博主介绍:程序喵大人
- 35 - 资深C/C++/Rust/Android/iOS客户端开发
- 10年大厂工作经验
- 嵌入式/人工智能/自动驾驶/音视频/游戏开发入门级选手
- 《C++20高级编程》《C++23高级编程》等多本书籍著译者
- 更多原创精品文章,首发gzh,见文末
- 👇👇记得订阅专栏,以防走丢👇👇
😉C++基础系列专栏
😃C语言基础系列专栏
🤣C++大佬养成攻略专栏
🤓C++训练营
👉🏻个人网站
一段后台工作线程的代码,Debug 模式下跑得好好的,切到 Release 就停不下来了。排查了一圈,有人跟你说"加个 volatile 就行"。你加上去,果然好了。
然而,这种看起来"跑正常了"的现象在底层逻辑上是根本经不起推敲的。
cpp
bool stop = false;
void Worker() {
while (!stop) {
DoOneRound();
}
}
void RequestStop() {
stop = true;
}这段代码在 Debug 编译下表现正常,是因为 Debug 模式通常不做激进的优化,编译器老老实实地每次循环都从内存里读 stop。一旦开了优化(-O2 或 Release 模式),编译器发现 Worker 函数内部没有任何地方修改 stop,就把它当成了循环不变量------要么提到循环外面只读一次,要么直接把 while (!stop) 优化成 while (true)。主线程再怎么改 stop,工作线程也看不见了。
这时候加一个 volatile:
cpp
volatile bool stop = false;编译器看到 volatile,就不敢把 stop 的读取优化掉了,每次循环都乖乖去内存里读一次。线程能停下来了。
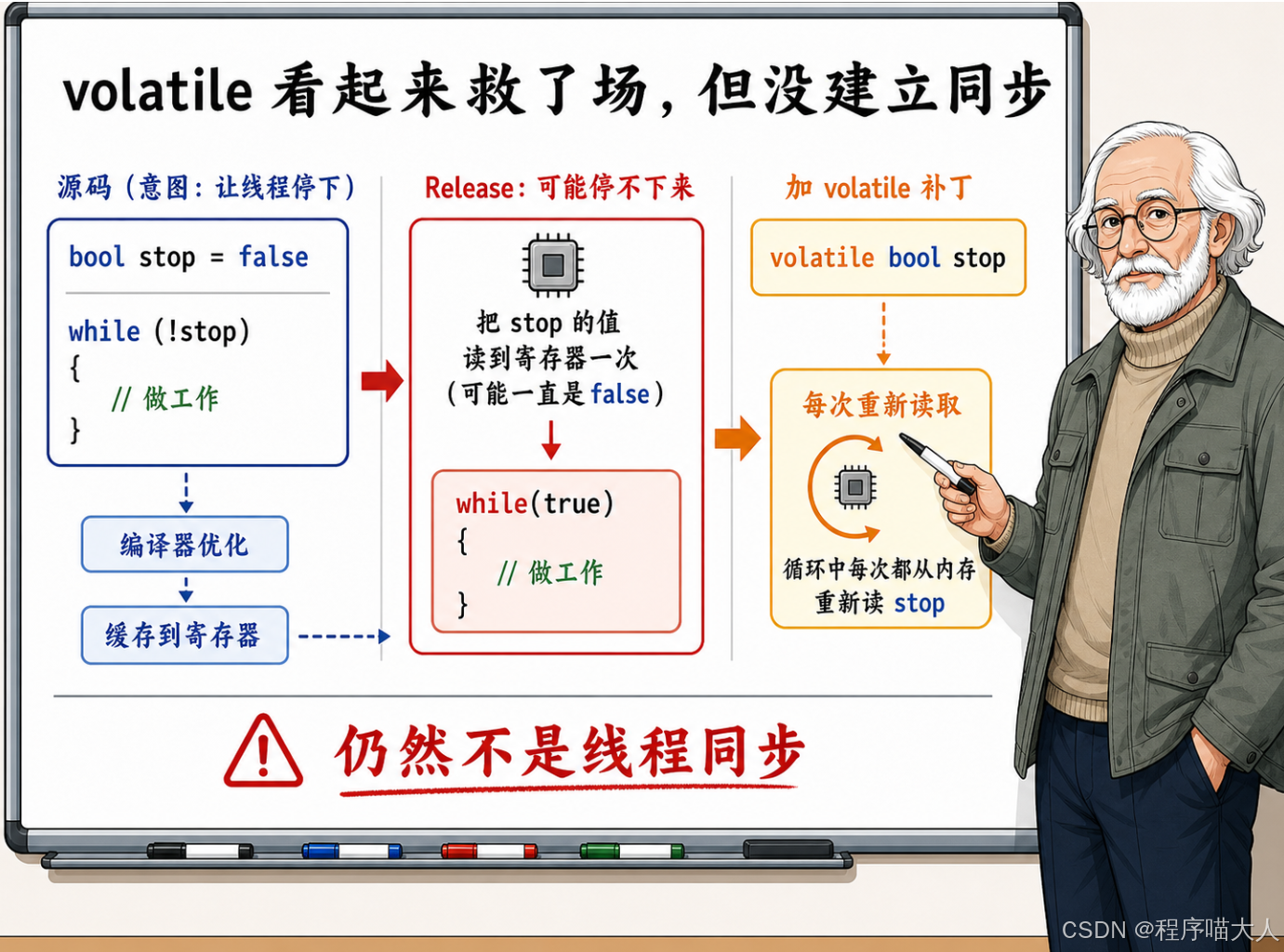
问题在于,这种修法仅仅是触及了表面。它虽然强迫编译器保留了读取动作,但完全没有在 C++内存模型层面建立任何线程间的同步关系,因为 volatile 在 C++里根本就不是一个用于线程同步的工具。
volatile 到底约束了谁
在 C++ 的设计语义中,volatile 约束的对象其实只有一个,那就是编译器。
它的核心作用是告诉编译器:"这个变量的每一次读写都有外部可观察的意义,你不能随便优化掉。"具体来说,当编译器遇到 volatile 声明后,就不能做以下几件事:
- 不能把多次读取合并成一次(哪怕你在循环里读一千次,它也得生成一千条 load 指令)。
- 不能把多次写入合并成一次(连续写两次不同的值,两次都得保留)。
- 不能把
volatile变量的读写跨过其他volatile访问进行重排。
但注意范围------这些约束仅限于编译器层面。volatile 管不了 CPU 硬件的行为。它不会插入任何内存屏障指令,不会阻止 CPU 的写缓冲区延迟刷入,也不会阻止 CPU 流水线对指令做乱序执行。
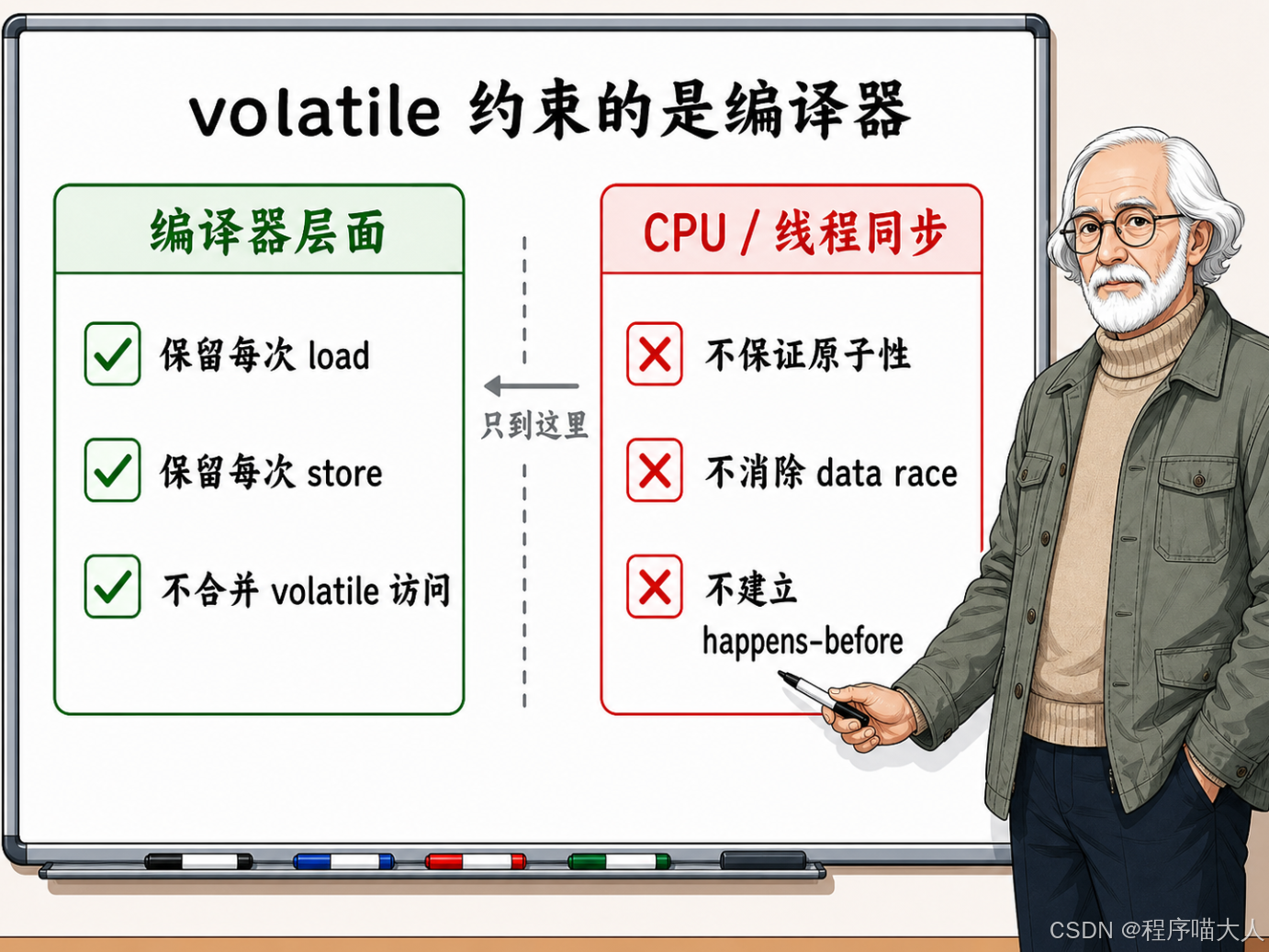
更要命的是,C++标准压根没有给 volatile 读写定义任何线程同步的语义。如果两个线程在没有其他同步手段的情况下,同时读写同一个 volatile 变量,在 C++ 标准看来依然是数据竞争(Data Race),属于未定义行为(Undefined Behavior)。既然是未定义行为,编译器怎么折腾这段代码都算合规------它甚至可以直接把相关逻辑优化掉,标准也完全管不着。
硬件寄存器才是 volatile 的主场
既然 volatile 不管线程同步,那它到底是干什么的?
它的设计初衷是服务于一类特殊场景:变量背后的存储并不是普通内存,而是硬件寄存器或者内存映射 I/O(MMIO)。
cpp
#include <cstdint>
volatile std::uint32_t* const kStatusRegister =
reinterpret_cast<volatile std::uint32_t*>(0x40000000);
std::uint32_t ReadStatus() {
return *kStatusRegister;
}这个地址 0x40000000 背后可能是一块网卡的状态寄存器。每次读它,硬件可能返回不同的值(比如当前有没有新数据包到达)。读一次和读两次是完全不同的操作------第一次读可能会清掉硬件的中断标志,第二次读才能拿到新状态。如果编译器把两次读合并成一次,硬件协议就乱套了。
在写入操作中也是完全相同的逻辑。当我们往一个控制寄存器连续写入 0x01 和 0x02 时,这两个值可能分别代表了"启动传输"和"设置模式"两个截然不同的硬件命令。如果此时编译器自作聪明地认为"反正最终值是 0x02,第一次写可以直接省掉",那么硬件设备就会因为漏掉指令而出现严重故障。
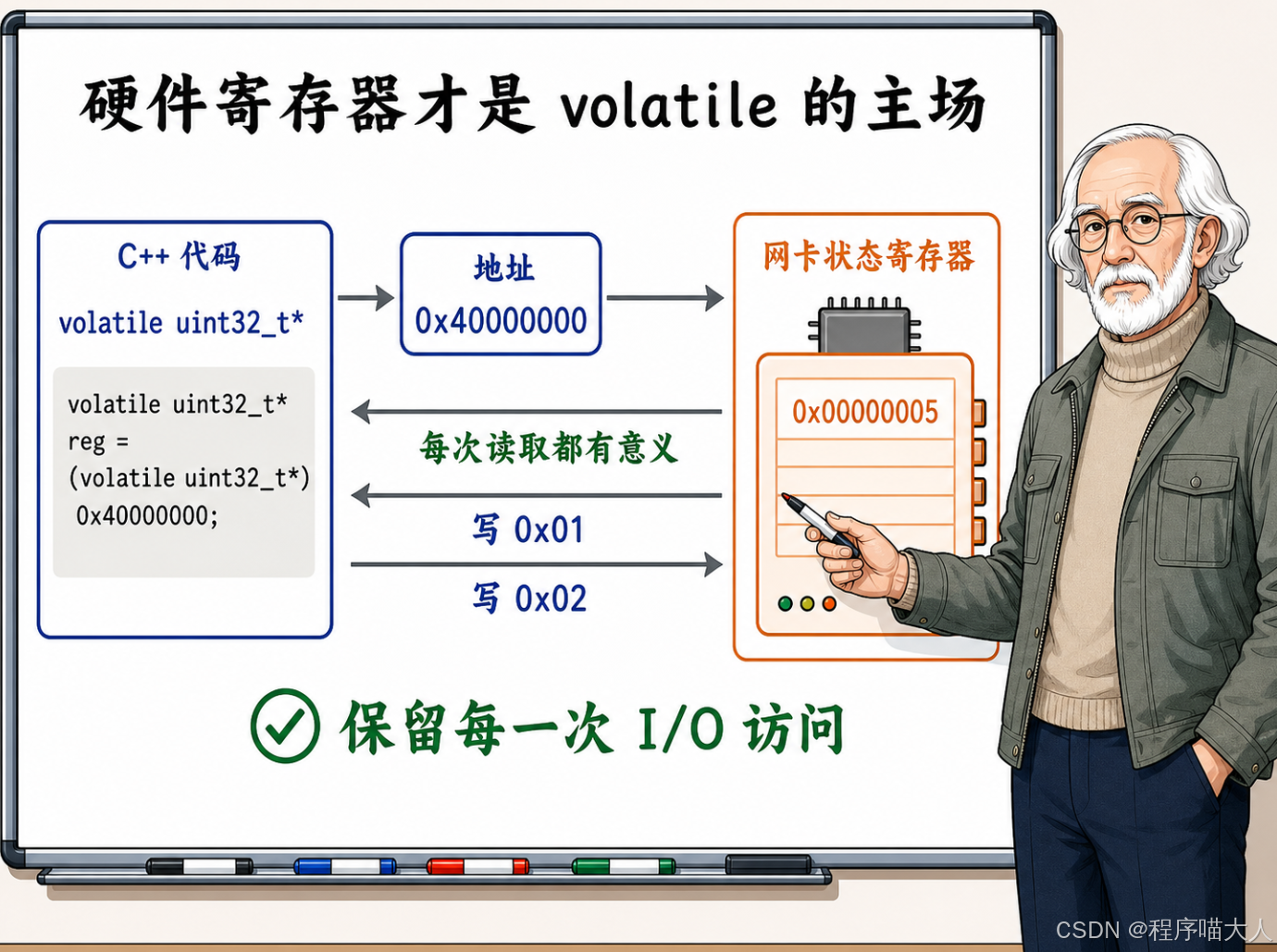
所以 volatile 的语义可以概括成一句话:保留每一次读写动作,保持 volatile 访问之间的相对顺序。 在嵌入式开发、驱动开发、信号处理这些场景下,这个语义非常关键。但它跟多线程同步需要的东西完全是两码事。
线程同步需要什么
当两个线程需要围绕一个共享变量进行安全协作时,通常需要满足三个核心条件,而 volatile 却连一个都无法提供。
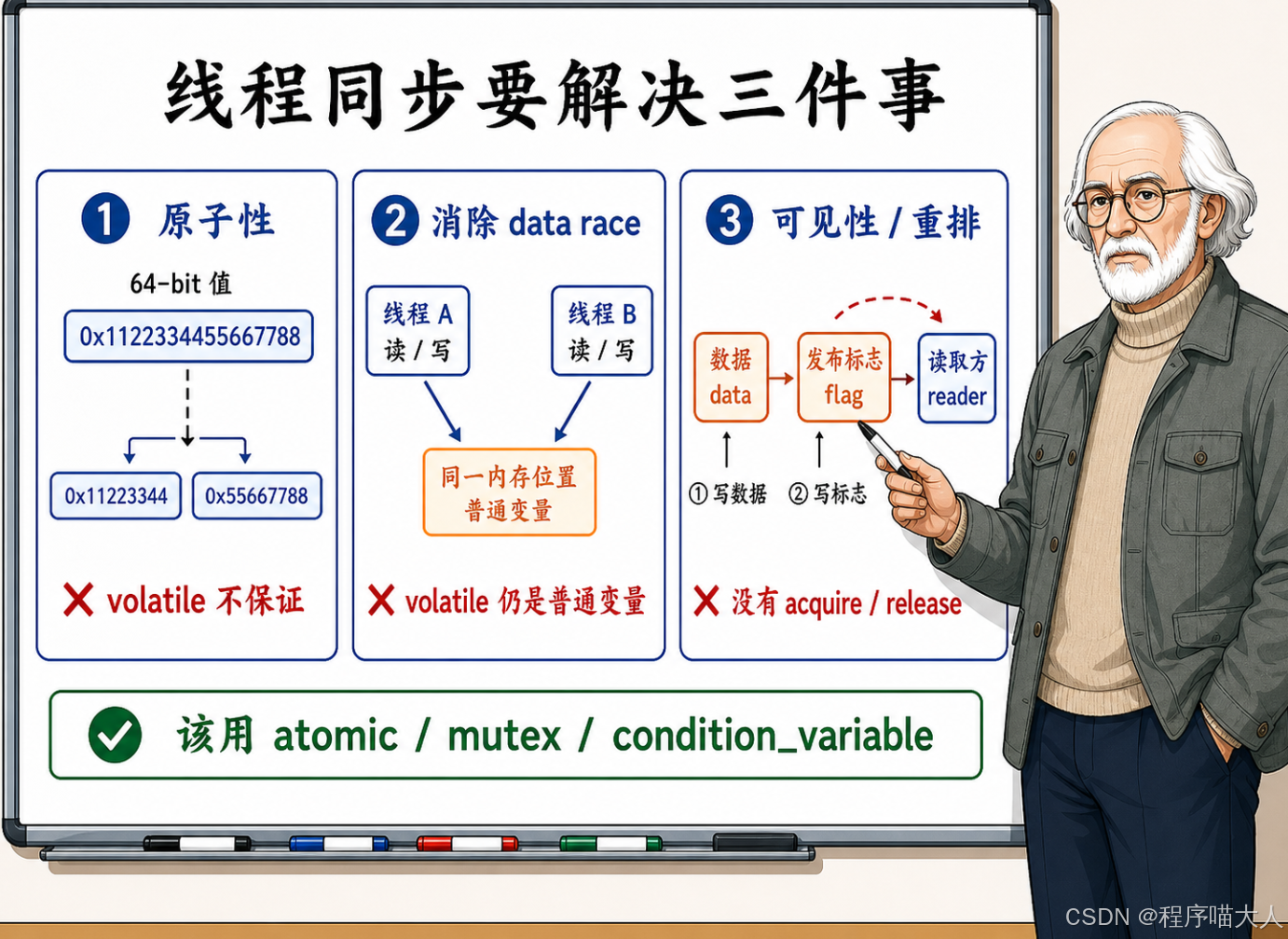
第一,原子性。 一个 64 位整数的读写,在有些平台上并不是一条指令完成的。如果线程 A 正在写入高 32 位,线程 B 同时读了整个值,读到的可能是"高 32 位是新的、低 32 位是旧的"这种撕裂数据。volatile 不保证读写的原子性。
第二,消除数据竞争。 C++ 标准规定,两个线程在没有同步保护的情况下并发访问同一个非原子变量,且至少一方是写操作,就构成数据竞争------直接判定为未定义行为(UB)。volatile 变量仍然是非原子变量,并发读写它照样是 UB。编译器在遇到 UB 时可以做任何事情,包括生成看起来完全不合理的代码。
第三,内存可见性和重排约束。 线程 A 在写标志位之前修改了一批普通数据,线程 B 看到标志位改变后去读那批数据------这中间需要一条完整的同步链来保证数据可见。volatile 既不会在标志位的写入处插入 release 屏障,也不会在标志位的读取处插入 acquire 屏障。没有这条屏障链,普通数据的修改有可能被 CPU 重排到标志位之后才对其他核心可见。
把这三条摆出来就很清楚了:volatile 只解决了"编译器别把这次读/写优化掉"这一个问题。线程同步需要的原子性、UB 消除、跨变量的内存可见性,它全都不管。
volatile ready flag 的错误与修正
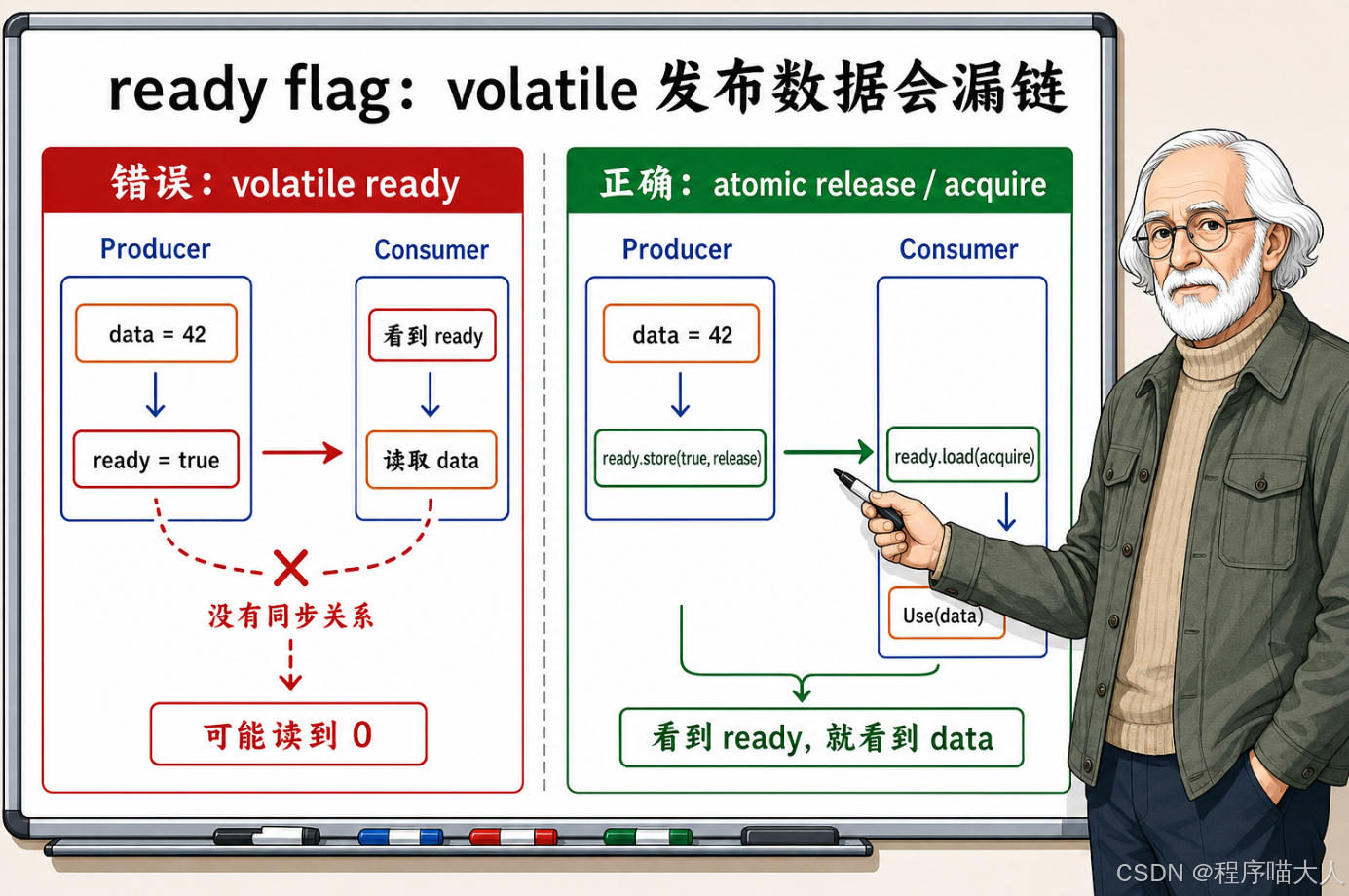
理解了上面三条之后,来看一个典型的错误用法------用 volatile 做数据发布:
cpp
volatile bool ready = false;
int data = 0;
void Producer() {
data = 42;
ready = true;
}
void Consumer() {
while (!ready) {
}
Use(data);
}这段代码想表达的意图很明确:Producer 准备好 data,然后翻 ready 标志;Consumer 等 ready 变成 true,然后读 data。
然而,这段看似合理的代码实际上隐藏了两个非常严重的并发安全问题。
第一个问题是数据竞争。ready 虽然标了 volatile,但它仍然是一个普通的 bool。Producer 写 ready、Consumer 读 ready,同时发生,没有同步保护------这在 C++ 标准中就是 UB。data 也一样,Producer 写 data、Consumer 读 data,中间没有任何同步关系建立,同样是 UB。
第二个问题是内存重排。即使我们不考虑 UB(比如在某些编译器和平台组合下"碰巧"跑对了),volatile 也没有在 data = 42 和 ready = true 之间建立任何屏障。CPU 完全有可能先执行 ready = true 的写入(写缓冲区先刷出去了),后执行 data = 42 的写入。Consumer 那边看到 ready 是 true,兴冲冲去读 data,读到的却是 0。
正确的做法是用 std::atomic:
cpp
#include <atomic>
std::atomic<bool> ready{false};
int data = 0;
void Producer() {
data = 42;
ready.store(true, std::memory_order_release);
}
void Consumer() {
while (!ready.load(std::memory_order_acquire)) {
}
Use(data);
}这个版本里,ready 是一个原子变量,并发读写它不是 UB。更关键的是,release 和 acquire 在 ready 上建立了一条同步链:Producer 的 store(true, release) 保证 data = 42 不会被重排到 store 之后;Consumer 的 load(acquire) 保证 Use(data) 不会被重排到 load 之前。Consumer 一旦看到 ready == true,就能确定 data 已经是 42 了。
这就是 volatile 和 atomic 的根本区别:volatile 只管编译器别优化掉读写动作;atomic 带着完整的同步语义------原子性、消除数据竞争、内存屏障,一样不少。
volatile 计数器为什么仍然丢更新
另一个常见误用是多线程计数器:
cpp
volatile int counter = 0;
void Worker() {
for (int i = 0; i < 100000; ++i) {
++counter;
}
}volatile 确保编译器每次都生成真实的 load 和 store 指令,不会把多次自增合并。但 ++counter 本身不是一条指令------它拆开来是三步:从内存读 counter 到寄存器、寄存器加 1、把新值写回内存。
虽然 volatile 保留了这三步的读写动作,但它没办法把三步合成一个不可打断的操作。当两个线程同时执行 ++counter 时,就完全可能出现如下的交叉执行顺序:
- 线程 A 读
counter,得到 0。 - 线程 B 也读
counter,也得到 0。 - 线程 A 算出 0 + 1 = 1,写回 1。
- 线程 B 也算出 0 + 1 = 1,写回 1。
两次自增,结果只加了 1。跑两个线程各自增 100000 次,最终结果远小于 200000。
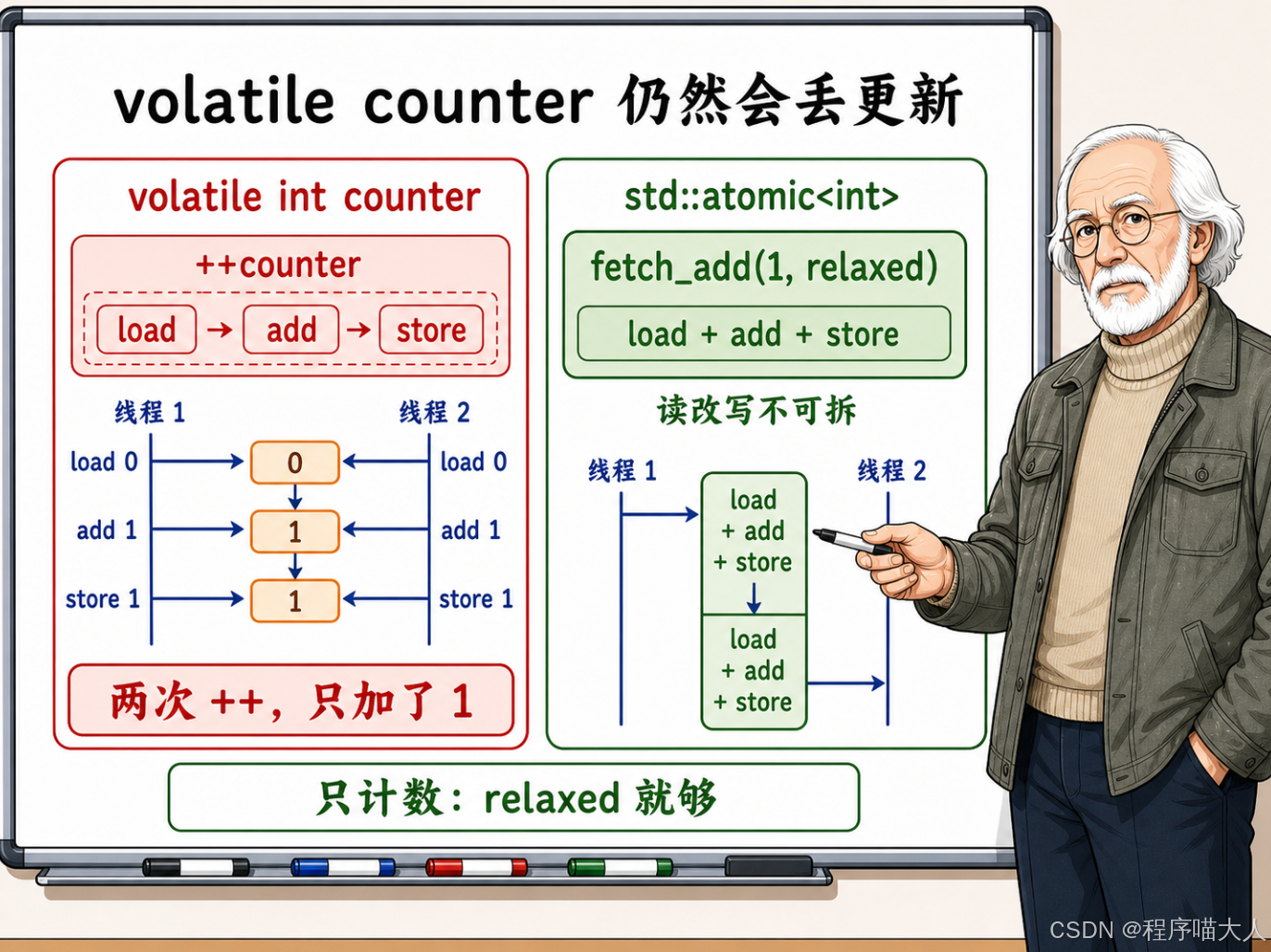
正确的做法是用 std::atomic 的读-改-写操作:
cpp
#include <atomic>
std::atomic<int> counter{0};
void Worker() {
for (int i = 0; i < 100000; ++i) {
counter.fetch_add(1, std::memory_order_relaxed);
}
}fetch_add 在硬件层面是一条原子指令(x86 上是 lock xadd),读取、加 1、写回三步合在一起,中间不会被其他核心插入。这里用 relaxed 内存序就够了,因为我们只需要计数本身的原子性,不需要用这个计数器去保护其他数据的可见性。
停止标志的正确内存序选择
回到最开始的停止标志场景。如果工作线程退出时不需要读取主线程在设置 stop 之前写入的其他数据,relaxed 就够了:
cpp
#include <atomic>
std::atomic<bool> stop{false};
void Worker() {
while (!stop.load(std::memory_order_relaxed)) {
DoOneRound();
}
}
void RequestStop() {
stop.store(true, std::memory_order_relaxed);
}relaxed 保证了原子性和消除数据竞争,但不提供跨变量的内存可见性保证。对于一个纯粹的"退出通知"标志,这就足够了------工作线程只要最终能看到 stop 变成 true 就行,不需要从 stop 的写入推导出其他变量的状态。
但如果主线程在设置停止标志的同时还要传递业务数据呢?比如主线程写好一条指令,然后通知工作线程去执行:
cpp
#include <atomic>
#include <string>
std::string command;
std::atomic<bool> command_ready{false};
void PublishCommand() {
command = "reload";
command_ready.store(true, std::memory_order_release);
}
void Worker() {
while (!command_ready.load(std::memory_order_acquire)) {
}
Run(command);
}这里 command_ready 不只是一个通知信号,它还承担了"发布 command 数据"的职责。release 保证 command = "reload" 不会被重排到 command_ready.store 之后;acquire 保证 Run(command) 不会被重排到 command_ready.load 之前。这条 release-acquire 同步链确保了 Worker 在跳出循环后读到的 command 是完整的。
长时间等待不要忙等
不管是 volatile 的忙等还是 atomic 的忙等,只要是空循环,就意味着一个 CPU 核心在全速空转。短时间的忙等(几微秒级别)在低延迟场景下有时是合理的,但普通业务逻辑中,生产者可能需要几毫秒甚至几秒才能准备好数据。让一个核心空转这么久,功耗和调度成本都不划算。
正常的业务等待应该用 std::condition_variable,让线程挂起,把 CPU 让出来:
cpp
#include <condition_variable>
#include <mutex>
bool ready = false;
int data = 0;
std::mutex mtx;
std::condition_variable cv;
void Producer() {
{
std::lock_guard<std::mutex> lock(mtx);
data = 42;
ready = true;
}
cv.notify_one();
}
void Consumer() {
std::unique_lock<std::mutex> lock(mtx);
cv.wait(lock, [] { return ready; });
Use(data);
}这个版本里 ready 和 data 都是普通变量。它们的线程安全性完全由 mtx 保证------lock_guard 和 unique_lock 在获取和释放锁的边界上天然提供了完整的 acquire-release 语义。condition_variable 在条件不满足时会让消费者线程挂起,不占用 CPU。生产者 notify_one 之后,消费者才会被操作系统唤醒。
Java 的 volatile 和 C++ 的 volatile 不是一回事
如果你写过 Java 或 C#,可能对 volatile 有完全不同的印象。在 Java 里,volatile 字段确实是线程同步工具的一部分。JVM 在实现 volatile 读写时会自动插入内存屏障,建立 happens-before 关系。Java 的 volatile 可以安全地用在双重检查锁定、状态标志等并发场景中。
C++的 volatile 完全不是这个意思。它的设计目标是硬件寄存器和信号处理,跟线程同步没有任何关系。C++标准里写得很清楚:volatile 读写不构成线程间的同步操作,不建立 happens-before 关系。
这两个关键字碰巧同名,语义却天差地别。从 Java 转过来的开发者特别容易踩这个坑------在 Java 里养成的"共享标志加 volatile"的习惯,搬到 C++里就是在写未定义行为。C++里对应 Java volatile 功能的东西是 std::atomic,不是 volatile。
代码审查中怎么处理 volatile
在日常的代码审查(Code Review)中,当我们看到 volatile 关键字时,应当条件反射地提高警惕并多问几个问题:
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
先确认它是不是在做线程同步。 如果一个 volatile 变量被多个线程读写,用来做停止标志、就绪信号、共享计数器之类的事情,那就是误用。改成 std::atomic,或者用 std::mutex 保护。
再确认它是不是在合理场景下。 volatile 的合理用途很窄:内存映射 I/O(嵌入式、驱动开发)、sig_atomic_t 配合信号处理函数、某些平台特定的底层操作。如果代码不属于这些场景,volatile 大概率是误用或者历史遗留。
警惕"优化降级"。 偶尔会有人把 std::atomic 改成 volatile,理由是"atomic 太重了,volatile 够用"。这几乎总是错的。volatile 不提供原子性,不消除数据竞争,不建立内存屏障。所谓"够用"只是在当前编译器、当前平台、当前负载下碰巧没出问题。换个编译器版本或者换个 CPU 架构,bug 就来了。如果确实需要降低 atomic 的开销,正确的做法是降低内存序(比如从默认的 seq_cst 降到 relaxed),而不是把 atomic 整个扔掉。
volatile 在 C++里有它的位置,但那个位置在硬件边界上,不在多线程同步里。把它从线程同步工具箱里拿走,是理解 C++并发模型的第一步。
下一章进入 std::atomic,看看它到底在硬件层面提供了什么保证,以及不同的原子操作各自解决什么问题。
码字不易,欢迎大家点赞,关注,评论,谢谢!