第一层:基础概念
很多人只记死规则:联合索引遵循最左前缀匹配(比如建立(a,b,c)联合索引,查询条件带a,索引才有可能生效)
但是有没有想过:单独查b,单独查c,索引为什么直接失效?查询顺序和索引列顺序不一致,加不加括号,又会不会影响索引命中?
先从联合索引的B+树入手,其实在遍历B+树过程中,就是通过>和<(如果只有一个字段)来判断在树中应该是往左子节点走还是右子节点走的,对于(a,b,c)这种有多个字段的联合索引,我们需要重构>和<,排序规则从原来的只排序一个字段到按顺序从左往右依次排序(是不是和基数排序很像,就是对与一组数字,从高位到低位进行排序)

1)那么我们回答第一个问题:单独查b,单独查c,索引为什么直接失效?
因为我们是按照a->b->c的顺序进行排序的,当a相同的时候,才对后面的字段进行排序,导致同样满足(b==?或者c==?)的多个数据行因为a不同分配到不同的内存部分,如果我们还想走这个索引,就只能够遍历所有a的值,变成(a==? AND b==?或者a==? AND c==?),那还不如全表查询。
2)第二个问题:查询顺序和索引列顺序不一致,会不会影响索引命中?
**不影响!**MySQL 优化器会自动重排 AND 条件,WHERE b=2 AND a=1 等价于 WHERE a=1 AND b=2
3)第三个问题:加括号影响索引命中吗?
这个要分条件,如果你的查询条件全是AND,那随便怎么加括号都不影响,就像(1+2)+3和1+1+(2+3)等价
sql
-- 这三种写法是完全等价的
WHERE b=2 AND a=1 AND c=3
WHERE (b=2 AND a=1) AND c=3
WHERE b=2 AND (a=1 AND c=3)
MySQL 优化器拿到这三种写法后,都会重排成:
WHERE a=1 AND b=2 AND c=3但是,如果有OR,就不能乱加括号了,会改变逻辑含义
sql
-- 写法 A:a=1 是前提,OR 只在 b 和 c 之间
WHERE a=1 AND (b=2 OR c=3)
-- 含义:先找 a=1 的所有人,再在其中找 b=2 或 c=3 的
-- → a 的索引能用 ✓(因为 a=1 是必须满足的)
-- 写法 B:OR 在最顶层,a=1+b=2 只是其中一个分支
WHERE (a=1 AND b=2) OR c=3
-- 含义:要么满足(a=1且b=2),要么满足(c=3)
-- → c=3 这个分支跳过了 a!走联合索引失效 ✗第二层:查询类型影响
1)第1个问题:范围查询会不会导致索引失效?
会!但是是部分失效!
拿 INDEX(a, b, c) + WHERE a=1 AND b>2 AND c=3 来讲:
| 层级 | 列 | 条件 | 索引状态 | 原因 |
|---|---|---|---|---|
| 前面的列 | a | a=1 等值 | ✅ 命中 | 等值匹配,锁定连续范围 |
| 截断点(当前列) | b | b>2 范围 | ✅ 命中 | 在 a=1 范围内,b 是有序的,>2 可以定位到范围起点 |
| 后面的列 | c | c=3 等值 | ❌ 失效 | b 是范围,跨越了多个 b 值,c 在不同 b 下面交织散列 |
但是有一个特殊情况,IN = 多次等值,不截断 。WHERE a IN (1,2) AND b=3 等价于 a=1 AND b=3 或 a=2 AND b=3,两次等值查找
还有其他的会截断后面列索引的操作符:
| 触发截断(范围查询) | 不触发截断(等值查询) |
|---|---|
>, <, >=, <= |
=, IN |
BETWEEN x AND y |
--- |
LIKE 'abc%'(前缀匹配) |
--- |
!=, <> |
--- |
IS NOT NULL |
IS NULL(等值) |
特别注意:
IN= 多次等值,不截断 。WHERE a IN (1,2) AND b=3等价于a=1 AND b=3或a=2 AND b=3,两次等值查找LIKE 'abc%'= 前缀范围匹配,截断 后续列。比如WHERE name LIKE '王%'等价于name >= '王' AND name < '球'(按字典序,可以用当前列索引)LIKE '%abc%'= 两边通配符和后缀范围匹配,完全无法用索引,连当前列都不行!=/<>= 反向范围,也截断后续列(而且当前列的索引利用效率也很低)
有聪明的小伙伴就想到了,比如这个例子:
拿 INDEX(a, b, c) + WHERE a=1 AND b>2 AND c=3
我可以加一个索引INDEX(b)
INDEX(a, b, c)+INDEX(b)+WHERE a=1 AND c=3 AND b IN(SELECT FROM 表 WHERE b>2)
这样确实全部走了索引,但是如果你b的值域如果很小(10种值以内的话,比如一些枚举值)这个方案有效!
但是假如你b的值域很大,就需要执行几百次甚至几千几万次SQL查询,就算走了索引,也完全不如范围查询
这个问题有一个更好的解决方案就是调整联合索引的顺序,将 INDEX(a, b, c)改成 INDEX(a, c, b)但是这个得看具体的应用场景下有没有其他SQL使用了原来的 INDEX(a, b, c)索引,如果贸然修改的话可能会导致你这个SQL优化了,其他SQL恶化了的问题
2)第2个问题:隐式类型转换、字符集不一致,明明建了索引,但是就是没有用?
常见场景:数字和字符串混用
sql
-- phone 字段是 VARCHAR(20),建了 INDEX(phone)
-- 你这样写:
WHERE phone = 13800138000 -- ← 没加引号!发生了什么?
- MySQL 发现左边是 VARCHAR,右边是 INT
- MySQL 的规则是:把列值转成右边类型
- 实际执行变成了:
CAST(phone AS SIGNED) = 13800138000 - CAST 函数作用在索引列上 → 索引失效!→ 全表扫描!
这跟写 WHERE UPPER(name) = 'ABC' 是同一个道理------函数包住了列,索引直接废掉。
怎么修复?
sql
-- 加引号,让两边都是字符串
WHERE phone = '13800138000' -- ✓ 索引正常工作字符集不一致同理
sql
-- 表字段定义:
name VARCHAR(50) COLLATE utf8mb4_general_ci
-- 但你的连接字符集是:
SET NAMES latin1 -- 或 utf8mb4_bin(排序规则不同)排序规则不同时,MySQL 认为无法安全地使用索引做比较(因为比较结果可能不同),于是放弃索引走全表扫描。
修复:确保连接字符集和表字段一致:
sql
SET NAMES utf8mb4 COLLATE utf8mb4_general_ci;第三层:结合业务优化
1)第1个问题:group by、order by、limit和联合索引结合时,哪些列能被索引覆盖、减少排序?
ORDER BY 能走索引排序的条件!但是对顺序敏感
| SQL | INDEX(a, b, c) | 结果 |
|---|---|---|
ORDER BY a |
✅ 命中前缀 | 直接有序 |
ORDER BY a, b, c |
✅ 完全匹配 | 最优,无 filesort |
ORDER BY a DESC, b DESC, c DESC |
✅ 全反序 | 反向扫描 B+ 树即可 |
ORDER BY a ASC, b DESC |
❌ 混合升降序 | filesort! |
ORDER BY b, a |
❌ 顺序不匹配 | filesort! |
ORDER BY c |
❌ 跳过前面列 | filesort! |
关键细节:
- ORDER BY 必须从索引最左列开始连续匹配------跟 WHERE 的最左前缀规则一样
- 所有列必须同升或同降,混合升降序必触发 filesort
- MySQL 8.0 支持函数索引可以绕过一些限制,但 5.x 不行
GROUP BY 本质上需要排序(才能聚合),所以它的索引使用规则跟 ORDER BY 几乎一样:
sql
INDEX(a, b, c)
GROUP BY a → ✅ 用索引有序性,直接聚合
GROUP BY a, b → ✅ 匹配前缀
GROUP BY b, a → ❌ 顺序错,Using temporary + filesort
GROUP BY c → ❌ 跳过a和b,全表扫描 + 排序filesort = "MySQL 无法利用索引的天然有序性,不得不自己额外做一次排序操作"
Using temporary 比 filesort 更可怕------它意味着 MySQL 需要创建一张临时表来存储中间结果,内存不够还会落盘。
LIMIT 单独没意义,但它配合 ORDER BY 索引时有奇效:
sql
-- INDEX(create_time)
SELECT * FROM user ORDER BY create_time DESC LIMIT 10
-- 只需反向扫描索引取前10条就返回!
-- 不需要扫描整个表,不需要回表所有数据
-- 这是分页查询性能优化的核心技巧但如果 ORDER BY 没走索引(触发了 filesort),LIMIT 只是减少最终返回的行数,前面的排序还是要做全部。
2)第2个问题:联合索引里,把区分度高的字段放前面还是把等值查询字段放前面?字段顺序设计的核心依据到底是什么?
正确的三步决策法
Step 1:等值查询列优先放最前(最重要)
sql
-- 你的高频查询:
WHERE status = 1 AND age > 20 ORDER BY name
-- 正确顺序: INDEX(status, name, age)
-- 等值列(status) → 排序列(name) → 范围列(age)
-- 错误顺序: INDEX(age, status, name)
-- 区分度再高也没用,age是范围查询,放在前面浪费了原因:等值查询能锁定的行数最少(筛选力最强),放在最前面能最大程度缩小后续操作的基数。
Step 2:多个等值列时,按两个维度排
| 维度 | 规则 | 示例 |
|---|---|---|
| 区分度 | 区分度越高越靠前 | status(10种值) vs gender(2种值) → status 放前 |
| 频率 | 高频查询中先出现的放前 | 如果90%查询都先查 shop_id,它就该放第一 |
当两者冲突时:
- 区分度差距大(比如 10000 种 vs 2 种)→ 听区分度的
- 区分度差不多 → 听查询频率的
- 实际工作中,等值列通常就1~2个,不太会出现纠结的情况
tep 3:排序列在范围列之前
sql
-- 高频查询:
WHERE status = 1 AND age > 20 ORDER BY create_time
-- ✅ 正确: INDEX(status, create_time, age)
-- status 等值锁定 → create_time 有序可排序 → age 放最后截断无害
-- ❌ 错误: INDEX(status, age, create_time)
-- age 范围查询截断了 create_time → ORDER BY 无法用索引 → filesort!一句话口诀:等值 → 排序/分组 → 范围
3)第3个问题:还有多条件组合查询,多条SQL共用一套联合索引,该如何取舍列的排布?
实际项目中不可能为每条 SQL 建专用索引,必须在多个查询之间做权衡。
取舍原则:帕累托最优(80/20 法则)
假设你有三条查询共用一张订单表:
sql
-- SQL-A (每天执行 50 万次): 列表页
WHERE shop_id = 100 AND status IN (1,2)
ORDER BY created_at DESC LIMIT 20
-- SQL-B (每天执行 5 万次): 商家后台筛选
WHERE shop_id = 100 AND created_at > '2026-01-01'
-- SQL-C (每天执行 500 次): 运营报表
WHERE status = 1 AND pay_type = 'wechat'建 INDEX(shop_id, status, created_at):
| SQL | 使用情况 | 性能 |
|---|---|---|
| SQL-A | shop_id + status 等值命中,created_at 排序命中 | ⭐⭐⭐ 最优 |
| SQL-B | shop_id 等值命中,created_at 范围命中 | ⭐⭐ 很好 |
| SQL-C | 跳过 shop_id,status 等值但不是最左前缀 | ⚠️ 只用到部分 |
取舍结论:牺牲 SQL-C(给低频的它单独建一个 status 索引),保证 SQL-A 和 SQL-B 走最优路径。
四条黄金法则
- 优先保证高频 SQL 的最优路径 ------ 一条每天跑 50 万次的查询优化 10ms = 每天省 1.4 小时 CPU 时间
- 中频 SQL 保证"能用就行" ------ 命中部分索引列已经比全表快很多了
- 低频 SQL 允许慢甚至全表 ------ 报表类查询一天跑几次,慢几秒无所谓
- 不要为了覆盖一条冷门 SQL 而拖垮热门查询 ------ 这是新手最容易犯的错误
第四层:底层存储与性能
1)第一个问题:联合索引在 B+ 树里到底是怎么存的?
先看底层物理结构------很多人以为联合索引是"多棵树",其实只有一棵树。

2)第二个问题:覆盖索引如何配合联合索引,对回表+IO开销有什么影响?
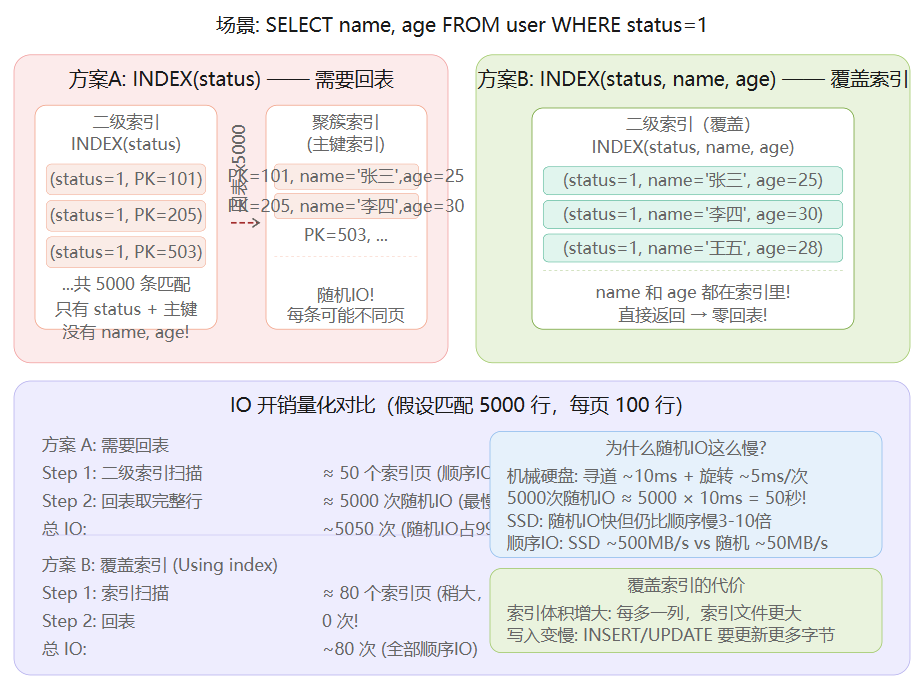
回表 = 用二级索引找到的主键 ID,再去聚簇索引(主键索引)里找完整行数据。
这是 MySQL InnoDB 最耗性能的操作之一,因为:
| 因素 | 影响 |
|---|---|
| 随机 IO | 5000 条匹配行可能散落在 5000 个不同的数据页里,每条都要单独寻址 |
| 机械硬盘 | 每次随机寻道 ~10ms,5000 次 = 50 秒 |
| SSD 好很多 | 但随机 IO 仍比顺序 IO 慢 3~10 倍 |
覆盖索引的魔法:把 SELECT 需要的字段全部放进索引里 → 索引扫描直接拿到所有数据 → 零回表 → 全部顺序 IO
EXPLAIN 里看到 Extra: Using index 就是覆盖索引生效了。
但覆盖索引有代价
- 索引体积膨胀:每多一列,整棵 B+ 树的每条记录都变宽
- 写入变慢:INSERT / UPDATE 要同时更新更多字节到索引
3)第三个问题:大量数据更新、删除时,联合索引的列数越多,为什么写入性能下降越明显?
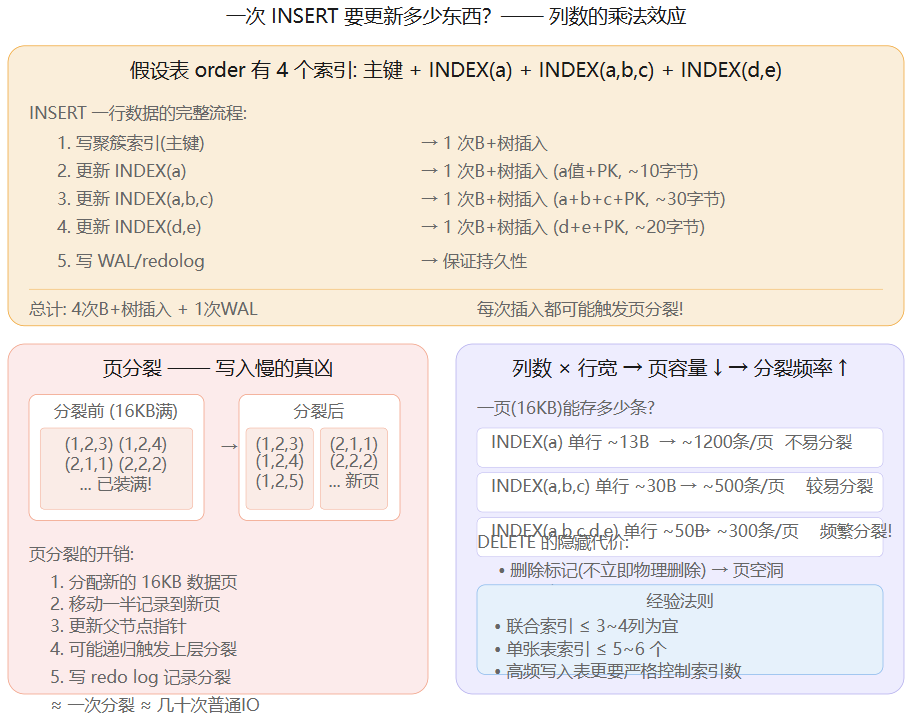
写入性能衰减的三层原因
第一层:写放大(Write Amplification)
一次 INSERT 不是只写一行------而是 N+1 次 B+ 树插入(N = 索引数量)。每多一个索引,INSERT 就多一次完整的 B+ 树操作。表有 6 个索引?一次 INSERT = 7 次树操作。
第二层:页分裂(Page Split)
这是最隐蔽的性能杀手。B+ 树的叶子页大小固定 16KB:
| 索引列数 | 单行大小 | 每页条数 | 分裂频率 |
|---|---|---|---|
| 1 列 | ~13B | ~1200 条 | 低 |
| 3 列 | ~30B | ~500 条 | 中 |
| 5 列 | ~50B | ~300 条 | 高 |
列越多 → 单行越宽 → 每页能存的行越少 → 插入时更容易满 → 页分裂更频繁。一次页分裂 ≈ 几十次普通 IO。
第三层:DELETE 的隐藏代价
MySQL 的 DELETE 不立即物理删除数据,只是打删除标记。大量 DELETE 后:
- 每个索引都有空洞(已删除但未释放的空间)
- 索引碎片化,查询要扫更多无效空间
- 合并页(Merge)比分裂还昂贵
4)第四个问题:索引选择性、索引失效后的慢查询排查思路?
索引选择性
选择性 = Cardinality(基数)/ 总行数
| 字段 | 基数/总行数 | 选择性 | 评价 |
|---|---|---|---|
| gender (男/女) | 2 / 100万 | 0.000002 | 极差,建了索引也几乎没用 |
| status (10种) | 10 / 100万 | 0.01 | 差,只能缩小到 10% |
| phone | 95万 / 100万 | 0.95 | 极好!几乎每行唯一 |
查看方法:
sql
SHOW INDEX FROM table_name\G
-- 看 Cardinality 字段(注意这是估算值)
ANALYZE TABLE table_name; -- 刷新估算值慢查询排查六步法
1. 开启 slow_query_log (long_query_time=1)
2. EXPLAIN → 看 type 列: 拒绝 ALL, 追求 ref/range
3. Extra → Using filesort? Using temporary? 都是危险信号
4. key_len → 确认实际用了索引的几列(字节)
5. rows → MySQL 估算要扫多少行
6. FORCE INDEX(idx_name) 验证你的优化猜想type 列从优到差:system > const > eq_ref > ref > range > index > ALL
看到 ALL = 全表扫描,必须优化;range = 范围扫描,通常可接受。
5)第五个问题:线上大表如何权衡联合索引的数量与字段?
三步决策法:
- 统计 TOP 慢 SQL:按耗时排序取前 10~20 条
- 提取字段模式:分析每个 SQL 的 WHERE(等值/范围)、ORDER BY、GROUP BY 字段
- 设计复合索引覆盖最多 SQL:一个联合索引服务多条高频查询
红线指标(不可逾越):
- 单表索引 ≤ 6 个
- 联合索引列数 ≤ 4 列
- 索引总大小 < 表数据的 50%
删索引的安全流程:
sql
-- 先查哪些索引没人用
SELECT * FROM sys.schema_unused_indexes
WHERE object_schema = 'your_db';
-- 观察 1~2 周,确认无使用后删除
ALTER TABLE order DROP INDEX idx_unused;