目录
下载和读取数据集:
python
import os # 导入操作系统接口模块,用于文件路径处理
import torch # 导入 PyTorch 深度学习框架
from d2l import torch as d2l # 导入 d2l 工具包(《动手学深度学习》配套库),别名 d2l
# @save 是 d2l 库中的装饰器,用于将变量/函数保存到 d2l 命名空间中,方便后续调用
# 注册 fra-eng 数据集的下载链接和 SHA-1 校验码
d2l.DATA_HUB['fra-eng'] = (d2l.DATA_URL + 'fra-eng.zip',
'94646ad1522d915e7b0f9296181140edcf86a4f5')
# @save 装饰器:将该函数保存到 d2l 中,便于复用
def read_data_nmt():
"""载入"英语-法语"数据集"""
# 从 DATA_HUB 获取下载地址并解压数据集,返回解压后的目录路径
data_dir = d2l.download_extract('fra-eng')
# 打开解压目录下的 fra.txt 文件(UTF-8 编码),读取全部内容并返回
with open(os.path.join(data_dir, 'fra.txt'), 'r',
encoding='utf-8') as f:
return f.read()
# 调用 read_data_nmt() 加载原始文本数据
raw_text = read_data_nmt()
# 打印原始文本的前 75 个字符,用于预览数据格式
print(raw_text[:75])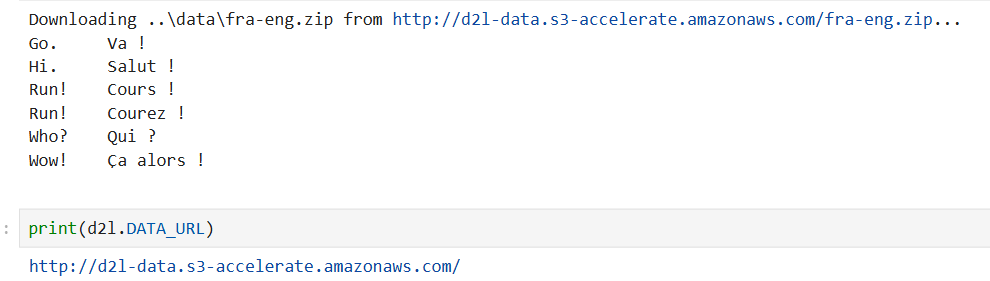
数据预处理(重要)
python
# 定义一个函数,用于预处理"英语-法语"数据集
def preprocess_nmt(text):
"""
预处理文本数据:
- 将不间断空格替换为普通空格
- 将所有字母转换为小写
- 在单词与标点符号之间插入空格,确保标点独立
"""
# 内部函数:判断当前字符是否应该在其前面加空格
# 规则:如果当前字符属于 ,.!? 且前一个字符不是空格,则返回 True
def no_space(char, prev_char):
return char in set(',.!?') and prev_char != ' '
# 第一步:替换两种特殊的不间断空格(Unicode \u202f 和 \xa0)(半角 全角)为普通空格
# 第二步:将所有英文字母转为小写
text = text.replace('\u202f', ' ').replace('\xa0', ' ').lower()
# 第三步:遍历每个字符,根据 no_space 条件决定是否在字符前插入空格
# 如果 i>0 且满足 no_space 条件,则在字符前加一个空格;否则保持原样
out = [' ' + char if i > 0 and no_space(char, text[i - 1]) else char
for i, char in enumerate(text)]
# 将列表拼接成字符串并返回
return ''.join(out)
"""
1. 为什么用 ''.join(out)?
out是一个列表,里面的每个元素是单个字符(或者前面加了一个空格的字符)。
例如处理 "Hello!"后,out可能是 ['h','e','l','l','o',' ','!']。
''.join(out)用空字符串作为连接符*****,把这些元素无缝拼回一个字符串:"hello !"。
如果不用 join,直接 str(out)会得到 "['h','e','l','l','o',' ','!']",显然不对。
如果用 ' '.join(out),则会变成 "h e l l o !"(每个字符间多一个空格),也不对。
所以必须用空字符串 ''来连接,才能恢复成正常的文本。
2. 字符串能用 enumerate()吗?
完全可以。Python 中字符串是一个可迭代对象*******,for i, char in enumerate(text)会逐个取出:
i:字符的索引(从 0 开始)
char:该位置的字符
例如 text = "abc",enumerate(text)产生 (0,'a'), (1,'b'), (2,'c')。
"""
# 对原始文本 raw_text 进行预处理,并将结果赋值给 text
text = preprocess_nmt(raw_text)
# 打印预处理后文本的前 80 个字符,用于快速查看效果
print(text[:80])| 原始文本中的字符 | 含义 | 替换后 |
|---|---|---|
\u202f(窄不间断空格) |
法语细空格,不可换行 | ' '(普通空格) |
\xa0(不间断空格) |
不可换行空格 | ' '(普通空格) |
在机器翻译等 NLP 任务中,标点符号通常被视为独立的 token,而不是附着在前一个单词上。这样做的原因是:
-
模型可以学习到标点本身的语义(句号表示结束、问号表示疑问等)。
-
避免词汇表膨胀(比如
hello和hello.是两个不同的词,但实际上它们应该共享词向量)。 -
方便序列到序列模型对齐源语言和目标语言的标点。
代码中 no_space的逻辑是:
如果当前字符是 , . ! ?之一,并且前一个字符不是空格,就在这个标点前插入一个空格。
例如:
输入 "Hello, world!"
经过处理后变为 "hello , world !"
这样,后续用空格分词时,标点就能被独立切分为 token,比如 ["hello", ",", "world", "!"]。
不过要注意:这个函数只在标点前没有空格 时才加空格,如果已经有一个空格了(比如 "Hello ,"),就不会重复添加,避免产生双空格。
词元化+绘制
python
# @save 装饰器:将此函数保存到 d2l 命名空间,方便后续复用
def tokenize_nmt(text, num_examples=None):
"""词元化"英语-法语"数据数据集"""
source, target = [], [] # 分别存储源语言(英语)和目标语言(法语)的词元列表
# 按换行符分割文本,每行是一对句子(英语\t法语)
for i, line in enumerate(text.split('\n')):
# 如果指定了 num_examples,且超过该数量则提前停止
if num_examples and i > num_examples:
break
parts = line.split('\t') # 用制表符分割,得到 [英语句子, 法语句子]
if len(parts) == 2: # 确保确实有两个部分(有些行可能为空或格式错误)
# 将每个句子按空格拆分成词元列表,存入对应列表
source.append(parts[0].split(' ')) # 英语句子 -> 词元列表
target.append(parts[1].split(' ')) # 法语句子 -> 词元列表
return source, target # 返回两个列表,每个元素是一个词元列表
# 调用 tokenize_nmt 处理预处理后的文本 text,得到源和目标词元列表
source, target = tokenize_nmt(text)
# 打印前6个样本的源和目标词元列表,检查结果
source[:6], target[:6]
# @save 装饰器:保存此绘图函数到 d2l
def show_list_len_pair_hist(legend, xlabel, ylabel, xlist, ylist):
"""绘制列表长度对的直方图"""
d2l.set_figsize() # 设置 matplotlib 图形大小(默认值)
# 计算 xlist 和 ylist 中每个子列表的长度,然后绘制两个直方图叠加
# [[len(l) for l in xlist], [len(l) for l in ylist]] 是一个长度为2的列表,
# 每个元素是长度列表,传给 hist 会同时绘制两组数据的直方图
_, _, patches = d2l.plt.hist(
[[len(l) for l in xlist], [len(l) for l in ylist]])
d2l.plt.xlabel(xlabel) # 设置 x 轴标签
d2l.plt.ylabel(ylabel) # 设置 y 轴标签
# 为第二组直方图(target)添加斜线填充图案,便于区分
for patch in patches[1].patches:
patch.set_hatch('/')
d2l.plt.legend(legend) # 添加图例,legend 参数应包含两个名称
# 调用函数,绘制源和目标句子长度分布的直方图
show_list_len_pair_hist(['source', 'target'], '# tokens per sequence',
'count', source, target);
"""
plt.hist()返回什么?
matplotlib.pyplot.hist()返回一个元组,包含三个元素:
第一个返回值:n------ 每个区间的频数(数组)
第二个返回值:bins------ 区间边界(数组)
第三个返回值:patches------ 一个包含所有柱状图对象的列表(BarContainer或 Rectangle列表)
示例:
n, bins, patches = plt.hist(data)
为什么用 _, _, patches?
在这段代码中,我们只需要 patches,因为后面要遍历 patches[1].patches来修改第二组柱子的填充样式(添加斜线)。
第一个 _忽略频数数组
第二个 _忽略区间边界数组
patches接收柱状图对象列表
"""结果:

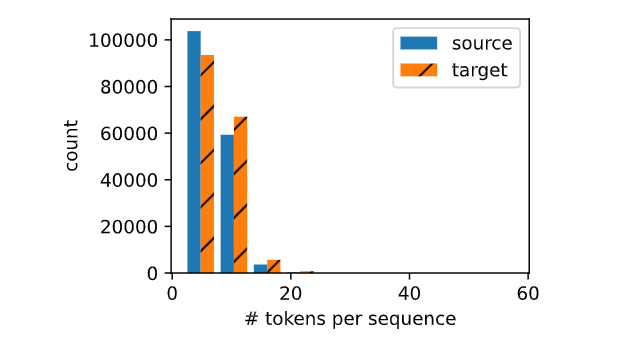
看得出基本句子都在10左右/以内,然后英语的短一些
文本处理例子:
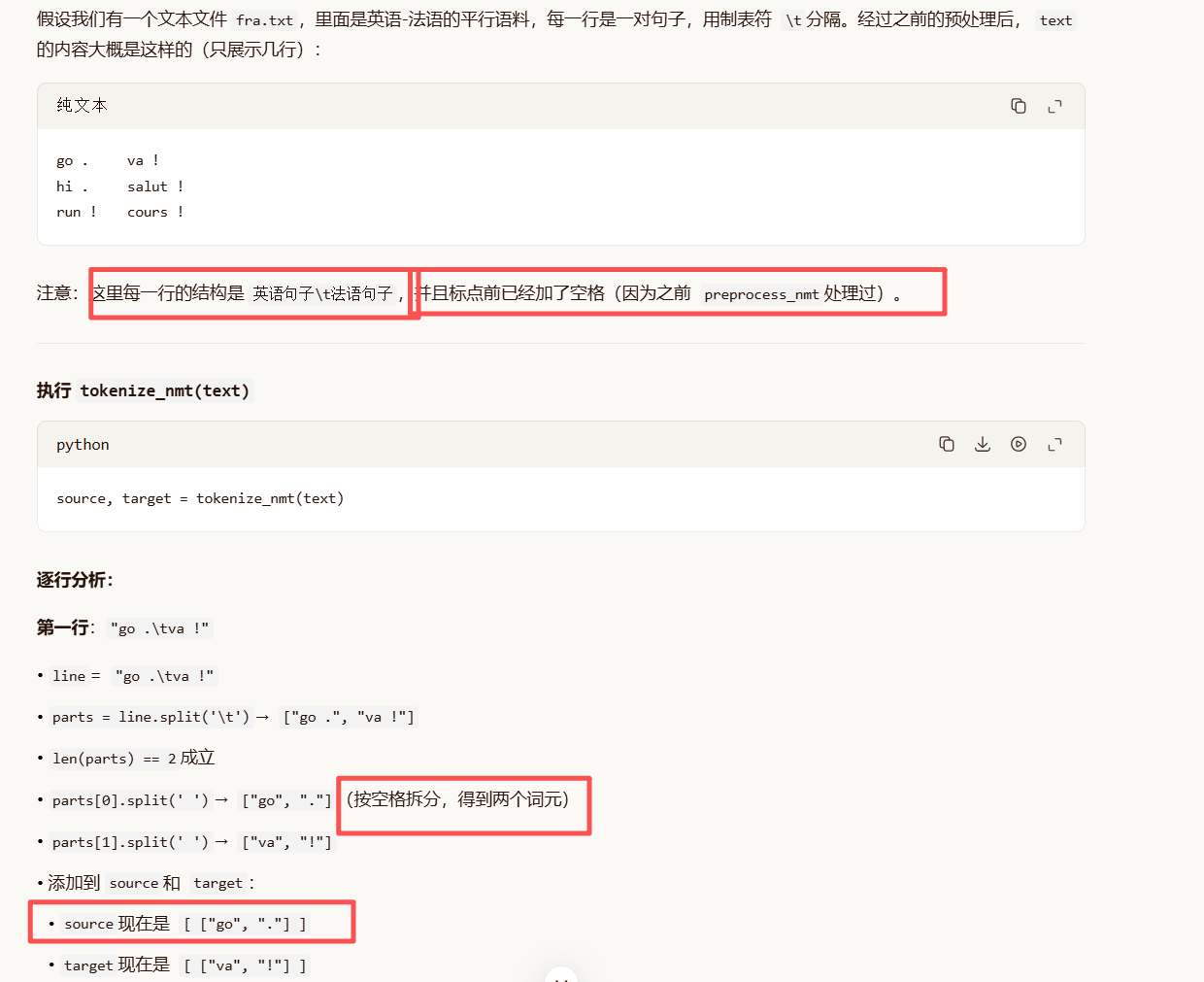
最终res: source和 target都是列表的列表,每个内层列表代表一个句子的词元序列。
source = [
"go", ".",
"hi", ".",
"run", "!"
]
target = [
"va", "!",
"salut", "!",
"cours", "!"
]
绘图函数说明:
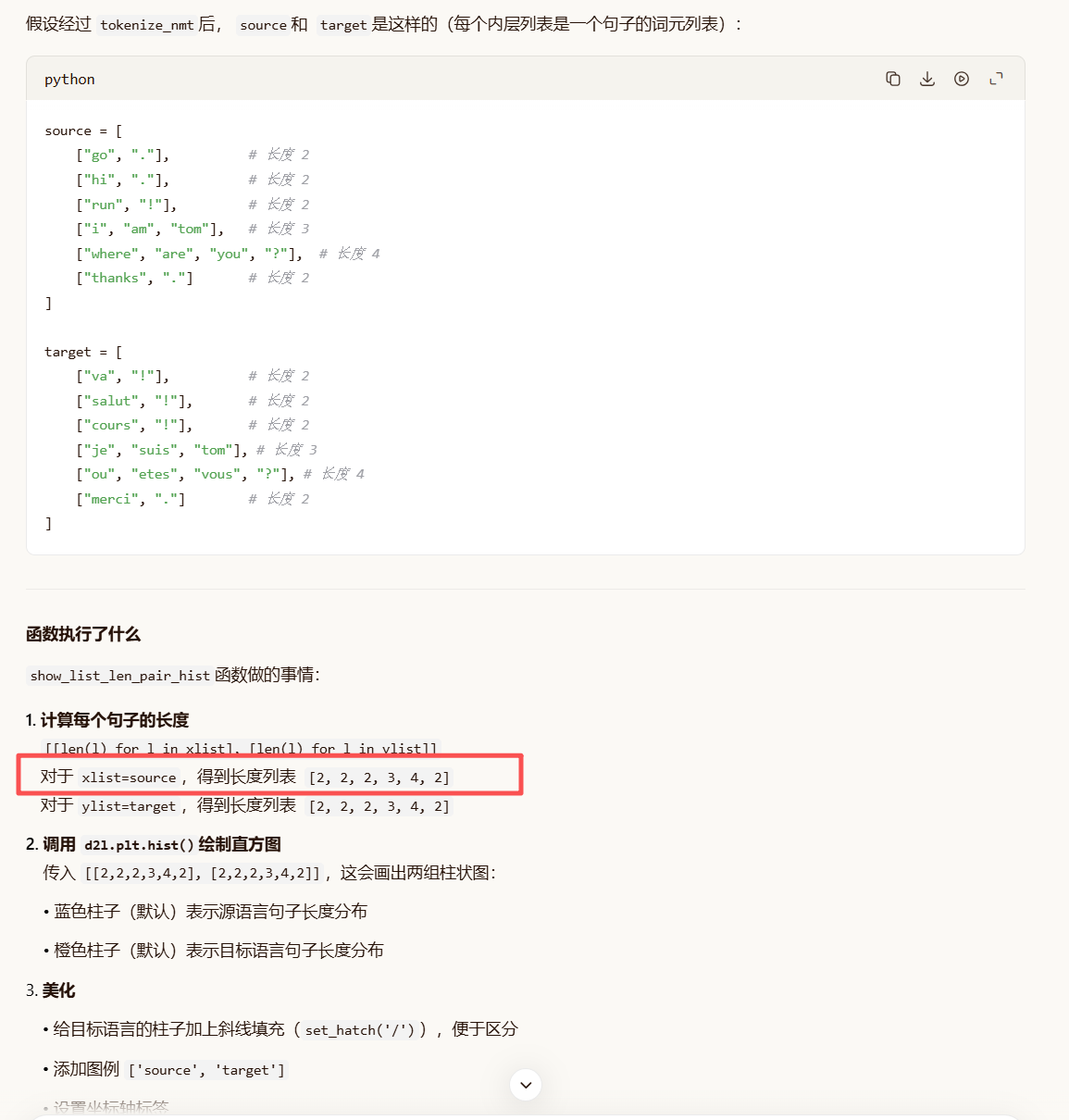
能看到的图形效果
横轴:每个句子的词元数(# tokens per sequence)
纵轴:出现该长度的句子数量(count)
对于上面的例子,你会看到:
-
长度为 2 的句子有 4 条(source 和 target 各 4 条,实际上重叠了)
-
长度为 3 的句子各有 1 条
-
长度为 4 的句子各有 1 条
柱状图会显示两组数据叠加,通过颜色和填充图案区分。
构建词表
由于机器翻译数据集由语言对 组成, 因此我们可以分别为源语言和目标语言构建两个词表。
使用单词级词元化时,词表大小将明显大于使用字符级词元化时的词表大小。 为了缓解这一问题,这里我们将出现次数少于2次的低频率词元 视为相同的未知("<unk>")词元 。 除此之外,我们还指定了额外的特定词元, 例如在小批量时用于将序列填充到相同长度的填充词元("<pad>"), 以及序列的开始词元("<bos>")和结束词元("<eos>")。 这些特殊词元在自然语言处理任务中比较常用。
python
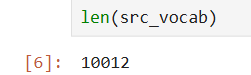
src_vocab = d2l.Vocab(source, min_freq=2,
reserved_tokens=['<pad>', '<bos>', '<eos>'])
len(src_vocab)
"""
前面章节有写的构建词表函数,意思是频率小于2的词不要了,然后bos是begin of sensence
"""
加载数据集
python
"""
语言模型中的[序列样本都有一个固定的长度],无论这个样本是一个句子的一部分还是跨越了多个句子的一个片断。这个固定长度是由 :numref:sec_language_model中的 num_steps(时间步数或词元数量)参数指定的。
在机器翻译中,每个样本都是由源和目标组成的文本序列对,其中的每个文本序列可能具有不同的长度。
为了提高计算效率,我们仍然可以通过截断(truncation)和 填充(padding)方式实现一次只处理一个小批量的文本序列。
假设同一个小批量中的每个序列都应该具有相同的长度num_steps,那么如果文本序列的词元数目少于num_steps时,我们将继续在其末尾添加特定的"<pad>"词元,直到其长度达到num_steps;
反之,我们将截断文本序列时,只取其前num_steps 个词元,并且丢弃剩余的词元。
这样,每个文本序列将具有相同的长度,以便以相同形状的小批量进行加载。
"""
# @save 装饰器:将此函数保存到 d2l 命名空间,方便后续复用
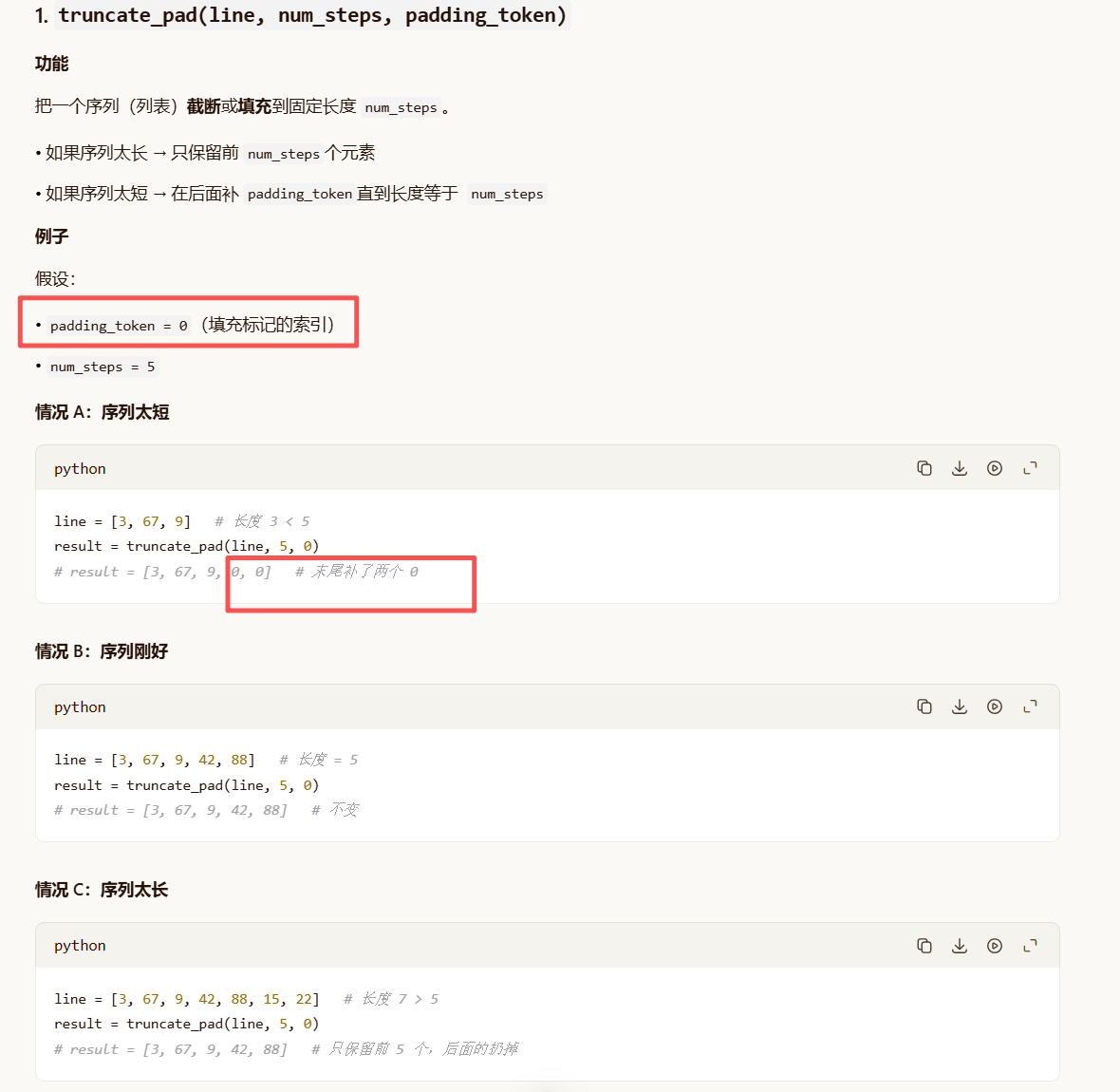
def truncate_pad(line, num_steps, padding_token):
"""截断或填充文本序列至固定长度 num_steps"""
if len(line) > num_steps:
# 如果序列长度超过 num_steps,则截断前 num_steps 个词元
return line[:num_steps]
# 否则,在序列末尾填充 padding_token,使总长度达到 num_steps
return line + [padding_token] * (num_steps - len(line))
# 测试调用:取 source 中第一个句子的词元索引列表,截断或填充至长度 10
# src_vocab[source[0]] 将第一个句子的词元转换为对应的整数索引列表
# src_vocab['<pad>'] 获取填充标记的索引
truncate_pad(src_vocab[source[0]], 10, src_vocab['<pad>'])
[47, 4, 1, 1, 1, 1, 1, 1, 1, 1]
"""
定义一个函数,可以将文本序列 [转换成小批量数据集用于训练]。
将特定的"<eos>"词元添加到所有序列的末尾, 用于表示序列的结束。
当模型通过一个词元接一个词元地生成序列进行预测时, 生成的"<eos>"词元说明完成了序列输出工作。
此外,我们还记录了每个文本序列的长度,统计长度时排除了填充词元,在稍后将要介绍的一些模型会需要这个长度信息。
"""
# @save 装饰器:保存此函数到 d2l
def build_array_nmt(lines, vocab, num_steps):
"""将机器翻译的文本序列转换成小批量(张量 + 有效长度)"""
# 第一步:将每个句子(词元列表)转换为词汇表中的索引列表
lines = [vocab[l] for l in lines] # vocab[l] 返回词元 l 对应的索引
# 第二步:在每个句子末尾添加 <eos>(句子结束符)的索引
lines = [l + [vocab['<eos>']] for l in lines]
# 第三步:对每个句子进行截断或填充至 num_steps,并转换为张量
array = torch.tensor([truncate_pad(
l, num_steps, vocab['<pad>']) for l in lines])
# 第四步:计算每个样本的有效长度(非填充标记的数量)
# (array != vocab['<pad>']) 生成布尔张量,True 表示有效位置
# .type(torch.int32) 转为整型(True→1, False→0)
# sum(1) 沿第1维求和,得到每个样本的有效长度
valid_len = (array != vocab['<pad>']).type(torch.int32).sum(1)
return array, valid_len # 返回填充后的张量和有效长度张量例子说明:
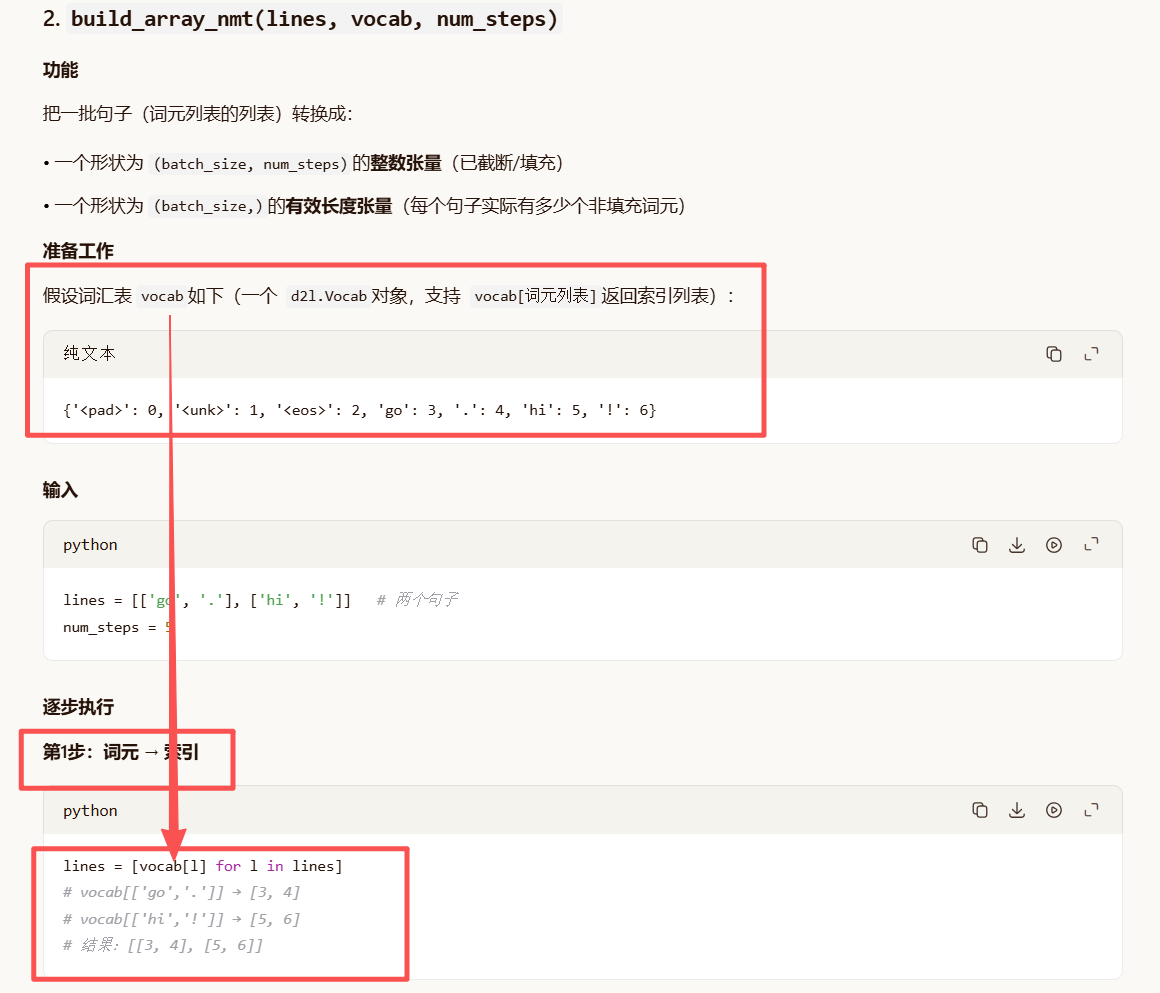
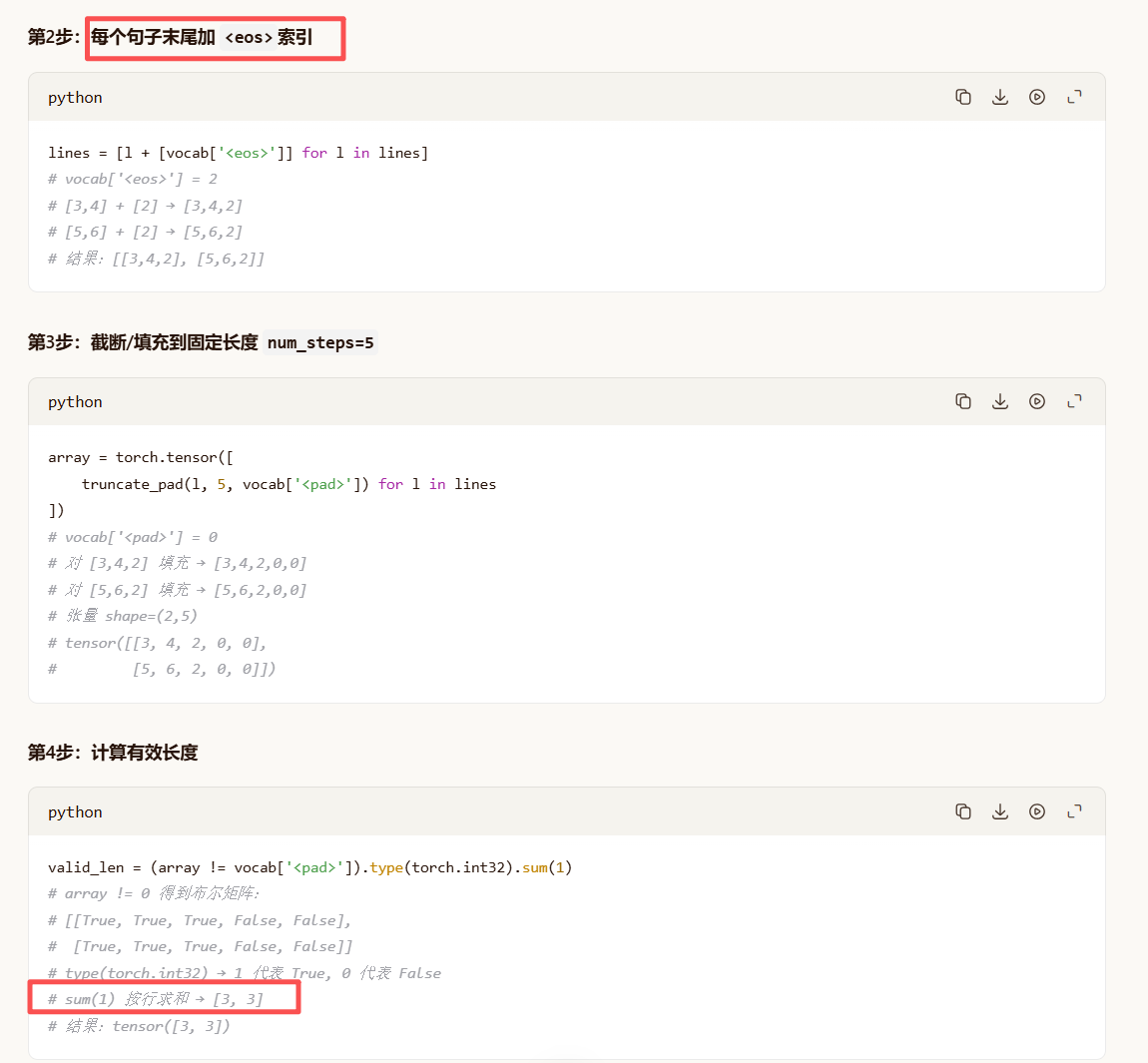
最终输出
array = tensor([[3, 4, 2, 0, 0],
[5, 6, 2, 0, 0]])
valid_len = tensor([3, 3])-
array可以直接喂给模型(如 LSTM/Transformer),模型知道哪些位置是填充(通过valid_len或 attention mask)。 -
valid_len告诉模型每个句子实际有多少个真实词元(不含<pad>),常用于计算损失时忽略填充位置,或在 RNN 中动态控制序列长度。
补充说明:


训练模型
定义load_data_nmt函数来返回数据迭代器, 以及源语言和目标语言的两种词表
python
# @save 装饰器:将此函数保存到 d2l 命名空间,方便后续复用
def load_data_nmt(batch_size, num_steps, num_examples=600):
"""返回翻译数据集的迭代器和词表"""
# 1. 预处理原始文本(替换特殊空格、转小写、标点前加空格)
text = preprocess_nmt(read_data_nmt())
# 2. 词元化:将文本按行分割,每行按制表符分为源和目标,再按空格拆成词元列表
source, target = tokenize_nmt(text, num_examples)
# 3. 构建源语言词表:基于 source 中的所有词元,过滤掉频率低于 2 的词,保留特殊标记
src_vocab = d2l.Vocab(source, min_freq=2,
reserved_tokens=['<pad>', '<bos>', '<eos>'])
# 4. 构建目标语言词表:同理
tgt_vocab = d2l.Vocab(target, min_freq=2,
reserved_tokens=['<pad>', '<bos>', '<eos>'])
# 5. 将源语言句子转换为固定长度的索引张量,并计算有效长度
src_array, src_valid_len = build_array_nmt(source, src_vocab, num_steps)
# 6. 将目标语言句子转换为固定长度的索引张量,并计算有效长度
tgt_array, tgt_valid_len = build_array_nmt(target, tgt_vocab, num_steps)
# 7. 组合四个数据数组
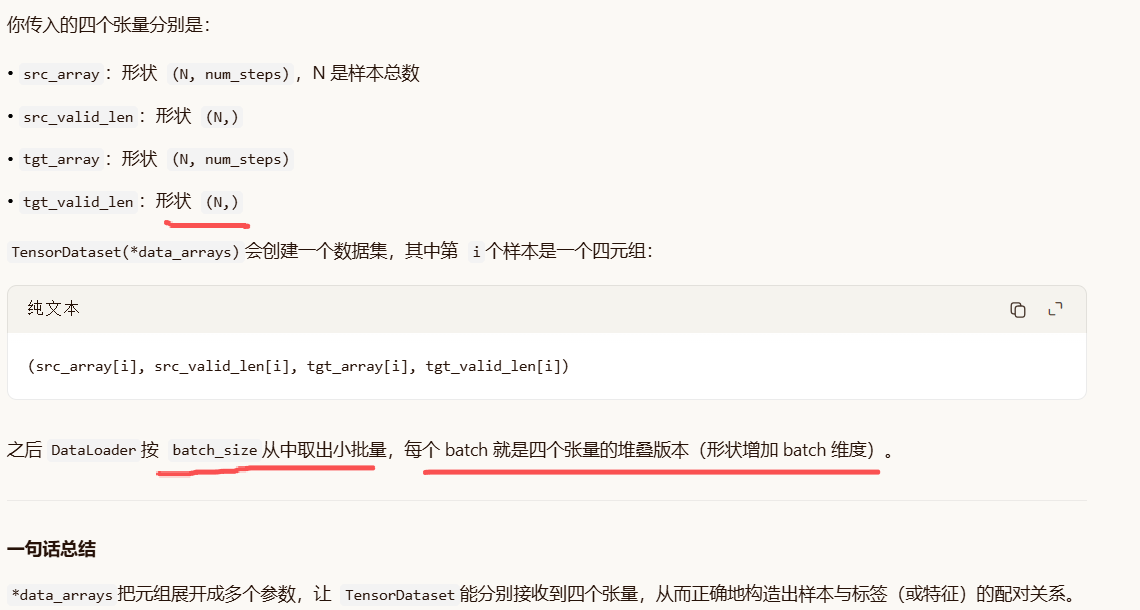
data_arrays = (src_array, src_valid_len, tgt_array, tgt_valid_len)
# 8. 使用 d2l 的数据加载器,按 batch_size 打包成迭代器
data_iter = d2l.load_array(data_arrays, batch_size)
# 9. 返回数据迭代器、源词表、目标词表
return data_iter, src_vocab, tgt_vocab
# 调用 load_data_nmt,设置 batch_size=2,num_steps=8(每个句子固定长度)
train_iter, src_vocab, tgt_vocab = load_data_nmt(batch_size=2, num_steps=8)
# 从迭代器中取一个小批量数据
for X, X_valid_len, Y, Y_valid_len in train_iter:
# X: 源语言句子张量,形状 (batch_size, num_steps),已填充/截断
print('X:', X.type(torch.int32))
# X_valid_len: 每个源句子的有效长度(不含 <pad>),形状 (batch_size,)
print('X的有效长度:', X_valid_len)
# Y: 目标语言句子张量,形状 (batch_size, num_steps)
print('Y:', Y.type(torch.int32))
# Y_valid_len: 每个目标句子的有效长度
print('Y的有效长度:', Y_valid_len)
break # 只打印第一批数据就退出循环DataLoader 负责把数据切成每 2 行一组(Batch Size=2)。
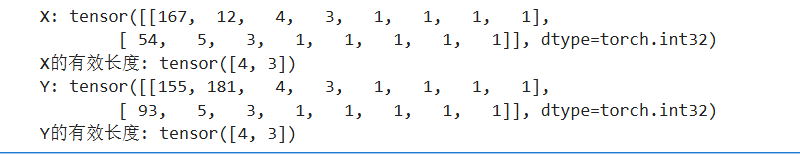
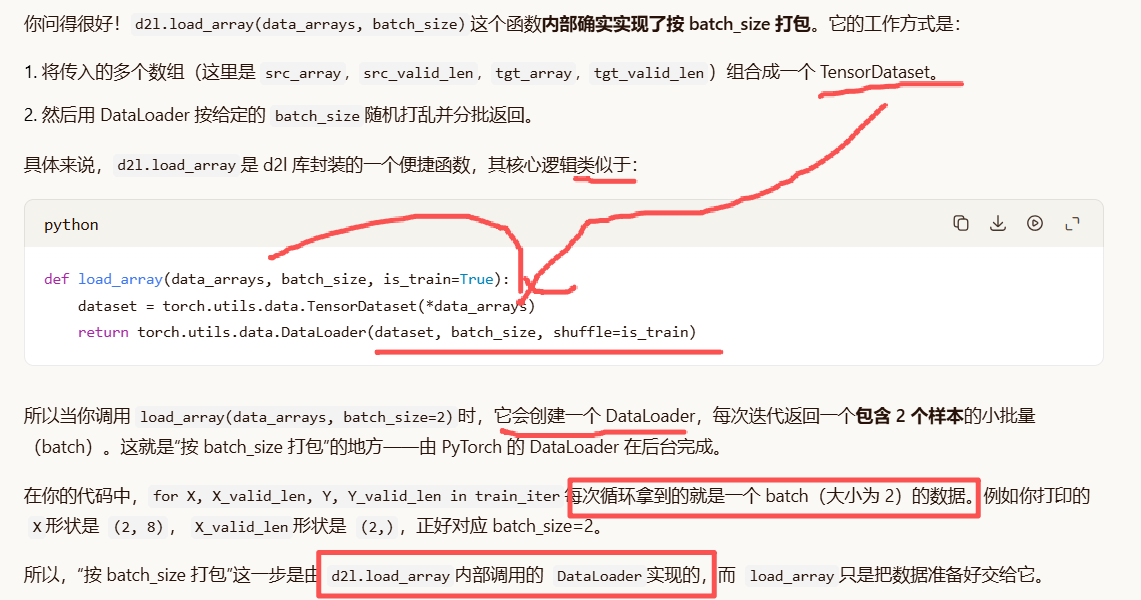
datadownloader:
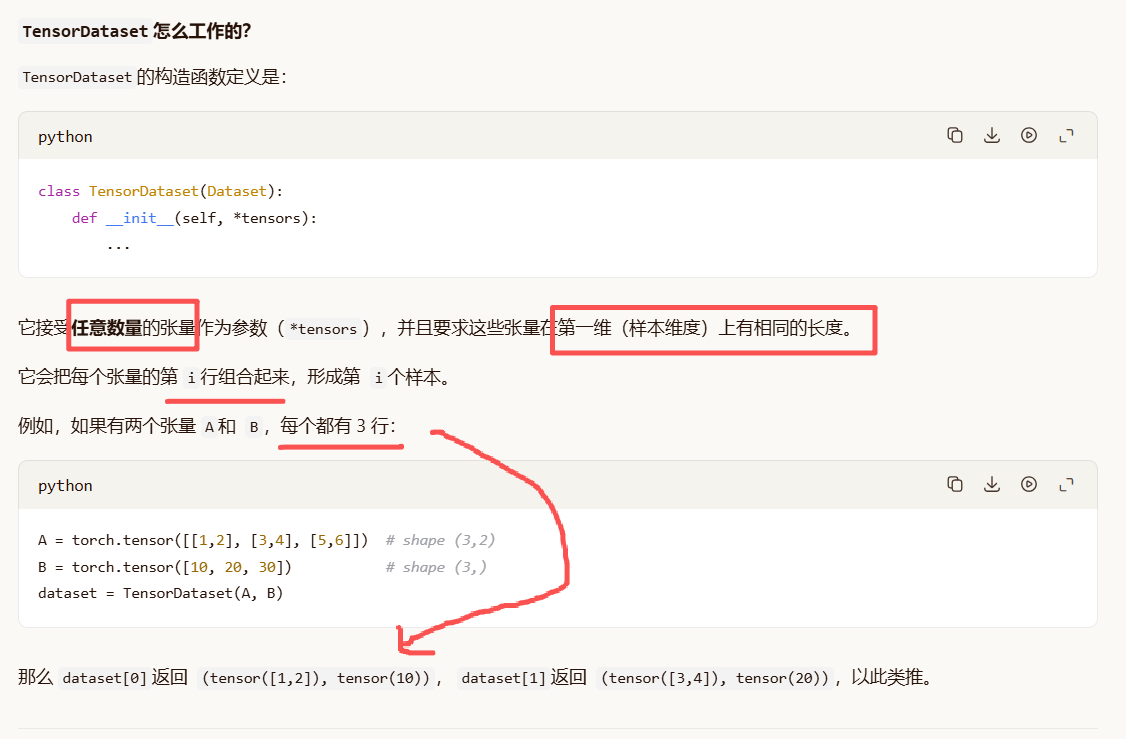
我们的代码: