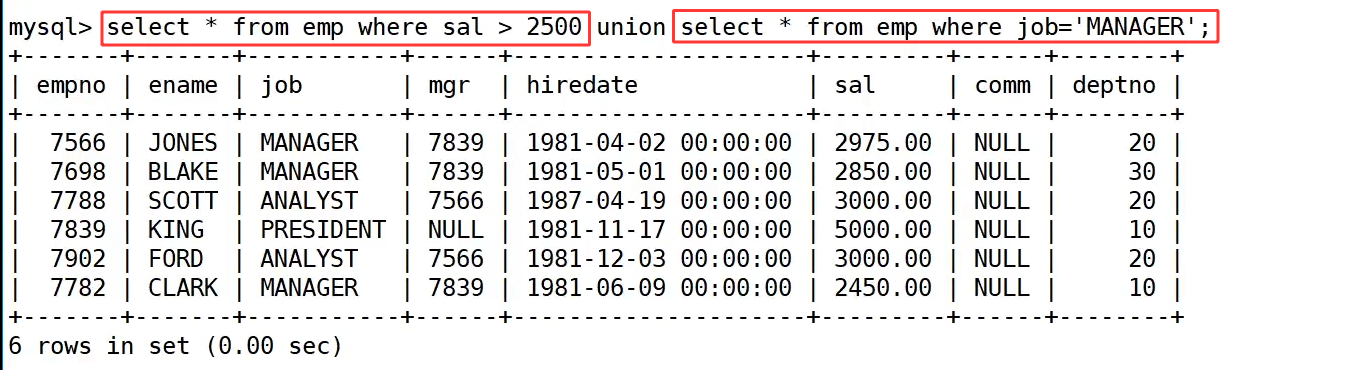
第一种写法使用了 like 进行模糊匹配,语句为 select * from emp where (sal>500 or job='MANAGER') and ename like 'J%';,这里用 () 控制了逻辑运算的优先级,确保先筛选 "工资高于 500 或岗位为 MANAGER" 的记录,再从中过滤出姓名以 J 开头的结果,最终返回了 JONES 和 JAMES 两条记录。
第二种写法使用了字符串函数来实现同样的效果,语句为 select * from emp where (sal>500 or job='MANAGER') and substring(ename, 1,1)='J';,通过 substring(ename, 1,1) 截取姓名的首字母,再判断是否等于 'J',实现了和 like 'J%' 相同的过滤效果,这也展示了字符串函数在条件查询中的灵活应用方式。
****需求2 :****按照部门号升序而雇员的工资降序排序
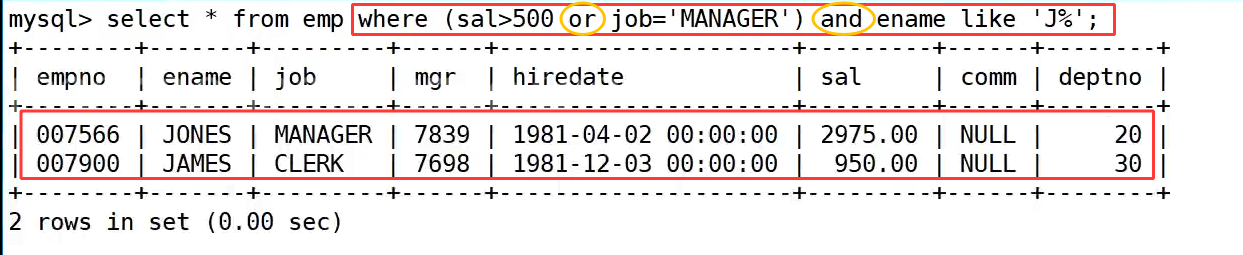
我们首先要先按部门号升序,再按工资降序排列员工数据。语句 select * from emp order by deptno asc, sal desc; 中,order by 后面指定了两个排序规则:deptno asc 表示先按部门号从小到大升序排列,部门 10 的员工排在最前,接着是部门 20、30;在同一部门内,再按 sal desc 按工资从高到低降序排列,比如部门 10 的员工按工资 5000.00、2450.00、1300.00 依次排列,部门 20、30 也遵循同样的规则。
这里要注意,order by 后的多个排序条件是用逗号分隔的,不能用 and 连接,因为它们是并列的排序规则,而非逻辑判断条件。多条件排序在实际业务中非常常见,比如按时间升序、再按热度降序,或是按分类排序、再按价格排序,通过这种方式可以精准控制数据的展示顺序。而 and 是逻辑运算符,只能用在需要写逻辑条件的地方(where/on/having 等),表示 "条件同时成立"。
****需求3 :****使用年薪进行降序排序
首先,我们先理解年薪的计算逻辑:年薪 = 月薪 sal × 12 + 年终奖 comm。但 emp 表中的 comm 字段存在三种情况:NULL、0 和具体数值,而 NULL 值参与运算时结果也会变成 NULL,无法正常计算年薪。因此我们用 ifnull(comm, 0) 处理奖金字段,当 comm 为 NULL 时,用 0 替代,保证所有员工的年薪都能正常计算。
我们先执行 select ename, sal, comm, sal*12+ifnull(comm,0) 年薪 from emp; 后,每个员工都得到了正确的年薪结果,比如 KING 的 comm 为 NULL,年薪计算为 5000×12 + 0 = 60000;ALLEN 的 comm 为 300,年薪计算为 1600×12 + 300 = 19500,直观体现了 ifnull() 的作用。
然后再按照年薪排序:
接着,我们按年薪进行降序排序,执行 select ename, sal, comm, sal*12+ifnull(comm,0) 年薪 from emp order by 年薪 desc;,通过 order by 年薪 desc 对计算出的年薪字段进行降序排列,结果中 KING 年薪最高排在首位,SMITH 年薪最低排在末尾,清晰展示了按自定义计算字段排序的效果。
这个示例的关键在于两点:一是用 ifnull() 处理 NULL 值,避免运算异常;二是 order by 可以直接使用 select 子句中定义的别名进行排序,简化了语句的书写。
需求4 : 显示工资最高的员工的名字和工作岗位
根据需求,我们需要先找出工资最高的员工的信息:
我们先看第一种分步查询的方式,它的核心思路是 "先拿到条件,再用条件查数据 "。第一步我们先通过 select max(sal) from emp; 计算出全表最高工资,聚合函数 max() 会遍历 sal 字段并返回最大值,得到结果 5000.00;第二步再用这个结果作为条件,执行 select * from emp where sal=5000;,就能匹配到工资为 5000 的员工记录,最后再通过 select ename, job 筛选出姓名和岗位字段,得到我们需要的结果。这种方式逻辑直观,便于分步调试,但需要手动执行两次查询,最高工资的数值是固定的,后续数据变化时语句无法自动适配。
所以下面我们介绍更简单的一个方法:
子查询:
子查询 : 我们可以在 where 子句中再使用 select 进行子查询,所以执行顺序就是先执行这个子查询,注意子查询要用括号括起来 我们使用更高效的子查询方式,它把两步操作合并成了一条语句,执行顺序是先执行括号内的子查询,再执行外层主查询。语句 select * from emp where sal=(select max(sal) from emp); 中,括号里的 select max(sal) from emp 会先运行并返回 5000,再把结果代入外层查询,等价于直接写 where sal=5000,一次执行就能拿到目标员工的完整信息。这里的子查询属于标量子查询,必须返回单个值,所以需要用括号包裹,同时也实现了动态计算,后续数据变化时无需修改语句。
最后我们再作名字和工作岗位的筛选:
最后我们可以直接在 select 子句中指定字段,执行 select ename, job from emp where sal=(select max(sal) from emp);,一步就得到了工资最高员工的姓名和岗位信息。
首先看分步查询的思路,我们需要先计算出全表的平均工资。执行 select avg(sal) 平均工资 from emp; 语句,avg(sal) 聚合函数会遍历 emp 表的 sal 字段,计算出所有员工工资的平均值,得到结果 2073.214286。得到这个数值后,再用它作为条件去筛选员工信息,执行 select * from emp where sal > 2073.214286;,就能找出所有工资高于平均值的员工记录。这种分步方式逻辑清晰,便于分步调试,但需要手动执行两次查询,而且如果后续员工工资发生变化,平均工资更新后,我们需要手动修改条件里的数值,不够灵活。
接着看子查询的实现方式,把计算平均工资和筛选员工信息合并成了一条语句,执行顺序是先执行括号内的子查询,再执行外层主查询。语句 select * from emp where sal > (select avg(sal) from emp); 中,括号里的 select avg(sal) from emp 会先运行,自动计算出全表平均工资,再把结果代入外层查询,等价于直接写 where sal > 2073.214286,一次执行就能拿到所有工资高于平均的员工信息。这里的子查询同样是标量子查询,返回单个数值,用括号包裹后作为外层 where 子句的条件,不仅简化了语句,还实现了动态计算,后续数据变化时无需修改语句,能自动适配最新的平均工资,和分步查询的结果完全一致。
需求6 : 显示每个部门的平均工资和最高工资
首先显示的是每个部门,因此我们需要 group by 分组。
首先,我们需要按部门进行分组,所以在语句中加上 group by deptno,它会把 emp 表中部门号相同的员工记录归为一组。执行 select deptno, max(sal) 最高, avg(sal) 平均 from emp group by deptno; 后,MySQL 会先按 deptno 分成三组(部门 10、20、30),再分别对每组执行聚合函数:max(sal) 统计每个部门的最高工资,avg(sal) 计算每个部门的平均工资,最终得到部门 10 最高工资 5000、平均 2916.67,部门 20 最高 3000、平均 2175,部门 30 最高 2850、平均 1566.67 的结果。
接着,为了让结果更易读,我们可以用 format() 函数对数值进行格式化处理,保留两位小数并添加千分位分隔符。执行 select deptno, format(max(sal),2) 最高, format(avg(sal),2) 平均 from emp group by deptno;,format(max(sal),2) 会把每个部门的最高工资格式化为保留两位小数的字符串,比如部门 10 的 5000 会变成 5,000.00,部门 10 的平均工资 2916.666... 会变成 2,916.67,这样数据的可读性更强,也更符合报表展示的需求。
需求7 : 显示平均工资低于2000的部门号和该部门的平均工资
首先我们要先算出每个部门的平均工资,然后再筛选出 < 2000 的部门,核心就是筛选分组后的聚合结果,用到了 group by 与 having 的组合。
语句 select deptno, avg(sal) 平均工资 from emp group by deptno having 平均工资 <= 2000; 先通过 group by deptno 按部门分组,计算出每个部门的平均工资;再通过 having 子句筛选出平均工资低于等于 2000 的部门,最终得到部门 30,其平均工资为 1566.666667。这里要注意,where 无法直接筛选聚合函数的结果,所以必须用 having 来完成分组后的过滤操作。
需求8 : 显示每种岗位的雇员总数,平均工资
先按岗位分组,然后再统计:
语句 select job, count(*) 人数, avg(sal) 平均工资 from emp group by job; 中,group by job 会将员工按岗位类型分成不同的组,再对每个组执行聚合统计:count(*) 统计每个岗位的员工总数,avg(sal) 计算每个岗位的平均工资,最终得到 ANALYST、CLERK、MANAGER 等不同岗位的人数和平均工资,清晰展示了岗位维度的人员分布与薪资水平。
💡 小补充:这里我们需要注意 SQL 的执行顺序,from → where → group by → 聚合函数 → having → select → order by,having 必须在 group by 之后,才能对分组结果进行过滤。
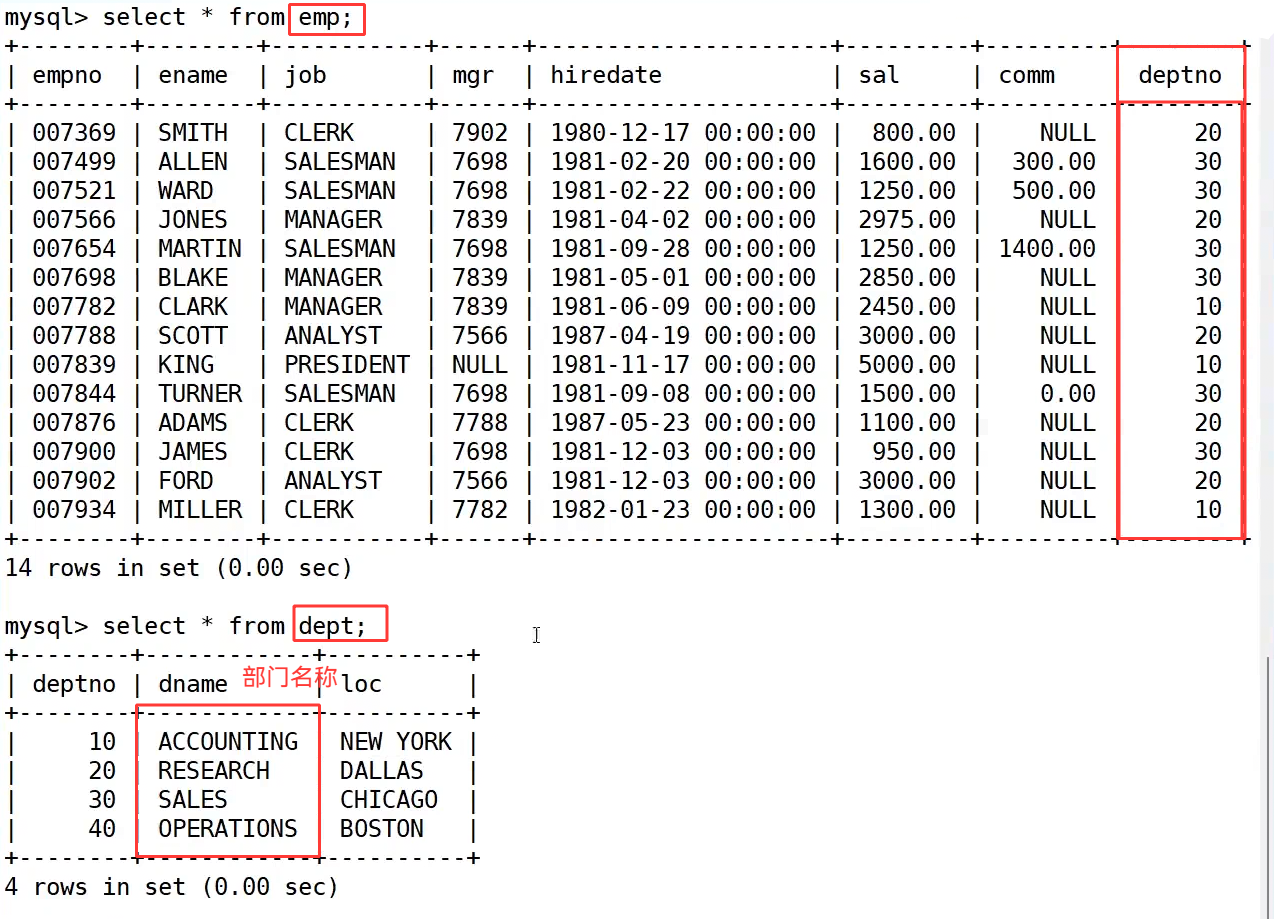
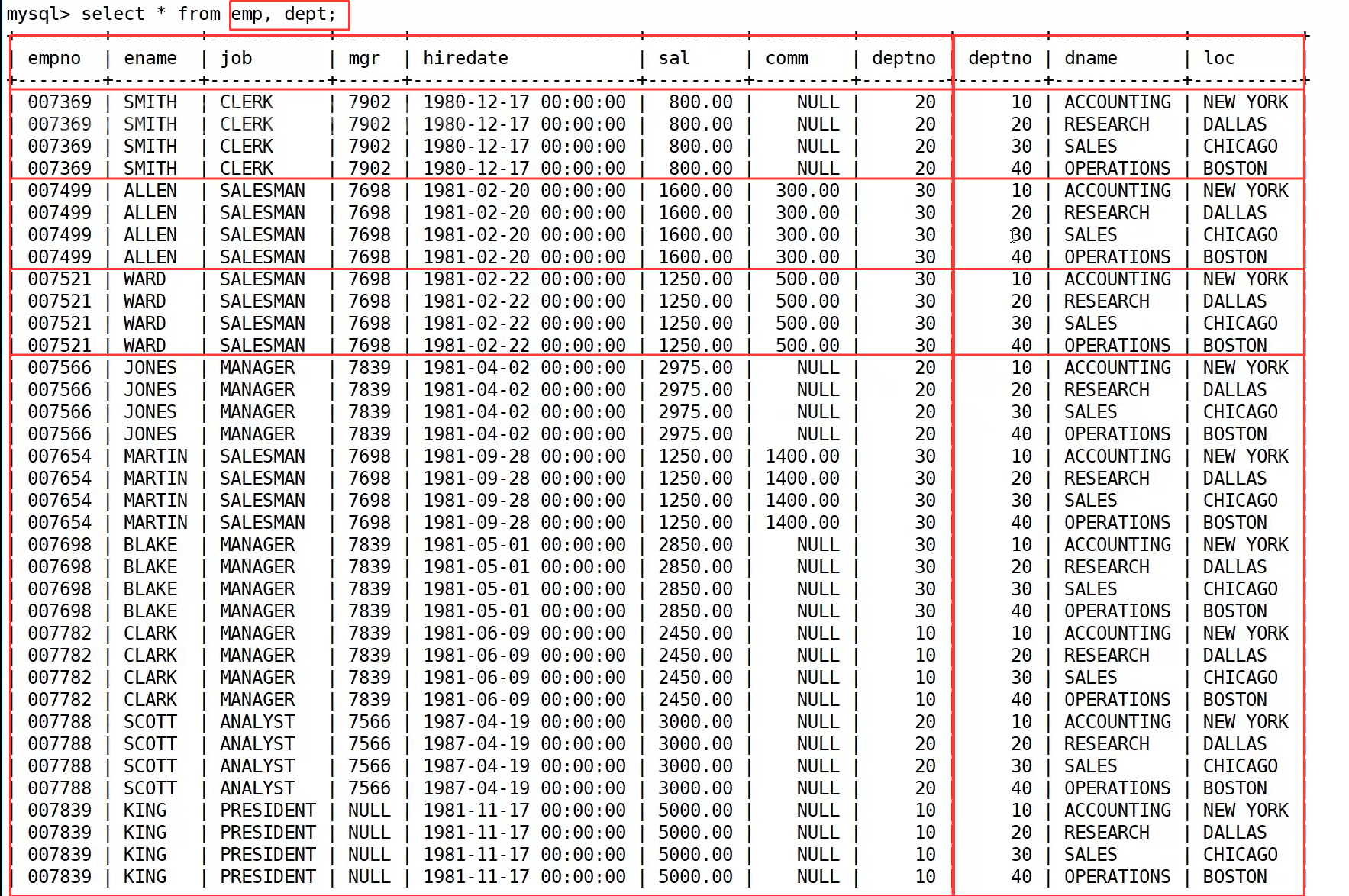
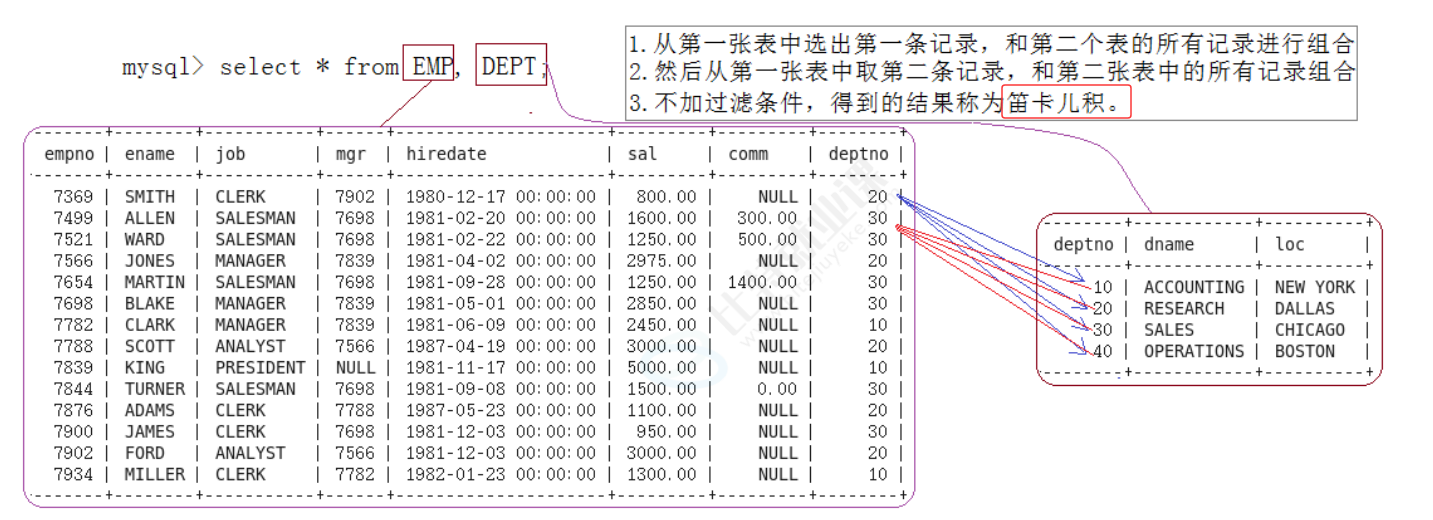
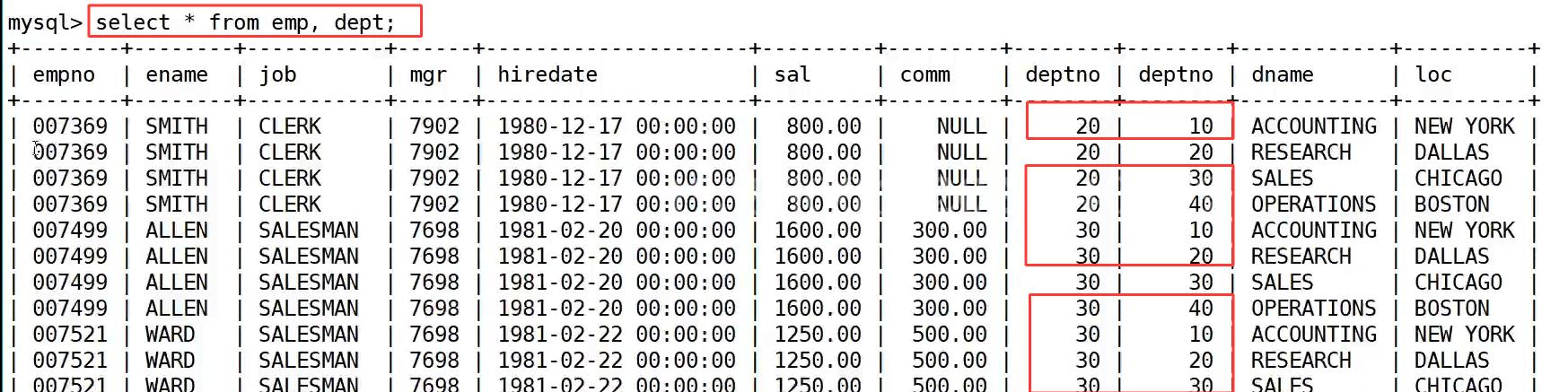
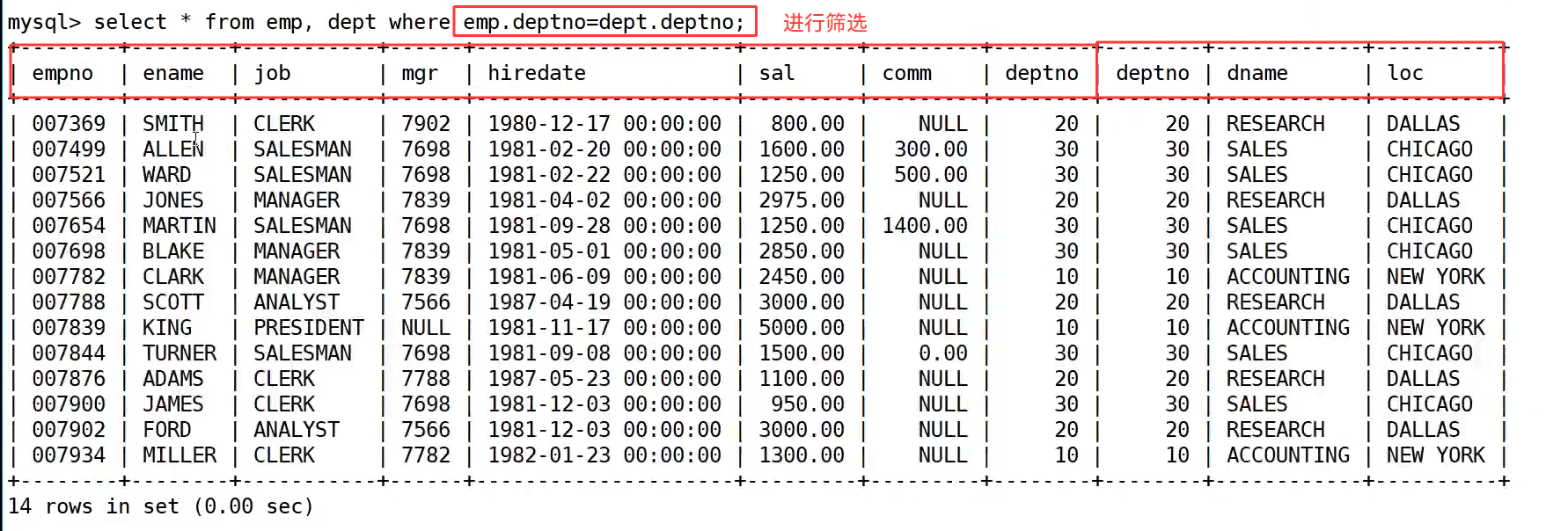
首先看没有过滤条件时的结果,执行 select * from emp, dept; 后,虽然把两张表的数据都拼在了一起,但出现了大量无意义的组合,比如员工 SMITH 的部门号是 20,却同时匹配了部门号为 10、20、30、40 的所有部门,这显然不符合业务逻辑,这些错误匹配的记录就是笛卡尔积带来的无效数据。
接下来,我们通过 where 子句添加连接条件 emp.deptno = dept.deptno,对笛卡尔积的结果进行过滤。执行 select * from emp, dept where emp.deptno = dept.deptno; 后,数据库会只保留员工部门号和部门表部门号相等的记录,这样 SMITH 就只会匹配到部门号为 20 的 RESEARCH 部门,其他错误匹配的记录都被过滤掉了,此时的结果就是完全符合业务逻辑的有效数据,共 14 条记录,和员工表的数量一致。
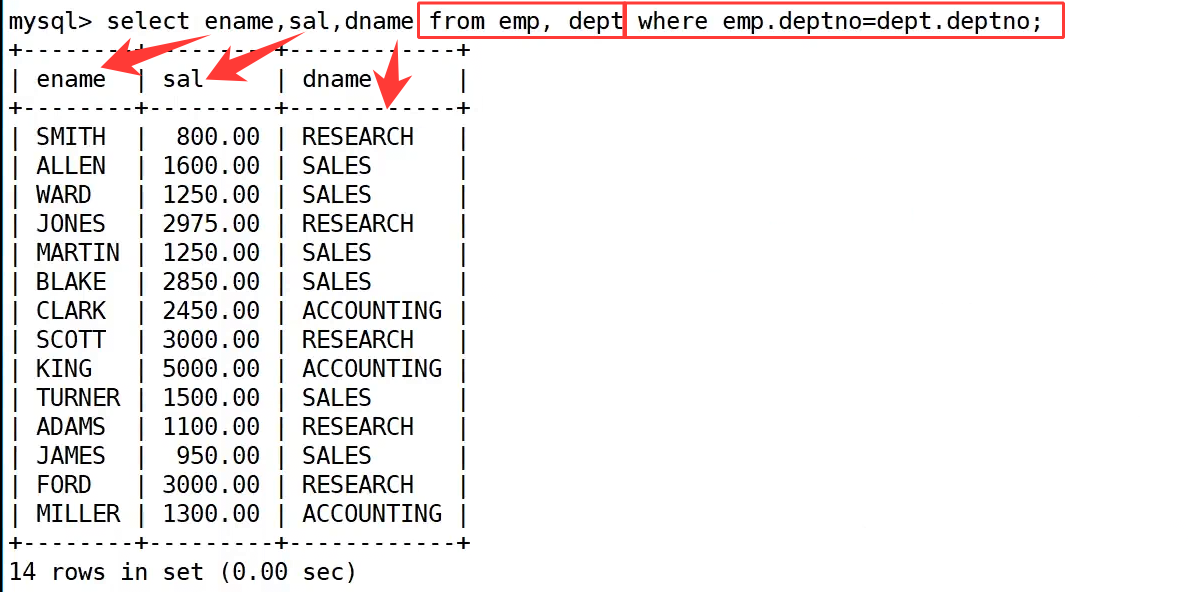
最后,我们根据需求只选择需要的字段,执行 select ename, sal, dname from emp, dept where emp.deptno = dept.deptno;,就得到了最终的查询结果,清晰展示了每个员工的姓名、工资和对应的部门名称,既满足了业务需求,也解决了笛卡尔积的无效数据问题。这也说明,多表查询的核心就是通过关联字段过滤无效组合,把两张表的数据正确拼接起来。
需求2 : 显示部门号为10的部门名,员工名和工资
这个需求是在两表关联的基础上,额外增加筛选条件,查询部门号为 10 的部门名称、员工姓名与工资。
语句沿用了 emp 和 dept 两张表的等值连接条件 emp.deptno=dept.deptno,再用 and emp.deptno=10 追加部门过滤规则。数据库会先匹配两张表正确的对应关系,再从中筛选出部门编号为 10 的员工,最终只返回 CLARK、KING、MILLER 三位员工的相关信息,精准锁定目标部门数据。这里两个条件用 and 并列,一个是表连接匹配条件,一个是业务筛选条件,顺序不影响最终查询结果。
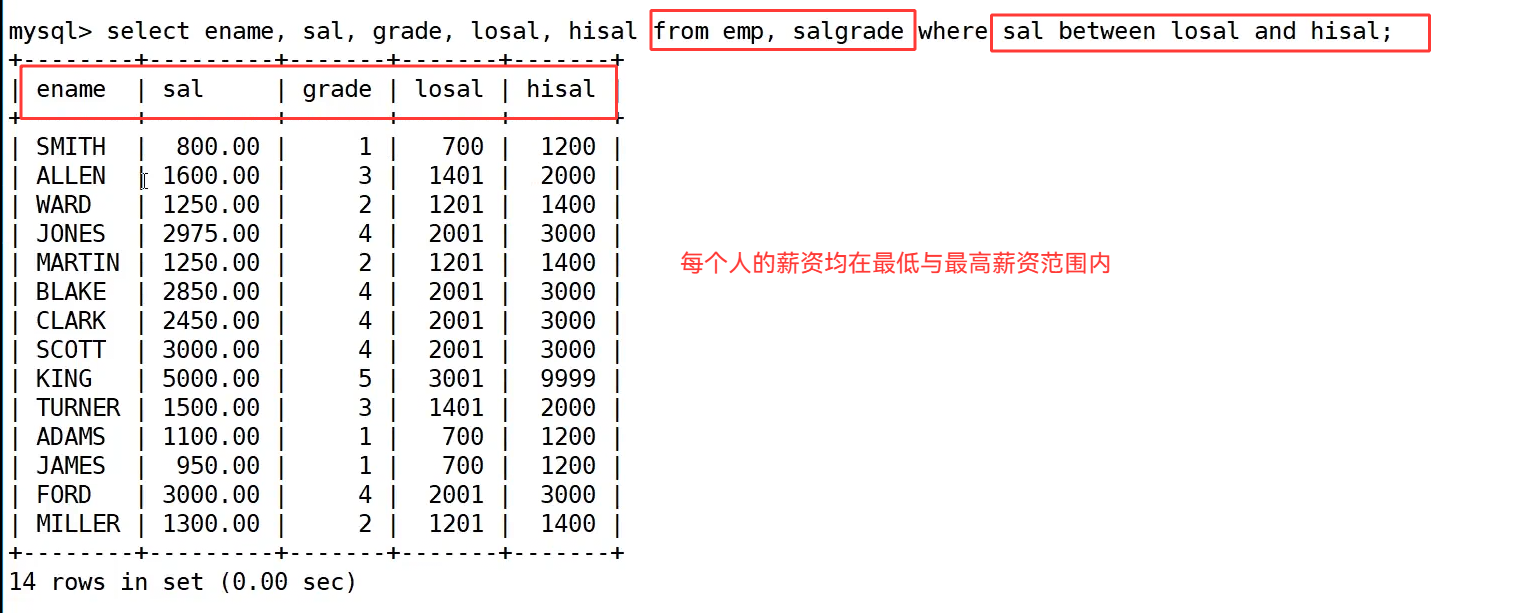
我们不能用等值匹配关联两张表,而是使用 between ... and ... 范围判断语句,语句为 select ename, sal, grade, losal, hisal from emp, salgrade where sal between losal and hisal;。执行时会逐个匹配员工工资,找到它所属的薪资区间,对应到正确的工资等级,最终每一位员工都能匹配到自己对应的薪资级别,完整呈现所有员工的姓名、工资与对应工资档位。
三、自连接
什么是自连接?
自连接,顾名思义就是在同一张表上进行连接查询。我们可以理解为 "一张表自己和自己做笛卡尔积,再加上过滤条件",以此来处理表内存在层级或关联关系的数据。自连接的原理和多表连接一样,也会先产生笛卡尔积,再通过 where 或 on 子句过滤出有效记录。
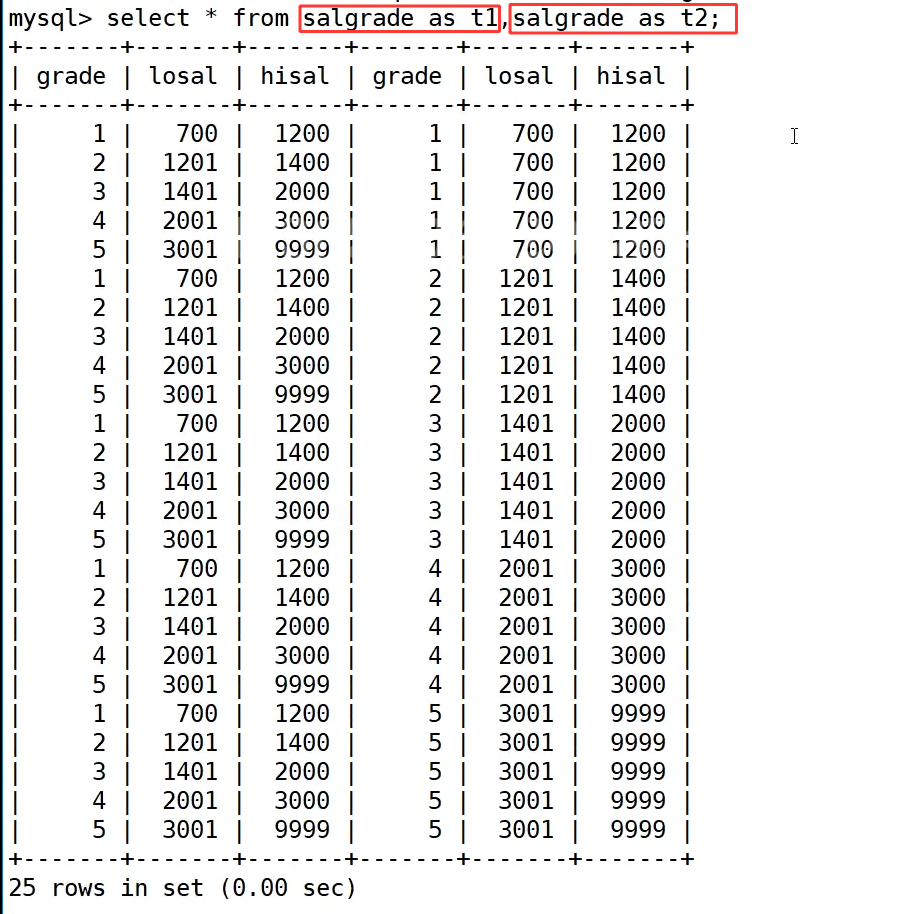
我们先看自连接中最容易踩的坑:不使用别名直接连接同一张表。执行 select * from salgrade, salgrade; 会直接报错 ERROR 1066 (42000): Not unique table/alias: 'salgrade',原因是数据库无法区分两个同名的 salgrade 表,后续如果引用字段,它不知道该从哪张表里取数据,所以自连接必须给表起不同的别名。
接着看正确的写法:select * from salgrade as t1, salgrade as t2;。这里通过 as t1 和 as t2 给同一张表起了两个不同的别名,逻辑上把它拆成了两张独立的表,数据库就能正常解析和执行了。执行后得到的是 salgrade 表的笛卡尔积,因为原表有 5 条记录,所以结果是 5×5=25 条数据,每一条 t1 的记录都和 t2 的所有记录做了交叉组合,比如 t1 中 grade=1 的记录,会和 t2 中 grade=1 到 grade=5 的所有记录依次拼接,这也是自连接的底层执行逻辑。
在实际使用中,我们必须添加 where 或 on 子句来过滤出符合业务逻辑的记录,或者通过范围条件才能让自连接发挥真正的作用。
使用场景是什么呢? 下面举例:
需求1 : 显示员工FORD的上级领导的编号和姓名(mgr是员工领导的编号--empno)
这个需求是查询员工 FORD 的上级领导编号和姓名,而员工和领导的信息都存在同一张 emp 表里,因为员工表的 mgr 字段是领导的员工编号,对应着 empno 字段,所以可以用两种方式来实现。
第一种方法: 子查询:
用子查询的方法,是分两步走的。第一步,通过 select mgr from emp where ename='FORD' 先查到 FORD 的领导编号是 007566;第二步,再用这个编号去匹配领导信息,执行 select ename, empno from emp where empno=(子查询结果),就能得到领导 JONES 的信息,这种方式逻辑很清晰,把两步查询合并成了一条语句。
第二种方法: 自连接:
而用自连接的方法是把 emp 表通过别名拆成两张表来处理,语句 select e2.ename, e2.empno from emp e1, emp e2 where e1.ename='FORD' and e1.mgr=e2.empno; 中,e1 作为员工表,e2 作为领导表,通过 e1.mgr=e2.empno 这个连接条件,直接把 FORD 和他的领导关联起来,一次查询就能得到结果,和子查询的结果完全一致。
多行子查询会返回多行数据,比如 "查询所有部门的平均工资",这种结果就不能再用 = 直接匹配了,需要搭配 in、any、all 这类多值运算符使用。比如用 where sal in (select avg(sal) from emp group by deptno),就能筛选出工资等于任意部门平均工资的员工,这也是多行子查询最常见的用法,适合处理 "在一组值中匹配" 的场景。
单行子查询
需求1 :显示SMITH同一部门的员工
这个需求是 "显示和 SMITH 同一部门的员工",而我们不知道 SMITH 的部门号,所以需要用子查询先拿到这个信息,再作为条件筛选员工。
首先,内层的 select deptno from emp where ename='SMITH' 就是典型的单行子查询,它只会返回一行一列的单个结果,也就是 SMITH 的部门号 20。这个结果会被直接代入外层查询的 where deptno=... 条件中,所以外层查询等价于 select * from emp where deptno=20;。接着,外层查询会根据部门号 20 筛选所有员工,最终返回了部门 20 的 5 条记录,包括 SMITH 本人和其他同事。整个过程是 "先算条件,再查数据",子查询在这里起到了动态获取条件值的作用,避免了手动硬编码部门号。
这两个关键字的核心区别在于,all 要求 "比所有值都满足条件",是一种严格的筛选;而 any 只要求 "比任意一个值满足条件",是宽松的筛选。它们都需要搭配多行子查询使用,让我们能对一组值进行批量比较,而不用手动写多个条件。
对比总结:
in 关键字的作用是判断字段值是否存在于子查询返回的结果列表中,本质上是一种 "多值等值匹配"。当子查询返回多行结果时,我们无法用 = 直接匹配,而 in 关键字可以让外层字段和子查询返回的每一个值进行比较,只要有一个匹配成功,该行就会被保留。它适合处理 "是否属于某一组值" 的场景,比如查询和 10 号部门岗位相同的员工,就是用 in 来匹配子查询返回的所有岗位列表。
all 关键字要求字段值与子查询返回的所有值都满足比较条件,是一种严格的批量比较。比如 sal > all(...) 就意味着,员工工资必须比子查询返回的每一个工资值都要大,也就是要大于这组值中的最大值。这种用法适合处理 "超过所有值" 的场景,比如查询工资比部门 30 所有员工都高的员工,就是要筛选出工资超过部门 30 最高值的记录,结果数量相对较少,筛选条件也更严苛。
any 关键字要求字段值与子查询返回的任意一个值满足比较条件即可,是一种宽松的批量比较。比如 sal > any(...) 就意味着,员工工资只要比子查询返回的工资列表中的某一个值大,就符合条件,也就是只要大于这组值中的最小值即可。这种用法适合处理 "超过任意一个值" 的场景,比如查询工资比部门 30 任意一名员工高的员工,只要工资高于部门 30 的最低工资就会被保留,结果数量会更多,筛选条件也更宽泛。
总的来说,in 关注的是 "是否在列表中",而 all 和 any 关注的是 "与列表中值的大小关系",它们分别对应了多行子查询中不同的业务筛选需求,能帮我们实现更灵活的批量数据过滤。
这个案例的需求是查询和 SMITH 的部门和岗位完全相同的所有雇员,且不包含 SMITH 本人。这里的关键是 "部门和岗位都要和 SMITH 完全一致",也就是需要同时匹配 deptno 和 job 两个字段,这正是多列子查询的典型使用场景。
多列子查询的关键语法是用括号把需要匹配的多个字段包起来,比如 (deptno, job),再和子查询返回的对应列进行等值比较。执行 select * from emp where (deptno, job) = (select deptno, job from emp where ename='SMITH'); 时,数据库会先执行内层子查询 select deptno, job from emp where ename='SMITH',一次性拿到 SMITH 的部门号 20 和岗位 CLERK,这是一个 "一行两列" 的结果。外层查询则会同时匹配员工的 deptno 和 job,筛选出和这两个值都相同的记录,所以结果会包含 SMITH 本人和同部门同岗位的 ADAMS,共 2 条数据。因为上面的结果包含了 SMITH 自己,而需求要求 "不含 SMITH 本人",所以我们需要在原来的条件基础上,加上 and ename <> 'SMITH' 来过滤。修改后的语句是 select * from emp where (deptno, job) = (select deptno, job from emp where ename='SMITH') and ename <> 'SMITH';,执行后就只会返回 ADAMS 这一条记录,符合需求。
多列子查询除了用 = 匹配单行结果,也可以把等号换成 in,来处理子查询返回多行多列的情况,语法结构依然是 (列1, 列2) in (多列子查询)。同时要注意,我们目前接触的所有子查询,都是在 where 子句中充当判断条件,而这些子查询返回的临时结果,本质上在逻辑上也是一张表,这也是后续 from 子查询的基础。
多列子查询的价值
多列子查询的价值在于简化了多字段等值匹配的逻辑。如果不用多列子查询,我们需要先查 SMITH 的部门号和岗位,再在外层用 deptno=... and job=... 来写条件,而多列子查询可以一次性拿到并匹配这两个值,让代码更简洁,也更贴合 "多字段同时匹配" 的业务场景。
在from子句中使用子查询
from 子句中使用子查询,也叫派生表查询。和之前在 where 子句中充当条件的子查询不同,这里的子查询是直接出现在 from 关键字后面,作为一张 "临时表" 来使用的。核心逻辑是数据库会先执行内层的子查询,生成一个临时的结果集,然后外层查询把这个结果集当作一张普通的表来进行后续操作,比如连接、筛选或聚合。这就意味着,我们可以先通过子查询把数据过滤、处理成我们想要的样子,再在外层对这部分 "干净" 的数据进行二次加工,非常适合处理复杂的分步查询逻辑。
我们先从需求出发,理解这个案例的目标是找出工资高于所在部门平均工资的员工,并展示他们的姓名、部门、工资和部门平均工资。为了实现这个目标,我们需要先拿到每个部门的平均工资,再和员工数据进行关联对比,而 from 子句中的子查询,就是实现这个分步处理的关键。
我们先进行笛卡尔积:首先,我们需要生成一个包含部门号和对应平均工资的临时结果集,这一步通过 select deptno, avg(sal) from emp group by deptno 完成。但要注意,在 from 子句中使用子查询时,必须给这个临时结果集起一个别名,否则数据库会报错,所以我们给它加上别名 tmp,并给平均工资列也起了别名 myavg,方便后续引用。执行 select * from emp, (select deptno, avg(sal) myavg from emp group by deptno) tmp 后,数据库会把员工表和这个临时平均工资表做笛卡尔积,每个员工都会和所有部门的平均工资做交叉组合,所以每个员工会出现多次,这是未过滤的原始数据,后续需要通过条件筛选出有效记录。
下面我们需要进行筛选:
接下来,我们添加连接条件,把员工和自己所在部门的平均工资对应起来,在 where 子句中加上 emp.deptno=tmp.deptno,这样每个员工只会保留和自己部门对应的平均工资记录,此时的结果已经是员工信息加上所在部门的平均工资,为下一步的对比做好了准备。然后,我们添加工资对比条件,在原来的条件基础上加上 and emp.sal > tmp.myavg,筛选出工资高于部门平均工资的员工,执行后就得到了符合需求的结果,能看到每个员工的工资都比自己部门的平均值要高,同时还能展示对应的部门平均工资数据。
如果我们想进一步丰富结果,比如加上部门的办公地点,只需要把部门表 dept 也加入查询,通过 deptno 字段进行关联即可。此时可以把上一步筛选出的员工结果集再作为一个临时表,和 dept 表连接,就能得到包含员工姓名、部门地点、部门号的完整信息,实现多层嵌套的复杂查询,也体现了 from 子句子查询可以灵活处理多步数据加工的优势。整个过程的核心,就是利用 from 子句中的子查询,把复杂的查询拆解成预处理、关联、筛选等步骤,让逻辑更清晰,也能实现普通查询难以直接完成的多维度数据对比。
案例2:查找每个部门工资最高的人的姓名、工资、部门、最高工资
先进行笛卡尔积:
案例 2 的目标是查询每个部门工资最高的员工信息,首先通过 select deptno, max(sal) mymax from emp group by deptno 得到每个部门的最高工资,并给这个临时结果集起别名 t2。
再筛选:
接着执行 select * from emp t1, t2,将员工表和部门最高工资表做笛卡尔积,此时每个员工都会和所有部门的最高工资交叉组合,这一步是为后续的关联对比做准备。然后添加 where t1.deptno = t2.deptno and t1.sal = t2.mymax 条件,既把员工和自己所在部门的最高工资对应起来,又筛选出工资等于部门最高值的员工,最终得到每个部门工资最高的记录,包含员工姓名、工资、部门号和最高工资。
案例3:显示每个部门的信息(部门名,编号,地址)和人员数量
先进行笛卡尔积:
案例 3 则是要展示每个部门的信息和人员数量,先通过 select deptno, count(*) dept_num from emp group by deptno 统计每个部门的人数,生成临时表 t2,再和部门表 dept t1 做笛卡尔积。
再筛选;
此时每个部门信息会和所有部门的人员数量交叉组合,之后通过 where t1.deptno = t2.deptno 条件,将部门信息和本部门的人员数量关联起来,就能得到每个部门的完整信息,包括部门名称、编号、地址和员工数量,同时也能看到部门 40 因为没有员工,不会出现在最终结果中。
多表查询的指导思想:
解决多表查询问题的本质,就是想办法把多表问题转化为单表问题,所以 MySQL 中所有的 select 问题,理论上都可以转化为单表问题来处理。这个思想贯穿了我们前面学过的所有多表查询和子查询用法。无论是普通的多表连接,还是 from 子句中的子查询,本质上都是通过关联字段或者临时表,把多张表的数据合并成一张逻辑上的 "大表",然后就可以用单表查询的方式来筛选、聚合数据了。
我们现在来看合并查询,它的核心是用 union 和 union all 这类集合操作符,把多个 select 语句的结果合并成一个结果集。union 操作符的作用是取两个结果集的并集,它会自动去除重复的记录。
案例1:将工资大于2500或职位是MANAGER的人找出来
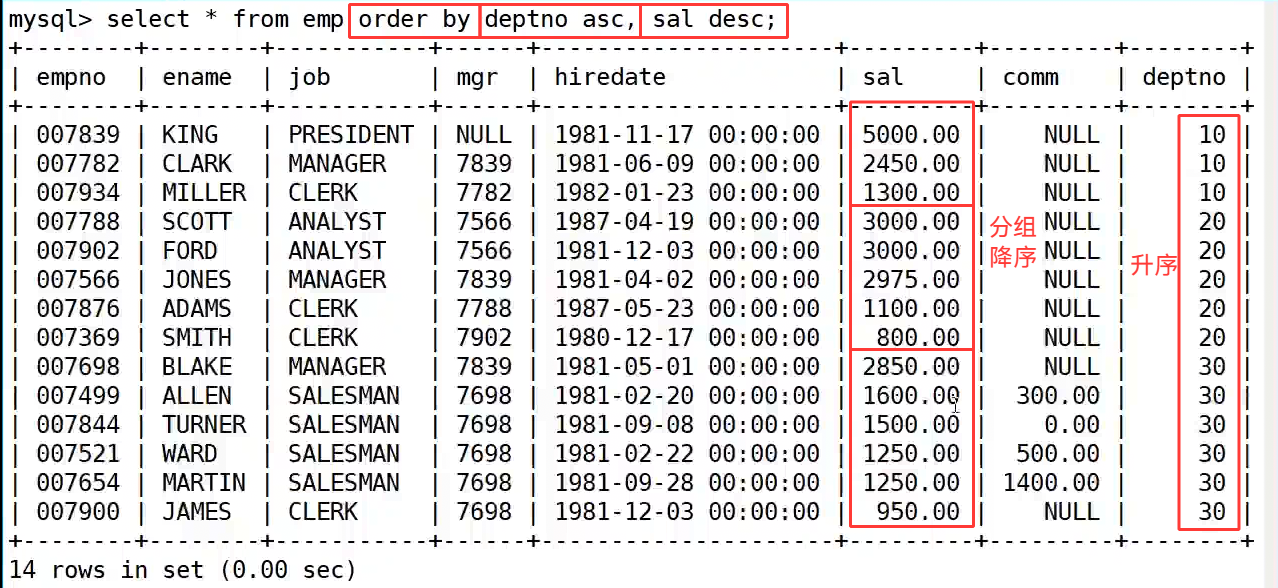
案例中 "工资大于 2500 或 职位是 MANAGER" 的需求,用 where sal > 2500 or job='MANAGER' 也能实现,而用 union 的方式,就是先分别查出 sal > 2500 的员工和 job='MANAGER' 的员工,再用 union 合并结果。执行后,像 JONES 这种同时满足两个条件的员工,只会出现一次,因为 union 会自动去重,最终得到 6 条不重复的记录。
而 union all 和 union 的区别就是 union all 不会去重,会保留所有重复的记录。如果上面的案例换成 union all,JONES 这种同时满足两个条件的员工就会出现两次,结果数量也会比 union 多。它的优势是执行效率比 union 高,因为不需要额外的去重操作,适合确定结果中没有重复数据,或者需要保留重复记录的场景。
使用合并查询时要注意,多个 select 语句返回的列数、列的顺序和数据类型必须一致,否则
会报错。这种写法的优势在于,可以把复杂的 or 条件或者跨表的查询拆分成多个独立的 select 语句,逻辑更清晰,也方便调试,同时还能根据是否需要去重,灵活选择 union 或 union all。
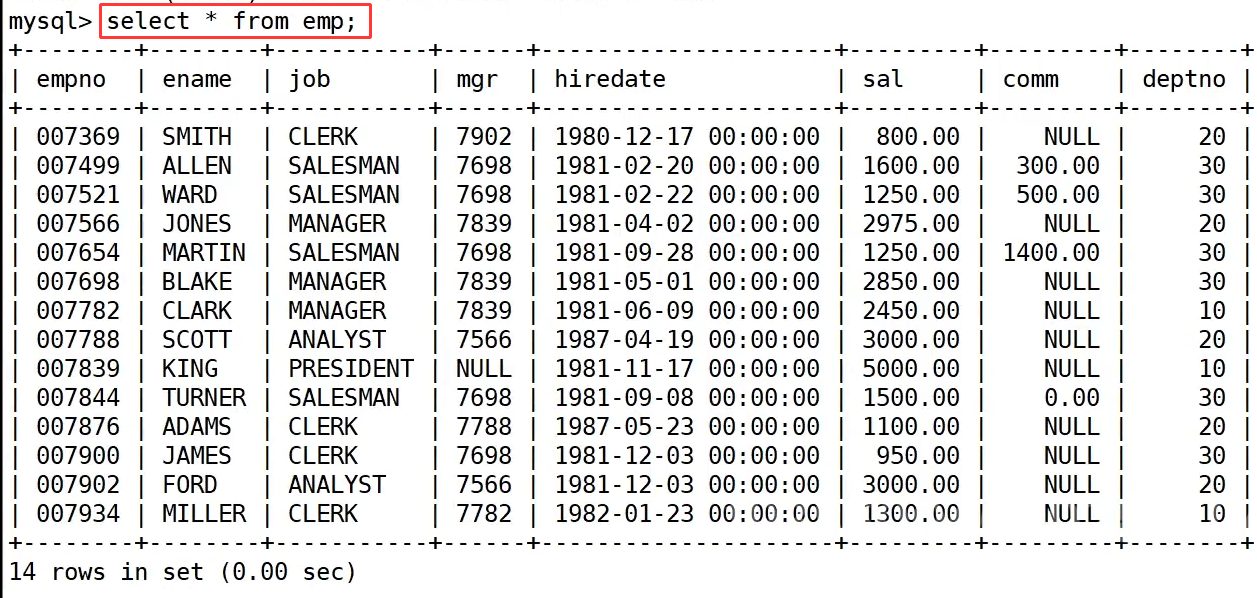 依旧是 emp 这张表,我们使用这张表进行基本查询。
依旧是 emp 这张表,我们使用这张表进行基本查询。第二种写法使用了字符串函数来实现同样的效果,语句为 select * from emp where (sal>500 or job='MANAGER') and substring(ename, 1,1)='J';,通过 substring(ename, 1,1) 截取姓名的首字母,再判断是否等于 'J',实现了和 like 'J%' 相同的过滤效果,这也展示了字符串函数在条件查询中的灵活应用方式。
我们先执行 select ename, sal, comm, sal*12+ifnull(comm,0) 年薪 from emp; 后,每个员工都得到了正确的年薪结果,比如 KING 的 comm 为 NULL,年薪计算为 5000×12 + 0 = 60000;ALLEN 的 comm 为 300,年薪计算为 1600×12 + 300 = 19500,直观体现了 ifnull() 的作用。
接着,我们按年薪进行降序排序,执行 select ename, sal, comm, sal*12+ifnull(comm,0) 年薪 from emp order by 年薪 desc;,通过 order by 年薪 desc 对计算出的年薪字段进行降序排列,结果中 KING 年薪最高排在首位,SMITH 年薪最低排在末尾,清晰展示了按自定义计算字段排序的效果。
我们先看第一种分步查询的方式,它的核心思路是 "先拿到条件,再用条件查数据 "。第一步我们先通过 select max(sal) from emp; 计算出全表最高工资,聚合函数 max() 会遍历 sal 字段并返回最大值,得到结果 5000.00;第二步再用这个结果作为条件,执行 select * from emp where sal=5000;,就能匹配到工资为 5000 的员工记录,最后再通过 select ename, job 筛选出姓名和岗位字段,得到我们需要的结果。这种方式逻辑直观,便于分步调试,但需要手动执行两次查询,最高工资的数值是固定的,后续数据变化时语句无法自动适配。
我们使用更高效的子查询方式,它把两步操作合并成了一条语句,执行顺序是先执行括号内的子查询,再执行外层主查询。语句 select * from emp where sal=(select max(sal) from emp); 中,括号里的 select max(sal) from emp 会先运行并返回 5000,再把结果代入外层查询,等价于直接写 where sal=5000,一次执行就能拿到目标员工的完整信息。这里的子查询属于标量子查询,必须返回单个值,所以需要用括号包裹,同时也实现了动态计算,后续数据变化时无需修改语句。

接着看子查询的实现方式,把计算平均工资和筛选员工信息合并成了一条语句,执行顺序是先执行括号内的子查询,再执行外层主查询。语句 select * from emp where sal > (select avg(sal) from emp); 中,括号里的 select avg(sal) from emp 会先运行,自动计算出全表平均工资,再把结果代入外层查询,等价于直接写 where sal > 2073.214286,一次执行就能拿到所有工资高于平均的员工信息。这里的子查询同样是标量子查询,返回单个数值,用括号包裹后作为外层 where 子句的条件,不仅简化了语句,还实现了动态计算,后续数据变化时无需修改语句,能自动适配最新的平均工资,和分步查询的结果完全一致。



语句 select deptno, avg(sal) 平均工资 from emp group by deptno having 平均工资 <= 2000; 先通过 group by deptno 按部门分组,计算出每个部门的平均工资;再通过 having 子句筛选出平均工资低于等于 2000 的部门,最终得到部门 30,其平均工资为 1566.666667。这里要注意,where 无法直接筛选聚合函数的结果,所以必须用 having 来完成分组后的过滤操作。






而用自连接的方法是把 emp 表通过别名拆成两张表来处理,语句 select e2.ename, e2.empno from emp e1, emp e2 where e1.ename='FORD' and e1.mgr=e2.empno; 中,e1 作为员工表,e2 作为领导表,通过 e1.mgr=e2.empno 这个连接条件,直接把 FORD 和他的领导关联起来,一次查询就能得到结果,和子查询的结果完全一致。
子查询的核心是把一个 select 语句嵌入到另一个 SQL 语句中,也叫嵌套查询。子查询的本质就是先执行内层的查询,把它的结果作为外层语句的条件或数据源,从而实现分步处理数据的逻辑。根据内层查询返回结果的不同,它可以分为单行子查询和多行子查询两种,它们在写法和使用场景上也有明显区别。

首先,内层的 select deptno from emp where ename='SMITH' 就是典型的单行子查询,它只会返回一行一列的单个结果,也就是 SMITH 的部门号 20。这个结果会被直接代入外层查询的 where deptno=... 条件中,所以外层查询等价于 select * from emp where deptno=20;。接着,外层查询会根据部门号 20 筛选所有员工,最终返回了部门 20 的 5 条记录,包括 SMITH 本人和其他同事。整个过程是 "先算条件,再查数据",子查询在这里起到了动态获取条件值的作用,避免了手动硬编码部门号。


需求是 "显示工资比部门 30 的所有员工工资都高的员工"。内层 select distinct sal from emp where deptno=30 会返回部门 30 所有员工的不重复工资,比如 1600、1250、2850 这些值。sal > all(...) 的意思是员工的工资必须比这一组值中的每一个都大,也就是要大于部门 30 的最高工资。部门 30 的最高工资是 2850,所以最终筛选出的是工资超过 2850 的员工,比如 JONES、SCOTT 等,共 4 条记录。
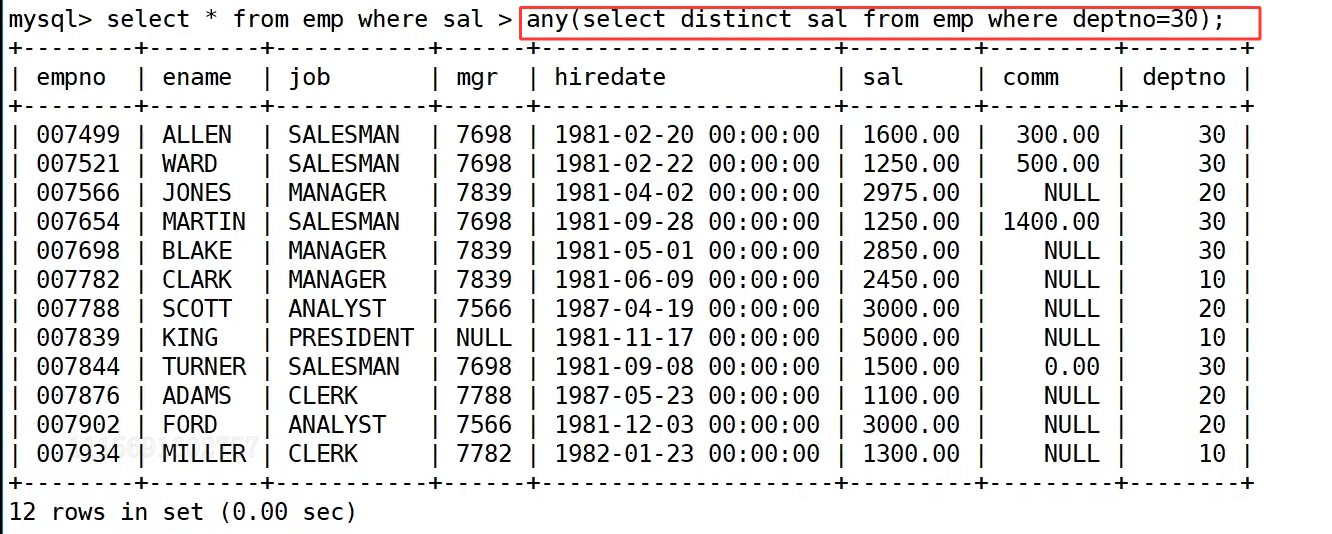
之前我们接触的单行、多行子查询,都是针对单列 的,返回的结果只有一列数据。而多列子查询,顾名思义是指子查询同时返回多个列的数据,相当于一次性拿到一组相关联的值,作为外层查询的匹配条件。它的核心优势是可以实现 "多字段同时匹配",不用分开写多个条件,逻辑更紧凑。
多列子查询的关键语法是用括号把需要匹配的多个字段包起来,比如 (deptno, job),再和子查询返回的对应列进行等值比较。执行 select * from emp where (deptno, job) = (select deptno, job from emp where ename='SMITH'); 时,数据库会先执行内层子查询 select deptno, job from emp where ename='SMITH',一次性拿到 SMITH 的部门号 20 和岗位 CLERK,这是一个 "一行两列" 的结果。外层查询则会同时匹配员工的 deptno 和 job,筛选出和这两个值都相同的记录,所以结果会包含 SMITH 本人和同部门同岗位的 ADAMS,共 2 条数据。因为上面的结果包含了 SMITH 自己,而需求要求 "不含 SMITH 本人",所以我们需要在原来的条件基础上,加上 and ename <> 'SMITH' 来过滤。修改后的语句是 select * from emp where (deptno, job) = (select deptno, job from emp where ename='SMITH') and ename <> 'SMITH';,执行后就只会返回 ADAMS 这一条记录,符合需求。
多列子查询的价值在于简化了多字段等值匹配的逻辑。如果不用多列子查询,我们需要先查 SMITH 的部门号和岗位,再在外层用 deptno=... and job=... 来写条件,而多列子查询可以一次性拿到并匹配这两个值,让代码更简洁,也更贴合 "多字段同时匹配" 的业务场景。

from 子句中使用子查询,也叫派生表查询。和之前在 where 子句中充当条件的子查询不同,这里的子查询是直接出现在 from 关键字后面,作为一张 "临时表" 来使用的。核心逻辑是数据库会先执行内层的子查询,生成一个临时的结果集,然后外层查询把这个结果集当作一张普通的表来进行后续操作,比如连接、筛选或聚合。这就意味着,我们可以先通过子查询把数据过滤、处理成我们想要的样子,再在外层对这部分 "干净" 的数据进行二次加工,非常适合处理复杂的分步查询逻辑。
首先,我们需要生成一个包含部门号和对应平均工资的临时结果集,这一步通过 select deptno, avg(sal) from emp group by deptno 完成。但要注意,在 from 子句中使用子查询时,必须给这个临时结果集起一个别名,否则数据库会报错,所以我们给它加上别名 tmp,并给平均工资列也起了别名 myavg,方便后续引用。执行 select * from emp, (select deptno, avg(sal) myavg from emp group by deptno) tmp 后,数据库会把员工表和这个临时平均工资表做笛卡尔积,每个员工都会和所有部门的平均工资做交叉组合,所以每个员工会出现多次,这是未过滤的原始数据,后续需要通过条件筛选出有效记录。
接下来,我们添加连接条件,把员工和自己所在部门的平均工资对应起来,在 where 子句中加上 emp.deptno=tmp.deptno,这样每个员工只会保留和自己部门对应的平均工资记录,此时的结果已经是员工信息加上所在部门的平均工资,为下一步的对比做好了准备。然后,我们添加工资对比条件,在原来的条件基础上加上 and emp.sal > tmp.myavg,筛选出工资高于部门平均工资的员工,执行后就得到了符合需求的结果,能看到每个员工的工资都比自己部门的平均值要高,同时还能展示对应的部门平均工资数据。
如果我们想进一步丰富结果,比如加上部门的办公地点,只需要把部门表 dept 也加入查询,通过 deptno 字段进行关联即可。此时可以把上一步筛选出的员工结果集再作为一个临时表,和 dept 表连接,就能得到包含员工姓名、部门地点、部门号的完整信息,实现多层嵌套的复杂查询,也体现了 from 子句子查询可以灵活处理多步数据加工的优势。整个过程的核心,就是利用 from 子句中的子查询,把复杂的查询拆解成预处理、关联、筛选等步骤,让逻辑更清晰,也能实现普通查询难以直接完成的多维度数据对比。
案例 2 的目标是查询每个部门工资最高的员工信息,首先通过 select deptno, max(sal) mymax from emp group by deptno 得到每个部门的最高工资,并给这个临时结果集起别名 t2。

案例 3 则是要展示每个部门的信息和人员数量,先通过 select deptno, count(*) dept_num from emp group by deptno 统计每个部门的人数,生成临时表 t2,再和部门表 dept t1 做笛卡尔积。

解决多表查询问题的本质,就是想办法把多表问题转化为单表问题,所以 MySQL 中所有的 select 问题,理论上都可以转化为单表问题来处理。这个思想贯穿了我们前面学过的所有多表查询和子查询用法。无论是普通的多表连接,还是 from 子句中的子查询,本质上都是通过关联字段或者临时表,把多张表的数据合并成一张逻辑上的 "大表",然后就可以用单表查询的方式来筛选、聚合数据了。
我们现在来看合并查询,它的核心是用 union 和 union all 这类集合操作符,把多个 select 语句的结果合并成一个结果集。union 操作符的作用是取两个结果集的并集,它会自动去除重复的记录。