引入
前几次熟悉了AMD显卡上的AI部署,微调,这次来学习一下更底层的AMD ROCm算子开发。
仍然是这个项目
https://ailc.datawhale.cn/hall/group/100000144
完整版文档是
https://datawhalechina.github.io/hello-rocm/zh/
云环境是
https://radeon.anruicloud.com/profile
具体云环境算力获取可以看datawhale网页的教程
ROCm简介
类似于Nvidia的CUDA生态,ROCm是AMD显卡上的底层GPU编程架构,和CUDA一样都是类C语言,基于LLVM项目构建,增加了GPU编程特有的关键字和优化pass,实现了LLVM ir到GPU ISA的翻译后端。
我们在AMD服务器上跑torch时,实际上代码会被一层层解析到ROCm,最后编译到机器码执行。
整体流程大概是:
- torch框架
- pybind映射到cpp
- aten cpp框架 封装的张量类
- rocm runtime实现的ROCm接口
- clang前端编译ROCm代码到LLMV IR
- LLVM IR进行中间代码优化
- IR翻译成AMD ISA(类似CUDA的PTX汇编)
- AMD ISA翻译成二进制可执行代码
- 交给AMD显卡执行
之前我们都在torch层,直接调用torch函数,组装AI模型,今天的重点是ROCm层,了解直接对ROCm编程,设计算子的方法
语法
ROCm为了方便CUDA代码迁移,runtime库和__device__等关键字,都和CUDA非常相似,只用替换一个前缀就可以直接迁移。
如果不熟悉CUDA语法的话,下面会以这个代码为例,讲解一下基本语法和编程模型,看了就知道为什么说类C了。
#include <hip/hip_runtime.h>runtime库,下面的hipMalloc等函数都在这个库内#include <iostream>类C语言,所以C的常用库仍然可以使用,只不过注意IO最好不要在核函数进行,尽量在cpu侧main函数进行__global__核函数关键字,表示接下来的函数是核函数,内部就遵循GPU编程模型了,不能用CPU思路来写。具体来说,内部执行的是SIMT架构,每个线程都会执行相同的语句,唯一的区别是,执行时根据线程编号不同,导致进行的操作可能略有区别,因此称为Single Instruction, Multiple Threads(单指令多线程)int i = blockIdx.x * blockDim.x + threadIdx.x;这就是上面说的,线程编号,变成模型分为两级:block和thread,确定了这两个维度的编号,就能唯一确定一个线程的编号,然后可以让这个线程根据自己的编号,去取特定数据,或执行特定指令。比如这里c[i] = a[i] + b[i];,就是让编号i的线程,负责i位置的a+bhipMalloc(&a, bytes);带hip头的函数,都是和GPU相关的,这里的作用就是在在GPU上申请一块内存,传入起始指针和内存大小float *h_a = new float[n];申请CPU侧的内存初始化数据。这些工作在CPU就能做,且耗时不长,不要去浪费GPU算力和内存带宽hipMemcpy(a, h_a, bytes, hipMemcpyHostToDevice);比较关键的一个接口,把CPU内存,拷贝到GPU侧hipLaunchKernelGGL(add, dim3(1), dim3(n), 0, 0, a, b, c, n);启动核函数,这是和CUDA最大的不同,AMD把启动也封装成了一个普通CPP函数,CUDA则定义了特殊语法,kernel_name<<<blocks, threads, shared_mem, stream>>>(args...);。区别在于blocks, threads, shared_mem, stream这些启动参数,CUDA放在尖括号里,而ROCm也一块放在圆括号里。dim3(1), dim3(n)保存了启动的grid和block的三个维度大小,这里只有一个参数,是默认后两维度都是1hipDeviceSynchronize();GPU和CPU显然是两个异步的设备,这里存在数据上的依赖关系,必须先CPU拷贝到GPU,GPU计算完毕,GPU再拷贝回CPU侧打印,GPU拷贝回CPU这一步,必须和GPU计算进行同步,计算完毕前CPU处于阻塞,所以这里用一个接口,让CPU等待GPU的同步信号。hipFree(a);GPU侧的内存释放
c
// file: simple_add.cpp
#include <hip/hip_runtime.h>
#include <iostream>
__global__ void add(float* a, float* b, float* c, int n) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n) {
c[i] = a[i] + b[i];
}
}
int main() {
int n = 1024;
size_t bytes = n * sizeof(float);
float *a, *b, *c;
hipMalloc(&a, bytes);
hipMalloc(&b, bytes);
hipMalloc(&c, bytes);
// 初始化数据
float *h_a = new float[n];
float *h_b = new float[n];
for(int i = 0; i < n; i++) {
h_a[i] = 1.0f;
h_b[i] = 2.0f;
}
hipMemcpy(a, h_a, bytes, hipMemcpyHostToDevice);
hipMemcpy(b, h_b, bytes, hipMemcpyHostToDevice);
// 启动核函数
hipLaunchKernelGGL(add, dim3(1), dim3(n), 0, 0, a, b, c, n);
hipDeviceSynchronize();
// 验证结果
float *h_c = new float[n];
hipMemcpy(h_c, c, bytes, hipMemcpyDeviceToHost);
std::cout << "Result: " << h_c[0] << ", " << h_c[n-1] << std::endl;
delete[] h_a;
delete[] h_b;
delete[] h_c;
hipFree(a);
hipFree(b);
hipFree(c);
return 0;
}编译就像gcc一样,编译后可以直接运行二进制代码
bash
# 编译
hipcc hello_rocm.cpp -o hello_rocm
# 运行
./hello_rocmGPU与SIMT架构
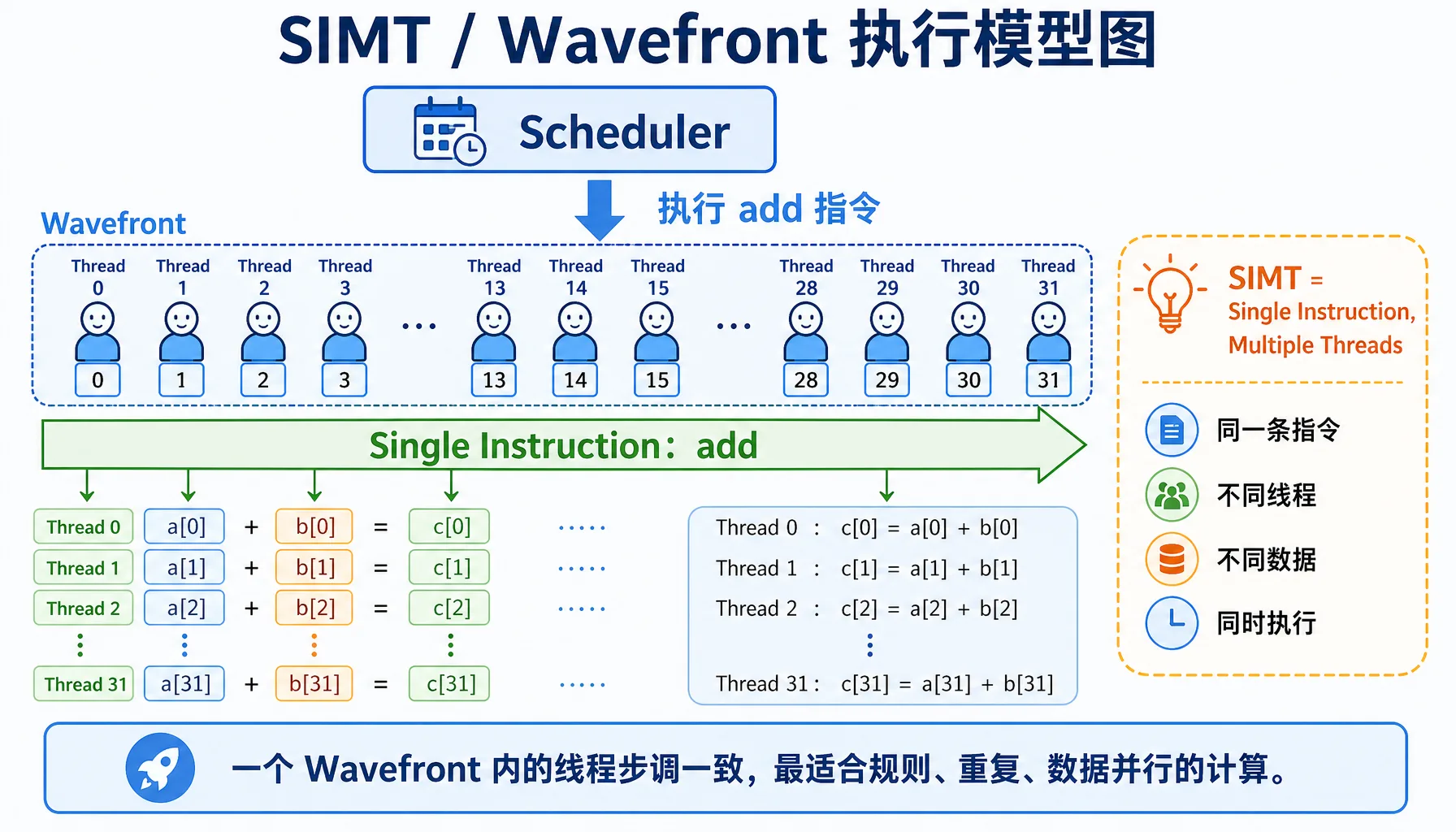
前面提到的SIMT架构。意思是单指令,多线程。一个相同指令,会同时发给GPU上的很多计算单元一块执行。
为什么要这样设计?先回到CPU时代。CPU也有多线程协作,但是CPU每个线程,都要一个CPU核心来执行,并且每个核心都有自己的内存。这样的好处是,每个CPU都很强大,可以执行各种计算任务,并且访问自己的专属内存很快,每个核心可以执行不同的任务,进行复杂的协作。缺点是,一个芯片上搭载不了太多的CPU核心,面对计算密集型任务,显得力不从心。
快速增长的图形化计算需求催生了GPU和SIMT架构,图形学和AI都是计算密集型任务,大部分任务可以直接被抽象成矩阵乘法,如果还用CPU还多线程计算,当然可以,但是每个核心执行的命令都是差不多格式的,对CPU的能力来说是一种浪费,并且CPU核心数堆不上去,导致CPU计算效率太低。
于是提出一种想法:既然矩阵运算每个核心的任务都差不多,且都是简单的加减乘除任务,可以把每个核心都做得更简单,只保留算数单元ALU和必要的寄存器,配套的缓存都砍掉,让一群核心共用。这样虽然牺牲了单个核心的能力,但是增加了片上核心的数量,提高了计算密集型任务的表现。至于说牺牲的复杂任务能力,本来也不需要GPU做这些,复杂任务(比如有很多if-else)的,交给cpu就好了。
GPU编程时采用SIMT编程模型,这是因为GPU生来就是为了并行的,SIMT可以让我们只写针对一个线程编写程序,就能启动多线程,大大降低了多线程开发的难度
对比CPU多线程:CPU的多线程,把任务均分给每个线程,线程内部还要进行一些复杂操作。让每个线程任务过于复杂是不符合GPU设计的,所以GPU没有沿用CPU多线程的MIMD
c
#include <iostream>
#include <vector>
#include <thread>
// CPU 线程函数:每个线程必须知道自己承包的"起点"和"终点"
void cpu_vector_add_task(const float* A, const float* B, float* C, int start, int end) {
// 这是一个完全独立的控制流(MIMD)
for (int i = start; i < end; ++i) {
C[i] = A[i] + B[i];
}
}
void run_cpu_multi_thread(const std::vector<float>& A, const std::vector<float>& B, std::vector<float>& C, int N) {
// 1. 获取 CPU 的物理核心数(比如 8 核)
unsigned int num_threads = std::thread::hardware_concurrency();
std::vector<std::thread> threads;
// 2. 算力切块(Chunking):把 100 万的数据平分给 8 个线程
int chunk_size = N / num_threads;
for (unsigned int i = 0; i < num_threads; ++i) {
int start = i * chunk_size;
// 最后一个线程收尾,防止除不尽
int end = (i == num_threads - 1) ? N : start + chunk_size;
// 3. 显式创建并启动线程
threads.push_back(std::thread(cpu_vector_add_task, A.data(), B.data(), C.data(), start, end));
}
// 4. 主线程苦苦等待所有子线程干完活(同步)
for (auto& th : threads) {
th.join();
}
}线程模型
CUDA和ROCm都采用grid-block-thread三级模型。
- grid:grid是最高层次的,一次内核启动只有一个,grid有三个维度,包含多个线程块block
- block:grid的一组坐标,能唯一确定一个block。在下图中grid看起来是二维的,是默认第三个维度大小等于1.于是用一个二维坐标比如(1,0),就可以确定一个block。在AMD也叫Work-Group
- thread :block内部类似,也有三个维度,下图只有两个。每部包含多个线程thread,每个thread可以用一个坐标唯一确定,在AMD也叫Work-item
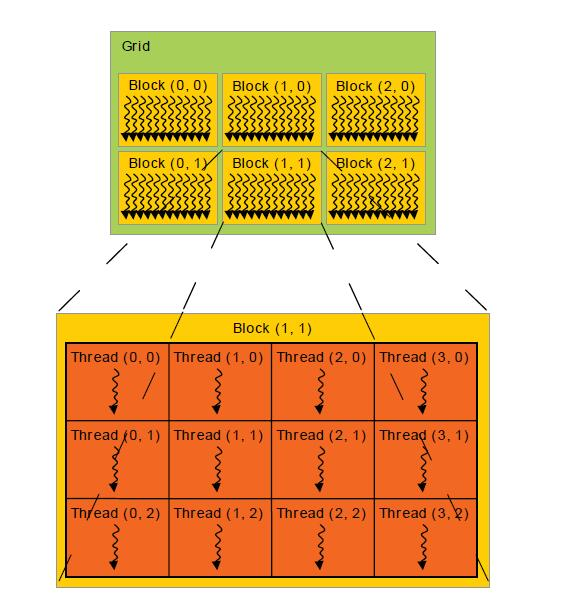
之前内核启动时,传入的dim3(1), dim3(n)就分别是grid和block的维度信息,意思是grid(1,1,1),block(n,1,1),只有一个block,block内是一个一维空间,有n个线程
内存层次
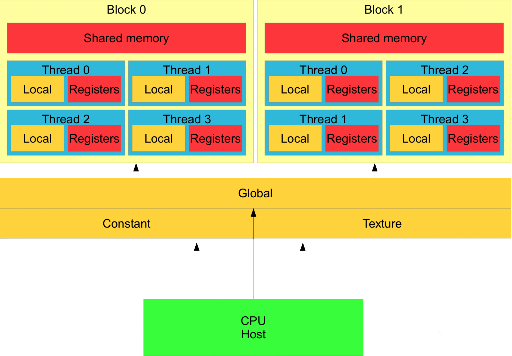
以下是一个CUDA的内存层次示意图,ROCm也差不多
- Host侧,也就是CPU侧的内存,和CPU都不在一块芯片上,是最慢的,所以我们第一步都是先把数据传送到GPU显存上。
- Global memory,device也就是GPU侧的全局内存,也就是一般所说的显存,很大,一般有几十GB,但是速度一般。一般计算所需的全部数据,都放在这。主要通过cpu侧main函数的
hipMalloc声明 - shared memory,共享内存,简称SMEM,每个block独享,距离计算单元更近,更快,但容量也更小。一般把当前线程块内线程所需要的数据放在这里,可能是一个数组的切片。核函数内,使用
__shared__声明的变量会放在共享内存。 - Register,寄存器,线程私有,和CPU架构类似,计算单元附近最近的就是寄存器,容量最小,但是最快,一般只有几K,只能存点temp中间变量,或者循环变量i,j,k之类的。在核函数内,直接用
int a方式声明变量,会优先放在寄存器上。 - local memory,图上寄存器旁边的那个。这个图相当有误导性。理论上也属于线程私有,但是这也是画在一个线程的块内部的原因,但是并不像寄存器一样就在计算单元旁边,而是和全局内存在一个位置!核函数内,用
int a直接声明的变量,在寄存器不够用的时候,会申请为local,放在全局内存上。这被称为寄存器溢出,显然,这会导致访存速度大幅变慢,产生严重的性能退化。所以核函数内要计算使用的变量大小,尽量不要溢出。 - 实际上当然还有缓存,类似CPU的缓存,保存最近读取的数据,用LRU机制更新,这样读取相同数据时,先检查缓存,若缓存命中,则不用真的去目的地址读取,直接从缓存中读,若缓存miss,则去实际地址读,并利用LRU机制替换写入缓存。一般分为L1/L2缓存,前者在block层次,后者在global层次,只是一般对编程者来说是隐藏的,先不谈。
硬件架构
前面我们说的都是编程概念,了解他们实际落到什么硬件上也是很重要的。、
- Wavefront:在CUDA也叫Warp,意思是线程束。一般32/64个线程组成的一组。你可能会想,已经有线程块这个吧一堆线程绑在一起的结构了,为什么还要定义一个线程束?答案是block是软件层次的,可以定义的很大,比如256,512个线程组成一个线程块,但是线程束是硬件执行层面的,我们不可能真的让一个线程块的几千个线程一块并行,这一方面是并行线程可能太多了,造不出这样的器件,另一方面是,软件层面的block大小是可变的,但是硬件一次能并行的线程束显然不可变!所以落到实际硬件设计上,肯定是造一个一次能并行x个个线程的单元,然后对于一个block的所有线程,分组得到多个线程束,每次执行一个线程束。
- 为什么线程束大小是32/64而不是更大?因为我们说了,一个线程束内的线程要并行执行,但这要求这些线程执行的操作完全相同,因为这是硬件并行。但是,设计程序是难免会使用if-else分支,如果一个线程束内的线程,走了不同分支,在硬件上就无法并行了,这被称为线程束分化,比如一个走if一个走else,就只能拆成两次串行,执行if的线程时,else的计算核心闲着,执行else时if的核心又闲着。这带来了计算资源的浪费。所以如果我们把线程束设置的很大,发生线程束分化时,造成的计算资源浪费也很大,比如一个线程数512个线程,只有一个线程走if,那么此时剩余511个计算核心都要阻塞等待这个if的核心!造成极大的浪费。但是,线程束设置的太小,相同大小的数据需要分组个数又会太多,调度会更复杂,也会降低性能。于是取得平衡,选择32/64大小。
- 为什么AMD同时有32/64两种线程束大小? 64面向AI计算,AI计算一般很少出现线程束分化,都是规则的矩阵乘法,所以线程束分化导致计算资源浪费的风险低,那么使用更大的线程束能实现更高的并行度。32则是用于游戏卡,游戏渲染中,一个经典问题是模型边界,边界内外的计算逻辑不一样,更容易出现线程束分化,再用64会导致更大计算资源浪费。顺带一提,CUDA只有32一种线程束大小,不过最新显卡推出了Warp Group,最多4个Warp可以一起调用硬件并行计算,也算变相地提高了warp大小。
- Wavefront和Warp的名字怎么来的?这是个小tips,可以不看。Warp的意思是经线,经线都是平行的,而一个线程束内的线程也都是执行完全一样的指令,也像是平行的。Wavefront是个物理概念,翻译是波前,意思是一个波中相位相同的所有点的集合,比如水面上投下一个石子,形成的圆形波向外扩散,一条圆环的波峰上所有点,相位都是π/2,相位相同,构成了一组波前,这个的比喻就更显然了,一个线程束内的线程状态都完全相同
- Compute Unit(CU):在CUDA叫SM,stream multiprocessor,流多处理器。每个CU有一些SIMD运算器件,一般会有1-4套,每一套可以执行一个线程束32路并行。每个block都会被安排到某一个CU上,到达CU后,block会被划分为多个线程束,接下来以线程束为基本调度单位。把这些线程束放入队列,调度执行。
- Scheduler:类似CPU的调度单元,有很多任务在排队,如何决定接下来进行哪一个,这就是CU上调度器的作用。这里类似CPU,进程有就绪,执行和阻塞三种状态,就绪就是需要的资源(一般是读内存)已经满足了,等待计算单元空闲即可运行,执行中就是计算单元正在处理的,阻塞则是正在等待所需的资源到位的任务。阻塞和等待形成两个队列,调度器负责从这两个队列取元素,给计算单元执行,从计算单元中取出任务,再插入这两个队列。在GPU中
- CU超线程:类似于CPU超线程,一个CU被安排的block数、划分出的线程束个数,一般远多于CU的SIMD计算核心个数。这个设计的的原因和CPU超线程类似,计算单元的速度远快于访问内存速度,所以如果任务不够多,可能任务都在等待数据搬运,导致计算单元闲置。解决办法就是增加任务个数到远大于计算单元个数,这样任何时候都有处于就绪状态的任务,计算单元永远有事干。可以最大化CU计算吞吐率
- LDS/Local Data Share:也就是Shared Memory,共享内存。之前说过,每个block内共享shared memory,现在block被分配到CU,所以SMEM其实就在CU上。每个block来了申请一块。
- VGPR (Vector General Purpose Register,矢量通用寄存器):每个线程私有的寄存器。叫矢量是因为,SIMD计算时,每个线程需要的数据都不同,整体形成一个矢量
- SGPR (Scalar General Purpose Register,标量通用寄存器) :可以理解为每个warp的共享内存,一个warp内诸如blockidx,循环变量等值相同的变量,可以只用存一份,相当于一个标量。
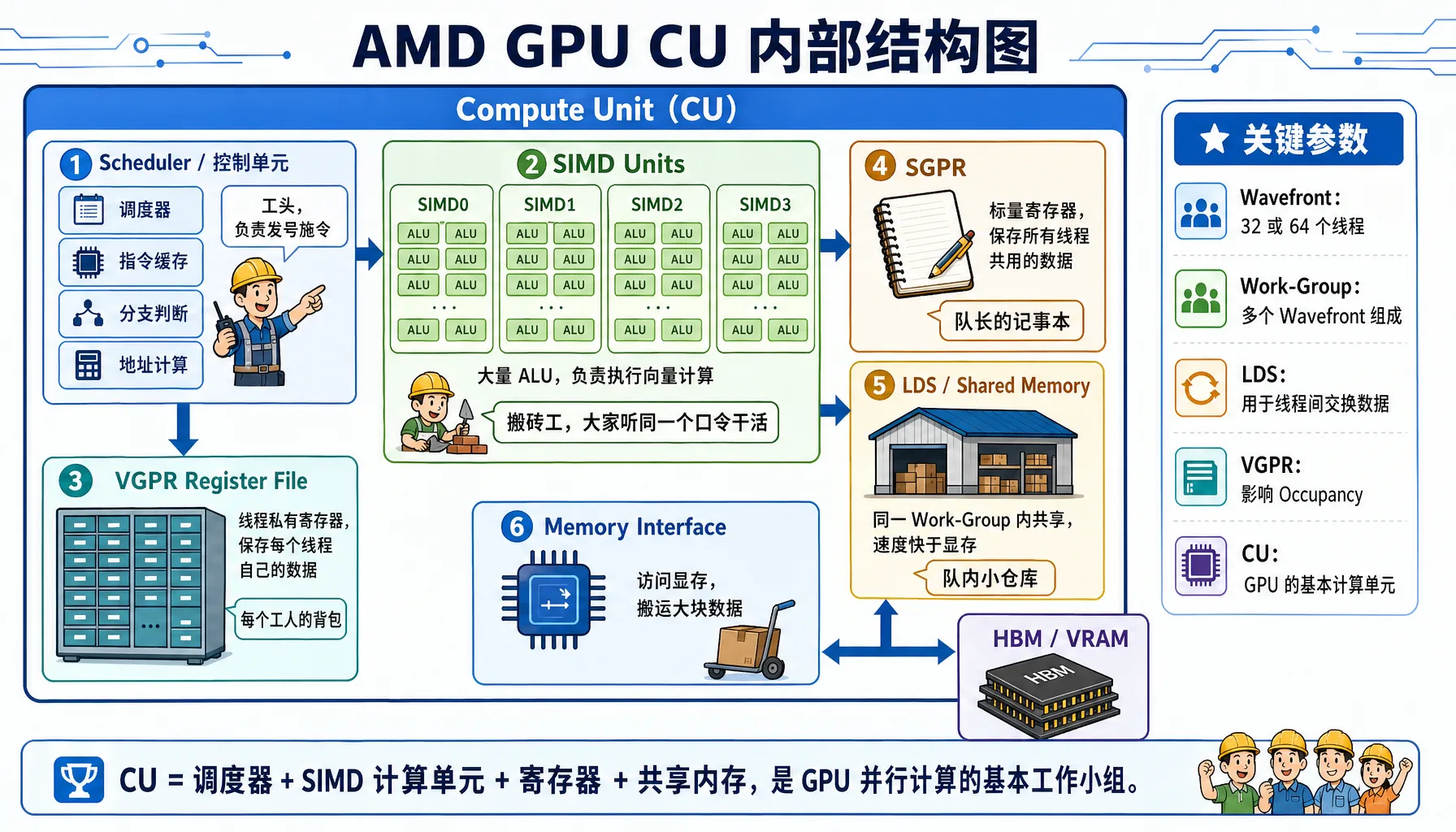
Occupancy:占用率
计算方式是一个CU的实际线程束个数、理论最大线程束个数,实际线程束个数,可能是由于共享内存资源决定的,也可能是由于线程所需寄存器资源决定的。如果因为block需要的LDS太多,或者wavefront需要的register太多,导致CU载入的wavefront不足,可能无法实现有效的超线程掩盖搬运延迟,降低计算单元利用率。
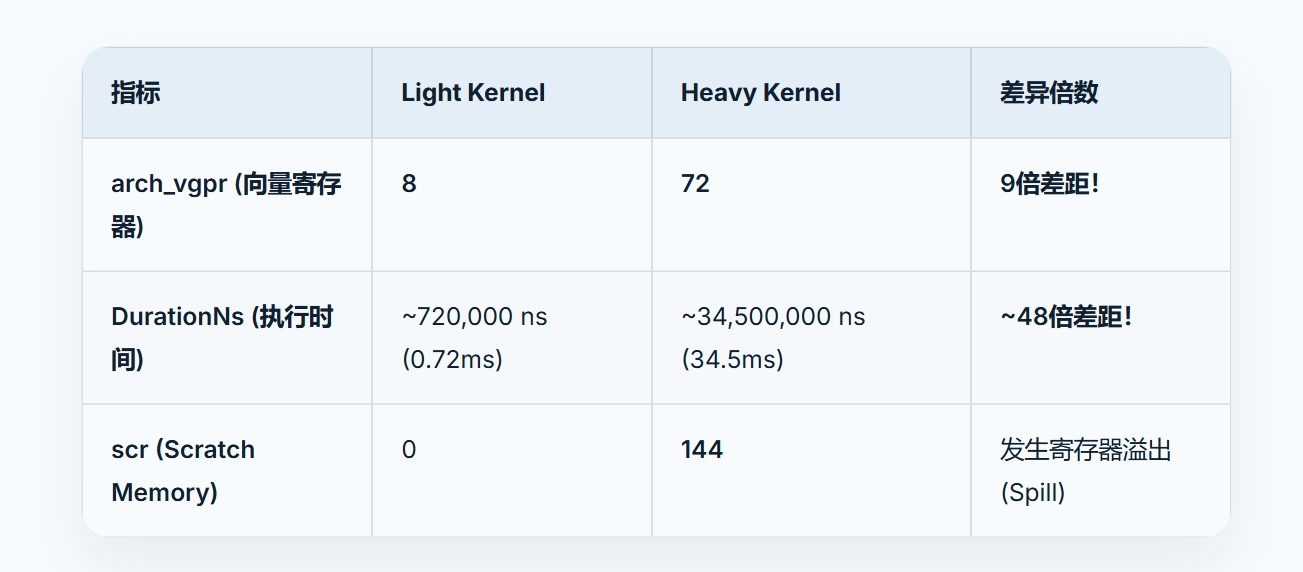
occupancy的影响可以用这个程序来分析,写了两个kernel,使用的寄存器内存量差距很大
c
// file: src/infra/decode-ai-accelerator/code/test_occupancy.cpp
#include <hip/hip_runtime.h>
#include <iostream>
#include <cstdlib>
#include <cmath>
#define HIP_CHECK(call) \
do { \
hipError_t err = call; \
if (err != hipSuccess) { \
std::cerr << "HIP Error: " << hipGetErrorString(err) \
<< " at line " << __LINE__ << std::endl; \
std::exit(EXIT_FAILURE); \
} \
} while (0)
// Heavy kernel: 让每个线程占用 >64 个 VGPR
__global__ void heavy_kernel(float* data, int n) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < n) {
volatile float v0 = data[idx];
volatile float v1 = v0 * 1.01f;
volatile float v2 = v1 * 1.02f;
volatile float v3 = v2 * 1.03f;
volatile float v4 = v3 * 1.04f;
volatile float v5 = v4 * 1.05f;
volatile float v6 = v5 * 1.06f;
volatile float v7 = v6 * 1.07f;
volatile float v8 = v7 * 1.08f;
volatile float v9 = v8 * 1.09f;
volatile float a[20];
#pragma unroll
for(int i=0; i<20; i++) {
a[i] = v0 * (float)(i+1);
}
float sum = 0.0f;
#pragma unroll
for(int i=0; i<20; i++) {
sum += a[i] * v1;
sum -= v2 * v3;
sum += v4 / (v5 + 1e-6f);
sum *= (v6 + v7);
}
data[idx] = sum + v8 + v9;
}
}
// 对照组:低寄存器占用 Kernel
__global__ void light_kernel(float* data, int n) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < n) {
float val = data[idx];
val *= 2.0f;
data[idx] = val;
}
}
int main() {
int n = 1024 * 1024 * 20; // 20M floats
size_t bytes = n * sizeof(float);
float *d_data;
HIP_CHECK(hipMalloc(&d_data, bytes));
const int threads = 256;
const int blocks = (n + threads - 1) / threads;
std::cout << "Data size: " << n << " elements (" << bytes/1024/1024 << " MB)" << std::endl;
hipLaunchKernelGGL(light_kernel, dim3(blocks), dim3(threads), 0, 0, d_data, n);
HIP_CHECK(hipDeviceSynchronize());
std::cout << "=== Running heavy_kernel (High Register Pressure) ===" << std::endl;
for(int i=0; i<5; i++) {
hipLaunchKernelGGL(heavy_kernel, dim3(blocks), dim3(threads), 0, 0, d_data, n);
}
HIP_CHECK(hipDeviceSynchronize());
std::cout << "\n=== Running light_kernel (Low Register Pressure) ===" << std::endl;
for(int i=0; i<5; i++) {
hipLaunchKernelGGL(light_kernel, dim3(blocks), dim3(threads), 0, 0, d_data, n);
}
HIP_CHECK(hipDeviceSynchronize());
HIP_CHECK(hipFree(d_data));
return 0;
}利用rocprof做性能分析
bash
# 编译
hipcc test_occupancy.cpp -o test_occupancy -O3
# 运行分析(会生成 results.csv)
rocprof --stats ./test_occupancy
# 查看生成的 CSV 文件
cat results.csv使用的VGPR很大差距,执行时间产生了更大差距,并且第二个内核发声了寄存器溢出!执行时间的差距,一方面是第二个kernel使用的寄存器多,启动的warp少,另一方面也是因为发生了寄存器溢出,溢出部分存在全局内存,访存延迟很大。
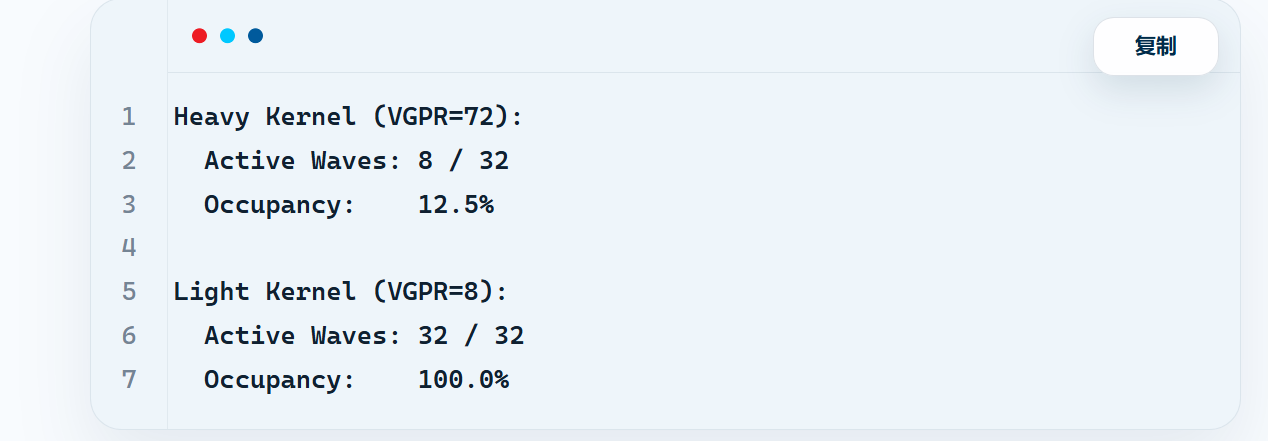
还可以用个简单的计算程序计算occupancy,思路大概就是,分别根据共享内存限制和寄存器限制,计算占有率,两个都要成立,于是取较小值。
py
# file: src/infra/decode-ai-accelerator/code/calc_occupancy.py
def calculate_occupancy_arch1151(vgpr_per_thread, lds_per_workgroup, threads_per_wg):
total_physical_vgprs = 65536 // 4 # 16384
wave_size = 32 # RDNA3 默认为 Wave32
max_waves_per_simd = 32
vgpr_granularity = 8
aligned_vgpr = ((vgpr_per_thread + vgpr_granularity - 1) // vgpr_granularity) * vgpr_granularity
vgpr_per_wave = aligned_vgpr * wave_size
if vgpr_per_wave == 0:
waves_by_vgpr = max_waves_per_simd
else:
waves_by_vgpr = total_physical_vgprs // vgpr_per_wave
max_lds_bytes = 65536
waves_per_wg = (threads_per_wg + wave_size - 1) // wave_size
if lds_per_workgroup > 0:
max_wgs_by_lds = max_lds_bytes // lds_per_workgroup
waves_by_lds = max_wgs_by_lds * waves_per_wg
else:
waves_by_lds = max_waves_per_simd
limit_waves = min(waves_by_vgpr, waves_by_lds, max_waves_per_simd)
active_waves = (limit_waves // waves_per_wg) * waves_per_wg
occupancy_pct = (active_waves / max_waves_per_simd) * 100
return active_waves, occupancy_pct
print("=== 理论 Occupancy 计算 (RDNA3 / gfx1151) ===\n")
vgpr_heavy = 72
occ_heavy, pct_heavy = calculate_occupancy_arch1151(vgpr_heavy, 0, 256)
print(f"Heavy Kernel (VGPR={vgpr_heavy}):")
print(f" Active Waves: {occ_heavy} / 32")
print(f" Occupancy: {pct_heavy:.1f}%")
vgpr_light = 8
occ_light, pct_light = calculate_occupancy_arch1151(vgpr_light, 0, 256)
print(f"\nLight Kernel (VGPR={vgpr_light}):")
print(f" Active Waves: {occ_light} / 32")
print(f" Occupancy: {pct_light:.1f}%")把前面两个内核的内存使用输进去可以得到,第二个内核占用率100%,第一个只有惊人的12%,再加上寄存器溢出,效率低是正常的
计时和错误捕捉API
仍然是个element-wise add,但是加入了计时和错误捕捉
#define HIP_CHECK(command),一个宏,接受所有hipxxx api的返回值,如果不为hipSuccess则说明api报错了,输出报错信息并终止进程hipEventCreate(&start); hipEventCreate(&stop);,声明event,可以用来计时hipEventRecord(start);想要计时的语句开始前,启动第一个事件记录hipEventRecord(stop);计时的语句结束后,启动第二个事件hipEventSynchronize(stop);eventrecord不是同步的,也需要用一个event同步接口hipEventElapsedTime(&ms_kernel, start, stop);最后把两个计时变量传入,就可以获取计时时长
c
#include <hip/hip_runtime.h>
#include <iostream>
#include <vector>
// 宏定义:捕捉底层 API 错误(工业界标配)
#define HIP_CHECK(command) { \
hipError_t status = command; \
if (status != hipSuccess) { \
std::cerr << "HIP Error: " << hipGetErrorString(status) \
<< " at line " << __LINE__ << std::endl; \
exit(1); \
} \
}
// 核函数:向量加法
__global__ void vectorAdd(const float* a, const float* b, float* c, int n) {
// 使用刚才学的 1D 寻址公式
int id = hipBlockDim_x * hipBlockIdx_x + hipThreadIdx_x;
// 边界保护:防止最后一个 Block 里的多余线程越界访问
if (id < n) {
c[id] = a[id] + b[id]; // 每个线程只负责一个元素的加法!
}
}
int main() {
int n = 10000000; // 1000万个元素
size_t bytes = n * sizeof(float);
// 1. Host 端内存分配与初始化
std::vector<float> h_a(n, 1.0f);
std::vector<float> h_b(n, 2.0f);
std::vector<float> h_c(n, 0.0f);
// 2. Device 端显存 (VRAM) 分配
float *d_a, *d_b, *d_c;
HIP_CHECK(hipMalloc(&d_a, bytes));
HIP_CHECK(hipMalloc(&d_b, bytes));
HIP_CHECK(hipMalloc(&d_c, bytes));
// 创建事件计时器
hipEvent_t start, stop;
hipEventCreate(&start); hipEventCreate(&stop);
// 3. 数据搬运:CPU -> GPU (记录耗时)
hipEventRecord(start);
HIP_CHECK(hipMemcpy(d_a, h_a.data(), bytes, hipMemcpyHostToDevice));
HIP_CHECK(hipMemcpy(d_b, h_b.data(), bytes, hipMemcpyHostToDevice));
hipEventRecord(stop);
hipEventSynchronize(stop);
float ms_memcpy_h2d;
hipEventElapsedTime(&ms_memcpy_h2d, start, stop);
// 4. 执行 Kernel 计算
int threadsPerBlock = 256;
// 向上取整计算需要的 Block 数量
int blocksPerGrid = (n + threadsPerBlock - 1) / threadsPerBlock;
hipEventRecord(start);
// 启动核函数:<<<Grid, Block>>>
hipLaunchKernelGGL(vectorAdd, dim3(blocksPerGrid), dim3(threadsPerBlock), 0, 0, d_a, d_b, d_c, n);
hipEventRecord(stop);
hipEventSynchronize(stop); // 等待 GPU 计时结束
float ms_kernel;
hipEventElapsedTime(&ms_kernel, start, stop);
// 5. 数据搬运:GPU -> CPU
HIP_CHECK(hipMemcpy(h_c.data(), d_c, bytes, hipMemcpyDeviceToHost));
// 打印性能数据
std::cout << "验证: c[0] = " << h_c[0] << " (预期: 3.0)" << std::endl;
std::cout << "[耗时] H2D 搬运 (PCIe): " << ms_memcpy_h2d << " ms" << std::endl;
std::cout << "[耗时] Kernel 计算 (VRAM): " << ms_kernel << " ms" << std::endl;
// 6. 释放显存
hipFree(d_a); hipFree(d_b); hipFree(d_c);
return 0;
}