目录
[charset 查看字符集:](#charset 查看字符集:)
[concat 连接字符串:](#concat 连接字符串:)
[instr 返回子串出现的位置:](#instr 返回子串出现的位置:)
[ucase 转成大写字符串:](#ucase 转成大写字符串:)
[lcase 转成小写字符串:](#lcase 转成小写字符串:)
[left/right 提取字符:](#left/right 提取字符:)
[length 获取字符串长度:](#length 获取字符串长度:)
[trim 清理空格:](#trim 清理空格:)
[replace 字符串替换:](#replace 字符串替换:)
[substring 字符串截取:](#substring 字符串截取:)
[abs 取绝对值:](#abs 取绝对值:)
[bin 十进制转二进制:](#bin 十进制转二进制:)
[hex 转为十六进制:](#hex 转为十六进制:)
[conv 进制转换:](#conv 进制转换:)
[format 格式化保留精度:](#format 格式化保留精度:)
[rand 生成并返回随机浮点数:](#rand 生成并返回随机浮点数:)
[mod 取模求余:](#mod 取模求余:)
[ceiling 向上取整:](#ceiling 向上取整:)
[floor 向下取整:](#floor 向下取整:)
[user 查询用户:](#user 查询用户:)
[md5 摘要:](#md5 摘要:)
[password 用户加密函数:](#password 用户加密函数:)
[ifnull 函数:](#ifnull 函数:)
MySQL内置了很多函数,本篇文章我们就一一来学习这些函数。
一、日期函数
mysql 内置了丰富的日期函数,专门用来处理和时间相关的数据,其中 current_date() 可以获取系统当前的日期,格式为 yyyy-mm-dd,current_time() 则用来获取当前的时间,格式为 hh:mm:ss,而 current_timestamp() 和 now() 功能相近,都能获取当前完整的日期和时间戳信息,包含年月日时分秒,是日常业务中记录数据创建、更新时间的常用函数。date(datetime) 函数可以从完整的日期时间参数中,提取出纯日期部分,方便单独处理日期维度的数据。date_add() 和 date_sub() 是一对互补的日期增减函数,通过 interval 关键字配合不同单位,比如 year、day、minute、second就能在指定日期上加上或减去指定时长。datediff(date1, date2) 函数则可以计算两个日期之间相差的天数,结果为 date1 减去 date2 的天数差,是计算入职天数、订单间隔天数等业务场景的常用工具,这些日期函数配合 where 筛选、分组聚合,就能轻松完成各类时间维度的数据统计需求。
下面我们就通过举例来应用这些函数:
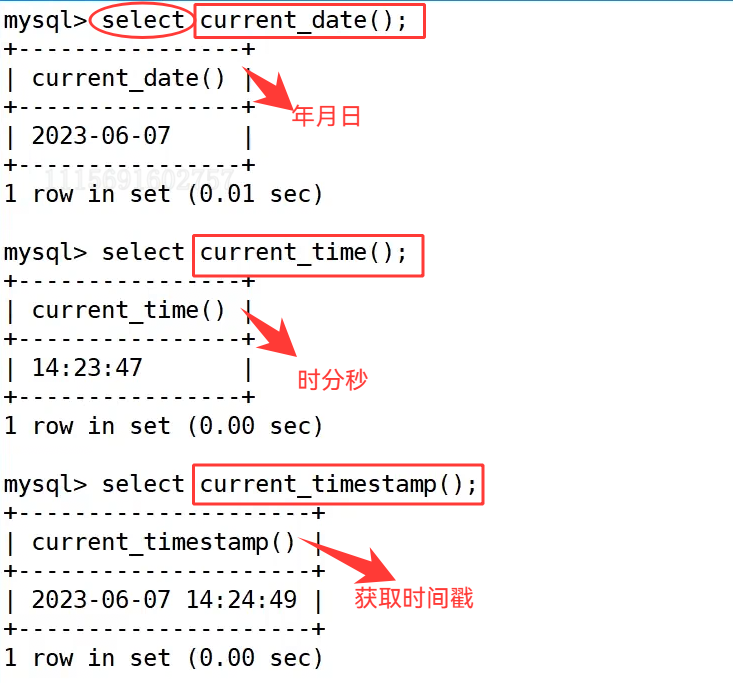
首先通过 select current_date(); 可以直接得到当前的日期,格式为 yyyy-mm-dd,示例中返回了2023-06-07; select current_time(); 则返回当前的时间,格式为 hh:mm:ss,示例结果为14:23:47;select current_timestamp(); 和 select now(); 都可以获取完整的时间戳,格式为 yyyy-mm-dd hh:mm:ss,二者在功能上几乎一致,示例中分别返回了 2023-06-07 14:24:49 和 2023-06-07 14:25:43,是记录数据创建或更新时间时的常用写法。
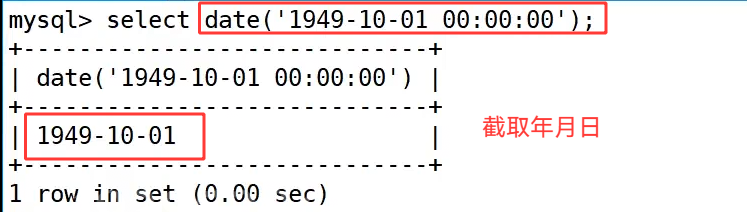
date() 函数可以从一个完整的日期时间参数中提取出纯日期部分,例如 select date('1949-10-01 00:00:00'); 会忽略时分秒,仅返回 1949-10-01;而 select date(now()); 则是 date() 与 now() 的搭配使用,先通过 now() 获取当前完整时间戳,再由 date() 提取出纯日期,示例中返回 2023-06-07,这种写法在业务中常用于获取当天日期,为后续按日期维度统计数据提供基础。


日期也可以加减:
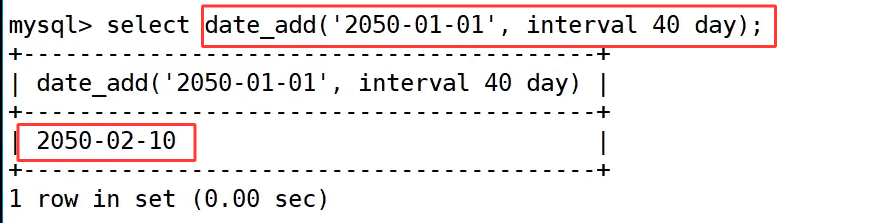
date_add() 函数用于对指定日期加上一段时间,通过 interval 关键字进行增减。如上图,select date_add('2050-01-01', interval 40 day); 以 2050-01-01 为基准,加上 40 天,得到结果 2050-02-10,自动处理了月份进位。
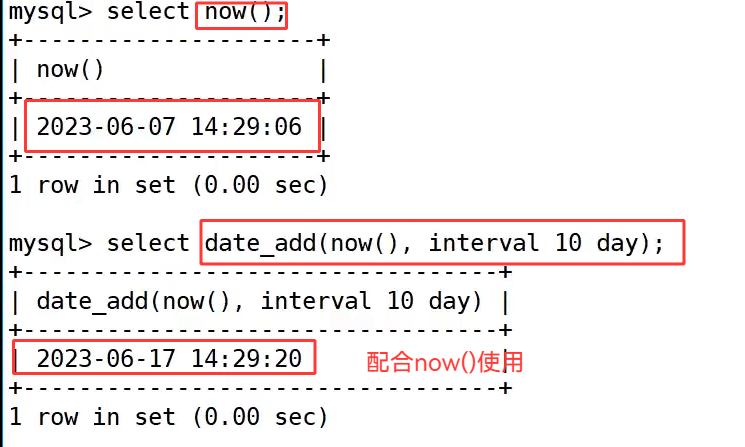
date_add() 函数也可以和 now() 配合使用,select date_add(now(), interval 10 day); 在当前时间 2023-06-07 14:29:06 的基础上增加 10 天,返回 2023-06-17 14:29:20,这种写法常用于计算未来的截止日期、提醒时间等。
日期也可以减时间:
date_sub() 函数是 date_add() 的反向操作,用于从指定日期减去一段时间。上图中首先我们 select date_sub('2050-01-01', interval 10 day); 从 2050-01-01 减去 10 天,自动处理了跨年份的计算,得到 2049-12-22。和 now() 搭配使用时,select date_sub(now(), interval 10 day); 可以计算出当前时间 10 天前的日期时间,示例中返回 2023-05-28 14:30:41,适合用于统计近一周、近一个月的数据。
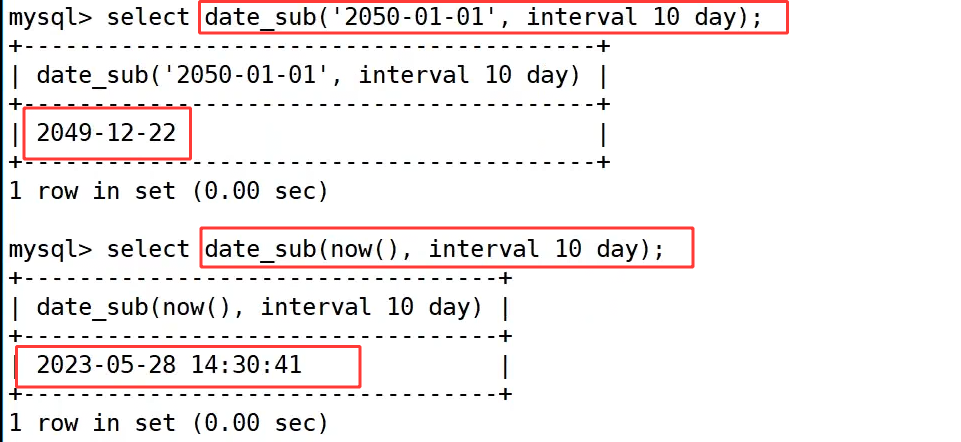
还可以计算两个日期相差多少天:
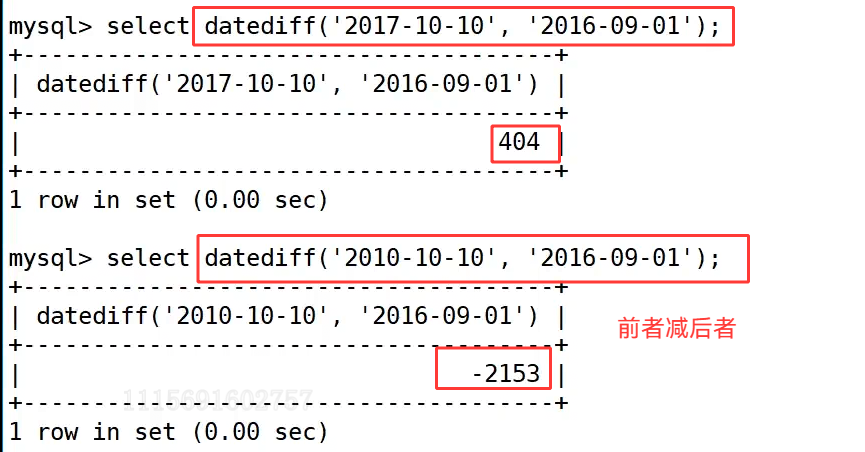
datediff() 函数用于计算两个日期之间相差的天数,计算规则为第一个日期减去第二个日期。首选我们执行 select datediff('2017-10-10', '2016-09-01'); 得到结果 404,表示前者比后者晚 404 天;执行 select datediff('2010-10-10', '2016-09-01'); 结果为 -2153,说明前者比后者早 2153 天。
datediff() 函数也可以和 date(now()) 搭配,select datediff(date(now()), '1949-10-01'); 计算出当前日期与建国日相差的天数,结果为 26912,这类写法常用于计算工龄、用户注册时长、订单天数差等业务场景。

此时我们把函数讲完了,下面我们举个样例应用一下:
案例1 : 创建一张记录生日的表:
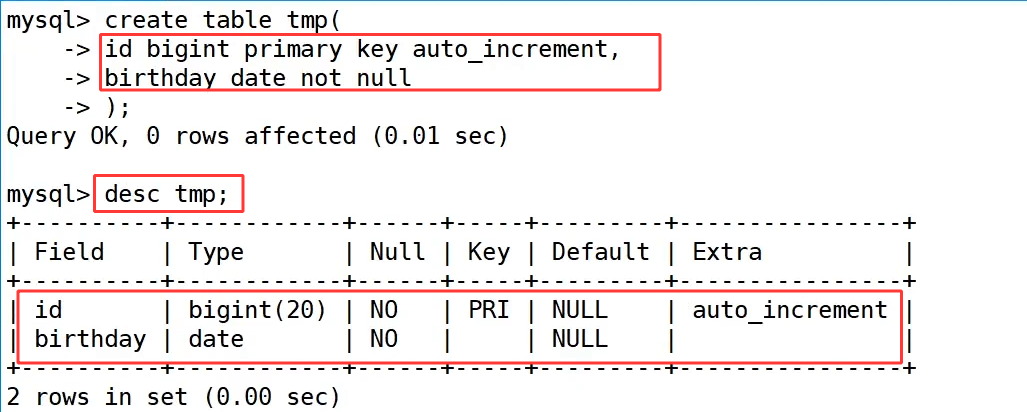
首先通过 create table tmp(id bigint primary key auto_increment, birthday date not null); 语句创建了一张名为 tmp 的测试表,用来记录生日信息。其中 id 字段设置为 bigint 类型的主键,并开启了自增属性,用于生成唯一的记录标识;birthday 字段被定义为 date 类型,且设置为非空约束,确保每条记录都必须填写日期信息。随后执行 desc tmp; 查看表结构,可以清晰看到两个字段的定义细节,包括字段类型、是否允许为空、键类型、默认值和额外属性,验证了表结构创建成功。
下面插入数据:
接着是数据插入环节,这里演示了多种向 date 类型字段插入数据的方式。前两条语句 insert into tmp (birthday) values ('1990-01-01'); 和 insert into tmp (birthday) values ('1980-01-01'); 直接插入字符串格式的日期数据。第三条语句 insert into tmp (birthday) values (current_date()); 使用 current_date() 函数插入当前系统日期,适合用来记录 "刚出生" 这类当前日期的场景,能够自动获取系统日期并以 date 格式存入。
随后两条语句展示了向 date 类型字段插入时间和时间戳数据的情况,insert into tmp (birthday) values (current_time()); 和 insert into tmp (birthday) values (current_timestamp()); 虽然分别传入了时间和完整时间戳,但 MySQL 会自动截取其中的日期部分进行存储。
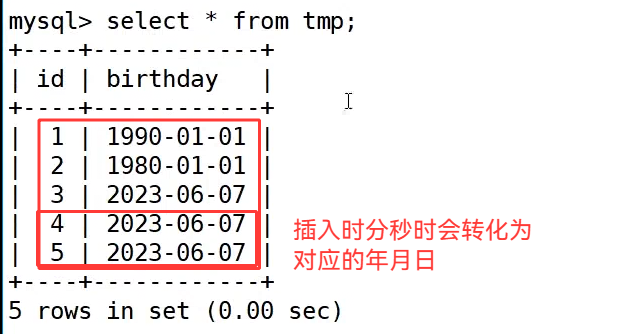
最后执行 select * from tmp; 查询所有数据,可以看到所有记录的 birthday 字段都统一显示为 yyyy-mm-dd 格式,包括插入时分秒数据的记录,最终也被转化为对应的日期存储。





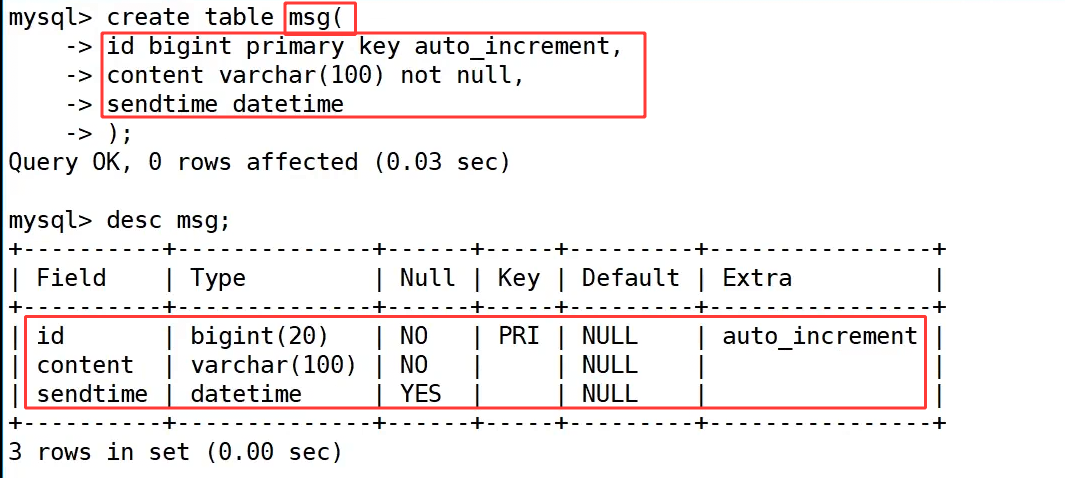
案例2 : 创建一个留言表,记录留言文字及留言时间:
先通过 create table msg(id bigint primary key auto_increment, content varchar(100) not null, sendtime datetime); 创建一张名为 msg 的留言表,用于存储留言内容和留言时间。其中 id 字段作为自增主键,确保每条留言都有唯一标识;content 字段定义为 varchar(100) 类型且非空,用来保存留言文字;sendtime 字段定义为 datetime 类型,支持存储完整的日期和时间信息,方便后续按时间维度筛选数据。执行 desc msg; 查看表结构,可以清晰看到三个字段的定义细节,验证表结构创建成功。
下面插入数据:
接下来是插入数据,这里使用 insert into msg (content, sendtime) values ('纸上得来终觉浅,绝知此事要躬行', now()); 和 insert into msg (content, sendtime) values ('恐惊天上人', now()); 两条语句插入留言数据,核心是通过 now() 函数获取当前系统的完整时间戳,直接存入 sendtime 字段。执行 select * from msg; 查询后,可以看到两条记录的 sendtime 字段都存储了完整的 yyyy-mm-dd hh:mm:ss 格式时间,与留言内容一一对应。
此时我们有一个需求 : 请查找两分钟以内发布的贴子:
方法一:
第一种方法使用 date_sub() 函数,先通过 date_sub(now(), interval 2 minute) 计算出当前时间往前推两分钟的时间点,再通过 sendtime >= 这个时间点筛选出所有在该时间之后发布的留言,执行 select content, sendtime from msg where sendtime >= date_sub(now(), interval 2 minute); 就能匹配出两分钟内发布的最新留言。
方法二:
方法二则通过 date_add() 函数实现,语句为 select content, sendtime from msg where date_add(sendtime, interval 2 minute) > now();。这条语句的逻辑是对每条留言的 sendtime 加上两分钟,再判断加上后的时间是否晚于当前时间,如果成立,就说明这条留言是在两分钟以内发布的。两种方法的逻辑本质是等价的,都是通过对时间的加减运算,筛选出符合时间范围的记录,只是运算的起点和方向不同。



二、字符串函数
接下来我们来看 MySQL 中的字符串函数,它们专门用于处理文本数据,覆盖了字符集查询、拼接、大小写转换、截取、替换、比较和去空格等常见场景。比如 charset(str) 可以获取字符串的字符集,concat() 用于拼接多个字符串,instr() 能查询子串的位置,ucase() 和 lcase() 分别实现大小写转换,left() 和 substring() 用来截取指定长度的字符,length() 可以获取字符串长度,replace() 用于内容替换,strcmp() 用于比较字符串大小,而 ltrim()、rtrim() 和 trim() 则可以去除字符串前后的空格,这些函数配合使用,能满足大多数文本处理需求。
举例:
charset 查看字符集:
charset() 函数的作用是返回指定字符串的字符集,常用于检查当前环境下字符串的编码格式。
示例:
示例中执行 select charset('abcd');,查询字符串 'abcd' 的字符集,返回结果为 utf8,说明当前 MySQL 环境下字符串默认使用 UTF-8 编码。

concat 连接字符串:
concat() 函数用于将多个字符串或其他类型的数据拼接成一个完整的字符串。
示例:
第一个示例 select concat('a', 'b', 'c'); 将 'a'、'b'、'c' 三个字符拼接,返回结果 'abc';第二个示例 select concat('a', 'b', 'c') as res; 给拼接后的结果设置了别名 res,方便后续引用;第三个示例 select concat('a', 'b', 'c', 123, 3.14) as res; 则展示了数字类型数据的拼接效果,MySQL 会自动将数字 123 和 3.14 转换为字符串,最终拼接成 'abc1233.14'。


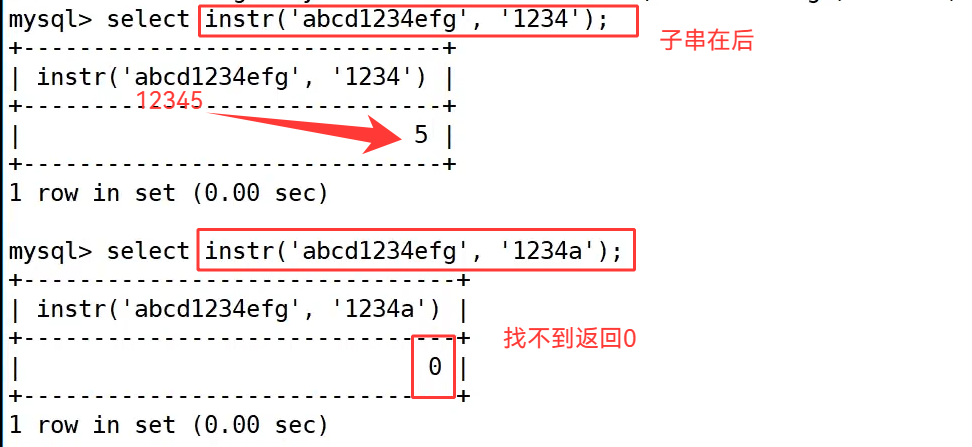
instr 返回子串出现的位置:
instr() 函数用于查找子字符串在目标字符串中首次出现的位置,返回从 1 开始计数的位置索引,如果找不到则返回 0。
示例:
第一个示例 select instr('abcd1234efg', '1234'); 中,子串 '1234' 在目标字符串的第 5 个位置开始出现,所以返回结果为 5;第二个示例 select instr('abcd1234efg', '1234a'); 中,目标字符串不存在子串 '1234a',因此返回 0,清晰体现了函数 "找不到则返回 0" 的特性。
ucase 转成大写字符串:
ucase() 函数的作用是将字符串中的所有字母转换为大写形式,数字和符号不受影响。
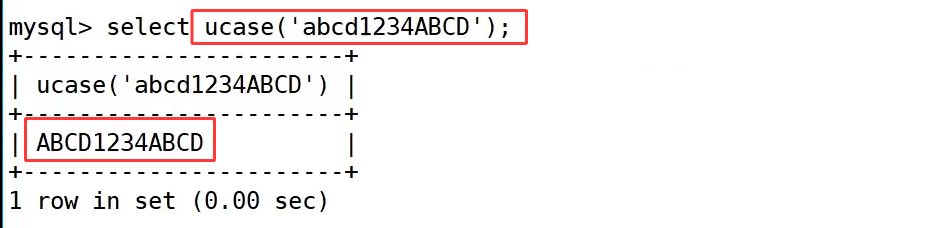 示例中执行 select ucase('abcd1234ABCD');,原字符串里的小写字母 abcd 被转为大写,最终返回 ABCD1234ABCD,实现了字母的全大写转换。
示例中执行 select ucase('abcd1234ABCD');,原字符串里的小写字母 abcd 被转为大写,最终返回 ABCD1234ABCD,实现了字母的全大写转换。
lcase 转成小写字符串:
lcase() 函数和 ucase() 功能相反,用于将字符串中的所有字母转换为小写形式,数字和符号保持不变。
示例:
示例中执行 select lcase('abcd1234ABCD');,原字符串里的大写字母 ABCD 被转为小写,最终返回 abcd1234abcd,实现了字母的全小写转换。
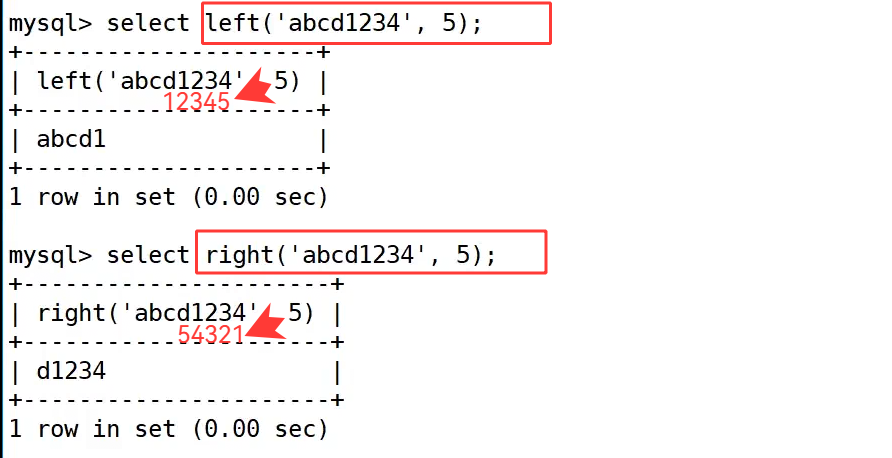
left/right 提取字符:
left() 和 right() 是一对用于截取字符串的函数,left() 从字符串的左侧开始截取指定长度的字符,right() 则从右侧开始截取。
示例:
示例中 select left('abcd1234', 5); 从左侧截取 5 个字符,返回结果为 abcd1;select right('abcd1234', 5); 从右侧截取 5 个字符,返回结果为 d1234,清晰展示了两者的截取方向差异。
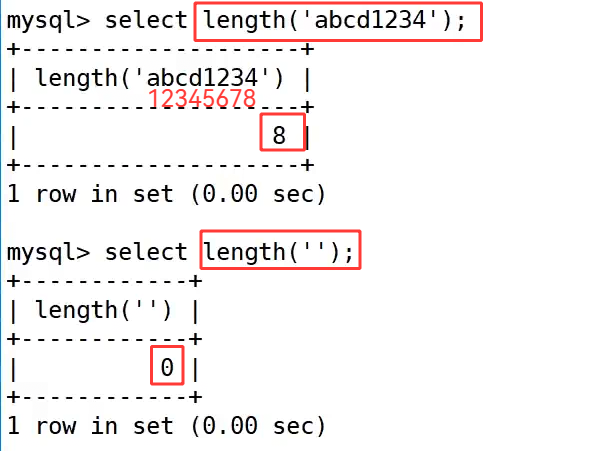
length 获取字符串长度:
length() 函数用于获取字符串的长度,返回字符串包含的字符数。
示例:
示例中 select length('abcd1234'); 统计字符串 'abcd1234' 的长度,返回结果为 8;select length(''); 统计空字符串的长度,返回结果为 0,体现了函数对空字符串的处理规则。
trim 清理空格:
trim()、ltrim() 和 rtrim() 是用于清理字符串空格的函数,trim() 会同时去除字符串左右两侧的空格,ltrim() 仅去除左侧空格,rtrim() 仅去除右侧空格,需要注意的是,这三个函数都不会去除字符串中间的空格。
示例:
示例中 select trim(' 你好 ') as res; 去除了字符串两端的空格,返回 '你好';select ltrim(' 你好 ') as res; 仅去除左侧空格,返回 '你好 ';select rtrim(' 你好 ') as res; 仅去除右侧空格,返回 ' 你好',直观体现了三者的功能区别。

关于后面的几个字符串函数我们下面举个样例说明:
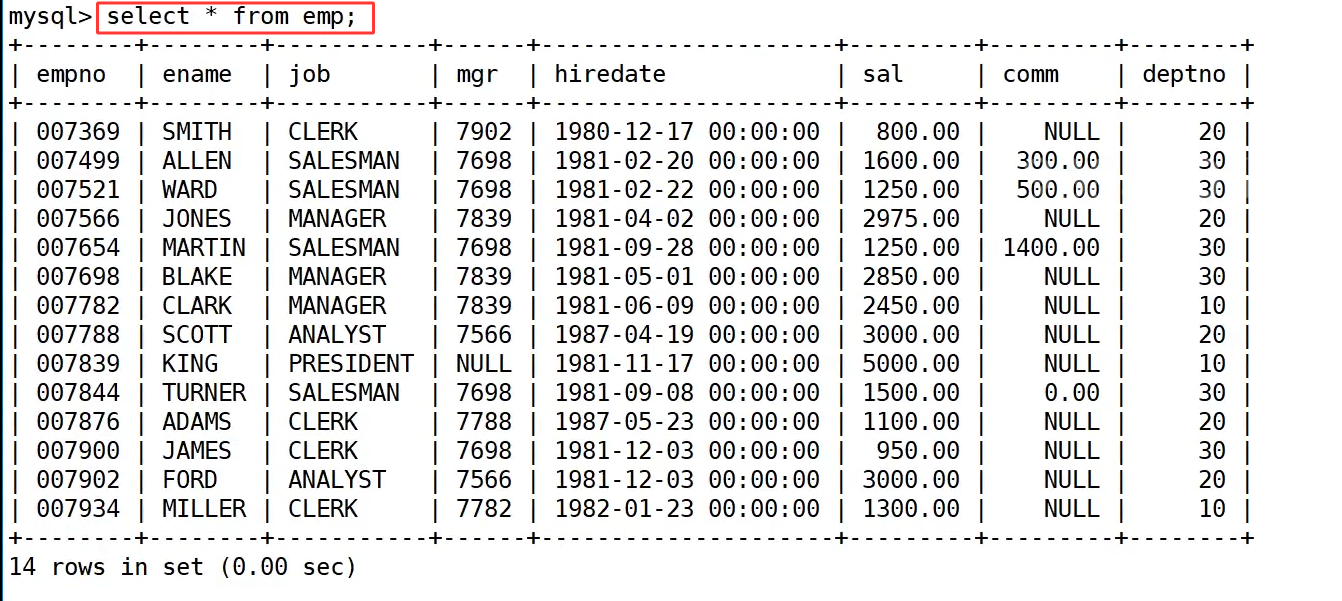
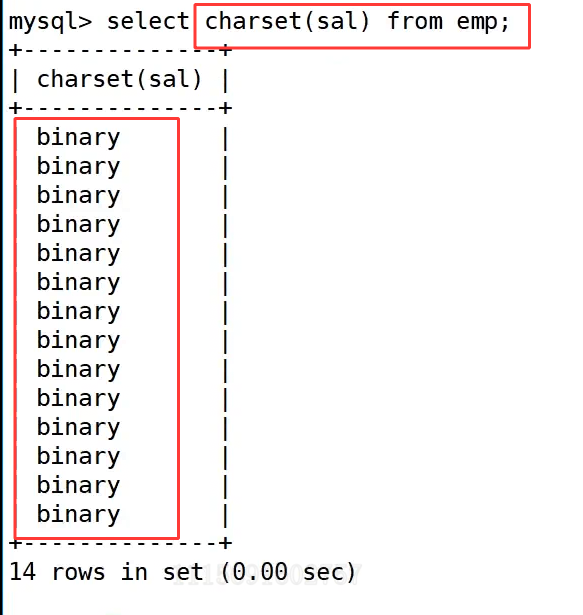
需求1 : 获取emp表的ename列的字符集
emp表如上,我们之前使用过,包含 empno、ename、job、sal 等字段共 14 条员工记录。
接下来,我们对两个不同类型的字段分别执行 charset() 函数。执行 select charset(ename) from emp; 查询 ename 列的字符集,结果显示所有记录的字符集均为 utf8,这符合我们对字符串类型字段的预期,表明员工姓名是以 UTF-8 编码存储的。作为对比,我们接着执行 select charset(sal) from emp; 查询 sal 列的字符集,结果显示为 binary。这是因为 sal 字段是数值类型(decimal),在 MySQL 中,数值型数据本身没有字符集的概念,charset() 函数会将其识别为二进制数据,因此返回 binary。这个案例清晰地展示了 charset() 函数的作用,同时也体现了它在字符串类型和数值类型字段上的不同表现。

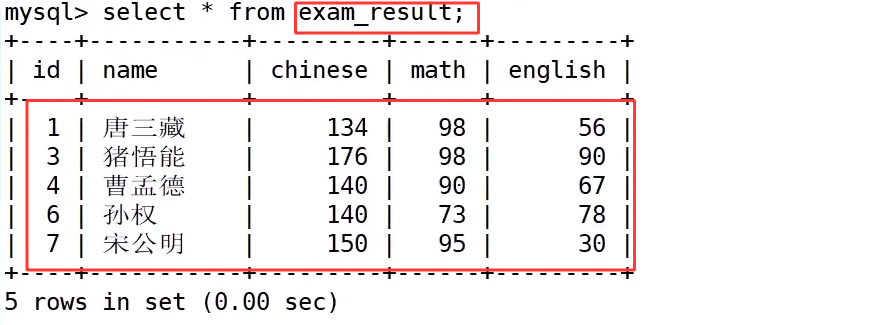
需求2 : 要求显示exam_result表中的信息,显示格式:"XXX的语文是XXX分,数学XXX分,英语XXX分"
exam_result 表如下,我们之前也使用过:
我们先通过 select * from exam_result; 可以看到表中存储了学生姓名和语文、数学、英语三科的成绩。
接着执行 select name, chinese+math+english 总分, chinese, math, english from exam_result;,先通过字段加法算出了每个学生的总分,同时查询了各科原始成绩,这一步是为后续拼接准备数据。
接下来就是核心的 concat() 拼接操作,语句 select concat('考生姓名: ',name, ', 总分: ', chinese+math+english, ', 语文成绩:',chinese, ', 数学成绩',math, ', 英语成绩:',english) msg from exam_result; 中,concat() 函数将固定文本、学生姓名、总分、各科成绩按顺序拼接在一起,生成了 考生姓名: 唐三藏, 总分: 288, 语文成绩:134, 数学成绩98, 英语成绩:56 这样的统一格式字符串,并且通过 as msg 给拼接后的列设置了别名。
这个案例直观展示了 concat() 函数的使用方法:它可以无缝拼接字符串、字段值和计算结果,而且会自动将数值类型的总分、成绩转换为字符串格式,非常适合用来生成固定格式的文本输出,比如报表、消息通知等场景。
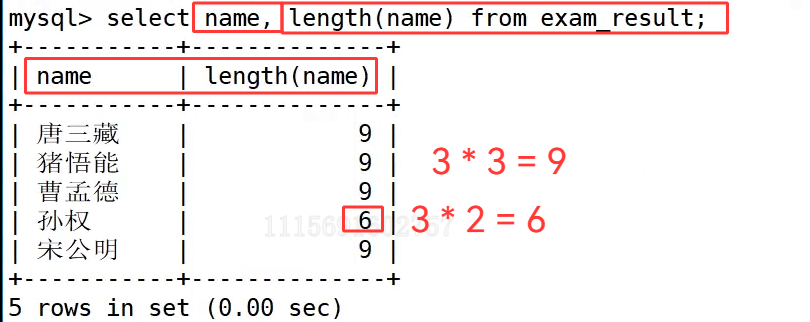
需求3 : 求学生表中学生姓名占用的字节数
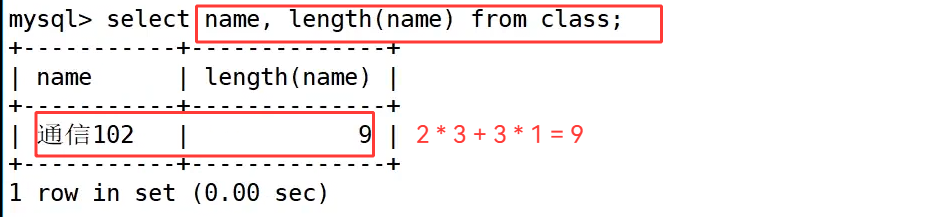
首先执行 select name, length(name) from exam_result; 查询 exam_result 表中学生姓名及其字节长度。在 UTF-8 编码下,一个汉字占用 3 个字节,所以 "唐三藏""猪悟能""曹孟德""宋公明" 这些三字姓名,字节数都是 9;而 "孙权" 是两个汉字,字节数为 6,和计算结果吻合。接着执行 select name, length(name) from class;,查询 class 表中的 "通信 102",这个字符串包含两个汉字和三个数字,汉字每个占 3 字节,数字每个占 1 字节,总字节数为 2×3 + 3×1 = 9,和函数返回的结果一致。
这两个示例直观说明了 length() 函数的核心特性:length() 返回的是字符串的字节长度,而非字符个数。在 UTF-8 编码中,英文、数字这类单字节字符,一个字符对应一个字节;而汉字这类多字节字符,一个字符对应多个字节,具体占用数和字符集编码有关,这也是处理中文数据时需要特别注意的地方。
replace 字符串替换:
replace() 函数的作用是在目标字符串中,将所有出现的指定子串替换为新的内容,它的语法是 replace(原字符串, 要查找的子串, 替换后的新字符串)。
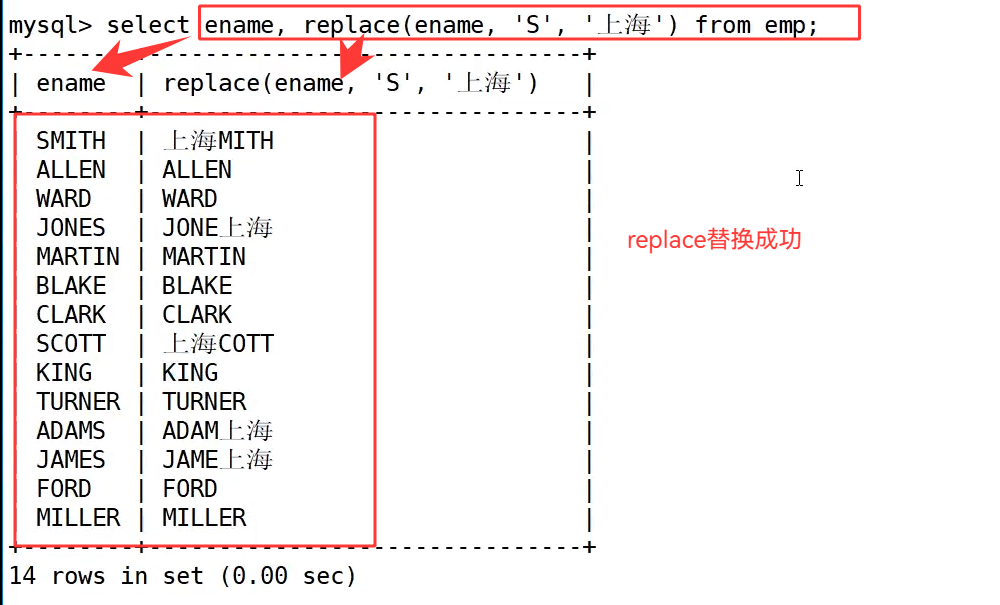
需求4 : 将EMP表中所有名字中有S的替换成****'上海'****
在 select ename, replace(ename, 'S', '上海') from emp; 这条语句中,函数会遍历 ename 字段的每一条记录,把所有的 'S' 都替换成 '上海',比如 SMITH 变成了 上海MITH,JONES 变成了 JONE上海,SCOTT 变成了 上海COTT,ADAMS 变成了 ADAM上海,JAMES 变成了 JAME上海,直观展示了替换效果。需要特别注意的是,select 语句中的 replace() 只是对查询结果做临时替换,并不会修改数据表中存储的原始数据,这一点在使用时需要区分清楚。
substring 字符串截取:
substring() 是 MySQL 中用于截取字符串的函数,它的基本语法为 substring(str, position , length),表示从字符串 str 的第 position 个字符开始,截取长度为 length 的子串;如果省略 length,则会截取到字符串末尾。
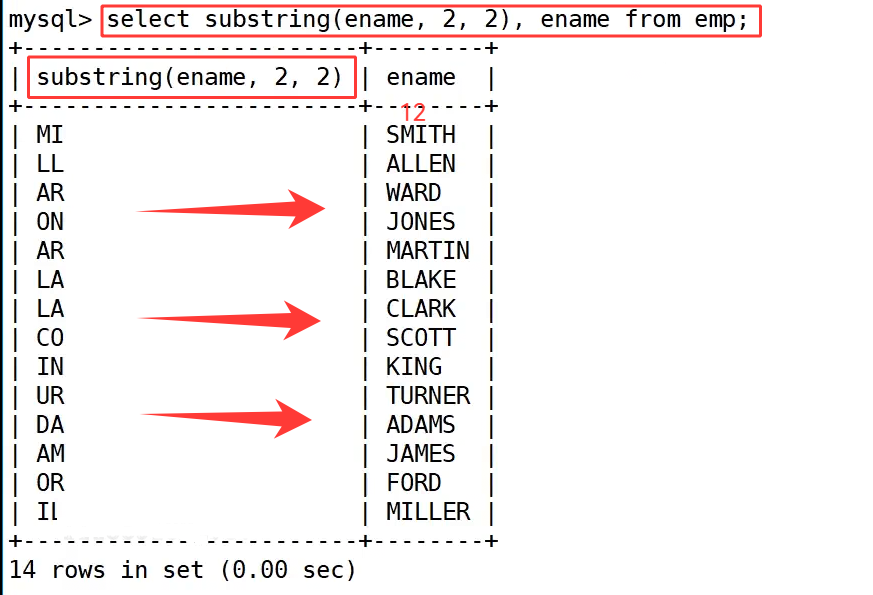
需求5 : 截取EMP表中ename字段的第二个到第三个字符
我们需要截取 emp 表 ename 字段的第 2 个到第 3 个字符,执行语句为 select substring(ename, 2, 2), ename from emp;。这里 substring(ename, 2, 2) 表示从第 2 个字符开始,连续截取 2 个字符,因此 SMITH 会截取为 MI,ALLEN 会截取为 LL,所有姓名都按规则得到了对应子串。
需求6 : 以首字母小写的方式显示所有员工的姓名
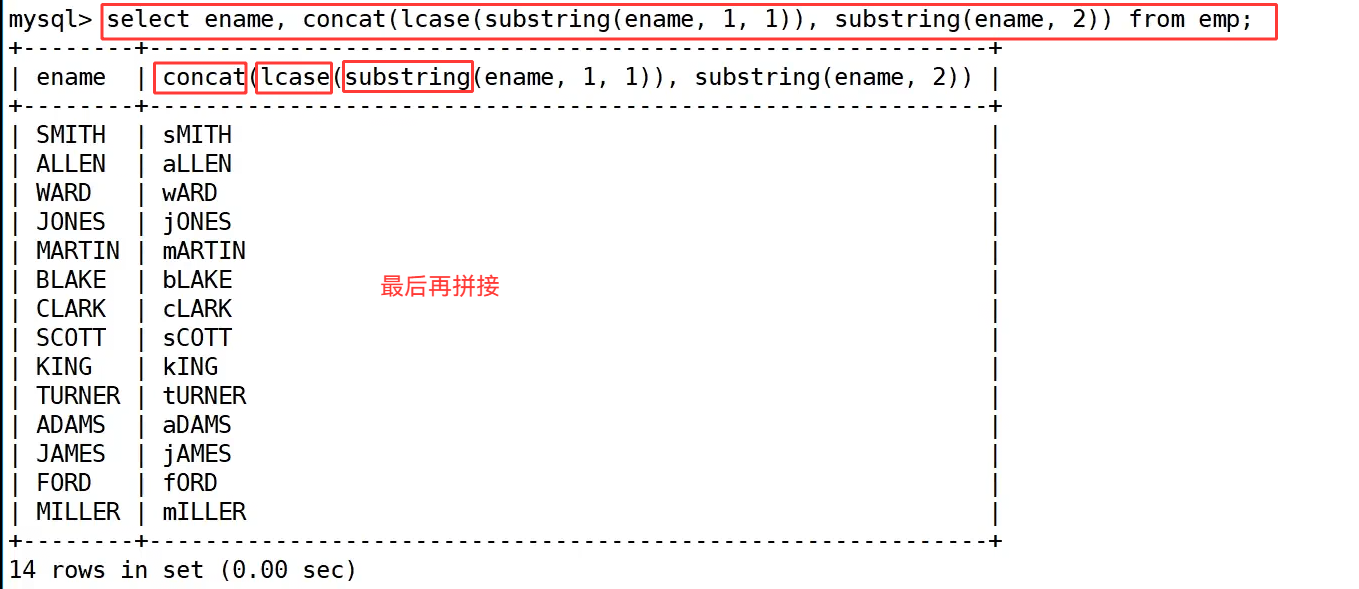
我们需要以 "首字母小写" 的方式显示所有员工姓名,这里需要组合使用 substring()、lcase() 和 concat() 函数。第一步先拆分处理,语句 select ename, lcase(substring(ename, 1, 1)), substring(ename, 2) from emp; 中,substring(ename, 1, 1) 截取姓名的首字母,再用 lcase() 转为小写;substring(ename, 2) 截取从第 2 个字符开始的剩余部分,这样就把姓名拆成了 "小写首字母" 和 "剩余部分" 两段。
第二步再用 concat() 函数将两段拼接起来,执行语句 select ename, concat(lcase(substring(ename, 1, 1)), substring(ename, 2)) from emp;,最终得到了 sMITH、aLLEN 这类首字母小写的完整姓名,直观展示了多个字符串函数组合使用的效果。
三、数学函数
上图展示了 MySQL 中常用的数学函数,这些函数主要用于数值计算、进制转换、取整、格式化和随机数生成等场景。abs(number) 用于计算数字的绝对值,不管输入正数还是负数,都会返回非负结果;bin(decimal_number) 和 hex(decimalNumber) 分别可以将十进制数转换为二进制和十六进制字符串,而 conv(number, from_base, to_base) 则是更通用的进制转换函数,支持任意进制之间的转换。ceiling(number) 和 floor(number) 是一对互补的取整函数,前者会向上去整。format(number, decimal_places) 可以将数字格式化并保留指定的小数位数,常用于处理金额、百分比等需要固定精度的数据。rand() 函数会返回一个范围在 [0.0, 1.0) 之间的随机浮点数,结合其他运算可以生成指定范围内的随机数,常用于数据抽样、随机排序等场景;mod(number, denominator) 则用于求两个数相除的余数,和 % 运算符功能类似,常用于判断数字的奇偶性或实现循环计数。这些函数可以独立使用,也可以组合起来解决复杂的数值处理问题,是数据库数据统计和分析中不可或缺的工具。
这些数学函数也比较常用,也比较简单,下面我们直接举例说明:
abs 取绝对值:
abs() 绝对值函数的作用是返回数字的非负形式,不管输入的是正数、负数还是小数,都会得到一个大于等于 0 的结果。
示例:
示例中 select abs(12); 直接返回了 12;select abs(-12); 将负数转为了 12;select abs(-12.3); 则保留了小数部分,返回 12.3,直观体现了它对不同数值类型的处理效果。

bin 十进制转二进制:
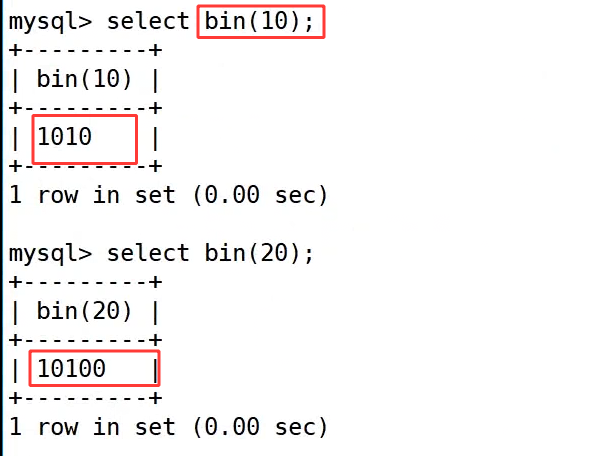
bin() 函数用于将十进制整数转换为二进制字符串。
示例:
示例中 select bin(10); 把十进制的 10 转为了二进制 1010;select bin(20); 则转为了 10100。需要注意的是,bin() 只能处理整数,浮点数无法直接转换,使用时要避免传入小数。
hex 转为十六进制:
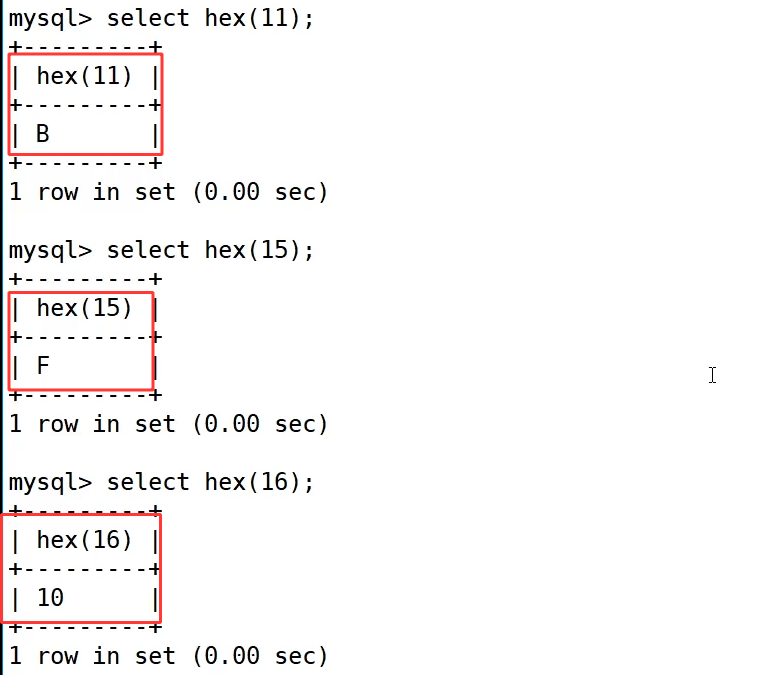
hex() 函数可以将十进制整数转换为十六进制字符串。
示例:
示例中 select hex(11); 返回了 B,select hex(15); 返回了 F,select hex(16); 返回了 10,符合十六进制的表示规则,适合处理需要以十六进制形式展示数据的场景。
conv 进制转换:
conv() 通用进制转换函数,它的语法是 conv(number, from_base, to_base),支持在不同进制之间互相转换。
示例:
示例中 select conv(10, 10, 2); 就是把十进制的 10 转换为二进制,返回结果 1010,和 bin(10) 的效果一致,说明 conv() 可以替代 bin()、hex() 这类专用转换函数,实现更灵活的进制转换需求。

format 格式化保留精度:
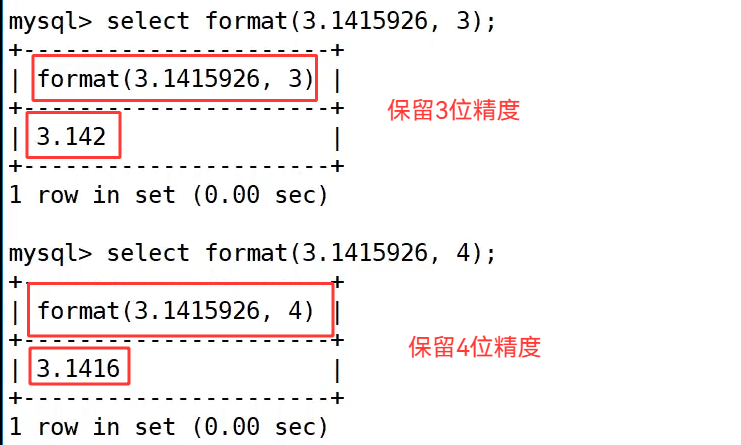
format() 格式化函数的作用是对数字进行格式化并保留指定的小数位数,同时会按规则进行四舍五入处理。
示例:
示例中 select format(3.1415926, 3); 将圆周率保留 3 位小数,结果为 3.142;select format(3.1415926, 4); 保留 4 位小数,结果为 3.1416,直观体现了它的精度控制效果,常用于金额、统计数据的展示场景。
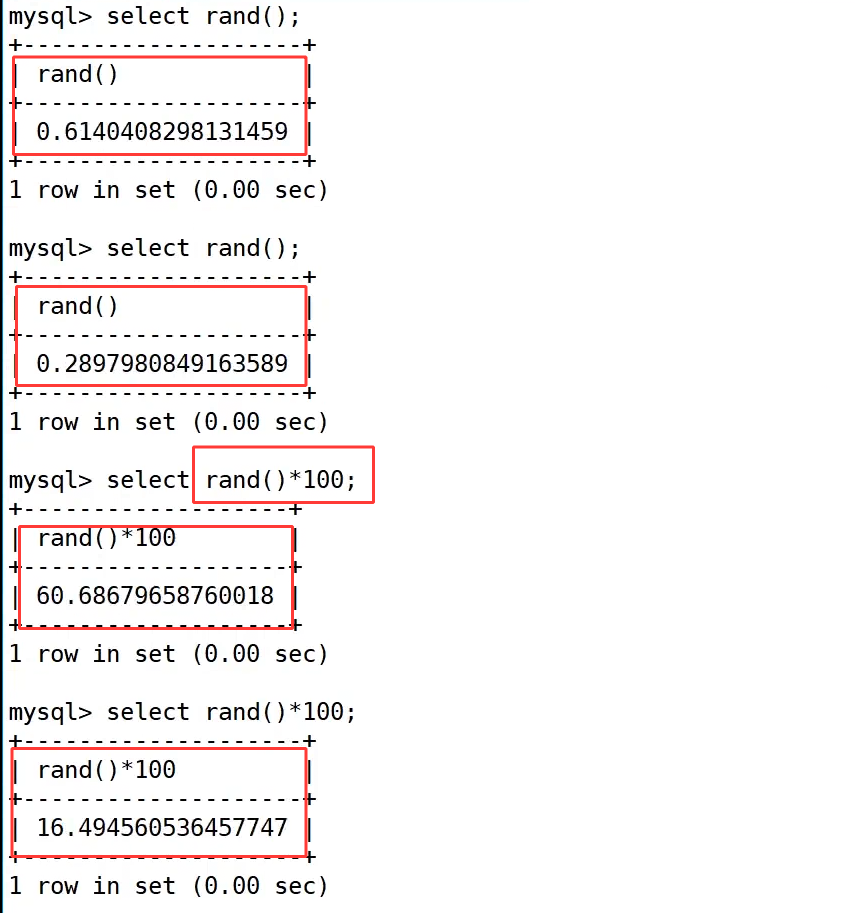
rand 生成并返回随机浮点数:
rand() 随机数函数默认返回一个范围在 [0.0, 1.0) 之间的随机浮点数,每次调用结果都不相同。

示例:
示例中直接执行 select rand(); 得到了不同的小数;通过 rand()*100 可以将随机数范围放大到 [0, 100),再配合 format(rand()*100, 0) 去掉小数部分,就能生成 0-100 之间的随机整数,实现了从随机浮点数到整数的转换。
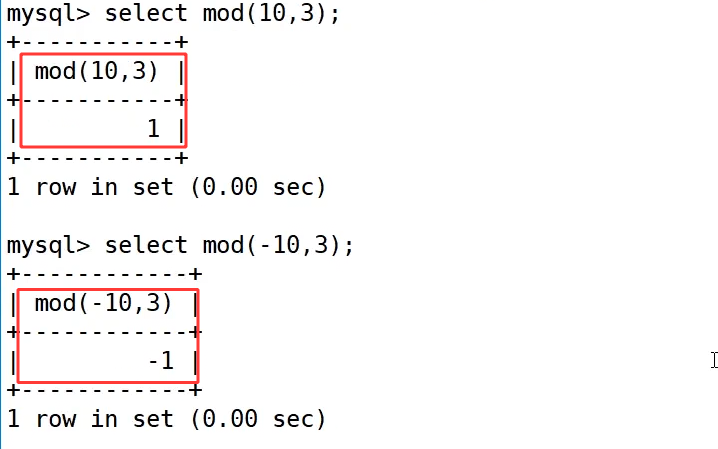
mod 取模求余:
mod() 取模函数用于计算两个数相除的余数,支持正数和负数运算。
示例:
示例中 select mod(10,3); 计算 10 ÷ 3 的余数,结果为 1;select mod(-10,3); 则返回 -1,说明取模结果的符号和被除数保持一致,和直接使用 % 运算符的效果完全相同,常用于判断数字奇偶性、循环计数等场景。
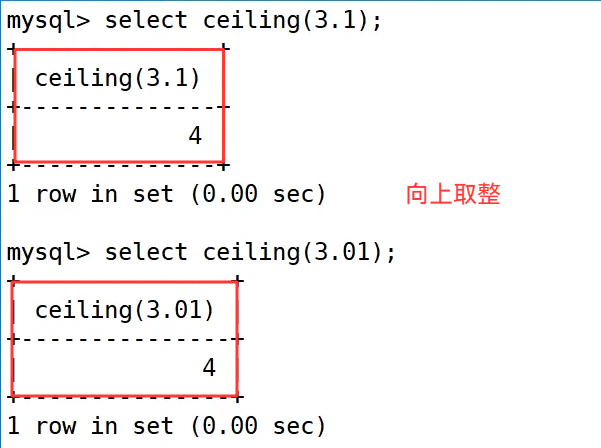
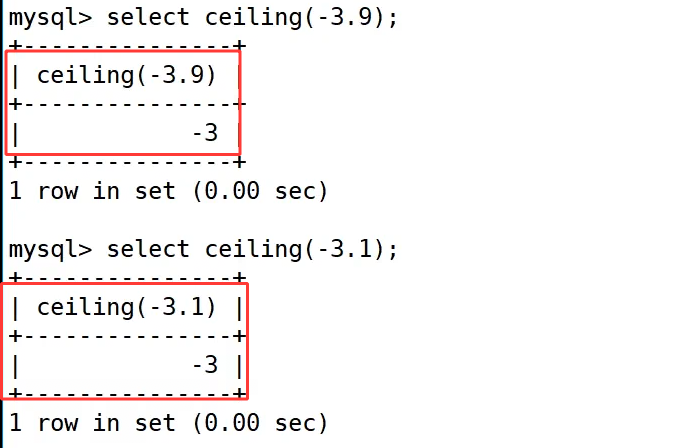
ceiling 向上取整:
ceiling() 向上取整函数,会将数字向 "更大的整数" 方向取整,无论正负。
示例:
对于正数 3.1 和 3.01,执行 select ceiling(3.1); 和 select ceiling(3.01); 都得到了 4;对于负数 -3.9 和 -3.1,select ceiling(-3.9); 和 select ceiling(-3.1); 都得到了 -3,因为 -3 比 -3.9 和 -3.1 更大,直观体现了 "向上" 的含义。
floor 向下取整:
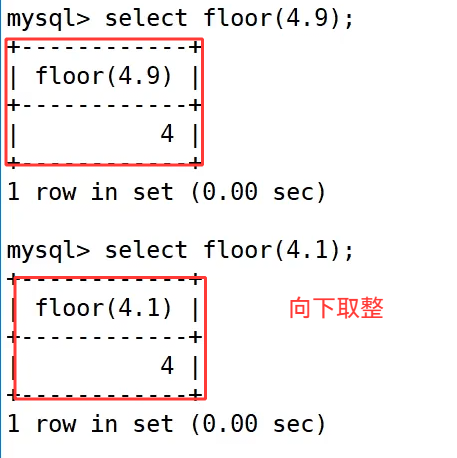
floor() 向下取整函数和 ceiling() 相反,它会将数字向 "更小的整数" 方向取整。
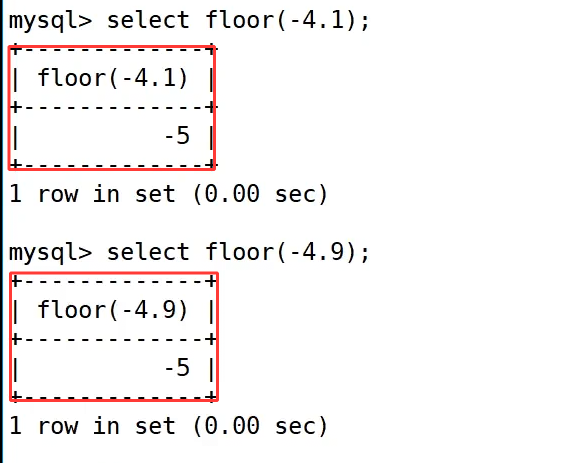
对于正数 4.9 和 4.1,执行 select floor(4.9); 和 select floor(4.1); 都得到了 4;对于负数 -4.1 和 -4.9,select floor(-4.1); 和 select floor(-4.9); 都得到了 -5,因为 -5 比 -4.1 和 -4.9 更小,和 ceiling() 形成了互补的取整效果。
正数负数都向上取 都变得更大正数负数都向下取 都变得更小
四、其他函数
user 查询用户:
user() 函数的作用是查询当前登录数据库的用户信息。
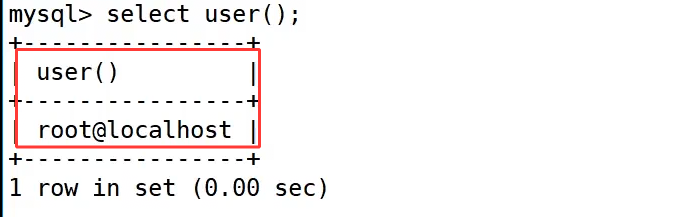
示例中执行 select user(); 后,返回了 root@localhost,这表示当前是 root 用户从本地主机登录的,格式为 用户名@主机名。在实际场景中,通过这个函数可以快速确认当前连接的用户身份,方便排查权限问题、区分不同的数据库会话。
md5 摘要:
md5() 摘要函数主要用于对敏感数据(比如用户密码)进行不可逆的加密处理,保障数据安全。
示例:
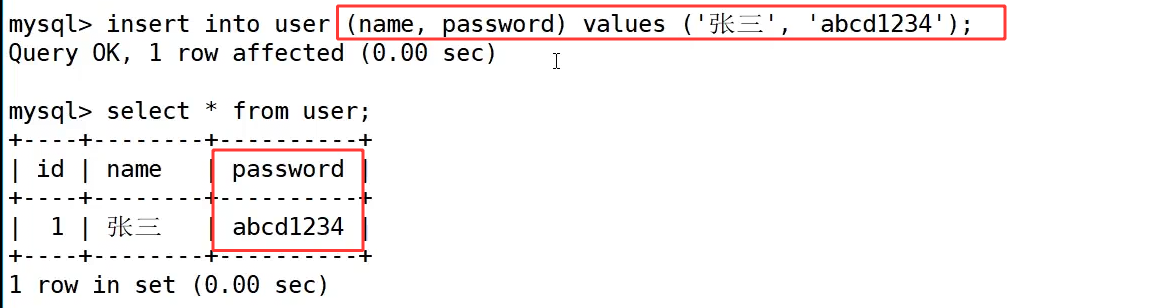
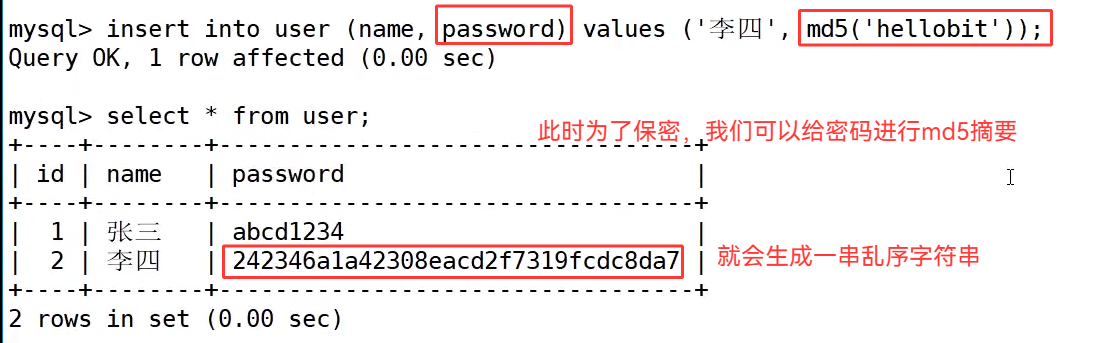
首先创建了一张 user 表,包含 id、name 和 password 三个字段,其中 password 字段被定义为 char(32) 类型,因为 md5() 生成的摘要结果固定为 32 位字符串。
插入数据:
第一次插入数据时,直接将明文 'abcd1234' 存入 password 字段,这种方式存在安全风险,因为明文密码可以被直接查看,同时 MySQL 也会对包含 password 字段的表禁用历史命令记录,避免泄露。此时如果我们上翻历史命令就找不到这条命令。
为了提升安全性,第二次插入数据时使用了 md5() 函数,执行 insert into user (name, password) values ('李四', md5('hellobit'));,将密码 'hellobit' 加密后存入数据库,此时 password 字段中存储的是一串乱序的 32 位字符串,而非明文,有效避免了密码泄露的问题。
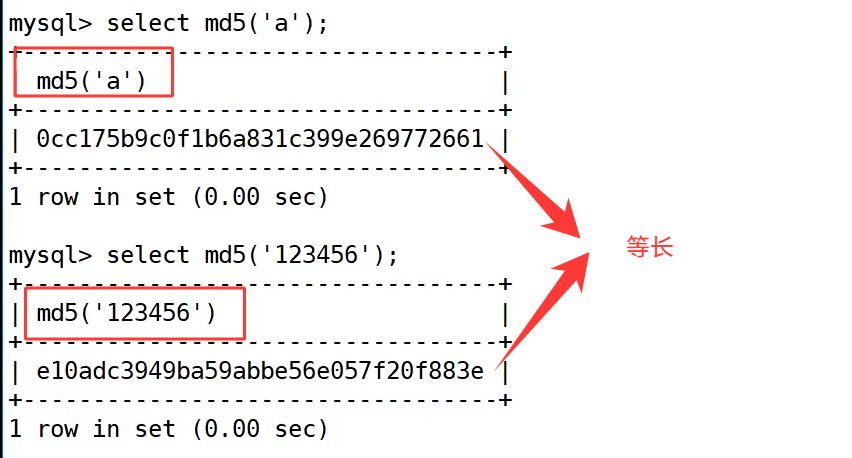
我们再单独测试了 md5('a') 和 md5('123456'),结果都生成了 32 位的摘要字符串,体现了 md5() 摘要结果 "定长" 的特点。
那如何查找密码呢?:
我们直接用明文 'hellobit' 去匹配 password 字段,无法找到对应记录;而使用 md5('hellobit') 生成摘要后再进行匹配,就能成功查询到用户 "李四"。这说明在实际登录验证场景中,前端传入的明文密码需要先通过 md5() 加密,再与数据库中存储的摘要进行比对,整个过程中明文密码不会直接出现在数据库中,从而实现了安全校验。
需要注意的是,md5() 是不可逆的加密算法,无法从摘要字符串反推出原始明文,这也是它适合存储密码的核心原因之一。

password 用户加密函数:
password() 用户加密函数是 MySQL 专属的账号密码加密函数,专门用于加密数据库登录账号的密码。
示例:
执行 select password('1223'); 后,会生成一串以 * 开头的哈希加密字符串,和明文完全无关,同时执行语句会附带警告,该函数安全性更高,仅用于数据库自身账号加密,不建议用来加密业务用户密码。
ifnull 函数:
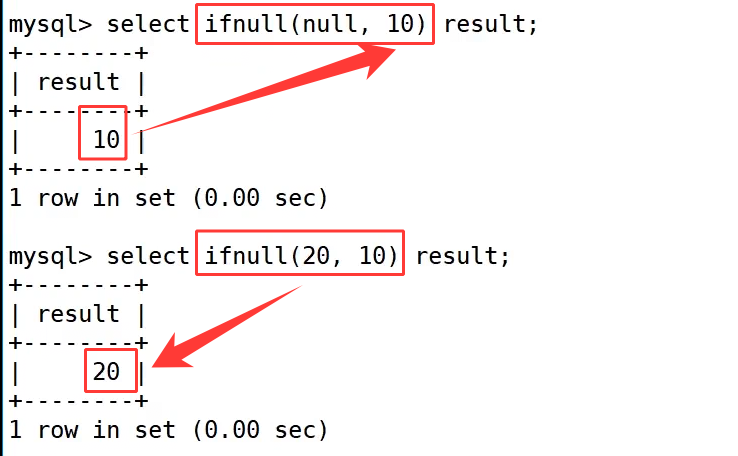
ifnull() 空值处理函数的语法规则为 ifnull(val1, val2),逻辑是当第一个参数 val1 为 null 时,返回第二个参数 val2;如果 val1 不为空,则原样返回 val1 的值。
示例:
示例中 select ifnull(null, 10) result; 因为第一个参数是空值,所以最终返回备用值 10;而 select ifnull(20, 10) result; 第一个参数不为空,就直接返回原值 20,这个函数经常用来处理表中允许为空的字段,避免空值导致统计、查询结果出错。
五、总结
本文介绍了MySQL中常用的内置函数,主要包括四大类:
-
日期函数:如current_date()、current_time()、now()获取当前时间,date_add()/date_sub()进行日期加减,datediff()计算日期差等,适用于时间维度的数据处理和统计。
-
字符串函数:包括concat()拼接字符串、instr()查找子串位置、ucase()/lcase()大小写转换、substring()截取字符串、replace()替换内容等,满足各类文本处理需求。
-
数学函数:如abs()取绝对值、bin()/hex()进制转换、format()格式化数字、rand()生成随机数、ceiling()/floor()取整等,用于数值计算和转换。
-
其他函数:如user()查询用户、md5()加密敏感数据、password()加密账号密码、ifnull()处理空值等特殊功能函数。
这些函数可以单独使用,也能组合应用,是数据库操作中不可或缺的工具,能显著提升数据处理效率和灵活性。
谢谢大家的观看!