AI生成测试用例这事儿,很多人试过,很多人放弃了。原因几乎都一样:生成的用例数量不少,能直接用的比例太低。要么测试点遗漏了关键场景,要么用例描述太泛没法执行,要么格式五花八门还得人工重新排版。
问题出在哪?不是模型不行,是Skill没写好。一个需求到用例的Agent,至少要过四道关------分析需求文档、提取测试点、生成测试用例、测试用例评审。每道关的输入输出、处理逻辑、边界条件都不一样。你要是把这四件事全塞进一个Skill里,跟写一个巨型Prompt没区别,最后就是啥都沾点啥都不精。
我前前后后写了三版需求解析的Skill,翻了不少车,也慢慢摸索出一套拆法。这篇文章把我怎么拆、怎么写、每一步出了什么问题,完整记录下来。
01 先想清楚:四件事还是一件事
一开始我的想法很简单------一个Skill搞定一切。需求文档扔进去,测试用例吐出来,多省事。
第一版Skill就是这么写的:一个入口函数,里面按顺序调用分析需求、提取测试点、生成用例、格式化输出。代码看起来很整洁,跑起来也确实能出结果。
但问题很快就来了。
最大的问题是:中间任何一步出错了,后面全跟着错。需求分析把一个条件判断理解成了状态流转,提取测试点就按状态流转来拆,生成的用例自然全跑偏。等看到最终结果,你根本不知道是哪一步开始歪的。
还有一个问题:四步的逻辑差异很大。分析需求文档偏理解,需要上下文窗口和文档解析能力;提取测试点偏推理,需要测试设计方法论的知识注入;生成用例偏结构化,需要严格遵循模板格式;用例评审偏判断,需要跟已有用例和历史Bug做比对。
混在一起写,提示词要兼顾四种完全不同的思维模式,结果就是哪头都不讨好。分析需求的时候提示词里还在讲用例模板格式,生成用例的时候又提需求文档的段落结构,互相干扰。
后来我改成了四个独立Skill,各管各的。每个Skill只关心自己的输入和输出,不操心上下游怎么衔接。Agent负责调度------先调Skill A,拿到结果喂给Skill B,以此类推。
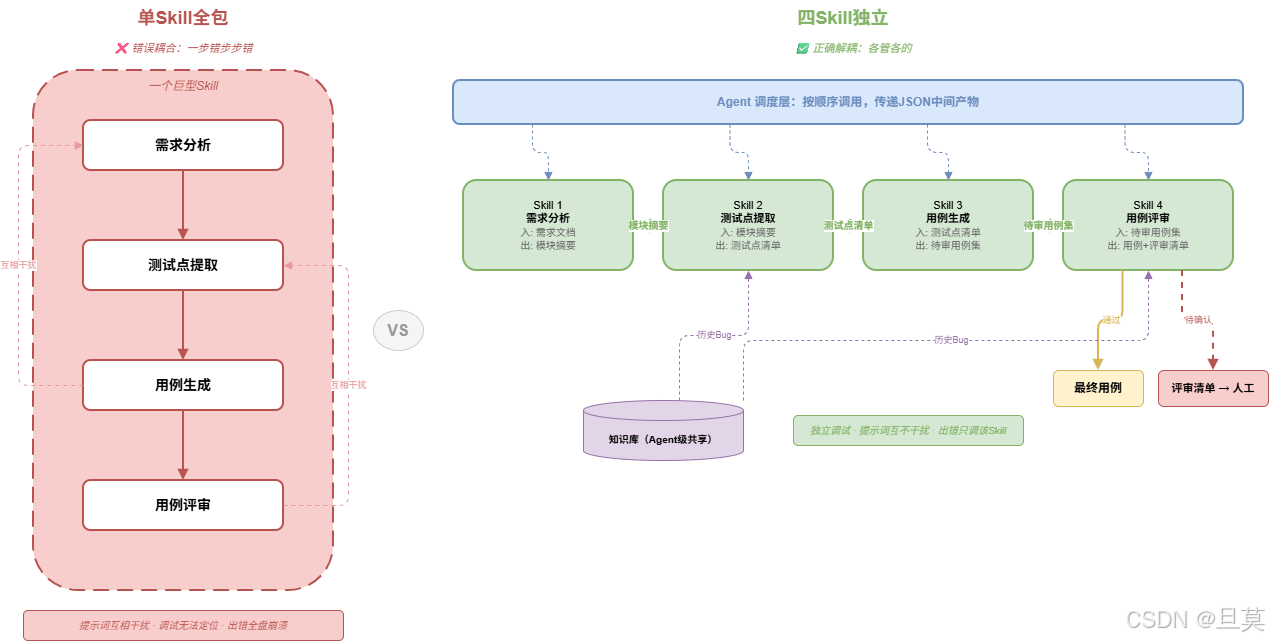
这改完之后,调试效率直接翻了好几倍。哪一步出了问题,单独调那个Skill就行,不用每次从头跑到尾。
02 第一个Skill:分析需求文档
这个Skill看着最简单,实际上最容易被忽视。
很多人觉得需求文档不就是一段文字吗,AI直接读就完了。但你实际跑起来就会发现,需求文档的格式千奇百怪:有的用Markdown写得很规范,有的用Word嵌套了七八层表格,有的是Excel里一行一个字段,还有的是XMind思维导图。
你的Skill如果只处理纯文本,那遇上Excel和XMind就傻眼了。
文档解析怎么做
我第一版只支持Markdown和纯文本。结果第一个真实需求就是Excel格式,直接翻车。
后来加了多格式解析器,按文件后缀走不同的解析逻辑:
python
def parse_document(file_path: str) -> str:
"""按文件类型选择解析器"""
ext = Path(file_path).suffix.lower()
parsers = {
".md": parse_markdown,
".txt": parse_text,
".docx": parse_docx,
".pdf": parse_pdf,
".xlsx": parse_excel,
".xmind": parse_xmind,
".png": parse_image, # 多模态,直接调VLM
}
parser = parsers.get(ext)
if not parser:
raise ValueError(f"不支持的文件格式: {ext}")
return parser(file_path)这里面有几个问题值得说。
问题一:Excel解析不是读文本那么简单
需求文档的Excel通常不是规整的表格。有的合并单元格一大片,有的在sheet里混着注释和备注,有的字段名写在A列但值跑到D列去了。你如果只是用pandas读成DataFrame再to_string,丢信息丢得比AI还多。
我的做法是:先做预处理,把合并单元格拆开填值,把空行空列删掉,把多级表头打平。然后再按行遍历,把每行的"字段名-值"对拼接成结构化文本。
问题二:长文档的上下文截断
一个中等规模的需求文档,解析成纯文本大概5000-8000字。这个长度对大多数模型来说已经接近舒适区的上限了,如果再塞进提示词模板和输出要求,很容易超限。
我的处理方式是分段解析。先提取文档的大纲结构(标题层级),然后按功能模块分段喂给AI。每段只处理一个模块,最后再汇总。
python
def split_by_modules(doc_text: str) -> list[dict]:
"""按功能模块拆分长文档"""
# 先提取标题层级
sections = extract_sections(doc_text)
modules = []
for section in sections:
if section.level <= 2: # 只拆到二级标题
modules.append({
"module_name": section.title,
"content": section.text,
"sub_modules": [s.title for s in section.children]
})
return modules问题三:图片和流程图
有些需求文档里嵌了UI设计稿或者业务流程图。纯文本解析器直接跳过图片,这些信息就全丢了。
我加了一个图片解析器,走多模态模型。把图片转成base64喂给VLM,让它描述图片内容,然后把描述文本跟文档正文合并。效果不算完美,但比直接丢掉强太多。
这个Skill的输出是什么
分析需求文档这个Skill,输出不是测试用例,也不是测试点,而是一份结构化的需求摘要。大概长这样:
json
{
"modules": [
{
"name": "用户登录",
"description": "支持手机号+验证码和账号密码两种登录方式",
"business_rules": [
"验证码60秒有效期",
"密码错误5次锁定30分钟",
"首次登录强制修改密码"
],
"dependencies": ["短信服务", "用户中心"],
"abnormal_scenarios": [
"网络超时",
"验证码过期",
"账户冻结"
]
}
],
"cross_module_flows": [
"登录成功后跳转首页,首页需显示用户昵称"
],
"implicit_requirements": [
"切换登录方式时已输入的内容需清空"
]
}注意最后那个implicit_requirements字段。这个是Skill在分析时主动推断出来的隐性需求,不是文档里直接写的。这一步做得好不好,直接决定后面测试点的覆盖度。
03 第二个Skill:提取测试点
需求分析完了,接下来是最容易出问题的一步:提取测试点。
为什么说容易出问题?因为测试点提取这事儿,纯靠提示词的质量。提示词写得好,测试点覆盖度能到80%以上;写得不好,可能连50%都不到。我之前专门写过一篇信息损耗的文章聊过这个问题,AI直接解析需求提取测试点,跟人工提取的差距接近50%。
提示词设计的三个层次
第一版提示词我就写了一句话:"根据以下需求提取测试点"。结果生成的测试点全是正常流程,边界和异常一个没有。
第二版我加了要求:"请覆盖正常流程、边界值、异常场景"。好了一些,但AI对边界值的理解跟我理解的不一样------我说的边界值是"输入框最大长度+1",它理解的边界值是"登录成功和登录失败"。
第三版我分层设计了提示词,效果才真正上来。
第一层:测试设计原则注入
python
TEST_DESIGN_PRINCIPLES = """
测试点提取需遵循以下原则:
1. 等价类划分:每个输入字段至少覆盖有效等价类和无效等价类各一个
2. 边界值分析:数值类字段测试最小值、最小值-1、最大值、最大值+1
3. 状态转换:有状态流转的功能,每个状态转换都应覆盖
4. 错误推测:根据业务经验推测可能的错误场景
5. 组合场景:多个条件组合时,重点覆盖条件交叉的情况
"""这段不放在每次调用的提示词里,而是放在Skill的配置文件中,每次生成时自动注入。好处是维护方便------发现新的测试设计原则,加一条就行,不用改提示词模板。
第二层:业务知识补充
测试设计原则解决的是"怎么想"的问题,业务知识解决的是"想什么"的问题。
比如你测一个支付功能,测试设计原则告诉你"要考虑异常场景",但具体有哪些异常场景?网络断开、支付超时、余额不足、重复支付、并发支付------这些是业务知识,不是通用规则。
业务知识的来源有两个:一个是知识库(历史Bug记录、业务规则文档),一个是提示词中的显式补充。我的做法是优先走知识库检索,检索不到的再靠提示词兜底。
python
def build_testpoint_prompt(module: dict, kb_results: list = None) -> str:
prompt = f"""
基于以下需求模块提取测试点:
模块名称:{module['name']}
模块描述:{module['description']}
业务规则:{module['business_rules']}
异常场景:{module['abnormal_scenarios']}
"""
if kb_results:
prompt += f"""
【历史相关Bug】
{format_kb_results(kb_results)}
请参考历史Bug,针对性补充测试点。
"""
prompt += """
请按以下格式输出测试点:
- 测试点编号
- 测试类型(功能/边界/异常/兼容/性能)
- 测试描述
- 优先级(P0/P1/P2)
"""
return prompt第三层:多轮迭代
单轮提取永远不够完整。我的做法是跑三轮:第一轮提基础测试点,第二轮专门补边界和异常,第三轮做去重和合并。
python
def multi_round_extraction(module: dict) -> list:
# 第一轮:基础测试点
round1 = extract_testpoints(module, focus="basic")
# 第二轮:补充边界和异常
round2 = extract_testpoints(
module,
focus="boundary_and_exception",
context=f"已提取的测试点:{round1}"
)
# 第三轮:去重合并
all_points = round1 + round2
final = deduplicate(all_points)
return final三轮下来,测试点数量比单轮大概多30-40%,而且边界和异常场景的覆盖明显更全。
这个Skill的输出是什么
json
{
"module": "用户登录",
"test_points": [
{
"id": "LOGIN-001",
"type": "功能",
"description": "手机号+验证码正常登录",
"priority": "P0"
},
{
"id": "LOGIN-002",
"type": "边界",
"description": "验证码输入第59秒仍有效,第61秒失效",
"priority": "P1"
},
{
"id": "LOGIN-003",
"type": "异常",
"description": "密码错误第5次触发锁定,第4次不锁定",
"priority": "P1"
},
{
"id": "LOGIN-004",
"type": "异常",
"description": "登录过程中网络断开,重连后状态恢复",
"priority": "P2"
}
]
}每个测试点都有明确的类型、描述和优先级。这个输出是下一个Skill的直接输入。
04 第三个Skill:生成测试用例
到这一步,很多人才意识到:测试点和测试用例不是一回事。
测试点说的是"要测什么",测试用例说的是"怎么测"。一个测试点"密码错误5次锁定",展开成测试用例至少要写清楚:前置条件是什么、每一步操作什么、每一步期望什么结果、用什么数据。
用例模板的硬约束
测试用例不是自由文本,它有格式要求。不同团队的模板不同,但基本都包含这几个字段:用例ID、测试模块、测试描述、前置操作、测试步骤、预期结果、优先级、用例状态、备注。
我吃过最大的亏:一开始让AI自由生成用例,输出格式五花八门。有的用例写了三行步骤,有的写了三十行;有的预期结果写"功能正常",有的写了一整段描述;有的带备注有的不带。
后来我做了两件事,彻底解决了格式问题。
第一,在Skill里硬编码模板Schema。
python
TESTCASE_SCHEMA = {
"case_id": {"type": "string", "pattern": r"^[A-Z]+-\d{3}$"},
"module": {"type": "string", "max_length": 20},
"description": {"type": "string", "max_length": 100},
"precondition": {"type": "string", "required": True},
"steps": {
"type": "array",
"items": {
"step_no": {"type": "integer"},
"action": {"type": "string", "required": True},
"expected": {"type": "string", "required": True}
},
"min_items": 1
},
"priority": {"type": "string", "enum": ["P0", "P1", "P2", "P3"]},
"status": {"type": "string", "enum": ["执行", "不执行", "调试"]},
"remark": {"type": "string", "default": ""}
}AI生成之后,用Schema做校验。格式不对的直接打回去让它重新生成,不人工干预。
第二,提示词里给示例而不是讲规则。
告诉AI"预期结果要具体可验证",它不一定懂。但给它看一个例子------
预期结果(错误示范):登录成功
预期结果(正确示范):页面跳转至首页,首页顶部显示用户昵称,底部Tab栏选中"首页"图标它马上就理解了。示例比规则管用十倍。
幻觉控制
生成用例这步最容易出幻觉。AI会编造一些需求里根本没提到的断言条件,比如"验证欢迎语中包含用户手机号中间4位"------PRD里压根没这条。
我的做法是:在生成用例的提示词里加一条硬约束------"所有预期结果必须能从需求文档中找到对应依据,不能凭推测添加断言条件"。同时在Skill里做后处理校验:拿生成的预期结果反向检索需求文档,如果匹配不到相关描述,标记为"待确认"。
python
def validate_against_prd(testcase: dict, prd_text: str) -> dict:
"""校验用例预期结果是否有PRD依据"""
for step in testcase["steps"]:
expected = step["expected"]
# 简单的关键词匹配,复杂场景可走语义检索
if not has_prd_basis(expected, prd_text):
step["review_flag"] = "待确认:预期结果未在需求中找到依据"
return testcase这个后处理不是万能的,但能拦截掉大概60-70%的明显幻觉。剩下的靠下一个Skill------用例评审来兜底。
步骤拆分的粒度问题
AI有个倾向:测试步骤写得太粗。比如"完成登录操作"就算一个步骤了。
但实际执行的时候,"完成登录操作"至少要拆成:打开登录页→输入手机号→获取验证码→输入验证码→点击登录→等待跳转。不拆到这个粒度,用例就没法执行。
我在Skill里加了一条规则:每个测试步骤必须是单一的、不可再分的操作。如果一步操作里包含了"并且""然后"这种连接词,说明粒度太粗,需要拆分。
python
def check_step_granularity(steps: list) -> list:
"""检查步骤粒度是否足够细"""
refined = []
split_keywords = ["并且", "然后", "接着", "之后", "同时"]
for step in steps:
if any(kw in step["action"] for kw in split_keywords):
# 按连接词拆分
sub_steps = split_by_keywords(step, split_keywords)
refined.extend(sub_steps)
else:
refined.append(step)
# 重新编号
for i, step in enumerate(refined, 1):
step["step_no"] = i
return refined这个处理虽然机械,但很实用。拆完之后步骤数量会变多,但每一步都是可执行的原子操作。
05 第四个Skill:测试用例评审
这一步是整个流程里最被低估的。
很多人觉得AI生成了用例就完事了,直接拿去执行。但你真的拿去执行就会发现------大概15-25%的用例是"正确的废话",描述看起来没问题,但对测试没有任何实际价值。还有5-10%的用例包含幻觉断言。
用例评审Skill就是干这个的:把AI生成的用例再过一遍筛子。
评审的三个维度
维度一:完整性检查
对照需求文档,看有没有遗漏的测试点。这个靠的是前面需求分析Skill输出的模块摘要------把每个模块的测试点数量和已生成的用例数量做个比对,差距大的标记出来。
python
def check_completeness(modules: list, testcases: list) -> list:
"""检查测试点覆盖完整性"""
issues = []
for module in modules:
module_cases = [tc for tc in testcases if tc["module"] == module["name"]]
# 检查异常场景覆盖
for scenario in module.get("abnormal_scenarios", []):
covered = any(scenario in tc["description"] for tc in module_cases)
if not covered:
issues.append({
"module": module["name"],
"issue": f"异常场景未覆盖: {scenario}",
"severity": "高"
})
# 检查业务规则覆盖
for rule in module.get("business_rules", []):
covered = any(rule[:10] in tc["description"] for tc in module_cases)
if not covered:
issues.append({
"module": module["name"],
"issue": f"业务规则未覆盖: {rule}",
"severity": "中"
})
return issues维度二:质量检查
质量检查主要看三个问题:断言是否具体可验证、步骤粒度是否够细、有没有幻觉断言。
断言模糊是重灾区。"功能正常""操作成功""页面正常显示"------这种断言等于没写。我的Skill里有一条规则:预期结果必须包含至少一个可观测的视觉特征(文字、颜色、位置变化)或者数值指标。
python
VAGUE_ASSERTIONS = ["功能正常", "操作成功", "页面正常", "显示正常", "正常运行", "正常响应"]
def check_assertion_quality(testcases: list) -> list:
"""检查断言质量"""
issues = []
for tc in testcases:
for step in tc["steps"]:
expected = step["expected"]
if any(vague in expected for vague in VAGUE_ASSERTIONS):
issues.append({
"case_id": tc["case_id"],
"step": step["step_no"],
"issue": f"断言过于模糊: '{expected}'",
"suggestion": "补充具体的视觉特征或数值指标"
})
return issues维度三:重复检查
AI有个毛病:换着说法写同一个用例。比如"验证密码错误3次后锁定"和"连续输入错误密码3次验证账户锁定",其实是同一个测试点。
去重不能简单按文本相似度来,因为同一个意思的表达差异可能很大。我的做法是:先把每个用例的关键信息提取出来(模块+操作+预期),然后做语义相似度比对。
python
def deduplicate_cases(testcases: list, threshold: float = 0.85) -> list:
"""语义去重"""
unique = []
for tc in testcases:
key = f"{tc['module']}_{tc['description']}"
is_dup = False
for existing in unique:
existing_key = f"{existing['module']}_{existing['description']}"
sim = semantic_similarity(key, existing_key)
if sim > threshold:
is_dup = True
break
if not is_dup:
unique.append(tc)
return unique评审要不要人介入
纯AI评审能拦截大部分问题,但有些东西AI确实审不出来。
比如:这个功能虽然PRD写了,但业务上这个月根本不会上线;或者这个测试点虽然逻辑上成立,但在我们系统里因为架构原因不可能触发。
这类判断需要业务经验,知识库和提示词都补不了。
我的做法是:AI评审完之后,把标记为"待确认"的用例单独拎出来,生成一份评审清单。人工只需要审这份清单,不用从头看所有用例。工作量大概是从头审的30%,但能把有效率从70%拉到90%以上。
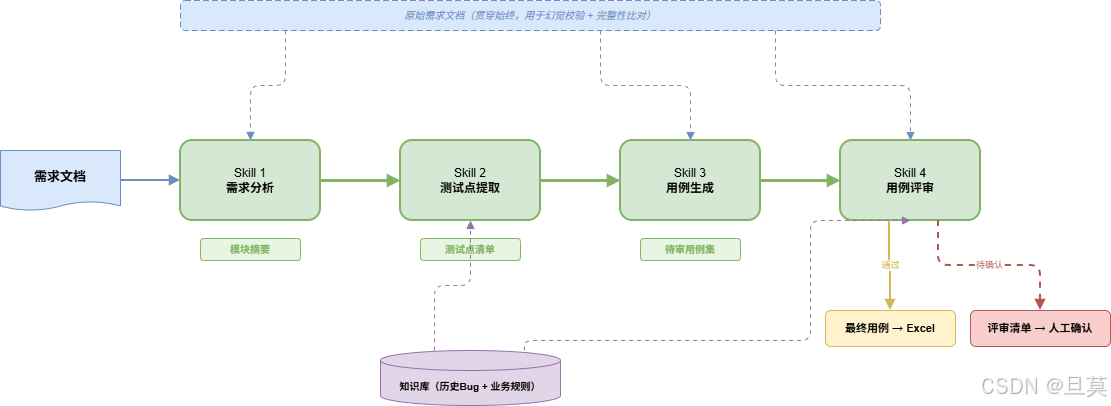
06 四个Skill怎么串起来
单个Skill写得再好,串不起来也白搭。
串起来的关键不在技术,在于数据格式的一致性。每个Skill的输出必须是下一个Skill能直接吃的输入,不能中间还得人工转格式。
我定义了一套统一的数据格式,四个Skill都围绕这套格式来:
需求文档 → [需求分析Skill] → 模块摘要(JSON)
模块摘要 → [测试点提取Skill] → 测试点清单(JSON)
测试点清单 → [用例生成Skill] → 待审用例集(JSON)
待审用例集 → [用例评审Skill] → 最终用例 + 评审清单所有中间产物都是JSON格式,字段定义统一。这样做的好处是:任何一个Skill都可以独立调试,只要给它符合格式的输入就行。
python
def run_full_pipeline(file_path: str, use_kb: bool = False) -> dict:
"""完整流水线"""
# Stage 1: 需求分析
doc_text = parse_document(file_path)
modules = analyze_requirements(doc_text)
# Stage 2: 测试点提取
all_testpoints = []
for module in modules:
kb_context = retrieve_from_kb(module["name"]) if use_kb else None
points = extract_testpoints(module, kb_context)
all_testpoints.extend(points)
# Stage 3: 用例生成
testcases = []
for point in all_testpoints:
case = generate_testcase(point, doc_text) # 传入原文做幻觉校验
case = validate_schema(case) # 格式校验
case = check_step_granularity(case) # 步骤粒度检查
testcases.append(case)
# Stage 4: 用例评审
review_result = review_testcases(testcases, modules)
final_cases = review_result["passed"]
review_list = review_result["pending_review"]
return {
"testcases": final_cases,
"review_list": review_list,
"stats": {
"total_modules": len(modules),
"total_testpoints": len(all_testpoints),
"total_cases": len(final_cases),
"pending_review": len(review_list)
}
}调度逻辑其实不复杂,就是按顺序调四个函数。但有个细节要注意:每个Skill的调用参数里,除了本步骤的输入,还要把原始需求文档带上。
为什么要带原文?因为后面步骤可能需要回溯原始需求来校验。比如生成用例时要校验幻觉,评审时要检查覆盖完整性,这些都需要原文做比对。如果只传中间产物,信息会逐级衰减,到后面就剩个骨架了。
Skill目录结构
光说原理不落地等于白搭。四个Skill最终是要加载到Agent里跑的,不管是Hermes Agent、Trae、Qoder还是飞书Aily,Skill的目录格式大同小异:一个SKILL.md描述能力边界,references放参考文档,scripts放执行脚本。我把四个Skill的完整目录摆出来,看一眼就知道每个Skill该塞什么。
skills/
├── requirement-analysis/ # Skill 1: 需求分析
│ ├── SKILL.md # 能力描述、触发条件、输入输出格式
│ ├── references/
│ │ ├── implicit_req_rules.md # 隐性需求推断规则(从哪些信号推断隐性需求)
│ │ └── doc_format_guide.md # 各格式文档的解析要点(Excel合并单元格怎么处理等)
│ └── scripts/
│ └── parse.py # 多格式文档解析(md/docx/pdf/xlsx/xmind/png)
│
├── testpoint-extraction/ # Skill 2: 测试点提取
│ ├── SKILL.md
│ ├── references/
│ │ ├── test_design_principles.md # 测试设计原则(等价类/边界值/状态转换/错误推测)
│ │ ├── boundary_rules.md # 常见边界值规则(数值/字符串/日期/列表类字段)
│ │ └── exception_patterns.md # 异常场景模式库(网络/数据/状态/权限异常)
│ └── scripts/
│ └── extract.py # 多轮提取+去重合并
│
├── testcase-generation/ # Skill 3: 用例生成
│ ├── SKILL.md
│ ├── references/
│ │ ├── testcase_template.md # 用例模板规范(9字段定义+命名规则)
│ │ ├── assertion_examples.md # 断言写法正反示例(模糊断言 vs 具体断言)
│ │ └── step_granularity_rules.md # 步骤粒度规则(连接词拆分、原子操作判定)
│ └── scripts/
│ └── generate.py # Schema校验+幻觉校验+粒度检查
│
└── testcase-review/ # Skill 4: 用例评审
├── SKILL.md
├── references/
│ ├── vague_assertion_list.md # 模糊断言黑名单("功能正常""操作成功"等)
│ ├── review_checklist.md # 评审检查项(完整性/质量/重复三维度)
│ └── dedup_guideline.md # 去重判定指南(语义相似度阈值+人工兜底规则)
└── scripts/
└── review.py # 完整性检查+质量检查+去重几个设计决策说明一下。
为什么用references而不是把规则写死在SKILL.md里? SKILL.md是给Agent看的"能力名片",告诉Agent这个Skill能干什么、什么时候该调。规则细节和参考文档放references里,SKILL.md保持精简。Agent加载Skill时先读SKILL.md判断该不该用,真要执行时再去references里取具体规则。如果全塞SKILL.md里,文件膨胀后Agent的上下文窗口压力很大。
scripts是必须的吗? 看你用什么Agent平台。Hermes Agent支持scripts目录放Python脚本,Agent调用Skill时可以直接执行脚本,不走模型推理------比如多格式文档解析、Schema格式校验、语义相似度计算这些确定性操作,脚本比模型又快又准。如果你的Agent平台不支持scripts,这些逻辑就得写进SKILL.md的指令里让模型自己跑,效果会差一些但也能用。
为什么没有知识库目录? 知识库是Agent级别的共享资源,不属于某个Skill。Hermes Agent里有专门的knowledge目录,Trae和Qoder也各有各的知识库挂载方式。Skill的references里放的是"规则"(怎么判断),知识库里放的是"事实"(历史Bug、业务规则),两者职责不同。测试点提取Skill需要查历史Bug时,走Agent的知识库检索接口,不需要自己维护一份。
references里的文件粒度怎么定? 单个文件不超过2000字,一个文件只讲一类规则。test_design_principles.md只讲测试设计原则,boundary_rules.md只讲边界值规则,不要混着写。粒度细的好处是:Agent按需加载,不会把无关内容拉进上下文;坏处是文件多了管理成本高。4-5个Skill加起来10-15个references文件是个合理的规模。
配套提示词:怎么把四个Skill串起来干活
Skill写好了,加载到Agent里,然后呢?你得告诉Agent怎么用这四个Skill,按什么顺序调,中间怎么传数据。这就需要一个任务提示词,在Agent的工作对话框里输入,让Agent按流程把四个Skill串起来。
以Hermes Agent为例,假设四个Skill已经加载好了,你给Agent的提示词大概是这样:
你需要完成一个需求到测试用例的全流程任务。请按以下步骤依次执行:
【第1步:需求分析】
使用 requirement-analysis Skill,分析我提供的需求文档。
输出:结构化的模块摘要(包含模块名、业务规则、异常场景、隐性需求)。
【第2步:测试点提取】
使用 testpoint-extraction Skill,基于第1步输出的模块摘要提取测试点。
要求:先做一轮基础提取,再补充一轮边界和异常场景,最后去重合并。
如果知识库中有历史Bug记录,优先参考。
输出:按模块组织的测试点清单(含类型、描述、优先级)。
【第3步:用例生成】
使用 testcase-generation Skill,将第2步的测试点转化为结构化测试用例。
要求:严格遵循9字段模板格式,预期结果必须具体可验证(不能出现"功能正常"这种模糊断言),
所有断言必须在原文中有依据,步骤粒度要拆到原子操作级别。
输出:待审用例集。
【第4步:用例评审】
使用 testcase-review Skill,对第3步生成的用例做评审。
检查三个维度:完整性(模块摘要中的业务规则和异常场景是否都有用例覆盖)、
质量(断言是否模糊、步骤是否太粗)、重复(语义相似的用例去重)。
输出:最终通过用例 + 待人工确认的评审清单。
【约束条件】
1. 每一步的输出必须是结构化JSON,直接作为下一步的输入,不要丢失格式
2. 原始需求文档全文必须贯穿始终,后面步骤需要回溯原文做校验
3. 第3步生成的用例,预期结果中如果找不到PRD依据,必须标记为"待确认"
4. 第4步评审清单单独输出,人工只需审这份清单
【需求文档】
{这里粘贴需求文档内容,或告诉Agent文档路径}说几个写提示词时容易忽略的点。
每一步要明确指出用哪个Skill。 不要写"先分析需求,再提取测试点",Agent可能跳过Skill直接自己干,那样references里的规则和scripts里的校验逻辑就全废了。显式指定Skill名,强制Agent走Skill流程。
每一步要写清楚输出是什么。 "模块摘要""测试点清单""待审用例集""评审清单"------每个阶段的产出物要有名字,Agent才知道下一步该拿什么当输入。不写清楚的话,Agent可能把第1步的原始文档直接丢给第3步生成用例,跳过了中间两步。
约束条件不能省。 特别是"原文贯穿始终"和"断言必须有PRD依据"这两条。不加约束,Agent很可能只传中间产物,到后面步骤信息已经衰减得没法用了。
实际使用中的变体。 上面的提示词是全流程模式,四个Skill全跑一遍。但有时候你只需要其中某一步------比如你已经有测试点了,只想让Agent生成用例和做评审,那提示词就只写第3步和第4步,把测试点清单直接喂进去。Skill拆开的用处就在这:全流程能串,单步也能用。
如果你觉得提示词太长了,还有一种更简洁的写法,适合熟练之后用:
全流程执行需求到用例:requirement-analysis → testpoint-extraction → testcase-generation → testcase-review
需求文档:{文档路径}
输出:最终用例Excel + 评审清单一行搞定,Agent看到Skill名就知道该怎么串。但前提是你对这四个Skill的行为已经足够熟悉,不需要再提醒它输出格式和约束条件了。
07 几条实操建议
写了几版下来,有几条经验我觉得值得记一下。
别想一次写对。 第一版Skill肯定不好用,这是正常的。我写了三版才基本满意。关键是每一版要能独立调试------这就是为什么一定要拆成四个Skill。如果是一个巨型Skill,你连问题出在哪一步都不知道。
提示词的维护比代码还重要。 模型在迭代,业务在变,模板也在变。提示词里的规则和示例要跟着更新。我把提示词模板单独放一个文件,不跟逻辑代码混在一起,改起来方便。
知识库优先级:历史Bug > 业务规则 > 通用测试原则。 知识库不是什么都往里塞,要有选择。历史Bug对测试点提取的帮助最大,因为AI看了历史Bug会主动避开同类问题,或者针对历史问题设计更严格的测试。通用测试原则其实放提示词里就够了,没必要进知识库。
评审环节不能省。 哪怕你的生成质量已经很高了,评审依然是必需的。AI不知道哪些功能暂时不上线,哪些场景在你们系统里不可能触发,这些只有人知道。评审的价值不是找错,而是补上AI认知之外的东西。
输出格式尽早锁定。 用例模板的格式、字段、命名规则,一开始就要定死,后面不要改。格式变了,所有Skill的提示词和校验逻辑都得跟着改,成本很高。我第一版没定好格式,后来改了一次模板,四个Skill全要调,折腾了两天。