很多人用 AI 编程工具,第一句话就是:
plain
帮我写一个接口。这当然可以,但有点浪费。
现在成熟的通用 AI 工具已经很会写代码。真正更值得尝试的,是让 AI 从需求开始参与工程,而不是只在最后一步帮你补几段 Controller 或 Service。
我用飞算 JavaAI 时,感觉它的智能引导更适合这类用法:不要把它当成代码补全,而是当成项目启动助手。
这次就以一个图书管理系统为例,看它如何从一句需求逐步引导到一个 Spring Boot 工程。
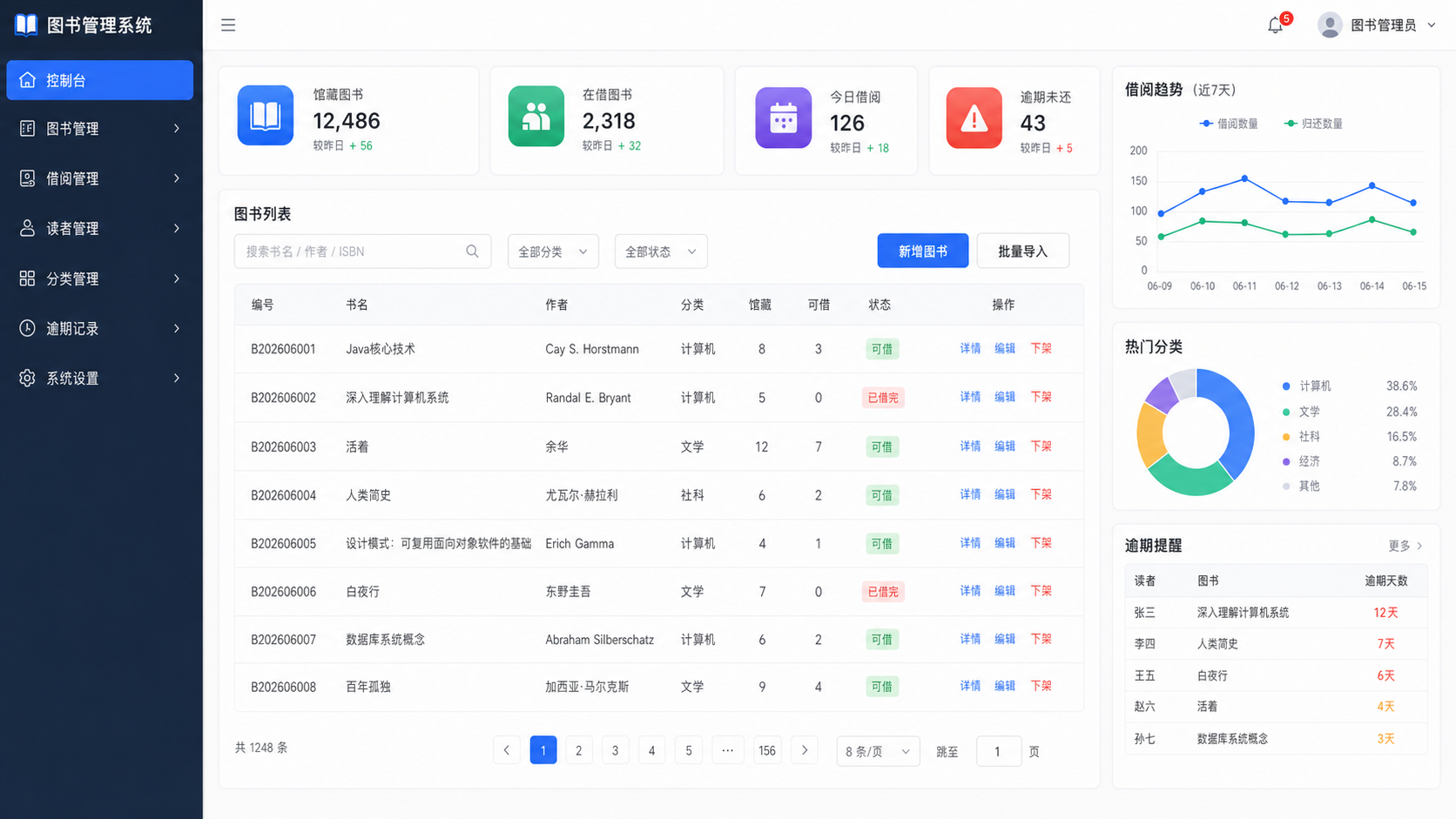
一、不需要把图书管理系统需求拆清楚,直接一句话生成
一句话描述需求:
plain
生成图书管系统如果你要做一个图书管理系统,之前你可能得先让 AI 帮我生成计划文档,然后再执行。但是我们只需要再 飞算 AI 中,提供简短的描述就能,一键生成真实的项目。
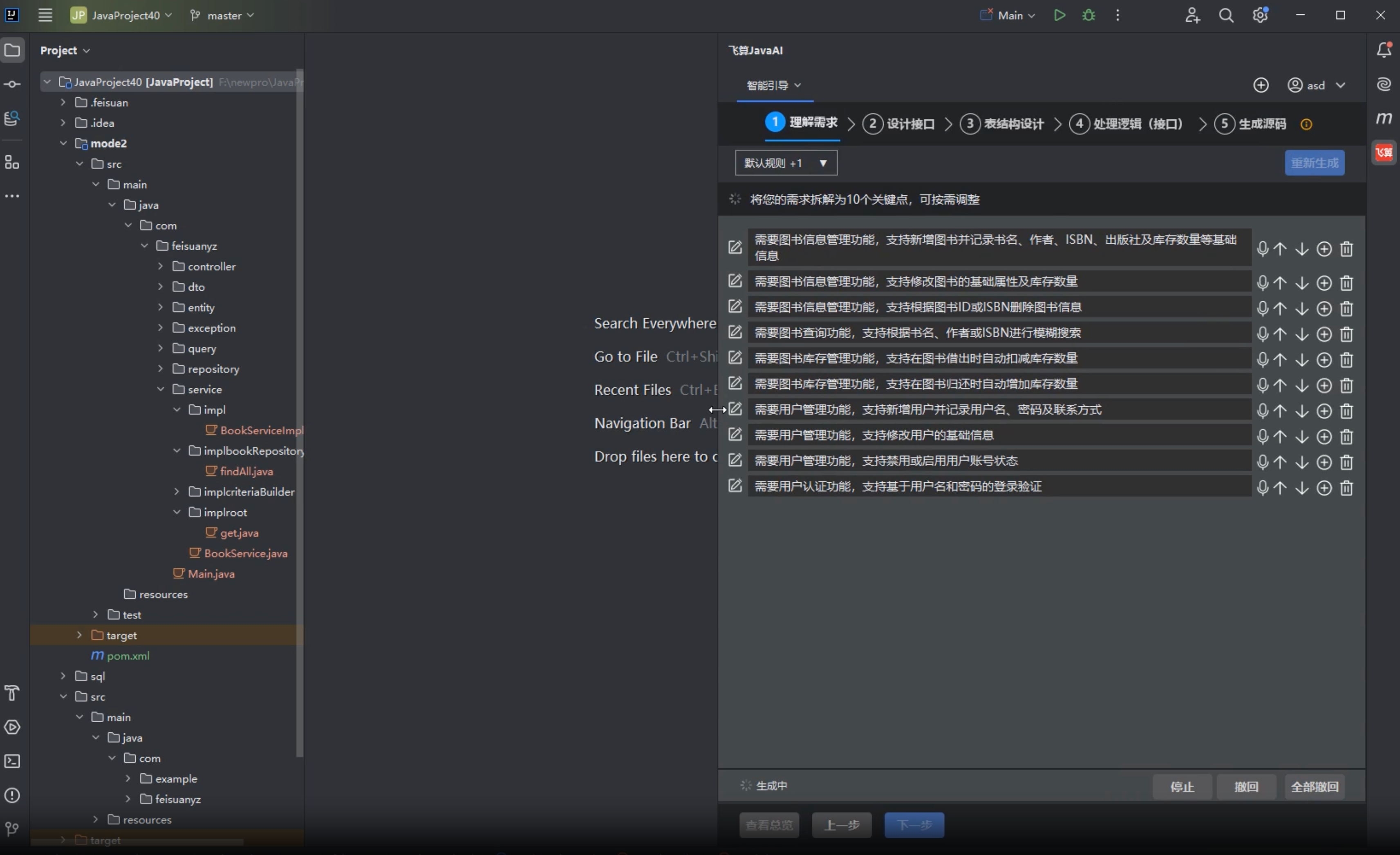
进入飞算 JavaAI 的智能引导后,可以继续把需求拆成更明确的关键点。截图里这类拆解方式就比较适合图书管理系统:
- 需要图书信息管理功能,支持新增图书,并记录书名、作者、ISBN、出版社以及库存数量等基础信息
- 需要图书信息管理功能,支持修改图书的基础属性及库存数量
- 需要图书信息管理功能,支持根据图书 ID 或 ISBN 删除图书信息
- 需要图书查询功能,支持根据书名、作者或 ISBN 进行模糊搜索
- 需要图书库存管理功能,支持在图书借出时自动扣减库存数量
- 需要图书库存管理功能,支持在图书归还时自动增加库存数量
- 需要用户管理功能,支持新增用户,并记录用户名、密码及联系方式
- 需要用户管理功能,支持修改用户的基础信息
- 需要用户管理功能,支持禁用或启用用户账号状态
- 需要用户认证功能,支持基于用户名和密码的登录验证
这样写的好处是,需求不再是一个模糊的大词,而是变成了可以落到代码里的模块和动作。
比如"图书信息管理"会对应图书实体、图书新增接口、图书修改接口、图书删除接口;"库存管理"会对应借出和归还时的库存变更逻辑;"用户认证"会对应登录接口、账号状态校验和密码校验。
AI 最怕的不是需求复杂,而是需求含糊。你把业务对象、业务动作、查询方式、库存规则、账号状态和工程目标讲清楚,它后面生成的 Controller、Service、Repository、Entity 才更容易贴近真实项目。
二、智能引导不是点下一步,要补业务规则
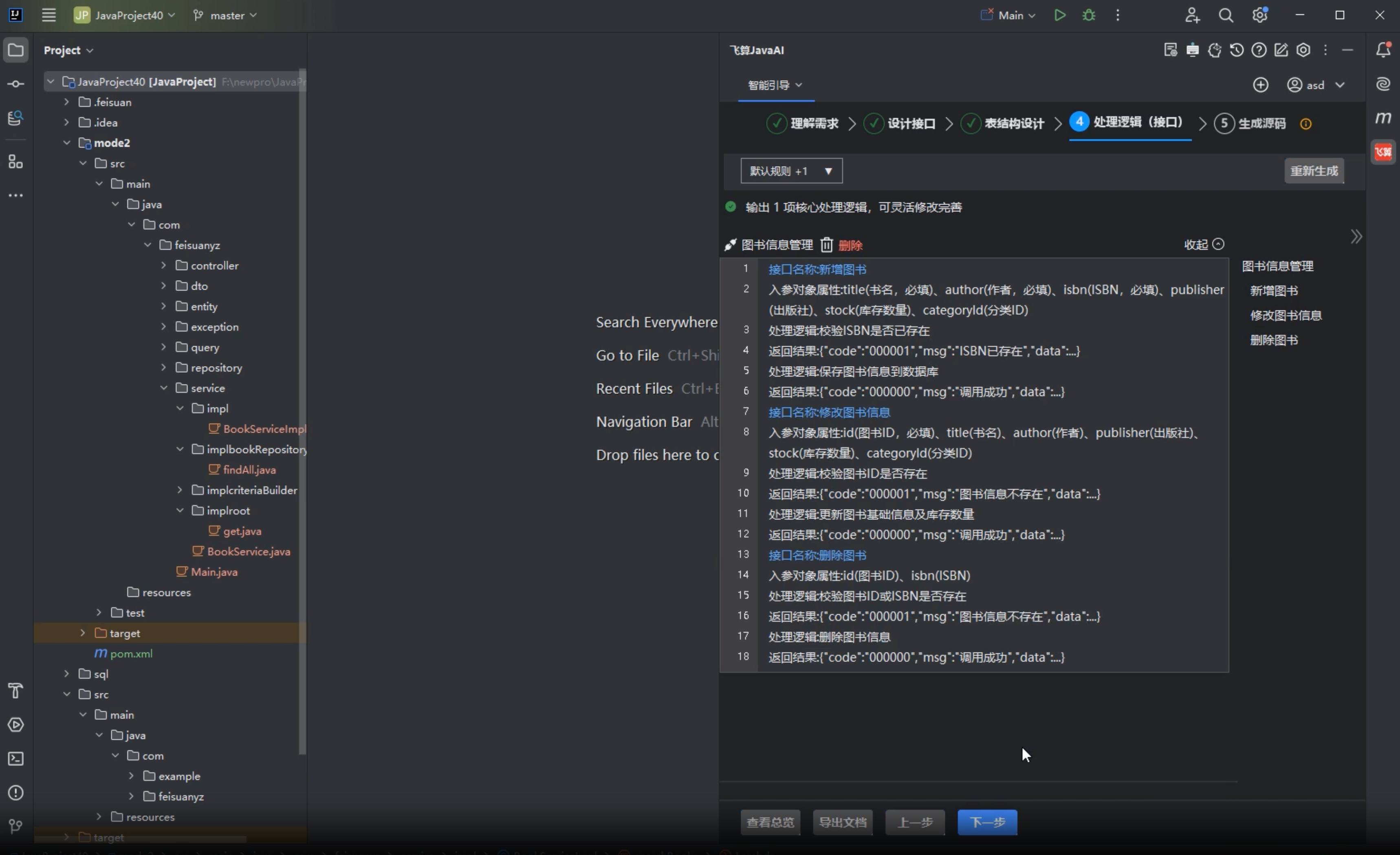
智能引导后面会继续确认一些内容,比如技术栈、数据库、登录鉴权、是否生成 SQL、是否生成接口文档、是否需要后台管理接口。
这些问题看起来基础,但不要随便点过去。
Java 项目很多返工都来自一开始没讲清楚。尤其是图书管理系统这种看起来简单的项目,一旦加入借出、归还、库存、用户状态,边界条件马上就多了。
比如可以在智能引导里补充这些规则:
- ISBN 必须唯一,同一本书不能重复录入
- 库存数量不能小于 0
- 库存为 0 时禁止借出
- 图书借出时要记录借阅人、借阅时间和归还状态
- 图书归还时要校验是否存在未归还的借阅记录
- 删除图书时,如果已经存在借阅记录,需要禁止删除或改为逻辑删除
- 用户密码不能明文保存,需要做加密处理
- 被禁用的用户不能登录,也不能继续借书
- 图书查询需要分页,避免一次性查出过多数据
- 接口返回结构要统一,方便前端处理成功和失败结果
这些规则决定了工程质量。
如果不提前说,AI 可能会生成一个能跑的项目,但业务上经不起推敲。比如借书接口只是简单把库存减 1,却没有判断库存是否够;用户登录只比对明文密码;删除图书时直接物理删除,导致借阅记录找不到关联图书。
所以智能引导不是"点下一步"那么简单。它更像是一次需求评审,把你脑子里的业务规则提前整理出来。
三、生成工程后,要重点看这几块
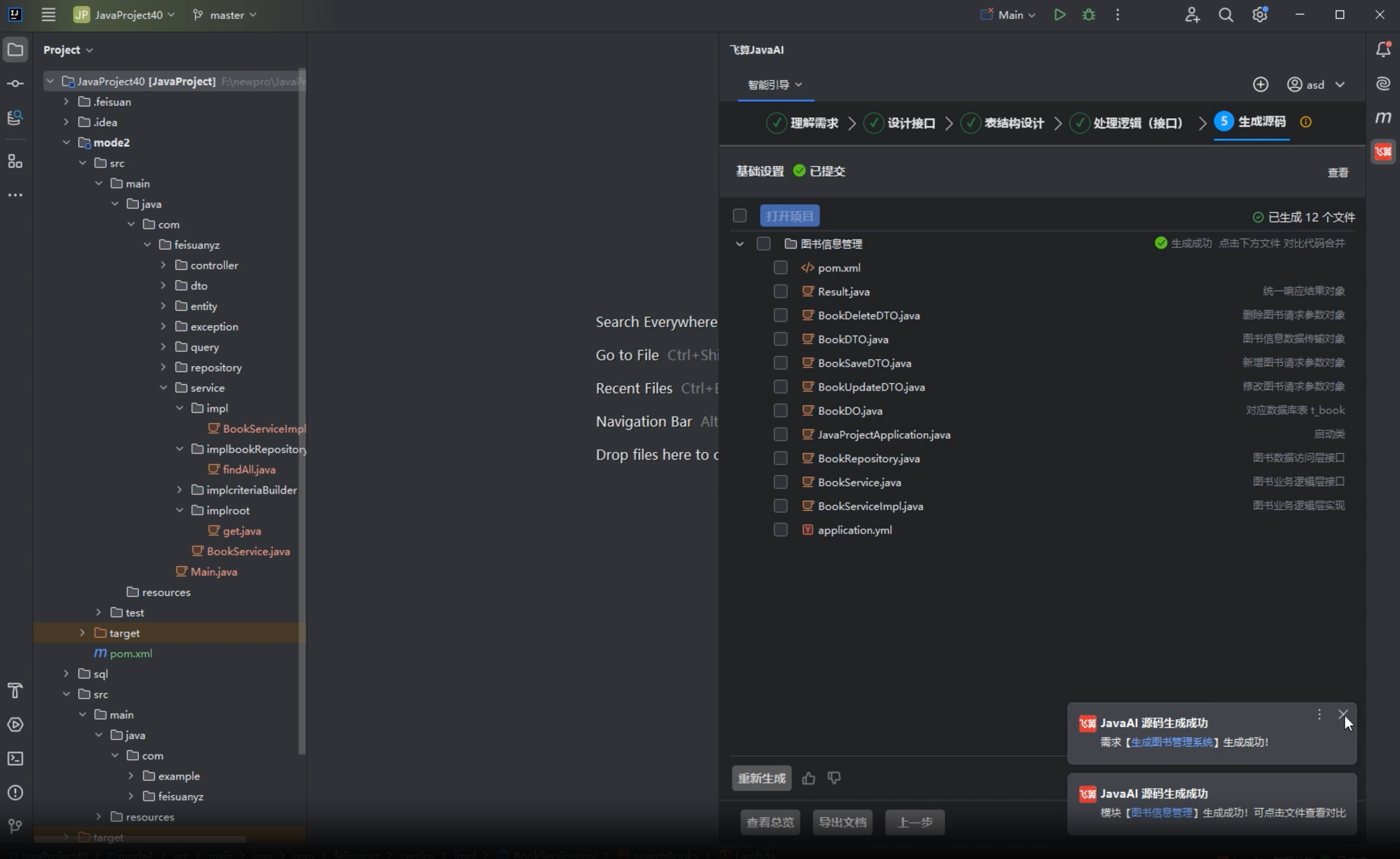
飞算 JavaAI 生成 Spring Boot 工程后,不要只看项目能不能启动。
能启动只是第一步,真正要看的,是它生成的工程结构是否合理。
我一般会先看这几块。
第一,看实体类和表结构。
图书管理系统至少会有图书表、用户表,如果支持借还书,还应该有借阅记录表。图书表里要有书名、作者、ISBN、出版社、库存数量、创建时间、更新时间等字段;用户表里要有用户名、密码、联系方式、账号状态;借阅记录表里要有关联图书、关联用户、借出时间、归还时间、借阅状态。
第二,看接口是否完整。
图书模块应该有新增、修改、删除、查询详情、分页搜索接口;库存模块应该有借出、归还接口;用户模块应该有新增、修改、启用、禁用接口;认证模块至少应该有登录接口。
第三,看 Service 里有没有业务判断。
很多 AI 生成代码最大的问题,是把业务逻辑写得太薄。Controller 收到请求后直接调用 Repository 保存,看起来很干净,但库存校验、账号状态校验、ISBN 唯一校验都没做。
图书借出这个动作尤其要注意。它不只是修改库存,还应该同时生成借阅记录。库存扣减和借阅记录保存应该放在一个事务里,不能出现库存扣了但借阅记录没保存成功的情况。
第四,看异常处理和返回格式。
比如 ISBN 已存在、库存不足、用户已禁用、图书不存在、借阅记录不存在,这些都应该有明确的错误提示。如果每个接口返回格式都不一样,后面接前端会很难受。
第五,看是否有基础测试或可验证数据。
哪怕只是练手项目,也建议让 AI 顺手生成一些基础测试用例,或者生成初始化 SQL。这样你可以更快验证新增图书、搜索图书、借出图书、归还图书这些流程是否跑通。
四、我一般按这个流程用
我的流程大概是:
- 先写图书管理系统的业务背景,不急着要代码
- 让它帮我优化需求,把图书、库存、用户、认证几个模块拆开
- 通过智能引导确认模块边界和业务规则
- 生成第一版 Spring Boot 工程
- 本地跑编译,先确认项目能启动
- 人工审表结构、接口、事务、权限和异常处理
- 把审查结果整理成新的需求,再让它改一版
这里最关键的是第 6 步和第 7 步。
AI 生成第一版不难,难的是你知道哪里不能直接用。比如图书借出和库存扣减应该放在一个事务里;ISBN 最好加唯一约束;用户密码不能明文保存;删除图书前要考虑是否存在借阅记录;列表查询最好支持分页。
这些都是业务判断,不能完全交给工具。
我比较推荐的做法,是不要一次性要求 AI 生成"完美项目"。可以先让它生成一个基础工程,然后第二轮再补:
plain
请帮我检查图书借出和归还逻辑,要求库存不能小于 0,借出时生成借阅记录,归还时更新借阅状态,并保证事务一致性。第三轮再补:
plain
请帮我完善用户登录逻辑,要求用户密码加密存储,被禁用用户不能登录,并统一接口返回格式。这样一轮一轮改,效果往往比一次性堆一个超长需求更稳定。
五、一键生成项目
飞算 JavaAI 的优势,是它更贴近 Java 工程化。
它会围绕 Controller、Service、Repository、Entity、SQL、配置、文档这些东西来组织结果,而不是只给你一段代码片段。
对图书管理系统这种练手项目来说,它很适合帮助初中级 Java 工程师看到一个完整工程的轮廓:图书表怎么设计,用户表怎么设计,借阅记录表怎么设计,接口怎么分层,库存变化应该放在哪一层处理,异常应该怎么统一返回。
对有经验的开发来说,它省的是启动时间。以前你从空项目开始,现在你从第一版底稿开始。你可以把精力放在审设计、审边界、审事务、审安全,而不是反复搭项目骨架。
当然,它生成的工程不能直接当生产代码用。
比如权限模型可能还比较粗,密码加密方式需要你确认,异常处理也可能不符合公司规范,接口命名和包结构也需要根据团队习惯调整。
但作为项目早期的底稿,它已经很有价值。
六、最后总结

飞算 JavaAI 的智能引导,最适合的使用方式不是"帮我写一个接口",而是"帮我从一个业务需求拆出一个工程雏形"。
以图书管理系统为例,正确的用法应该是:
- 先描述完整业务背景
- 再拆图书、库存、用户、认证模块
- 在智能引导里补充 ISBN、库存、借还书、账号状态等业务规则
- 生成 Spring Boot 工程后人工审查
- 根据审查结果让 AI 继续迭代
9.9 元包月适合拿来练这种流程。不要只生成一次就结束,多让它改几轮,看它能不能跟着你的业务规则调整。
最后还是那句话:AI 负责打底,人负责判断。
如果你能把这个边界掌握好,飞算 JavaAI 这种工具会很适合放进 Java 项目的早期开发阶段。