
摘要
2026年,数字中国建设持续推进,工业物联网、智能制造、智慧电网、航运监管等行业规模化落地,各类传感器、终端设备持续产生海量时序数据,时序数据库作为数据存储与分析的底层底座,市场需求持续扩张。经过多年技术迭代,国内时序数据库赛道已经告别粗放扩张,不同技术路线产品定位分化清晰。
本文梳理当前主流国产时序数据库的技术路线与适用场景,重点讨论基于传统关系库内核拓展时序能力的多模融合方案,结合电力、海事、港口等真实落地案例,对比专用时序引擎与一体化多模数据库的适用边界,结合企业数字化转型过程中的数据孤岛、多系统运维、数据一致性等实际痛点,给出客观的数据库选型参考思路。
一、2026主流国产时序数据库技术路线梳理
随着国产化软硬件替换工作持续落地,国内时序数据库形成多条并行发展路线,大致分为专用独立时序引擎、云原生时序库、垂直行业定制时序系统、关系型数据库拓展多模时序能力四大类,不同产品适配的业务场景、技术侧重点差异明显。各主流产品核心定位整理如下:
| 数据库名称 | 开发主体 | 核心特点与适用场景 |
|---|---|---|
| TDengine | 涛思数据 | 分布式专用时序数据库,写入吞吐、存储压缩表现突出,开源集群版本生态完善,主打工业物联网、新能源海量设备监测场景,适合仅需单纯时序采集、简单指标统计的业务。 |
| KaiwuDB | 浪潮云弈 | 分布式多模数据库,原生支持时序、关系、文档混合存储,内置轻量AI算法,面向工业互联网、交通等需要多类数据简单协同分析的场景。 |
| Apache IoTDB | 清华大学(Apache社区) | 开源物联网原生时序库,采用端边云协同架构,树形数据模型贴合设备层级,边缘轻量化部署优势明显,是工厂、园区设备采集常用开源方案。 |
| DolphinDB | 浙江智臾科技 | 数据库与流计算、自研编程语言深度绑定,高频数值计算性能突出,核心应用于金融量化、高频工业仿真分析等重度计算场景。 |
| openGemini | 华为云 | 开源云原生时序数据库,兼容InfluxDB使用习惯,容器弹性扩缩容能力完善,多用于云平台运维监控、云上业务指标采集。 |
| CnosDB | 诺司时空 | 支持单机、分布式两种部署形态,架构轻量化,运维门槛低,适合中小企业IT监控、小型物联网项目。 |
| GreptimeDB | 格睿科技 | 云原生分布式架构,侧重实时流式分析、即时告警,主打线上业务实时指标观测、故障预警场景。 |
| YMatrix、RealHistorian、GoldenData | 四维纵横、紫金桥、庚顿数据 | 深耕化工、冶金、市政等垂直工业领域,针对行业协议、老旧设备做定制适配,配套成熟行业解决方案。 |
| 金仓时序扩展模块 | 中电科金仓 | 在成熟商用关系库KingbaseES内核上新增时序处理能力,属于多模一体化路线,统一支持时序、关系、GIS空间、JSON数据,侧重需要强事务、多数据类型关联分析的政企核心业务系统。 |
二、多模融合时序方案:基于关系库内核的技术路径分析
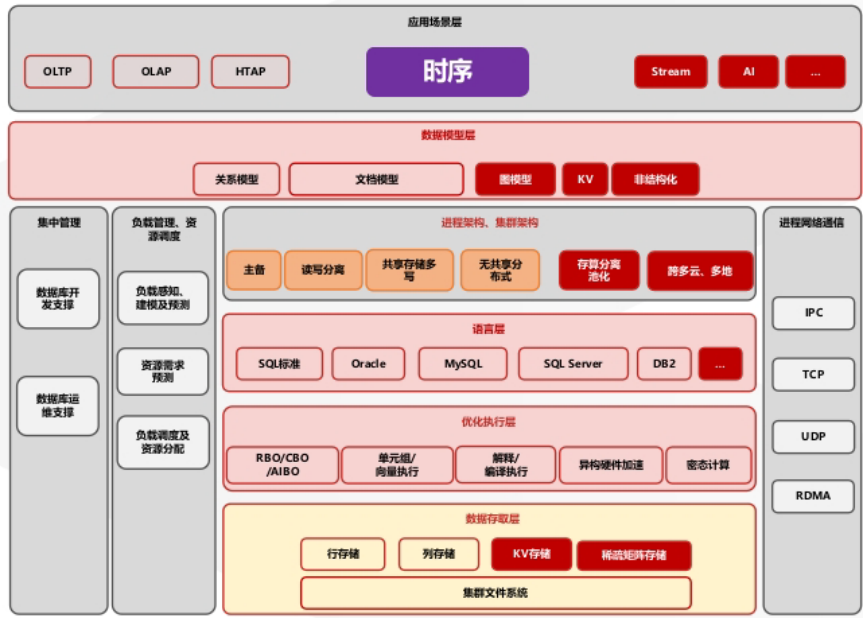
目前市场上绝大多数时序产品,都选择独立引擎路线,优先打磨单一时序读写性能,更适配数据类型单一、分析逻辑简单的监控类业务。另一条发展路线则是在成熟企业级关系数据库基础上,以内核扩展的方式增加时序处理能力,金仓数据库的时序模块是该路线的典型代表,这套架构的优劣可以从数据融合、企业级能力、综合性能三个维度客观分析。
1. 底层一体化存储,缓解多库数据孤岛问题
独立时序数据库普遍存在数据割裂问题:企业需要单独搭建一套集群存放传感时序数据,业务台账、工单、设备档案等结构化数据仍存放在传统关系库,两套系统独立运维,跨库关联分析需要频繁做数据同步、数据导出,流程繁琐且容易产生数据延迟、不一致问题。
采用关系库原生拓展时序的方案,底层共用同一存储内核,具备几点特性:
- 统一基础设施:无需新增独立时序集群,企业现有数据库硬件、集群架构可复用,减少多套系统部署成本;
- 原生跨模型查询:时序传感器数据、设备档案、地理坐标数据在同一实例内存储,通过标准SQL即可完成多表联合查询,无需额外中间件做数据流转;
- 多元数据类型兼容:除时间序列数值外,原生支持GIS空间几何、JSON、数组等格式,适配同时存在定位、设备属性、采集指标的复合型工业场景。
2. 完整继承成熟企业级数据库配套能力
多数专用时序数据库为提升写入速度,会弱化事务、权限、灾备等企业级特性,仅提供最终一致性,无法用于电力调度、政务监管等对数据准确性要求极高的核心生产系统。依托成熟关系库拓展时序能力的方案,可完整继承多年沉淀的商用数据库配套能力:
- 完整ACID事务机制:时序数据表同样支持事务写入、修改、删除,保障电力、海事等核心场景下的数据强一致性;
- 完善高可用与安全机制:主备切换、分片集群、读写分离、行列权限控制、存储加密、操作审计等能力全部复用,满足政企行业国产化安全合规要求;
- 统一运维工具链:备份恢复、迁移工具KDTS、监控告警、集群管理工具无需单独适配,现有DBA仅需掌握传统SQL技能即可完成时序业务维护,降低多技术栈学习成本,长期运维总拥有成本更可控。
3. 时序场景专项优化,兼顾综合查询能力
该方案并非单纯复用关系内核而忽视时序性能,针对海量时间序列读写做了分区、批量插入、数据压缩等专项优化。根据TSBS标准测试结果:
- 写入性能:单机可支撑百万级测点每秒写入,分布式集群可达到千万级测点吞吐,能够满足大规模船舶、厂区设备同步采集需求;
- 查询表现:单纯时序聚合查询性能与主流专用时序库基本持平;在时序+业务台账+地理空间混合关联的复杂查询场景中,依托成熟SQL优化器,查询效率优于多数独立时序引擎,更适合需要多维度融合分析的业务。
同时该路线也存在客观短板:纯大规模、无关联逻辑的简单时序采集场景下,相比轻量化专用时序库,资源开销会略高,更适合业务逻辑复杂、多类型数据并存的中大型项目。
三、行业落地实践案例
多模一体化时序方案更适配需要将采集数据与核心业务系统深度打通的行业,目前在能源、海事、港口、智能制造国产化项目中已有较多落地案例:
1. 福建省船舶安全综合管理平台
平台需实时采集沿海数十万艘船舶GPS位置、航行状态时序数据,单日写入数据量达到亿级。业务侧同时需要结合船舶备案档案、航道地理信息做轨迹查询、航行异常判断。
基于金仓多模架构,统一承载时序定位数据、船舶关系档案、航道GIS数据,依靠分片集群承载高峰写入压力,实现百亿级历史轨迹数据毫秒级检索,为海事监管、应急调度提供数据支撑。
2. 国家电网智能调度国产化改造项目
电网调度属于关键生产业务,采集的电力运行时序数据不允许出现数据丢失、错乱,同时需要和设备台账、调度工单、运维记录联动分析。
传统独立时序库无法满足强事务要求,一体化多模数据库完整保留ACID能力,实现电力采集时序数据与业务台账统一存储,兼顾高频写入与跨表联合分析,支撑调度系统全栈国产化替换。
3. 智慧港口与智能制造产线
厦门港等港口项目中,统一存储装卸设备运行时序、车辆定位、港口调度工单数据,实时分析设备能耗、作业效率,提前识别设备故障隐患;
制造厂区场景下,产线传感器采集的工艺时序数据与生产工单、质检记录联合统计,辅助工艺调优、产能分析与设备预测性维护。
四、2026时序数据库选型客观参考思路
当下企业选型不能只单一参考写入峰值指标,需要结合自身业务数据结构、系统规模、运维团队能力综合判断,可从三个角度评估:
1. 匹配自身业务数据结构
如果业务仅采集设备指标,仅做简单统计、告警,不存在和业务档案、地理数据联动分析的需求,轻量化专用时序引擎部署简单、资源占用更低,是更合适的选择;
若业务同时存在时序采集、设备台账、空间定位等多类数据,且日常分析频繁需要多表关联查询,多模融合数据库能够简化整体技术架构,减少多系统对接、数据同步带来的额外开发工作量。
2. 评估长期运维成本TCO
多套独立数据库意味着需要维护多套集群、掌握多套技术语法,运维、开发学习成本会持续增加。
如果企业现有技术团队以传统关系数据库运维为主,选择基于SQL标准的多模时序方案,能够复用现有人员技能、运维工具,长期人力与配套开发成本更低;纯时序专用产品则适合有独立物联网开发、运维小组的企业。
3. 区分业务系统安全等级
IT监控、园区设备采集等非核心辅助业务,对数据一致性、故障容忍度要求较低,各类轻量化时序库均可满足;
电网、海事、金融、政务等核心生产系统,数据容错空间极小,需要完整事务、权限审计、加密等高等级企业级能力,选型时需要优先考量数据库的商用企业级配套能力。
五、行业总结与发展趋势
2026年国内时序数据库赛道已经形成清晰分化,不同技术路线各有适配场景,不存在绝对最优产品:TDengine、IoTDB、DolphinDB等专用时序引擎,在轻量化、纯时序、重度数值计算场景具备不可替代的优势;而基于关系库拓展的多模融合时序方案,开辟了面向复杂政企核心业务的差异化路线。
以金仓时序模块为代表的一体化方案有明确适用边界,并不适合所有时序业务,但针对多数据类型共存、强事务要求、整体国产化替换的大型企业项目,能够解决多库割裂、运维复杂、数据一致性不足等现实痛点,也是国产基础软件多元化技术路线的一种实践探索。
长远来看,伴随实时智能分析、AI数据分析普及,时序数据库的竞争不再只局限于单一时序读写性能,多模型统一存储、流批一体计算、云边端协同、AI原生集成将成为行业共同的发展方向。如何打通时序、关系、空间等多类数据,搭建统一、易维护的实时数据底座,是所有厂商共同需要解决的行业课题。