来自github开源资料------《从零开始学Agent》
Token、Temperature与模型参数的讲解
Token:模型的基本单位
是模型处理文本的最小单位。
python
import tiktoken # Token 计数库(注:此处以 OpenAI 体系为例演示核心原理,2026 年不同厂商如 Qwen、Gemini 均有专属的 Tokenizer,但底层逻辑相通)
def count_tokens(text: str, model_encoding: str = "cl100k_base") -> int:
"""计算文本的 Token 数量"""
encoding = tiktoken.get_encoding(model_encoding)
tokens = encoding.encode(text)
return len(tokens)
def visualize_tokens(text: str, model_encoding: str = "cl100k_base"):
"""可视化 Token 分割"""
encoding = tiktoken.get_encoding(model_encoding)
tokens = encoding.encode(text)
print(f"文本:{text}")
print(f"Token 数量:{len(tokens)}")
print(f"Token 列表:{[encoding.decode([t]) for t in tokens]}")
print()
# 英文分词示例
visualize_tokens("Hello, how are you today?")
# Token 列表:['Hello', ',', ' how', ' are', ' you', ' today', '?']
# Token 数量:7
# 中文分词示例(中文通常更多 Token,不同模型切词粒度差异较大)
visualize_tokens("你好,今天天气怎么样?")
# 中文每个字通常占 0.5 到 2 个 Token 不等
# 代码的 Token 计数
code = """
def fibonacci(n):
if n <= 1:
return n
return fibonacci(n-1) + fibonacci(n-2)
"""
visualize_tokens(code)
## 输出:
# 文本:Hello, how are you today?
# Token 数量:7
# Token 列表:['Hello', ',', ' how', ' are', ' you', ' today', '?']
#
# 文本:你好,今天天气怎么样?
# Token 数量:13
# Token 列表:['你', '好', ',', '今', '天', '天', '�', '�', '�', '�', '么', '样', '?']
#
# 文本:
# def fibonacci(n):
# if n <= 1:
# return n
# return fibonacci(n-1) + fibonacci(n-2)
#
# Token 数量:29
# Token 列表:['\n', 'def', ' fibonacci', '(n', '):\n', ' ', ' if', ' n', ' <=', ' ', '1', ':\n', ' ', ' return', ' n', '\n', ' ', ' return', ' fibonacci', '(n', '-', '1', ')', ' +', ' fibonacci', '(n', '-', '2', ')\n']
# Token 成本计算器(价格单位:美元/百万 Token,仅供参考)
PRICE_PER_1M_TOKENS = {
"claude-3-5-sonnet": {"input": 3.0, "output": 15.0}, # Anthropic 旗舰,逻辑最强
"gemini-2.5-pro": {"input": 2.0, "output": 12.0}, # 超长上下文与多模态王者
"qwen-plus": {"input": 1.2, "output": 6.0}, # 业务主力,性价比高
"kimi-k2": {"input": 1.0, "output": 3.0}, # 适合超长文本检索提取
"deepseek-r1": {"input": 0.55, "output": 2.19}, # 推理模型(Reasoning)性价比之王
}
def estimate_cost(
input_text: str,
expected_output_tokens: int,
model: str = "qwen-plus"
) -> dict:
"""估算 API 调用成本"""
input_tokens = count_tokens(input_text)
price = PRICE_PER_1M_TOKENS.get(model, {"input": 1.0, "output": 2.0})
input_cost = (input_tokens / 1_000_000) * price["input"]
output_cost = (expected_output_tokens / 1_000_000) * price["output"]
return {
"input_tokens": input_tokens,
"expected_output_tokens": expected_output_tokens,
"total_tokens": input_tokens + expected_output_tokens,
"estimated_cost_usd": input_cost + output_cost,
"estimated_cost_cny": (input_cost + output_cost) * 7.2 # 近似汇率
}
# 估算成本
prompt = "请为我写一篇关于 Python 异步编程的500字文章"
for models in PRICE_PER_1M_TOKENS:
print(models)
cost = estimate_cost(prompt, 500, models)
print(f"输入 Token:{cost['input_tokens']}")
print(f"预估总成本:¥{cost['estimated_cost_cny']:.4f}")
# claude-3-5-sonnet
# 输入 Token:19
# 预估总成本:¥0.0544
# gemini-2.5-pro
# 输入 Token:19
# 预估总成本:¥0.0435
# qwen-plus
# 输入 Token:19
# 预估总成本:¥0.0218
# kimi-k2
# 输入 Token:19
# 预估总成本:¥0.0109
# deepseek-r1
# 输入 Token:19
# 预估总成本:¥0.0080不同内容类型的 Token 消耗详解
英文规律:
- 常见英文单词约 1 Token/词,不常见或超长单词会被拆成 2-3 个 Token
- 空格通常与后面的单词合并为 1 个 Token(如 ' how')
- 平均来看,英文文本约 1 Token ≈ 4 个字符(含空格)
中文规律:
- 常见中文字 1 个字 ≈ 1 个 Token
- 高频词组(如"你好""人工""智能")可能被合并为 1 个 Token
- 罕见汉字可能占 2-3 个 Token(因为需要多个字节编码)
- 同样语义的内容,中文 Token 数通常是英文的 1.5~2 倍(但 2026 年的新模型如 Qwen 已经极大优化了中文压缩率)
标点符号规律:
- 英文常见标点(, . ! ? : ;)通常 1 个 = 1 Token
- 中文标点(,。!?)也通常 1 个 = 1 Token
- 特殊/罕见标点可能消耗更多 Token
- 标点经常和相邻的文字合并(如 'world!' 可能是 1 个 Token)
数字规律:
- 1-4 位整数通常为 1 Token
- 较长数字会被拆分,每 3-4 位约占 1 Token
- 小数点会导致额外的 Token 拆分
对于图像:
- 缩略图/图标 (256x256): low=85, high=255 Token
- 小图 (512x512):low=85, high=255 Token
- 普通照片 (1024x768): low=85, high=765 Token
- 全高清截图 (1920x1080):low=85, high=1445 Token
- 4K 图像 (4096x2160): low=85, high=1445 Token (缩放截断后)
实用提示: 如果你的 Agent 需要频繁处理图像(如网页 UI 截图分析),先在本地代码里将图像压缩到 1080p 以下 ,或者在非 OCR 场景使用 detail="low",可以为你省下极其可观的 API 费用!
Temperature-创造力旋钮
Temperature 控制输出的随机性,是最重要的参数之一。
python
from openai import OpenAI, RateLimitError, AuthenticationError, APIConnectionError, NotFoundError
from dotenv import load_dotenv
import os
load_dotenv()
api_key = os.getenv("DeepSeek_API_KEY")
if not api_key:
raise RuntimeError("没有读取到 DeepSeek_API_KEY,请先设置环境变量或写入 .env 文件。")
client = OpenAI(
api_key=api_key,
base_url="https://api.deepseek.com",
)
def test_temperature(prompt: str, temperatures: list, runs: int = 3):
"""对比不同 Temperature 的输出效果"""
for temp in temperatures:
print(f"\n{'=' * 50}")
print(f"Temperature = {temp}")
print('=' * 50)
for i in range(runs):
response = client.chat.completions.create(
model="deepseek-chat",
messages=[{"role": "user", "content": prompt}],
temperature=temp,
max_tokens=50
)
print(f" 运行 {i + 1}:{response.choices[0].message.content}")
# 测试创意写作(高 Temperature 更好)
test_temperature(
"用一句话描述美女",
temperatures=[0.0, 0.7, 1.5],
runs=3
)
==================================================
Temperature = 0.0
==================================================
运行 1:四川美女,常被形容为"辣中带甜,肤白貌美,性格直爽如火锅,温柔似锦江"。
运行 2:四川美女,常被形容为"辣中带甜,肤白貌美,性格直爽如火锅,温柔似锦江"。
运行 3:四川美女,常被形容为"辣中带甜,肤白貌美,性格直爽如火锅,温柔似锦江"。
==================================================
Temperature = 0.7
==================================================
运行 1:四川美女,常以肤白如玉、眉眼含情、性格直爽中带着麻辣鲜活的灵气而著称。
运行 2:四川美女,常被形容为"辣中带甜,肤白如雪,眉眼间藏着川剧变脸般的灵动与泼辣"。
运行 3:四川美女,常被形容为"辣中带甜,肤白如雪,眉眼间透着川西坝子的灵气与温柔"。
==================================================
Temperature = 1.5
==================================================
运行 1:四川美女常年被湿气浸润,养出了一身水灵灵的白嫩肌肤,肤如凝脂透粉,个不高却旺夫的瓷娃娃身段,一双会说话的杏子眼看人时自然带三分藏不住的灵气,
运行 2:川妹子往往皮肤白皙、性格火辣,兼具水灵的柔情与干练的韧性。
运行 3:川渝美女融合了蜀山灵气与火锅热辣,眉眼间自带水墨丹青的婉约与竹海林风的飒爽。对于不同场景,一般要设置不同的Temperature值:
python
TEMPERATURE_GUIDE = {
"代码生成": 0.1, # 要求精确,低随机性
"数据提取/JSON格式化": 0.0, # 完全确定性,防崩溃
"问答/事实查询": 0.3, # 稍微稳定
"文案/摘要": 0.7, # 平衡创意和准确
"头脑风暴/创意": 1.0, # 鼓励多样性
"诗歌/创意写作": 1.2, # 高创意
"Agent 逻辑路由": 0.1, # 工具调用需要极度稳定
"对话/闲聊": 0.8, # 自然对话
}
def get_optimal_temperature(task_type: str) -> float:
return TEMPERATURE_GUIDE.get(task_type, 0.7)所以,我们在使用大模型时,可以根据需求,去定义temperature值,让模型去做对应的事儿。
Top-p:另一种控制随机性的方式
Top-p(也叫 Nucleus Sampling)从概率最高的词集合中动态截断并采样,集合大小由 p 决定:
python
response = client.chat.completions.create(
model="qwen-plus",
messages=[{"role": "user", "content": "写一个关于 AI 觉醒的短故事开头"}],
temperature=0.8, # 控制随机程度
top_p=0.9, # 只从概率总和前 90% 的核心词汇中选择
max_tokens=200
)通常是选择二者中的其中一个进行调整,另一个保持默认。
Max_tokens:控制输出长度(推理模型的隐蔽陷阱)
python
from openai import OpenAI, RateLimitError, AuthenticationError, APIConnectionError, NotFoundError
from dotenv import load_dotenv
import os
from sympy import content
load_dotenv()
api_key = os.getenv("DeepSeek_API_KEY")
if not api_key:
raise RuntimeError("没有读取到 DeepSeek_API_KEY,请先设置环境变量或写入 .env 文件。")
client = OpenAI(
api_key=api_key,
base_url="https://api.deepseek.com",
)
def chat_with_length_control(
message: str,
max_output_tokens: int = 300,
model: str = "deepseek-chat"
) -> dict:
"""控制输出长度"""
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": message}],
max_tokens=max_output_tokens # 限制生成长度
)
usage = response.usage
content = response.choices[0].message.content
finish_reason = response.choices[0].finish_reason
return {
"content": content,
"total_tokens": usage.total_tokens,
"finish_reason": finish_reason # "stop"=正常结束, "length"=达到上限被截断
}
# 常规模型测试
result = chat_with_length_control("写一篇20字的文章", max_output_tokens=300)
if result["finish_reason"] == "length":
print("⚠️ 输出被 max_tokens 截断了!")
print(result["content"]) 2026 年硬核预警:推理模型(如 DeepSeek-R1)的 CoT Token 陷阱:如果你使用的是像 DeepSeek-R1 这样的"慢思考"推理模型,千万不要把 max_tokens 设得太小!
推理模型 在给出最终答案前,会输出大量的内部**"思维链"(Chain of Thought)**。这些思考过程同样受限于 max_tokens 且会计费。如果你为了省钱把 max_tokens 设为 500,模型很可能在思考阶段就把额度耗尽了,导致你连最终答案都拿不到。
最佳实践:调用推理模型处理复杂规划时,将max_tokens 放宽至 4000 甚至 8000。
Presence Penalty & Frequency Penalty:控制重复
适合用于 :需要列举多样选项 、生成长篇不重复研报的场景
python
def demo_penalties():
# 这两个参数帮助避免模型像车轱辘话一样重复自己
response = client.chat.completions.create(
model="qwen-plus",
messages=[{"role": "user", "content": "列举10种不同的创业方向"}],
# presence_penalty:存在惩罚(只要出现过就惩罚,鼓励开启新话题)
# 范围:-2.0 到 2.0,正值降低话题重复率
presence_penalty=0.5,
# frequency_penalty:频率惩罚(用的次数越多越不想用,鼓励词汇丰富度)
# 范围:-2.0 到 2.0,正值降低高频词
frequency_penalty=0.3,
)stop:自定义停止条件
对于结构化输出场景,可以标记某个标记符为终止API生成的标记,防止大模型后面补充废话。
n:生成多个候选结果
python
from openai import OpenAI
from dotenv import load_dotenv
import os
load_dotenv()
api_key = os.getenv("DeepSeek_API_KEY")
if not api_key:
raise RuntimeError("没有读取到 DeepSeek_API_KEY,请先设置环境变量或写入 .env 文件。")
client = OpenAI(
api_key=api_key,
base_url="https://api.deepseek.com",
)
def generate_titles(prompt: str, count: int = 3) -> list[str]:
response = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[
{
"role": "user",
"content": (
f"{prompt}\n\n"
f"请直接输出 {count} 个候选标题,每行一个,不要解释。"
)
}
],
temperature=0.8,
max_tokens=120,
)
text = response.choices[0].message.content or ""
return [
line.strip(" -0123456789.、")
for line in text.splitlines()
if line.strip()
]
titles = generate_titles(
"为一篇关于 Agent 多智能体协同的技术博客生成吸引人的中文标题",
count=3,
)
for i, title in enumerate(titles, 1):
print(f"候选 {i}:{title}")实际Agent架构设计--路由工厂
根据具体任务的属性动态切换底座模型和参数配置
python
def create_agent_call(
messages: list,
task_type: str = "general",
**override_params
) -> dict:
"""
Agent 调用的最佳实践封装工厂
根据任务类型自动匹配最优的模型与参数
"""
# 不同任务类型的动态路由预设
task_presets = {
"reasoning": { # 复杂推理、逻辑 Bug 排查
"model": "deepseek-r1", # 使用强大的推理模型
"temperature": 0.6, # 推理模型自带内部探索,通常不需要过低的温度
"max_tokens": 8000, # 必须预留大量 Token 供其生成思考链 (CoT)
},
"code": { # 纯代码编写/重构
"model": "claude-3-5-sonnet", # 编程天花板
"temperature": 0.1,
"max_tokens": 4000,
},
"extraction": { # 信息提取、意图分类、JSON 生成
"model": "kimi-k2", # 性价比极高,处理长文本块便宜
"temperature": 0.0, # 杜绝任何随机性导致 JSON 解析崩溃
"max_tokens": 500,
},
"creative": { # 创意文案、脑暴
"model": "qwen-plus",
"temperature": 0.9,
"max_tokens": 1000,
"presence_penalty": 0.3,
},
"general": { # 通用闲聊与常规指令
"model": "qwen-plus",
"temperature": 0.7,
"max_tokens": 1500,
}
}
params = task_presets.get(task_type, task_presets["general"])
params.update(override_params) # 允许外部业务层覆盖默认参数
params["messages"] = messages
response = client.chat.completions.create(**params)
return {
"content": response.choices[0].message.content,
"usage": {
"input": response.usage.prompt_tokens,
"output": response.usage.completion_tokens,
"total": response.usage.total_tokens
},
"model": response.model,
"finish_reason": response.choices[0].finish_reason
}
# 使用示例:要求 Agent 根据文案生成提取结论
result = create_agent_call(
messages=[{"role": "user", "content": "从这段文字中提取用户购买意向评级..."}],
task_type="extraction"
)
print(f"路由选用模型:{result['model']}")
print(f"Token 总消耗:{result['usage']['total']}")
# 这里应该会输出:
# 路由选用模型:deepseek-v4-flash
# Token 总消耗:111小结
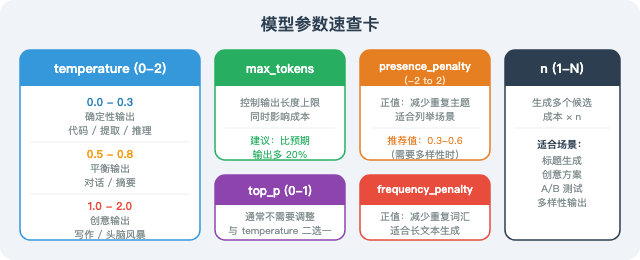
理解模型参数是 Agent 架构师的必备基本功:
- Token 是计费原石:多模态图像计费尤其容易超标,预处理压缩是关键。
- Temperature 决定稳定性:提取工具传参时设为 0.0,头脑风暴发散时设为 0.9 以上。
- 注意推理模型的 max_tokens 陷阱:像 DeepSeek-R1 这样的模型会吃掉大量的隐形思维 Token,切记要留够配额避免截断。
- 动态路由模型:不同任务类型(提取 vs. 推理 vs. 创意)应映射不同的参数组合与最佳性价比模型。
掌握这些参数,能在质量、延迟和 API 账单之间取得完美的平衡,真正控制住 Agent 的行为。