作者:FR,LZM,LHJ from DeepLink Group@Shanghai AI Lab;LFX,LHM from SJTU
3D高斯泼溅(3DGS)凭借出色的渲染质量和速度,已成为三维重建、具身智能等领域的当红技术。然而,当场景规模扩大或分辨率升至4K时,即使3DGS也难以维持实时帧率。
现有优化多从算法角度压缩高斯数量或简化光栅化,却忽略了更根本的问题:3DGS的渲染管线与硬件特性并不匹配。以GPU为例,其Alpha混合过程长期跑在CUDA Core上,而算力更强的张量处理单元Tensor Core却完全闲置------因为Tensor Core只擅长矩阵乘法,不擅长传统光栅化。
本文另辟蹊径,从硬件加速角度:将Alpha混合过程映射为矩阵乘法,让Tensor Core真正参与3DGS渲染,并设计G2L坐标变换解决FP16精度难题。基于这一思路,本文将详细介绍如何针对GPU、NPU和树莓派的不同硬件架构与性能约束,开展专项适配与优化。
什么是3DGS
3D Gaussian Splatting(3DGS)是一种革命性的可微分3D渲染技术,可以实时渲染出高保真的图像,在三维重建、增强现实、辅助驾驶、具身智能、电影特效、游戏动画等领域有着广泛地应用。然而由于3D场景包含庞大的参数量,在大场景实时渲染、多机位渲染、端侧设备渲染以及需要低延迟的场景中,现有的渲染速度仍然无法满足其需求。
关于3DGS的背景介绍和理解可以参考下面两篇文章:
同时,随着深度学习的发展,主流GPU厂商也为深度学习频繁使用的矩阵乘法与累加(Matrix-Multiplication Accumulation,MMA)操作设计出专用的硬件---张量处理单元(Tensor Core)。例如在NVIDIA的H100(PCIe)的GPU上,不使用Tensor Core的FP16峰值算力为96 TFLOPS,而使用Tensor Core的FP16算力超过了800 TFLOPS。
3DGS性能瓶颈分析
3DGS管线分析
3D Gaussian是一种3D资产的一种表征方式,它由一系列"高斯球"组成。每个高斯球由它的位置、协方差(形状)、不透明度和颜色特征(由球谐函数编码)组成。"渲染"则是将3D场景转化成2D图像的过程。
3D Gaussian Splatting是一种主流的3D Gaussian的渲染管线,它主要由下列3步组成:
这里不做过多的介绍,推荐文章:https://zhuanlan.zhihu.com/p/26101040053
-
预处理:逐一将高斯球投影至二维平面得到投影后参数,根据特征计算出高斯球颜色,同时初步剔除不可见的高斯球。
-
排序:成像平面会被划分为多个密铺的"tiles"。而排序阶段要做的则是对于每一个tile,确定它需要渲染的高斯球并将它们的索引由近到远排序。
-
Alpha混合:对于各Tile内的所有像素,根据顺序遍历排序后高斯球的参数,并将它们转换成像素值,输出图像。
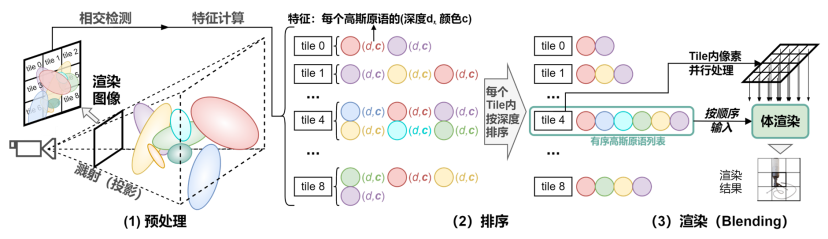
3DGS的渲染管线示意
对比了多款3DGS管线实现中各个步骤的时间占比,可以发现Alpha混合占大部分渲染时间,是管线的主要性能瓶颈,如下图左边柱状图所示:
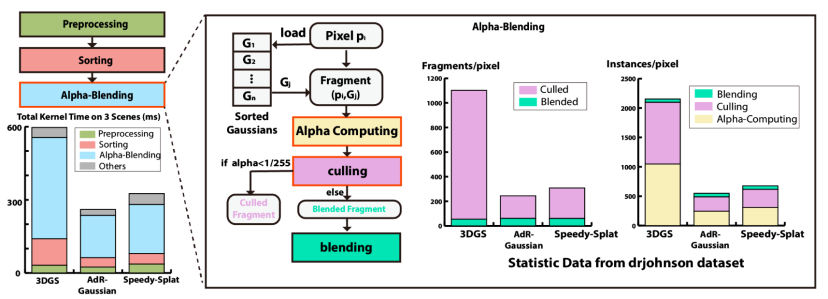
3DGS性能瓶颈分析
继续分析Alpha混合的步骤:
-
初始化:对于每个像素 p ∈ R 2 p\in\mathbb{R}^2 p∈R2,初始化它的颜色 C ← 0 , 0 , 0 T C\leftarrow0,0,0^T C←0,0,0T和透射率 T ← 1 T\leftarrow1 T←1.
-
遍历每个投影后的高斯去参数(位置 μ \mu μ,协方差 Σ \Sigma Σ,不透明度 o o o和颜色 c c c):
-
计算Alpha值: α = o e − 1 2 ( μ − p ) T Σ − 1 ( μ − p ) \alpha=o\mathrm{e}^{-\frac{1}{2}(\mu-p)^T\Sigma^{-1}(\mu-p)} α=oe−21(μ−p)TΣ−1(μ−p).
-
裁剪:如果Alpha值小于一定的阈值,比如 α < 1 255 \alpha<\frac{1}{255} α<2551,则跳过这个高斯球。否则进行下一步的混合步骤。
-
混合:更新像素的状态: C ← C + c α T , T ← T − α T C\leftarrow C+c\alpha{T},\quad T\leftarrow T-\alpha{T} C←C+cαT,T←T−αT.
-
经过运行时统计、对于一个像素来说,绝大多数(上图柱状图品红色区域)高斯球都会被裁剪,不参与后续的混合步骤。所以alpha混合中主要的计算量都来自于Alpha值的计算。
综上所述,Alpha值的计算是3DGS渲染管线的主要计算瓶颈。
计算的隐忧
然而,3DGS渲染管线和当代 AI 硬件的最powerful的计算单元并不兼容。
Alpha值的计算公式为:
α i j = o j e − 1 2 ( μ j − p i ) T Σ j − 1 ( μ j − p i ) \alpha_{ij}=o_j\mathrm{e}^{-\frac{1}{2}(\mu_j-p_i)^T\Sigma_j^{-1}(\mu_j-p_i)} αij=oje−21(μj−pi)TΣj−1(μj−pi)
这不是矩阵乘,不是卷积,不是任何 Tensor Core 擅长的规则数据流。所以如下图所示,3DGS并没有充分利用现代AI硬件单元。结果是:价值最高的计算单元在空转,而老旧的向量单元被不规则的访存和分支压得喘不过气。
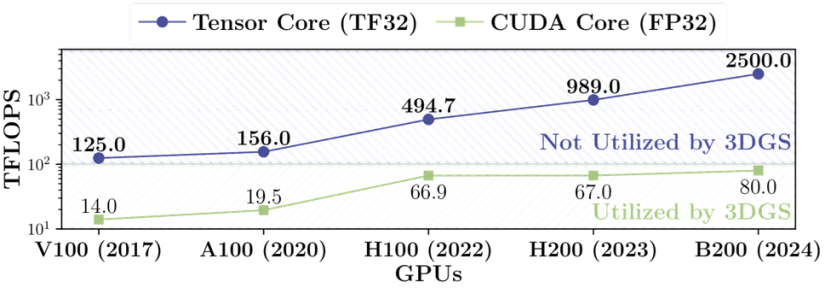
GPU算力趋势
于是,业界开始造专用加速器(DSA):GScore、GBU、VR-Pipe、MetaSpiens......它们用定制硬件做剔除、排序、体渲染。但这又带来新问题------这些芯片只会跑 3DGS,跑不了神经网络、更跑不了更通用的计算逻辑。同时,3DGS往往在3D感知、3D资产生成、具身智能等领域应用,与传统深度神经网络配合使用,而这些应用都需要与AI芯片(例如GPU、NPU等)协同运行。
无论是3DGS专用硬件的生成与部署,或是多种硬件的协同,都是一套复杂的流程或系统。
奥卡姆剃刀原理指出:"如无必要,勿增实体"。
能不能不造新硬件,利用现有的 AI 芯片的硬件单元原生高效地跑 3DGS?
这正是 本文要回答的问题。
将3DGS渲染管线转化成GEMM以适配硬件加速
首先,从alpha计算的原始公式出发:
α = o e − 1 2 ( μ − p ) T Σ − 1 ( μ − p ) . \alpha=o\mathrm{e}^{-\frac{1}{2}(\mu-p)^T\Sigma^{-1}(\mu-p)}. α=oe−21(μ−p)TΣ−1(μ−p).
其中 p = ( x , y ) T p=(x,y)^T p=(x,y)T表示像素点的坐标。 μ = ( μ x , μ y ) T \mu=(\mu_x,\mu_y)^T μ=(μx,μy)T表示投影后高斯球的均值, Σ = σ 11 σ 12 σ 12 σ 22 − 1 \Sigma=\begin{bmatrix}\sigma_{11}&\sigma_{12}\\\sigma_{12}&\sigma_{22}\end{bmatrix}^{-1} Σ=σ11σ12σ12σ22−1是投影后的对称的协方差,而 o o o表示高斯球的不透明度。
将它转化成指数的形式:
α = e ln ( o ) − 1 2 ( μ − p ) T Σ − 1 ( μ − p ) = e β . \alpha=\mathrm{e}^{\ln(o)-\frac{1}{2}(\mu-p)^T\Sigma^{-1}(\mu-p)}=\mathrm{e}^\beta. α=eln(o)−21(μ−p)TΣ−1(μ−p)=eβ.
进而,处理指数项:
β = ln ( o ) − 1 2 ( μ − p ) T Σ − 1 ( μ − p ) \beta=\ln(o)-\frac{1}{2}(\mu-p)^T\Sigma^{-1}(\mu-p) β=ln(o)−21(μ−p)TΣ−1(μ−p)
展开表达式,可以得到:
β = ( ln ( o ) − 1 2 μ T Σ − 1 μ ) + ( σ 11 μ x + σ 12 μ y ) x + ( σ 12 μ x + σ 22 μ y ) y − 1 2 σ 11 x 2 − σ 12 x y − 1 2 σ 22 y 2 . \beta=(\ln(o)-\frac{1}{2}\mu^T\Sigma^{-1}\mu)+(\sigma_{11}\mu_x+\sigma_{12}\mu_y)x+(\sigma_{12}\mu_x+\sigma_{22}\mu_y)y-\frac{1}{2}\sigma_{11}x^2-\sigma_{12}xy-\frac{1}{2}\sigma_{22}y^2. β=(ln(o)−21μTΣ−1μ)+(σ11μx+σ12μy)x+(σ12μx+σ22μy)y−21σ11x2−σ12xy−21σ22y2.
令
u = 1 x y x 2 x y y 2 T , \mathbf{u}=\begin{bmatrix}1&x&y&x^2&xy&y^2\end{bmatrix}^T, u=1xyx2xyy2T,
v = ln ( o ) − 1 2 μ T Σ − 1 μ σ 11 μ x + σ 12 μ y σ 12 μ x + σ 22 μ y − 1 2 σ 11 − σ 12 − 1 2 σ 22 T . \mathrm{v}=\begin{bmatrix}\ln(o)-\frac{1}{2}\mu^T\Sigma^{-1}\mu&\sigma_{11}\mu_x+\sigma_{12}\mu_y&\sigma_{12}\mu_x+\sigma_{22}\mu_y&-\frac{1}{2}\sigma_{11}&-\sigma_{12}&-\frac{1}{2}\sigma_{22}\end{bmatrix}^T. v=ln(o)−21μTΣ−1μσ11μx+σ12μyσ12μx+σ22μy−21σ11−σ12−21σ22T.
此时指数 β \beta β被分解成两个独立 向量的点积。向量 u \mathbf{u} u仅 依赖于像素坐标,向量 v \mathbf{v} v仅 依赖于高斯球的参数。这些向量可以提前计算出来,分别用 i , j i,j i,j表示像素和高斯球的下标:
β i j = u i T v j \beta_{ij}=\mathrm{u}_i^T\mathrm{v}_j βij=uiTvj
可以用多个向量堆叠成矩阵:
U = u 1 u 2 ⋯ u n \mathbf{U}=\begin{bmatrix}\mathbf{u}_1&\mathbf{u}_2&\cdots&\mathbf{u}_n\end{bmatrix} U=u1u2⋯un
V = v 1 v 2 ⋯ v m \mathbf{V}=\begin{bmatrix}\mathbf{v}_1&\mathbf{v}_2&\cdots&\mathbf{v}_m\end{bmatrix} V=v1v2⋯vm
然后就可以使用GEMM通过矩阵乘法批量计算了:
B = β 11 ⋯ β 1 m ⋮ ⋱ ⋮ β n 1 ⋯ β n m = u 1 T v 1 ⋯ u 1 T v m ⋮ ⋱ ⋮ u n T v 1 ⋯ u n T v n = U T V \mathbf{B}=\begin{bmatrix}\beta_{11}&\cdots&\beta_{1m}\\\vdots&\ddots&\vdots\\\beta_{n1}&\cdots&\beta_{nm}\end{bmatrix}=\begin{bmatrix}\mathbf{u}_1^T\mathbf{v}_1&\cdots&\mathbf{u}_1^T\mathbf{v}_m\\\vdots&\ddots&\vdots\\\mathbf{u}_n^T\mathbf{v}_1&\cdots&\mathbf{u}_n^T\mathbf{v}_n\end{bmatrix}=\mathbf{U}^T\mathbf{V} B= β11⋮βn1⋯⋱⋯β1m⋮βnm = u1Tv1⋮unTv1⋯⋱⋯u1Tvm⋮unTvn =UTV
从GPU到NPU:跨硬件平台的最佳部署方案
GPU篇:通过坐标变换适配FP16精度
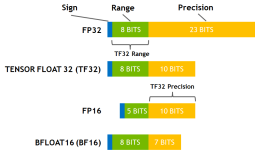
Tensor Core是现代GPU的矩阵乘法专用硬件加速单元。但是由于电路设计原因,Tensor Core支持的数据类型有限。如下图所示,Nvidia GPU的Tensor Core不支持常用的FP32数据类型,而是精度位更低的FP16或者TF32等数据类型。由于TensorCore的浮点舍入误差更大,须找到一条误差更小的计算路径来进行渲染。
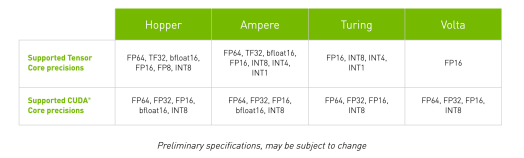
部分NVIDIA GPU的CUDA Core和Tensor Core支持的数据类型
部分浮点数据格式
如下图所示,浮点数在实数数轴上的分布是不均匀的。在靠近零的中央处分布更加密集,而在远离零的两侧分布更加稀疏。如果用一个浮点数来表示一个实数,那么就可能会产生舍入误差。如果这个实数数的绝对值越大,那么附近浮点数的分布就更加稀疏,进而产生的舍入误差就越大。
所以,需要尽可能减小参与TensorCore运算的数的绝对值来限制其舍入误差。

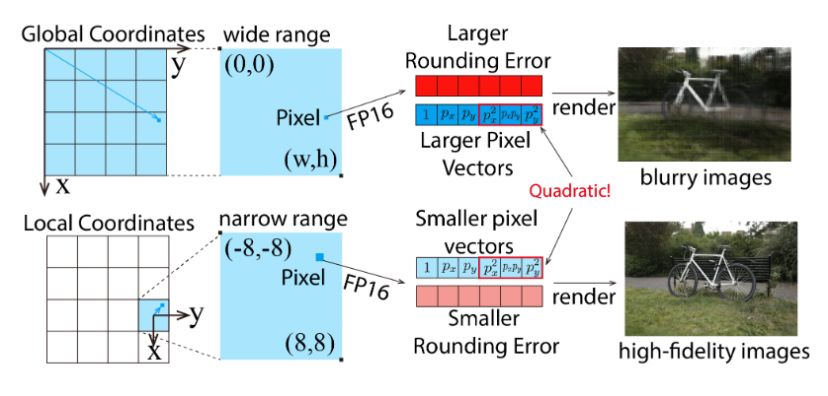
事实上,如果使用TensorCore来加速3DGS,那么它的误差来源往往在向量 u = 1 x y x 2 x y y 2 T \mathbf{u}=\begin{bmatrix}1&x&y&x^2&xy&y^2\end{bmatrix}^T u=1xyx2xyy2T中的二次项。假设图像大小为 ( w , h ) (w,h) (w,h),那么该向量元素的绝对值往往会达到百万级别,进而产生巨大的舍入误差,这在FP16/TF32等精度下是不可接受的。如果直接使用上述方法来计算alpha值,那么渲染出来的图片也通常是模糊的。
但是,可以使用坐标变换来减小向量元素的绝对值。由于3DGS是每个Tile分别渲染的,可以对每个Tile分别建立坐标系。假设Tile大小为 16 × 16 16\times{16} 16×16,对于每个Tile,选择这个Tile的中心点作为坐标原点,从而把坐标范围从 0 , w × 0 , h 0,w\times0,h 0,w×0,h缩小到 − 8 , 8 2 -8,8^2 −8,82,进而使向量元素的绝对值从百万级缩短至64以下,产生更小的舍入误差。经过坐标变换后,渲染模糊的问题被成功解决了。
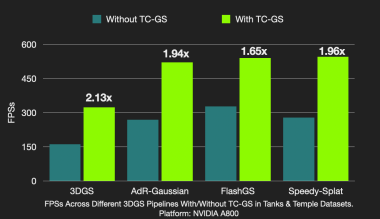
TC-GS是3DGS渲染的加速模块,可以即插即用至常用的3DGS加速框架上,如3DGS、AdR-Gaussian、FlashGS、SpeedySplat等,并且都能基于原框架达到2倍左右 的加速比。如果对比原版3DGS,TC-GS配合FlashGS/Speedy-Splat可以达到5.6倍的加速比。
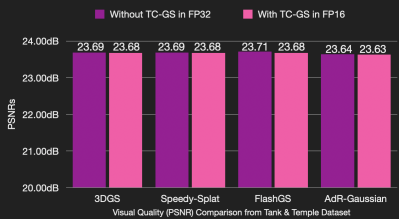
为了适配TensorCore,TC-GS使用FP16数据格式进行渲染,并进行了坐标变换。如下图所示,TC-GS在多种渲染管线上都保持了渲染精度。
NPU篇:打破SIMD的负载失衡
挑战:NPU 采用 SIMD 架构,缺乏 GPU SIMT 的灵活线程切换能力。 3DGS渲染不同 Tile 的开销差异巨大,简单并行会导致多核负载严重不均衡,导致有的核心忙不过来,有的核心却在"摸鱼"。
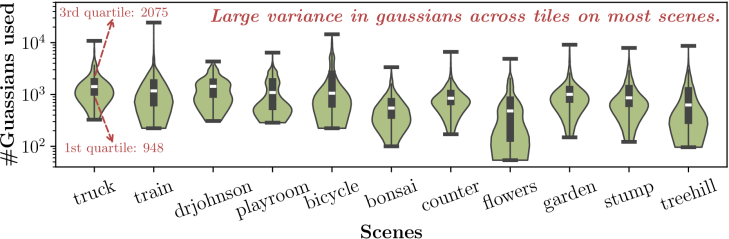
Tile渲染开销负载分布统计
洞察: 实验发现tile的负载存在空间上的相似性:即成像平面上距离相近的tile的负载开销相似;渲染一张图片所需要处理的tile数量远超过NPU的核心数量,这给予了我们显式调度的优化空间。
优化: ORANGE(HPCA'2026)先采样部分 Tile 获取运行时信息,预测剩余 Tile 负载,并据此进行分批均衡调度,让多核执行更稳定高效。
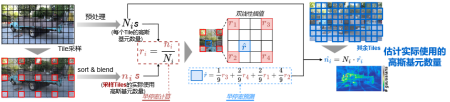
基于采样的Tile负载预测
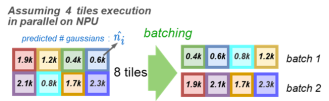 分批均衡调度
分批均衡调度
结果: 在 3DGS 负载上,ORANGE 相比移动端GPU Jetson Xavier NX 实现 15.5× 加速,相比 3DGS 专用加速器 GScore 也有 1.67× 提升。在 3DGS + DNN 的协同负载下,ORANGE 甚至能够分别达到 27.91× 和 7.18× 的加速效果。
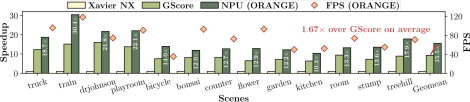
3DGS负载的加速收益
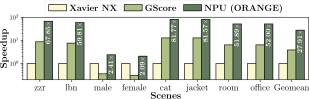 3DGS+DNN混合负载的加速收益
3DGS+DNN混合负载的加速收益
树莓派篇:极低算力的部署探索
挑战: 不同于具有强大算力的NPU和Nvidia的GPU,树莓派等单板电脑的GPU一般采用为VideoCore,不仅没有强大的TensorCore可以利用,并且整体的算力非常孱弱。此外,VideoCore支持的通用计算接口(Vulkan)版本较低,很多特性无法使用。
优化: 基于开源项目 3DGS.cpp,对所有Kernel进行硬件特性适配;设计 CPU-GPU 异构协同流水线设计,规避GPU低性能排序瓶颈,通过双buffer设计掩盖延迟;兼容SpeedySplat等算法优化方案。
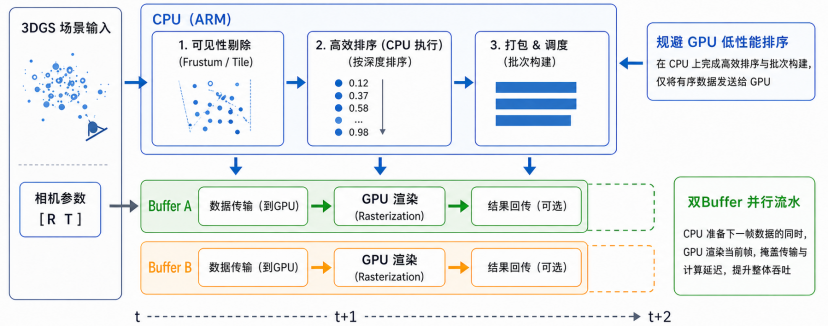
树莓派的CPU-GPU异构协同流水线设计
结果: 从简单适配后不足 1 FPS 的"幻灯片"级体验,优化后的方案可以达到 3 FPS。
开源地址:3DGS.RaspberryPi
视频地址:渲染视频Demo
总结
从 GPU 上的 FP16 坐标变换,到 NPU 上的负载均衡调度,再到树莓派上的极限降级适配,3DGS的渲染瓶颈,不在于"算力不够",而在于"算力用错了"。Alpha blending 里的二次型指数,本质上只是点积计算,可以把它写成矩阵乘法,从而充分发挥GPU的Tensor Core 和 NPU的Systolic Array的算力------这正是奥卡姆剃刀在3DGS管线上的体现:与其为 3DGS 造一颗专用芯片,不如重构它的数学表达,让现有硬件自己"学会"这门语言。同一套 GEMM 抽象贯穿了三个数量级的算力跨度。
如果你喜欢我们的内容,欢迎**点赞👍、收藏⭐️、关注➕**我们!
也欢迎在评论区与我们互动!
你的支持是我们持续创作的动力!
参考文献
-
Zimu Liao, Jifeng Ding, Siwei Cui, Ruixuan Gong, Boni Hu, Yi Wang, Hengjie Li, Hui Wang, Xingcheng Zhang, Rong Fu. "TC-GS: A faster gaussian splatting module utilizing tensor cores." Proceedings of the SIGGRAPH Asia 2025 Conference Papers. 2025.
-
Haomin Li, Bowen Zhu, Fangxin Liu, Zongwu Wang, Xinran Liang, Li Jiang, and Haibing Guan. "GEMM-GS: Accelerating 3D Gaussian Splatting on Tensor Cores with GEMM-Compatible Blending." 63rd ACM/IEEE Design Automation Conference (DAC). 2026. arXiv preprint arXiv:2604.02120 (2026).
-
Haomin Li, Yue Liang, Fangxin Liu, Bowen Zhu, Zongwu Wang, Yu Feng, Liqiang Lu, Li Jiang, and Haibing Guan. "ORANGE: Exploring Ockham's Razor for Neural Rendering by Accelerating 3DGS on NPUs with GEMM-Friendly Blending and Balanced Workloads." 2026 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 2026.