跟着论文学习从图纸到决策:用于将2D工程图纸解析为结构化制造知识的混合视觉-语言框架
一、论文基本信息
- 英文标题: From Drawings to Decisions: A Hybrid Vision-Language Framework for Parsing 2D Engineering Drawings into Structured Manufacturing Knowledge
- 中文标题: 从图纸到决策:用于将2D工程图纸解析为结构化制造知识的混合视觉-语言框架
- 作者: Muhammad Tayyab Khan, Lequn Chen, Zane Yong, Jun Ming Tan, Wenhe Feng, Seung Ki Moon
- 机构 :
- 新加坡制造技术研究院 (SIMTech), A*STAR
- 先进再制造技术中心 (ARTC), A*STAR
- 南洋理工大学机械与航空航天工程学院
- 页数: 48页
- arXiv编号: 2506.17374v2
二、研究背景与问题陈述
2.1 研究背景
- 工程图纸的重要性: 工程图纸是制造业的基础,传达几何尺寸、公差、表面处理和标注等关键信息
- 现状问题 :
- 人工解释图纸耗时费力(如ballooning过程)
- 半自动化工具(如AutoCAD ballooning、Mitutoyo MeasurLink)仍依赖大量人工输入
- 通用OCR模型在复杂布局、工程符号、旋转文本等场景下表现不佳
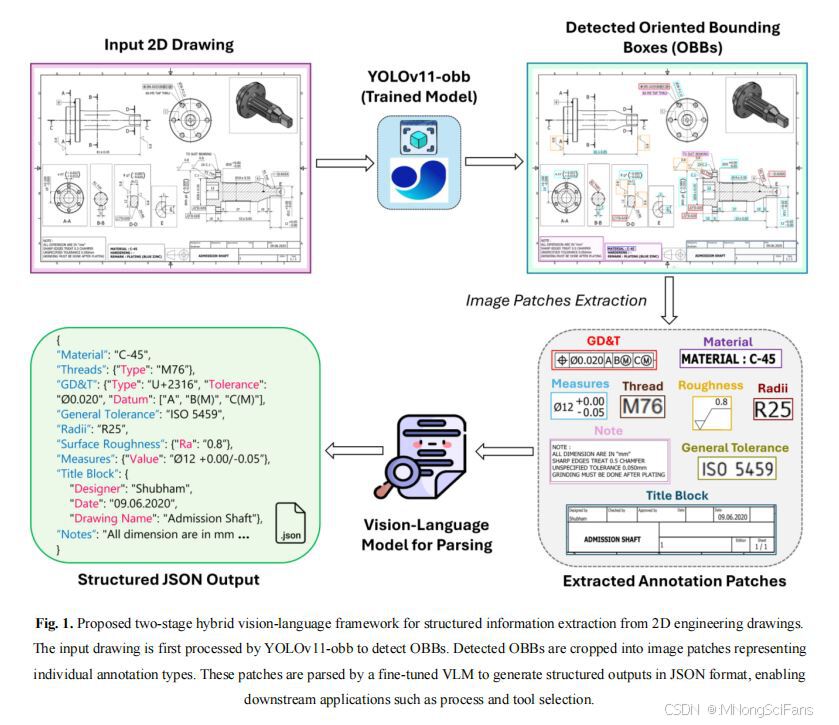
2.2 核心问题
- 定位挑战: 准确本地化多样化的标注类型,处理布局、方向和尺度变化
- 解析挑战: 解析标注需要针对工程文档的视觉和符号约定进行微调的模型
- 结构化输出: 将非结构化标注转换为机器可读的结构化格式
三、方法论
3.1 总体框架(两阶段混合架构)
输入图纸 → Stage 1: YOLOv11-obb检测 → OBB图像块 → Stage 2: VLM解析 → 结构化JSON输出3.2 数据集构建
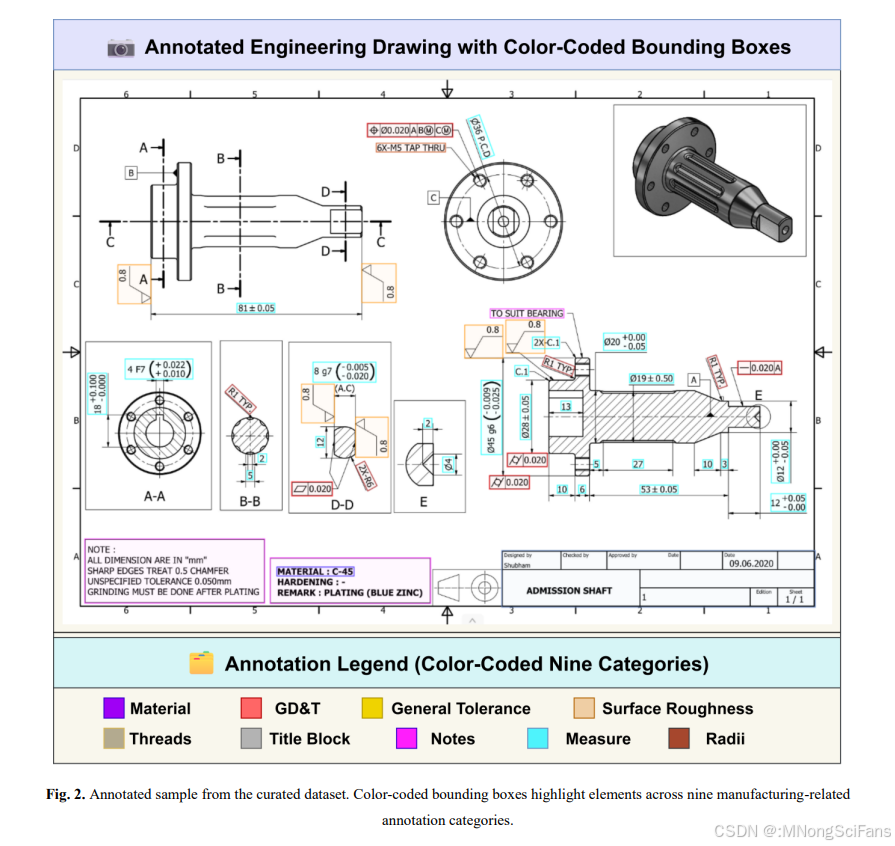
3.2.1 数据来源
- 数量: 1,367张2D机械图纸
- 来源: 公共数据集、标准文档、开源CAD存储库
- 领域: 航空航天、汽车、通用机械工程
- 格式 : 从CAD导出文件到扫描旧蓝图,涵盖多种图纸条件

3.2.2 标注类别(9类)
| 类别 | 说明 | 示例 |
|---|---|---|
| GD&T | 几何尺寸与公差 | 位置度、平面度、圆柱度等 |
| General Tolerances | 默认公差值 | 通用公差注释或表格 |
| Measures | 线性/角度尺寸标注 | 直径、长度、宽度等 |
| Material | 材料类型或处理 | 材料规格文本指示器 |
| Notes | 通用说明或补充设计细节 | 自由文本注释 |
| Radii | 半径尺寸指示器 | 半径标注 |
| Surface Roughness | 表面粗糙度符号 | 纹理要求符号 |
| Threads | 螺纹特征标注 | 螺纹规格 |
| Title Block | 图纸元数据 | 标题栏(通常位于右下角) |
3.2.3 数据增强策略
针对少数类别(Threads、Material、Surface Roughness等)采用5种增强技术:
- 锐度变化: 模拟模糊或过锐化扫描
- 对比度调整: 模拟过曝或褪色打印条件
- 旋转: 随机0°、90°、180°、270°方向偏移
- 灰度转换: 将彩色/多色调转换为单色
- 颜色反转: 反转黑白像素模拟底片扫描
3.3 Stage 1: YOLOv11-obb检测
3.3.1 模型选择理由
- 旋转感知: 支持有向边界框(OBB),适合处理倾斜尺寸、扭曲GD&T符号
- 单阶段架构: 相比两阶段检测器(Oriented R-CNN、ReDet),在准确性和效率间取得更优权衡
- 性能: DOTA-v1基准达到80.9 mAP,推理速度约10.1 ms (TensorRT)
3.3.2 训练配置
| 参数 | 值 |
|---|---|
| 模型 | Yolo11m-obb.pt |
| 图像尺寸 | 1024×1024像素 |
| 训练轮数 | 400 |
| 批次大小 | 16 |
| 预训练 | COCO权重 |
3.3.3 检测输出
- 在1,367张图纸上检测到11,469个标注实例
- 平均每张图纸产生8.4个标注块
- 评估指标:Precision、Recall、mAP@0.5、mAP@0.5-0.95均超过0.95
3.4 Stage 2: 视觉-语言模型微调
3.4.1 Donut模型
架构:
- 视觉编码器 : Swin Transformer Base (Swin-B)
- 4个Swin Transformer阶段,窗口大小10
- 输出1024维潜在视觉嵌入
- 文本解码器 : 预训练多语言BART模型
- 自回归生成结构化JSON输出
- 采用掩码多头自注意力、编码器-解码器交叉注意力
特点:
- 无OCR: 直接 from 图像 to 结构化文本,不依赖通用OCR
- 参数: 约1.43亿参数
- 训练: 端到端微调,交叉熵损失
两种微调策略:
- 统一模型: 单个Donut模型训练所有9个类别(本论文采用)
- 类别特定模型: 每个类别独立训练一个模型
3.4.2 Florence-2模型
架构:
- 视觉编码器 : DaViT (Dual Attention Vision Transformer)
- 嵌入维度: 128, 256, 512, 1024
- Transformer块配置: 1, 1, 9, 1
- 注意力头: 4, 8, 16, 32
- 多模态Transformer编码器-解码器 :
- 6层Transformer编码器(768维嵌入)
- 6层Transformer解码器
- 位置嵌入量化为1,000个离散区间
特点:
- 提示驱动: 通过自然语言提示条件化输出
- 参数: 约2.32亿参数
- OCR-free: 不依赖OCR模块或区域特定检测器
3.4.3 共享微调配置
| 参数 | 值 |
|---|---|
| 模型 | Donut-base & Florence-2-base |
| 优化器 | AdamW (余弦衰减) |
| 学习率 | 1e-6 |
| 批次大小 | 1 |
| 训练轮数 | 30 |
| 损失函数 | 交叉熵 |
3.5 GD&T符号标准化
为增强一致性并减少识别错误,14个常见GD&T符号使用标准化Unicode字符编码(符合ASME Y14.5):
| 名称 | 符号 | Unicode |
|---|---|---|
| 位置度 | ⌖ | U+2316 |
| 平面度 | ⏥ | U+23E5 |
| 圆度 | ○ | U+25CB |
| 圆柱度 | ⌭ | U+232D |
| 线轮廓度 | ⌒ | U+2312 |
| 面轮廓度 | ⌓ | U+2313 |
| 平行度 | ∥ | U+2225 |
| 垂直度 | ⟂ | U+27C2 |
| 直线度 | ⏤ | U+23E4 |
| 同轴度 | ◎ | U+25CE |
| 倾斜度 | ∠ | U+2220 |
| 对称度 | ⌯ | U+232F |
| 圆跳动 | ↗ | U+2197 |
| 全跳动 | ⌰ | U+2330 |
四、实验结果
4.1 YOLOv11-obb检测性能
定量结果:
- Precision: >0.95
- Recall: >0.95
- mAP@0.5: >0.95
- mAP@0.5-0.95: >0.95
混淆矩阵分析:
- 几乎所有类别的分类准确率接近1.0
- 少数类别(Material、Threads、General Tolerances)出现频率较低,但检测准确率仍保持高位
4.2 结构化解析性能
4.2.1 评估指标
- True Positive (TP): 预测键值对与真实值完全匹配
- False Positive (FP): 预测键值对错误或不存在于真实值中
- False Negative (FN): 真实值键值对缺失于预测中
计算公式:
Precision = TP / (TP + FP)
Recall = TP / (TP + FN)
F1-score = 2 × (Precision × Recall) / (Precision + Recall)
Hallucination Rate = 1 - Precision4.2.2 Donut vs Florence-2对比结果
| 类别 | Donut (Precision/Recall/F1/Hallucination) | Florence-2 (Precision/Recall/F1/Hallucination) |
|---|---|---|
| Measures | 0.896 / 0.992 / 0.941 / 0.104 | 0.76 / 0.873 / 0.813 / 0.24 |
| Title Block | 0.522 / 0.545 / 0.533 / 0.478 | 0.302 / 0.52 / 0.382 / 0.698 |
| GD&T | 0.933 / 1.0 / 0.965 / 0.067 | 0.838 / 0.995 / 0.91 / 0.162 |
| Notes | 0.681 / 1.0 / 0.81 / 0.319 | 0.655 / 1.0 / 0.791 / 0.345 |
| Material | 1.0 / 1.0 / 1.0 / 0.0 | 1.0 / 1.0 / 1.0 / 0.0 |
| Surface Roughness | 1.0 / 1.0 / 1.0 / 0.0 | 0.857 / 0.923 / 0.889 / 0.143 |
| Radii | 0.891 / 1.0 / 0.943 / 0.109 | 0.837 / 0.818 / 0.828 / 0.163 |
| Threads | 0.833 / 0.909 / 0.870 / 0.167 | 0.75 / 0.6 / 0.667 / 0.25 |
| General Tolerance | 0.5 / 1.0 / 0.667 / 0.5 | 0.5 / 1.0 / 0.667 / 0.5 |
| 总体 | 0.892 / 0.992 / 0.940 / 0.108 | 0.784 / 0.927 / 0.85 / 0.216 |
关键发现:
- Donut全面优于Florence-2 :
- F1-score: 94% vs 85%
- 幻觉率: 10.8% vs 21.6%
- 类别性能差异 :
- 高频且结构一致的类别(Measures、GD&T): 两模型均表现良好
- 符号约束类别(Surface Roughness、Radii): Donut达到完美或接近完美的F1分数
- 低视觉结构类别(Title Block、General Tolerances、Notes): 两模型均面临挑战
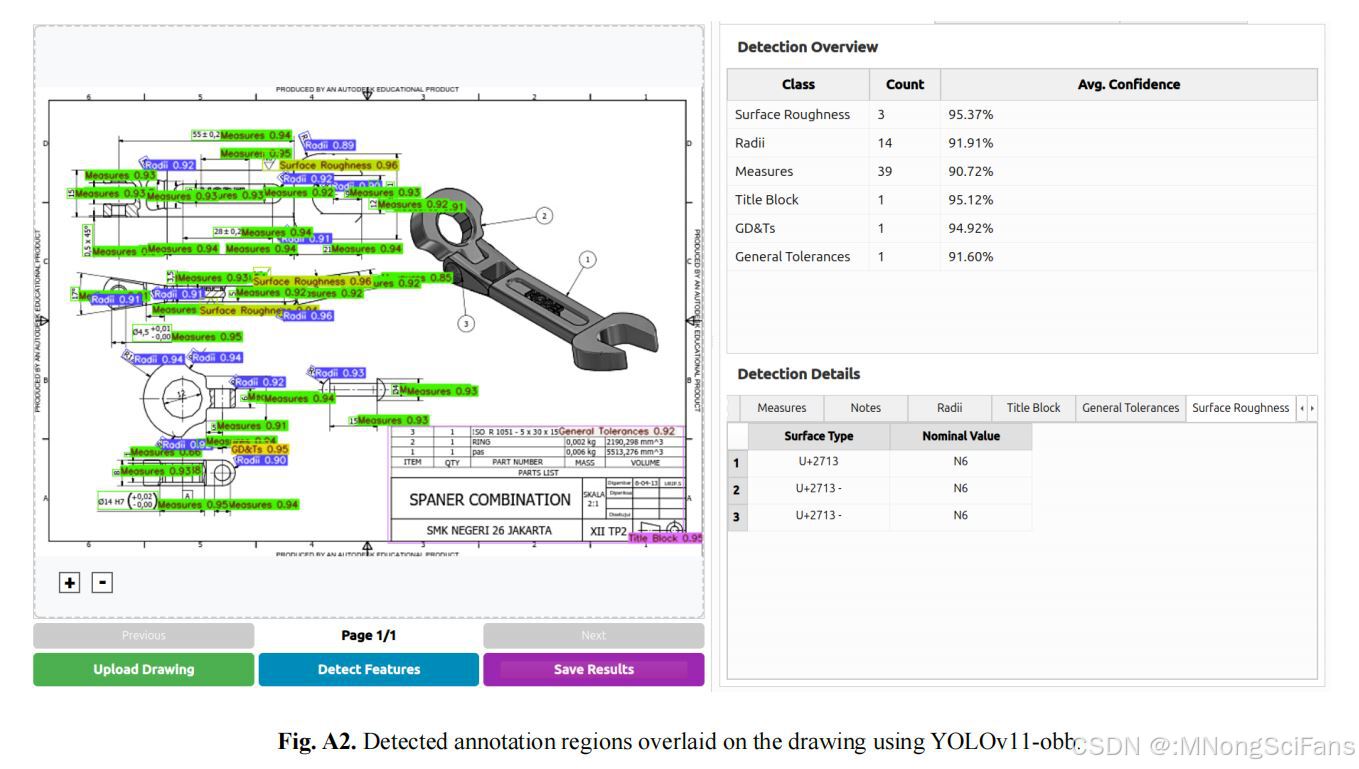
4.3 定性验证
GUI可视化界面:
- 上传2D图纸后实时查看标注叠加
- 按类别颜色编码,显示置信度分数
- 结构化表格界面展示解析字段
JSON输出示例:
json
{
"Material": "C-45",
"Threads": [{"Type": "6×M5 TAP THRU"}],
"GD&T": [
{"Type": "Position", "Tolerance": "Ø0.020", "Datums": ["A", "B(M)", "C(M)"]},
{"Type": "Straightness", "Tolerance": "0.020", "Datums": ["A"]},
{"Type": "Cylindricity", "Tolerance": "0.020", "Datums": []},
{"Type": "Flatness", "Tolerance": "0.020", "Datums": []}
],
"Surface Roughness": [{"Ra": "0.8 μm"}],
"Measures": [
{"Feature": "Shaft Length", "Value": "81 ±0.05 mm"},
{"Feature": "Diameter", "Value": "Ø28 ±0.05 mm"}
],
"Title Block": {
"Designer": "Shubham",
"Date": "09.06.2020",
"Drawing Name": "Admission Shaft"
},
"Notes": "All dimensions are in mm. Sharp edges treat 0.5 chamfer..."
}五、案例研究:基于规则的制造决策
5.1 解释前提条件
- 零件材料(含属性)已从图纸提取或外部提供
- 图纸遵循公认标准(如ASME Y14.5 for GD&T、ISO 21920 for 表面粗糙度)
- 所有相关标注已准确解析为结构化JSON
- 制造环境具有定义的工具和操作集合
5.2 基于规则的推理引擎
规则示例:
| 特征类型 | 条件 | 推荐操作 | 工具选择 |
|---|---|---|---|
| 螺纹孔 | 6×M5 TAP THRU, 材料: C-45钢 | 钻孔Ø4.2mm, 攻丝M5×0.8 | 麻花钻(Ø4.2mm, HSS); 螺旋槽丝锥(M5×0.8, HSS-E, TiN涂层) |
| 圆柱轴 | Ø28mm, 公差±0.05mm, Ra 0.8μm | 粗车, 精车 | 硬质合金刀片(粗加工); 精加工刀片(精加工) |
| 孔(紧公差) | 公差在ISO IT6-IT8范围内 | 钻孔+精加工(铰孔/镗孔) | 铰刀(H7级); 精密钻头 |
| 轴(超精加工) | Ra < 0.4μm 或紧直径公差 | 精车或磨削 | 精加工刀片; 砂轮 |
5.3 下游流程集成
- 操作排序: 基于特征类型和公差要求
- 加工参数选择: 查询工具数据库获取切削速度、进给量
- 检测规划: 根据GD&T要求生成检测计划
- 与MES集成: 支持制造执行系统集成
六、创新点
6.1 技术贡献
- 首个混合框架: 结合旋转感知检测与微调VLM用于工程图纸
- 无OCR流水线: Donut和Florence-2不依赖OCR,直接处理图像到结构化输出
- 有向边界框(OBB): 准确处理旋转和倾斜标注
- 结构化JSON输出: 机器可读格式,支持下游集成
6.2 数据集贡献
- 规模: 1,367张图纸,11,469个标注实例
- 类别覆盖: 9个制造业相关类别
- 质量保证: 由具有机械设计和制造背景的标注员标注,领域专家验证
6.3 性能贡献
- Donut优越性: 相比Florence-2,F1-score提高9%(94% vs 85%)
- 低幻觉率: Donut仅10.8%,适合工程应用
- 高召回率: Donut达到99.2%召回率,减少漏检
七、局限性与未来工作
7.1 局限性
- 数据集规模: 1,367张图纸仍有限,可能未完全捕捉真实工业图纸的多样性和复杂性
- 类别不平衡: 某些类别(如General Tolerances、Material)自然出现频率较低
- 理想假设: 案例研究假设理想条件和标准化工具,可能限制泛化能力
- 视图-标注关联: 当前框架未将标注与参考几何和视图关联
7.2 未来工作方向
- 数据集扩展 :
- 包含更多样化和复杂的工程图纸
- 改进对少数类别的表示
- 不平衡感知策略 :
- Focal loss
- 类别加权训练
- 高级重采样技术
- 工业规模验证 :
- 在CAD/CAM工作流中部署结构化输出
- 评估真实制造环境中的适用性
- 级联误差分析 :
- 系统研究检测质量如何影响下游语义提取
- 开发误差检测和纠正机制
- 实时制造反馈集成 :
- 开发自适应、上下文感知的决策模块
- 增强框架在不同生产环境中的鲁棒性
八、工业应用价值
8.1 直接应用场景
- 工艺规划: 从图纸自动提取特征信息,辅助工艺路线设计
- 工具选择: 基于特征类型、公差、材料推荐合适工具
- 检测规划: 根据GD&T要求生成检测计划
- 成本估算: 利用结构化信息进行快速报价
8.2 对QuoteApp的借鉴价值
可直接应用的技术:
- YOLOv11-obb :
- 用于检测图纸中的尺寸标注、GD&T符号、表面粗糙度符号
- 相比当前PaddleOCR方案,更适合处理旋转和倾斜文本
- Donut模型 :
- 无OCR的端到端解析,避免OCR错误传播
- 生成结构化JSON输出,与QuoteApp数据模型对齐
- OBB图像块提取 :
- 局部化解析策略,避免整图解析的性能下降
- 适合处理高密度标注图纸
集成建议:
- 替换当前OCR引擎: 用YOLOv11-obb + Donut替换PaddleOCR
- 增强特征提取: 利用GD&T解析能力,支持形位公差识别
- 结构化输出: 直接生成JSON格式,减少后处理工作量
九、关键图表索引
| 图表 | 内容 |
|---|---|
| 图1 | 提出的两阶段混合视觉-语言框架流程图 |
| 图2 | 数据集标注示例(颜色编码边界框) |
| 图3 | 11,469个检测标注的类别分布 |
| 图4 | 检测和图像块提取过程示例 |
| 图5 | GD&T和Measures类别的图像-JSON对示例 |
| 图6 | 增强前后类别分布对比 |
| 图7 | Donut架构(针对工程标注解析定制) |
| 图8 | Donut微调策略:统一vs类别特定 |
| 图9 | Florence-2架构 |
| 图10 | Florence-2微调流水线 |
| 图11 | YOLOv11-obb性能曲线 |
| 图12 | YOLOv11-obb检测结果示例 |
| 图13 | YOLOv11-obb混淆矩阵 |
| 图14 | GUI定性解析验证界面 |
| 图15 | 结构化JSON输出示例 |
| 图16 | 提取的工程图纸信息集成到下游制造工作流 |
| 图17 | 规则驱动的解释流水线示意图 |
十、结论
本研究提出了一个混合视觉框架,用于从2D工程图纸中自动提取结构化信息。通过结合旋转感知对象检测(YOLOv11-obb)与轻量级视觉-语言模型(Donut和Florence-2),该框架有效地将多样化标注类型本地化并解析为结构化数据格式。
主要成果:
- 两阶段混合框架: YOLOv11-obb + 微调VLM
- 数据集: 1,367张图纸,9个类别,11,469个标注实例
- 性能: Donut达到94% F1-score,10.8%幻觉率
- 案例研究: 证明提取的结构化输出在工具选择和工艺规划中的实用性
影响:
- 推动图纸解释的现代化
- 增强数字制造工作流中的自动化和数据互操作性
- 为知识驱动的制造流程铺平道路
附录:对QuoteApp的具体改进建议
A. 短期改进(1-2周)
- 集成YOLOv11-obb :
- 用于检测图纸中的尺寸标注区域
- 替换或辅助当前PaddleOCR检测模块
- 实现OBB裁剪 :
- 根据检测结果裁剪图像块
- 为每个块分配类别标签
B. 中期改进(1-2月)
- 微调Donut模型 :
- 使用QuoteApp现有标注数据微调Donut
- 针对中文工程图纸优化(当前论文使用英文图纸)
- JSON Schema设计 :
- 定义与QuoteApp数据模型对齐的JSON Schema
- 支持长、宽、高、直径、材质等字段
C. 长期改进(3-6月)
- 完整流水线集成 :
- PDF → YOLOv11-obb检测 → Donut解析 → QuoteApp数据库
- GD&T支持 :
- 添加形位公差识别能力
- 支持工艺路线自动生成
- 反馈机制 :
- 允许用户纠正解析错误
- 持续微调模型提升准确性
参考文献(精选)
- Khan, M.T., et al. (2024). "Fine-Tuning Vision-Language Model for Automated Engineering Drawing Information Extraction." arXiv:2411.03707.
- Kim, G., et al. (2022). "OCR-Free Document Understanding Transformer." ECCV 2022.
- Xiao, B., et al. (2024). "Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks." CVPR 2024.
- Lin, Y.H., et al. (2023). "Integration of Deep Learning for Automatic Recognition of 2D Engineering Drawings." Machines, 11(8).
- Gao, J., et al. (2005). "Extraction/conversion of geometric dimensions and tolerances for machining features." Int. J. Adv. Manuf. Technol., 26(4).