本文深入分析了DSA(特定领域架构)与传统指令集(ISA)在半导体设计中的本质差异。DSA通过硬件级算法定制,大幅提升计算效率:1)精简90%冗余指令,采用专用张量/向量指令;2)硬件直接映射算法,消除译码延迟,使MAC单元利用率突破90%。相比之下,通用指令集(如x86/ARM)存在严重译码开销,实际算力利用率常低于30%。文章对比了特斯拉、英伟达、华为等主流芯片的DSA实现方案,指出专用架构在智驾领域的显著优势,同时揭示了不同厂商在编译器优化、运行时效率及云端协同等方面的技术差异。
在半导体微架构的底层大账本里,DSA(Domain-Specific Architecture,特定领域架构)与指令集(ISA,Instruction Set Architecture)之间,是一场关于"硬件执行效率"与"软件控制主权"的铁血割接与制衡。
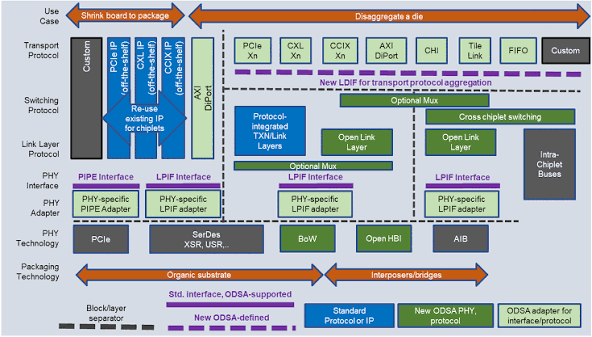
简单来说:指令集(ISA)是软件和硬件之间签订的"法律合同" ,规定了芯片能听懂哪些命令;而 DSA 则是为了某个特定算法领域,对晶圆内部的电路和这本法律合同进行了一次彻底的"铁血精简与剪裁"。
我们直接把它们放在晶圆内部的电荷流水线上进行深度清算:
1. 传统通用指令集(CISC/RISC):繁琐的"外交翻译官"
无论是英伟达 THOR 内部采用的 ARM Neoverse V2(属于 RISC 复杂指令集/精简指令集阵列),还是传统的 x86 芯片,其通用指令集的晶圆版图里都充满了大量的:
-
译码器(Decoder):把软件发来的通用高维代码,翻译成晶圆能听懂的微码。
-
硬件分支预测器(Branch Predictor) :猜软件下一步要执行
if还是else。 -
巨量的寄存器与通用控制逻辑。
物理痛点(算力踩踏)
当你在车端跑百亿参数的 VLA 自回归大模型时,算法最核心的动作就是巨量矩阵的乘加(GEMM/Attention)。
在通用指令集下,软件每执行一次矩阵乘法,CPU/通用GPU 都需要经过:"取指(Fetch) → 译码(Decode) → 执行(Execute) → 写回(Writeback)" 的繁琐外交流程。在这个过程中,晶圆内部真正干活的数学马达(MAC 单元)大部分时间都在原地"烧机油"等指令译码,导致指令集本身的开销(Instruction Overhead)甚至超越了计算本身的开销,实际算子榨干率往往低于 30%。
2. DSA 特定领域架构:斩断外交,用硬件电路直接"烧死"算子
当小鹏图灵(Turing)、特斯拉 AI 5 或华为达芬奇架构走向 DSA(特定领域架构) 时,它们在晶圆内部对指令集执行了颠覆性的 Backward-defining(算法反向定义):
A. 极简的专用指令集(Custom ISA)
DSA 抛弃了通用指令集里 90% 的繁琐控制命令(比如复杂的浮点跳转、虚拟化多层嵌套指令)。它在晶圆内部只保留和定制了极少数针对张量(Tensor)和向量(Vector)的专用大指令(如 Load_Tensor、Matrix_Multiply)。
- 技术本质:通用指令集是一次只能加两个数字的"小勺子";而 DSA 的专用指令是一次能把两个 256 × 256 矩阵直接拍碎对齐的"大铲车"。
B. 算法硬件化(解耦译码,全速吞吐)
在 DSA 的晶圆版图里,大面积的控制译码逻辑被无情砍掉,让渡给了极其奢侈的片内 SRAM 静态缓存池与专用脉动阵列(Systolic Array)电荷流水线。
-
电荷流向 :当端到端大模型的 Attention 算子下发时,DSA 编译器将其直接映射为芯片内部焊死的物理硬件通道。数据一过引脚,不需要复杂的硬件分支预测和译码等待,电荷直接在晶圆的硬件网络(NoC)中像水流一样漫过乘加单元。
-
没有了指令转换的"时钟气泡(Bubble)",将 MAC 单元实际榨干率硬生生卡死在 \\ge 88\\% 甚至 90% 的全时满载转速(如 Tesla AI 5)。
3. 横向清算:主流智驾 SoC 在"DSA 与指令集"上的物理对账
为了让你能在一秒钟内看清行业巨头的底牌,我们将它们的片内指令与架构特征进行全量脱水对照:
| 芯片平台 | 晶圆内部主控指令集体系 (ISA Base) | DSA 专用架构硬核 IP 布局 (Domain-Specific Core) | 软硬协同的图优化编译器表现 (Compiler Integration) |
|---|---|---|---|
| NVIDIA THOR | ARMv9-A (Neoverse V2) 通用精简指令集簇。 | 集成 Blackwell 架构 Tensor Core(张量核心) DSA 算力硬核。 | 依托成熟的 PTX(并行线程执行)微码层,通过 TensorRT 编译器将大模型 Attention 矩阵拆分为底层 PTX 指令流,在级联核心间调度。 |
| Tesla AI 5 (HW 5.0) | 极简自研私有定制指令集 (废除通用包袱)。 | 新一代全视觉 FSD 向量/张量加速核心簇,占据绝对晶圆面积。 | 算法反向定制编译器。在编译阶段直接将全视觉隐空间(Latent Space)计算图硬核融合,直接映射为晶圆内部焊死的物理电路。 |
| 华为 昇腾核心 | 自研定制指令集体系 + 鲲鹏通用 CPU 指令。 | 达芬奇 3D Cube(张量计算立方) DSA 加速仓。 | 依托 CANN 异构计算架构。图优化阶段将 4D 时空体素(Occupancy Grid)算子在底软直接量化编译,由达芬奇硬件流水线零气泡吞吐。 |
| 小鹏 图灵 (Turing) | 标准车规通用 CPU 指令 + 自研私有 NPU 微码指令集。 | Transformer 自注意力机制专用 DSA 加速电路。 | 编译器在编译期识别出大模型 Attention 结构后,直接将其映射为 NPU 电路里烧死的硬件专用算子,片内时延压缩 80%。 |
📊 2026 全球智驾 SoC 软硬协同设计与集成特征确权总账
| 芯片平台 / 自研体系 | 晶圆级算子固化匹配 (DSA 微架构与大模型算子对接) | 接口层感知进场流控 (像素 Raw 流数据搬运与零拷贝) | 跨芯片编译与分布式调度 (多片级联时的软件拓扑) | 脑死亡时的底软熔断硬隔离机制 (Hypervisor/操作系统级铁闸) |
|---|---|---|---|---|
| Tesla AI 5 (HW 5.0) | 算法硬件化(晶圆级微码烧死)。 专为端到端全波前(Full Wavefront)时空自回归网络定制,自研加速核心直接烧死 Transformer 矩阵算子,MAC 单元利用率冲破 ≥ 90%。 | 纯视觉引脚 DMA 直灌。 引脚原生对接板级片外高清相机流,硬件 DMA 引擎绕过任何中间件和 CPU,将原始像素直灌片内超大 SRAM 缓存池,片内时延压缩 90%。 | 双片全时对称主备拓扑。 自研超低时延、超大带宽片间高速总线,通过编译器在最底层执行矩阵跨片并行吞吐,完全不考虑第三方传感器兼容。 | 微秒级指令集原位硬复位。 采用激进的 ASIL B 算力热仓 + 白盒化硬件看门狗,大模型突发局部显存死锁时,支持在 ≤ 50us 内直接执行硬件级硬复位切换。 |
| NVIDIA THOR | FP4 硬件级低精度张量核心。 通过通用张量核心(Tensor Core)加速大模型 Attention 矩阵乘法,自回归序列推演时 MAC 实际榨干率 ≥ 85%。 | 标准数字接口控制器。 晶圆边缘为纯数字引脚(MIPI CSI-2 ),引脚到 NPU 之间依赖大带宽片上网络(NoC)进行数据调度,多路相机进场时需严防中断风暴。 | NVLink-C2C 算子级 All-Reduce。 通过 NVLink 互联矩阵,在编译器底层执行 Column/Row 跨芯片矩阵垂直切片,实现无损的跨芯片张量并行(Tensor Parallelism)。 | ARM EL2 级双阶段虚拟化隔离。 硬件层完美支持 Type-1 Hypervisor 虚拟机管理,大模型突发显存换页死锁(Cache Miss)时,硬件支持在 100us 内一拍闭闸挂起 vCPU。 |
| 华为 昇腾集群 (Ascend 系列) | 达芬奇 3D Cube(张量计算立方)。 专为 4D 时空体素(Occupancy Grid)优化。通过高并发流控(Stream Control)电路榨干矩阵算力,MAC 单元利用率 ≥ 80%。 | 主板网关层确定性流控。 引脚原生对接片外自研车载交换机(Switch)芯片。感知大包与规控小包在主板网关层通过 DIP(确定性 IP)网络流控 执行硬件级排队仲裁。 | HCCS 板级集群级联。 利用自研 HCCS 高速片间总线,在主板层面拉通多片 NPU 进行数据流并行对账。软件层面通过华为自研 VOS 操作系统实现全车 Zonal(区控)网络大一统。 | 微内核"冷热密室割接"。 VOS 实时微内核通过两阶段页表将开放 Linux 仓与规控仓彻底切开。大模型 Panic 瞬间,底软在100us内挂起 Linux 所有虚拟机,不污染规控流。 |
| 高通 Ride V2 | 微架构大缓存硬核匹配。 自研 Hexagon NPU 引入了全新的 Vector & Tensor Extensions(向量与张量扩展) 硬件算子流控电路,在图优化和算子融合上大幅度压减硬件流水线气泡,MAC 榨干率实际可冲破 ≥ 80%。 | 系统级缓存(System Cache)卡闸。 感知数据进入引脚后,优先灌入晶圆内大容量系统级缓存,通过硬件 QoS 染色机制压减总线延迟与带宽踩踏。 | 横向"舱驾一体"跨域高度集成。 单片晶圆内部通过极庞大的外设 I/O 硬件多路复用器(MUX),在底层软件 Flex 架构调度下,单芯片同时兼顾座舱娱乐与自驾规控。 | 片内物理 ASIL D 安全岛监控。 晶圆内部物理集成多核锁步 ARM Cortex-R52 核心簇与总线 MPU(内存保护单元)防火墙,在片内总线层面硬核锁死座舱与自驾的内存边界。 |
| 地平线 征程 6 (J6 家族) | 自研纳什架构 BPU 核心。 跑传统 BEV 和空间感知网络时算力效率 ≥ 80%;但在处理自回归生成文本/动作 Tokens 时,硬件流水线会出现气泡(Bubble),效率滑坡。 | 片内巨量 SRAM 寄存器对账。 采用前级流控中央存储(Stream Storage)微架构,在晶圆内部塞入巨量片内 SRAM 作为超大缓存池,彻底消除数据频繁读写片外显存的总线延迟。 | 纵向工具链大一统复用。 家族从低配到顶配采用同源 BPU 架构,主机厂可实现"一套底软工具链、一套算子库"向上扩展到千安中央计算,向下裁剪到单路行泊一体。 | 硬件级锁步监控单元(FIT值卡闸)。 晶圆内部集成高可靠性硬件锁步监控,专门用来防范先进制程晶圆的硬件随机失效,安全合拢主机厂白盒规控状态机。 |
| 小鹏 图灵 (Turing) | Backward-defining 算子固化。 在晶圆设计阶段,直接将 Transformer 自注意力矩阵乘法算子电路硬核烧死在 NPU 微码里,大模型实际算力榨干率 ≥ 88%。 | 片内硬件级 DMA 零拷贝流控。 引脚原生对接片外 A-PHY 解串芯片阵列(Rx)传来的纯数字 MIPI CSI-2 信号。像素一过引脚,直接由硬件 DMA 引擎原位直灌共享显存静态匿名指针。 | 垂直私有化高速片间级联。 晶圆预留自研高速片间级联走线协议。支持多片在中央主板上原位级联。软件栈和编译器完全基于自研端到端算法垂直锁死。 | 双核锁步安全岛硬件抢权。 片内集成双核锁步安全岛,在大模型发生显存死锁的绝对瞬间,硬件层具备微秒级一拍闭闸强行挂起 vCPU 的晶圆级主权。 |
| 蔚来 神玑 NX9031 | 前级特征图像隐空间释放。 通过自研超大面积硬核 ISP 释放 NPU 的算力开销。感知前级自研硬核编译流,高能效聚焦于前级 Raw 图像信号的像素级光子校正。 | 前级超高吞吐像素硬洗刷。 引脚定义专门针对蔚来 Aquila 超感系统设计, Raw 图像进入引脚后,片内 ISP 在微秒门口直接执行高动态范围(HDR)的非线性光子校正。 | 对等双片级联垂直私有化。 在中央 AD 主板上采用对等双片级联架构。全栈软件栈、编译器、算子库均独立搭建,引脚和微码高度锁死自研激光雷达主控芯片与周视相机。 | 纠错码(ECC)内存保护电路。 5nm 先进制程,片内设置极其严密的纠错码保护电路,防止晶圆内部因高频电磁干扰(EMI)或漏电流发生比特翻转(Bit Flip)。 |
| 黑芝麻 武当 C1200 | 轻量级神经网络异构解算。 算力完全无法支撑 百亿参数的 VLA 世界模型。但在传统 L2+ 轻量级神经网络和车辆状态机解算上,综合物理资源利用率 ≥ 80%。 | 硬件总线仲裁器(Bus Arbiter)。 在片内 NoC(片上网络)层面执行物理总线染色与强流控,确保座舱侧的大流量数据进场时举足轻重的控制字不会踩踏智驾控制字的内存通道。 | 跨域融合单晶圆多核调度。 不追求芯片间的超大算力级联,在同一块 Die 内部,用极其精简的晶圆面积直接集成了负责智驾/座舱的 Cortex-A 核与车规级实时控制内核。 | 片内物理硬核隔离密室。 晶圆内部集成了 ASIL D 级别的 Cortex-M7 硬锁步实时内核,配合 NoC 硬件防火墙,强行划定 MCU 域、Android 域、QNX 域的寄存器读写边界。 |
📊 2026 全球智驾 SoC 算法部署与工具链特征确权总账
| 芯片平台 / 编译生态 | 核心编译工具链与量化机制 (Compiler & Quantization) | 图优化与算子融合策略 (Graph Optimization & Fusion) | 车端运行时与大模型吞吐 (Runtime & LLM/VLA Deployment) | 影子模式与云端数据流对账 (Cloud-to-Vehicle MLOps) |
|---|---|---|---|---|
| Tesla AI 5 (HW 5.0) | 自研深度私有化编译器。 原生支持定制的 FP4 / INT4 / FP8 混合精度量化。针对自研 FSD 核心的指令集进行二进制底层重写,彻底斩断通用层开销。 | 时空级超大算子硬核融合。 将端到端网络中的三维体素流与时间序列算子,在编译阶段强行融合为一个超大计算图(Full Graph),在晶圆内部一次性吞吐。 | 端到端全波前全时并发运行时。 本地运行时(Runtime)深度精简,直接执行全视觉隐空间(Latent Space)特征解算,百亿参数模型在车端保持刚性稳定转速。 | 全球最大视觉数据工厂一体化并网。 通过影子模式(Shadow Mode)实现车端芯片与云端 Dojo 超算中心的比特流精确对账(Bit-accurate),闭环极速进化。 |
| NVIDIA THOR | NVCC / TensorRT 生态大一统。 支持最新的 FP4(4位浮点)精度开闸 。依托强大且极度成熟的 PTX(并行线程执行) 底层编译架构,量化精度损失极低。 | 跨核心张量并行编译。 通过 TensorRT 编译器在底层执行 Column/Row 矩阵跨芯片垂直切片,自动将大模型 Attention 计算图切分下发至 NVLink 级联核心。 | 云端全同源标准运行时。 完全兼容标准 Transformer 与 VLA 变体网络。只要云端 CUDA 能跑的模型,车端 Runtime 即可直接零转换下发部署,无算子碎片化风险。 | 全球大一统 MLOps 生态。 依托 NVIDIA Omniverse 与云端超算一体化账本,车端触发的长尾场景(Edge Cases)可以直接在云端无缝克隆、仿真并重新下发。 |
| 华为 昇腾集群 (Ascend 系列) | CANN 异构计算架构编译器。 支持自研的 INT8 / FP16 混合精度量化。通过自动量化工具(AMCT)执行算子级敏感度分析,守住大模型规控精度红线。 | 3D 张量流图深度优化。 将 4D 时空体素(Occupancy Grid)算子与 Transformer 矩阵在 CANN 底层进行流水线深度排布,消除数据搬运的"时钟气泡"。 | MindSpore / ATC 专用运行时。 针对达芬奇 3D Cube 架构,运行时执行极高强度的确定性进程流控制,结合 VOS 实时内核卡死时钟抖动(Jitter ≤ 5us)。 | 国内最大数据大兵团闭环。 依托盘古大模型云端超算中心,车端 MDC 采集的非标点云与视频流通过确定性通信网络直接回流,执行全生命周期自动化训练对账。 |
| 高通 Ride V2 | Qualcomm AI Stack 编译器。 主要支持 INT8 / INT4 量化。将传统深度学习网络拆分为底层微码,下发至自研的异构 NPU 核心簇中。 | 大异构算子拆分与硬件裁切。 图优化需要将一个大模型网络肢解为 CPU、GPU、NPU 协同解算的碎片图,通过片内系统级缓存(System Cache)进行数据暂存。 | Snapdragon Neural Runtime。 对开源百亿参数变体网络的算子支持存在碎片化,Runtime 在处理复杂的自回归 Transformer 序列时易发生 MAC 利用率滑坡。 | Software Defined Vehicle 横向并网。 侧重于将座舱感知(眼球追踪、语音大模型)与智驾大模型的云端数据回流进行跨域融合,但在商用车重型力学闭环上缺少云端专有底座。 |
| 地平线 征程 6 (J6 家族) | 艾迪(Aidi)/ 天工开物工具链。 主攻 INT8 极致量化与混合精度。通过先进的量化感知训练(QAT)工具,在算法训练阶段即完成对 BPU 纳什架构的对齐。 | 前级流控中央存储图优化。 编译器重点优化数据在片内巨量 SRAM 缓存池内部的读写逻辑,在图优化阶段强行合并高频访存算子,断绝片外显存换页死锁。 | BPU 专有原生高效运行时。 跑 BEV 和空间几何视觉网络时 Runtime 吞吐效率极高;但在处理 VLA 大模型自回归文本/动作 Tokens 生成时,编译器会产生硬件流水线气泡。 | 中国本土海量车型大纵深生态。 由于从低配到顶配采用完全同源的 BPU 核心,工具链纵向大一统。云端数据回流方案可完美横向覆盖从 10 万到 40 万的全系车型。 |
| 小鹏 图灵 (Turing) | 算法反向定制(微码大一统)编译器。 基于自研算法栈垂直剪裁的专用编译器,重点压榨定制版 Transformer 大模型的 INT8 / FP8 量化效率。 | Attention 矩阵微码硬核融合。 编译器在编译阶段识别出 Transformer 结构后,直接将其映射为 NPU 电路里焊死的专用硬件加速算子,实现零气泡级图优化。 | 垂直私有化端到端运行时。 Runtime 极其纯净,原生对接片内硬件级 DMA 零拷贝流控电路,数据一过引脚直接开闸吞吐,将全生命周期时延压缩 80%。 | C端海量乘用车高频影子模式。 依托小鹏在乘用车领域的庞大出货量,车端图灵芯片的高频影子模式采集与云端"扶摇"超算中心高度并网,自动化剪裁闭环极速。 |
| 蔚来 神玑 NX9031 | 自研"神玑"高性能编译器。 主攻 INT8 / FP16 混合精度量化。针对 5nm 先进制程的大集群 CPU 与自研 NPU 进行底层编译器微指令深度优化。 | 前级图像Raw流与隐空间图优化。 编译器核心差异化在于将前级自研超大面积硬核 ISP 的像素处理流水线,与后级神经网络加速图进行像素级的无缝拼装。 | 私有化高性能感知运行时。 Runtime 被前级图像信号洗刷流水线占领。前级洗刷直接擦除夜间强光眩光与多径鬼影,使得后级 Runtime 部署的大模型特征极度纯净。 | "神玑家族"垂直私有闭环。 全栈软件栈、编译器、算子库和云端回流机制均独立搭建,高度锁死自研激光雷达主控芯片(NX6031)与 Aquila 超感系统,外界无法渗透。 |
| 黑芝麻 武当 C1200 | 瀚海(Hanhai)AI 工具链。 主攻传统卷积神经网络(CNN)与轻量级神经网络的 INT8 刚性量化,编译器结构精简。 | 跨域多核寄存器级图优化。 图优化不针对超大模型,而是针对如何在同一块 Die 内部,优化 Cortex-A 核与 Cortex-M7 安全核之间的寄存器读写防火墙与数据交互。 | 轻量级车规状态机运行时。 Runtime 完全无法支撑 百亿参数的世界模型,但在传统 L2+ 行泊一体、全车状态机解算与 Zonal 区域控制上,运行极其稳健。 | 传统 Tier 1 供应链分账模式。 侧重于低成本整车 BOM 的离线部署与基础数据回流,主要在下沉级跨域控制(Zonal 区域聚焦控制器)市场中执行成熟量产。 |