基于Anthropic+OpenAI官方指南:别吹全自主Agent了,生产落地99%是Workflow为主
本文100%基于两篇官方落地指南:
- Anthropic《Building Effective Agents》(总结数十个行业客户的Agent落地经验)
- OpenAI《Agents 101: A Developer's Guide to Building Agents》(OpenAI官方Agent开发最佳实践)
一、先看官方明确定义:90%的"Agent"都是伪概念
首先我们直接引用Anthropic原文对两类智能体系统的严格定义,这是所有讨论的基础,也是市面上90%概念混淆的根源:
✅ Workflow(工作流系统) :LLM和工具通过预定义的代码路径进行编排的系统。所有步骤、分支、流转规则全部由开发者提前设定,LLM仅负责单个节点的内容处理,不决定流程走向。
✅ Agent(智能体系统) :LLM动态主导自身执行流程与工具使用、自主控制任务完成方式的系统。无需预设全量执行步骤,LLM自主规划路径、选择工具、纠错重试、判断终止。
OpenAI在《Agents 101》中补充了Agent的三个核心必要组件,缺一不可:
- Model:负责推理和决策的大模型
- Tools:外部工具能力,用于和环境交互
- Instructions:明确的行为规则和边界定义
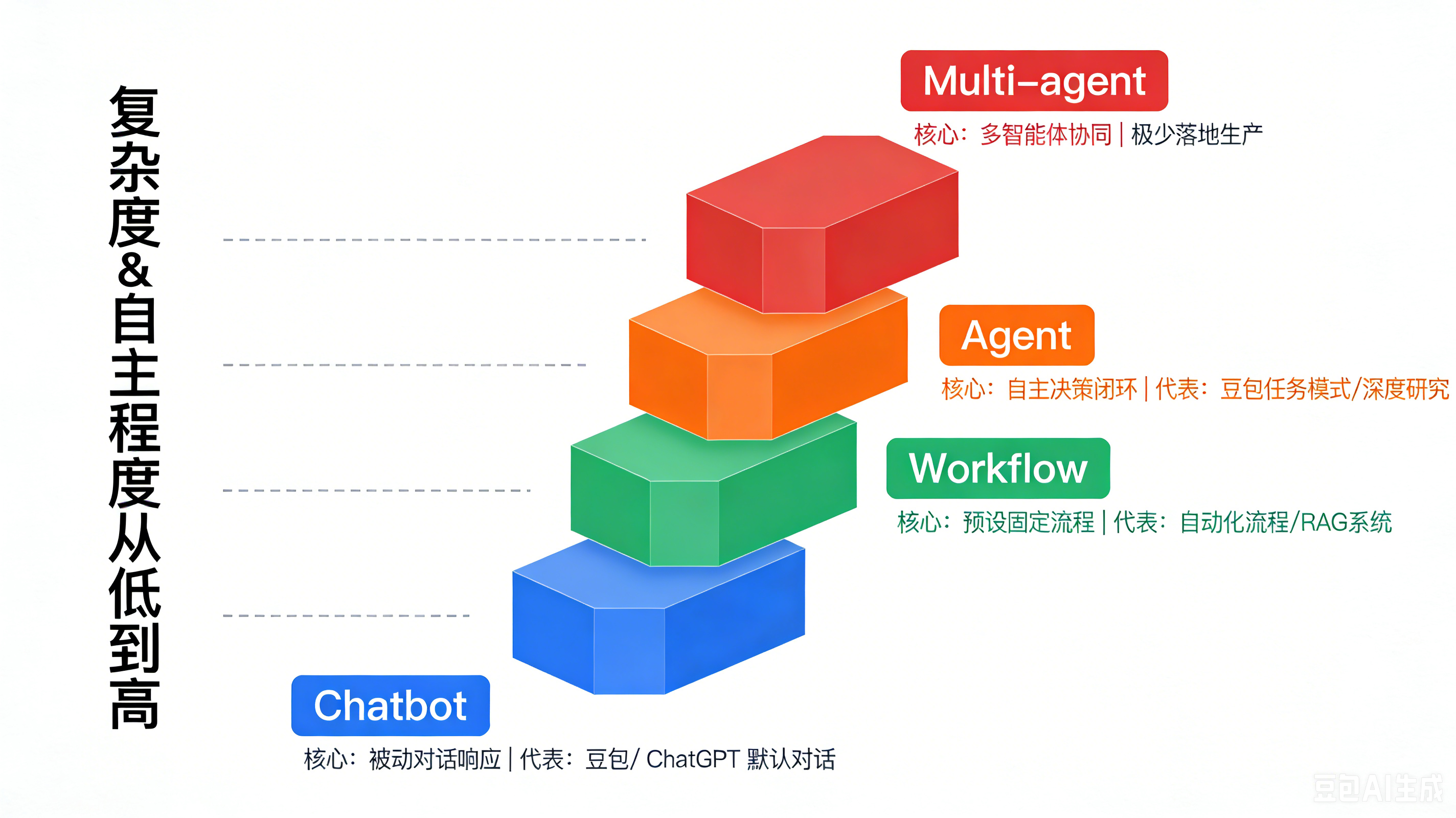
对应到我们熟悉的产品,直接对号入座:
| 产品形态 | 所属类别 | 官方定义匹配 |
|---|---|---|
| 豆包/DeepSeek/ChatGPT 默认网页对话 | Chatbot(不属于智能体系统) | 仅被动响应用户输入,没有流程控制权,不满足Workflow或Agent的定义 |
| 豆包任务模式/ ChatGPT Deep Research | 专用Agent | LLM自主拆解步骤、调用工具、判断终止,符合Agent的官方定义 |
| Dify/Coze 低代码搭建的自动化流程 | Workflow | 所有步骤、分支全部预设,符合Workflow的官方定义 |
| Devin / Claude Code | 垂直领域专用Agent | 自主闭环完成开发任务,符合Agent定义 |
官方明确澄清误区:能调用工具不等于Agent。如果工具调用是单次触发、流程是固定的,那只是带工具增强的Chatbot或Workflow,不是Agent。
二、Anthropic官方核心结论:能不用Agent就绝对不要用
这是两篇官方指南最反常识、也最核心的落地原则,我之前的版本没有重点强调,这是最大的疏漏:
📌 Anthropic原文原话:
"We recommend finding the simplest solution possible, and only increasing complexity when needed. This might mean not building agentic systems at all. "
(我们永远优先选择最简单的可行方案,仅在必要时增加复杂度,这可能意味着完全不用智能体系统)
官方给出的「绝对不要用Agent」的场景:
-
任务流程固定、可完全预测
官方明确说明:对于定义清晰的任务,Workfl
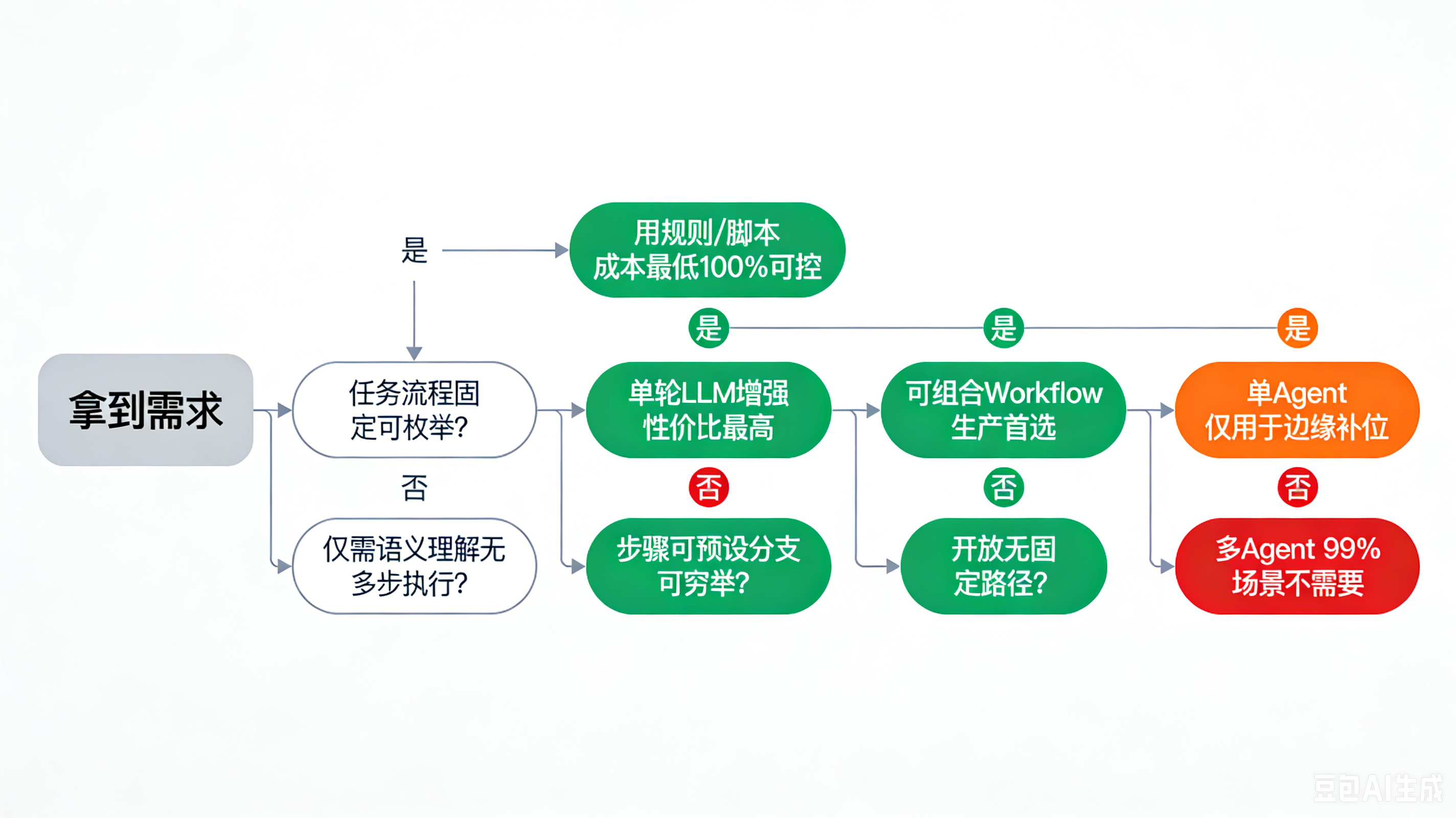
ow能提供更好的可预测性、一致性和成本控制,Agent的自主决策只会引入不必要的不确定性。
比如固定格式报表生成、常规数据统计、标准化表单处理,普通脚本或规则就能解决的,绝对不要用Agent。
-
对结果确定性、合规性要求极高
Agent的自主决策天然带有波动,同一条指令可能走出不同路径,还可能出现错误累积。金融、合规、医疗等对流程有强制要求的场景,主流程必须用Workflow锁死,不能让LLM自主决策。
-
单轮LLM或简单Workflow就能满足需求
📌 Anthropic原文原话:
"For many applications, however, optimizing single LLM calls with retrieval and in-context examples is usually enough."
(对大多数应用来说,优化单轮LLM调用、搭配检索和上下文示例就足够了)
强行上Agent只会徒增复杂度、成本和延迟,收益可以忽略。
官方给出的「规则 vs LLM vs Agent」的选择优先级:
规则/脚本 > 单轮LLM增强 > 简单Workflow > 复杂Workflow > 单Agent > 多Agent每一步升级都必须有明确的效果提升作为支撑,禁止为了技术概念而叠加复杂度------这是Anthropic总结数十个客户落地失败案例得出的核心教训。
三、Agent的本质:官方定义的最小循环+可运行实现
Anthropic在原文中明确指出:Agent没有任何黑科技,本质就是一个「感知-思考-行动-反馈」的循环,所有复杂的Agent框架都是把这个简单循环包装了多层抽象。
官方定义的Agent最小循环
- Observe(感知):从环境获取真实状态(用户指令、工具返回结果、执行反馈)
- Think(思考):基于感知信息决策:判断进度、规划下一步、选择工具、判断是否终止
- Act(行动):执行决策,调用工具或输出结果
- 回到Observe:获取执行反馈,进入下一轮循环
完全符合官方定义的最小实现:Calculator Agent
下面的实现100%对应官方定义的Agent三组件和最小循环,零框架、无依赖,可直接运行:
python
import math
import re
# ========== 对应OpenAI Agent三组件:Tools 工具层 ==========
# 安全计算器工具,白名单校验防止注入,符合Anthropic对工具设计的要求
def calculator(expression: str) -> float | str:
allowed_pattern = r'^[\d+\-*/().% sqrt round pi e]+$'
if not re.match(allowed_pattern, expression.strip()):
return "错误:非法表达式,仅支持纯数值计算"
try:
safe_globals = {'__builtins__': {}, 'sqrt': math.sqrt, 'round': round, 'pi': math.pi, 'e': math.e}
return eval(expression, safe_globals, {})
except Exception as e:
return f"计算失败:{str(e)}"
# ========== 对应OpenAI Agent三组件:Model + Instructions 决策层 ==========
# Instructions隐含在决策逻辑中,实际使用替换为任意大模型API即可
def llm_decide(user_query: str, history_steps: list) -> dict:
"""
符合Anthropic官方决策输出规范:{"action": "calculate"/"finish"/"reject", "content": "..."}
"""
if not history_steps:
return {"action": "calculate", "content": "1234 * 5678"}
elif len(history_steps) == 1:
return {"action": "calculate", "content": f"{history_steps[-1]['result']} + 9012"}
elif len(history_steps) == 2:
return {"action": "calculate", "content": f"round(sqrt({history_steps[-1]['result']}), 2)"}
else:
return {"action": "finish", "content": f"计算完成,最终结果为 {history_steps[-1]['result']}"}
# ========== Agent核心循环:100%对应Anthropic官方定义的Observe-Think-Act循环 ==========
def calculator_agent(user_query: str, max_steps: int = 5) -> str:
history = []
step = 0
# 官方要求:必须设置最大循环步数,防止无限循环
while step < max_steps:
step += 1
# 1. Observe:获取当前状态
# 2. Think:调用LLM决策
decision = llm_decide(user_query, history)
if decision["action"] == "finish":
return decision["content"]
elif decision["action"] == "reject":
return f"无法处理:{decision['content']}"
elif decision["action"] == "calculate":
# 3. Act:调用工具执行
result = calculator(decision["content"])
# 4. Observe:获取执行结果进入下一轮
history.append({"step": step, "expr": decision["content"], "result": result})
if isinstance(result, str) and result.startswith("错误"):
return f"执行中断:{result}"
return f"已达最大步数{max_steps},任务终止"
# 运行测试
if __name__ == "__main__":
query = "1234乘以5678,再加9012,最后开平方保留两位小数"
print(calculator_agent(query))Anthropic原文特别强调:优先直接调用LLM API实现,不要上来就用Agent框架。框架会增加不必要的抽象层,掩盖底层的提示词和响应,让调试变得极其困难------这也是上面的实现没有用任何框架的原因,完全符合官方推荐。
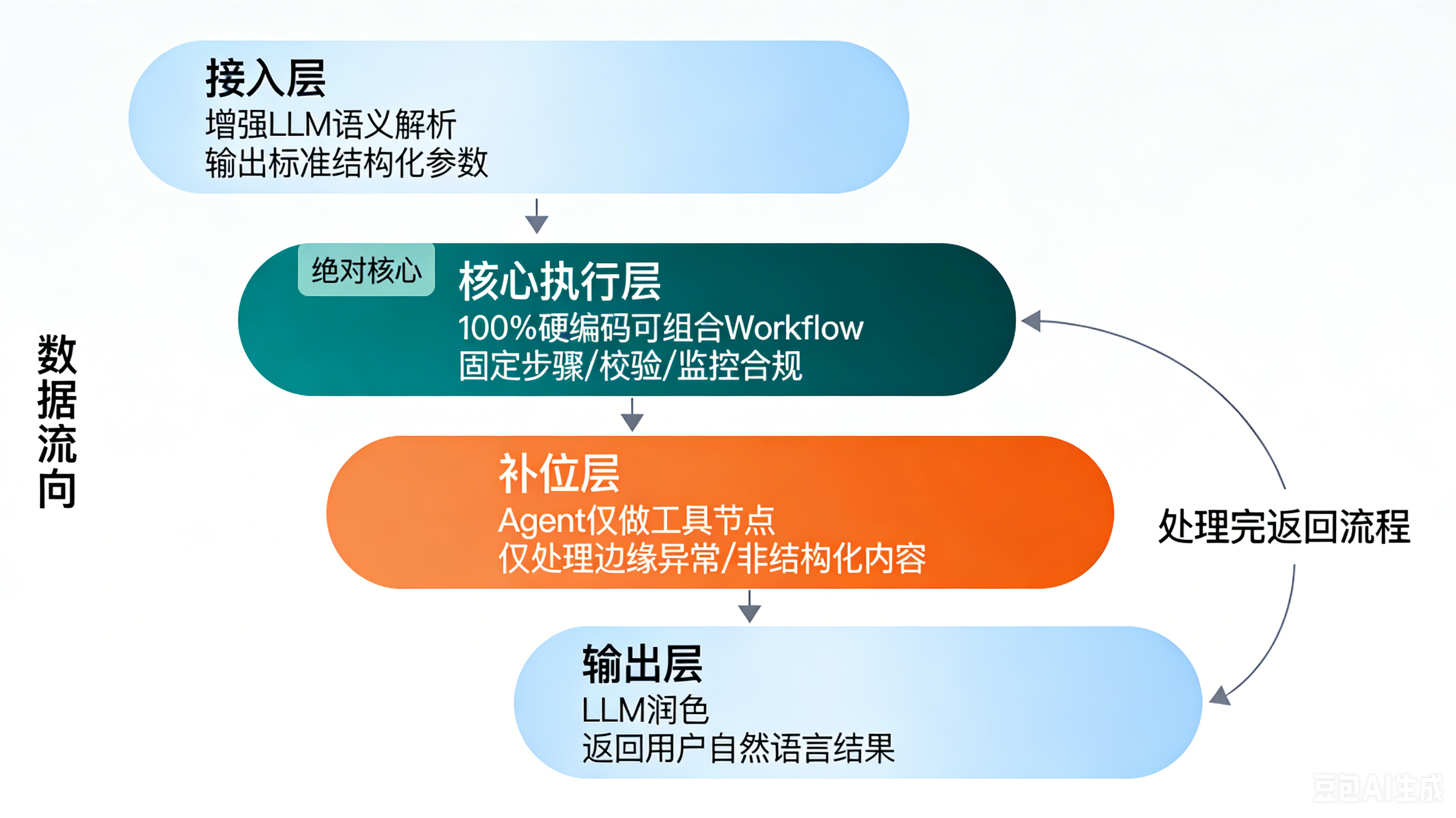
四、两篇官方共同推荐的生产落地架构:Workflow为主,Agent补位
Anthropic和OpenAI在两篇指南中给出了完全一致的生产落地架构,核心就是:Workflow做核心骨架,Agent做边缘补位,绝对不要用全自主Agent做主流程 。
第一步:优先使用Anthropic定义的6种可组合Workflow模式
Anthropic在原文中总结了生产中99%场景会用到的6种可组合Workflow模式,所有复杂系统都可以通过这几种模式拼接实现:
- 提示词链(Prompt Chaining):拆解任务为固定步骤,逐次调用LLM
- 路由(Routing):分类输入后定向到专用处理流程
- 并行(Parallelization):拆分任务并行执行后汇总结果
- 编排器-工作者(Orchestrator-workers):中心调度分配任务给专用节点
- 评估器-优化器(Evaluator-optimizer):生成-评估-迭代的循环
- 增强LLM(Augmented LLM):单轮LLM搭配工具、检索、记忆
官方标准分层架构(100%来自两篇指南的推荐)
┌─────────────────────────────────────────────────────────────┐
│ 1. 接入层:增强LLM(Anthropic定义) │
│ 用户自然语言 → 单轮LLM语义解析 → 标准结构化参数/意图路由 │
└─────────────────────────────┬───────────────────────────────┘
│
┌─────────────────────────────▼───────────────────────────────┐
│ 2. 核心执行层:可组合Workflow(Anthropic 6种模式) │
│ 固定步骤 → 固定分支 → 固定校验 → 固定工具调用 │
│ 官方要求:所有核心业务流程、高风险操作必须放在这一层硬编码 │
└─────────────────────────────┬───────────────────────────────┘
│
┌─────────────────────────────▼───────────────────────────────┐
│ 3. 补位层:Agent作为Workflow的工具节点 │
│ 仅处理:边缘异常Case / 非结构化内容处理 / 规则覆盖不到的场景 │
│ 官方要求:Agent只能提建议,执行权永远在Workflow手中 │
└─────────────────────────────┬───────────────────────────────┘
│
┌─────────────────────────────▼───────────────────────────────┐
│ 4. 输出层:增强LLM │
│ Workflow执行结果 → 单轮LLM润色 → 自然语言返回用户 │
└─────────────────────────────────────────────────────────────┘OpenAI官方明确的架构红线
📌 OpenAI《Agents 101》原话:
"Our general recommendation is to maximize a single agent's capabilities first. More agents can provide intuitive separation of concepts, but can introduce additional complexity and overhead, so often a single agent with tools is sufficient."
(我们的通用建议是先最大化单Agent的能力。多Agent虽然能实现概念分离,但会引入额外的复杂度和开销,通常单Agent加工具就足够了)
绝对禁止上来就做多Agent系统,这是官方明确指出的最常见的落地失败原因。
五、官方给出的落地踩坑红线
全部来自两篇官方指南的客户落地经验总结:
- ❌ 不要让Agent掌控核心业务流程:所有涉及钱、数据、用户信息的操作,必须Workflow硬编码校验,不能让LLM自主决策
- ❌ 不要使用过度抽象的Agent框架:优先直接调用LLM API,框架会掩盖底层逻辑,大幅提升调试成本
- ❌ 不要做无边界的Agent循环:必须设置最大步数、超时、成本上限,防止死循环
- ❌ 不要模糊边界:Agent的能力范围、禁止行为必须在Instructions中明确定义,Anthropic特别强调边界越清晰,Agent越可靠
- ❌ 不要跳过评估:每增加一层复杂度,都必须有明确的效果评估证明收益大于成本
最后:两篇官方指南的共同结论
无论是Anthropic还是OpenAI,给开发者的核心建议高度一致:
Agent不是颠覆Workflow的革命,而是Workflow的补充。
成功的Agent落地,从来不是做最复杂的全自主系统,而是从最简单的方案开始,按需逐步增加复杂度,永远用最简单的方式解决问题。