最近很多人都在聊 Agent。
Cursor 是 Agent。
Claude Code 是 Agent。
Codex 是 Agent。
很多企业里的 AI 自动化产品,本质也都是 Agent。
但新手一上来很容易懵:
LLM、Agent、Tools、reasoning、messages 到底是什么关系?
为什么大模型明明会回答问题,却不能自己查股价、读文件、操作浏览器?
为什么接了 Tools 之后,AI 就像"能干活"了一样?
这篇文章用一个可运行的 Node.js 小 Demo,把这些概念讲清楚。
你能学到:
- Agent 和 LLM 的区别
- Tools 为什么是 Agent 的行动能力
- messages 多轮对话怎么传
- reasoning_content 有什么用
- 如何用 OpenAI SDK + DeepSeek 做一次 tool calling 闭环
代码都可以直接复制。
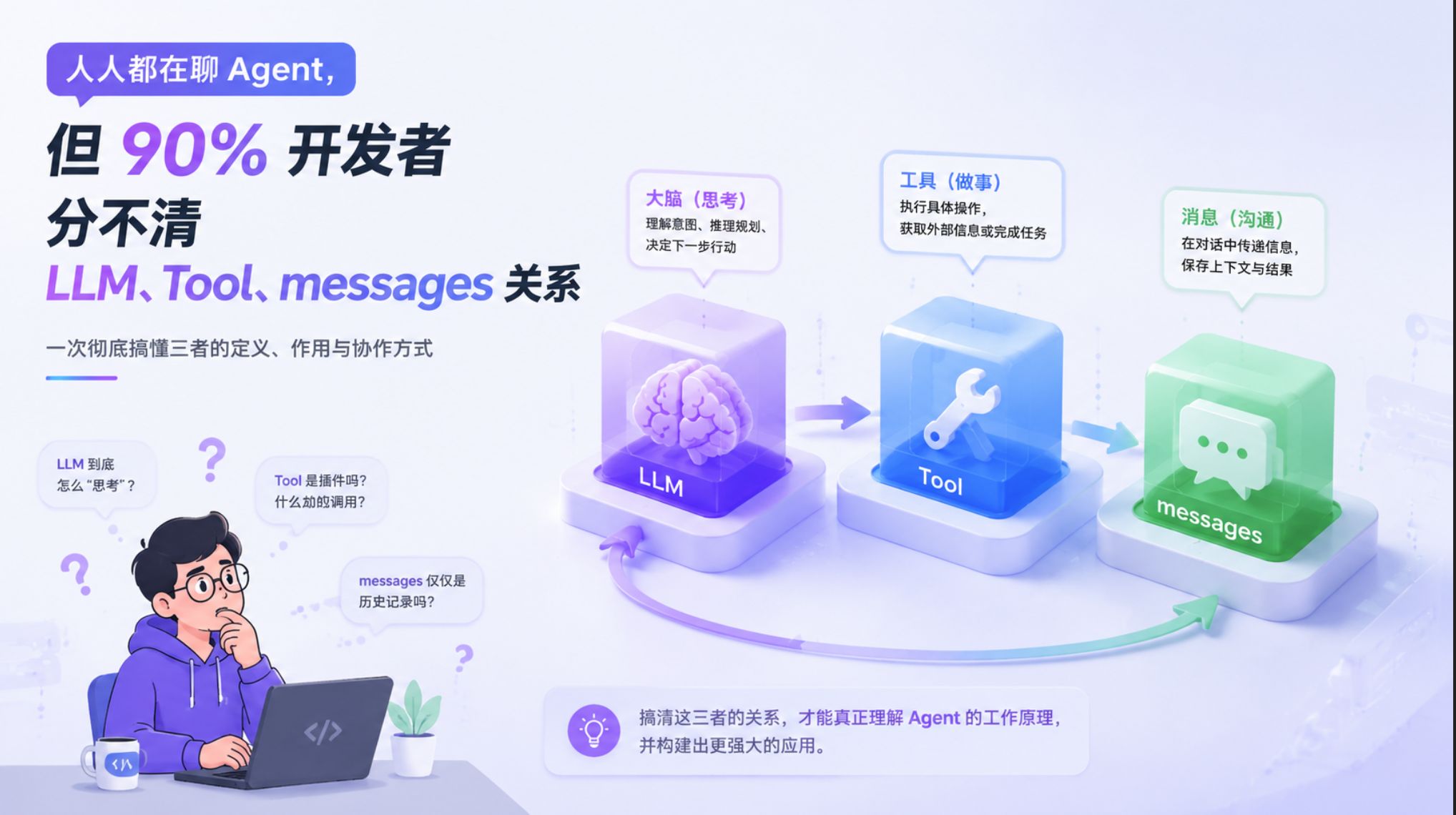
一、先说结论:Agent = 大脑 + 工具 + 上下文
一句话理解 Agent:
Agent 不是只会聊天的 AI,而是能理解任务、调用工具、拿到结果、继续完成任务的系统。
一个 Agent 有多强,主要看三件事:
- 用了什么大脑:LLM
- 装了什么工具:Tools
- 拿到了什么信息:Context
可以简单理解成:
txt
Agent = LLM + Tools + ContextLLM 负责思考和生成。
Tools 负责连接外部世界。
Context 负责告诉模型现在发生了什么、之前聊了什么、可用信息有哪些。
所以 Agent 不是一个神秘概念。
它更像一个工程组合。
二、LLM:Agent 的大脑,但它本身不会行动
LLM 是大模型。
比如 DeepSeek、GPT、Claude、豆包背后的模型。
它最擅长两件事:
推理。
生成。
比如你问:
txt
C 罗是哪个国家的足球运动员?模型可以回答:
txt
C 罗是葡萄牙的足球运动员。但如果你问:
txt
青岛啤酒今天的收盘价是多少?问题就变了。
模型如果没有联网、没有金融接口、没有数据库,它其实并不知道实时数据。
它最多只能猜。
这就是 LLM 的边界:
它能推理和生成,但不能天然操作外部世界。
想让它真的干活,就需要 Tools。
三、Tools:让 AI 从"会说"变成"会做"
Tools 可以理解成你给模型安装的能力。
比如:
- 查询股票价格
- 搜索网页
- 读取文件
- 写入代码
- 操作浏览器
- 调用数据库
- 发送消息
- 生成图片
没有 Tools,AI 只能回答。
有了 Tools,AI 可以决定:
这个问题我不能靠脑补,需要调用某个函数。
比如用户问:
txt
青岛啤酒的收盘价是多少?模型应该推理出:
txt
我需要调用 get_closing_price 工具,参数是:青岛啤酒。然后程序真正执行这个函数:
js
get_closing_price('青岛啤酒')拿到结果:
txt
67.92再把结果交回模型。
最后模型组织成自然语言:
txt
青岛啤酒的收盘价是 67.92。这就是一次典型的 tool calling。
四、项目准备:一个最小 Node.js Demo
先准备一个目录:
txt
reason-demo
├─ client.mjs
├─ completion.mjs
├─ main.mjs
├─ index.mjs
├─ package.json
└─ .env安装依赖:
bash
npm install openai dotenvpackage.json 里依赖大概是这样:
json
{
"dependencies": {
"dotenv": "^17.4.2",
"openai": "^6.43.0"
}
}再准备 .env。
注意不要把真实 key 提交到 Git 仓库。
bash
DEEPSEEK_API_KEY=你的_API_KEY
DEEPSEEK_API_BASE_URL=https://api.deepseek.com
DEEPSEEK_MODEL=deepseek-v4-flash五、封装 client:所有请求都从这里走
先创建 client.mjs。
js
import { OpenAI } from 'openai'
import dotenv from 'dotenv'
dotenv.config()
const client = new OpenAI({
apiKey: process.env.DEEPSEEK_API_KEY,
baseURL: process.env.DEEPSEEK_API_BASE_URL
})
export default client这里有两个关键点。
第一,使用 dotenv.config() 读取 .env。
第二,通过 baseURL 把 OpenAI SDK 接到 DeepSeek API。
也就是说:
我们用的是 OpenAI SDK 的调用方式,但请求发到 DeepSeek 的接口地址。
六、messages:多轮对话不是字符串拼接
大模型的对话不是简单传一个字符串。
它传的是一个 messages 数组。
每一条消息都有角色。
常见角色有:
system:系统设定user:用户输入assistant:模型回复tool:工具执行结果
比如这个例子:
js
import client from './client.mjs'
const main = async () => {
const result = await client.chat.completions.create({
model: 'deepseek-v4-pro',
reasoning_effort: 'high',
messages: [
{
role: 'system',
content: '你是一个足球领域的专家,请尽量帮我回答与足球相关的问题'
},
{
role: 'user',
content: 'C 罗是哪个国家的足球运动员?'
},
{
role: 'assistant',
content: 'C 罗是葡萄牙的足球运动员'
},
{
role: 'user',
content: '内马尔呢?'
}
]
})
console.log('思考过程:')
console.log(result.choices[0].message.reasoning_content)
console.log('\n最终答案:')
console.log(result.choices[0].message.content)
}
main()这里的关键是最后一句:
txt
内马尔呢?如果只看这一句,它是不完整的。
但因为前面 messages 里已经有了 C 罗的问题,所以模型能理解:
用户是在继续问:内马尔是哪个国家的足球运动员?
这就是多轮对话的核心。
不是自己拼接一大段文本。
而是维护好 messages。

七、reasoning_content:观察模型怎么想
有些模型会返回推理过程字段。
比如:
js
result.choices[0].message.reasoning_content它的价值不是给用户看。
而是给开发者调试。
你可以用它观察:
- 模型有没有理解问题
- 模型为什么要调用某个工具
- 模型是否被 system prompt 带偏
- 模型对上下文的判断是否正确
比如:
js
console.log('思考过程:')
console.log(result.choices[0].message.reasoning_content)
console.log('\n最终答案:')
console.log(result.choices[0].message.content)这在开发 Agent 时非常有用。
因为 Agent 出错时,常见问题不是代码直接报错。
而是模型判断错了。
它可能该调工具却没调。
也可能选错工具。
还可能参数抽取错。
reasoning 能帮你更快定位问题。
八、先封装一个普通 completion 方法
如果只是普通问答,可以封装成这样。
创建 completion.mjs。
js
import client from './client.mjs'
export async function getCompletion(prompt) {
const response = await client.chat.completions.create({
model: process.env.DEEPSEEK_MODEL,
messages: [
{
role: 'user',
content: prompt
}
]
})
return response.choices[0].message.content
}使用:
js
import { getCompletion } from './completion.mjs'
const answer = await getCompletion('请用一句话解释什么是 Agent')
console.log(answer)这个方法适合普通文本生成。
但它还不是 Agent。
因为它没有工具。
下一步我们开始加 Tools。
九、实战:让 AI 查询股票收盘价
我们做一个最小实战:
用户问:
txt
青岛啤酒的收盘价是多少?模型不要直接瞎答。
它应该调用工具:
js
get_closing_price程序执行工具后,再让模型回答用户。
整体流程是:
txt
用户提问
↓
LLM 判断是否需要工具
↓
返回 tool_calls
↓
Node.js 执行真实函数
↓
把工具结果加入 messages
↓
再次请求 LLM
↓
生成最终回答十、定义 Tools:告诉模型你有什么能力
创建 index.mjs。
先定义 tools。
js
import client from './client.mjs'
const tools = [
{
type: 'function',
function: {
name: 'get_closing_price',
description: '获取指定股票的收盘价',
parameters: {
type: 'object',
properties: {
name: {
type: 'string',
description: '股票名称,例如:青岛啤酒、贵州茅台'
}
},
required: ['name']
}
}
}
]注意这里不是直接把函数传给模型。
而是告诉模型:
我有一个工具,名字叫 get_closing_price,它需要一个 name 参数。
其中最重要的是:
js
description: '获取指定股票的收盘价'这个描述越清晰,模型越容易准确调用工具。
参数描述也很重要:
js
description: '股票名称,例如:青岛啤酒、贵州茅台'因为模型需要从自然语言里提取参数。
十一、实现真正的工具函数
上面的 tools 只是"说明书"。
真正执行的函数还要我们自己写。
js
function get_closing_price(name) {
if (name === '青岛啤酒') return '67.92'
if (name === '贵州茅台') return '1488.21'
return '未找到股票'
}实际项目里,这里可以换成:
- 调用股票 API
- 查询数据库
- 请求后端服务
- 读取本地文件
但 Demo 阶段用一个普通函数就够了。
重点是理解 tool calling 的闭环。
十二、完整可运行代码:实现一次 Agent 闭环
下面是完整的 index.mjs。
可以直接复制运行。
js
import client from './client.mjs'
const tools = [
{
type: 'function',
function: {
name: 'get_closing_price',
description: '获取指定股票的收盘价',
parameters: {
type: 'object',
properties: {
name: {
type: 'string',
description: '股票名称,例如:青岛啤酒、贵州茅台'
}
},
required: ['name']
}
}
}
]
function get_closing_price(name) {
if (name === '青岛啤酒') return '67.92'
if (name === '贵州茅台') return '1488.21'
return '未找到股票'
}
const toolMap = {
get_closing_price
}
async function sendMessage(messages) {
return await client.chat.completions.create({
model: process.env.DEEPSEEK_MODEL || 'deepseek-v4-flash',
messages,
tools,
tool_choice: 'auto'
})
}
async function main() {
const messages = [
{
role: 'user',
content: '青岛啤酒的收盘价是多少?'
}
]
const firstResponse = await sendMessage(messages)
const firstMessage = firstResponse.choices[0].message
messages.push(firstMessage)
const toolCalls = firstMessage.tool_calls || []
for (const toolCall of toolCalls) {
const toolName = toolCall.function.name
const toolArgs = JSON.parse(toolCall.function.arguments)
const toolFn = toolMap[toolName]
if (!toolFn) {
throw new Error(`未知工具:${toolName}`)
}
const toolResult = toolFn(toolArgs.name)
messages.push({
role: 'tool',
tool_call_id: toolCall.id,
content: String(toolResult)
})
}
const finalResponse = await sendMessage(messages)
const finalMessage = finalResponse.choices[0].message
console.log(finalMessage.content)
}
main()运行:
bash
node index.mjs你会得到类似结果:
txt
青岛啤酒的收盘价是 67.92。这才是完整闭环。
不是只拿到模型返回的 tool call。
而是:
模型决定调用工具,程序执行工具,模型再基于工具结果回答。
十三、拆开看:模型第一次返回了什么?
第一次请求时,messages 只有用户问题:
js
const messages = [
{
role: 'user',
content: '青岛啤酒的收盘价是多少?'
}
]同时告诉模型可用工具:
js
tools,
tool_choice: 'auto'tool_choice: 'auto' 的意思是:
让模型自己判断要不要调用工具。
如果模型认为需要工具,它会返回 tool_calls。
大概长这样:
js
{
role: 'assistant',
content: null,
tool_calls: [
{
id: 'call_xxx',
type: 'function',
function: {
name: 'get_closing_price',
arguments: '{"name":"青岛啤酒"}'
}
}
]
}这里要注意:
arguments 是字符串。
所以要手动解析:
js
const toolArgs = JSON.parse(toolCall.function.arguments)十四、工具执行结果为什么还要发回模型?
很多新手会卡在这里。
模型返回 tool call 后,为什么不直接把工具结果返回给用户?
比如工具结果是:
txt
67.92直接给用户看也不是不行。
但这不够自然。
更好的做法是把工具结果作为 tool 消息放回 messages:
js
messages.push({
role: 'tool',
tool_call_id: toolCall.id,
content: String(toolResult)
})然后再请求一次模型。
模型会根据上下文生成最终回答:
txt
青岛啤酒的收盘价是 67.92。这一步很关键。
因为真实 Agent 里,工具结果可能很复杂。
比如:
- 一段 JSON
- 一组搜索结果
- 一份文件内容
- 一批数据库记录
让模型再整理一次,用户体验会更好。
十五、踩坑提醒:写 Agent 最容易错的 6 个点
1. Tools 只是描述,不是函数本身
很多人以为把 tools 传给模型,模型就能直接执行函数。
不是。
模型只会返回:
txt
我想调用哪个工具,参数是什么。真正执行函数的是你的程序。
2. description 写得太随意
工具描述会影响模型是否准确调用。
不推荐这样写:
js
description: '查一下'推荐写清楚:
js
description: '获取指定股票的收盘价'参数也要写清楚:
js
description: '股票名称,例如:青岛啤酒、贵州茅台'3. 忘记把 assistant 的 tool_call 消息放回 messages
完整流程里,这一步不能省:
js
messages.push(firstMessage)因为后面的 tool 结果是对应这次 tool call 的。
如果少了它,模型可能无法正确理解工具结果来自哪里。
4. 忘记传 tool_call_id
工具结果消息里要带:
js
tool_call_id: toolCall.id它用于把工具结果和某次工具调用对应起来。
尤其当模型一次请求多个工具时,这个字段很重要。
5. arguments 忘记 JSON.parse
tool call 的参数通常是字符串:
js
toolCall.function.arguments要先解析:
js
const toolArgs = JSON.parse(toolCall.function.arguments)不要直接当对象用。
6. 把 reasoning_content 直接展示给用户
reasoning 更适合开发调试。
正式产品里不要把它直接展示给用户。
用户真正需要的是结果。
开发者才需要看模型怎么推理。
十六、Agent 和普通聊天机器人的区别
普通聊天机器人更像:
txt
用户问 → 模型答Agent 更像:
txt
用户问
↓
模型判断任务
↓
选择工具
↓
执行工具
↓
观察结果
↓
继续推理
↓
返回答案或继续行动所以 Agent 的能力边界更大。
它可以做:
- 自动写代码
- 自动读项目文件
- 自动查接口文档
- 自动生成报告
- 自动操作网页
- 自动调用公司内部系统
这也是为什么现在很多 AI 产品,本质上都在往 Agent 方向发展。
真正有价值的不是"聊得像人"。
而是能把任务完成 。

十七、总结
入门 AI Agent,先抓住 4 个核心概念:
LLM 是大脑。
它负责推理和生成。
Tools 是手脚。
它负责连接外部世界,补齐模型不能直接行动的问题。
messages 是上下文。
它让模型知道之前发生了什么,当前任务进行到哪一步。
reasoning 是调试窗口。
它帮助开发者理解模型为什么这么判断。
用工程视角看,Agent 并不神秘。
它就是把模型、工具、上下文和控制流程组织起来。
这篇文章里的股票收盘价 Demo 虽然很小,但已经包含了 Agent 最关键的工作流:
模型决定调用工具 → 程序执行工具 → 工具结果回填 → 模型生成最终答案。
理解这个闭环,再去看 Cursor、Claude Code、Codex 这类产品,就会清楚很多。
我也把这次的 client.mjs、completion.mjs、main.mjs、index.mjs 拆成了完整源码,想继续对照理解的话,可以直接打开源码一步步跑(Knowledge_Repository/ai/agent/consepts at main · Guwen-yue/Knowledge_Repository)。