在上一篇文章中,我们建立了AI的整体认知框架:AI → 机器学习 → 深度学习 → 大语言模型。这篇文章,我们聚焦到最内层的"大语言模型",搞清楚它到底是怎么工作的,以及你每天用的ChatGPT、Claude和它是什么关系。
大模型是什么
想象一个读过全人类书籍的超级学者。你问他任何问题,他都能根据自己读过的内容给你一个回答。他不是在"思考",而是在根据海量的阅读经验,预测出最合理的回答。
这就是大语言模型(Large Language Model,简称LLM)的运作方式。
从技术层面来说,大语言模型是一个基于海量文本数据训练的超大型神经网络。"大"体现在三个方面:训练数据大(读遍互联网上的网页、书籍、文章)、模型参数大(通常在数十亿到数千亿级别)、计算资源需求大(训练一个模型可能需要上万张显卡运行数月)。
你不需要记住这些数字,只需要理解一个核心概念:大模型是通过"阅读"海量文本,学会了人类语言规律的AI系统。
你用的AI工具,不等于大模型
很多人会把"ChatGPT"和"大语言模型"混为一谈,其实它们是不同的东西。
**大语言模型(LLM)**是"大脑"------它只会做一件事:根据你给的文本,预测下一个最可能出现的词。它没有记忆,没有界面,不能联网,不能读文件。
ChatGPT、Claude.ai、Kimi这些产品,是"大脑 + 外壳"------它们在LLM的基础上,加了很多能力:
- 对话记忆:记住你之前说了什么
- 文件处理:能读取你上传的文档和图片
- 联网搜索:能获取最新信息
- 用户界面:给你一个好看的聊天窗口
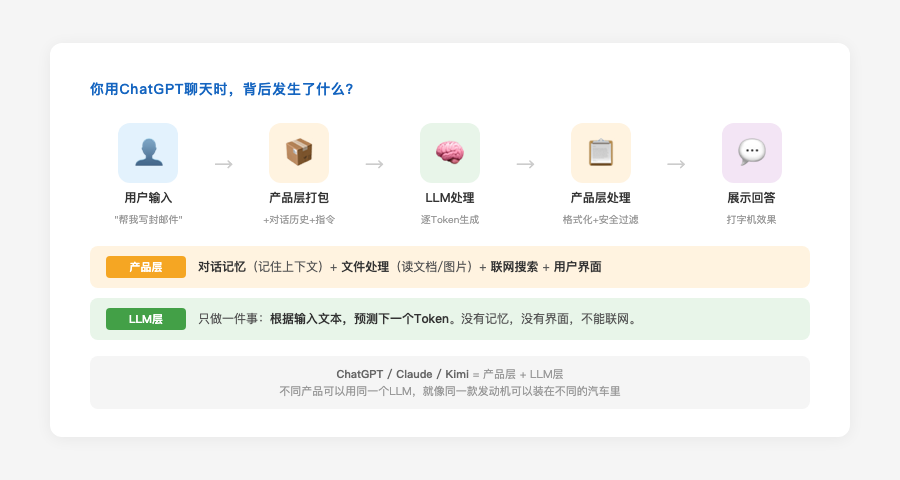
所以当你打开ChatGPT聊天时,背后发生的事情是这样的:
- 你输入一段话
- 产品层把你的新问题 + 之前的对话历史打包,发给LLM
- LLM一个词一个词地生成回答
- 产品层把回答以"打字机效果"展示给你
同一个LLM可以被不同的产品使用。就像同一款发动机可以装在不同的汽车里------外观、功能、体验都不同,但核心动力来源是同一个。
几个关键术语
理解大模型,你只需要掌握几个核心概念。
Token:AI理解的"词"
AI并不像人类一样一个字一个字地阅读,它把文本切成更小的片段,叫做Token。

简单来说,一个Token大约是一个词或半个词。比如"我喜欢喝咖啡"这句话,可能被切成"我"/"喜欢"/"喝"/"咖啡"四个Token。
为什么你要知道这个概念?因为两个原因:
第一,上下文窗口 (下面会讲)的大小是用Token来衡量的,不是用字数。第二,如果你以后用到API,计费也是按Token算的------你输入和输出的Token越多,费用越高。
上下文窗口:AI的"短期记忆"
每次你跟AI对话,它能"记住"的内容是有限的,这个上限叫做上下文窗口。
打个比方:AI的上下文窗口就像一个人的短期记忆容量。如果记忆容量是8万个Token(大约6万字),那它能记住你最近大约6万字的对话内容。超过这个量,它就会"忘记"最早的内容。
这也是为什么有时候你聊了很久之后,AI好像"忘了"你之前说过的话------不是它出故障了,而是对话太长,超出了它的上下文窗口。
不同的模型上下文窗口大小不同,从几千到几十万个Token都有。目前Claude的上下文窗口可以达到20万个Token,在长文档处理方面有明显优势。
推理:AI"思考"的过程
当你向AI提问,它生成回答的过程叫做推理(Inference)。
虽然我们习惯说AI在"思考",但技术上它做的事情和文章1里讲的一样:预测下一个Token。只不过它预测得非常快,每秒能生成几十个Token,所以看起来像是在实时思考。
训练、推理和API:三个不同的阶段
理解大模型,还需要分清三个概念。

训练就像上学------模型阅读海量文本,学习语言规律。这个过程非常昂贵,通常需要数月时间和数百万美元。训练完成后的成果叫做"模型权重",可以理解成AI"学到的知识"。
推理就像考试------模型根据学到的知识,回答你的问题。你在ChatGPT里每次发消息触发的就是推理。推理速度快(秒级),成本相对较低。
API则是另一种使用方式------开发者通过程序接口调用大模型的能力,把AI嵌入到自己的产品中。
打个比方:LLM是一台发动机。训练是制造发动机的过程,推理是启动发动机运行,API则是把发动机装到不同机器上的接口。
当你直接使用ChatGPT网页版时,相当于"坐出租车"------产品已经帮你把一切都包装好了。当开发者通过API调用LLM时,相当于"自己造车装发动机"------更灵活,但需要懂技术。
你用的很多AI应用------智能客服、AI写作助手、Dify搭建的问答系统------背后都是通过API调用某个大模型。
主流模型简介
市面上有大大小小几十个大模型,但对于普通用户来说,你只需要了解几个主要的:
Claude系列(Anthropic)
编程能力突出,长文本理解强,适合处理复杂任务。比如Claude Code就是基于Claude模型的AI编程工具,能直接帮你写代码、改bug。
需要注意的是:Claude在国内无法直接使用,需要通过特殊网络或API代理访问。
GPT系列(OpenAI)
生态最成熟的模型系列。GPT-5支持多模态(能看图、听语音、说语音),插件生态丰富。ChatGPT是OpenAI基于GPT模型推出的产品,目前用户量最大。
同样的问题:国内无法直接使用。
Llama系列(Meta)
和上面两家不同,Llama是开源的------任何人都可以免费下载,部署到自己的服务器上。对企业来说,这意味着数据不用离开公司,安全性更高。但需要技术团队来部署和维护。
国内模型
文心一言(百度)、通义千问(阿里)、Kimi(月之暗面)、DeepSeek等------这些模型的优势是国内直接可用,不需要特殊网络,中文理解能力强。但在复杂任务(如编程、长文本分析)上,与国际顶尖模型仍有差距。
怎么选?
没有万能的"最好模型",只有最适合你场景的模型。 选模型主要看三个维度:
- 能不能用:网络是否可访问、是否符合公司合规要求
- 好不好用:能力是否匹配你的需求(编程选Claude,通用选GPT,中文选国内模型)
- 贵不贵:API调用量大时,成本差异会很明显
大模型能做什么,不能做什么
能做的:文本生成、翻译、摘要提取、问答对话、代码编写、文档分析------基本上所有和"语言处理"相关的事情。
不能做的:获取实时信息(除非产品层加了联网搜索)、与物理世界交互(它不能帮你开门、做饭)、保证100%正确(它有时候会"自信地胡说八道",这个我们后面会专门讲)。
下一步
现在你已经理解了大模型是什么、怎么工作的,以及主流模型的选择逻辑。在下一篇文章中,我们会从"模型"上升到"应用"------看看Prompt、RAG、Agent这些概念是什么,以及它们如何把大模型变成真正实用的工具。
延伸阅读 :文章1:AI入门------一张地图看懂AI世界 | 文章3:AI应用实战------从Prompt到Agent