
子玥酱 (掘金 / 知乎 / CSDN / 简书 同名)
大家好,我是 子玥酱,一名长期深耕在一线的前端程序媛 👩💻。曾就职于多家知名互联网大厂,目前在某国企负责前端软件研发相关工作,主要聚焦于业务型系统的工程化建设与长期维护。
我持续输出和沉淀前端领域的实战经验,日常关注并分享的技术方向包括 前端工程化、小程序、React / RN、Flutter、跨端方案,
在复杂业务落地、组件抽象、性能优化以及多端协作方面积累了大量真实项目经验。
技术方向: 前端 / 跨端 / 小程序 / 移动端工程化 内容平台: 掘金、知乎、CSDN、简书 创作特点: 实战导向、源码拆解、少空谈多落地 **文章状态:**长期稳定更新,大量原创输出
我的内容主要围绕 前端技术实战、真实业务踩坑总结、框架与方案选型思考、行业趋势解读 展开。文章不会停留在"API 怎么用",而是更关注为什么这么设计、在什么场景下容易踩坑、真实项目中如何取舍,希望能帮你在实际工作中少走弯路。
子玥酱 · 前端成长记录官 ✨
👋 如果你正在做前端,或准备长期走前端这条路
📚 关注我,第一时间获取前端行业趋势与实践总结
🎁 可领取 11 类前端进阶学习资源 (工程化 / 框架 / 跨端 / 面试 / 架构)
💡 一起把技术学"明白",也用"到位"
持续写作,持续进阶。
愿我们都能在代码和生活里,走得更稳一点 🌱
文章目录
-
- 引言
- [一、为什么单 Agent 会走向失控](#一、为什么单 Agent 会走向失控)
- [二、Multi-Agent 的本质是什么](#二、Multi-Agent 的本质是什么)
- [三、经典 Multi-Agent 架构](#三、经典 Multi-Agent 架构)
- [四、Planner Agent:系统的大脑](#四、Planner Agent:系统的大脑)
- [五、Worker Agent:专业分工](#五、Worker Agent:专业分工)
- [六、Agent 之间如何通信](#六、Agent 之间如何通信)
-
- [Shared Memory](#Shared Memory)
- [Message Queue](#Message Queue)
- [Event Driven](#Event Driven)
- [七、Memory Center 才是真正难点](#七、Memory Center 才是真正难点)
- [八、为什么需要 Supervisor Agent](#八、为什么需要 Supervisor Agent)
- [九、真正的成本黑洞:Context Sync](#九、真正的成本黑洞:Context Sync)
- [十、Multi-Agent 正在走向 Agent Operating System](#十、Multi-Agent 正在走向 Agent Operating System)
- 总结
引言
过去两年,Agent 几乎成为整个 AI 行业最火的方向。从:
text
ChatGPT
Copilot
Claude
Manus
OpenAI Operator到各种 Agent Framework:
text
LangGraph
AutoGen
CrewAI
OpenAI Agents SDK大家都在试图解决一个问题:
如何让 AI 真正完成复杂任务?
于是很多团队的第一反应都是:
text
Prompt 更长
工具更多
上下文更大
模型更强最终打造出一个:
text
Super Agent看起来:
text
会写代码
会搜索
会分析
会测试
会部署似乎无所不能,但真正落地后,大多数团队都会遇到同样的问题:
text
上下文越来越长
推理成本越来越高
Prompt 越来越复杂
能力互相干扰
系统越来越难维护甚至很多 Agent 项目最终都会演变成:
一个几万 Token Prompt + 几十个 Tool 的怪物。
结果是:
text
能力没有变强
成本却越来越高于是,行业开始出现一个新的共识:
不是让一个 Agent 学会所有事情,而是让多个 Agent 像团队一样协作。
从:
text
Single Agent到:
text
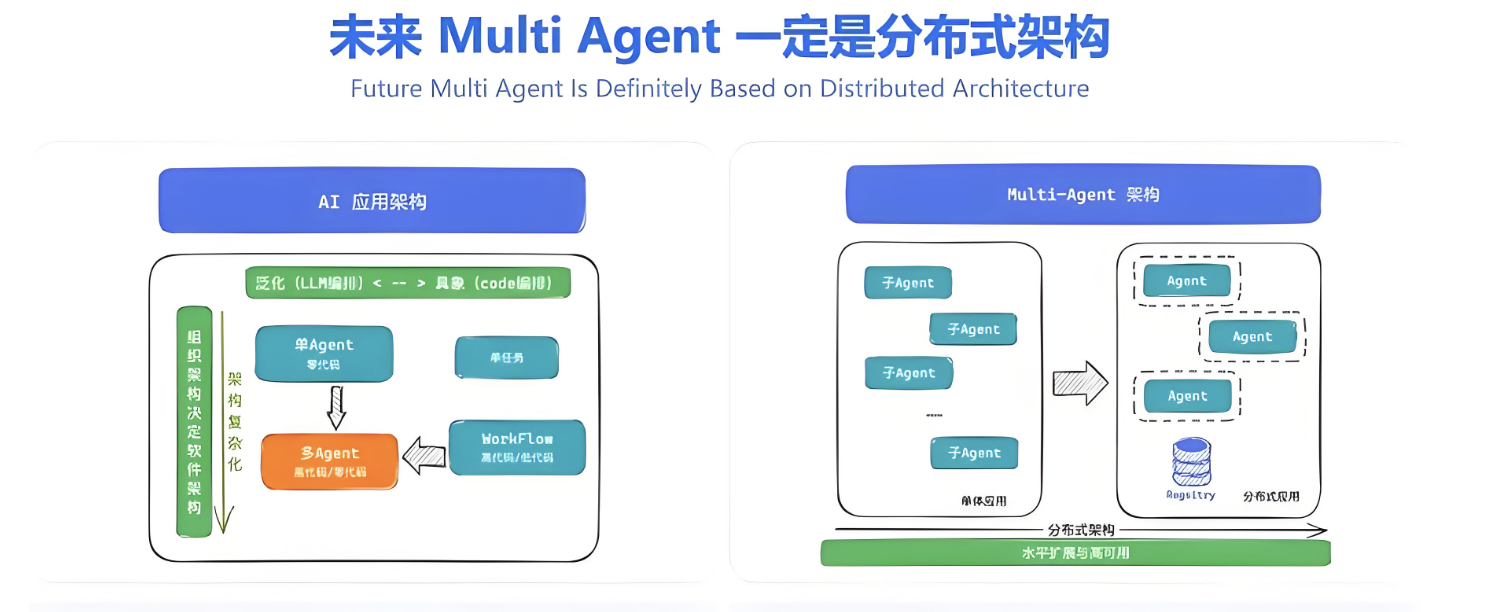
Multi-Agent背后其实不是简单的 Agent 数量增加,而是 AI 系统架构的一次升级。
一、为什么单 Agent 会走向失控
先看一个 Coding Agent,需求:
text
开发一个电商 App如果只有一个 Agent,它需要负责:
text
需求分析
架构设计
代码生成
测试
部署
Bug 修复于是 Prompt 会越来越大:
text
System Prompt
+
历史上下文
+
Memory
+
Tools
+
当前任务最终:
text
30K Token
50K Token
100K Token成为常态,看起来模型变聪明了,实际上:
Token 成本暴涨
上下文越长:
text
Attention Cost
↑
KV Cache
↑
Latency
↑能力互相污染
例如:
text
Coding Prompt
Review Prompt
Research Prompt混在一起,导致:
text
角色冲突
推理质量下降Tool Explosion
工具数量:
text
10
↓
50
↓
100最终模型不知道:
text
什么时候该调用哪个 Tool上下文爆炸
很多时候:
text
真正有用的信息
<10%而:
text
90%
都是历史垃圾信息于是问题出现:
为什么一定要让一个 Agent 完成所有事情?
二、Multi-Agent 的本质是什么
很多人理解:
text
Multi-Agent
=
多个 Agent实际上不准确,真正的定义应该是:
Multi-Agent = 分布式智能系统。
类似于,传统单体应用:
text
Monolithic逐渐演化成:
text
Microservice同样,Single Agent:
text
Super Agent正在演化成:
text
Agent Service Mesh从:
text
一个大脑变成:
text
多个专业大脑协同本质上:
text
单体智能
↓
系统智能这也是 Multi-Agent 最大的价值。
三、经典 Multi-Agent 架构
一个企业级系统通常长这样:
text
User
↓
┌──────────────┐
│ Planner Agent│
└──────┬───────┘
↓
┌────────┬─────────┬─────────┐
↓ ↓ ↓
Research Coding Testing
Agent Agent Agent
↓ ↓ ↓
└────────┴─────────┘
↓
Review Agent
↓
Supervisor
↓
Output整个系统实际上分成六层:
text
Planning Layer
Execution Layer
Memory Layer
Communication Layer
Governance Layer
Runtime Layer越来越像:
text
操作系统而不是:
text
聊天机器人四、Planner Agent:系统的大脑
Planner Agent 是整个系统的入口,负责:
text
任务拆解
依赖分析
任务调度
结果聚合例如,用户输入:
text
开发一个 Todo AppPlanner 会自动拆解:
python
tasks = [
"generate_ui",
"write_backend",
"write_test",
"deploy"
]形成:
text
Task DAG而不是:
text
一步到位生成所有代码本质上:
Planner Agent 更像 Kubernetes Scheduler。
负责:
text
资源调度
任务编排而不是执行。
五、Worker Agent:专业分工
真正执行任务的是:
text
Research Agent
Coding Agent
Review Agent
Testing Agent每个 Agent 拥有:
text
独立 Prompt
独立 Tool
独立 Memory例如,Coding Agent:
text
只生成代码Review Agent:
text
只检查代码Testing Agent:
text
只负责测试这样:
Context 更短
text
5K Token而不是:
text
100K Token推理质量更高
避免:
text
角色污染成本更低
减少:
text
Attention Cost本质上:
Multi-Agent 的核心是上下文隔离。
六、Agent 之间如何通信
这是 Multi-Agent 最大难点。
Shared Memory
所有 Agent 共用:
python
redis_memory优点:
text
简单缺点:
text
容易冲突Message Queue
类似:
text
Kafka
RabbitMQ流程:
text
Planner
↓
MQ
↓
Worker Agent优点:
text
解耦适合:
text
企业级系统Event Driven
事件驱动:
text
CodeGenerated
↓
ReviewAgent Triggered类似:
text
EDA这也是 LangGraph 的核心思想。
七、Memory Center 才是真正难点
很多团队刚开始,每个 Agent:
text
独立 Memory结果很快发现:
text
信息不同步
状态混乱
重复推理于是逐渐演化出:
text
Memory Center统一管理:
1、Short Memory ➡️ Session
2、Long Memory ➡️ Vector DB
3、Semantic Memory ➡️ Knowledge Graph
4、State Memory ➡️ Redis
形成:
text
Memory Bus整个系统共享知识,越来越像:
text
Distributed Cache八、为什么需要 Supervisor Agent
随着 Agent 数量增加,新的问题出现:
无限循环
text
A → B → C → A重复执行
text
重复调用 ToolToken 爆炸
上下文不断复制。
Agent 崩溃
任务卡死,于是需要:
text
Supervisor Agent负责:
text
Retry
Timeout
Circuit Breaker
Rollback
Kill Task看到这里会发现:
Supervisor 很像微服务中的 Service Mesh。
负责:
text
治理而不是业务。
九、真正的成本黑洞:Context Sync
很多人以为,Multi-Agent 最大成本来自:
text
模型调用次数其实不是,真正昂贵的是:
text
Context Sync例如:
text
Agent A
↓
Agent B
↓
Agent C如果每次都复制:
text
20K Token成本会指数增长,于是出现:
1、Context Compression ➡️ 上下文压缩
2、Shared Memory ➡️ 共享状态
3、State Reference ➡️ 引用而非复制
4、Incremental Context ➡️ 增量同步
这也是 Agent Runtime 正在解决的问题。
十、Multi-Agent 正在走向 Agent Operating System
越来越多团队发现,真正需要管理的已经不是:
text
Prompt而是:
text
Agent 生命周期
Memory
Tool
Task
State
Communication整个系统开始长成:
text
Agent OS
↓
┌────────────────────┐
│ Scheduler │
├────────────────────┤
│ Memory Center │
├────────────────────┤
│ Tool Registry │
├────────────────────┤
│ Communication Bus │
├────────────────────┤
│ Supervisor Layer │
└────────────────────┘越来越像:
text
Kubernetes
+
Operating System而不是:
text
ChatBot Framework总结
如果用一句话理解 Multi-Agent:
Multi-Agent 不是让 AI 拥有更多 Agent,而是让 AI 从"单体应用"进化成"分布式系统"。
其核心架构可以概括为:
text
Planner
+
Worker
+
Memory Center
+
Communication Bus
+
Supervisor
+
Runtime过去:
text
ChatBot
↓
Copilot
↓
Single Agent未来正在走向:
text
Multi-Agent
↓
Agent Runtime
↓
Agent Operating System
↓
Autonomous System最终,AI 系统竞争的核心,很可能不再是谁拥有最强的大模型。
而是谁能够构建出:
一个稳定、高效、可扩展的智能体操作系统。