声明:
- 🍨 本文为 🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者: K同学啊
前言:
本节不止学了LSTM网络的运用,还学习了数据可视化处理的常用方法
数据集介绍:本文采用的数据集为公开的医用费用预测数据集,在采集患者年龄与年度医疗费用的基础上,还采集了以下20种特征:
age
gender
bmi
smoker
diabetes
hypertension
heart_disease
asthma
physical_activity_level
daily_steps
sleep_hours
stress_level
doctor_visits_per_year
hospital_admissions
medication_count
insurance_type
insurance_coverage_pct
city_type
previous_year_cost
annual_medical_cost
有一个叫Seaborn的库,集成了很多可以直接用的常用的高级绘图

热力图:
sns.heatmap(numeric_cols.corr(), annot=True, cmap='coolwarm')计算numeric_cols数据之间的相关系数,然后采用冷暖颜色表示的格子内有数字的热力图
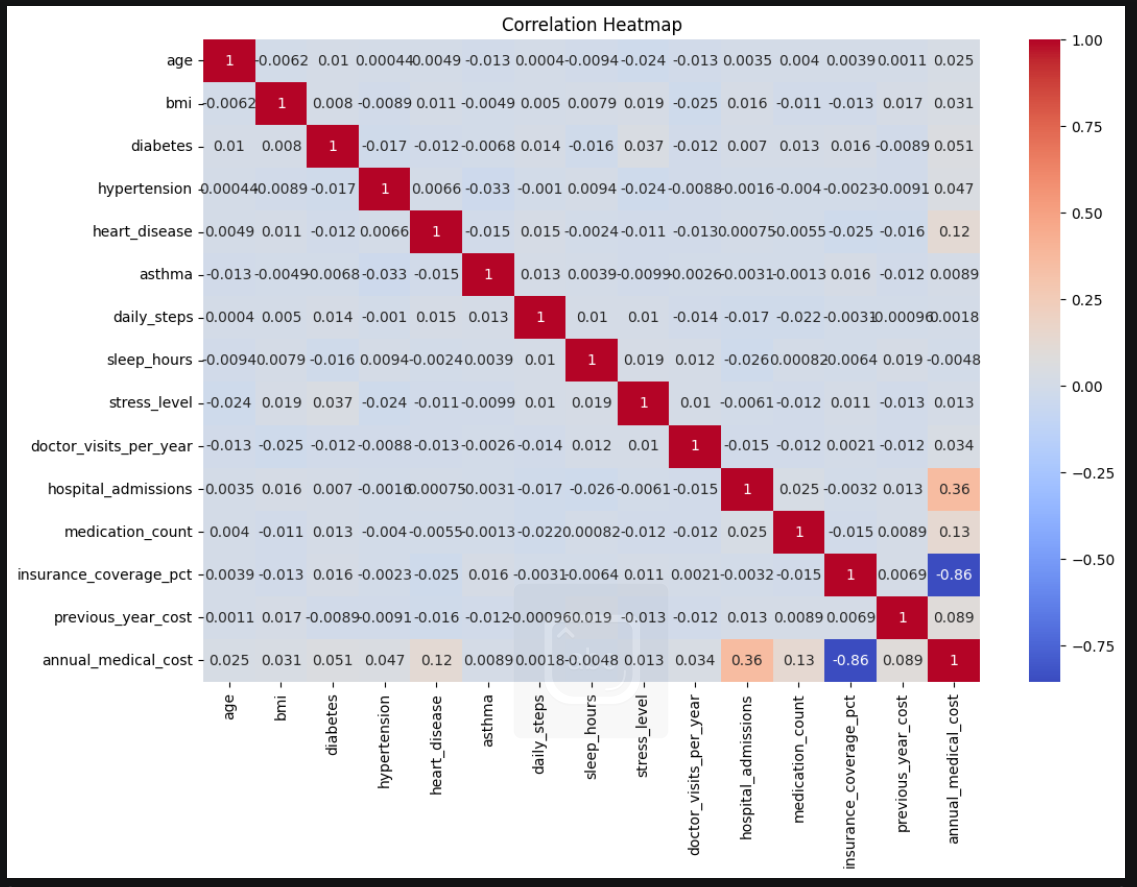
热力图能够很清楚的看出各个数据之间的相关性,例如:hospital_admissions 和annual_medical_cost有着很强的相关性(住院一般都容易花很多钱),而insurance_coverage_pct 和annual_medical_cost则表示出负相关(保险覆盖率高花钱少)
热力图可以通过颜色很清楚的看出最强相关的和最不相关的东西,送入神经网络训练也是一个很好的样本
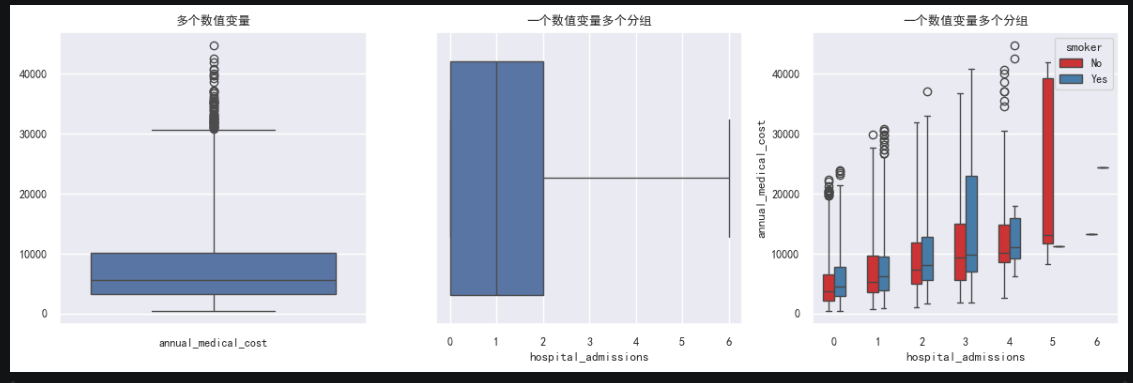
箱线图 boxplot:
sns.boxplot(data = df.loc[:, ['annual_medical_cost']], ax=ax[0], whis=3)
ax[0].set_title('多个数值变量')
sns.boxplot(x = df['hospital_admissions'], ax=ax[1], whis=3)
ax[1].set_title('一个数值变量多个分组')
sns.boxplot(x = 'hospital_admissions', y = 'annual_medical_cost', hue = 'smoker', data = df, palette='Set1', width=0.5, ax=ax[2], whis=3)
ax[2].set_title('一个数值变量多个分组')
含义:
x='hospital_admissions':按住院次数分组。
y='annual_medical_cost':看每组的年度医疗费用分布。
hue='smoker':再按是否吸烟分颜色。
data=df:数据来自 df。
palette='Set1':颜色方案。
width=0.5:箱子宽度。
ax=ax[2]:画在第 3 个子图上。
whis=3:离群值判断范围放宽到 3 倍 IQR。箱子中间那条线是代表中位值箱体上沿和下沿分别是75%和25%的数据点位。
上须:75%点位+1.5*(75%点位值-25%点位值),表示理论最大值,上须以外的叫离群点,实际值,下须同理
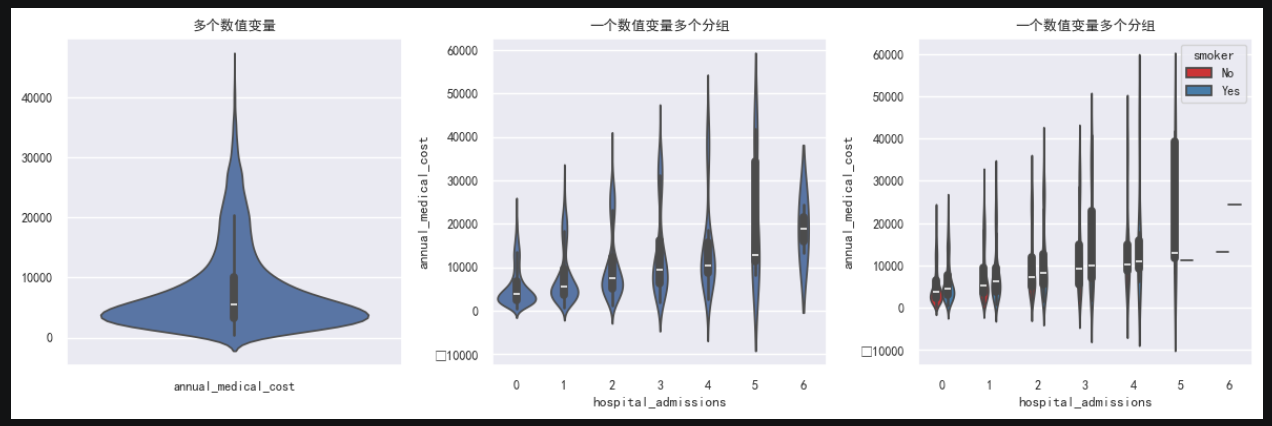
小提琴图 violinplot:
sns.violinplot(data = df.loc[:, ['annual_medical_cost']], ax=ax[0])
ax[0].set_title('多个数值变量')
sns.violinplot(x = df['hospital_admissions'], y = df['annual_medical_cost'], ax=ax[1])
ax[1].set_title('一个数值变量多个分组')
sns.violinplot(x = 'hospital_admissions', y = 'annual_medical_cost', hue = 'smoker', data = df, palette='Set1', width=0.5, ax=ax[2])
ax[2].set_title('一个数值变量多个分组')小提琴图和箱线图类似,但它多了一层信息:分布密度。
怎么看:
- 图越宽:这个数值附近的数据越多。
- 图越窄:这个数值附近的数据少。
- 形状如果很胖,说明数据集中在某些区间。
- 如果上下拉得很长,说明波动范围大。
箱线图更适合看中位数和离群点,小提琴图更适合看"数据集中在哪里"。
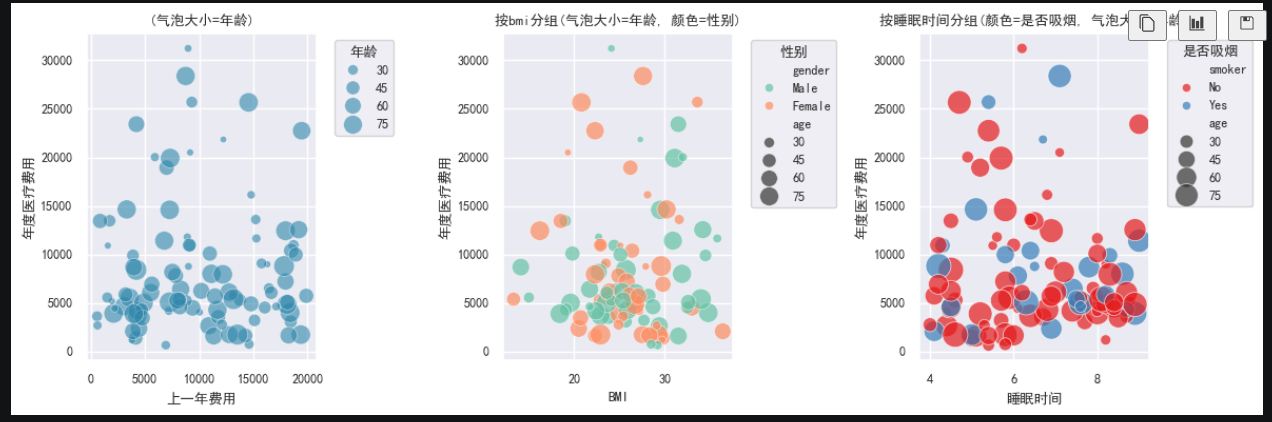
散点图 scatterplot:
sns.scatterplot(
data = df[:100],
x = 'previous_year_cost',
y = 'annual_medical_cost',
size = 'age',
sizes = (20, 200),
alpha = 0.6,
color = '#2E86AB',
ax = ax[0]
)
ax[0].set_title('(气泡大小=年龄)')
ax[0].set_xlabel('上一年费用')
ax[0].set_ylabel('年度医疗费用')
ax[0].legend(title='年龄', loc='upper left', bbox_to_anchor=(1.05, 1))
sns.scatterplot(
data = df[:100],
x = 'bmi',
y = 'annual_medical_cost',
size = 'age',
sizes = (20, 200),
alpha = 0.7,
hue = 'gender',
palette = 'Set2',
ax = ax[1]
)
ax[1].set_title('按bmi分组(气泡大小=年龄, 颜色=性别)')
ax[1].set_xlabel('BMI')
ax[1].set_ylabel('年度医疗费用')
ax[1].legend(title='性别', loc='upper left', bbox_to_anchor=(1.05, 1))
sns.scatterplot(
data = df[:100],
x = 'sleep_hours',
y = 'annual_medical_cost',
hue = 'smoker',
size = 'age',
sizes = (40, 300),
alpha = 0.7,
palette = 'Set1',
ax = ax[2]
)
ax[2].set_title('按睡眠时间分组(颜色=是否吸烟, 气泡大小=年龄)')
ax[2].set_xlabel('睡眠时间')
ax[2].set_ylabel('年度医疗费用')
ax[2].legend(title='是否吸烟', loc='upper left', bbox_to_anchor=(1.05, 1))散点图用来看两个连续变量之间的关系。
怎么看:
- 点整体从左下到右上:正相关。
- 点整体从左上到右下:负相关。
- 点乱成一团:关系不明显。
- 颜色
hue:看不同类别是否形成不同模式。 - 大小
size:看第三个变量是否有影响。
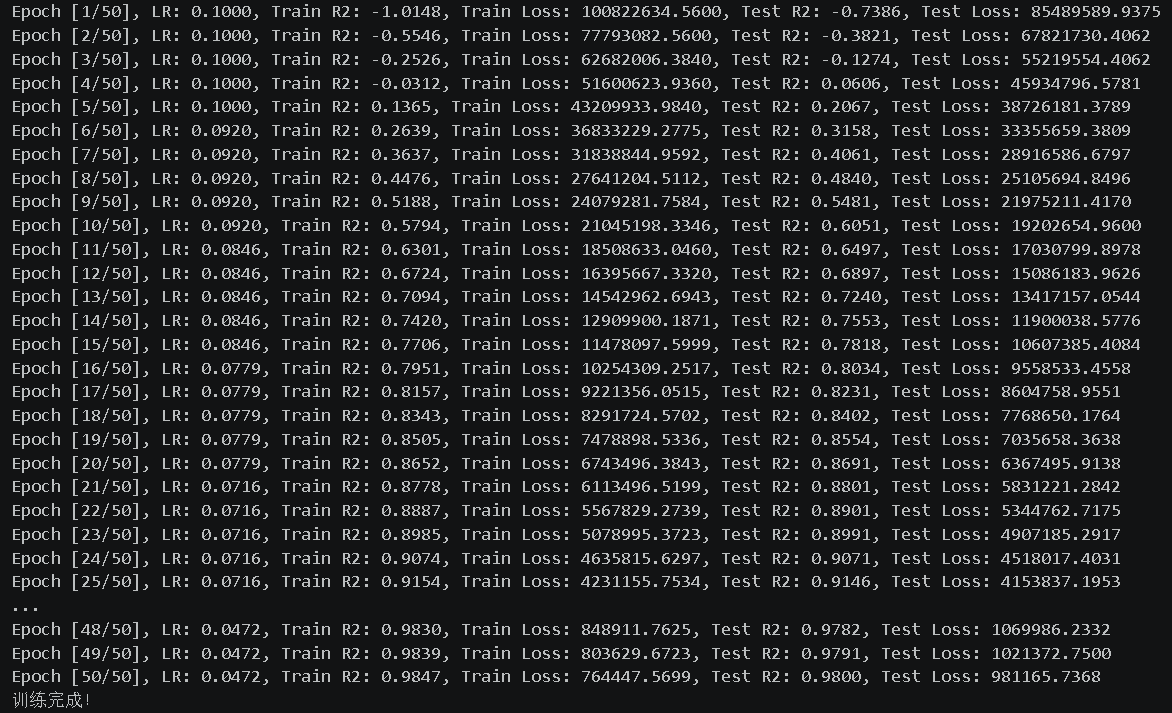
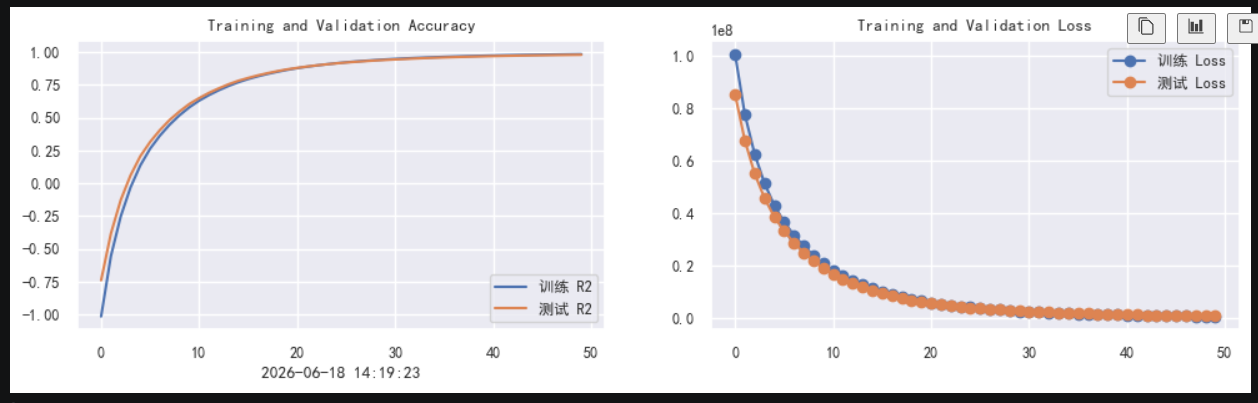
训练结果:
总结:
LSTM的预测用的是R2而不是acc
关键区别
R2:衡量连续数值预测的拟合程度,越接近 1 越好。accuracy:衡量离散类别预测是否正确,不能直接用于预测数值型医疗费用。
而且loss计算由于是直接计算的,没有归一化,所以特别大。
整体和RNN的训练还是很相似的,这节的重点在于熟悉一下这几个常用的绘图方式。