在 Kubernetes 集群中,日志分散在各个节点的容器和系统组件中,手动查看效率极低。集中式日志收集是生产环境必备的基础设施。本文介绍两种主流方案:EFK(Elasticsearch + Fluentd + Kibana) 和 Loki + Promtail + Grafana,包括架构原理、部署步骤和配置示例,帮助你根据集群规模选择合适的日志方案。
一、为什么需要集中日志收集?
Kubernetes 中日志的分布特点:
Pod 可能随时被重建,日志随容器销毁而丢失。
多副本 Pod 的日志分散在不同节点。
应用日志输出到 stdout/stderr,由 kubelet 写入节点文件(/var/log/containers/*.log)。
集中日志收集的核心价值:
统一查询:在单一界面搜索所有 Pod 的日志。
关联分析:结合时间线排查分布式系统故障。
长期存储:日志保留更长时间,满足审计和合规需求。
告警:基于日志关键词触发告警(如 ERROR 突增)。
二、方案一:EFK Stack(Elasticsearch + Fluentd + Kibana)
EFK 是 Kubernetes 官方推荐的经典日志方案,由三个组件构成:
Fluentd:日志收集器,以 DaemonSet 部署在每个节点,收集容器日志并添加 Kubernetes 元数据。
Elasticsearch:分布式搜索引擎,存储和索引日志,支持全文检索。
Kibana:可视化平台,提供日志搜索、图表和仪表盘。
2.1 架构与部署方式

2.2 部署 Elasticsearch
Step 1:创建命名空间
bash
kubectl create namespace loggingStep 2:创建 Elasticsearch StatefulSet
elasticsearch-statefulset.yaml:
yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: elasticsearch
namespace: logging
spec:
serviceName: elasticsearch
replicas: 3
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch
spec:
containers:
- name: elasticsearch
image: docker.elastic.co/elasticsearch/elasticsearch:8.9.0
env:
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: cluster.name
value: k8s-logs
- name: discovery.seed_hosts
value: "elasticsearch-0.elasticsearch,elasticsearch-1.elasticsearch,elasticsearch-2.elasticsearch"
- name: ES_JAVA_OPTS
value: "-Xms2g -Xmx2g"
- name: ELASTIC_PASSWORD
value: "your-strong-password"
ports:
- containerPort: 9200
name: http
- containerPort: 9300
name: transport
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 100GiStep 3:创建 Headless Service
yaml
apiVersion: v1
kind: Service
metadata:
name: elasticsearch
namespace: logging
spec:
clusterIP: None
ports:
- port: 9200
name: http
- port: 9300
name: transport
selector:
app: elasticsearch应用配置:
bash
kubectl apply -f elasticsearch-statefulset.yaml
kubectl apply -f elasticsearch-service.yaml2.3 部署 Fluentd(DaemonSet)
Fluentd 负责在每个节点收集日志,并添加 Kubernetes 元数据(namespace、pod name、container name 等)。
Step 1:创建 Fluentd ConfigMap
yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
namespace: logging
data:
fluent.conf: |
<source>
@type tail
path /var/log/containers/*.log
pos_file /var/log/fluentd-containers.log.pos
tag kubernetes.*
read_from_head true
<parse>
@type json
time_format %Y-%m-%dT%H:%M:%S.%NZ
</parse>
</source>
<filter kubernetes.**>
@type kubernetes_metadata
</filter>
<match **>
@type elasticsearch
host elasticsearch
port 9200
logstash_format true
logstash_prefix k8s-logs
<buffer>
@type file
path /var/log/fluentd-buffers/kubernetes.system.buffer
flush_mode interval
flush_thread_count 2
flush_interval 5s
</buffer>
</match>Step 2:创建 Fluentd DaemonSet
需配置 RBAC 权限,使 Fluentd 能访问 Kubernetes API 获取 Pod 元数据。
yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
namespace: logging
spec:
selector:
matchLabels:
app: fluentd
template:
metadata:
labels:
app: fluentd
spec:
serviceAccountName: fluentd
containers:
- name: fluentd
image: fluent/fluentd-kubernetes-daemonset:v1-debian-elasticsearch
env:
- name: FLUENT_ELASTICSEARCH_HOST
value: "elasticsearch"
- name: FLUENT_ELASTICSEARCH_PORT
value: "9200"
volumeMounts:
- name: varlog
mountPath: /var/log
- name: config
mountPath: /fluentd/etc
volumes:
- name: varlog
hostPath:
path: /var/log
- name: config
configMap:
name: fluentd-config2.4 部署 Kibana
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
namespace: logging
spec:
replicas: 1
selector:
matchLabels:
app: kibana
template:
metadata:
labels:
app: kibana
spec:
containers:
- name: kibana
image: docker.elastic.co/kibana/kibana:8.9.0
env:
- name: ELASTICSEARCH_HOSTS
value: "http://elasticsearch:9200"
ports:
- containerPort: 5601
---
apiVersion: v1
kind: Service
metadata:
name: kibana
namespace: logging
spec:
type: NodePort
ports:
- port: 5601
targetPort: 5601
nodePort: 30601
selector:
app: kibana访问 http://:30601 进入 Kibana,创建索引模式(如 k8s-logs-*)即可查询日志。
2.5 EFK 的优缺点

三、方案二:Loki + Promtail + Grafana(轻量级)
Loki 是 Grafana Labs 开发的日志聚合系统,受 Prometheus 启发,只索引日志的标签(labels),不索引日志内容,从而大幅降低存储成本和资源消耗。
3.1 核心组件
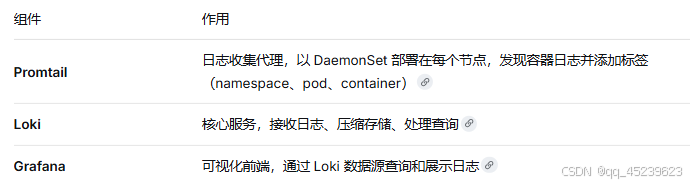
3.2 使用 Helm 部署 Loki Stack(推荐)
Step 1:添加 Grafana Helm 仓库
bash
helm repo add grafana https://grafana.github.io/helm-charts
helm repo updateStep 2:自定义配置值
bash
helm show values grafana/loki-stack > loki-values.yaml修改 loki-values.yaml,启用 Grafana 并配置持久化存储:
yaml
loki:
persistence:
enabled: true
size: 100Gi
config:
storage_config:
aws:
s3: "" # 若使用 S3 或 MinIO 作为后端存储
endpoint: ""
grafana:
enabled: true
persistence:
enabled: true
size: 10Gi
promtail:
enabled: true
config:
clients:
- url: http://loki:3100/loki/api/v1/pushStep 3:部署 Loki Stack
bash
helm upgrade --install loki grafana/loki-stack \
--namespace loki-stack \
--create-namespace \
--values loki-values.yamlStep 4:验证部署
bash
kubectl get pods -n loki-stack3.3 获取 Grafana 密码并访问
bash
# 获取 admin 密码
kubectl get secret --namespace loki-stack loki-grafana \
-o jsonpath="{.data.admin-password}" | base64 --decode端口转发访问 Grafana:
bash
kubectl port-forward --namespace loki-stack service/loki-grafana 3000:80访问 http://localhost:3000,用户名 admin,密码为上一步获取的值。
3.4 配置 Loki 数据源
在 Grafana 中:
点击 Configuration → Data Sources。
点击 + Add data source,选择 Loki。
输入 URL:http://loki:3100。
点击 Save & Test。
3.5 查询日志(LogQL)
在 Grafana 的 Explore 页面,使用 LogQL 查询:
logql
查询特定命名空间的所有日志
{namespace="default"}
查询包含 ERROR 的日志
{namespace="production"} |= "ERROR"
查询特定 Pod 的日志
{pod="nginx-7b8c9d5f6-abcde"}
正则匹配
{namespace="default"} |~ ".timeout. "
Loki 的标签模型与 Prometheus 一致,可以结合指标和日志进行关联分析。
3.6 Loki 的优缺点
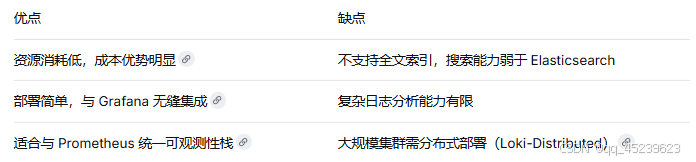
四、方案对比与选型建议

选型建议:
需要全文检索、复杂日志分析、大容量存储 → 选择 EFK。
强调成本控制、轻量级、与 Prometheus 指标统一观测 → 选择 Loki。
如果已使用 Elasticsearch 的其他场景(如 APM),可继续使用 EFK。
五、生产环境最佳实践
资源限制:为 Fluentd/Promtail 设置 CPU/内存 limits,避免日志收集器影响节点性能。
日志轮转:配置 logrotate 限制日志文件大小和保留天数,防止磁盘占满。
索引生命周期管理(ILM) :对 Elasticsearch 配置自动清理旧日志的策略。
安全加固:为 Elasticsearch 和 Kibana 启用 TLS 加密,为 Fluentd/Promtail 配置最小权限 ServiceAccount。
监控告警:监控日志收集组件自身的健康状态和资源使用。
六、小结
EFK 和 Loki 是 Kubernetes 日志收集的两大主流方案。EFK 功能强大但资源消耗高,适合复杂分析场景;Loki 轻量高效,适合与 Prometheus 统一可观测性栈。根据集群规模和业务需求选择合适的方案,可以显著提升故障排查效率。