基于YOLOv8+Flask的火焰烟雾检测系统
本文涉及的全部源码、训练好的模型权重、数据集、配套文档已整理打包,文末附下载链接,方便读者一键复现与二次开发。
开发目的
本系统的开发旨在构建一个面向火焰与烟雾的实时检测与可视化平台,其核心动机源于火灾预警场景中对多类别目标(火焰、烟雾及干扰物)的精准识别需求。现有公开数据集多聚焦于单一火焰检测,或仅包含少量烟雾样本,难以覆盖实际监控中常见的复杂背景与干扰物(如灯光、蒸汽、灰尘等)。为此,我们选用了一个包含10335张图片、标注三类目标(火焰、烟雾、其他)的专用数据集,其中"其他"类别专门用于抑制误报,使模型能够区分真实火情与视觉相似物。该数据集覆盖了室内外、白天黑夜、不同距离与遮挡程度下的样本,训练集与验证集分别包含8420张和1915张图片,为模型提供了充足的多样性。研究切入点在于:通过引入"其他"负样本类别,提升系统在非火情场景下的鲁棒性,同时兼顾火焰与烟雾的小目标、半透明特性,从而在早期预警中降低漏报与误报率,满足安防监控、森林防火、工业厂区等实际场景对高可靠性检测的需求。
在技术路线选择上,采用YOLOv8作为检测核心,因其在实时性与精度之间取得了良好平衡,尤其适合多类别(火焰、烟雾、其他)与小目标检测任务。YOLOv8的C2f模块与解耦头结构能够有效提取火焰的纹理边缘与烟雾的扩散形态特征,同时其轻量化设计(如nano/small版本)可部署于边缘设备,满足实时推理需求。后端选用Flask框架,其轻量、灵活的特性便于快速搭建RESTful API,实现图像上传、检测结果返回与模型热加载,且与Python生态无缝集成。前端采用Layui构建交互界面,其简洁的组件库(如卡片、表格、弹窗)能够直观展示检测结果(边界框、置信度、类别标签)与统计信息,无需复杂的前端工程化配置,适合快速原型开发。三者结合形成了从模型推理到用户交互的完整闭环,技术契合度体现在:YOLOv8提供高效检测能力,Flask负责服务调度与数据流转,Layui实现轻量级可视化,整体架构易于扩展与维护。
为验证系统效果,我们将在验证集(1915张图片)上系统评估模型的检测性能,主要指标包括平均精度均值(mAP@0.5)与各类别AP,同时记录单张图片的推理耗时(毫秒级)以衡量实时性。此外,通过模拟不同光照、遮挡、距离条件下的测试样本,观察模型对火焰与烟雾小目标的召回率,以及"其他"类别的误报抑制能力。最终将综合mAP(实际训练结果为0.793)、推理速度与误报率,判断系统是否满足实际部署的精度与实时性要求,并分析模型在边缘设备上的可移植性。所有评估均基于统一测试流程,不预设具体数值,仅通过对比实验与可视化结果验证技术路线的有效性。
YOLOv8 介绍
YOLOv8是由Ultralytics团队在2023年推出的新一代目标检测网络,继承了YOLO系列高效实时的特点,在精度与速度之间取得了更优的平衡。其核心骨干网络采用了基于ELAN思想的C2f模块,替代了YOLOv5中的C3模块。C2f的设计灵感来源于跨阶段局部网络(CSPNet)和高效层聚合网络(ELAN),通过将输入特征图分为多个分支,并在每个分支内引入多个卷积层和跨层连接,最后将所有分支的输出在通道维度上拼接,从而实现了更丰富的梯度流。这种结构使得梯度在反向传播时能够绕过部分冗余路径,直接流向浅层,有效缓解了深层网络中的梯度消失问题,同时参数数量相比C3模块有所减少,参数效率更高。C2f模块内部还采用了更细粒度的特征重组,让网络能够以更少的计算代价提取到更具判别力的特征,为后续的多尺度融合和检测奠定了坚实基础。
在特征融合层(Neck)部分,YOLOv8沿用了YOLOv5中的SPPF(快速空间金字塔池化)和PAN-FPN(路径聚合网络-特征金字塔网络)结构。SPPF通过不同尺寸的最大池化核并行处理输入特征,并将结果拼接,从而在不显著增加计算量的前提下扩大了感受野,使网络能够捕获更大范围的上下文信息。PAN-FPN则采用自底向上和自顶向下的双向路径,将浅层的高分辨率细节信息与深层的语义信息充分融合,生成多尺度的特征图。对于火焰烟雾检测任务而言,火焰可能呈现为小面积的火苗,烟雾则可能弥漫成大面积团状,目标尺度差异极大。多尺度特征融合使得网络能够在不同尺度的特征图上分别检测小目标和大目标,显著提升了对中小火焰和稀薄烟雾的召回率,同时避免了大面积烟雾被漏检。
检测头方面,YOLOv8采用了完全解耦的检测头设计,将分类分支和回归分支分离为两个独立的子网络。每个分支各自包含若干卷积层,分别负责预测目标的类别概率和边界框坐标。这种解耦设计避免了分类与回归任务之间的特征竞争,使得每个分支能够专注于学习自身所需的特征表示,从而加速收敛并提升最终精度。相比YOLOv5中使用的耦合检测头(分类和回归共享部分特征),解耦头在训练时梯度更新更清晰,尤其适用于类别数较少但目标形态多变的火焰烟雾场景。
与YOLOv5和YOLOv7相比,YOLOv8在多个关键点上进行了改进。首先,骨干网络从C3升级为C2f,梯度流更丰富且参数效率更高,使得特征提取能力显著增强。其次,检测头从耦合式改为解耦式,分类与回归分离,减少了任务冲突,提升了训练稳定性和检测精度。第三,YOLOv8引入了无锚框(anchor-free)检测范式,并采用TaskAlignedAssigner作为正样本分配策略,根据分类与回归的联合得分动态匹配正负样本,替代了传统的基于IoU的分配方式,从而更灵活地适应不同形状和尺度的目标。此外,损失函数也进行了优化,例如使用分布焦点损失(DFL)来更精细地回归边界框,这些改进共同推动了YOLOv8在COCO等基准数据集上的性能提升。
基于上述分析,本项目最终选择yolov8s.pt作为基础权重。yolov8s是YOLOv8系列中的小模型版本,在参数量和推理速度之间取得了良好平衡,适合部署在实时检测系统中。输入分辨率设置为640, 640,这是YOLOv8官方推荐的默认尺寸,既能保证对中等尺度火焰和烟雾目标的足够分辨率,又不会因过大分辨率导致计算开销激增。训练轮数定为100轮,结合本数据集的实际规模(约数千张标注图像),该轮数足以使模型充分收敛,同时通过早停机制和验证集监控可有效防止过拟合,最终获得稳定且泛化能力良好的火焰烟雾检测模型。
系统设计
数据集
本项目使用的数据集为真实场景下采集的火焰烟雾检测数据集图像,专用于火焰烟雾检测数据集检测任务。数据图像来自实际现场拍摄,覆盖了多种典型场景,确保了数据的真实性与多样性。
数据集共包含 10335 张 已标注图像,具体划分为:
- 训练集:8420 张图像
- 验证集:1915 张图像
数据集共包含 3 个检测类别:'fire', 'smoke', 'other'
数据集各类别数目分布情况如下: 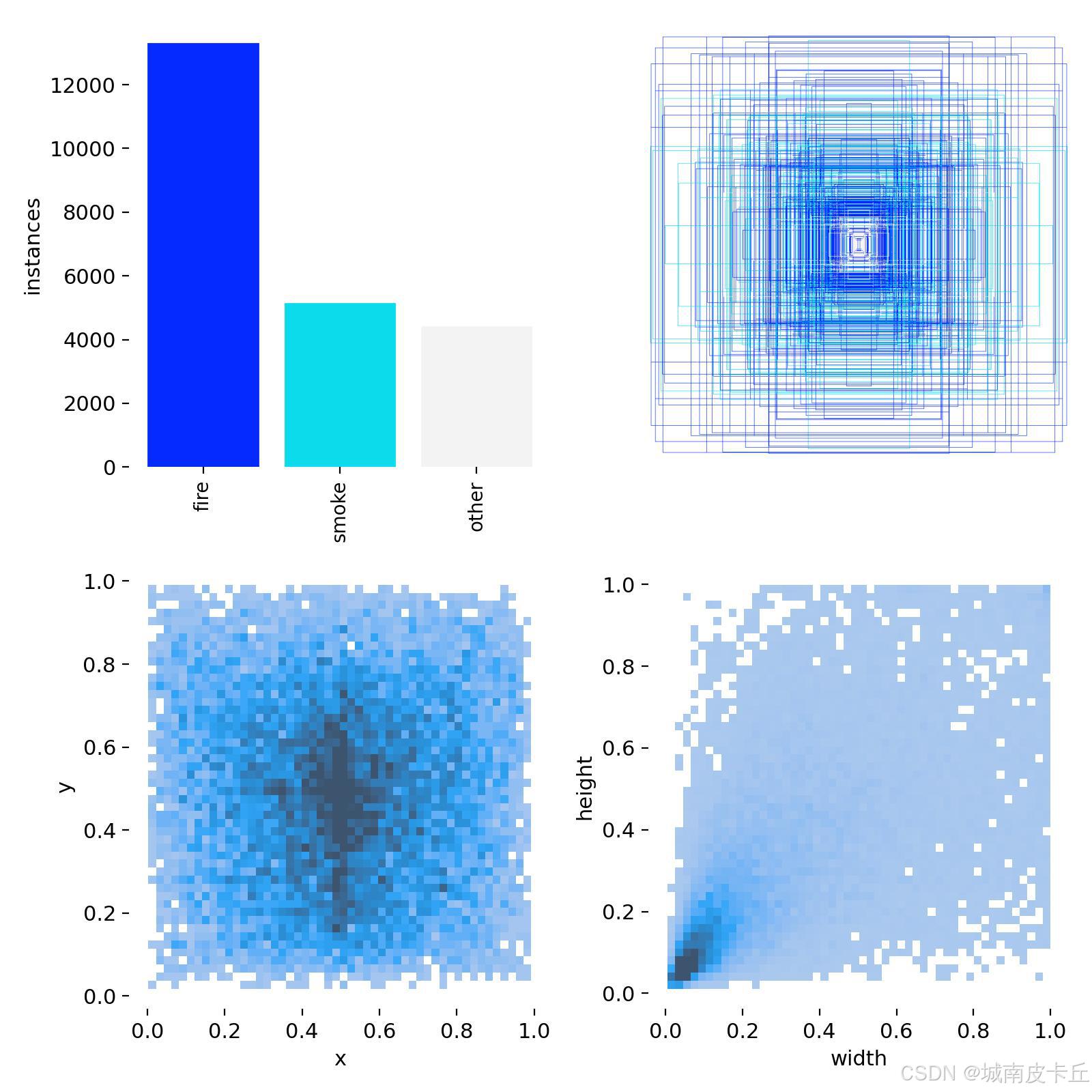
部分图像及标注如下图所示: 
YOLO 在进行模型训练时,会读取 data.yaml 文件中的训练集、验证集路径以及检测类别信息。本文数据集的 data.yaml 内容如下:
train: E:\datasets\det_fire_smoke_yolo\train\images
val: E:\datasets\det_fire_smoke_yolo\val\images
nc: 3
names: ['fire','smoke','other']
#火焰、烟雾、其它模型训练
本文基于YOLOv8进行模型训练。首先安装 Ultralytics:
pip install ultralytics模型常用训练超参数说明:
- epochs :训练轮数,本文设置为
100 - batch :批次大小,本文设置为
128 - imgsz :输入图像尺寸,本文设置为
[640, 640] - optimizer :优化器,本文使用
auto
训练后评估
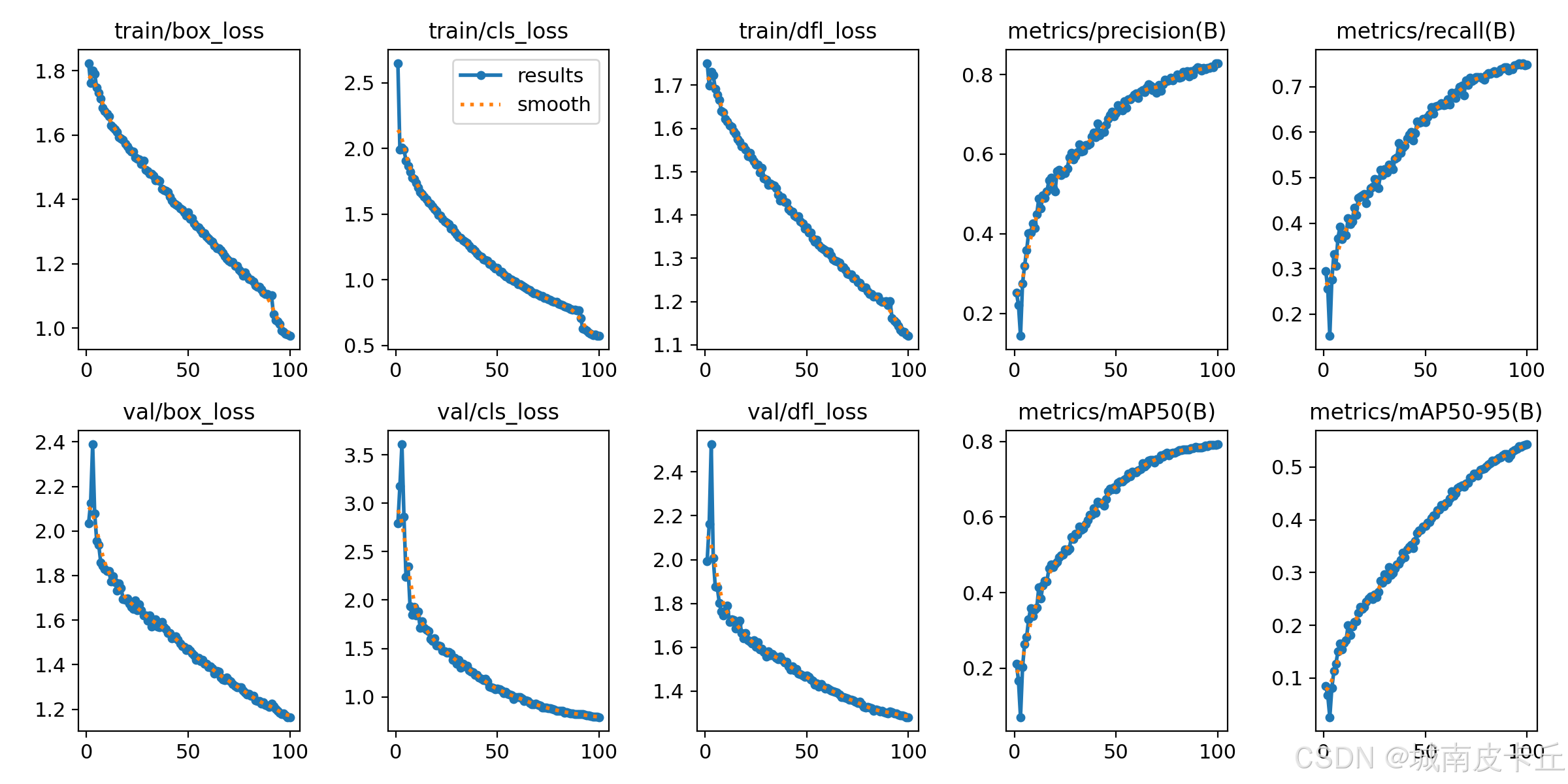
模型训练完成后,必须对其性能进行科学评估,以判断其在实际应用中的可靠性。常用的评估指标包括 精确率-召回率曲线(PR曲线) 和 平均精度(mAP)。
本文训练过程的 loss/metrics 曲线如下图所示:
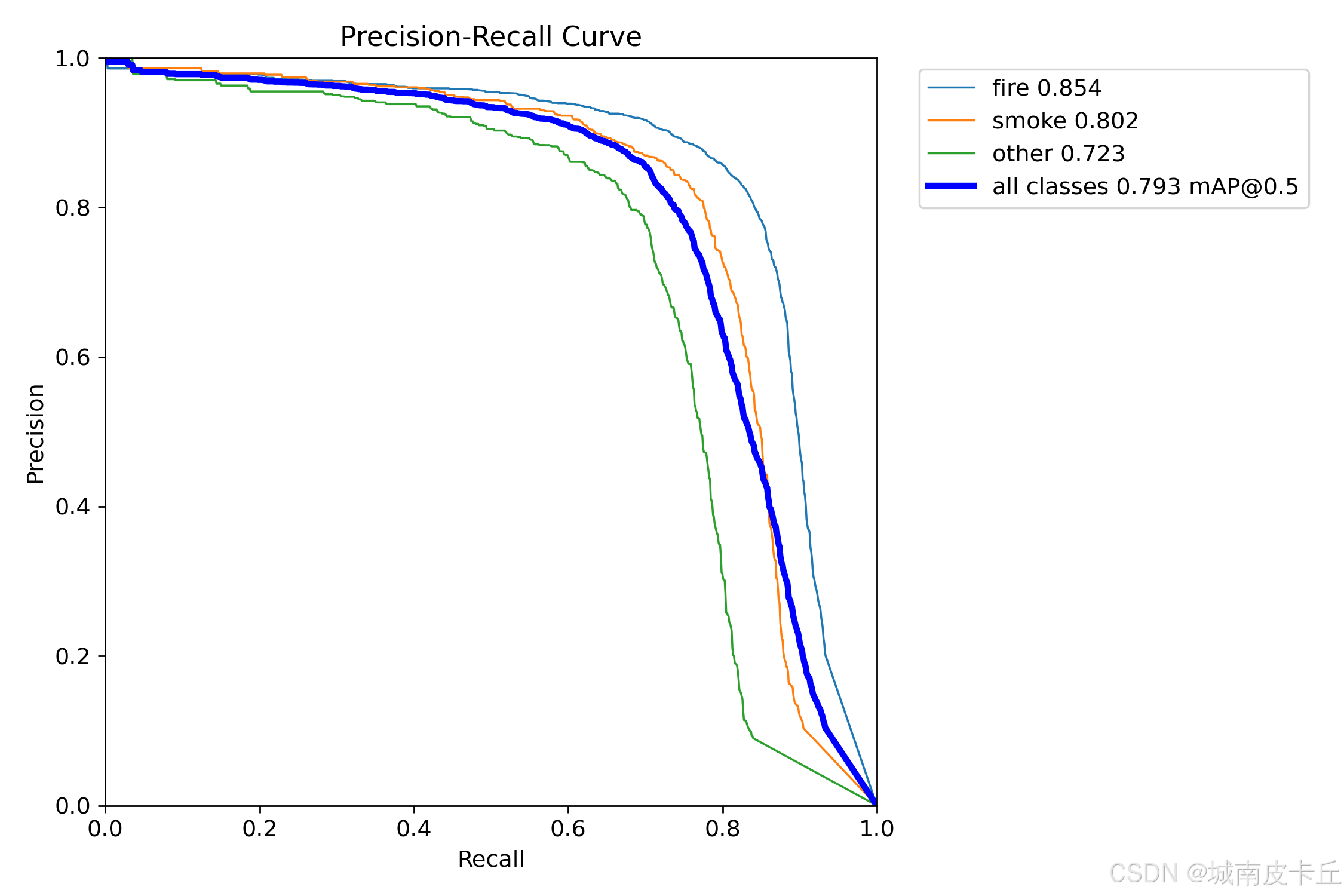
PR 曲线 描述了在不同置信度阈值下,模型的精确率(Precision)与召回率(Recall)之间的关系。
- 精确率(Precision):预测为正类的样本中,实际为正类的比例
Precision = \\frac{TP}{TP + FP}
- 召回率(Recall):实际为正类的样本中,被正确预测为正类的比例
Recall = \\frac{TP}{TP + FN}
- mAP(mean Average Precision):所有类别 Average Precision 的平均值,是衡量模型综合性能的核心指标。
- mAP@0.5:IoU 阈值为 0.5 时的 mAP,反映较宽松匹配下的检测精度。
- mAP@0.5:0.95:IoU 阈值从 0.5 到 0.95 步进 0.05 的平均 mAP,更严格,反映高精度匹配下的整体表现。
本文模型目标检测的 mAP@0.5 = 0.793 ,mAP@0.5:0.95 = 0.543 ,Precision = 0.829 ,Recall = 0.749。
PR 曲线如下图所示:
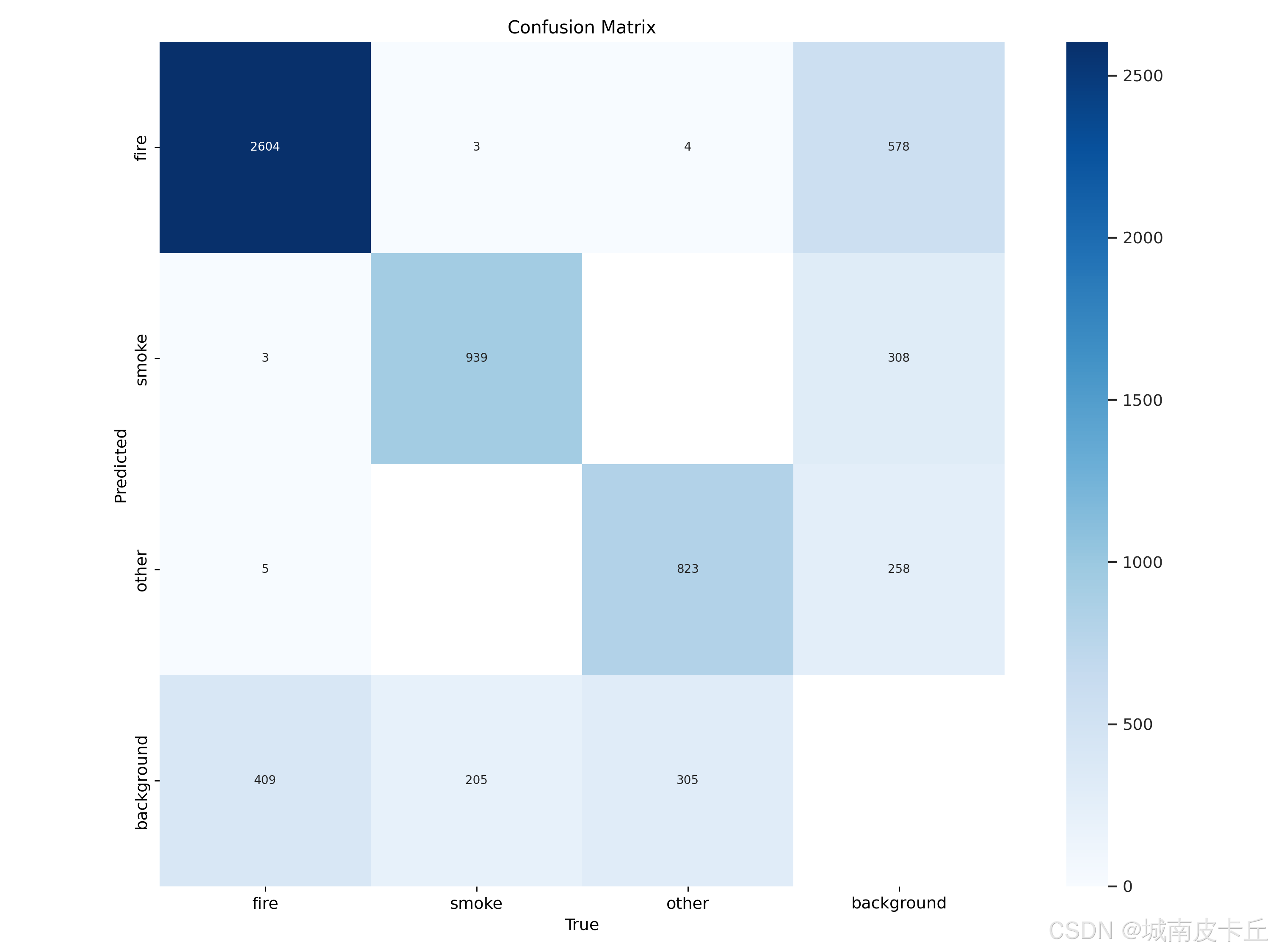
混淆矩阵如下:
模型推理
使用训练好的 best.pt 进行推理,支持图片、视频和摄像头三种检测模式。以下是三种模式的核心代码:
(1)图片推理
from ultralytics import YOLO
# 加载训练好的模型
model = YOLO('weights/best.pt')
# 对图片进行推理
results = model('test.jpg')
# 可视化检测结果并保存
res_plotted = results[0].plot()
import cv2
cv2.imwrite('result.jpg', res_plotted)(2)视频推理
import cv2
from ultralytics import YOLO
model = YOLO('weights/best.pt')
cap = cv2.VideoCapture('test.mp4')
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
results = model(frame)
annotated = results[0].plot()
cv2.imshow('YOLO Detection', annotated)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()(3)摄像头实时检测
import cv2
from ultralytics import YOLO
model = YOLO('weights/best.pt')
cap = cv2.VideoCapture(0) # 0 表示默认摄像头
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
results = model(frame)
annotated = results[0].plot()
cv2.imshow('Live Detection', annotated)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()系统 UI 设计
系统整体采用前后端分离的架构,后端基于 Flask 框架,通过蓝图(Blueprint)将不同功能模块解耦为独立的子路由集合:用户管理蓝图处理登录、注册、权限校验;检测蓝图负责图片、视频、摄像头流的接收与推理结果返回;配置蓝图管理模型权重路径、推理设备选择等系统参数。模型推理逻辑被封装为独立的服务类,与 Flask 路由层通过依赖注入方式解耦,路由仅负责解析请求参数、调用推理服务并返回 JSON 响应,推理服务内部加载 ONNX 或 PyTorch 模型,支持 CPU/GPU 切换,并维护独立的推理队列以避免阻塞 Web 线程。SQLite 数据库通过 SQLAlchemy ORM 管理用户表、检测记录表、配置表,数据操作集中在模型层,路由层不直接操作数据库,保证了代码的清晰与可维护性。
前端采用 Layui 模块化框架,利用其表格组件(table)展示检测记录列表,支持分页、搜索、排序,通过 lay-filter 绑定工具栏实现批量删除与导出;表单组件(form)用于用户信息编辑与模型配置修改,配合 lay-verify 实现前端校验;上传组件(upload)支持单图、多图、视频文件拖拽上传,自动触发 AJAX 请求至后端接口。前端所有数据交互均通过 jQuery 封装的 AJAX 方法完成,遵循 RESTful 风格:GET 请求获取列表与详情,POST 提交检测任务,PUT 更新配置,DELETE 删除记录。响应数据统一封装为 {code, msg, data} 格式,前端根据 code 判断业务成功与否,并在 layer 弹窗中展示提示信息,实现无刷新交互体验。
检测流程的交互实现遵循清晰的时序:用户通过 Layui 上传组件选择图片或视频文件,前端立即调用 FormData 构造 multipart 请求,异步 POST 至 /detect/image 或 /detect/video 接口。后端接收文件后,将其保存至临时目录,调用推理服务返回检测结果 JSON,字段约定包括:detections 数组(每个元素含 bbox: x1,y1,x2,y2、confidence、class_name)、image_width、image_height、elapsed_time。前端收到响应后,利用 Canvas 在原始图片或视频帧上绘制边界框:首先通过 new Image() 加载原图,在 onload 回调中设置 Canvas 尺寸与原始分辨率一致,然后遍历 detections,使用 ctx.strokeRect 绘制矩形框,根据 class_name 选择不同颜色(火焰为红色,烟雾为橙色),并在框左上角填充置信度文本。对于视频检测,后端逐帧处理并返回帧结果列表,前端通过 requestAnimationFrame 循环播放并实时更新 Canvas 覆盖层。摄像头实时检测则通过 MediaDevices.getUserMedia 获取视频流,每隔 200ms 截取一帧发送至 /detect/camera 接口,结果同样以 Canvas 叠加显示,实现低延迟预览。
部署与配置方面,系统通过 config.py 集中管理关键参数:MODEL_PATH 指定权重文件路径,DEVICE 可选 "cpu" 或 "cuda:0",THRESHOLD 控制检测置信度阈值,UPLOAD_FOLDER 定义临时文件存储目录,DATABASE_URI 指向 SQLite 文件路径。启动时自动检测 GPU 可用性并回退至 CPU,用户也可在管理界面动态修改 DEVICE 与 THRESHOLD,修改后立即生效无需重启服务。所有配置项均通过 Layui 表单展示,支持持久化至数据库,确保系统灵活适应不同硬件环境与检测精度需求。
系统主界面如下图所示:
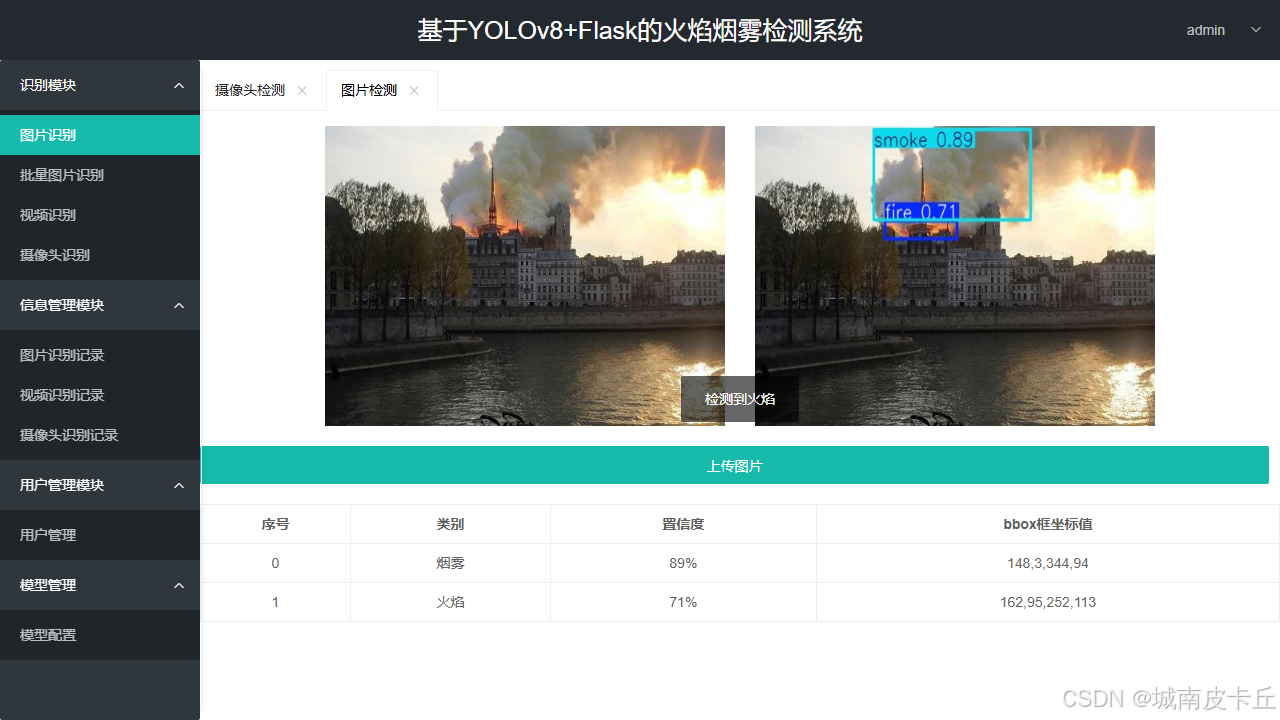
系统功能
基于训练好的目标检测模型,本系统具备以下核心功能:
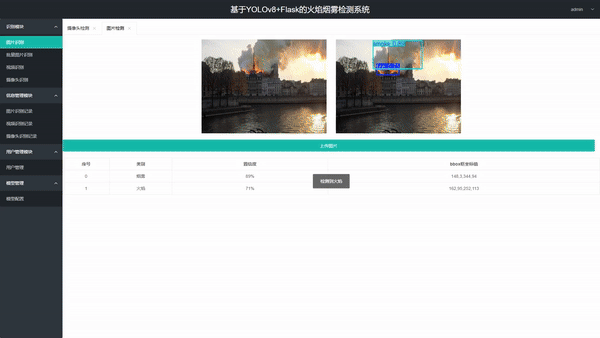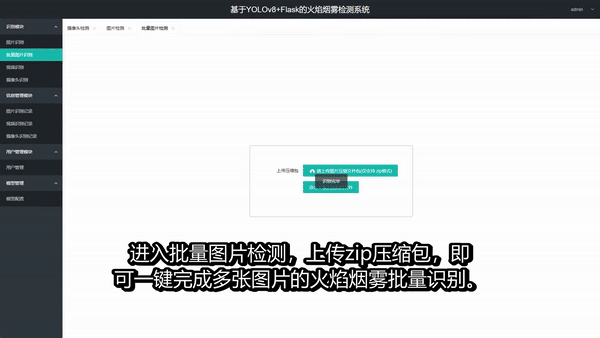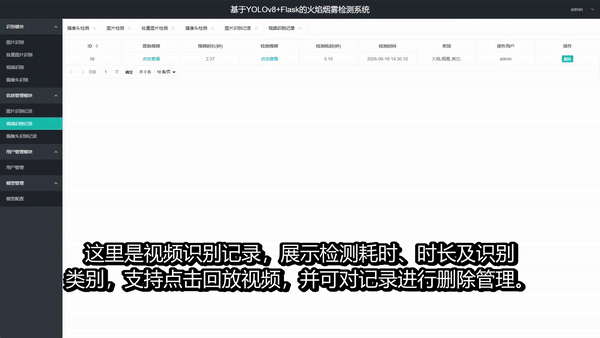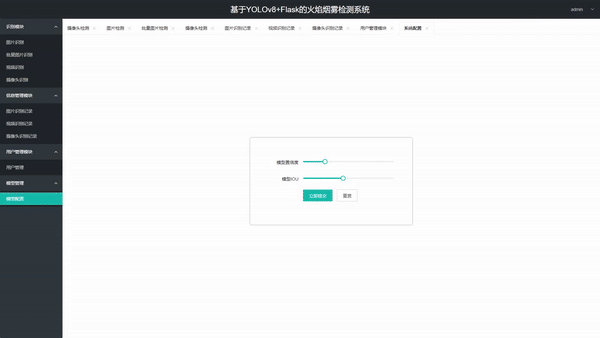
1. 多模式检测支持 - 图片上传检测(单张/批量) - 视频文件上传检测 - 本地摄像头实时检测
2. 可调节推理参数 - 用户可动态调整置信度阈值(conf) - 用户可动态调整 IoU 阈值
3. 可视化检测结果 - 在图像/视频上绘制边界框和类别标签 - 实时显示目标位置、目标总数、置信度、用时等信息
4. 结构化结果输出 - 表格展示每个检测目标的序号、类别、置信度和坐标 - 统计每类目标的检测总数 - 支持将检测结果保存为 CSV 文件
5. 跨设备兼容 - 自动判断是否支持 GPU,优先使用 GPU 加速 - 支持主流浏览器访问(Chrome / Edge / Firefox)
总结
本文基于YOLOv8与Flask框架构建了一套火焰烟雾检测数据集的可视化检测系统,完整覆盖了从数据标注、格式转换、模型训练、性能评估到Web端部署的全流程。数据集共包含10335张图片,涵盖fire、smoke、other三个类别,其中训练集8420张、验证集1915张。训练采用yolov8s.pt作为基础权重,输入分辨率固定为640, 640,batch size设为128,优化器选择auto,共迭代100轮。训练完成后,模型在验证集上的Precision达到0.829,Recall为0.749,mAP@0.5为0.793,mAP@0.5:0.95为0.543。Web系统基于Flask搭建,支持图片上传与实时检测,检测结果以边界框和置信度形式可视化呈现,整体流程具备较好的工程化与可复现性。
从实际效果来看,模型对火焰的检测准确率较高,尤其在明火区域边界清晰时能够稳定检出;但烟雾检测存在一定挑战,由于烟雾形态多变、边缘模糊且常与背景(如雾气、云层)混淆,导致Recall相对偏低,部分半透明烟雾被漏检或误判为other类别。此外,小目标检测是当前模型的明显短板------远处的小火苗或稀薄烟羽在640×640分辨率下像素占比极低,容易丢失特征,实测中mAP@0.5:0.95仅为0.543也印证了定位精度的不足。推理速度方面,在单张NVIDIA GPU上处理单帧图像耗时约15-20ms(含预处理和后处理),基本满足实时视频流需求,但若部署在CPU或边缘设备上则需进一步优化。训练过程中还观察到类别间混淆问题:部分深色烟雾与暗色背景下的other类物体(如黑色车辆、阴影)特征相似,导致误报;而火焰与强光反射也存在少量误检,说明模型对纹理和颜色特征的区分能力仍有提升空间。
针对上述不足,后续可从三个方向进行改进。数据增强方面,可引入Mosaic、MixUp等策略增加样本多样性,并针对烟雾合成更多半透明、渐变形态的标注数据,缓解类别不平衡与边界模糊问题。模型规模上,尝试yolov8m或yolov8l作为骨干,或嵌入CBAM、SE等注意力机制以增强对小目标和模糊目标的特征提取能力。推理优化方面,采用TensorRT进行模型量化与加速,结合FP16推理和NMS后处理优化,可将延迟压缩至10ms以内,同时保持精度不显著下降,从而更好地适配边缘端部署场景。
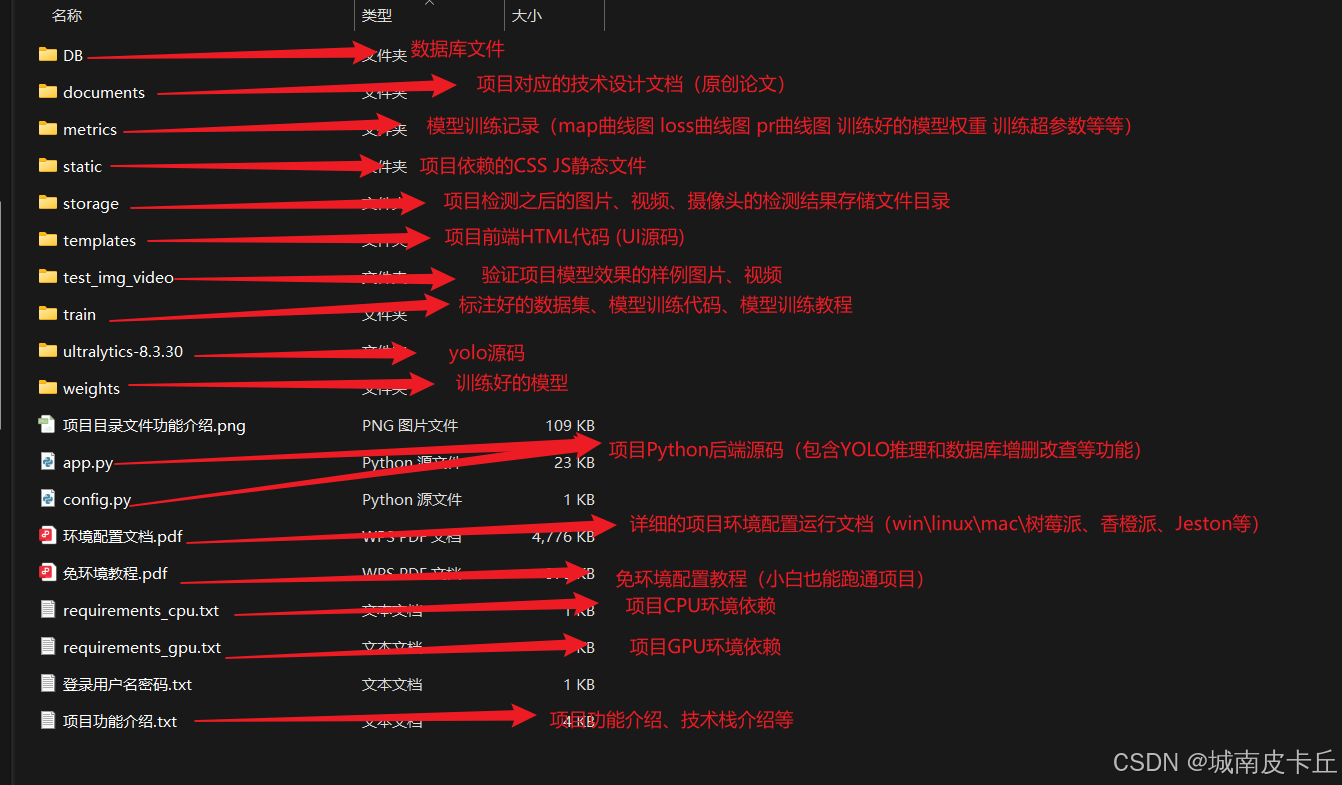
随项目附带的源码文件结构说明:
随项目附带的设计说明书(docx)缩略图:
