一、引言
Java/Scala 的类型系统在分布式计算场景下存在两个核心问题:
- 泛型擦除(Type Erasure):运行时无法获取 List<String> 中的 String 信息
- 序列化低效:Java 原生序列化性能差、体积大,无法满足大数据场景的吞吐要求
类型系统是 Flink 高效序列化、内存管理和算子优化的基石,Flink 从设计之初就构建了独立的类型系统,目标是:
- 完整的类型感知:在编译期或提交期捕获完整类型信息
- 高效的序列化:为每种类型生成专用的 Serializer,避免通用序列化开销
- 内存优化:基于类型信息进行堆外内存管理和二进制数据操作
二、TypeInformation 体系(DataStream API)
TypeInformation<T>(包路径:org.apache.flink.api.common.typeinfo)是 DataStream API 和旧版 DataSet API 的类型描述核心。每个TypeInformation实例描述了一种数据类型,并能生成对应的TypeSerializer。
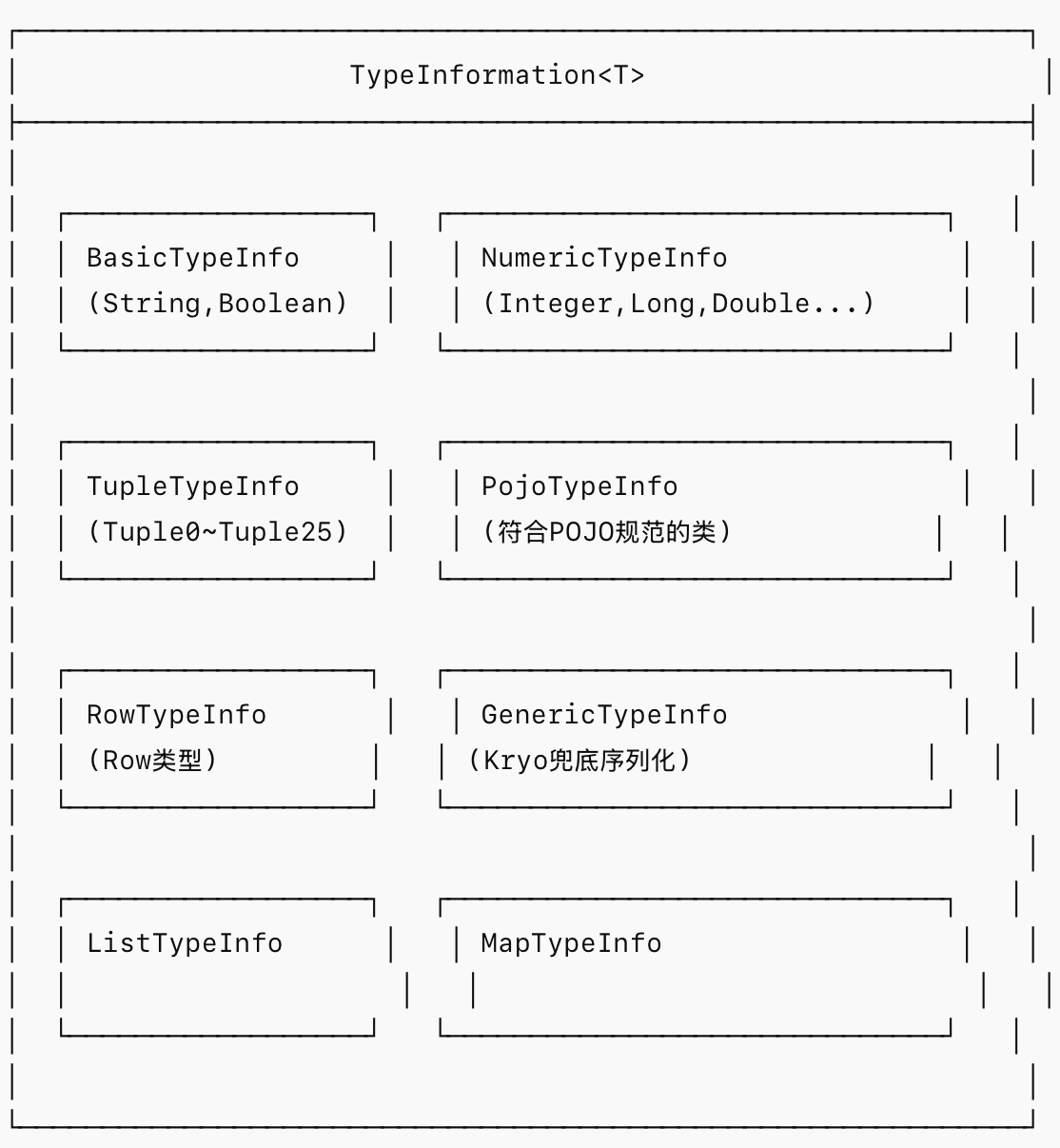
Flink 通过TypeExtractor在作业提交时自动推断类型信息:
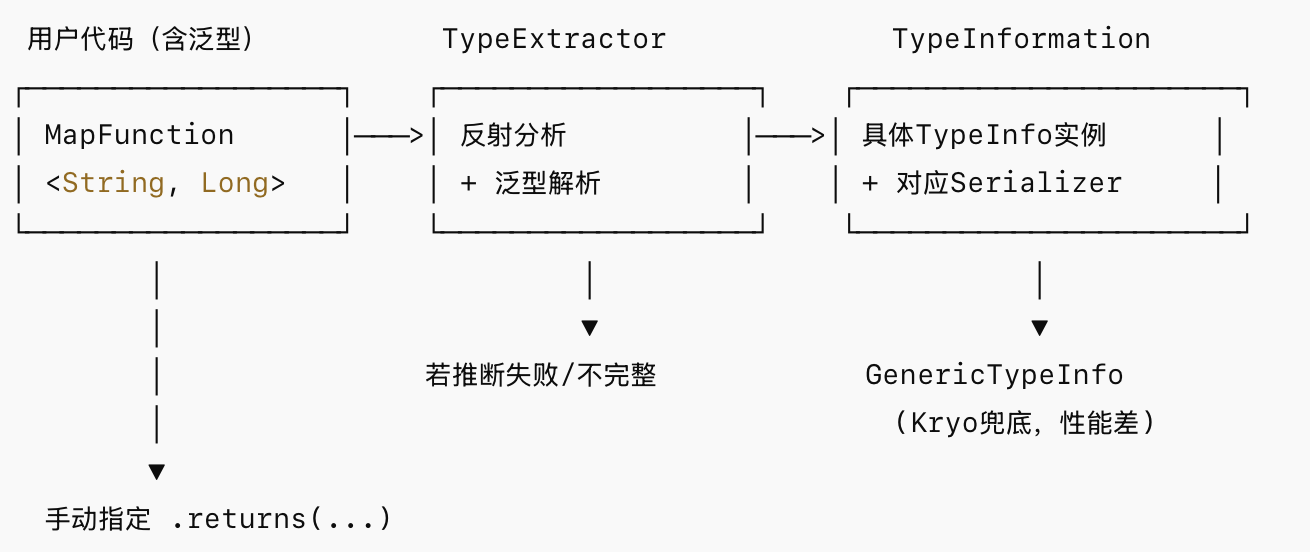
关键API用法示例如下:
// 方式1:自动推断(大多数场景下有效)
DataStream<String> stream = env.fromSource(...);
// 方式2:TypeHint 解决泛型擦除
DataStream<Tuple2<String, Long>> result = stream
.map(new MyMapFunction())
.returns(new TypeHint<Tuple2<String, Long>>() {});
// 方式3:直接指定 TypeInformation
DataStream<MyPojo> result = stream
.map(new MyMapFunction())
.returns(TypeInformation.of(MyPojo.class));
// 方式4:@TypeInfo 注解(自定义类型工厂)
@TypeInfo(MyTypeInfoFactory.class)
public class MyCustomType { ... }Flink 对 POJO 类型有明确要求(满足时使用高效的 PojoSerializer,否则回退 Kryo):
- 类必须是 public 且独立的(非内部类,或 static 内部类)
- 必须有 public 无参构造器
- 所有字段要么是 public,要么有对应的 getter/setter
- 字段类型必须是 Flink 支持的类型
三、DataType 体系(Table API & SQL)
随着 Table API & SQL 成为 Flink 的一等公民,原有的 TypeInformation 暴露出局限:
- 无法精确表达 SQL 语义(如精度 DECIMAL(10,2)、VARCHAR(100))
- 逻辑类型与物理表示耦合
- 不符合 SQL 标准类型系统
Flink 从 1.9 版本开始引入全新的 DataType 体系(包路径:org.apache.flink.table.types)。
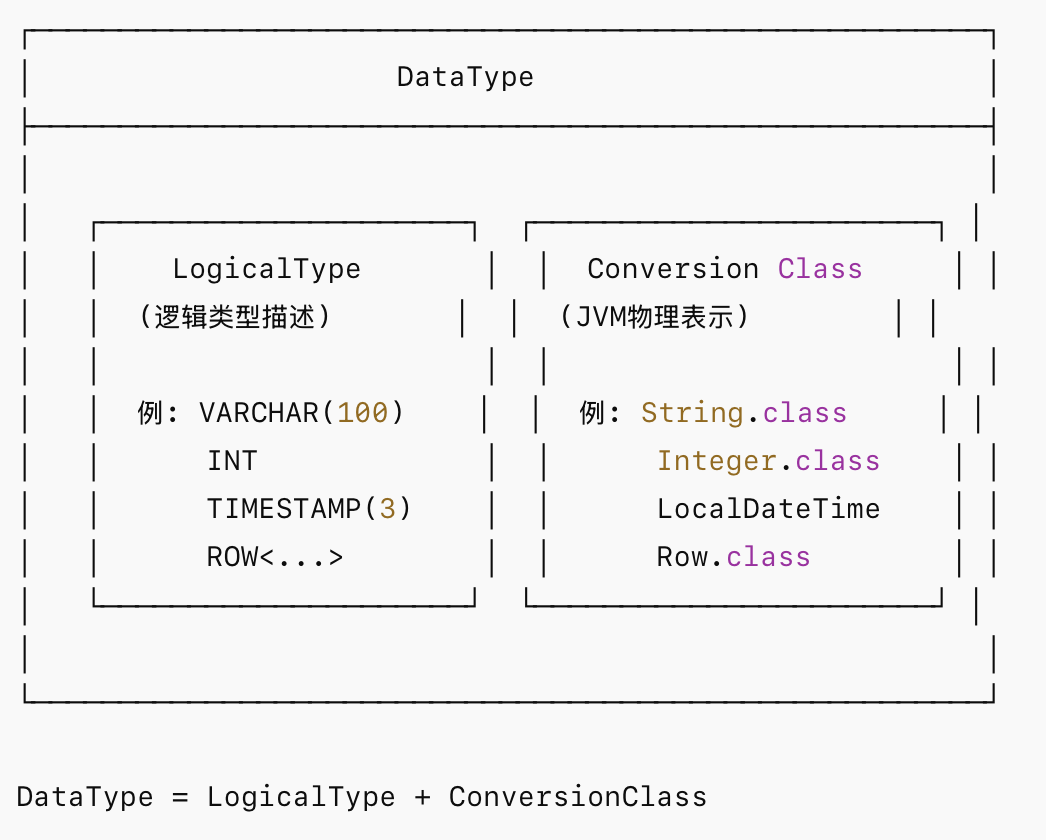
这种设计意味着:同一个逻辑类型可以对应不同的物理表示。例如TIMESTAMP(3)可以映射为java.time.LocalDateTime,也可以映射为java.sql.Timestamp。
LogicalType 类型体系示例如下:
LogicalType
├── CharType -- CHAR(n)
├── VarCharType -- VARCHAR(n) / STRING
├── BooleanType -- BOOLEAN
├── TinyIntType -- TINYINT
├── SmallIntType -- SMALLINT
├── IntType -- INT
├── BigIntType -- BIGINT
├── FloatType -- FLOAT
├── DoubleType -- DOUBLE
├── DecimalType -- DECIMAL(p, s)
├── DateType -- DATE
├── TimeType -- TIME(p)
├── TimestampType -- TIMESTAMP(p)
├── LocalZonedTimestampType -- TIMESTAMP_LTZ(p)
├── ArrayType -- ARRAY<t>
├── MapType -- MAP<k, v>
├── MultisetType -- MULTISET<t>
├── RowType -- ROW<f0 t0, f1 t1, ...>
├── RawType -- RAW('class', 'serializer')
└── NullType -- NULLDataTypes 工厂类常用方法示例:
import static org.apache.flink.table.api.DataTypes.*;
// 基本类型
DataType stringType = STRING(); // VARCHAR(2147483647)
DataType intType = INT();
DataType tsType = TIMESTAMP(3);
DataType decimalType = DECIMAL(10, 2);
// 复合类型
DataType rowType = ROW(
FIELD("name", STRING()),
FIELD("age", INT()),
FIELD("score", DECIMAL(5, 2))
);
// 集合类型
DataType arrayType = ARRAY(STRING());
DataType mapType = MAP(STRING(), INT());
// 指定物理转换类
DataType customTs = TIMESTAMP(3).bridgedTo(java.sql.Timestamp.class);四、TypeInformation VS DataType
|-------------|---------------------------|--------------------------------|
| 维度 | TypeInformation | DataType |
| 所属 API | DataStream / DataSet | Table API & SQL |
| 包路径 | o.a.f.api.common.typeinfo | o.a.f.table.types |
| 设计理念 | 类型 + 序列化一体 | 逻辑类型与物理表示分离 |
| SQL 语义 | 不支持精度等 | 完整 SQL 标准支持 |
| Nullability | 不原生支持 | 内建支持(.nullable() / .notNull()) |
| 引入版本 | Flink 初始版本 | Flink 1.9+ |
| 长期规划 | 维护模式 | 未来统一方向 |
在 Table 与 DataStream 互转时,Flink 提供了内置的类型映射:
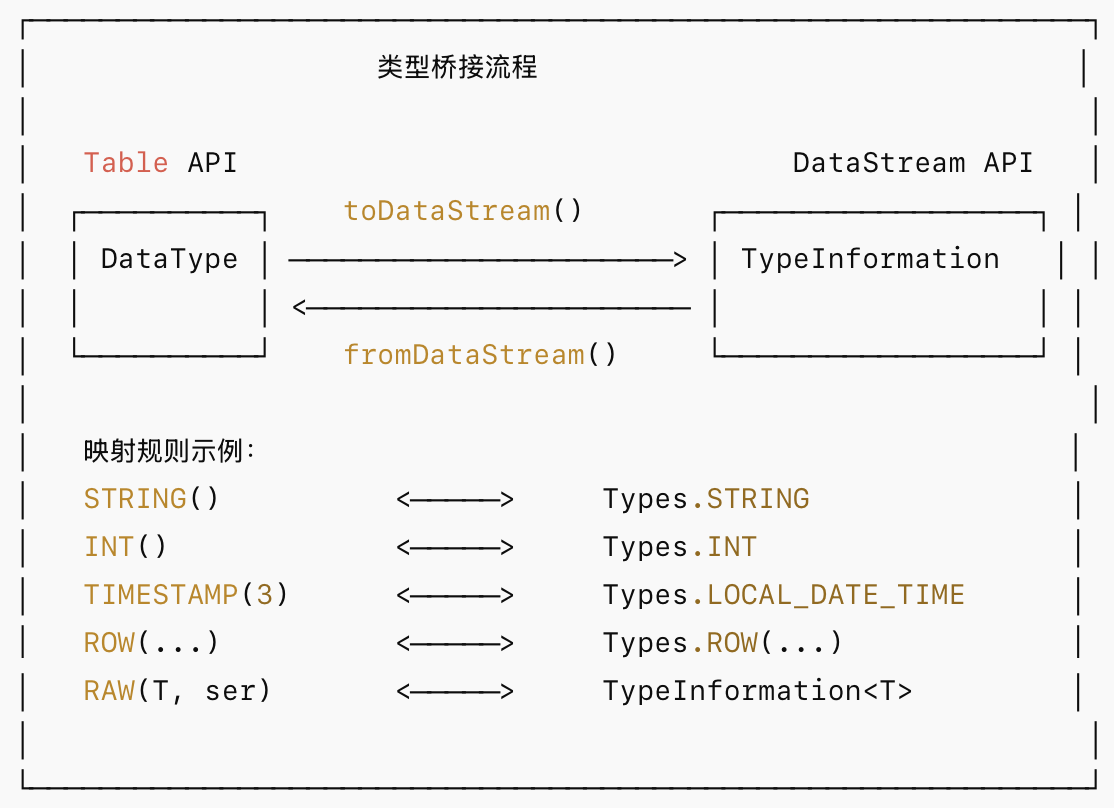
代码示例:
// DataStream -> Table
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
DataStream<UserEvent> stream = ...;
// Flink 1.13+ 推荐方式
Table table = tEnv.fromDataStream(stream,
Schema.newBuilder()
.column("userId", DataTypes.STRING())
.column("timestamp", DataTypes.BIGINT())
.column("eventType", DataTypes.STRING())
.build());
// Table -> DataStream
DataStream<Row> resultStream = tEnv.toDataStream(resultTable);
// 指定目标类型
DataStream<UserEvent> typedStream = tEnv.toDataStream(resultTable, UserEvent.class);五、类型工作流程与实践
以下展示一条数据从输入到序列化的类型处理全流程:
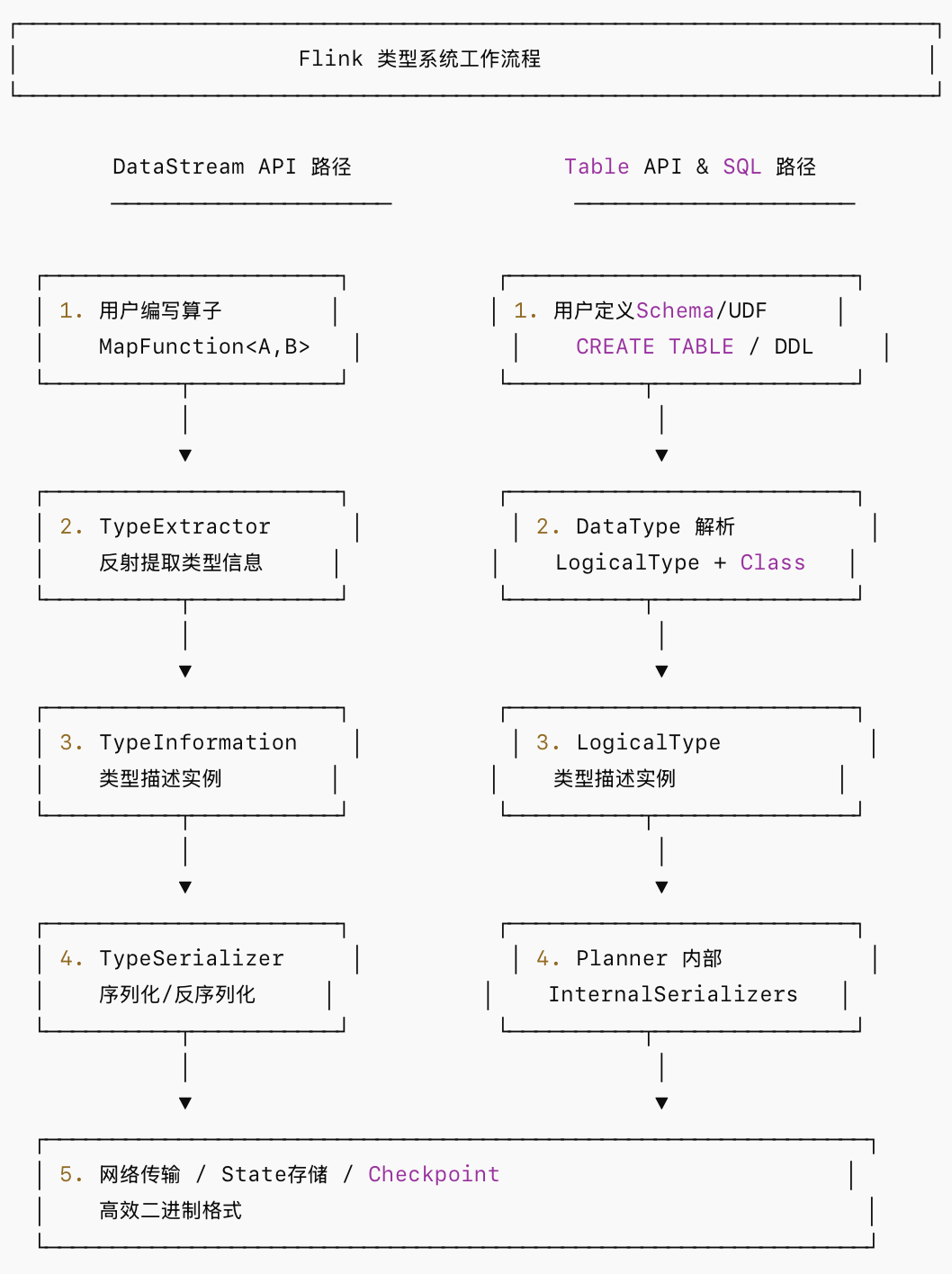
- 使用DataStream API 应避免 Kryo 回退,确保类型可被正确推断
- 使用Table API 应尽量明确声明类型,避免依赖反射推断
- 大状态State场景,建议使用 POJO/Tuple 而非 GenericType,序列化体积更小
- 高吞吐网络 Shuffle场景,避免嵌套复杂对象,优先使用扁平化 Row/Tuple
- Schema 频繁变更场景,建议使用 POJO,状态兼容性更好,避免 Tuple(基于位置索引)
- Table-DataStream 互转场景下,使用RAW类型包装不可映射的自定义类