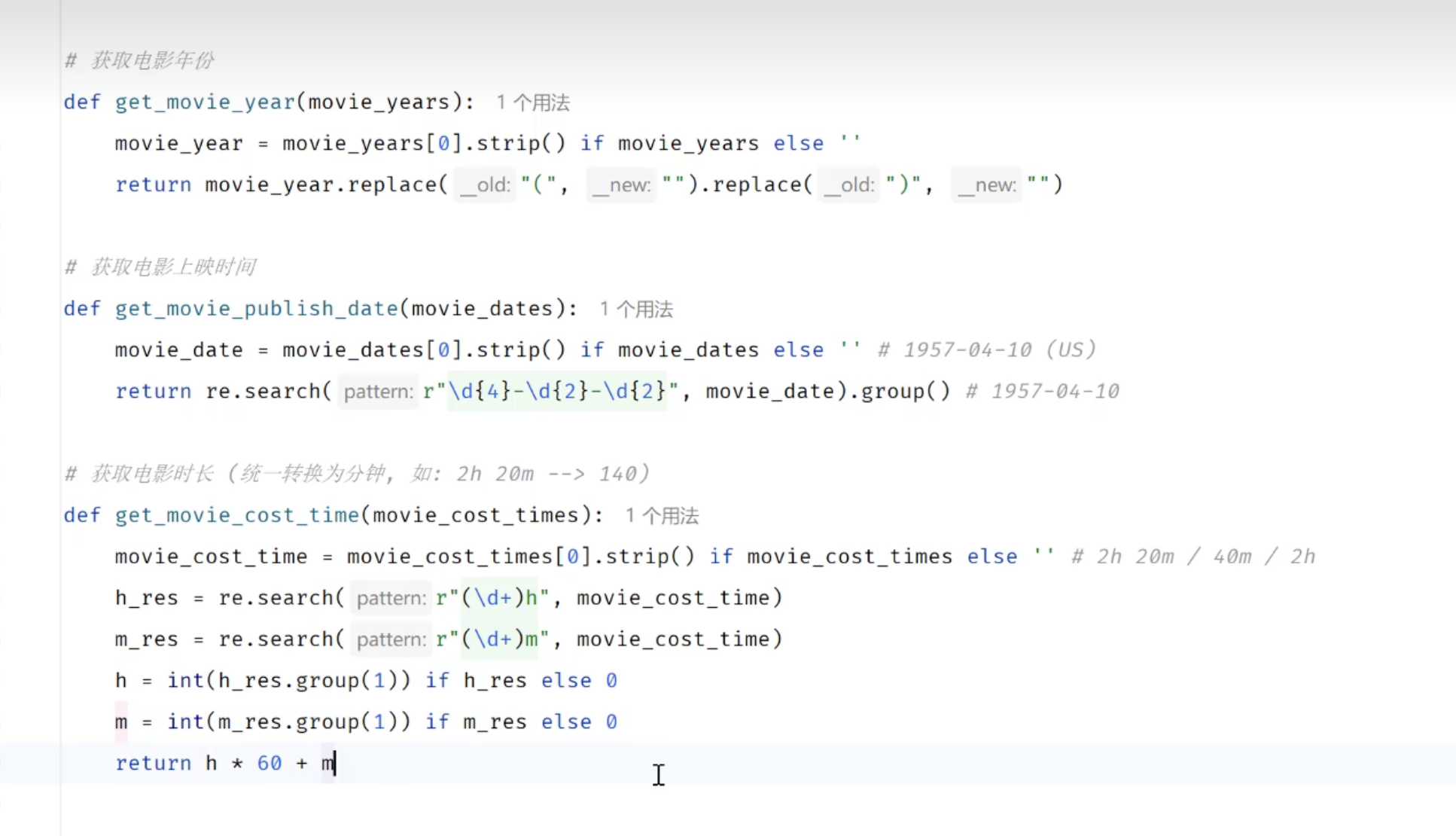
3.3.3 数据清洗-程序优化
python
import requests
from lxml import html
import csv
import re
from streamlit.components.v1 import iframe
# 增加加载更多的请求,获取到top100的数据
# 请求地址
MOVIEDB_BASE_URL = "https://www.themoviedb.org"
TOP100_URL=MOVIEDB_BASE_URL+"/movie/top-rated" #第一页的访问地址 GET请求
TOP100_URL_2=MOVIEDB_BASE_URL+"/discover/movie/items" #加载更多的访问地址 POST请求
# 获取电影年份
def get_movie_year(year):
year = year[0].strip() if year else ""
return re.findall(r"\d{4}",year)[0]
# 获取电影上映时间
def get_movie_release_date(release_date):
release_date = release_date[0].strip() if release_date else ""
return re.match(r"\d{4}-\d{2}-\d{2}",release_date).group()
# 获取电影时长
def get_movie_time(time):
time = time[0].strip() if time else ""
hours = re.search(r"(\d*)h",time)
total_minites = int(hours.group(1)) * 60 if hours else 0
minitues = re.search(r"(\d*)m", time)
total_minites +=int(minitues.group(1)) if minitues else 0
return total_minites
# 获取电影详情
def get_details(url):
response_data=requests.get(url)
document = html.fromstring(response_data.text)
movie_name = document.xpath("//*[@id=\"original_header\"]/div[2]/section/div[1]/h2/a/text()")#电影名称
year = document.xpath("//*[@id=\"original_header\"]/div[2]/section/div[1]/h2/span/text()")#年份
# 修改获取元素的xpath,修复某些数据获取不到的问题
# release_date = document.xpath("//*[@id=\"original_header\"]/div[2]/section/div[1]/div/span[2]/text()")#上映时间
# type =document.xpath("//*[@id=\"original_header\"]/div[2]/section/div[1]/div/span[3]/a/text()")# 类型
# time = document.xpath("//*[@id=\"original_header\"]/div[2]/section/div[1]/div/span[4]/text()")#时长
release_date = document.xpath("//*[@id=\"original_header\"]/div[2]/section/div[1]/div/span[@class=\"release\"]/text()")#上映时间
type =document.xpath("//*[@id=\"original_header\"]/div[2]/section/div[1]/div/span[@class=\"genres\"]/a/text()")# 类型
time = document.xpath("//*[@id=\"original_header\"]/div[2]/section/div[1]/div/span[@class=\"runtime\"]/text()")#时长
score = document.xpath("//*[@id=\"consensus_pill\"]/div/div[1]/div/div/@data-percent")#评分
language = document.xpath("//*[@id=\"media_v4\"]/div/div/div[2]/div/section/div[1]/div/section[1]/p[3]/text()")#语言
director = document.xpath("//*[@id=\"original_header\"]/div[2]/section/div[3]/ol/li[1]/p[1]/a/text()")# 导演
author = document.xpath("//*[@id=\"original_header\"]/div[2]/section/div[3]/ol/li/p[1]/a/text()")# 作者
starring = document.xpath("//*[@id=\"cast_scroller\"]/ol/li/a/div/img/@alt")#主演
slogan = document.xpath("//*[@id=\"original_header\"]/div[2]/section/div[3]/h3[1]/text()")#宣传语
introduction = document.xpath("//*[@id=\"original_header\"]/div[2]/section/div[3]/div/p/text()")#介绍
data = {
"电影名称":movie_name[0].strip() if movie_name else "",
"年份":get_movie_year(year),
"上映时间":get_movie_release_date(release_date),
"类型":",".join( type) if type else "",
"时长":get_movie_time(time),
"评分":score[0].strip() if score else "",
"语言":language[0].strip() if language else "",
"导演":director[0].strip() if director else "",
"作者":",".join( author)if author else "",
"主演":starring[0].strip() if starring else "",
"宣传语":slogan[0].strip() if slogan else "",
"简介":introduction[0].strip() if introduction else "",
}
# print(data)
return data
# 保存数据到csv
def save_to_csv(list_data):
with open("csv_data/top100-1.csv","w",encoding="utf-8",newline="") as f:
writer = csv.DictWriter(f,fieldnames=["电影名称","年份","上映时间","类型","时长","评分","语言","导演","作者","主演","宣传语","简介"])
writer.writeheader()
writer.writerows(list_data)
# 主函数,定义核心逻辑
def main():
data_list = [] #爬取数据结果
# 循环获取电影列表
for i in range(1,6):
print(f"开始爬取第{i}页数据")
if i==1:
response_data = requests.get(TOP100_URL)
else:
response_data = requests.post(TOP100_URL_2,f"air_date.gte=&air_date.lte=&certification=&certification_country=CN&debug=&first_air_date.gte=&first_air_date.lte=&include_adult=false&include_softcore=false&latest_ceremony.gte=&latest_ceremony.lte=&page={i}&primary_release_date.gte=&primary_release_date.lte=®ion=&release_date.gte=&release_date.lte=2026-12-14&show_me=everything&sort_by=vote_average.desc&vote_average.gte=0&vote_average.lte=10&vote_count.gte=300&watch_region=CN&with_genres=&with_keywords=&with_networks=&with_origin_country=&with_original_language=&with_watch_monetization_types=&with_watch_providers=&with_release_type=&with_runtime.gte=0&with_runtime.lte=400")
# 解析数据,获取电影列表
document = html.fromstring(response_data.text)
div_list = document.xpath("//*[@id=\"media-list\"]/*/div/div[@class=\"media-list-results contents\"]")
# 获取电影详情
for div in div_list:
hrefs = div.xpath("./div/div/div/a/@href")
for href in hrefs:
detail_url = MOVIEDB_BASE_URL + href
print(f"获取电影详情url:{detail_url}")
data_list.append(get_details(detail_url))
print("数据保存中...")
save_to_csv(data_list)
print("数据保存完毕!")
# 测试
if __name__ == '__main__':
main()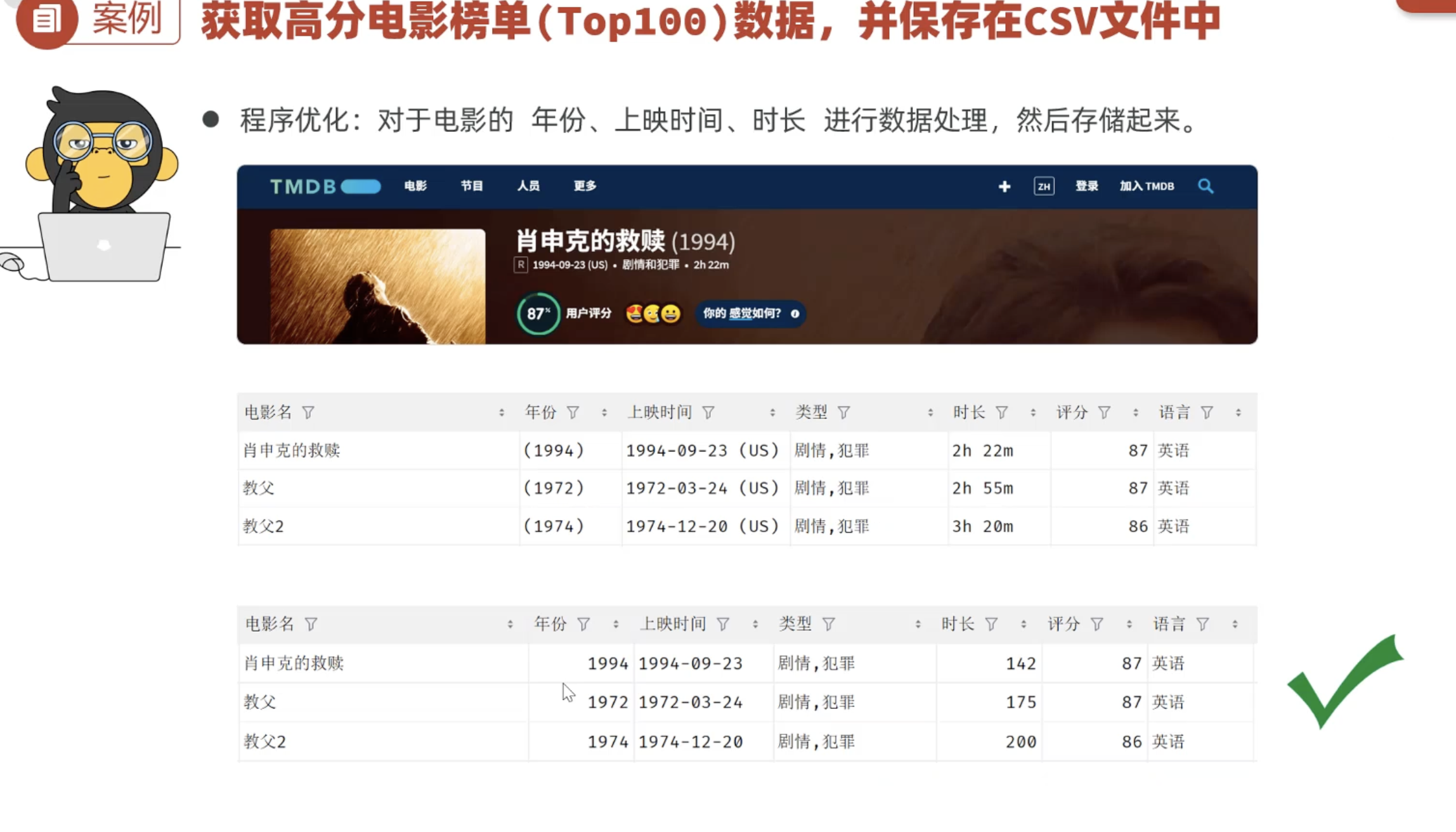
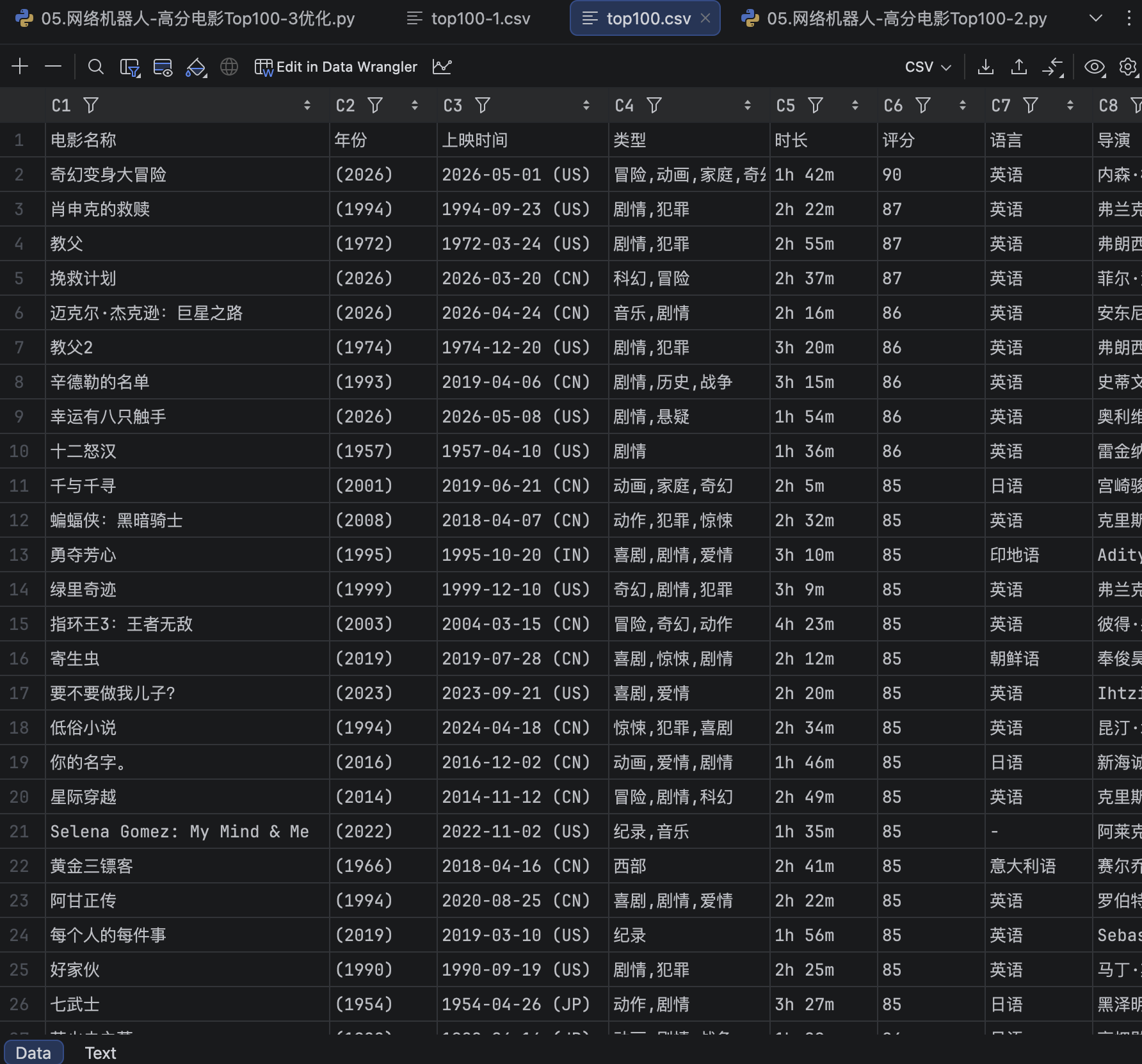
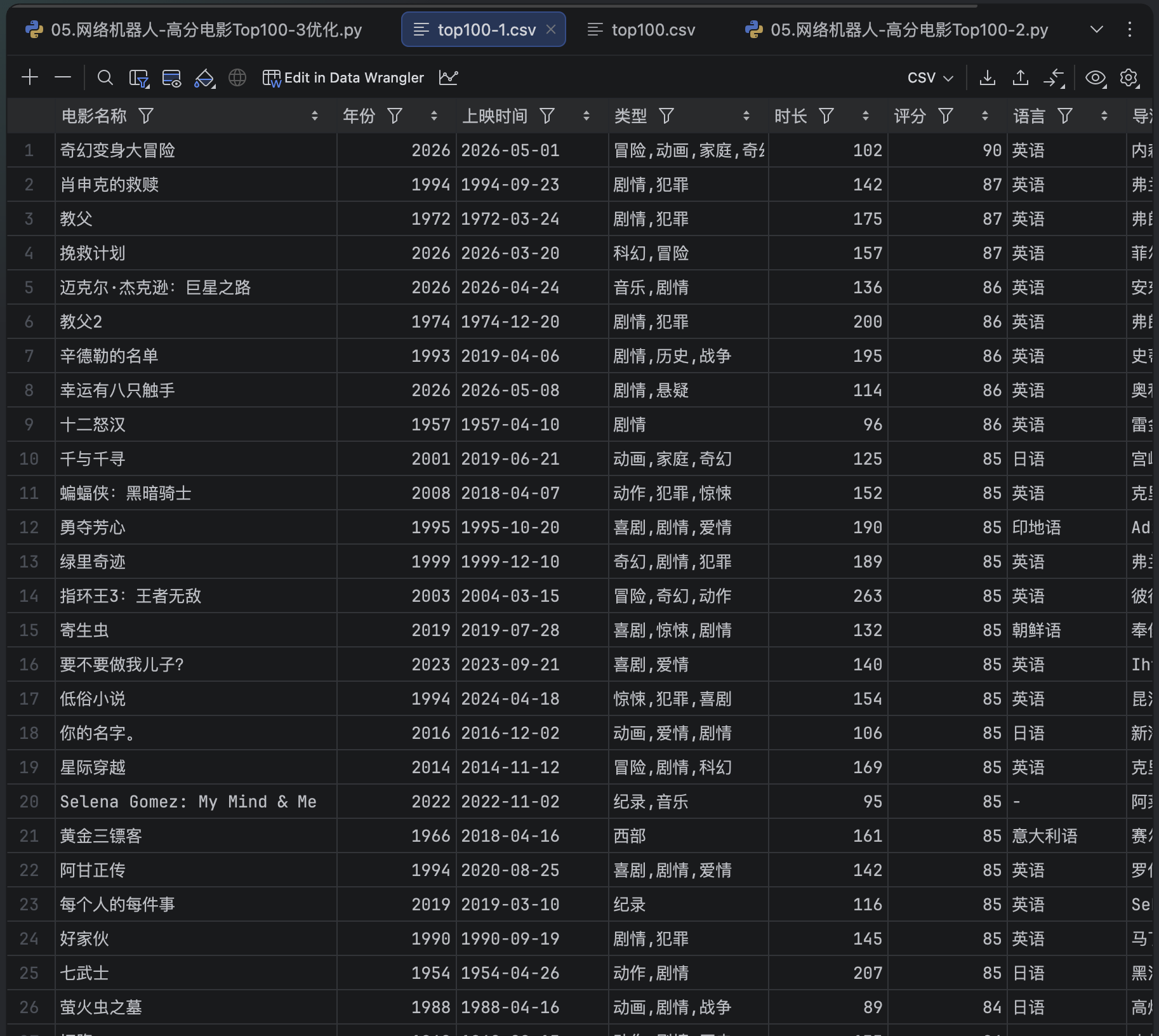
优化前后的数据分别如下: