【EPGF 白皮书】路径治理驱动的多版本 Python 架构------ Windows 环境治理与 AI 教学开发体系
【EPGF 实战】告别依赖地狱:基于四级隔离架构的 stable-diffusion.cpp 极速编译与本地部署实战指南
0️⃣ 导言:AI 部署的痛点与 EPGF 破局
在 AI 绘画全面爆发的今天,无论是 Stable Diffusion WebUI 还是 ComfyUI,庞大的 Python 依赖池、极易冲突的 xformers 环境,以及动辄几十 GB 的磁盘占用,常常让开发者在部署时心力交瘁。特别是对于 Windows 系统,C++ 编译工具链(如 MSBuild)的环境变量污染更是"灾难级"的痛点。
难道在 Windows 上本地跑图,就必定要忍受这种"依赖地狱"吗?
本文将基于 EPGF(Engineering Python Governance Framework)架构 的理念,带你暂时抛弃臃肿的 PyTorch 生态,拥抱纯 C/C++ 的超轻量级推理引擎 ------ stable-diffusion.cpp 。我们将通过"四级隔离"机制,结合 GitHub Desktop + PyCharm 的全图形化工作流,打造一个零系统污染、极低资源占用且性能拉满的本地 AI 绘画服务器。
1️⃣ 架构映射:EPGF 在 C++ 编译部署中的应用
在编译 stable-diffusion.cpp 这类底层硬件加速(CUDA)项目时,我们将 EPGF 的核心理念进行如下映射:
| EPGF 理念 | 本次实战落地策略 | 解决的痛点 |
|---|---|---|
| 第一、二级隔离 (系统与版本隔离) | 依托 D:\A\envs\py312 提供纯净的 Python 基座,绝不在系统直接安装构建工具。 |
避免 CMake、Ninja 等工具污染 Windows 全局 PATH。 |
| 第三、四级隔离 (工具链与项目自包含) | 采用 python -m venv --copies .venv 进行硬拷贝物理隔离,在项目内独立安装 Ninja 构建工具。 |
彻底规避 Conda 环境对 C++ 编译路径的幽灵干扰。 |
| 五项自治 (迁移与运行自治) | 项目文件夹即交付单元,编译产出 sd-server.exe,直接脱离 Python 依赖运行。 |
拷贝到任何同架构机器,双击即可直接拉起带 WebUI 的 AI 画室。 |
2️⃣ 战术实施:四级隔离下的环境构建
2.1 获取项目代码(进入工作区)
告别繁琐的命令行拉取,我们直接用图形化工具保持路径整洁:
-
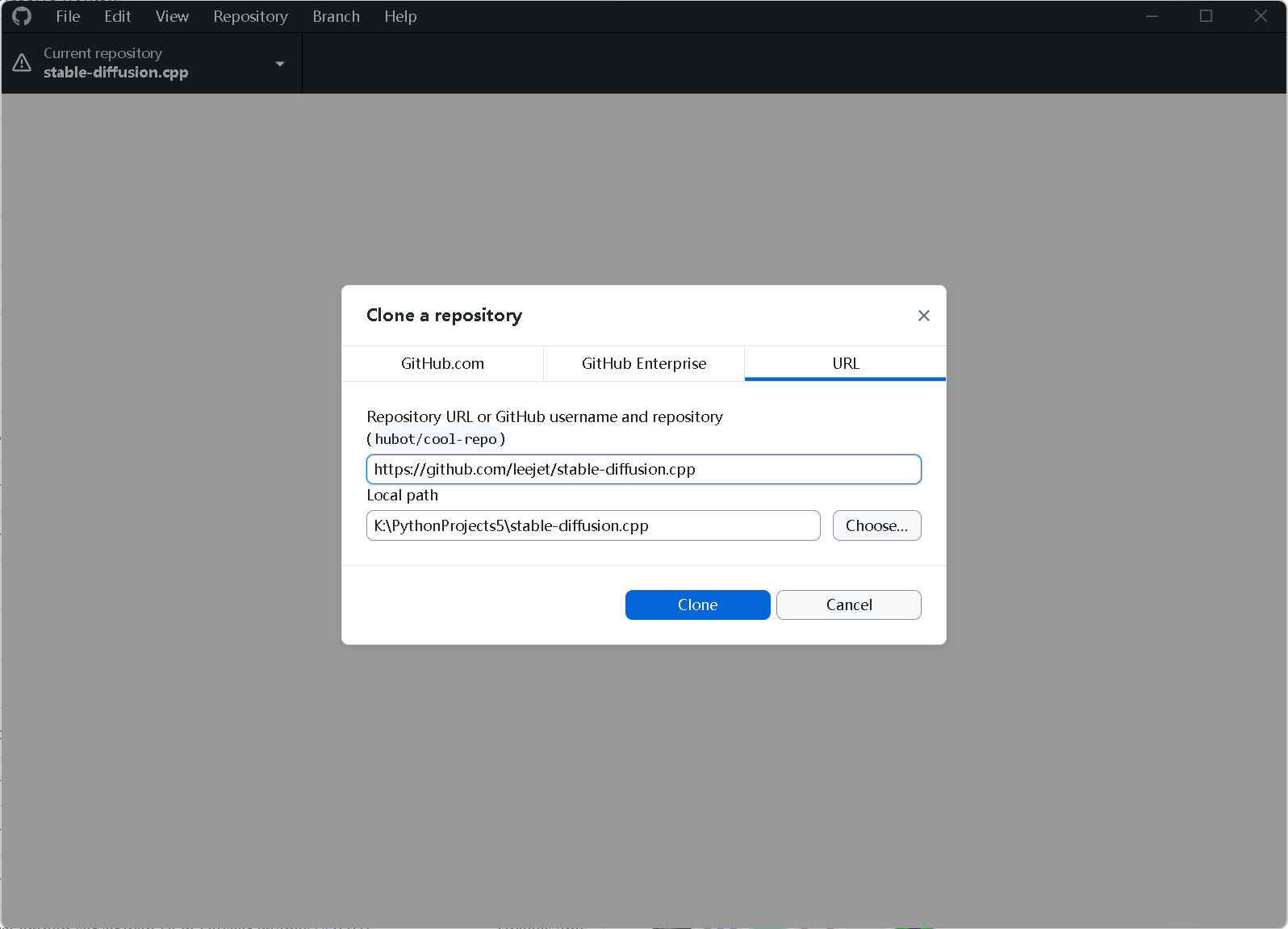
访问官方仓库
leejet/stable-diffusion.cpp。 -
点击绿色的 Code 按钮,选择 "Open with GitHub Desktop"。
-
将项目克隆至统一管理路径(⚠️ 警告:全路径必须为纯英文,不可包含中文! 例如
K:\PythonProjects\stable-diffusion.cpp)。 -
在 GitHub Desktop 中直接点击 "Open in PyCharm",让 IDE 接管项目。
2.2 构建第四级隔离(硬拷贝虚拟环境)
在 PyCharm 底部打开 Terminal 终端,此时我们处于项目的根目录。为了防止 C++ 编译器嗅探到错误的全局环境变量,我们必须执行 EPGF 标准的"硬拷贝隔离大法":
DOS
# 1. 借助 Conda 激活底层版本环境(以 py312 为例)
conda activate py312
# 2. 核心操作:硬拷贝一个纯净的 venv 虚拟环境,拒绝软链接带来的路径溯源报错
python -m venv --copies .venv
# 3. 卸磨杀驴,退出 Conda 环境,彻底斩断与全局环境变量的联系
conda deactivate
# 4. 激活项目本地的、完全独立且纯净的虚拟环境
.venv\Scripts\activate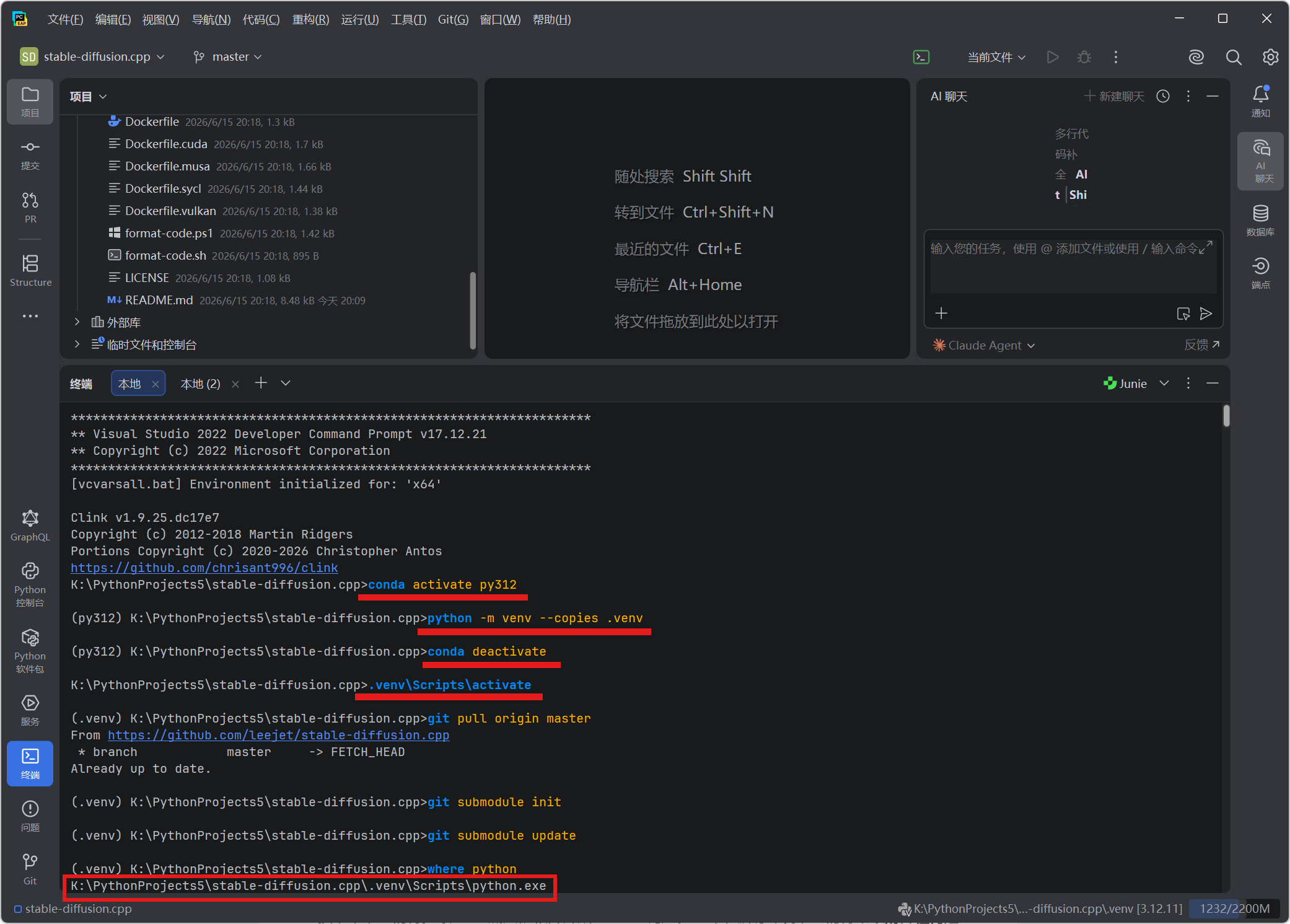
✨ IDE 魔法触发:
此时,PyCharm 会在右下角弹窗提示:"检测到新的虚拟环境 .venv" 。点击 "Set as Project Interpreter"。至此,环境实现了物理层面的绝对隔离,底座坚如磐石。
3️⃣ 核心编译:防御性构建与避坑指南
接下来,我们将拉取 C++ 底层依赖并开始 CMake 构建。此环节极易踩坑,我们将采取防御性构建策略。
3.1 补齐 Git 子模块
项目依赖了 ggml 等底层张量库。必须在项目根目录的终端中执行:
DOS
git submodule update --init --recursive
3.2 工具链本地化(安装 Ninja)
DOS
pip install ninja
💡 EPGF 工具治理理念:为什么要用 Ninja?
Windows 默认使用 Visual Studio 的 MSBuild 编译,但 MSBuild 对 CUDA 版本的嗅探极其"玄学",极易读取系统残留的旧版(如 13.2)配置导致路径报错。将 Ninja 隔离安装在
.venv中,不仅能完美绕过 VS 的恶心机制,还能大幅提升多核编译速度!
3.3 编译配置与 /bigobj 错误阻击
新建构建目录并进入:
DOS
mkdir build && cd build
这是决定成败的一行配置命令,请完整执行(请将 nvcc.exe 路径替换为你本机的真实 CUDA 路径):
DOS
cmake .. -G "Ninja" -DSD_CUDA=ON -DCMAKE_CUDA_COMPILER="C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v13.1/bin/nvcc.exe" -DCMAKE_BUILD_TYPE=Release🔥 核心避坑:C1128 错误
很多新手走到 98% 进度时会爆出乱码报错:
fatal error C1128: 节数超过对象文件格式限制: 请使用 /bigobj 编译。根本原因:项目包含海量网络架构的硬编码,默认生成的 Debug 版对象文件体积撑爆了 MSVC 编译器的上限。
EPGF 解法 :严格追加
-DCMAKE_BUILD_TYPE=Release参数。剔除冗余信息,不仅体积达标,最终的生图推理速度也会获得质的飞跃。
3.4 极速编译起飞
DOS
cmake --build . --config Release在 Ninja 的并发加持下,静待进度条跑到 [352/352] Linking CXX executable bin\sd-server.exe。
此时,你的专属纯 C++ 极速 AI 引擎已成功诞生!
验证生成产物
dir bin\*.exe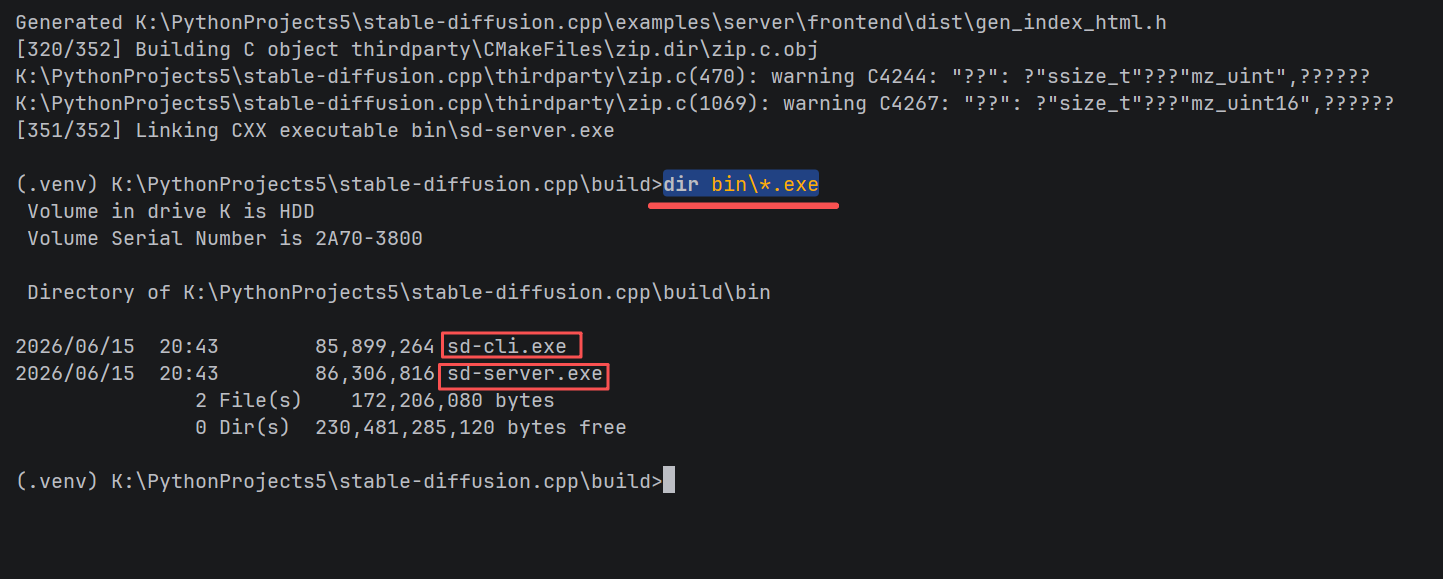
4️⃣ 价值交付:模型部署与五项自治体验
编译完成后,我们已彻底摆脱了复杂的 Python 依赖,进入了清爽的项目自治 与运行自治阶段。
4.1 模型准备(命令行直拉)
退回根目录并新建 models 文件夹:
DOS
cd ..
mkdir models && cd models
直接使用系统 curl 拉取经典的 SD v1.5 模型(约 4GB)进行初测:
DOS
curl -L -O https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned-emaonly.safetensors
4.2 启动 Web UI(原生 Flash Attention 降维打击)
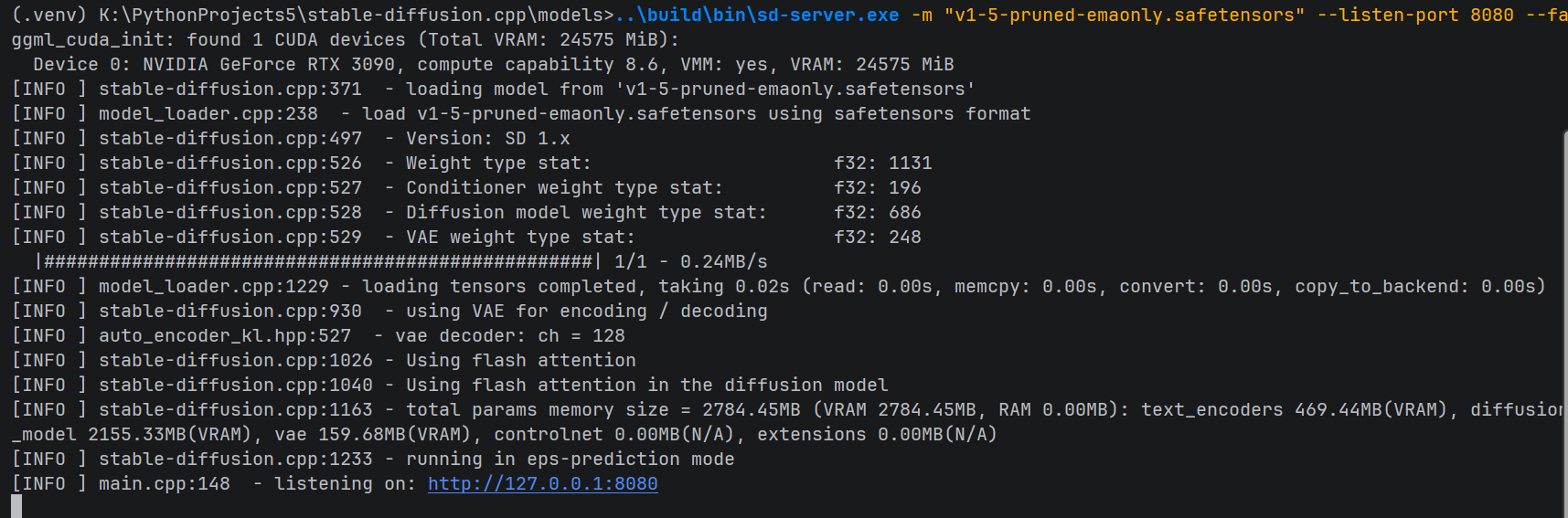
在 models 目录下,直接拉起刚才编译出的服务端:
DOS
..\build\bin\sd-server.exe -m "v1-5-pruned-emaonly.safetensors" --port 8080 --flash-attn🚀 架构亮点揭秘:
在臃肿的 PyTorch 生态中,配置 Flash Attention 往往伴随着痛苦的 pip 编译报错。而在
stable-diffusion.cpp里,C++ 底层已原生硬编码实现了 Flash Attention! 仅需追加--flash-attn参数,即可直接压榨 RTX 3090 的极限算力,显存占用断崖式下降,出图速度飙升,堪称降维打击!
当控制台打印出 Server listening on 127.0.0.1:8080 时,打开浏览器访问 http://127.0.0.1:8080。一个极简、丝滑、纯本地、毫无依赖负担的 AI 画室正式呈现在你面前。
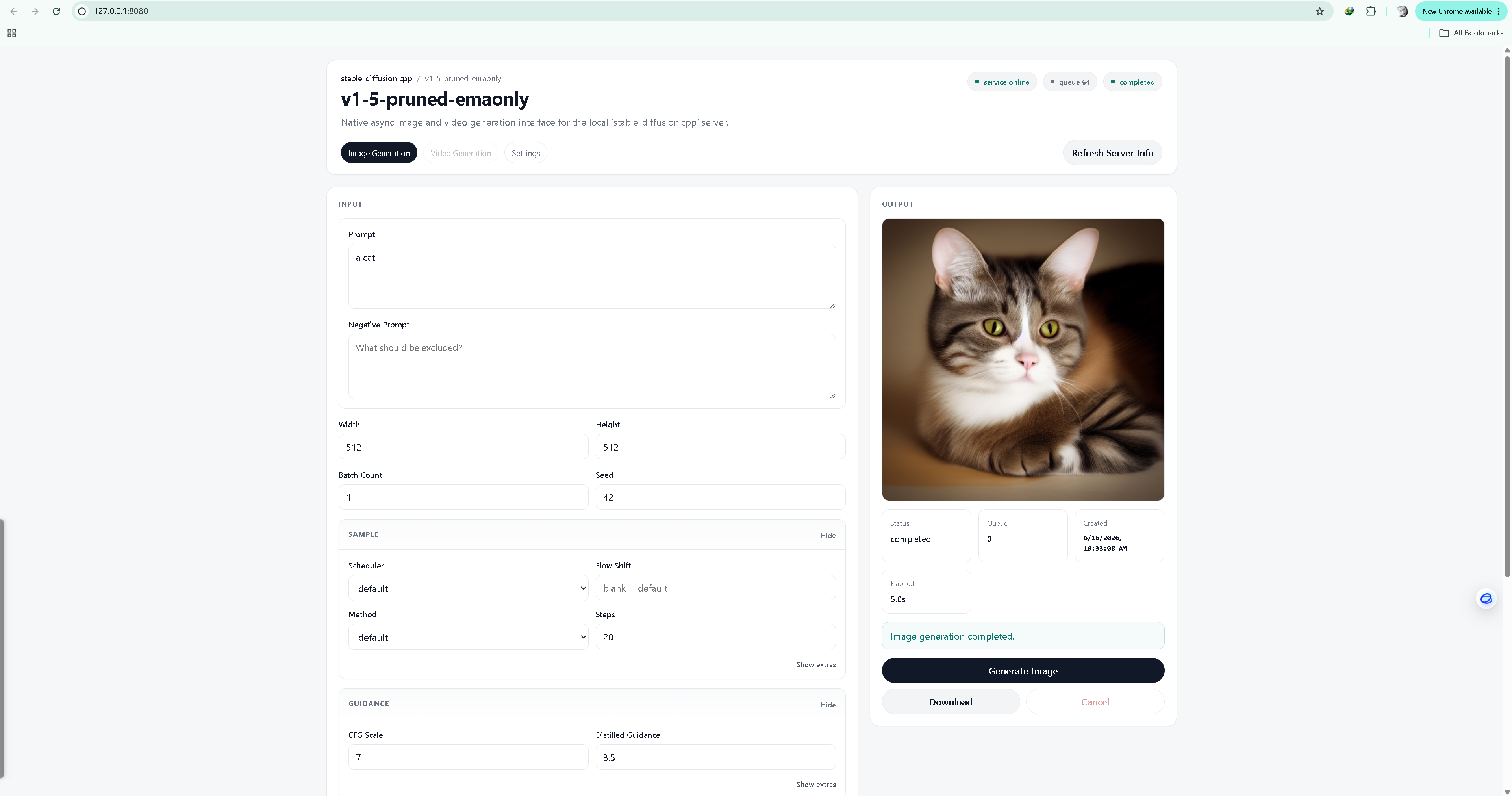
✅ 总结
通过引入 EPGF 架构的四级隔离理念,我们将原本危机四伏的 Windows C++ / CUDA 编译过程,转变成了标准化、可控、可复现的流水线工程。
利用 venv --copies 的硬隔离加上 Ninja 的精准构建,我们彻底告别了"依赖地狱"。目前,stable-diffusion.cpp 已经支持 FLUX.1、SD3.5、Qwen-Image 甚至最新的 Wan2.1 视频大模型。赶快用这套标准化的工程范式,去探索超轻量级 AI 推理的新大陆吧!