Python 基础语法入门(四):从函数、列表到字典和文件操作

🔥 星恒随风: 个人主页 ❄️ 个人专栏: 《指针合集》 | 《C语言基础》 | 《数据结构》 | 《机器学习导论》 | 《前端基础》 | 《python基础》 | 《C++从入门到入土》 ✨ 数据即知识,压缩即智能
文章目录
- [Python 基础语法入门(四):从函数、列表到字典和文件操作](#Python 基础语法入门(四):从函数、列表到字典和文件操作)
-
- 前言
- 一、函数:把重复代码封装起来
- 二、函数参数:让函数处理不同的数据
-
- [1. 参数个数要匹配](#1. 参数个数要匹配)
- [2. Python 的参数不需要写类型](#2. Python 的参数不需要写类型)
- 三、函数返回值:把结果交还给调用者
-
- [1. return 会结束函数](#1. return 会结束函数)
- [2. Python 可以返回多个值](#2. Python 可以返回多个值)
- 四、变量作用域:为什么函数里的变量外面不能直接用
- 五、函数调用过程:代码是怎么执行的
- 六、链式调用和嵌套调用
-
- [1. 链式调用](#1. 链式调用)
- [2. 嵌套调用](#2. 嵌套调用)
- 七、递归:函数调用自己
- 八、默认参数和关键字参数
-
- [1. 默认参数](#1. 默认参数)
- [2. 关键字参数](#2. 关键字参数)
- 九、列表:保存一组可以修改的数据
-
- [1. 创建列表](#1. 创建列表)
- [2. 通过下标访问元素](#2. 通过下标访问元素)
- [3. len 获取列表长度](#3. len 获取列表长度)
- 十、切片:一次取出一段列表
-
- [1. 省略边界](#1. 省略边界)
- [2. 指定步长](#2. 指定步长)
- [3. 反转列表](#3. 反转列表)
- 十一、遍历列表
- 十二、列表常见操作
-
- [1. append:尾插](#1. append:尾插)
- [2. insert:指定位置插入](#2. insert:指定位置插入)
- [3. in:判断元素是否存在](#3. in:判断元素是否存在)
- [4. index:查找元素下标](#4. index:查找元素下标)
- [5. pop:删除元素](#5. pop:删除元素)
- [6. remove:按值删除](#6. remove:按值删除)
- [7. + 和 extend:连接列表](#7. + 和 extend:连接列表)
- 十三、元组:不能修改的列表?
- 十四、字典:保存键值对
-
- [1. 创建字典](#1. 创建字典)
- [2. 查找 key](#2. 查找 key)
- [3. 新增和修改元素](#3. 新增和修改元素)
- [4. 删除元素](#4. 删除元素)
- [5. 遍历字典](#5. 遍历字典)
- [十五、字典的 key 有什么要求?](#十五、字典的 key 有什么要求?)
- 十六、文件:把数据保存到硬盘里
-
- [1. 文件路径](#1. 文件路径)
- 十七、打开和关闭文件
- 十八、写文件
- 十九、读文件
-
- [1. read:一次读取全部内容](#1. read:一次读取全部内容)
- [2. readline:一次读取一行](#2. readline:一次读取一行)
- [3. for 循环逐行读取](#3. for 循环逐行读取)
- 二十、练习:统计成绩
前言
如果你刚开始学 Python,最容易遇到的问题不是"语法有多难",而是"知识点太散"。
函数、列表、元组、字典、文件操作,这些东西单独看都不复杂,但如果没有一条清晰的主线,很容易学完之后只记住了几个零散的写法,真正写代码时还是不知道该怎么组织程序。
这篇文章就,把 Python 中几个非常核心的基础语法串起来:
- 函数:如何把重复代码封装起来
- 参数和返回值:函数如何接收数据、返回结果
- 变量作用域:为什么函数里面的变量外面不能直接用
- 递归:函数调用自己的特殊情况
- 列表和元组:如何保存一组数据
- 字典:如何保存"键值对"数据
- 文件操作:如何把数据保存到硬盘里
一、函数:把重复代码封装起来
在没有函数之前,如果我们想分别求:
- 1 到 100 的和
- 300 到 400 的和
- 1 到 1000 的和
很可能会写成这样:
python
# 求 1 到 100 的和
total = 0
for i in range(1, 101):
total += i
print(total)
# 求 300 到 400 的和
total = 0
for i in range(300, 401):
total += i
print(total)
# 求 1 到 1000 的和
total = 0
for i in range(1, 1001):
total += i
print(total)这段代码能运行,但问题也很明显:重复内容太多。
真正写项目时,复制粘贴不是一个好习惯。因为一旦重复代码里有一个地方需要修改,你可能要改十几处甚至几十处,很容易漏掉。
这时候就可以把重复逻辑封装成函数。
python
def calc_sum(beg, end):
total = 0
for i in range(beg, end + 1):
total += i
return total
print(calc_sum(1, 100))
print(calc_sum(300, 400))
print(calc_sum(1, 1000))函数的作用可以简单理解为:
把一段可以重复使用的代码起一个名字,以后需要的时候直接调用它。
Python 中定义函数的基本格式是:
python
def 函数名(参数列表):
函数体
return 返回值比如:
python
def say_hello():
print("hello")
say_hello()需要注意一点:函数定义本身不会执行函数体,只有调用函数时才会执行。
python
def test():
print("函数被执行了")
# 这里只是定义函数,不会打印任何内容
test() # 调用函数,才会真正执行二、函数参数:让函数处理不同的数据
函数如果只能处理固定数据,那作用就比较有限。参数的意义就在于:让同一个函数可以处理不同的数据。
例如:
python
def calc_sum(beg, end):
total = 0
for i in range(beg, end + 1):
total += i
return total这里的 beg 和 end 就是形参,也就是函数定义时写在括号里的名字。
调用函数时传进去的具体值叫实参:
python
result = calc_sum(1, 100)
print(result)在这次调用中:
python
beg = 1
end = 100再看另一次调用:
python
result = calc_sum(300, 400)
print(result)这次就是:
python
beg = 300
end = 400所以函数参数本质上就是一种"外部给函数传数据"的方式。
1. 参数个数要匹配
如果函数定义时需要两个参数,调用时也应该传两个参数。
python
def add(x, y):
return x + y
print(add(10, 20))如果少传参数:
python
print(add(10))程序就会报错,因为 Python 不知道 y 应该是多少。
2. Python 的参数不需要写类型
和 C/C++、Java 不同,Python 是动态类型语言。定义函数时,参数名旁边通常不用写类型。
python
def show(value):
print(value)
show(10)
show("hello")
show(True)这段代码都可以运行。
不过这也带来一个问题:函数更灵活了,但你自己也要更清楚这个函数"期望接收什么类型的数据"。否则写着写着就可能传错数据。
三、函数返回值:把结果交还给调用者
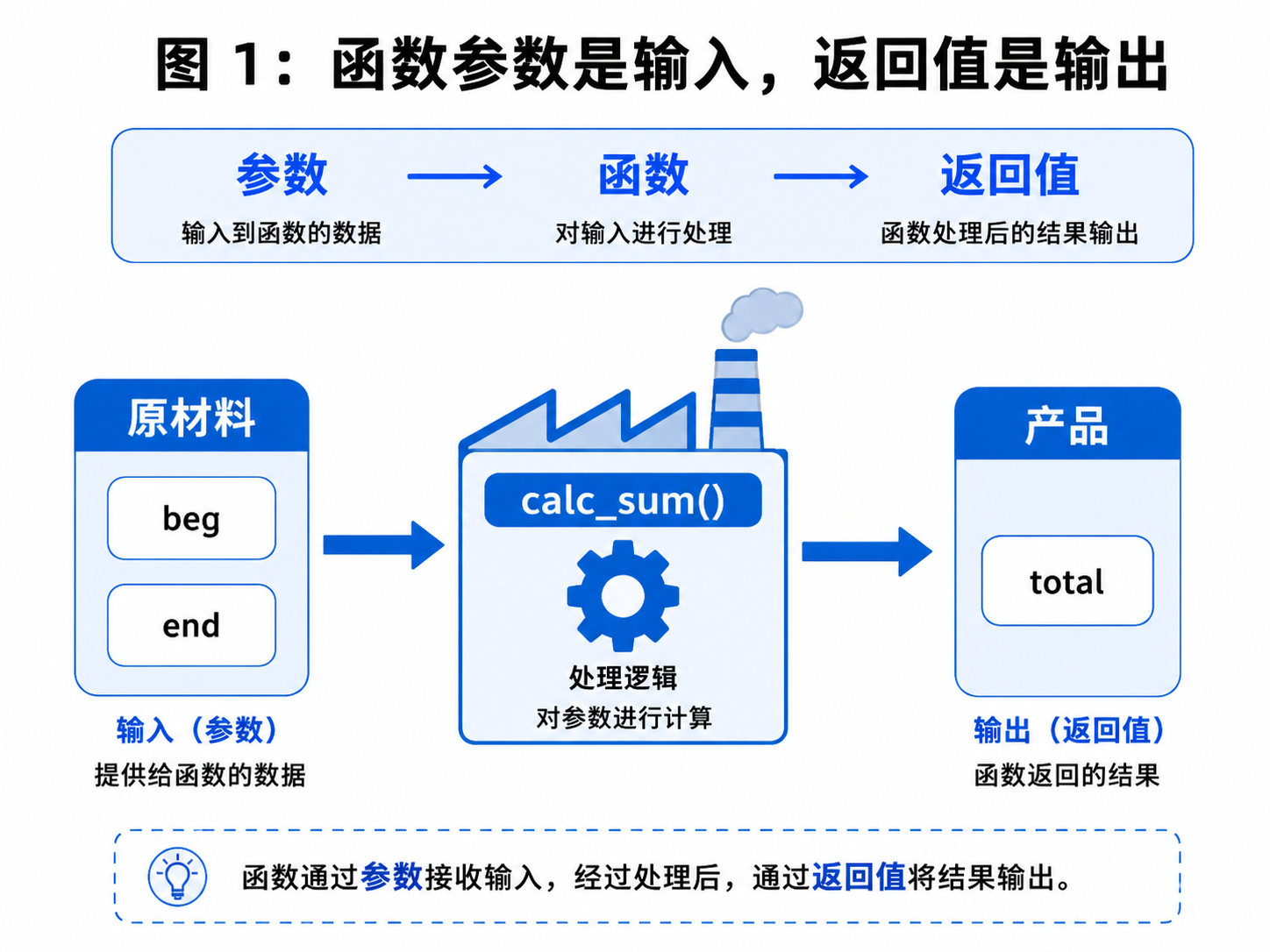
函数的参数可以看成输入,返回值可以看成输出。
比如下面这个函数:
python
def calc_sum(beg, end):
total = 0
for i in range(beg, end + 1):
total += i
print(total)它能打印结果,但它把"计算"和"输出"绑在了一起。这样在实际中不够灵活,因为我们写代码的 时候最好的守则是"低耦合,高内聚"
因此更推荐写成:
python
def calc_sum(beg, end):
total = 0
for i in range(beg, end + 1):
total += i
return total
result = calc_sum(1, 100)
print(result)这样函数只负责计算,至于结果是打印到控制台、写入文件,还是显示到网页上,都可以由调用者决定。
这就是一个很重要的编程习惯:
计算逻辑和用户交互尽量分开。
1. return 会结束函数
函数执行到 return 后,会立即结束。
python
def is_odd(num):
if num % 2 == 0:
return False
return True
print(is_odd(10))
print(is_odd(11))当 num 是偶数时,执行到:
python
return False函数就结束了,后面的 return True 不会继续执行。
2. Python 可以返回多个值
Python 的函数可以一次返回多个值:
python
def get_point():
x = 10
y = 20
return x, y
a, b = get_point()
print(a, b)输出:
python
10 20如果你只关心其中一部分返回值,可以用 _ 忽略不需要的值:
python
_, y = get_point()
print(y)这里 _ 只是一个常见写法,表示"这个值我不打算使用"。
四、变量作用域:为什么函数里的变量外面不能直接用
先看一段代码:
python
def get_point():
x = 10
y = 20
return x, y
get_point()
print(x, y)这段代码会报错,因为 x 和 y 是在函数内部定义的变量。它们只在函数内部有效,函数执行结束后,外部不能直接访问它们。
这种变量叫局部变量。
python
def test():
x = 10
print(f"函数内部 x = {x}")
test()而定义在函数外部的变量叫全局变量。
python
x = 20
def test():
print(f"x = {x}")
test()如果函数内部没有找到某个变量,Python 会尝试到外层作用域中查找。

global:在函数内部修改全局变量
如果你想在函数内部修改全局变量,需要使用 global。
python
x = 20
def test():
global x
x = 10
print(f"函数内部 x = {x}")
test()
print(f"函数外部 x = {x}")输出结果中,函数外部的 x 也会变成 10。
不过实际写代码时,不建议大量使用 global。全局变量改来改去,很容易让程序变得难以维护。更多时候,我们应该通过参数和返回值传递数据。
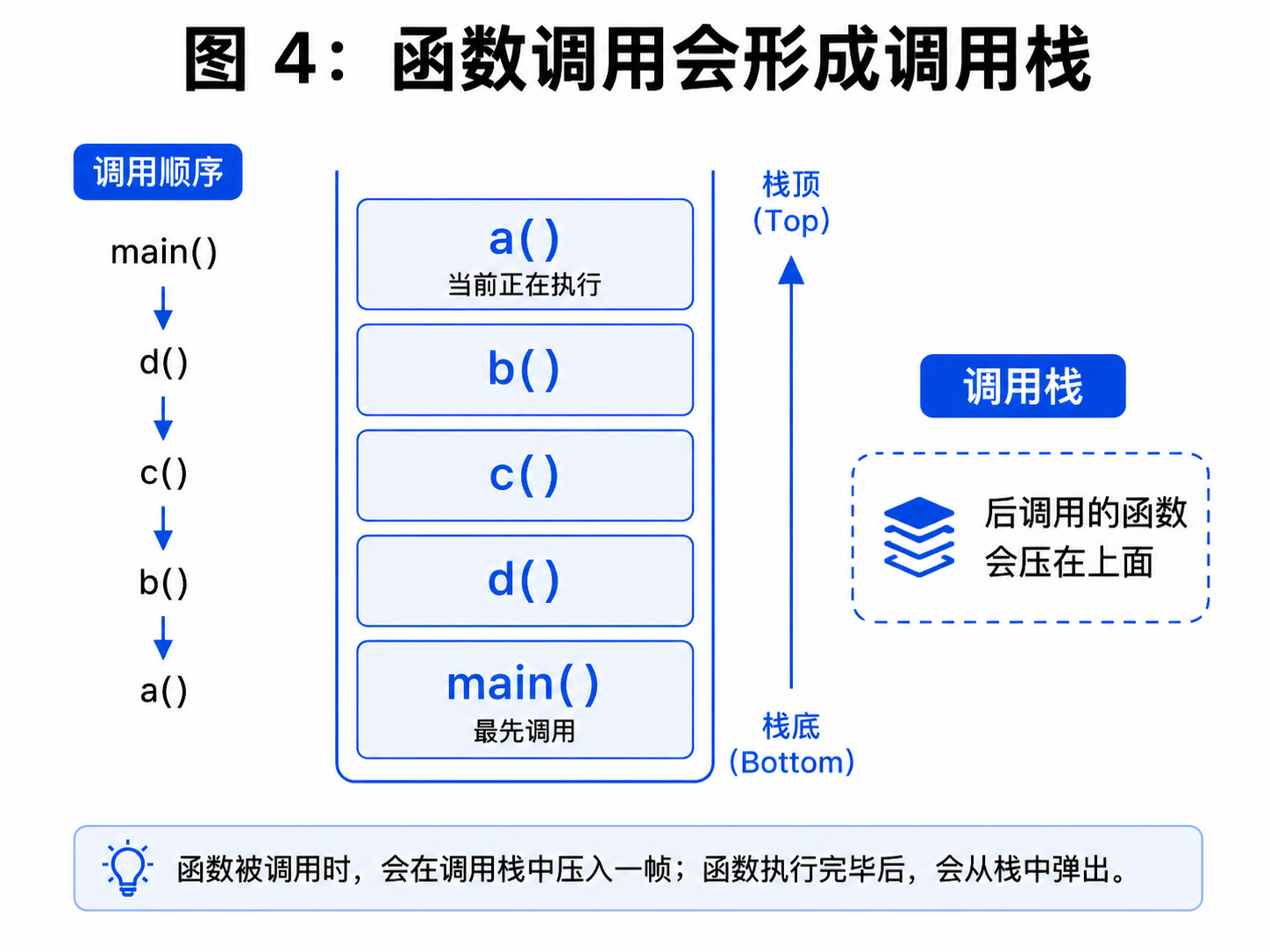
五、函数调用过程:代码是怎么执行的
函数不是从定义处开始执行的,而是从调用处开始执行的。
python
def test():
print("执行函数内部代码")
print("执行函数内部代码")
print("执行函数内部代码")
print("1111")
test()
print("2222")
test()
print("3333")执行顺序是:
python
1111
执行函数内部代码
执行函数内部代码
执行函数内部代码
2222
执行函数内部代码
执行函数内部代码
执行函数内部代码
3333每次调用函数,程序都会进入函数内部执行;函数执行结束后,再回到原来的调用位置继续往下执行。
如果你用 PyCharm 或 VS Code 调试代码,可以通过断点和单步执行观察这个过程。初学函数时,强烈建议自己打断点走一遍,这比单纯看文字更容易理解。
六、链式调用和嵌套调用
1. 链式调用
有时候我们会先接收函数返回值,再把它传给另一个函数:
python
result = is_odd(10)
print(result)也可以直接写成:
python
print(is_odd(10))这就是一种简单的链式调用:把一个函数的返回值,直接作为另一个函数的参数。
2. 嵌套调用
函数内部也可以调用其他函数。
python
def a():
print("函数 a")
def b():
a()
print("函数 b")
b()输出:
python
函数 a
函数 bb() 内部调用了 a(),这就是嵌套调用。
七、递归:函数调用自己
递归是函数嵌套调用的一种特殊情况:函数内部调用自己。
比如计算阶乘:
python
def factor(n):
if n == 1:
return 1
return n * factor(n - 1)
print(factor(5))5! 可以拆成:
python
5! = 5 * 4!
4! = 4 * 3!
3! = 3 * 2!
2! = 2 * 1!
1! = 1对应到代码里,就是函数不断调用自己。
写递归时必须注意两点:
- 必须有结束条件
- 每次递归都要逐渐靠近结束条件
比如:
python
def factor(n):
return n * factor(n - 1)这段代码没有结束条件,会一直调用自己,最后出现递归深度超限的问题。
递归的优点是代码短,适合描述某些天然递归的问题,比如树、文件夹遍历、数学递推等。
但递归也有缺点:理解成本更高,而且递归层数太深时容易出问题。初学阶段不要为了递归而递归,能用循环清楚表达的问题,用循环往往更稳。
八、默认参数和关键字参数
1. 默认参数
Python 函数可以给参数指定默认值。
python
def add(x, y, debug=False):
if debug:
print(f"调试信息:x={x}, y={y}")
return x + y
print(add(10, 20))
print(add(10, 20, True))如果不传第三个参数,debug 默认就是 False。
需要注意:带默认值的参数要放在没有默认值的参数后面。
错误写法:
python
def add(x, debug=False, y):
return x + y正确写法:
python
def add(x, y, debug=False):
return x + y2. 关键字参数
正常情况下,函数传参是按照顺序传递的。
python
def test(x, y):
print(f"x = {x}")
print(f"y = {y}")
test(10, 20)也可以显式指定参数名:
python
test(x=10, y=20)
test(y=100, x=200)这种写法叫关键字参数。它的优点是代码更清楚,尤其是参数比较多的时候,不容易看错。
九、列表:保存一组可以修改的数据
如果只有几个数据,可以写多个变量:
python
num1 = 10
num2 = 20
num3 = 30但如果有一百个数据,总不能写一百个变量。这个时候就需要列表。
列表可以一次保存多个数据。
python
nums = [10, 20, 30, 40]
print(nums)1. 创建列表
创建空列表:
python
alist = []或者:
python
alist = list()创建带初始值的列表:
python
alist = [1, 2, 3, 4]Python 的列表里可以放不同类型的数据:
python
alist = [1, "hello", True]
print(alist)不过实际开发中,一个列表里通常会放同一类数据。比如学生成绩列表、商品价格列表、文件名列表。这样代码会更容易理解。
2. 通过下标访问元素
列表下标从 0 开始。
python
alist = [1, 2, 3, 4]
print(alist[0]) # 1
print(alist[2]) # 3也可以修改元素:
python
alist[2] = 100
print(alist)如果下标越界,会报错。
python
print(alist[100])常见错误信息是:
python
IndexError: list index out of range3. len 获取列表长度
python
alist = [1, 2, 3, 4]
print(len(alist))最后一个元素的下标是:
python
len(alist) - 1Python 也支持负数下标:
python
print(alist[-1]) # 最后一个元素
print(alist[-2]) # 倒数第二个元素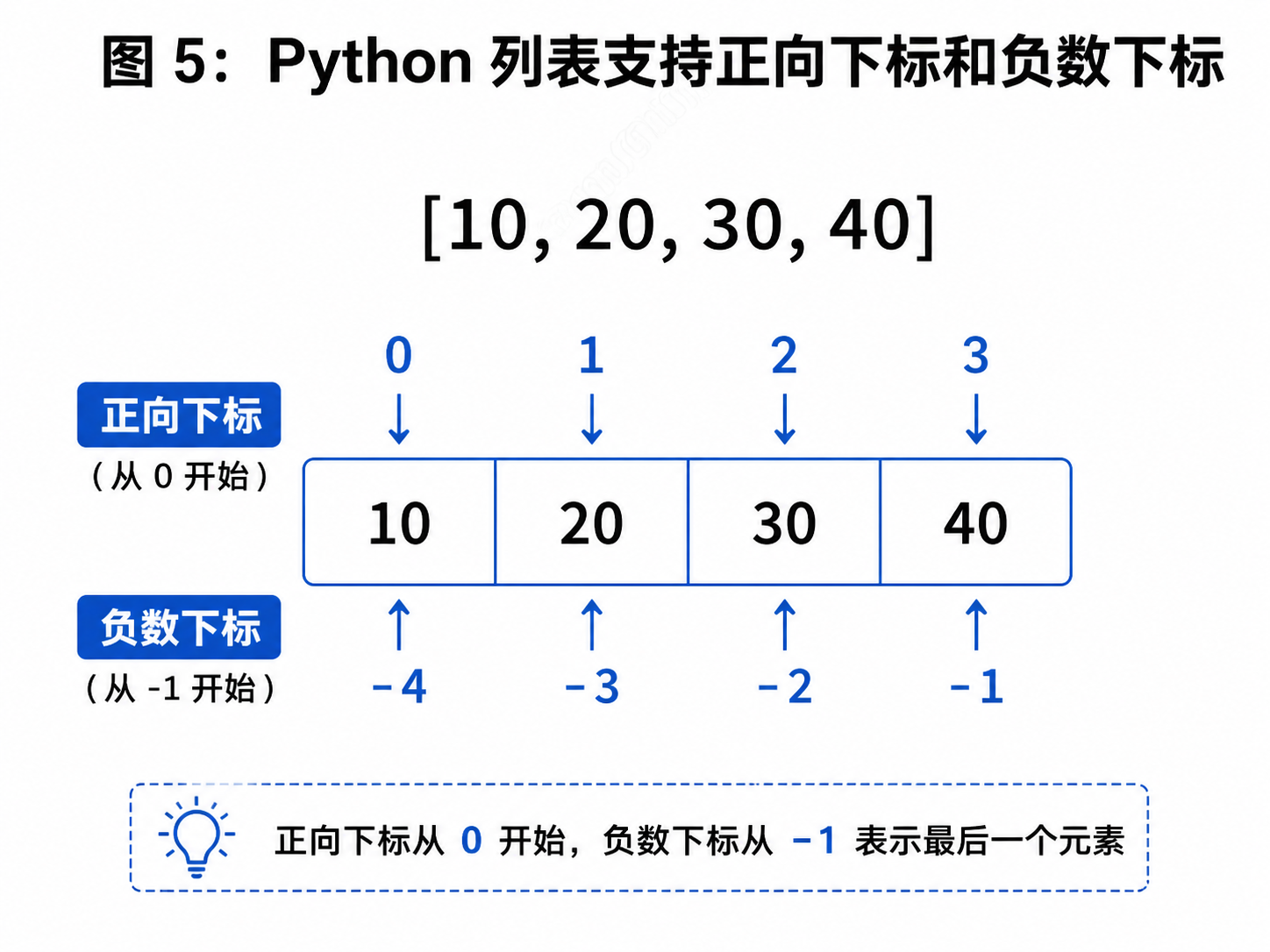
十、切片:一次取出一段列表
下标一次只能取一个元素,切片可以一次取出一组连续元素。
python
alist = [1, 2, 3, 4]
print(alist[1:3])结果是:
python
[2, 3]注意,[1:3] 表示的是前闭后开区间:
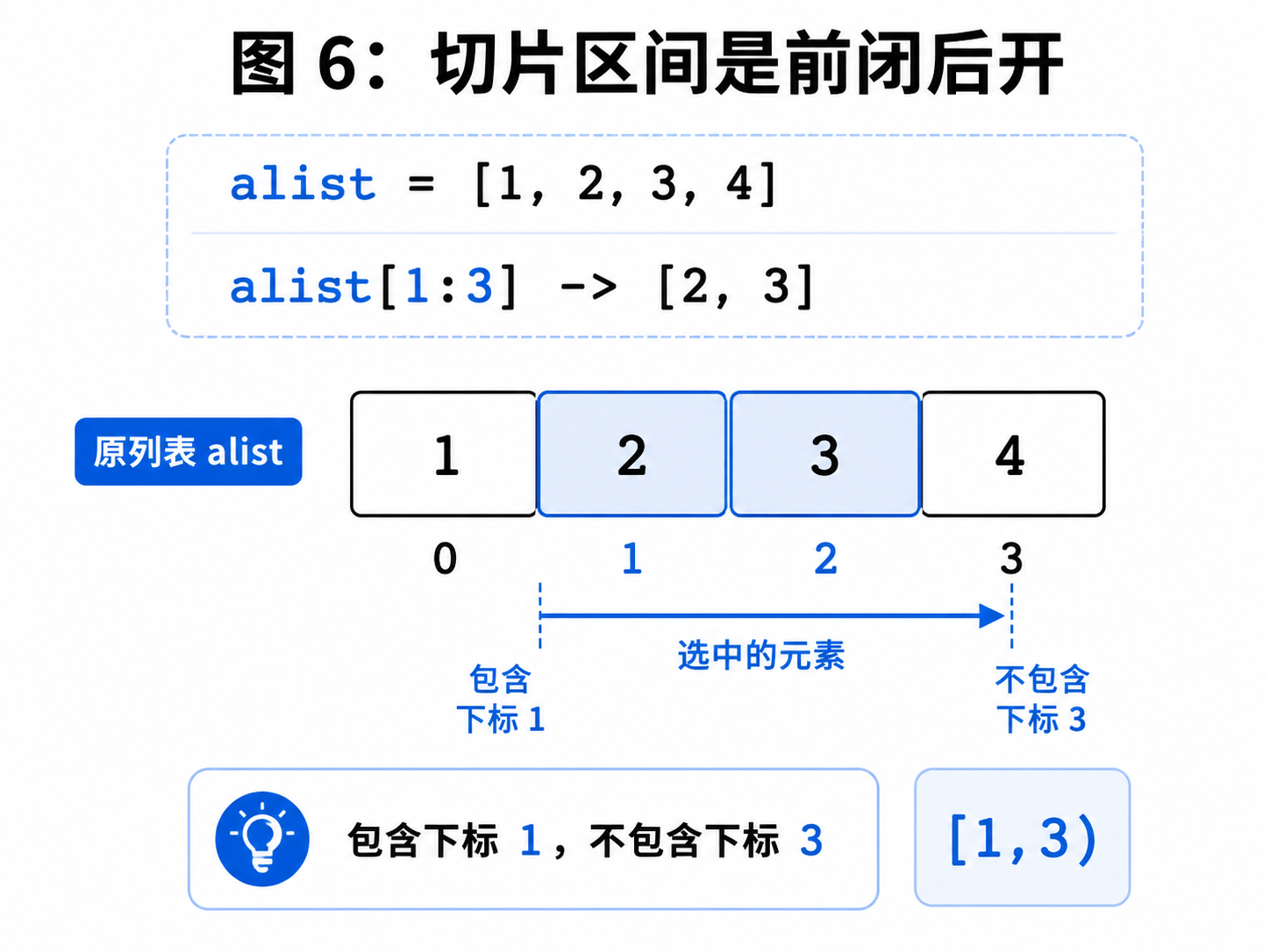
python
[1, 3)也就是包含下标 1,不包含下标 3。
1. 省略边界
python
alist = [1, 2, 3, 4]
print(alist[1:]) # 从下标 1 到末尾
print(alist[:-1]) # 从开头到倒数第一个之前
print(alist[:]) # 复制整个列表2. 指定步长
python
alist = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(alist[::1])
print(alist[::2])
print(alist[::3])步长为 2 时,就是每隔一个元素取一次。
3. 反转列表
python
alist = [1, 2, 3, 4, 5]
print(alist[::-1])这是 Python 中很常见的反转写法。
十一、遍历列表
遍历就是把列表中的元素一个一个取出来处理。
最常见写法:
python
alist = [1, 2, 3, 4]
for elem in alist:
print(elem)如果需要下标,可以这样写:
python
for i in range(len(alist)):
print(i, alist[i])更推荐使用 enumerate:
python
for i, elem in enumerate(alist):
print(i, elem)这种写法同时拿到下标和元素,比手动写 range(len(...)) 更自然。
十二、列表常见操作
1. append:尾插
python
alist = [1, 2, 3]
alist.append(4)
print(alist)结果:
python
[1, 2, 3, 4]2. insert:指定位置插入
python
alist = [1, 2, 3]
alist.insert(1, "hello")
print(alist)结果:
python
[1, 'hello', 2, 3]3. in:判断元素是否存在
python
alist = [1, 2, 3, 4]
print(2 in alist)
print(10 in alist)结果:
python
True
False4. index:查找元素下标
python
alist = [1, 2, 3, 4]
print(alist.index(3))如果元素不存在,index 会报错。
5. pop:删除元素
删除最后一个元素:
python
alist = [1, 2, 3, 4]
alist.pop()
print(alist)按下标删除:
python
alist = [1, 2, 3, 4]
alist.pop(2)
print(alist)6. remove:按值删除
python
alist = [1, 2, 3, 4]
alist.remove(2)
print(alist)pop 是按照下标删除,remove 是按照值删除。
7. + 和 extend:连接列表
使用 + 会生成一个新列表:
python
a = [1, 2, 3]
b = [4, 5, 6]
c = a + b
print(c)
print(a)
print(b)使用 extend 会修改原列表:
python
a = [1, 2, 3]
b = [4, 5, 6]
a.extend(b)
print(a)
print(b)这两个写法看起来都能拼接列表,但含义不一样:
+:生成新列表extend:修改原列表
十三、元组:不能修改的列表?
元组和列表很像,也是一种序列结构。
列表使用 []:
python
alist = [1, 2, 3]元组使用 ():
python
atuple = (1, 2, 3)元组最大的特点是:创建之后不能修改。
python
atuple = (1, 2, 3)
atuple[0] = 100 # 报错元组支持很多读操作,比如:
python
atuple = (1, 2, 3, 4)
print(atuple[0])
print(atuple[1:3])
for elem in atuple:
print(elem)但是它不支持修改、新增、删除这类操作。
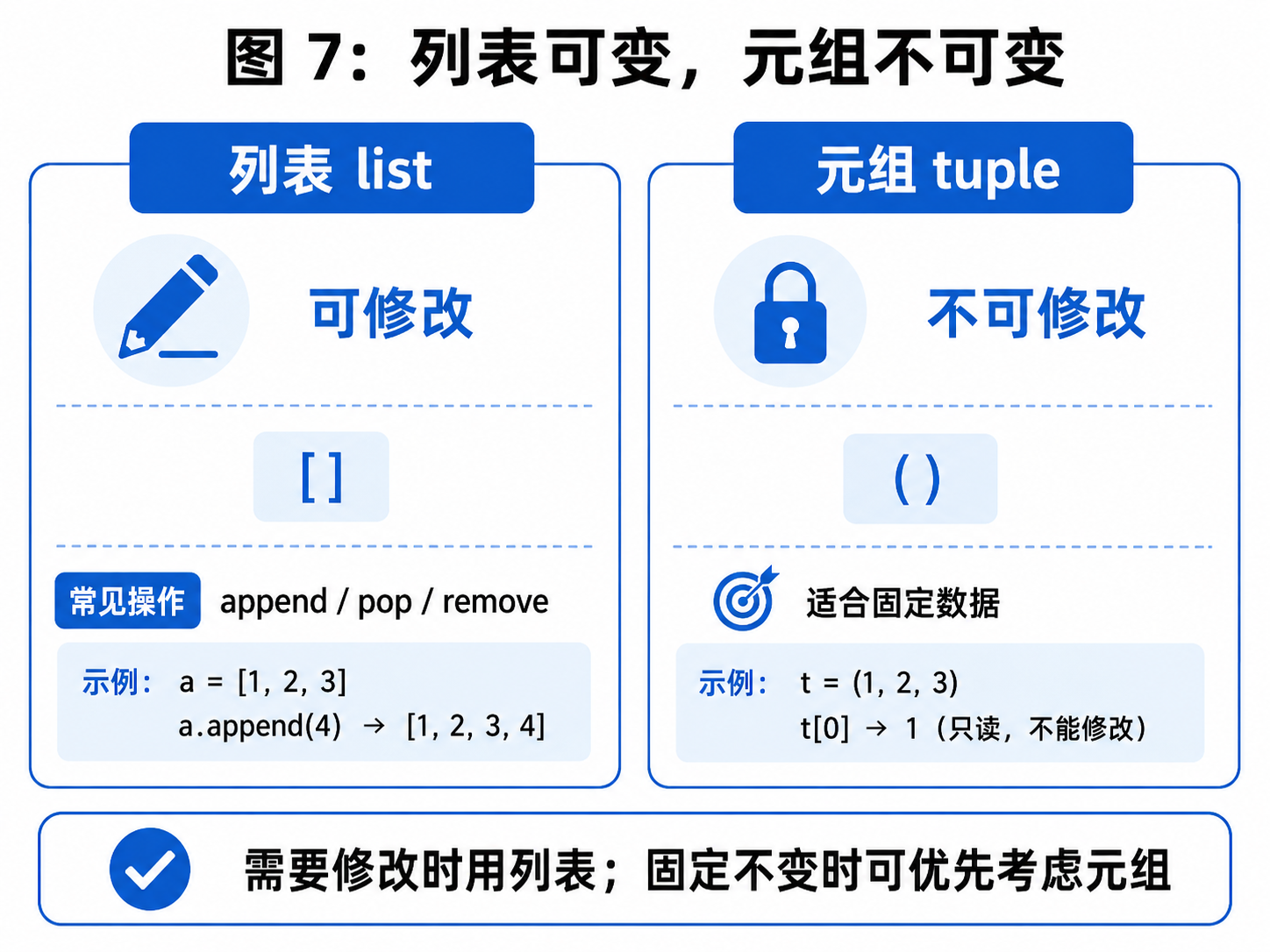
什么时候用列表,什么时候用元组?
可以简单这样判断:
- 数据后续需要修改:用列表
- 数据创建后不希望被修改:用元组
比如一个点的坐标:
python
point = (10, 20)通常更适合用元组,因为坐标本身更像一个固定组合。
另外,Python 函数返回多个值时,本质上经常就是通过元组来组织的:
python
def get_point():
return 10, 20
result = get_point()
print(result)
print(type(result))输出:
python
(10, 20)
<class 'tuple'>十四、字典:保存键值对
列表适合保存一组有顺序的数据,比如:
python
scores = [80, 90, 95]但有时候我们希望通过一个名字找到对应的数据。比如保存一个学生信息:
python
student = {
"id": 1,
"name": "zhangsan",
"score": 90
}这就是字典。
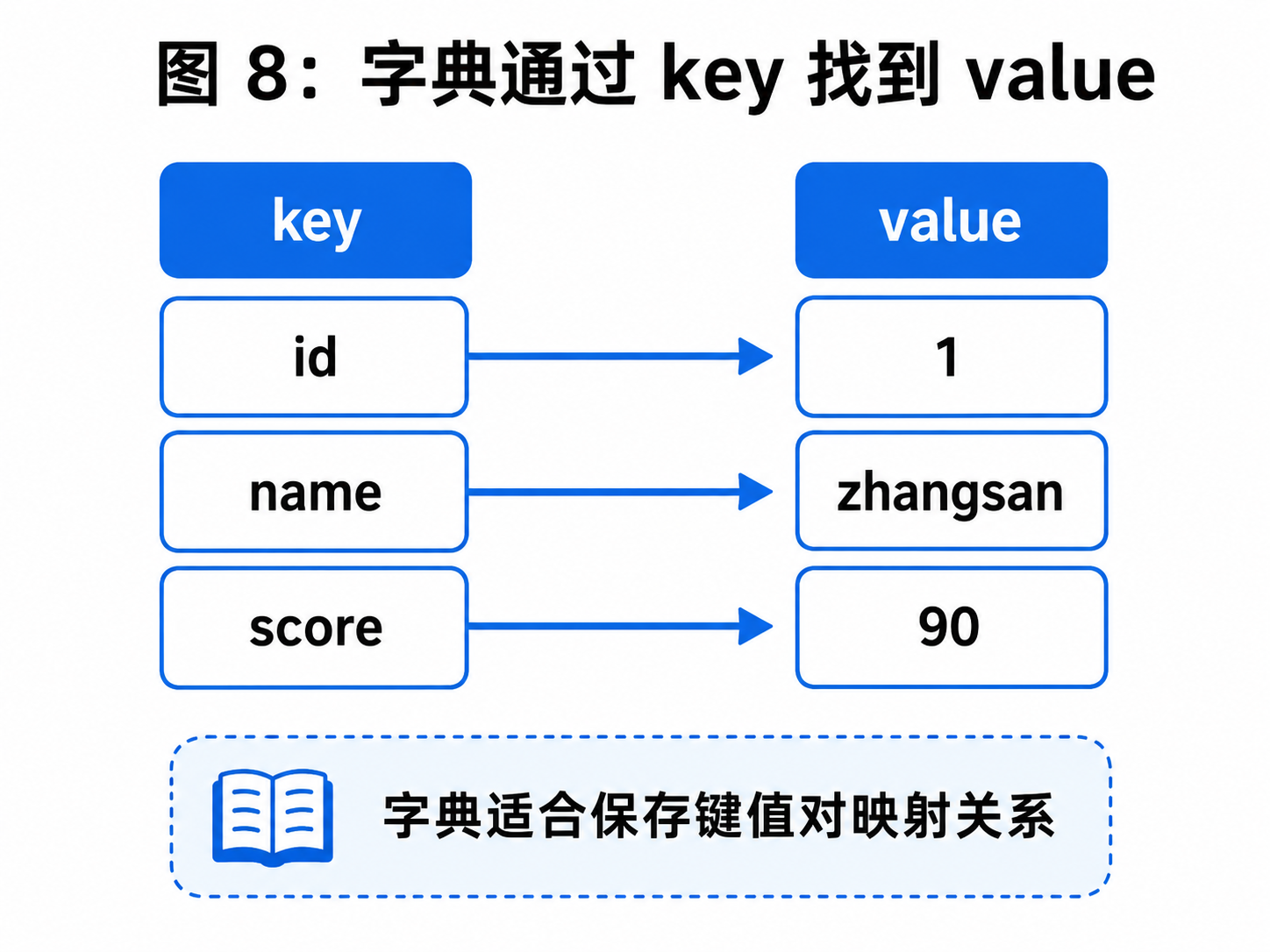
字典是一种键值对结构:
python
key -> value比如:
python
"id" -> 1
"name" -> "zhangsan"
"score" -> 90可以把字典理解成现实中的通讯录:
python
姓名 -> 电话号码知道 key,就能找到对应的 value。
1. 创建字典
创建空字典:
python
student = {}或者:
python
student = dict()创建带初始值的字典:
python
student = {
"id": 1,
"name": "zhangsan",
"score": 90
}写多行时,最后一个键值对后面可以加逗号,也可以不加。实际开发中,很多人会保留最后一个逗号,方便后续继续添加字段。
python
student = {
"id": 1,
"name": "zhangsan",
"score": 90,
}2. 查找 key
判断某个 key 是否存在:
python
student = {
"id": 1,
"name": "zhangsan",
}
print("id" in student)
print("score" in student)通过 key 获取 value:
python
print(student["id"])
print(student["name"])如果 key 不存在,会报错:
python
print(student["score"])更稳妥的写法是使用 get:
python
print(student.get("score"))
print(student.get("score", 0))如果 "score" 不存在,第一行返回 None,第二行返回默认值 0。
3. 新增和修改元素
如果 key 不存在,就是新增:
python
student = {
"id": 1,
"name": "zhangsan",
}
student["score"] = 90
print(student)如果 key 已经存在,就是修改:
python
student["score"] = 100
print(student)4. 删除元素
python
student.pop("score")
print(student)5. 遍历字典
直接遍历字典,拿到的是 key:
python
student = {
"id": 1,
"name": "zhangsan",
"score": 90,
}
for key in student:
print(key, student[key])也可以使用 items() 同时拿到 key 和 value:
python
for key, value in student.items():
print(key, value)这种写法更常用。
还可以分别获取所有 key 和 value:
python
print(student.keys())
print(student.values())
print(student.items())十五、字典的 key 有什么要求?
不是所有对象都能作为字典的 key。
字典底层依赖哈希思想,所以 key 通常要求是可哈希的。简单理解就是:这个对象应该是相对稳定、不可变的。
常见可以作为 key 的类型:
python
student = {
1: "zhangsan",
"name": "lisi",
True: "yes",
(10, 20): "point",
}列表不能作为 key:
python
d = {}
d[[1, 2, 3]] = "hello" # 报错因为列表是可变对象,内容可以被修改,不适合作为字典的 key。
元组通常可以作为 key:
python
location = {
(10, 20): "A 点",
(30, 40): "B 点",
}这也是元组比列表多出来的一个实际用途。
十六、文件:把数据保存到硬盘里
前面用变量、列表、字典保存的数据,都是放在内存中的。程序一结束,这些数据通常就没了。
如果希望数据长期保存,就需要写入文件。
比如:
- 保存用户信息
- 保存程序运行日志
- 保存爬虫结果
- 保存配置文件
- 读取已有文本数据
这些都离不开文件操作。
1. 文件路径
在 Windows 中,文件路径可能长这样:
python
D:/test.txt也可能写成:
python
D:\\test.txt因为反斜杠 \ 在字符串里有特殊含义,所以新手写路径时,建议优先使用 /,更不容易出错。
绝对路径是从盘符或根目录开始写的完整路径,例如:
python
D:/code/python/test.txt相对路径则是相对于当前程序所在位置来找文件,例如:
python
test.txt初学阶段如果总是找不到文件,可以先使用绝对路径,等熟悉之后再使用相对路径。
十七、打开和关闭文件
Python 使用 open 打开文件。
python
f = open("D:/test.txt", "r", encoding="utf-8")
f.close()常见打开方式:
| 模式 | 含义 |
|---|---|
"r" |
读模式,文件必须存在 |
"w" |
写模式,文件不存在会创建,文件存在会清空原内容 |
"a" |
追加模式,内容写到文件末尾 |
"rb" |
二进制读 |
"wb" |
二进制写 |
文件使用完后一定要关闭。
如果程序打开很多文件却不关闭,可能会超过系统限制,导致程序报错。
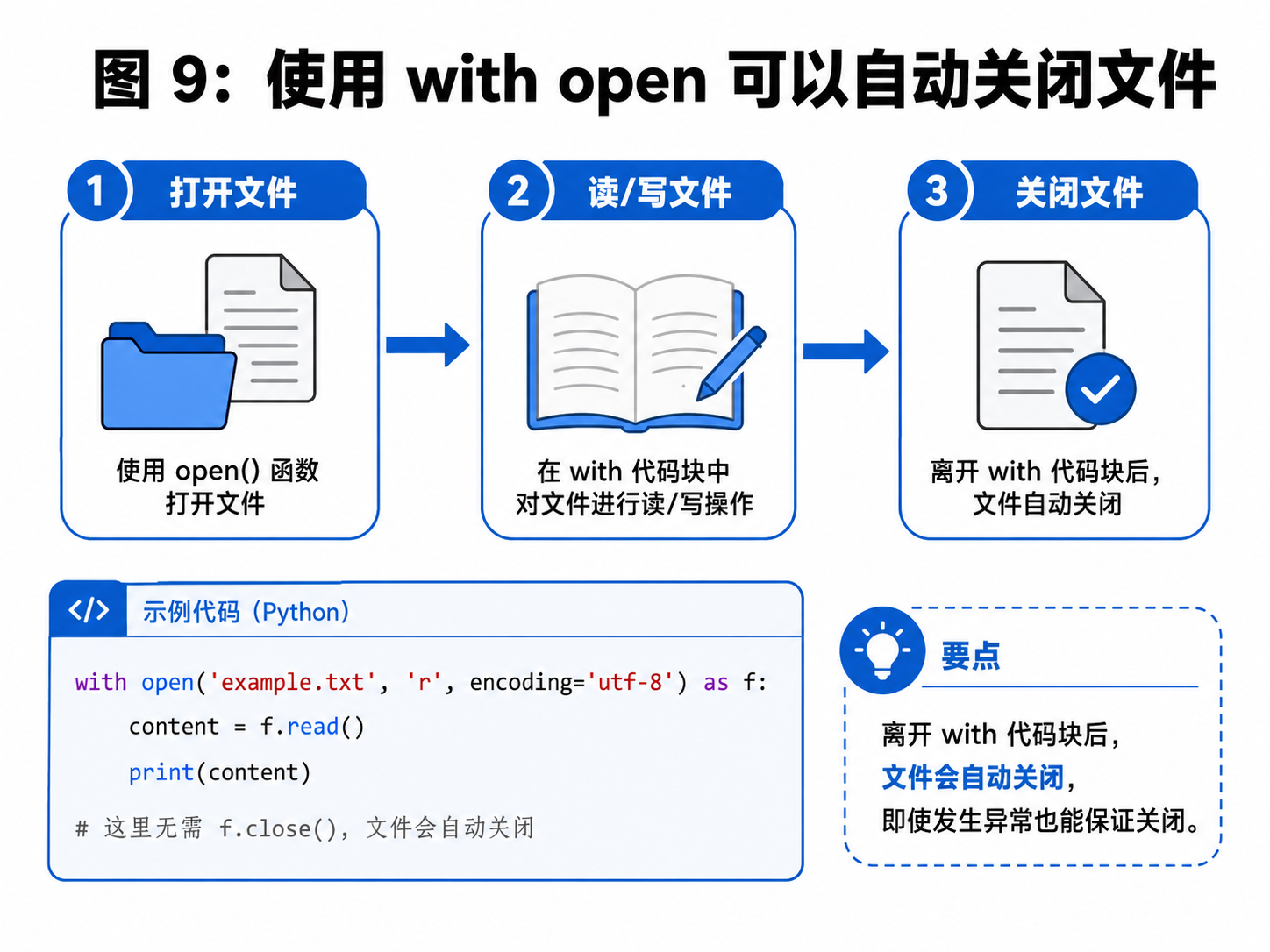
不过实际开发中,更推荐使用 with open(...) 写法。
python
with open("D:/test.txt", "r", encoding="utf-8") as f:
content = f.read()
print(content)使用 with 的好处是:代码块执行结束后,文件会自动关闭。这样不容易忘记 close()。
十八、写文件
使用 "w" 模式写文件:
python
with open("D:/test.txt", "w", encoding="utf-8") as f:
f.write("hello Python\n")注意:"w" 模式会清空原文件内容。
如果你想保留原文件内容,并在末尾继续写,应该使用 "a" 模式。
python
with open("D:/test.txt", "a", encoding="utf-8") as f:
f.write("追加一行内容\n")十九、读文件
1. read:一次读取全部内容
python
with open("D:/test.txt", "r", encoding="utf-8") as f:
content = f.read()
print(content)适合读取比较小的文本文件。
2. readline:一次读取一行
python
with open("D:/test.txt", "r", encoding="utf-8") as f:
line = f.readline()
print(line)3. for 循环逐行读取
python
with open("D:/test.txt", "r", encoding="utf-8") as f:
for line in f:
print(line, end="")如果文件比较大,更推荐逐行读取,不要一次性全部读入内存。
二十、练习:统计成绩
最后用一个简单例子,把函数、列表、字典结合起来。
假设有一组学生成绩:
python
students = [
{"name": "张三", "score": 80},
{"name": "李四", "score": 95},
{"name": "王五", "score": 70},
]我们写一个函数,计算平均分:
python
def calc_average(students):
total = 0
for student in students:
total += student["score"]
return total / len(students)
students = [
{"name": "张三", "score": 80},
{"name": "李四", "score": 95},
{"name": "王五", "score": 70},
]
avg = calc_average(students)
print(f"平均分:{avg}")