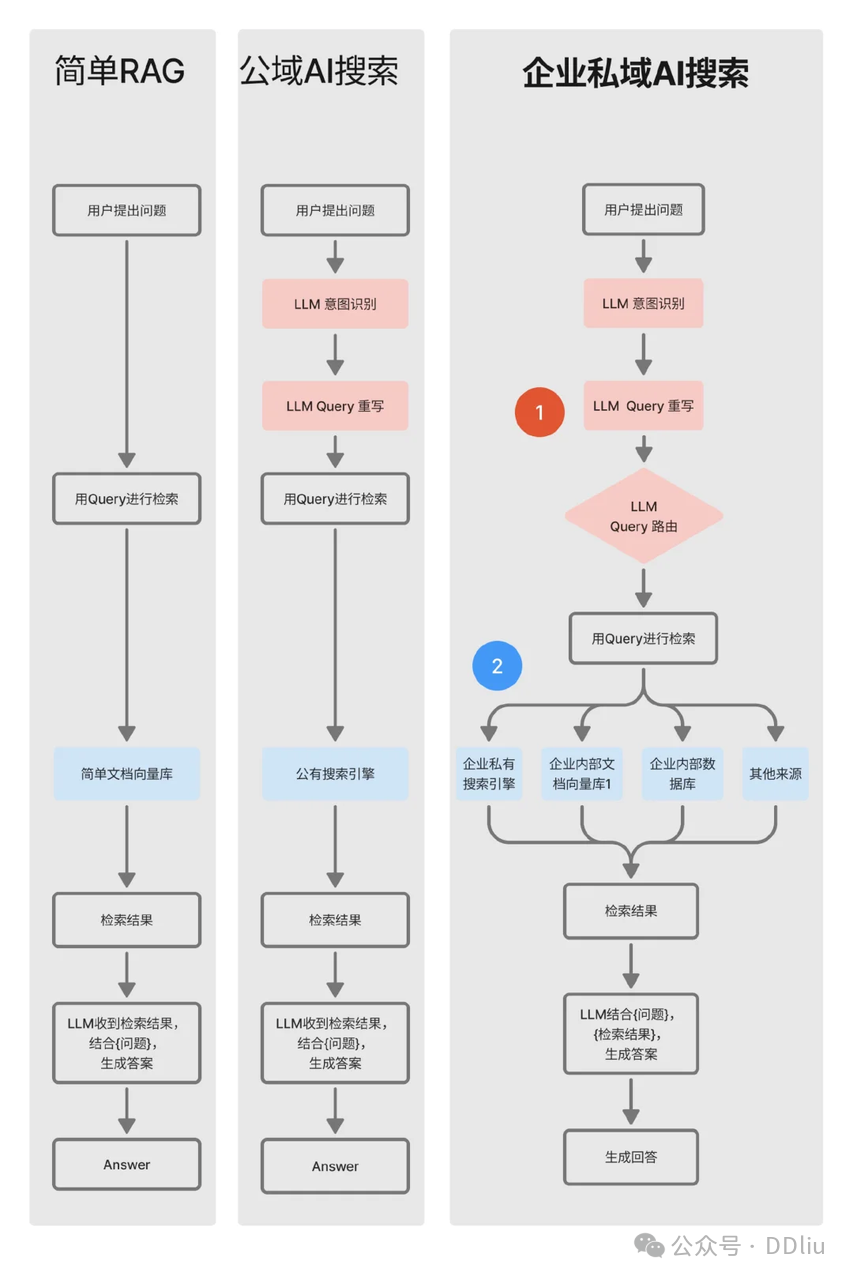
query改写底层原理
我们常用的检索方法有两种:关键词检索和向量检索。【现在也有混合检索方式,将前两种检索混合】
所以基于大模型的query改写也有两个与之对应的思路:
- 一是让 Query 能更大程度地切中关键词,以适应关键词检索。
- 二是让 Query 能更大程度地贴近被检索知识库中的文本块向量,以适应向量检索。
查询改写实战:让RAG系统真正理解用户到底想问什么-CSDN博客
三种主流改写策略
1. 多查询扩展(Multi-Query)
这是最简单的策略。把用户的一个问题,扩展成多个相关的问题。
比如用户问:"LoRA微调效果怎么样?"
改写后:
"LoRA微调在各类任务上的效果评估"
"LoRA相比全量微调的优缺点"
"LoRA微调的实际应用案例和效果数据"
这三个查询覆盖了用户问题的不同侧面。分别去检索,然后合并结果。
2. 假设式文档嵌入(HyDE)
这个思路很有意思------先让LLM根据用户问题生成一个"假想的答案",然后用这个假答案去检索。
核心思想是:一个假想的答案比问问题本身更容易匹配到相关文档。
比如用户问:"怎么解决大模型幻觉问题?"
你先生成一个假设答案:
"解决大模型幻觉问题的方法包括:检索增强生成(RAG)、知识图谱约束、事实性验证、温度参数调优、少量样本示例引导..."
然后用这段文字去向量库检索,大概率能找到最相关的论文或技术文档。
这招在技术问答场景下 效果奇好,因为假想答案的语义空间和真实文档的语义空间更接近。但缺点也很明显------如果LLM生成的假想答案方向错了,检索结果会偏得更离谱。
3. 对话历史感知改写
如果用户是多轮对话,查询改写就是必须做的事。
考虑这个场景:
用户:"介绍一下AdaFactor优化器"
助手:介绍了AdaFactor
用户:"它跟Adam比哪个好?"
"它"指代谁?很明显是AdaFactor。但如果你不做改写,直接拿"跟Adam比哪个好"去检索,结果可想而知。
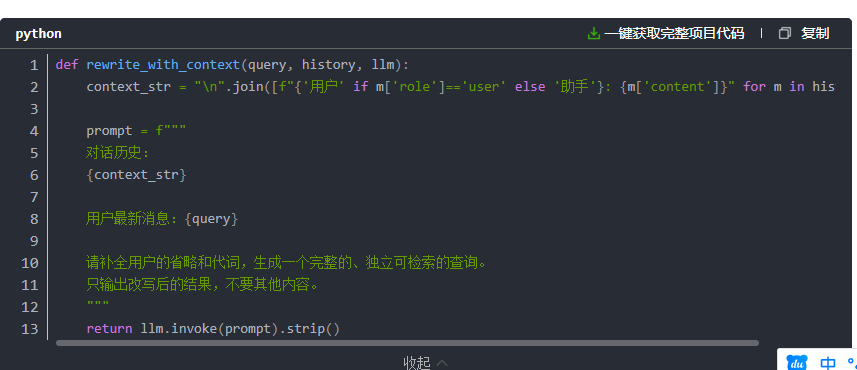
这是我个人觉得ROI最高的改写策略。因为多轮对话中省略和代词使用太频繁了,不做改写基本等于盲打。
工程实践:完整的查询改写pipeline
上面三种策略可以组合使用。我现在的项目里用的是这么一套流程:

每个查询独立检索top 10,合并后去重,再用Rerank模型精排top 5。
这么一套下来,检索质量提升明显,但延迟也上去了------从一次检索变成了3-4次。不过对于大多数场景来说,多出来一两秒的检索时间是值得的。
踩坑经验
做了几个月查询改写,有几个血泪教训。
Token消耗比你想象的大。
优化方案:写个轻量级改写模型,或者用分类器只对"需要改写"的查询做处理。约70%的短查询不需要改写也能搜到结果。
改写过度也是问题
有时候LLM太"聪明"了,把用户的简单问题改写得面目全非。
用户问:"Python怎么读文件?"
改写后:"在Python编程语言中,通过内置的open()函数以指定模式打开磁盘文件并读取其内容的最佳实践..."
过于啰嗦的改写结果会让向量检索丢失原始意图。建议控制改写后文本的长度,保持和原问题相近的长 度。