文章目录
-
- 一、2026国产时序数据库全景图:八仙过海,各显神通
- 二、焦点解析:金仓的"融合多模架构"------为何不走寻常路?
-
- [1. 内核级多模态融合,打破数据孤岛](#1. 内核级多模态融合,打破数据孤岛)
- [2. 复用并强化企业级核心能力](#2. 复用并强化企业级核心能力)
- [3. 面向复杂场景的综合性能表现](#3. 面向复杂场景的综合性能表现)
- 三、行业应用与实践:融合架构的真功夫
- 四、2026年国产时序数据库选型思考:超越单一的"性能指标"
- 结论:精耕细作时代,架构创新的胜利

摘要:
步入2026年,随着"数字中国"与工业物联网浪潮的持续翻涌,国产时序数据库市场迎来了前所未有的繁荣期。然而,在表面的喧嚣之下,一场关于"极致性能"与"业务融合"的路线之争正悄然上演。本文将跳出单一的性能指标对比,全景式扫描当前主流的国产时序数据库,并深度聚焦中电科金仓(Kingbase),剖析其为何选择一条"反共识"的道路------不造孤立引擎,而是以"融合多模架构"重塑企业级时序数据底座,为那些深陷数据孤岛与高昂运维成本的企业提供破局思路。
一、2026国产时序数据库全景图:八仙过海,各显神通
如果说前几年国产时序数据库还在摸索阶段,那么2026年,它们已经找到了各自的"舒适区"。市场不再是混沌一片,而是根据核心技术路线与商业模式,分化出了清晰的阵营:
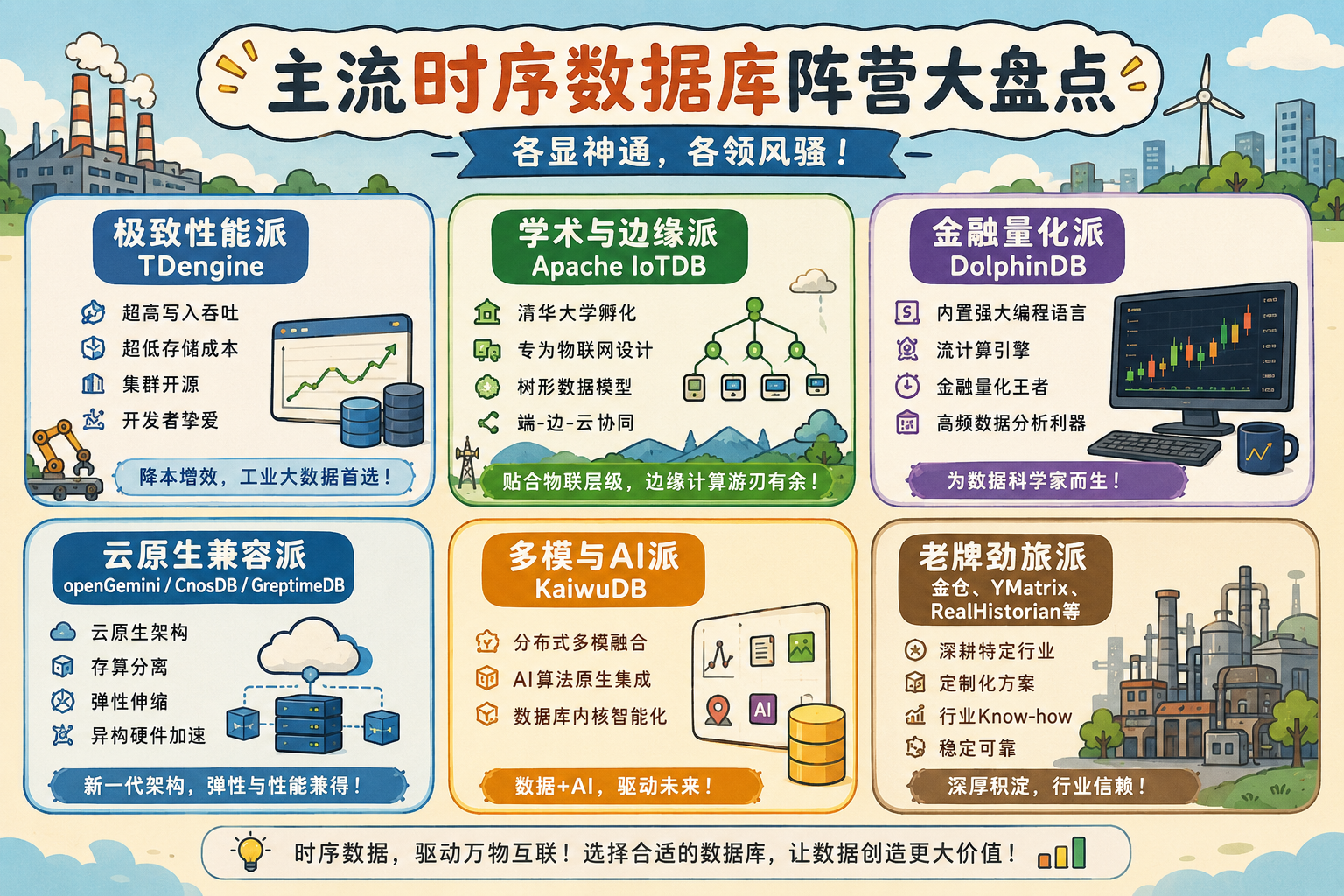
- 极致性能派(TDengine):涛思数据将"降本增效"刻进了基因。在写入吞吐和存储成本上的绝对优势,让它成为了纯工业大数据平台的宠儿。集群开源的策略,更是让它在开发者群体中迅速扎根。
- 学术与边缘派(Apache IoTDB):背靠清华,天生带着科研的严谨。它专为物联网设计,树形数据模型完美贴合物理设备的层级结构,"端-边-云"协同的原生架构,让它在边缘计算场景中游刃有余。
- 金融量化派(DolphinDB):浙江智臾科技将数据库与强大的编程语言、流计算引擎融为一体。在金融量化交易和高频数据分析领域,它是绝对的王者,是数据科学家的专属玩具。
- 云原生兼容派(openGemini / CnosDB / GreptimeDB):华为云的openGemini、诺司时空的CnosDB以及格睿科技的GreptimeDB,代表了新一代架构的探索。它们主打云原生、存算分离,试图在弹性伸缩与异构硬件加速上弯道超车。
- 多模与AI派(KaiwuDB):浪潮云弈的KaiwuDB则另辟蹊径,强调分布式多模融合,试图将AI算法原生集成进数据库内核。
- 老牌劲旅派(金仓、YMatrix、RealHistorian等):四维纵横、紫金桥、庚顿数据等厂商,在特定工业或监控领域拥有深厚的行业积淀,它们的解决方案往往更重定制化与行业Know-how。
在这个百花齐放的舞台上,**金仓数据库(Kingbase)**显得格外特殊。它没有选择在"纯时序"这条赛道上与专业选手死磕,而是祭出了"融合多模"的大旗。
二、焦点解析:金仓的"融合多模架构"------为何不走寻常路?
在大多数厂商都在追求"更快的写入、更大的并发"时,金仓时序数据库选择了一条更具挑战性的路:不做孤立的专用引擎,而是作为强大融合数据库体系(KES)中的一个核心板块。
这种架构选择,看似"逆潮流",实则切中了企业数字化转型中最痛的痛点。
1. 内核级多模态融合,打破数据孤岛
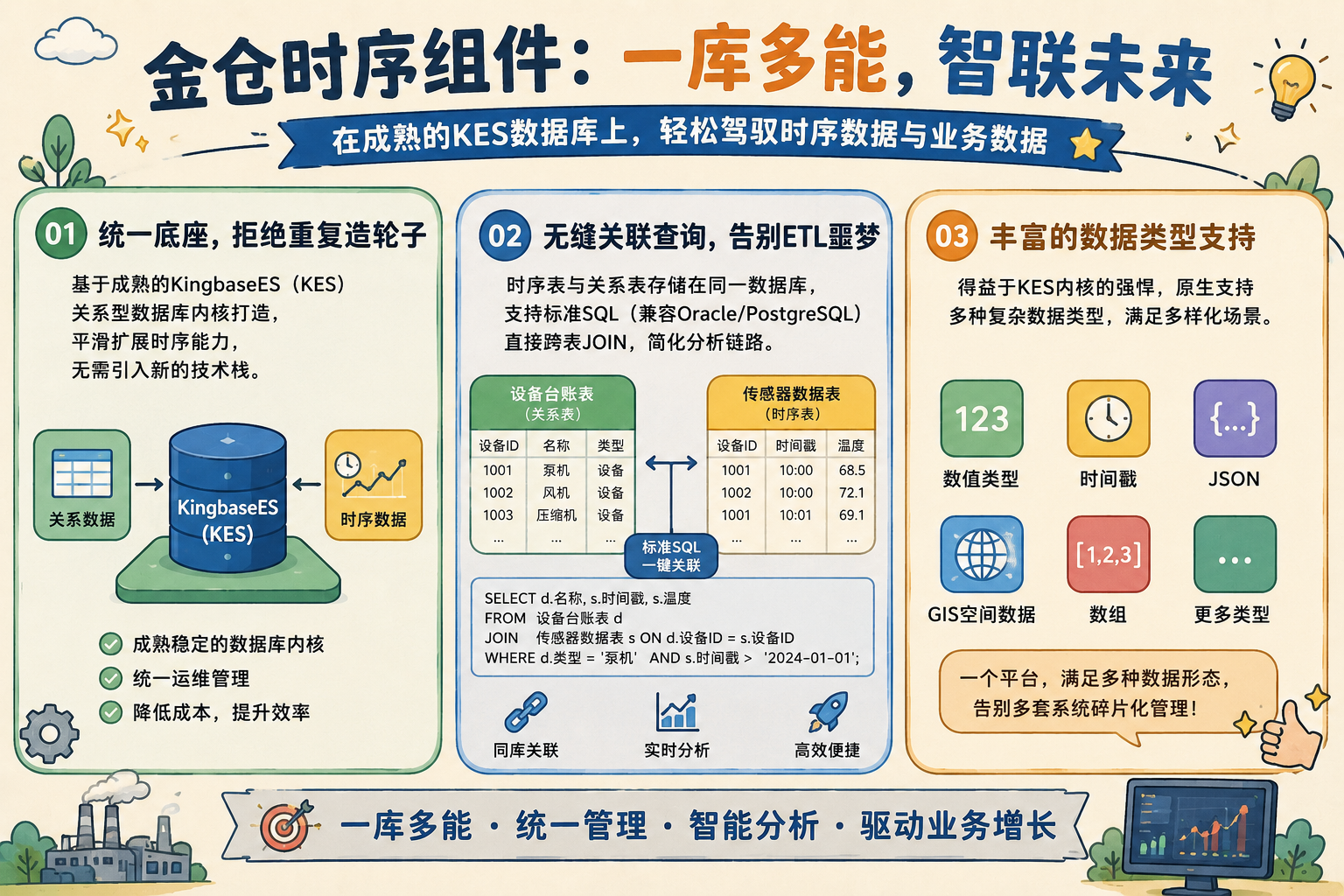
- 统一底座,拒绝重复造轮子:金仓时序组件并非一个独立的、需要重新搭建和运维的新基础设施。它基于成熟的KingbaseES(KES)关系型数据库内核打造。这意味着,企业可以在现有的数据库体系上,平滑地获得时序数据处理能力,无需引入新的技术栈。
- 无缝关联查询,告别ETL噩梦:在真实的工业场景中,时序数据(如传感器读数)从来不是孤立存在的。它必须与业务关系数据(如设备台账、生产工单、人员信息)结合分析。金仓的方案允许你将时序表与关系表存储在同一个数据库中,直接使用标准SQL(支持Oracle/PostgreSQL兼容模式)进行跨表JOIN。这极大地简化了数据分析链路,避免了繁琐的数据同步与导出。
- 丰富的数据类型支持:得益于KES内核的强悍,它不仅支持基础的数值和时间戳,还原生支持JSON、GIS空间数据、数组等复杂类型。一个平台,满足多种数据形态,这是单一时序库难以做到的。
2. 复用并强化企业级核心能力
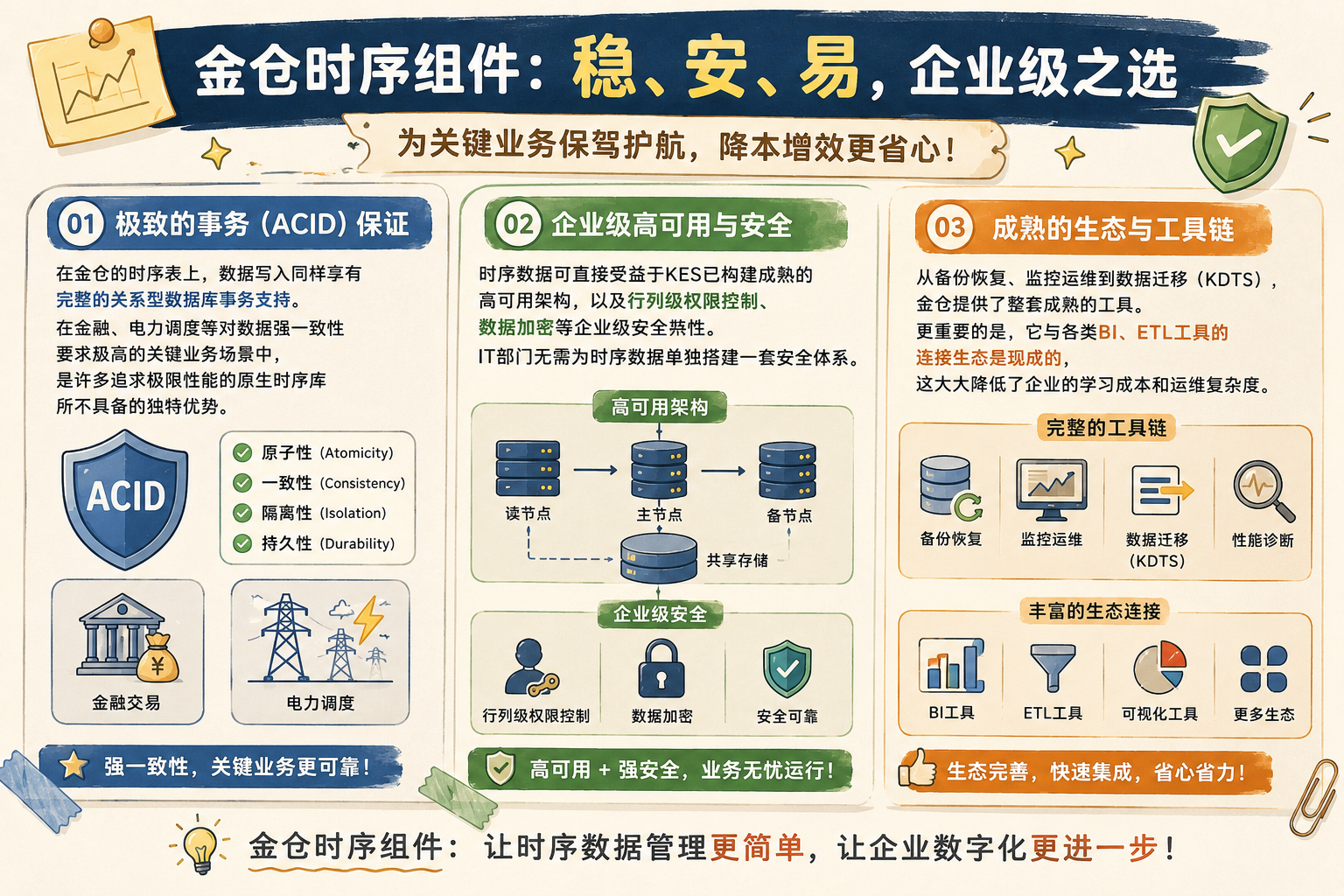
- 极致的事务(ACID)保证:在金仓的时序表上,数据写入同样享有完整的关系型数据库事务支持。这在金融、电力调度等对数据强一致性要求极高的关键业务场景中,是许多追求极限性能的原生时序库所不具备的独特优势。
- 企业级高可用与安全:时序数据可直接受益于KES已构建成熟的读写分离、共享存储、分布式集群等高可用架构,以及行列级权限控制、数据加密等企业级安全特性。IT部门无需为时序数据单独搭建一套安全体系。
- 成熟的生态与工具链:从备份恢复、监控运维到数据迁移(KDTS),金仓提供了整套成熟的工具。更重要的是,它与各类BI、ETL工具的连接生态是现成的,这大大降低了企业的学习成本和运维复杂度。
3. 面向复杂场景的综合性能表现
从金仓官方披露的测试报告(如使用TSBS工具对比InfluxDB)来看,其时序组件在特定场景下展现出强大的竞争力:
- 写入性能:通过优化分区策略、并行插入等手段,在特定配置下可实现单机百万级、集群千万级数据点/秒的写入能力。
- 查询性能:在涉及多维度聚合、跨表关联等复杂查询场景中,凭借成熟的SQL优化器与执行引擎,其性能表现显著优于部分原生时序数据库。它尤其适合需要将时序数据与业务数据进行深度整合分析的场景。
三、行业应用与实践:融合架构的真功夫
金仓时序组件的融合架构,在那些既需要处理海量时序数据流,又需要与核心业务系统紧密集成的场景中,找到了用武之地。公开案例包括:
- 福建省船舶安全综合管理平台:处理沿海数十万船舶终端的GPS定位时序数据。基于KES的分片(Sharding)方案,实现了日峰值亿级写入与百亿级历史数据的毫秒级地理空间查询。
- 国家电网智能电网调度系统:在国产化迁移项目中,支撑高频、可靠的电力数据录入,并实现与大量既有关系型业务数据的混合处理与分析。
- 智慧港口(如厦门港)、智能制造厂区:记录设备轨迹、工况时序数据,并与生产管理系统、设备管理系统进行实时关联分析,提升运营效率。
这些案例的共同点在于:数据不是割裂的,业务是复杂的,对稳定性和一致性要求极高。 这正是金仓融合架构的用武之地。
四、2026年国产时序数据库选型思考:超越单一的"性能指标"
企业在2026年进行时序数据库选型时,应超越对单一峰值性能指标的过度关注,从更宏观的视角评估:
- 数据架构的复杂性:如果业务中时序数据与关系数据、空间数据等紧密耦合,需要频繁进行关联分析,那么金仓的融合多模架构将提供极大的便利性和整体性价比。
- 长期运维与总拥有成本(TCO):引入一个全新的、专用的时序数据库,意味着需要培养新的运维团队、购买新的工具、承担更高的学习成本。而复用现有的关系型数据库团队的技能栈和工具链,是金仓方案的一大隐性优势。
- 业务场景的匹配度 :纯监控、日志场景,选TDengine/InfluxDB;金融量化,选DolphinDB;如果业务是"时序数据 + 复杂业务逻辑 + 国产化替换",金仓这种融合架构可能是最省心的。
结论:精耕细作时代,架构创新的胜利
2026年的国产时序数据库赛道,已经从"拼速度"进入了"精耕细作"的阶段。以TDengine、IoTDB、DolphinDB为代表的专业时序库在各自的优势领域持续深化,构筑了坚固的护城河。
而金仓时序数据库,凭借其独特的"融合多模架构",走出了一条差异化道路。它并非要成为所有场景的"万能钥匙",但对于那些业务逻辑复杂、数据形态多样、且对事务一致性与系统整合有高要求的企业级用户而言,它提供了一个能够将时序数据能力平滑、稳健地嵌入到现有企业数据核心中的优秀选择。
这不仅是技术的胜利,更是国产基础软件在架构设计上深度思考与务实创新的体现。未来,随着AI for Data、实时智能分析的普及,时序数据库的"智能"与"融合"能力将愈发关键。如何更好地将时序处理能力与多模数据、AI框架、流批计算无缝结合,将是所有厂商共同面临的下一个课题。