一、先搞懂:不用 Milvus(向量库)、不用 RAG 会有什么致命问题
DeepSeek 这类大模型有三个天生短板,完全靠 RAG + Milvus 向量数据库解决:
知识截止时间固定 模型训练完后,新知识、企业内部文档、实时业务数据它完全不知道;比如 2026 年最新政策、公司内部产品手册、业务工单,模型原生没有。
上下文窗口有限 哪怕支持超长上下文,一次性塞几万字文档进去,token 成本极高、推理变慢,还容易混淆信息、产生幻觉。
无法接入私有 / 动态数据 内部合同、运维文档、客户资料不能全部灌进模型训练,重新训练成本百万级,且无法实时更新。
RAG(检索增强生成)就是方案:先检索相关资料,再丢给大模型回答;而 Milvus 是专门用来做「文本相似度检索」的向量数据库,是 RAG 的核心存储底座。
二、RAG 完整工作流程(结合你前面 Client+MCP+DeepSeek 架构)
文档向量化(入库 Milvus) 业务文档 / 知识库 → 文本切分 (chunk) → 嵌入模型 (Embedding) 转多维向量 → 存入 Milvus 向量库,同时绑定原文、元数据。
用户提问向量化检索 用户问题通过 Embedding 生成向量,去 Milvus 做近似相似度搜索,快速召回最相关的几段文档片段。
片段注入 LLM 上下文 Client 把 Milvus 检索到的参考资料拼进 prompt,发给 DeepSeek;模型基于真实文档作答,而不是靠内部训练记忆。
输出准确回答,减少幻觉
三、为什么必须用 Milvus,不能用 MySQL/ES 替代?
1. MySQL:完全不适合向量检索
向量是几百 / 上千维浮点数数组,MySQL 无原生向量索引。
只能全表暴力遍历计算相似度,数据量上万后查询秒级→分钟级,完全不可用;
不支持 ANN(近似最近邻)检索,性能完全崩盘。
2. Elasticsearch:轻量场景能用,但企业级 RAG 短板明显
ES 向量只是附加能力,底层是倒排索引,天生为关键词设计:
百万级向量以上检索延迟高、占用内存巨大;
分片扩容、向量更新、混合检索(向量 + 业务筛选)性能差;
不支持海量向量、动态分区、冷热数据分离、高性能批量导入;
四、结合现有架构
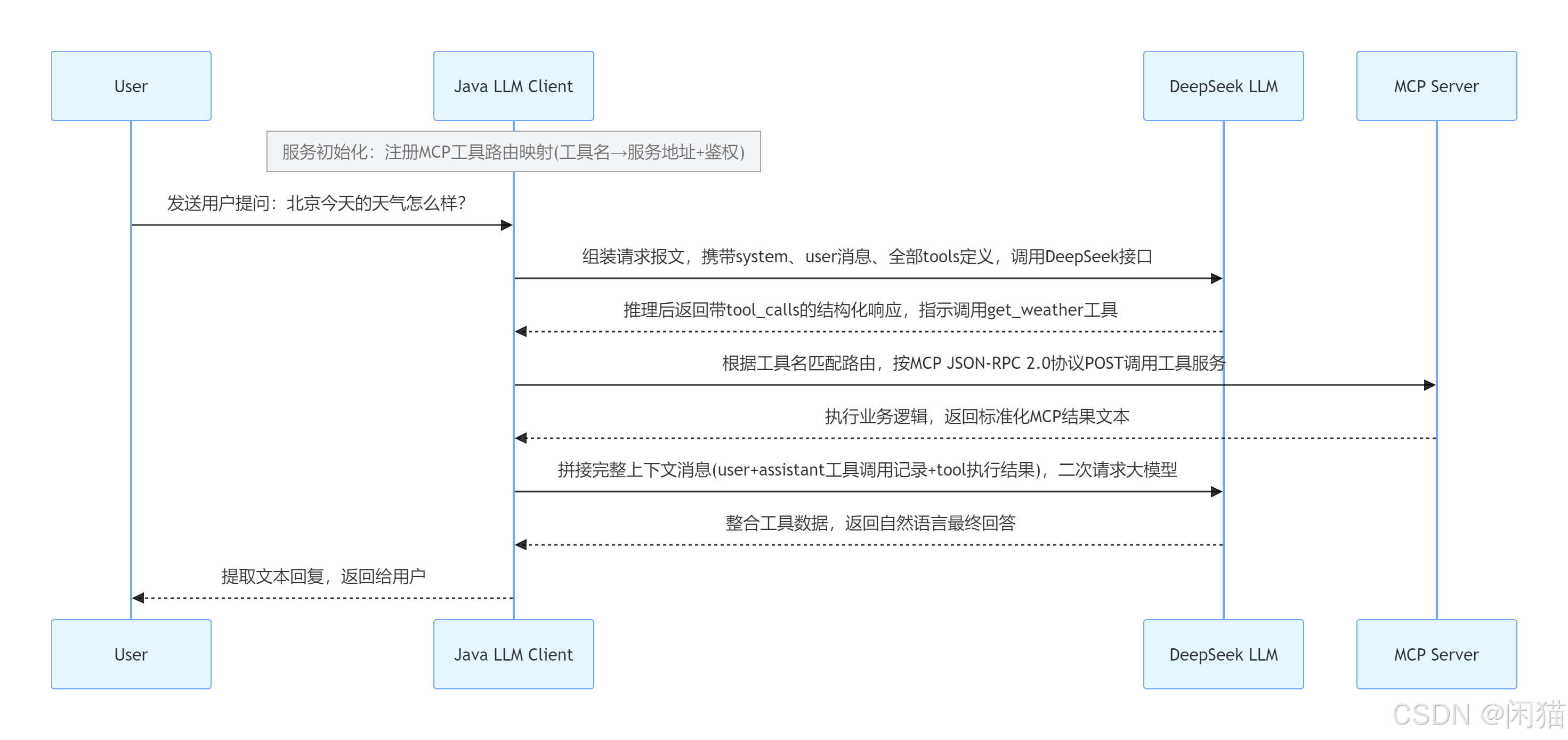
你现有链路:用户 → Java Client → DeepSeek → MCP Server 引入 Milvus RAG 后扩展链路:
- 用户提问到达 Client
- Client 同步两条分支:
- 分支 A:RAG 检索:问题向量化 → 查询 Milvus → 获取相关知识库片段
- 分支 B:正常工具路由(天气 / 股票 MCP 调用)
- Client 将 Milvus 检索到的参考文档、MCP 工具返回数据一起组装进 messages
- 交给 DeepSeek 结合私有知识库 + 实时工具数据生成精准回答
对应业务价值:
内部文档问答:运维手册、平台接口文档、故障方案存在 Milvus,提问直接匹配对应方案,不用调用外部 MCP;
消除模型幻觉:所有回答依托真实内部资料,不会编造不存在的接口、故障处理步骤;
实时知识更新:更新一份运维文档,Milvus 增量同步,模型立刻生效,不用微调 / 重训 DeepSeek;
节省 LLM Token 成本:只检索相关片段,不用全量加载整本知识库,大幅减少输入 token;
权限隔离:Milvus 可绑定部门、用户权限元数据,检索时过滤无权限文档,保障内部数据安全。
五、安装
官网
官网:https://milvus.io/docs/zh/overview.md
Milvus 怎么读,点击这个👂。好评,不用读错了。
绕不开的Python
即使Milvus支持JAVA的JDK,也最好能了解Python
安装
官方文档已经非常详细了,不需要多解释。
Milvus Lite类似Java中H2数据库
Milvus 单机版:bat,sh文件安装,默认有WEB管理页面
Milvus Distributed:集群版了
文档:https://milvus.io/docs/zh/install-overview.md

我选择本地Docker安装:https://milvus.io/docs/zh/install_standalone-docker.md
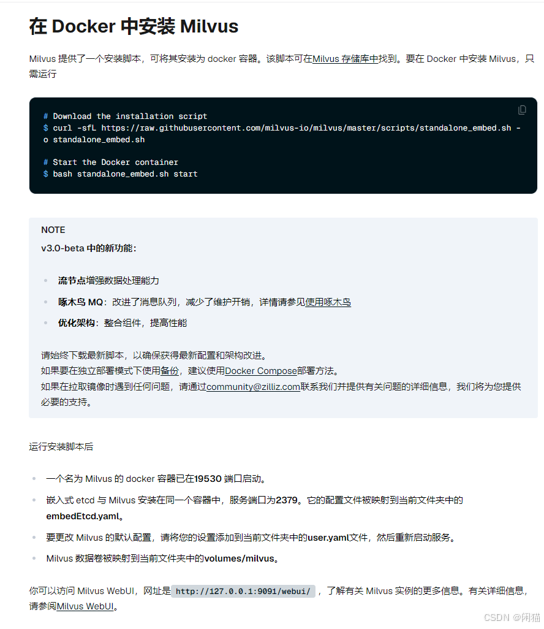
下载文件:记着PowerShell需要用管理员启动

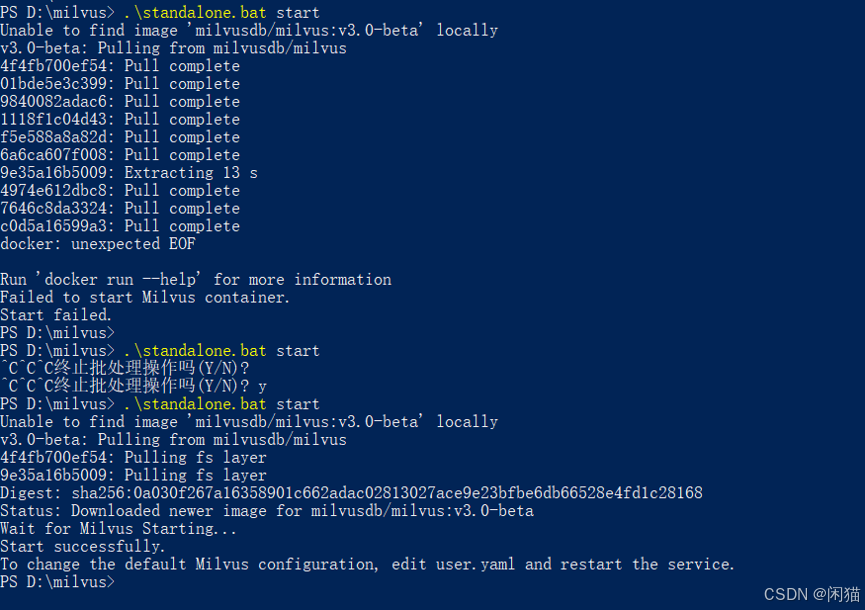
启动:
WEB UI:
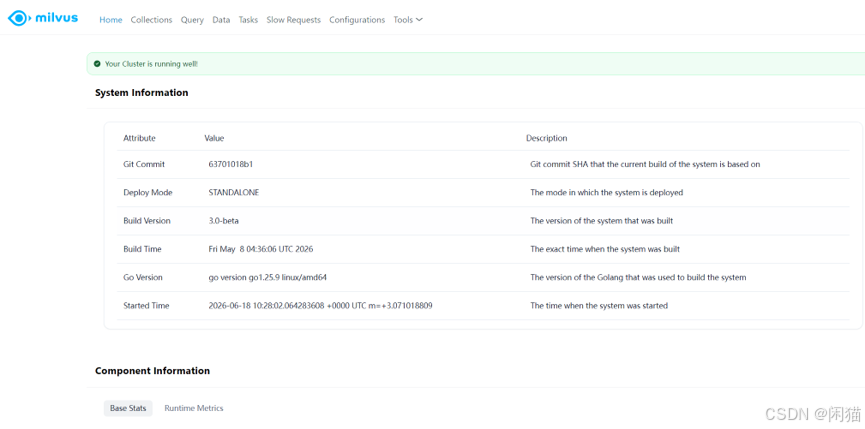
信息详解参考:https://milvus.io/docs/zh/milvus-webui.md#Home
数据目录: