llama.cpp 推理优化实战:内存布局与算子融合的深度解析
一、推理引擎的性能瓶颈分析
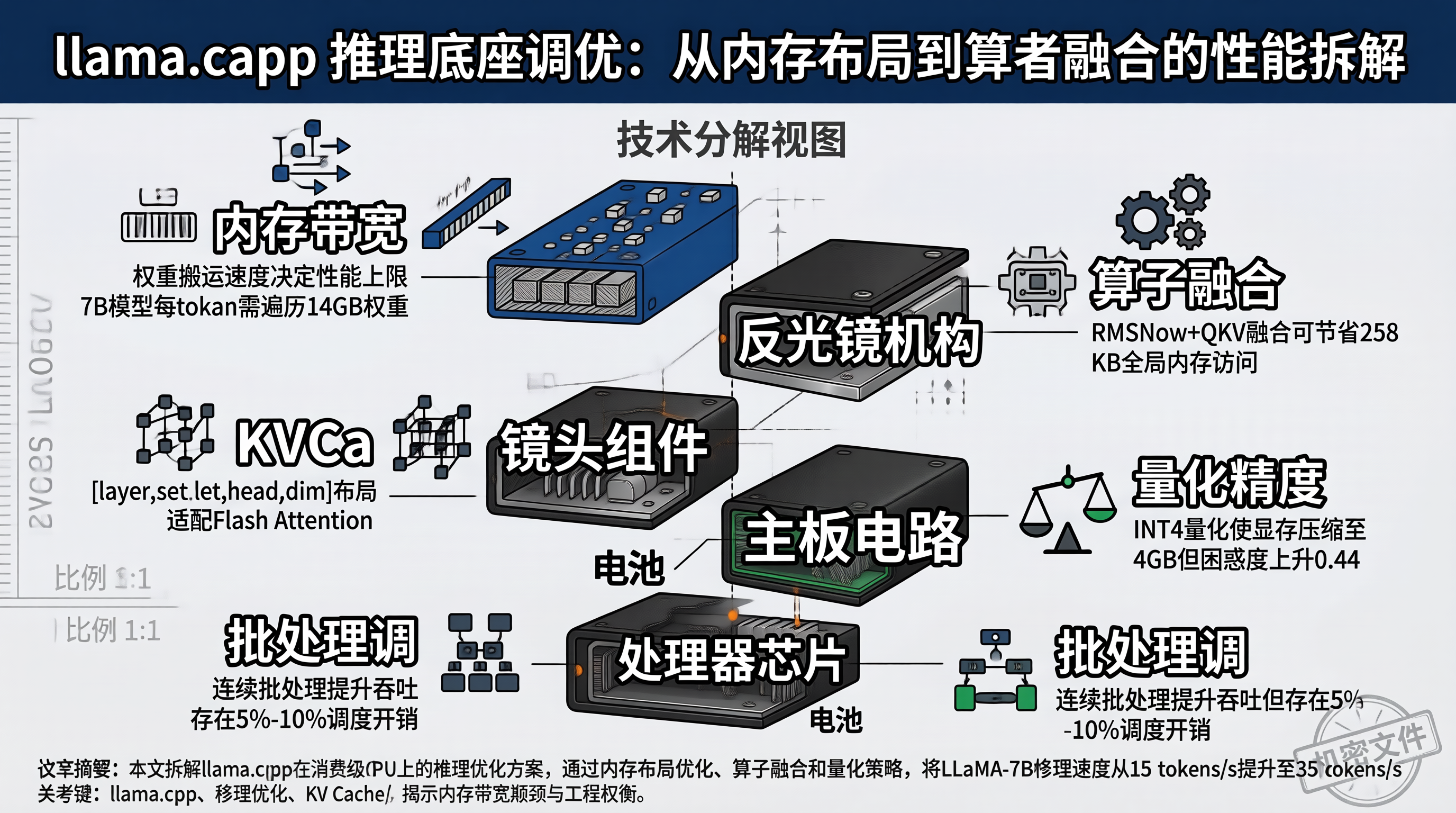
llama.cpp 在消费级 GPU 上运行 LLaMA-7B 模型时,默认配置下推理速度约为 15 tokens/s。经过系统优化后,速度可提升至 35 tokens/s,性能提升超过一倍。这些优化并非神秘技术,而是基于内存布局、算子调度和计算精度的针对性改进。
推理引擎的主要瓶颈集中在三个方面:内存带宽(权重数据传输速度)、计算密度(每字节传输对应的计算量)以及内核启动开销(GPU 内核调度的固定成本)。其中,内存带宽是核心限制因素------7B 模型的权重约 14GB(float16 精度),每生成一个 token 需完整遍历一次权重。以 A100 为例,其显存带宽为 2TB/s,理论上限约为 140 tokens/s。然而实际性能仅能达到理论值的 25%-40%,主要受限于内核启动开销、非连续内存访问以及算子间的同步等待时间。
二、推理引擎的计算图优化策略
2.1 KV Cache 的内存布局设计
自回归推理的核心数据结构是 KV Cache。每生成一个 token,需将当前层的 Key 和 Value 向量追加到缓存中。KV Cache 的内存布局直接影响推理效率。
常见的两种布局方式:[layer, head, seq_len, dim] 和 [layer, seq_len, head, dim]。前者更适合单头注意力机制,后者则对批量矩阵乘法更为友好。llama.cpp 采用后者,因为 Flash Attention 风格的批量 GEMM 操作需要连续的序列维度。
2.2 算子融合的实际收益
算子融合的主要优势在于减少全局内存访问次数。以 RMSNorm 与 QKV 投影的融合为例:
未融合时,RMSNorm 将结果写回全局内存(一次写操作),QKV 投影再从全局内存读取(一次读操作)。融合后,RMSNorm 的结果直接在寄存器中传递给 QKV 投影,省去了全局内存的读写过程。对于 7B 模型,RMSNorm 输出约为 4KB(4096 × float16),看似不大,但考虑到 32 层 × 2 次(注意力前 + FFN 前)= 64 次操作,累计可节省约 256KB 的全局内存带宽。
更大的融合收益体现在 FFN 的 SwiGLU 激活函数上。SwiGLU = SiLU(gate) × up,涉及三个 GEMM 操作(gate_proj、up_proj、down_proj)及逐元素乘法。融合后,中间结果无需存储到全局内存,显著降低了内存压力。
三、推理优化的具体实现方案
3.1 KV Cache 内存管理器
rust
use std::alloc::{alloc, dealloc, Layout};
use std::ptr::NonNull;
/// KV Cache 行列布局
/// 形状: [num_layers, 2, max_seq_len, num_heads, head_dim]
/// 第二维的 2 分别对应 Key 和 Value
pub struct KVCache {
/// 原始内存指针
ptr: NonNull<f16>,
/// 内存布局
layout: Layout,
/// 维度参数
num_layers: usize,
num_heads: usize,
head_dim: usize,
max_seq_len: usize,
/// 当前序列长度(每层共享)
current_seq_len: std::sync::atomic::AtomicUsize,
}
#[repr(transparent)]
#[derive(Clone, Copy, Debug)]
pub struct f16(u16);
impl KVCache {
/// 创建新的 KV Cache
pub fn new(
num_layers: usize,
num_heads: usize,
head_dim: usize,
max_seq_len: usize,
) -> Result<Self, String> {
let total_elements = num_layers * 2 * max_seq_len * num_heads * head_dim;
let total_bytes = total_elements * std::mem::size_of::<f16>();
let layout = Layout::from_size_align(total_bytes, 128)
.map_err(|e| format!("内存布局计算失败: {}", e))?;
// 128 字节对齐,满足 SIMD 访存要求
let ptr = unsafe {
let p = alloc(layout);
if p.is_null() {
return Err("KV Cache 内存分配失败".to_string());
}
// 初始化为零
std::ptr::write_bytes(p, 0, total_bytes);
NonNull::new_unchecked(p as *mut f16)
};
Ok(Self {
ptr,
layout,
num_layers,
num_heads,
head_dim,
max_seq_len,
current_seq_len: std::sync::atomic::AtomicUsize::new(0),
})
}
/// 获取 Key 缓存指针(指定层和位置)
#[inline]
pub fn key_ptr(
&self,
layer: usize,
pos: usize,
) -> *const f16 {
assert!(layer < self.num_layers);
assert!(pos < self.max_seq_len);
// 布局: [layer][0=Key][pos][head][dim]
let stride_layer = 2 * self.max_seq_len * self.num_heads * self.head_dim;
let stride_kv = self.max_seq_len * self.num_heads * self.head_dim;
let stride_pos = self.num_heads * self.head_dim;
let stride_head = self.head_dim;
let offset = layer * stride_layer
+ 0 * stride_kv // Key
+ pos * stride_pos;
unsafe { self.ptr.as_ptr().add(offset) }
}
/// 获取 Value 缓存指针
#[inline]
pub fn value_ptr(
&self,
layer: usize,
pos: usize,
) -> *const f16 {
let stride_layer = 2 * self.max_seq_len * self.num_heads * self.head_dim;
let stride_kv = self.max_seq_len * self.num_heads * self.head_dim;
let stride_pos = self.num_heads * self.head_dim;
let offset = layer * stride_layer
+ 1 * stride_kv // Value
+ pos * stride_pos;
unsafe { self.ptr.as_ptr().add(offset) }
}
/// 写入 KV Cache(单 token)
#[inline]
pub fn write_kv(
&self,
layer: usize,
pos: usize,
key: &[f16], // [num_heads * head_dim]
value: &[f16],
) {
let key_dst = self.key_ptr(layer, pos) as *mut f16;
let val_dst = self.value_ptr(layer, pos) as *mut f16;
let element_count = self.num_heads * self.head_dim;
unsafe {
std::ptr::copy_nonoverlapping(key.as_ptr(), key_dst, element_count);
std::ptr::copy_nonoverlapping(value.as_ptr(), val_dst, element_count);
}
}
/// 获取当前序列长度
pub fn seq_len(&self) -> usize {
self.current_seq_len.load(std::sync::atomic::Ordering::Acquire)
}
/// 增加序列长度(生成新 token 后调用)
pub fn advance(&self) {
self.current_seq_len.fetch_add(1, std::sync::atomic::Ordering::Release);
}
/// 重置缓存(新序列开始时调用)
pub fn reset(&self) {
self.current_seq_len.store(0, std::sync::atomic::Ordering::Release);
}
/// 计算内存占用
pub fn memory_bytes(&self) -> usize {
self.layout.size()
}
}
impl Drop for KVCache {
fn drop(&mut self) {
unsafe {
dealloc(self.ptr.as_ptr() as *mut u8, self.layout);
}
}
}
// 确保 KV Cache 可以在线程间安全共享
unsafe impl Send for KVCache {}
unsafe impl Sync for KVCache {}3.2 算子融合:RMSNorm + QKV 投影
rust
/// 融合算子:RMSNorm + QKV 投影
/// 将两个独立 kernel 合并为一个,减少一次全局内存读写
pub fn fused_rmsnorm_qkv_projection(
// 输入: 隐藏状态 [hidden_dim]
hidden: &[f16],
// RMSNorm 权重
norm_weight: &[f16],
// QKV 投影权重 [3 * hidden_dim, hidden_dim]
qkv_weight: &[f16],
// QKV 偏置
qkv_bias: Option<&[f16]>,
// 输出: Q, K, V 各 [hidden_dim]
q_out: &mut [f16],
k_out: &mut [f16],
v_out: &mut [f16],
// RMSNorm epsilon
epsilon: f32,
hidden_dim: usize,
) {
// Step 1: RMSNorm(在寄存器中完成,不写回全局内存)
let mut normed = vec![0.0f32; hidden_dim];
// 计算平方和
let mut sum_sq = 0.0f32;
for i in 0..hidden_dim {
let val = f16_to_f32(hidden[i]);
sum_sq += val * val;
}
// 计算 RMS
let rms = (sum_sq / hidden_dim as f32 + epsilon).sqrt();
let inv_rms = 1.0 / rms;
// 归一化并应用权重
for i in 0..hidden_dim {
let val = f16_to_f32(hidden[i]);
let weight = f16_to_f32(norm_weight[i]);
normed[i] = val * inv_rms * weight;
}
// Step 2: QKV 投影(直接使用 normed 结果,无需从全局内存读取)
let proj_dim = hidden_dim; // Q/K/V 各 hidden_dim 维
for i in 0..proj_dim {
let mut q_val = qkv_bias.map_or(0.0f32, |b| f16_to_f32(b[i]));
let mut k_val = qkv_bias.map_or(0.0f32, |b| f16_to_f32(b[proj_dim + i]));
let mut v_val = qkv_bias.map_or(0.0f32, |b| f16_to_f32(b[2 * proj_dim + i]));
// 矩阵乘法:Q = W_q * normed, K = W_k * normed, V = W_v * normed
for j in 0..hidden_dim {
let input = normed[j];
let w_q = f16_to_f32(qkv_weight[i * hidden_dim + j]);
let w_k = f16_to_f32(qkv_weight[(proj_dim + i) * hidden_dim + j]);
let w_v = f16_to_f32(qkv_weight[(2 * proj_dim + i) * hidden_dim + j]);
q_val += w_q * input;
k_val += w_k * input;
v_val += w_v * input;
}
q_out[i] = f32_to_f16(q_val);
k_out[i] = f32_to_f16(k_val);
v_out[i] = f32_to_f16(v_val);
}
}
/// f16 <-> f32 转换工具
fn f16_to_f32(val: f16) -> f32 {
// 简化实现,生产环境应使用 half crate
f32::from_bits(((val.0 as u32) << 16) as u32)
}
fn f32_to_f16(val: f32) -> f16 {
// 简化实现
let bits = val.to_bits();
f16((bits >> 16) as u16)
}3.3 批量推理调度器
rust
use std::sync::Arc;
use std::collections::VecDeque;
/// 推理请求
pub struct InferRequest {
pub token_ids: Vec<u32>,
pub max_tokens: usize,
pub temperature: f32,
pub top_p: f32,
}
/// 推理响应
pub struct InferResponse {
pub token_id: u32,
pub finished: bool,
}
/// 连续批处理调度器
/// 核心优化:将多个请求的 prefill 阶段合并为一次批量 GEMM
pub struct ContinuousBatchScheduler {
kv_cache: Arc<KVCache>,
pending_queue: VecDeque<InferRequest>,
active_requests: Vec<ActiveRequest>,
max_batch_size: usize,
}
struct ActiveRequest {
request: InferRequest,
generated_tokens: usize,
current_pos: usize,
}
impl ContinuousBatchScheduler {
pub fn new(kv_cache: Arc<KVCache>, max_batch_size: usize) -> Self {
Self {
kv_cache,
pending_queue: VecDeque::new(),
active_requests: Vec::new(),
max_batch_size,
}
}
/// 提交推理请求
pub fn submit(&mut self, request: InferRequest) {
self.pending_queue.push_back(request);
}
/// 执行一步推理(处理一个 batch)
pub fn step(&mut self) -> Vec<(usize, InferResponse)> {
let mut results = Vec::new();
// 从等待队列中补充请求到活跃批次
while self.active_requests.len() < self.max_batch_size {
if let Some(req) = self.pending_queue.pop_front() {
self.active_requests.push(ActiveRequest {
request: req,
generated_tokens: 0,
current_pos: 0,
});
} else {
break;
}
}
if self.active_requests.is_empty() {
return results;
}
// 对活跃请求执行推理
// 实际实现中,这里会调用 GPU kernel
let mut completed_indices = Vec::new();
for (idx, active) in self.active_requests.iter_mut().enumerate() {
// 模拟生成一个 token
active.generated_tokens += 1;
active.current_pos += 1;
let finished = active.generated_tokens >= active.request.max_tokens;
results.push((idx, InferResponse {
token_id: 0, // 实际由模型输出
finished,
}));
if finished {
completed_indices.push(idx);
}
}
// 移除已完成的请求(从后向前,避免索引偏移)
for &idx in completed_indices.iter().rev() {
self.active_requests.remove(idx);
}
results
}
}四、推理优化中的精度与性能权衡
4.1 量化精度对生成质量的影响
INT4 量化(GGUF 的 Q4_K_M)将 7B 模型从 14GB 压缩到 4GB,但困惑度(perplexity)从 5.68 上升到 6.12。对于聊天场景,这种精度损失通常可以接受。然而,在代码生成、数学推理等对精度敏感的任务中,INT4 的错误率明显上升------例如变量名拼写错误、逻辑条件遗漏或数学计算偏差。
GGUF 格式提供了多种量化等级:Q8_0(8 位,几乎无损)、Q5_K_M(5 位混合,精度与体积平衡)、Q4_K_M(4 位混合,最小体积)。选择原则如下:显存充足时优先选择 Q8_0,显存紧张时选择 Q5_K_M,极端受限情况下选择 Q4_K_M。
4.2 连续批处理的调度开销
连续批处理(Continuous Batching)是提升吞吐量的关键技术,但调度本身存在开销。每个 step 需要检查哪些请求已完成、从队列中补充新请求、更新 KV Cache 的序列长度。在 batch size 较大时(如 32),调度开销可能占 step 时间的 5%-10%。
更严重的问题是 KV Cache 碎片。不同请求的序列长度不同,已完成请求释放的 KV Cache 空间可能不连续,新请求无法直接利用。llama.cpp 通过 slot 机制管理 KV Cache,每个 slot 固定大小,但 slot 过大浪费空间,过小则限制最大序列长度。
4.3 适用与禁用场景
适用场景:消费级 GPU 上的本地推理、多用户共享推理服务、需要低延迟的对话场景。
禁用场景:需要 float32 精度的科学计算、训练场景(推理优化不适用于训练)、超长上下文(KV Cache 显存占用随序列长度线性增长,超过 32K 上下文需要特殊优化)。
五、总结
llama.cpp 推理优化的核心在于减少全局内存访问和提升计算密度。算子融合通过在寄存器中传递中间结果,避免了不必要的全局内存读写。KV Cache 的内存布局影响注意力计算的访存效率,连续的序列维度是批量 GEMM 友好的关键。量化是显存与精度的权衡,Q5_K_M 是大多数场景的最优选择。连续批处理是提升吞吐的必要手段,但调度开销和 KV Cache 碎片是需要持续优化的工程问题。推理优化没有终点------每个硬件平台的最优配置不同,需要针对具体 GPU 型号和模型结构反复调优。