mvanhorn/last30days-skill 项目解析:给 AI Agent 装上"最近 30 天"的社区情报引擎
摘要:大模型很聪明,但它并不天然知道"最近真实用户在讨论什么"。
mvanhorn/last30days-skill是一个面向 AI Agent 的近 30 天社区研究 Skill,它让 Claude Code、Codex、Cursor 等 Agent 在回答前先检索 Reddit、X、YouTube、Hacker News、Polymarket、GitHub 和 Web 等高信号来源,再把热度、评论、视频 transcript、PR 活动等信息综合成有来源的研究简报。本文从项目定位、架构、多源信号、安装使用、风险边界和开发者启发,分析它为什么代表 Agent 工具从"单次调用"走向"可复用工作流"。
TL;DR
- 场景:AI Agent 缺少对"最近真实社区讨论"的感知,普通 Web 搜索被 SEO 旧文和官网信息主导
- 结论 :
last30days-skill是一个面向 Claude Code/Codex/Cursor 等宿主 Agent 的"近 30 天研究 Skill",通过SKILL.md规范流程 + Python 脚本调度多源信号(v3.0.2,2026-06 发布) - 产出:可在写作选题、工具选型、产品调研、热点跟踪场景直接复用的研究工作流
版本矩阵
| 功能 | 状态 | 说明 |
|---|---|---|
| 多源社区检索(Reddit/X/YouTube/HN/Polymarket/GitHub) | ✅ 已验证 | 仓库 README 列出完整支持平台 |
| SKILL.md + Python 双层架构 | ✅ 已验证 | skills/last30days/SKILL.md + scripts/last30days.py |
| Claude Code Plugin/Marketplace 安装 | ✅ 已验证 | /plugin marketplace add mvanhorn/last30days-skill |
| Codex/Cursor/Copilot/Gemini CLI 安装 | ✅ 已验证 | npx skills add mvanhorn/last30days-skill -g |
| v3.0.2 修复 Claude Code v2.1.105+ slash command | ✅ 已验证 | 2026-06-07 Release 记录 |
| 跨源 cluster merging 聚类 | ✅ 已验证 | v3 README 明确说明 |
| Polymarket 资金权重信号 | ✅ 已验证 | README 列为支持来源 |
| person-mode 人物研究模式 | ✅ 已验证 | README 描述的智能搜索能力 |
| 全量平台数据源配置 | ⚠️ 待验证 | 依赖 API Key/cookie/本地 CLI 配置 |
| TikTok/Instagram Reels 长期稳定性 | ⚠️ 待验证 | 平台访问规则经常变化 |
| 输出作为可追溯 SQLite/Markdown 资产 | ✅ 已验证 | 支持 --emit 多种格式 |
文章正文
大模型很聪明,但它并不天然知道"最近真实用户在讨论什么"。
mvanhorn/last30days-skill是一个面向 AI Agent 的近 30 天社区研究 Skill,它让 Claude Code、Codex、Cursor 等 Agent 在回答前先检索 Reddit、X、YouTube、Hacker News、Polymarket、GitHub 和 Web 等高信号来源,再把热度、评论、视频 transcript、PR 活动等信息综合成有来源的研究简报。本文从项目定位、架构、多源信号、安装使用、风险边界和开发者启发,分析它为什么代表 Agent 工具从"单次调用"走向"可复用工作流"。

为什么这个项目值得关注?
如果你长期用 AI 写代码、写文章、做产品调研,会发现一个问题:模型很聪明,但它不天然知道最近真实用户在讨论什么。
模型有训练数据边界。即使接入普通网页搜索,拿到的也常常是官网、博客、新闻、SEO 页面。这些内容有价值,但并不等同于真实用户最近的讨论现场。
很多高信号内容先出现在社区:开发者吐槽在 Hacker News,真实踩坑在 Reddit 评论,产品传播在 X、YouTube、TikTok,市场预期在 Polymarket,开源项目进展在 GitHub issue、PR 和 release note。
last30days-skill 解决的正是这个问题。它不是普通搜索工具,也不是单纯 prompt 模板,而是一个面向 AI Agent 的"近 30 天研究技能":用户给出主题,Agent 围绕主题搜索多个高信号平台,并综合点赞、评论、观看、转发、赔率、PR 活动等信号,生成有来源、有侧重、有时间感的研究简报。
一句话概括:
text
last30days-skill 让 AI 不只是回答"它知道什么",而是先理解"最近真实的人在说什么"。项目定位:不是 Web Search,而是 Agent Skill
官方 README 对它的定位很明确:研究任意主题在最近 30 天内的 Reddit、X、YouTube、Hacker News、Polymarket、Web 等公开讨论,并生成 grounded summary。
这个定位里有三个关键词。
第一是"最近 30 天"。它不是百科,也不是官方文档替代品,而是专门捕捉近期动态。AI Agent 框架、模型 API、Cursor、Claude Code、Codex、Qwen、vLLM、MCP、RAG 这类领域变化很快,半年前的文章可能已经过期。
第二是"people actually say"。它更关注真实用户、开发者、创作者、交易者和社区成员最近怎么表达,而不是只看媒体报道和 SEO 页面。
第三是"Agent Skill"。它不是独立 SaaS 页面,而是可被 Claude Code、Codex、Cursor、Gemini CLI 等 Agent Harness 调用的 Skill。Skill 的核心是 SKILL.md:它把触发条件、执行流程、约束、自检规则、脚本入口和输出格式打包成可复用能力。
所以这个项目可以理解成一个"研究型 Agent 能力包":SKILL.md 负责流程规范,Python 脚本负责多平台检索与处理,宿主模型负责总结、归纳和再加工。
它解决了什么痛点?
假设你要写一篇文章:《最近开发者怎么看 Claude Code Skills?》
普通做法是打开 Google,再分别看 Reddit、X、HN、YouTube、GitHub。你要判断哪些内容是最近的,哪些只是 SEO 旧文,哪些是少数情绪,哪些是社区真正反复讨论的问题。
这个流程很耗时间。技术内容尤其如此,因为你需要的不是"资料",而是"最近 30 天的真实语境":大家关心安装体验、安全风险、跨平台兼容、Skill 分发标准,还是 Claude Code 与 Codex 对 Skills 的支持差异?
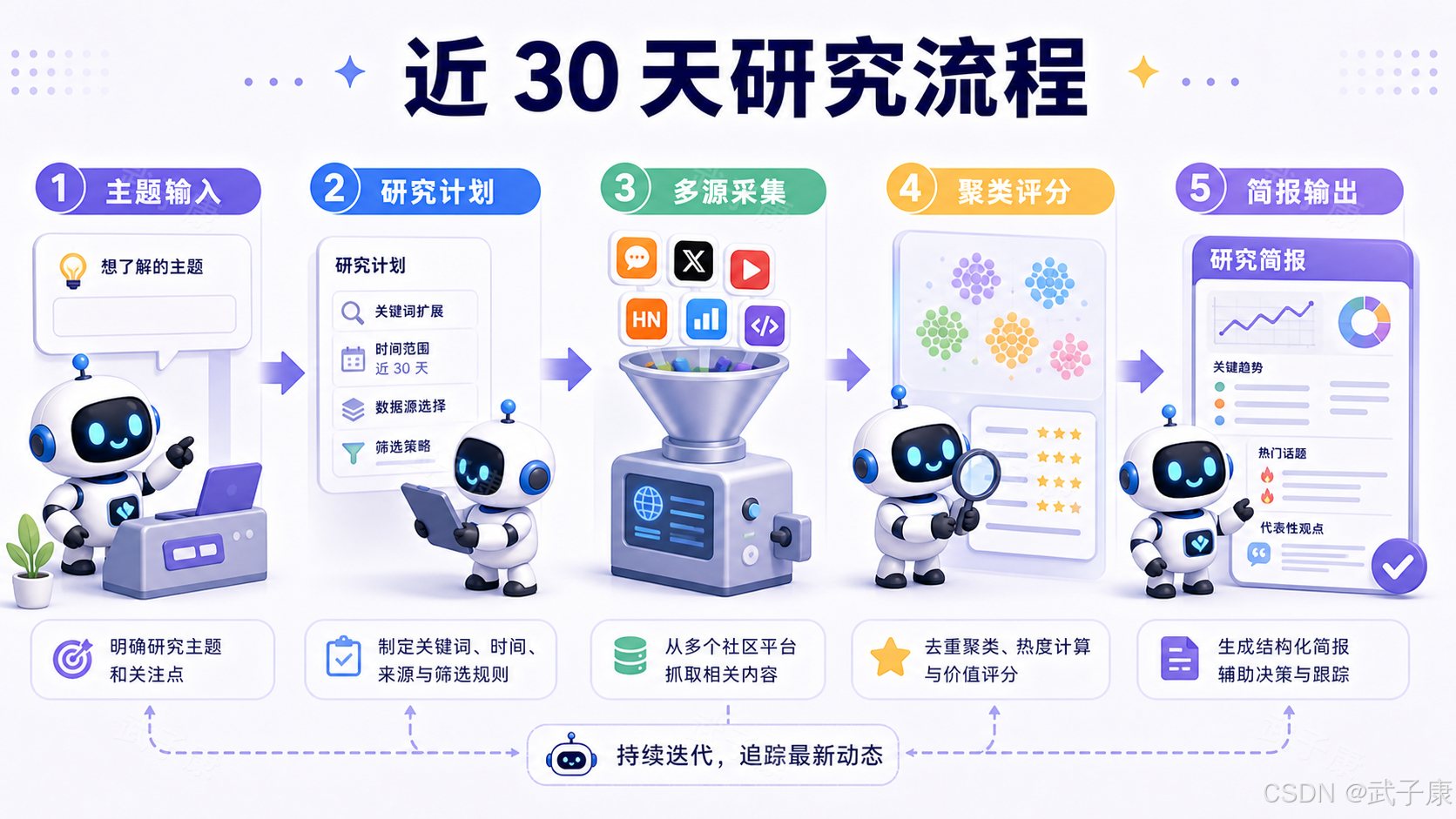
last30days-skill 把这个流程自动化了。它会先做意图解析和预研究,判断要搜索哪些平台、关键词、账号、subreddit、GitHub repo、YouTube channel 或 hashtag;再并行搜索多个来源,根据相关性、热度、参与度和新鲜度排序聚类,最后合成为一份简报。
这不是保证所有结论绝对正确,而是把"人工打开几十个标签页做调研"的成本降下来。对内容创作者,它能帮助选题验证;对开发者,它能补充真实使用反馈;对产品经理,它能更快找到用户语言。
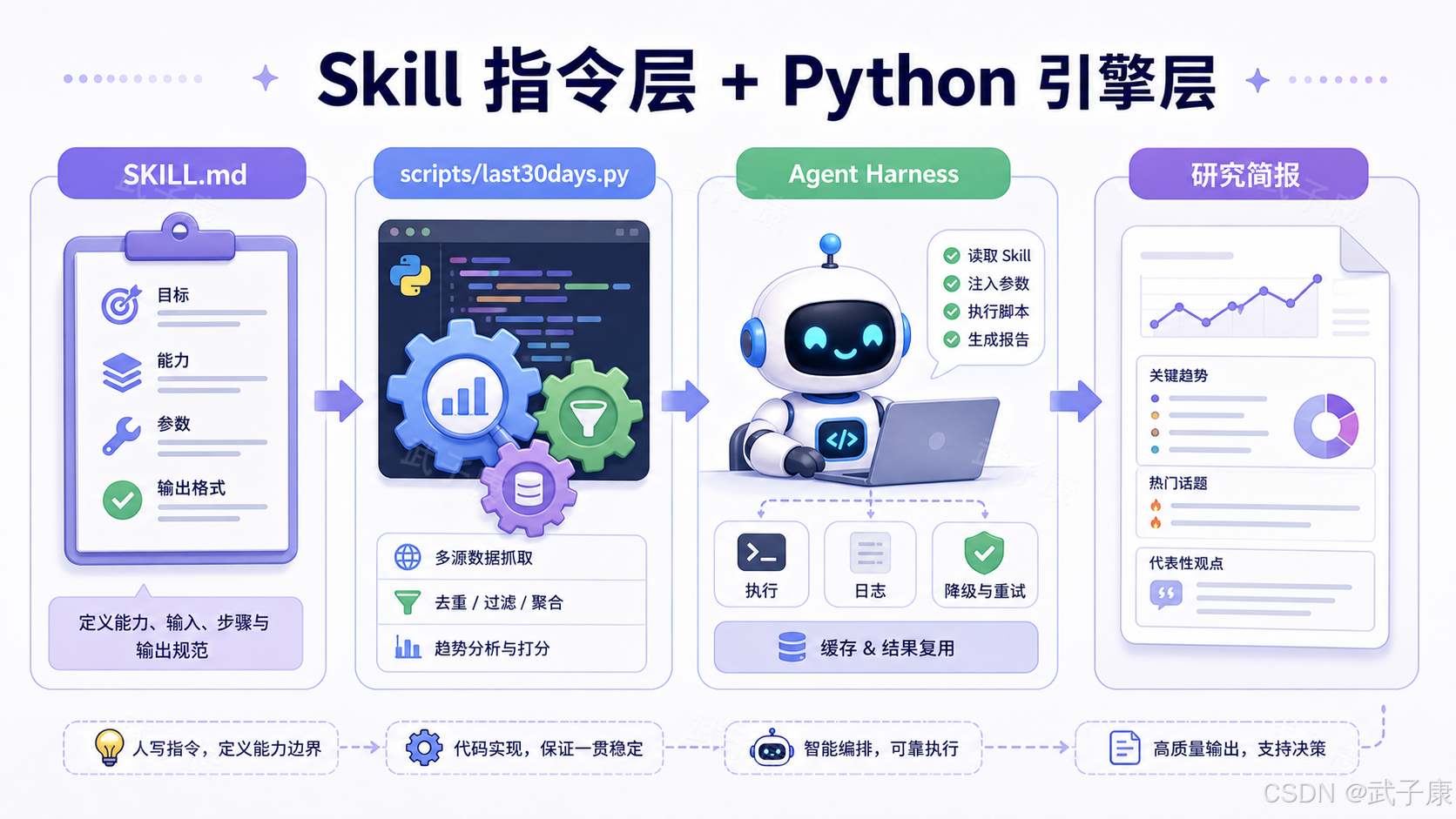
项目架构:Skill 指令层 + Python 引擎层
从仓库结构看,last30days-skill 不是只有一个 Markdown 文件。核心运行文件位于 skills/last30days,并配套 scripts、docs、fixtures、tests、插件配置等目录。
第一层是 Skill 指令层。
skills/last30days/SKILL.md 是行为规范核心,包含名称、描述、支持工具、环境变量、运行前检查、首次设置向导、用户意图解析、查询类型判断、搜索策略、输出格式、引用规则和自检规则。
这一层决定 Agent 怎么"思考和行动"。例如用户输入 /last30days AI video tools,Agent 不应该直接泛泛回答,而要先解析主题、判断查询类型、生成子查询、决定搜索源、执行引擎、读取完整输出、补充 WebSearch,再综合最终答复。
第二层是 Python 引擎层。
仓库里的 scripts/last30days.py 是 CLI 入口,负责解析 --quick、--deep、--days、--emit、--save-dir、--store、--diagnose、--github-user、--github-repo、--competitors 等参数,再调用内部 pipeline、render、schema、env、html_render 等模块。
这种设计很适合 Agent:模型负责规划、判断和综合,传统代码负责检索、解析、持久化、格式化和确定性处理。纯 prompt 难以稳定处理复杂 I/O,纯脚本又缺少语义弹性;Skill 把二者连接起来。
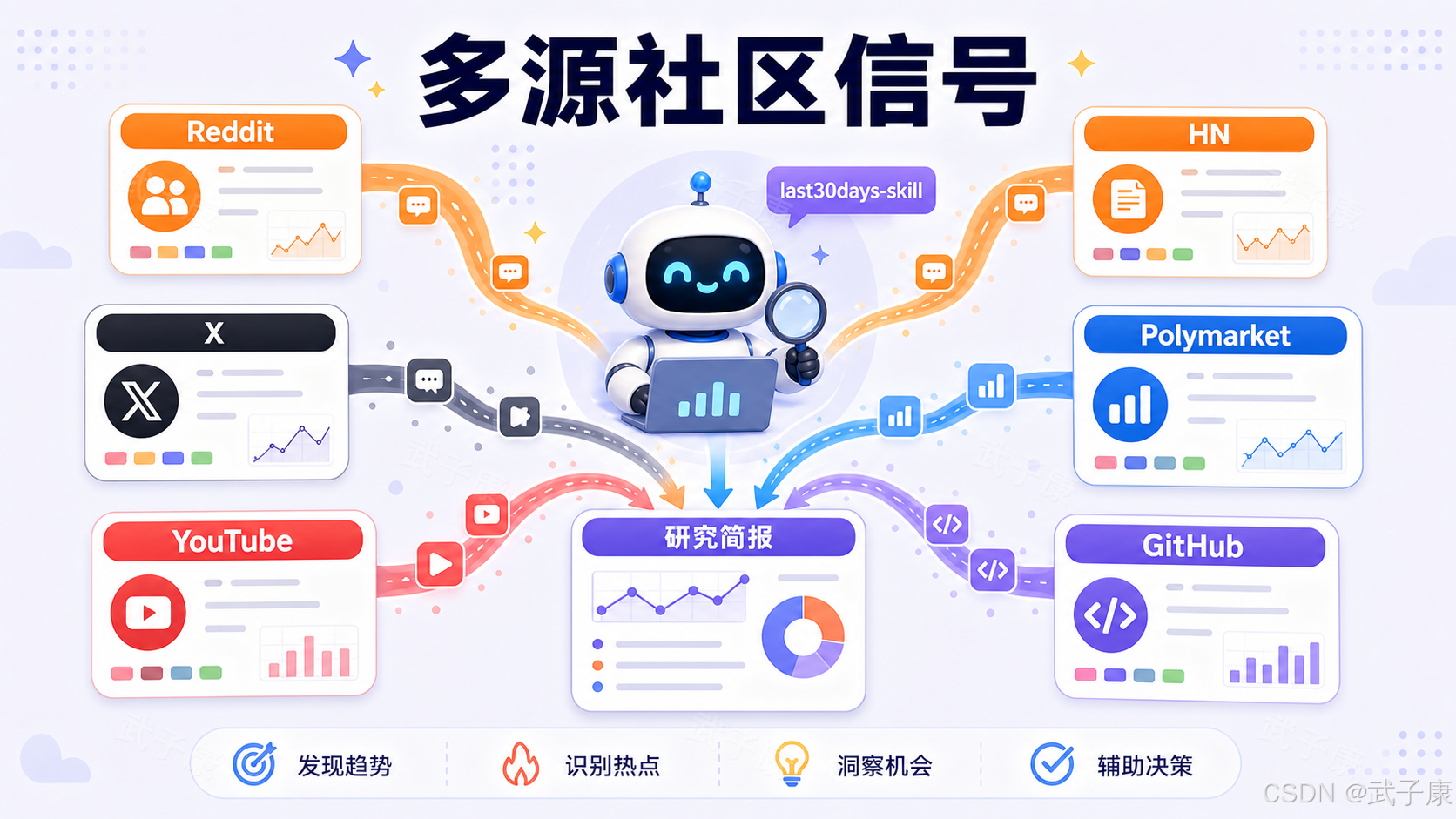
多源信号:不同平台提供不同答案
last30days-skill 最吸引人的地方是多源整合。README 提到的主要来源包括 Reddit、X/Twitter、YouTube、TikTok、Instagram Reels、Hacker News、Polymarket、GitHub、Threads、Bluesky、Perplexity 和 Web 等。
这些来源的价值不一样。
Reddit 更适合看真实用户意见。长评论、踩坑反馈、工具推荐和负面体验,往往比官网更接近实际使用。
X/Twitter 更适合看实时反应、专家观点、行业传播和观点扩散。
YouTube 的价值在长内容和 transcript。一个 40 分钟工具评测,可能包含大量实际使用细节。
Hacker News 更适合看工程师共识。高赞评论经常暴露架构复杂度、商业模式、隐私风险、开源许可证和性能瓶颈。
Polymarket 是带资金权重的预测信号。它不能代表事实,但可以作为市场预期维度。
GitHub 更偏工程事实。对于开源项目和工具链,它可以看 PR、release、issue、star 和 repo 活跃度。
重点不是"平台越多越好",而是不同平台代表不同类型的信号。一个主题只在新闻里出现,可能只是媒体事件;如果同时在 Reddit、X、HN、YouTube、GitHub 出现,就说明它已经形成跨社区讨论。
搜索流程:先理解主题,再搜索平台
普通搜索工具往往是关键词搜索。用户输入什么,它就搜什么。
last30days-skill 更像 Agent:它在搜索前先理解主题。README 把这类能力称为 intelligent search,也就是在真正搜索前识别主题相关的人、账号、社区、repo、频道和标签。
例如用户输入一个产品名,系统不应该只搜索产品名,还应该识别创始人、官方账号、相关 GitHub repo、subreddit、YouTube 频道。用户输入一个人名,也不应该只搜这个名字,而要切换到 person-mode,看这个人最近在 GitHub 合并了什么 PR、在哪些项目活跃、社区如何讨论。
这一步很重要,因为真实世界的信息并不总是使用同一个关键词。一个开源项目可能有项目名、组织名、创始人名、CLI 名、repo 名、缩写名和社区昵称。只搜一个关键词,很容易漏掉大量内容。
聚类、评分和综合
多源检索之后,最大的问题是噪音和重复。
某个 AI 工具发布,GitHub 上有 release,X 上有作者线程,HN 上有讨论,Reddit 上有吐槽,YouTube 上有评测。普通搜索会给你一堆重复链接;真正需要的是把这些信号合并成一个"事件簇"。
last30days-skill 的 v3 README 提到 cross-source cluster merging,也就是当同一个故事出现在多个来源时,系统会尝试合并为 cluster,而不是展示成互不相关的结果。
这有两个意义:第一,降低阅读负担;第二,提高置信度。一个只出现在单一来源的小消息,和一个同时出现在 Reddit、X、YouTube、HN 的话题,重要性并不一样。
但要注意:高互动不等于高质量,高热度不等于正确。争议话题可能因为情绪强而获得大量互动,低调但重要的技术变更可能热度很低。所以这类结果应该被看作"研究入口"和"舆论信号",不是最终事实判决。
安装、配置与使用
Claude Code 可使用 plugin/marketplace 方式安装:
bash
/plugin marketplace add mvanhorn/last30days-skill
/plugin install last30days对于 Codex、Cursor、Copilot、Gemini CLI 等支持 Agent Skills 的宿主,可以使用:
bash
npx skills add mvanhorn/last30days-skill -g常见使用方式类似:
bash
/last30days AI video tools
/last30days Claude Code skills
/last30days OpenAI vs Anthropic vs xAI
/last30days Peter Steinberger更完整的数据源通常需要配置 API Key、cookie 或本地 CLI。配置文件可以放在全局目录 ~/.config/last30days/.env,也可以放在项目目录 .claude/last30days.env。项目级配置优先级更高,适合给不同客户或项目设置不同数据源。
输出默认保存到 ~/Documents/Last30Days/,也可以通过 LAST30DAYS_MEMORY_DIR 或 --save-dir 修改。它还支持 raw markdown、HTML、JSON、SQLite store 等输出形态,可以把每次研究变成可追溯资产。
适合哪些场景?
第一,技术博客选题。写文章前先看最近 30 天社区信号,能避免只凭经验写大纲。比如写 Agent Skills 工具链研究,可以先看安装体验、安全风险、Skill 和 MCP 区别、跨平台兼容、Marketplace 等近期讨论。
第二,工具选型。比较 OpenClaw vs Claude Code vs Codex,不能只看官网和 GitHub stars,还要看真实用户抱怨:哪个安装麻烦,哪个上下文管理差,哪个生态更快,哪个适合团队协作。
第三,产品需求调研。如果你准备做本地语音 Agent、SEO 工具、Prompt 管理器、Agent Memory 系统,社区讨论往往比竞品官网更能暴露需求。
第四,会前研究。对某个人或公司做近 30 天研究,比只看官网、LinkedIn 更接近当前状态。
第五,热点跟踪。把主题加入 watchlist,定期生成 briefing,就接近一个个人化情报系统。
和 Web Search、MCP 的区别
普通 Web Search 解决的是"有没有网页提到这个东西"。last30days-skill 更接近解决"最近真实社区如何讨论这个东西"。
它不应该替代官方文档和权威资料,而应该作为前置调研层。正确用法是:先用它看社区最近在讨论什么,再回到官方文档、GitHub release、issue、论文、API 文档中验证事实。
它和 MCP 也不同。MCP 更像给 Agent 提供外部工具和数据接口,强调"Agent 能调用什么"。Skill 更像给 Agent 提供可复用工作方法,强调"Agent 应该怎么做"。last30days-skill 可以调用脚本和外部服务,但它的核心价值是把近 30 天研究流程写进 Skill。
未来更强的形态可能是 Skill + MCP:Skill 负责研究方法论,MCP 负责连接 GitHub、YouTube transcript、Reddit、浏览器、内部知识库、Slack 等数据源。
限制和风险
第一,数据源依赖复杂。多平台意味着多认证、多 API、多格式、多失败点。X、YouTube、TikTok、Instagram 的访问规则经常变化,维护成本很高。
第二,结果质量依赖宿主模型。脚本能检索,Skill 能约束流程,但最终综合仍由模型完成。如果模型没有认真读取结果,可能生成看似合理但不忠于来源的总结。
第三,社区热度不等于事实。高赞帖子可能错,热门视频可能夸大,X 传播可能被圈层放大,Polymarket 赔率也不代表真相。
第四,隐私和安全需要审计。它可能读取本地配置、API Key、cookie、浏览器会话,甚至调用外部服务。安装第三方 Skill 前,应该审计脚本、依赖和网络访问行为。
对开发者的启发
这个项目最值得学习的,不只是它能搜 Reddit 或 X,而是它展示了一种新型 Agent 工具设计方法。
过去工具通常有两种模式:写 CLI,稳定但不懂语义;写 prompt,灵活但不稳定。Skill 把两者合并了。
SKILL.md 是操作手册,告诉模型何时使用、如何判断、如何输出、如何自检。scripts 是工具箱,处理确定性的部分。模型不是凭空发挥,而是在 Skill 的约束下调度脚本和工具。
这意味着很多 AI 工具不一定一开始就做 SaaS,也不一定只做 MCP。可以先做成高质量 Skill:写博客前的资料调研 Skill、Java 项目重构 Skill、vLLM 部署排查 Skill、VPS 安全加固 Skill、SEO 工具页优化 Skill、GitHub issue triage Skill。
这些任务都有共同点:不是单次工具调用,而是一套多步骤流程。只要流程能写清楚,部分步骤能脚本化,就适合做成 Skill。
总结
mvanhorn/last30days-skill 不是重新发明搜索引擎,而是重新组织搜索流程。它不试图成为权威事实源,而是把近 30 天的社区讨论、平台热度、开发者反馈、视频 transcript、市场赔率和 GitHub 活动压缩成一份可继续追问的研究上下文。
它真正展示的是一种新范式:把人的研究流程写进 Skill,把确定性工作交给脚本,把语义综合交给模型,把最终结果变成可追溯的研究资产。
未来的 AI Agent 不会只靠大模型本身变强。它们会通过 Skills、MCP、插件、脚本、本地知识库和工作流模板不断获得新的能力。
last30days-skill 的意义就在这里:它不是让 AI 更会"回答",而是让 AI 更会"研究"。

错误速查卡
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
/last30days 返回 Unknown command |
Claude Code v2.1.105+ 升级后 plugin.json 未声明 skills 目录 | /doctor 报错 Path escapes plugin directory |
升级到 v3.0.2+,确认 .claude-plugin/plugin.json 包含 "skills": ["skills"] |
出现重复的 last30days-3@last30days-skill |
用户作用域与项目作用域安装冲突 | /plugin list 出现两条同名记录 |
删除 user-scope 重复安装,仅保留 project-scope |
| 检索结果只显示单一来源 | 主题过于狭窄,缺少智能扩展 | 关键词搜索未触发 intelligent search | 在 SKILL.md 流程中先做主题扩展(人名/账号/repo/channel) |
| 平台数据为空或频繁失败 | X/YouTube/TikTok 访问规则变化 | 认证 cookie 或 API Key 失效 | 检查 ~/.config/last30days/.env 配置并更新 token |
| 总结与来源内容对不上 | 宿主模型未认真读取 JSON 输出 | 输出文件存在但模型跳读 | 强化 SKILL.md 中"必须读取完整输出"自检规则 |
| 热门结论与事实不符 | 社区热度不等于事实质量 | 单源高赞贴不代表共识 | 至少要求 2 个独立来源交叉验证 |
| 安装后脚本拒绝运行 | 第三方 Skill 安全审计未通过 | 脚本请求网络访问或读取浏览器会话 | 安装前审计 scripts/last30days.py 网络/文件访问行为 |
| 输出保存到默认目录找不到 | 未配置 --save-dir 或环境变量 |
~/Documents/Last30Days 路径缺失 |
设置 LAST30DAYS_MEMORY_DIR 或传 --save-dir |
✍️ 作者:武子康的个人博客