简介
saa是java的ai agent框架,本系列将深入剖析 Spring AI Alibaba 的源码实现与核心原理,不仅可以指导agent的开发,更可以改造框架,增加新特性
系列内容:
系列( 一) 架构 完成
系列( 三) 调用
I 工具 完成
II MCP
-1 MCP MCP 能力,工具,资源,Prompts ,sampling ,。。。;springboot 自动配置 完成
-2 分布式 MCP
-3 MCP security
III skills 完成
系列( 四) RAG 完成
I 知识库,文档读取,分块;嵌入,向量store
II 检索,增强生成,模块化;混合检索,融合重排
系列( 二) 模型 model 模型 完成
chat 模型,消息,提示词,结构化输出,记忆
chat client ,advisor 组件
系列( 五) graph 图结构,节点和边;StateGraph
推理框架graph 映射示例: ReAct ,relection ,CoT ,Plan-And-Execute
CompiledGraph ;图执行,状态和存储
系列( 六) agent 组件分析,ReactAgent ,钩子和拦截器,记忆,结构化输出,人工介入
系列( 七) MAS
I flow agent; handoffs 模式,toolcalling 模式;
II 分布式agent ,A2A ,分布式运行
系列( 九) agent 管理平台(admin) agent 发现(a2a) ,agent 列表,提示词管理,会话管理,skill 管理,MCP 管理;chat ;评估;观测
系列( 八) I 观测:观测组件(micrometer-observation) ,观测点:chatClient ,chat 模型,工具(tracing) II 模型评估
本文分析graph,图编译
based spring ai alibaba v1.1.2.2
关键词
agent
graph
缩写
spring ai缩写sa
spring ai alibaba 缩写saa
参考资料
概览 | Spring AI Alibaba spring ai alibaba官网文档
https://docs.spring.io/spring-ai/reference/index.html spring ai官方文档
SAA概览
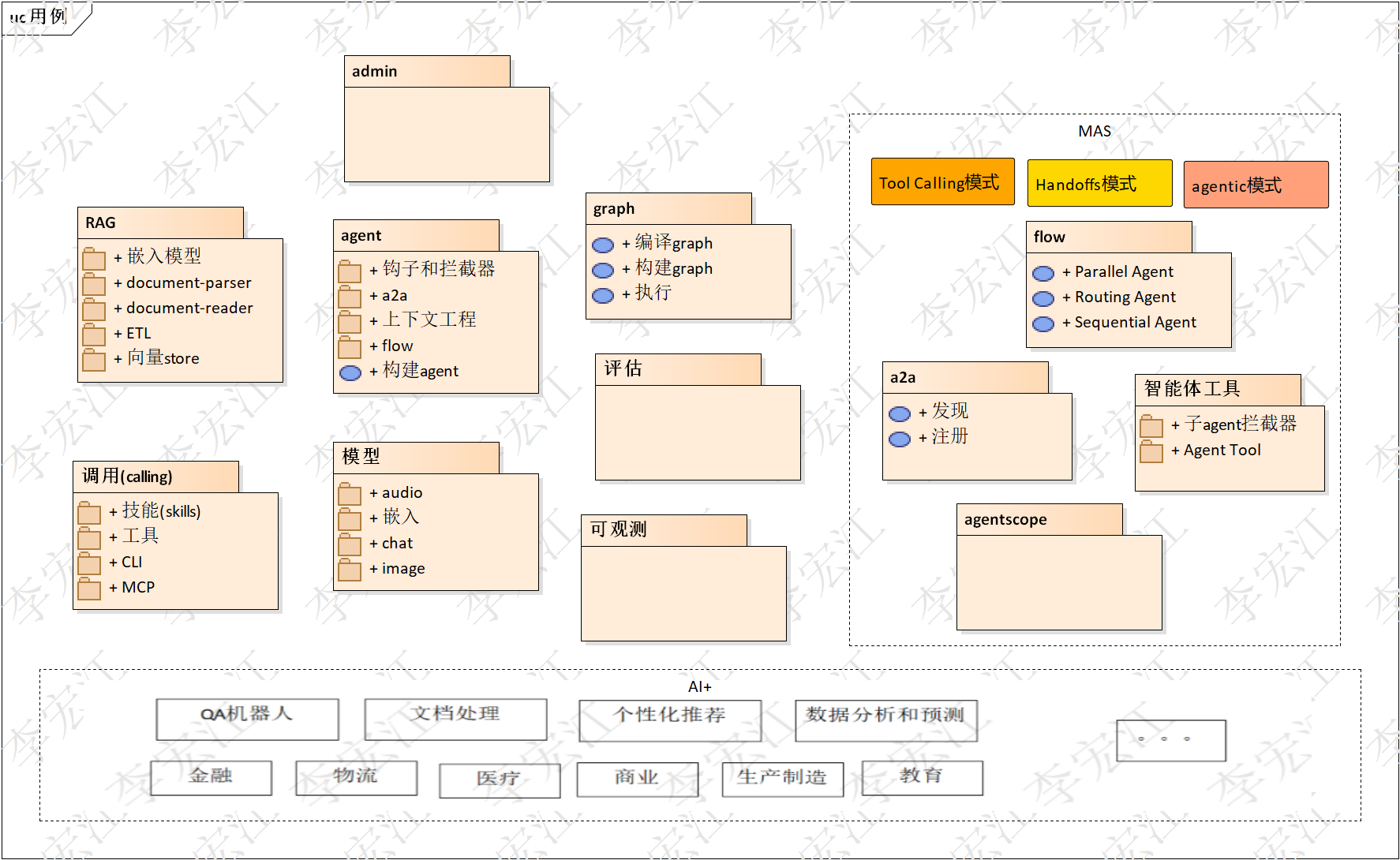
上图是saa原理源码分析场景视图,每个包对应着saa/sa组件或特性,是本文分析的目录
model 大模型的封装,模型包括Chat,嵌入,audio,image等类型,其中chat模型包括,advisor组件,提示词,记忆等
agent/graph saa agent,多agent与图紧密相关,可以认为saa agent/多agent是一种既定的"图"形,实现推理框架,开发人员可以使用graph底层api直接构建graph,使用agent获得既定的图形,简化agent的开发
外部调用(calling) 工具,MCP,skills
RAG 检索增强生成
MAS A2A,FlowAgent,子agnet,agent Tool;agent 集群
studio 简易的agent管理工具,嵌入到agent,带有agent面板,列表agent;提供chat界面,用于调试agent,是开发agent的便利工具
admin 管理台, agent的发布,列表,管理,执行;提示词工程,评估和数据集,观测
graph
saa graph-core是saa的图组件,以图的结构,节点,边构建处理流程,节点执行动作,边决定下一个节点,对应的,agentic是另一种模式,整个流程大模型自主编排,agentic省心省事,但同时agentic容易失控,纯粹看大模型心情,因此,目前比较好的方案,主体使用flowable,需要的时候使用agentic节点。
spring ai alibaba,agent的推理框架映射成graph,多agent角色也映射成graph,以图的节点承载执行逻辑,边决定下一节点,支持检查点保存执行状态,实现执行的暂停和恢复
外部介入
本节介绍saa的中断机制,中断等待外部干预,例如,人工验证,同时生成检查点(CheckPoint),用于恢复执行
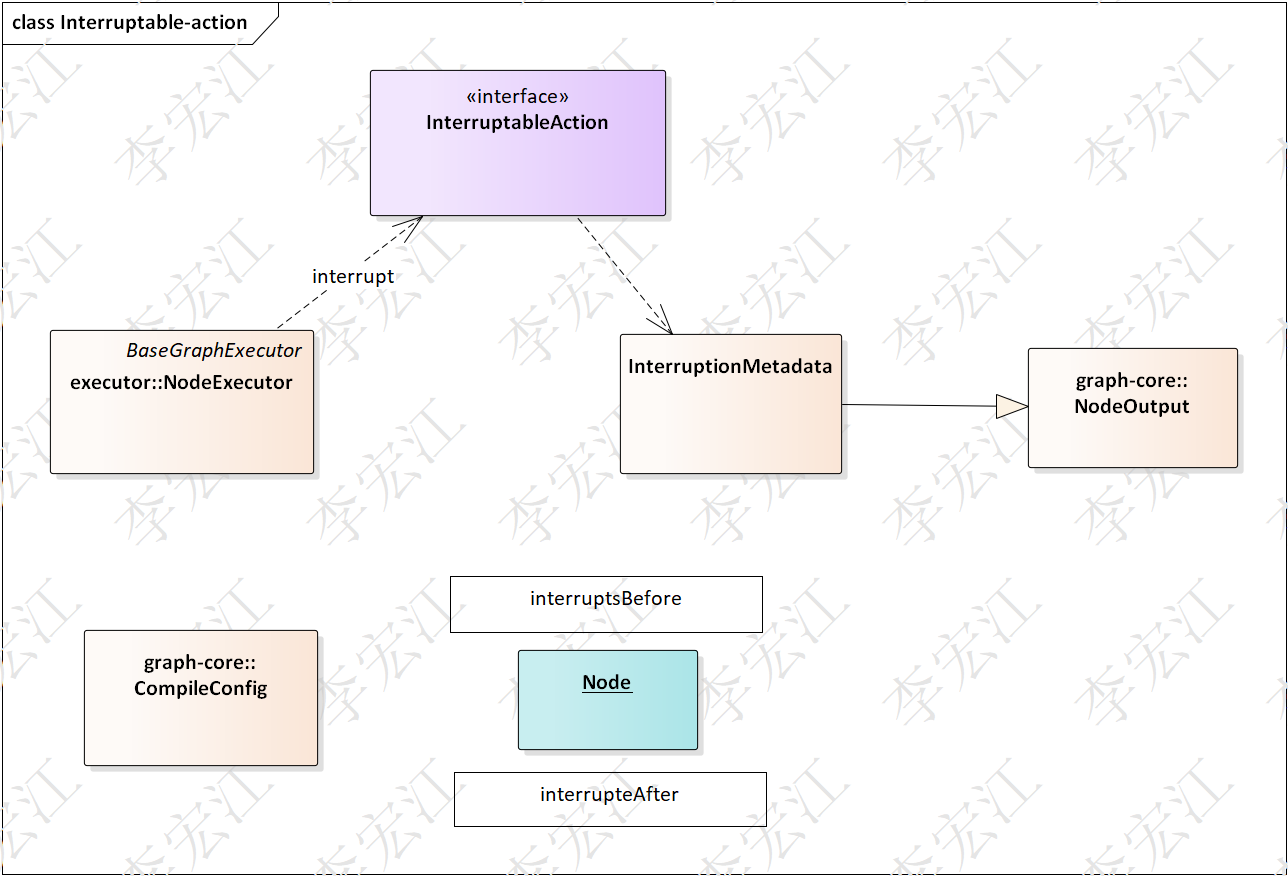
上图是中断机制两种实现方式,
- InterruptableAction 实现该接口的NodeAction,执行器识别Action类型,中断,返回提示,等候外部恢复
- interruptsBefore /interrupteAfter 设置interruptsBefore/ interrupteAfter,在CompileConfig设置哪个节点的前/后中断,执行时识别,中断处理
编译图
前面分析了状态图,状态图是图的结构,目的是为了方便构建图,编译图扁平化邻接表数据结构,目的是为了高效执行
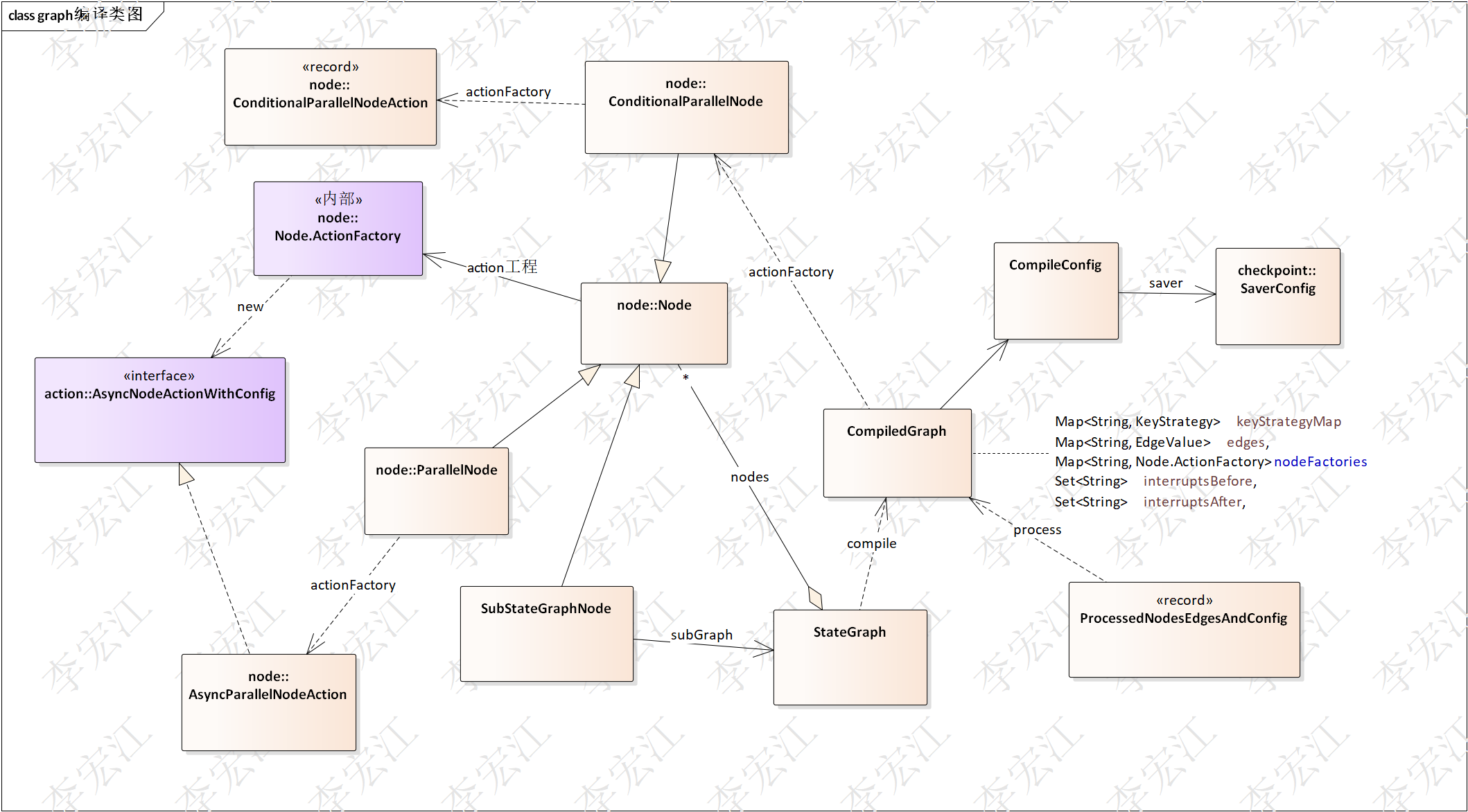
上图是编译图类图,编译把整个图,包括子图的数据结构转换为扁平化的邻接表结构,遍历不需要递归,还有并行处理,使用并行节点/action,节点内处理并行,执行过程不需处理。
下面分析原理和源码
扁平化邻接表
ProcessedNodesEdgesAndConfig 负责扁平化状态图数据结构,代码比较多,用示例解释代码逻辑,注释版的代码放到附录
首先介绍一下邻接表,
|---------------------------------------|----------------------------------------------------------------------------|
| 'A': 'B', 'B': 'C', 'C': \[\] | 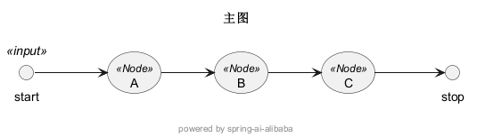 |
|
左:连接点结构,左是head节点,右是数组,head节点连接的节点;右:对应的图
进一步,若B是子图节点,其子图 D->E, D->F,E->G,F->G
ProcessedNodesEdgesAndConfig 处理过后
|--------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------|
| 'A': 'B-D', 'B-D': 'B-E', 'B-F', 'B-E': 'B-G', 'B-F': 'B-G', 'B-G': 'C', 'C': \[\] | 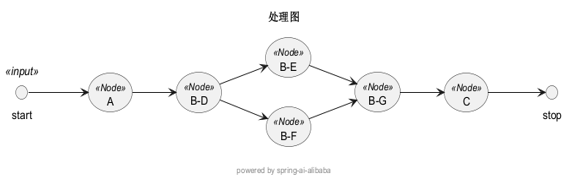 |
|
主图子图扁平化,合并到一个**邻接表结构,**主图与子图节点(B)的连接重定向到子图的节点,子图节点名称修改,格式%s-%s
最后,返回子图的Node写入到nodeFactoryes,id为key,action工程为value的map
CompiledGraph.CompiledGraph()

nodeFactoryes是最终的邻接表head节点集
边和并行处理
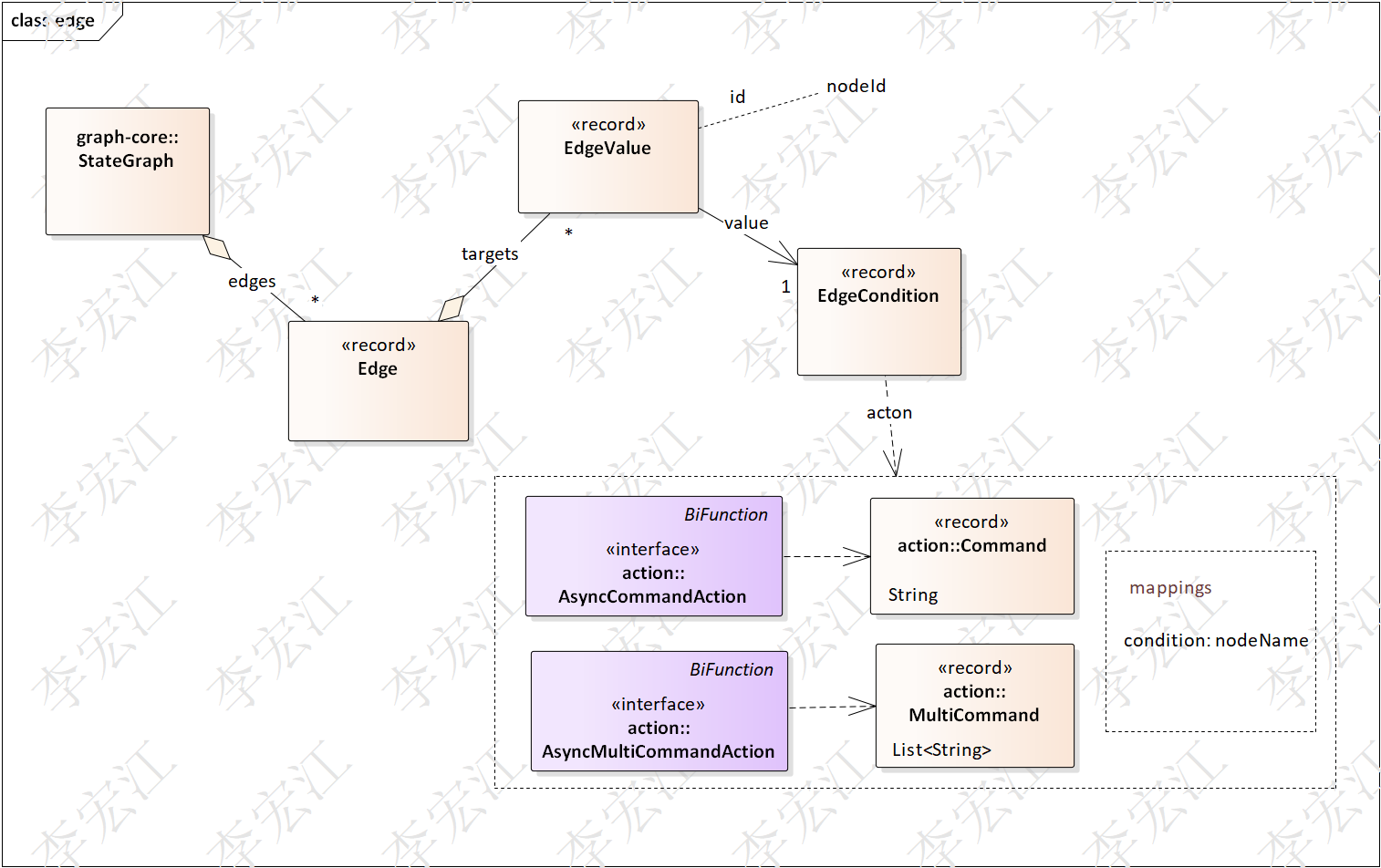
ProcessedNodesEdgesAndConfig处理后,返回边(edges)是list,图遍历按节点找边需要遍历list,因此边数据需要转为map,以sourceNodeId为key,即,List<Edge>类型转为Map<String, EdgeValue>,另外,图有并行分支,编译使用并行节点替代,并行执行在节点action完成,不需要执行器介入
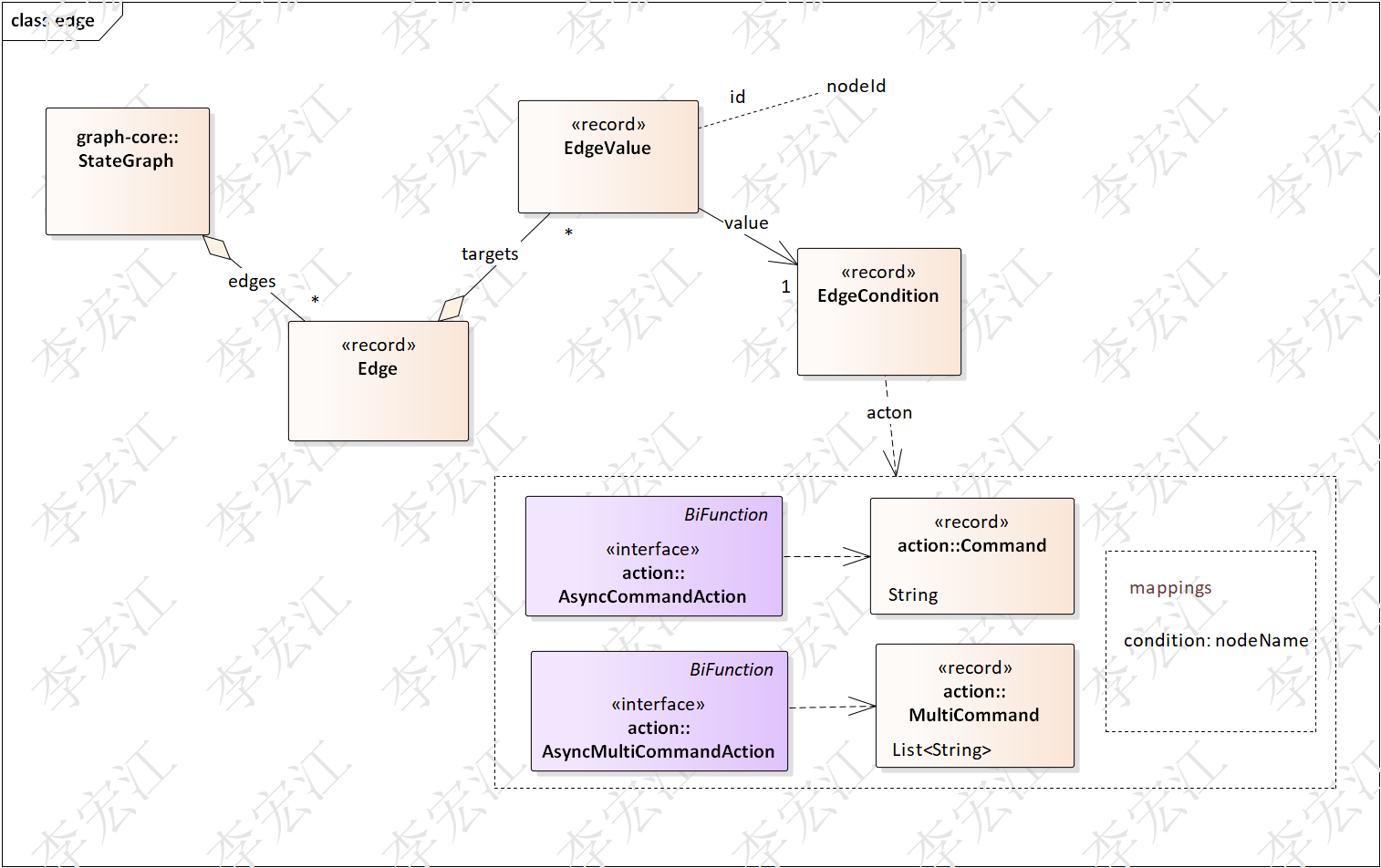
首先上图回顾一下图的边模型,边处理分多targes和单个target处理,
单个target
单个target又可以分为,++nodeId++ ,++单++ ++command++ ++条件++ ,++多++ ++command++ ++条件++(带条件的并行)3个情况
其中++nodeId++ ,EdgeValue是NodeId;++单++ ++command++ ++条件++,返回一个NodeId,均可直接put到Map<String, EdgeValue>即可
++多command++ ++条件++ 使用ConditionalParallelNode/ConditionalParallelNodeAction处理,并行在其action处理,不需执行器处理,这也是编译的一个关键任务,下面分析源码,
下面的代码来自CompiledGraph.CompiledGraph()方法
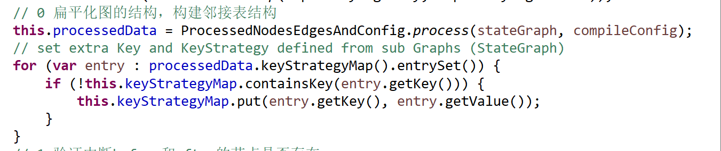
接上节,图扁平化处理返回

处理单target,进一步分为++nodeid++,单command条件,多command条件3种情况

首先处理多command条件,插入条件并行节点,负责并行执行,边原来的source节点连接到新增的并行节点
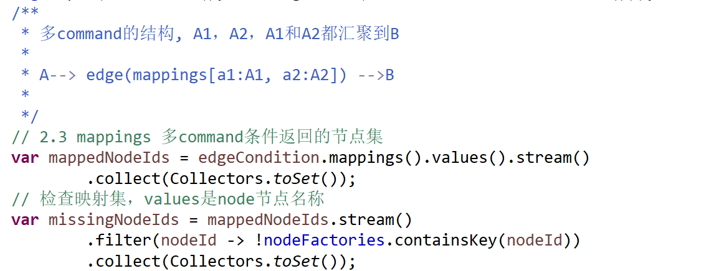
上图展示示例图,通过返回节点名称映射(mappings),找出返回节点集,即示例的A1,A2

查找返回节点集的汇聚点,上图的B,graph组件的约束,分支后需要汇聚到同一节点,最后并行节点连到B
即,A-- edge(mappingsa1:A1, a2:A2) --B 变成 A--> 并行节点 -->B
上面的isEmpty判断是错误的,数量只能是1,v2.0版本已经修改了

最后,单target的其余两种情况,单comman条件和nodeId直接增加到edges
多target
并行分支处理,与上面++多++ ++command++ ++条件++类似,用ParallelNode/AsyncParallelNodeAction处理并行
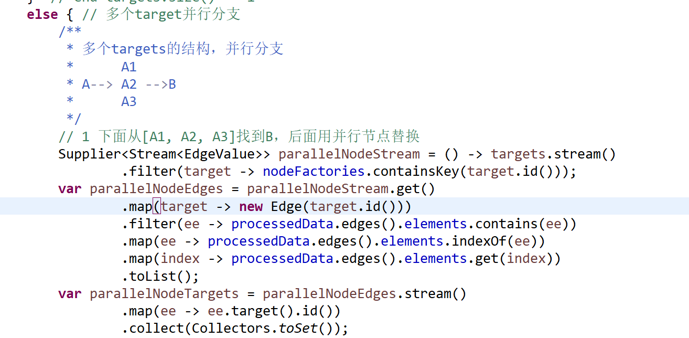
上面展示示例图,A1,A2,A3是并行分支,首先找到A1,A2,A3的汇聚点,即B

上图检验,并行分支汇聚到一节点,分支的边不能带条件
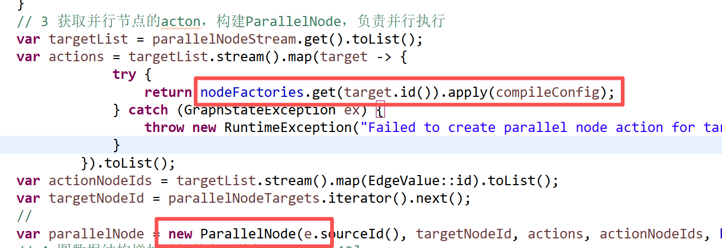
获取并行节点的++acton++,构建ParallelNode

插入新的并行节点,重新连接
总结:

上图是示例编译后的图,可以理解为是一个"降维"的处理,"摆平"多层的主图子图结构,"摆平"并行处理,降低执行器复杂度,提高执行效率
编译前后对比
本节对比编译前后类图
- 编译前
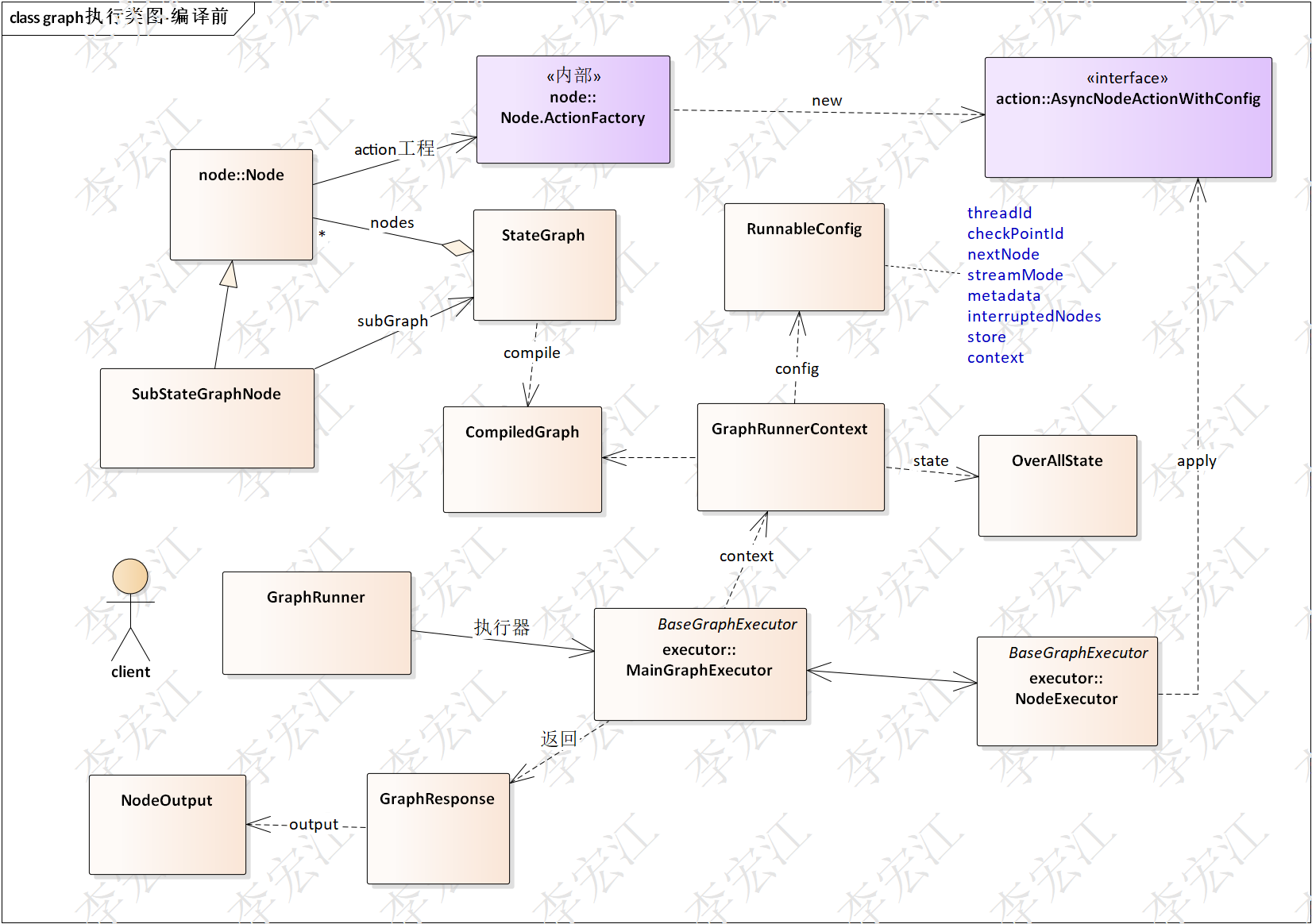
上图编译前类图,为了清晰,边部分类图放在下图
图遍历需要使用状态图的数据结构,遍历Node,执行NodeAction,若Node是子Node,深度递归遍历,并行,包括并行分支,多command边条件,需要执行器处理
- 编译后
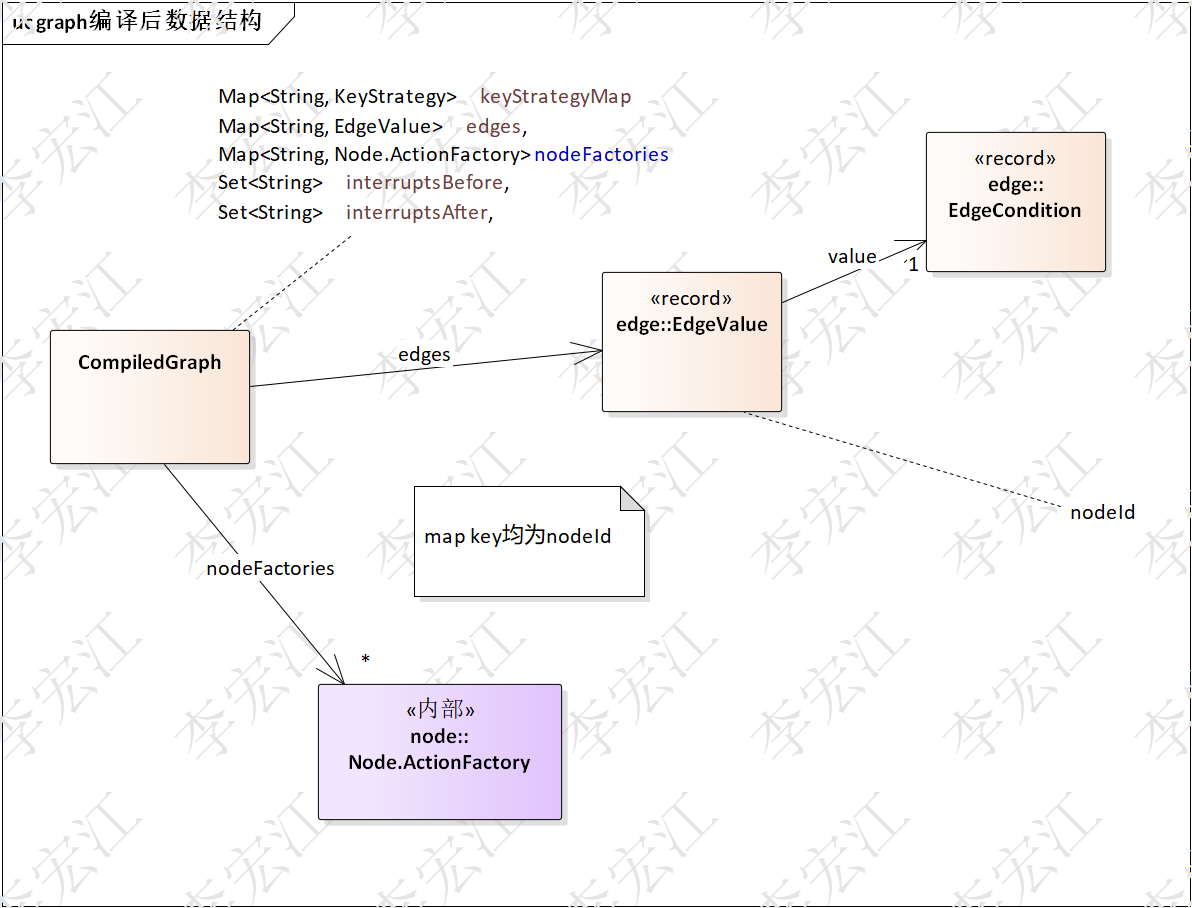
图编译后图的数据结构
编译后,邻接表结构,节点集在nodeFactories, nodeFactories的values存放ActionFatory,节点连接的边放到edges,注意,虽然名字与原状态图一样,但类型变了,编译后,edges是map类型,状态图相当于list类型。
并行处理替换为并行节点/action,执行阶段并行执行与执行一般的action一样,编译图与代码编译的意义是一样的,减少执行的工作,提高执行效率
附录
